
Парсинг сайтов — как получить данные с сайта

Парсинг является принятым в информатике определением синтаксического анализа. Например, когда мы читаем, то, с точки зрения филологии, проводится синтаксический анализ — сравнение увиденных на бумаге слов с теми, что имеются в нашем словарном запасе.
Программа (скрипт), которая позволяет компьютеру «читать», извлекать и проводить анализ данных, именуется парсером. Область использования подобных программ довольно обширная, вы можете ознакомиться с вариантами применения парсеров на siteclinic.ru.
Алгоритм действия парсера следующий:
- выход в сеть;
- доступ к коду веб-портала и его скачивание;
- чтение, извлечение данных и обработка;
- представление извлечённой информации в удобном формате: txt, sql, xml, html или иных вариантах.
Чем парсят сайты для технического SEO-аудита
Рассмотрим популярные программы для парсинга.
Обучение парсингу на Python, парсинг любых сайтов, в том числе SPA
Screaming Frog SEO Spider
Screaming Frog — всем известный британский парсер — лучшая программа в своей категории. Софт очень удобный — можно быстро собрать множество характеристик сайта и также легко просмотреть эти данные и проанализировать их.
Есть платная и бесплатная версии.
У программы имеется подробный мануал, где вы можете отыскать всю необходимую информацию для работы.
Минусы — завышенная цена платной версии и не очень-то комфортный интерфейс.
ComparseR
ComparseR — отечественный краулер, который прекрасно справляется с парсингом сайтов. Необходимо добавить, что его главная особенность — не просто спарсить странички ресурса, а ещё и проверить их индексацию в поисковых системах и сравнить с данными парсинга сайта.
Среди других фишек — сверка индексаций веб-страниц в Гугле и Яндексе и поиск определённого текста либо кода на сайте.
Есть платная и бесплатная версии.
Минус — нет перечня ссылок на страничку и со странички.
Netpeak Spider
Netpeak Spider 3.0 является новой версией парсера, премьера которой состоялась не так давно. Нетпик Спайдер — незаменимый инструмент для парсинга сайта. Главное отличие от «лягушки» — очень комфортный интерфейс на русском языке и широкие дополнительные функции.
Создатели программы говорят, что она также незаменима для работы с огромными сайтами, и при этом, ПК затрачивает мало ресурсов для работы с программой. Подобная функция на самом деле очень полезна, так как не каждая «машина» справляется с сайтами-миллионниками.
№191 — Что такое парсинг и как мы зарабатываем на парсинге сайтов? Делимся нашим опытом парсинга…
Подписка платная. Можно воспользоваться бесплатным пробным доступом, чтобы познакомиться с функционалом краулера.
SiteAnalyzer
SiteAnalyzer — веб-краулер, позволяющий парсить сайты и проверять их основные технические и SEO-параметры.
Программа анализирует контент, ищет технические ошибки (битые ссылки, дубликаты и пр.), а также ошибки в SEO-оптимизации (title, description, h1-h3 и др.). Всего анализируется более 60 параметров.
Программа полностью бесплатна. Работает без установки на ПК.
Для чего ещё используется парсинг сайтов
Главной проблемой современного Интернета считается избыток данных, которые человек не может сам систематизировать. Поэтому у парсеров безграничные возможности — от сбора цен с сайтов конкурентов, до наполнения карточек в интернет-магазинах и поиска контактов для прямых продаж.
Примеры применения парсинга:
- Анализ ценовой политики. К примеру, чтобы подсчитать среднюю цену каких-то услуг на рынке, нужно собрать массив данных по конкурентам. Вручную эту объёмную работу практически невозможно выполнить, а парсер может её выполнить легко и быстро.
- Отслеживание изменений. Парсер может постоянно мониторить сайты конкурентов и агрегаторов для поиска новых товаров или услуг, акций и скидок по рынку. Или следить за изменениями цен у партнёров.
- Наполнение интернет-магазинов. Если вы создали онлайн-магазин, счёт товаров в нём идёт на сотни и тысячи. Своими руками делать карточку каждого товара невозможно — уйдут месяцы, поэтому применяют парсинги. В основном парсят с иностранных порталов, переводят полученные тексты машиной и получают почти готовые описания товаров. В некоторых случаях парсят текст с русскоязычных магазинов и через синонимайзер делают описание уникальным.
- Наведение порядка на сайте . Парсер помогает это сделать — найти несуществующие странички, дубликаты товаров или изображений, отсутствие некоторых свойств товара, либо несоответствие товарных остатков на складе и информации на сайте.
- Получение базы потенциальных клиентов. Есть парсинг, который связан с подготовкой, к примеру, списка лиц, принимающих решение (ЛПР) в каком-то регионе или городе. Для этого используется аккаунт на порталах для поиска работы, с открытым доступом к архивным и актуальным резюме. Этичность последующего применения такой базы любая организация определяет самостоятельно.
Источник: apsolyamov.ru
Инструменты парсинга данных в 2021 году
Apify SDK — это масштабируемая библиотека для сканирования и просмотра веб-страниц на Javascript. Позволяет обрабатывать данные и полностью автоматизировать работу по сбору данных. Есть несколько тарифных планов, в том числе и бесплатный со своими ограничениями.
Apify SDK может использоваться автономно в ваших проектах Node.js или запускаться как бессерверный микросервис в облаке Apify (собственный сервер Apify Cloud). При обходе сайтов используется анонимный прокси, динамический в том числе. Может быть создана кастомная разработка под вашу потребность по запросу.
- Автоматизирует любой веб-рабочий процесс
- Позволяет легко и быстро обходить сайты в Интернете, в том числе списком
- Работает локально и в облаке
- Работает на JavaScript
- Работает с прокси
Content Grabber
http://www.contentgrabber.com/
Это мощное решение от компании Sequentum для сбора больших групп данных и главное надежного извлечения данных. Это позволит вам быстро и эффективно развернуть вашу компанию по сбору данных. Решение предлагает простые в использовании функции, такие как интуитивно понятный визуальный редактор.
- Извлекает данные быстрее чем другие похожие решения.
- Поможет вам в создании веб-приложения с помощью специального веб-API, который внедряется и позволяет выполнять сбор данных прямо с вашего сайта.
- Помогает вам переключаться между различными платформами (десктопная версия и серверная онлайн).
Data streamer
http://www.datastreamer.io
Data Stermer — инструмент помогает вам получать контент из всевозможных социальных сетей. Это позволяет извлекать метаданные с использованием обработки на естественном языке.
Простой в использовании API
Вы можете начать работу с Datastreamer менее чем за час. Если вы используете Java, вы сможете начать сбор данных за считанные минуты. Если вы используете другой язык, вам нужно анализировать только несколько файлов JSON каждые несколько секунд.
Построен на веб-стандартах
Создан с нуля, чтобы индексировать сырой HTML5. Сюда входят метаданные HTML, в том числе микроформаты и микроданные, — именно так Google и другие поисковые системы индексируют свой контент. Платформа также индексирует RSS и Atom (включая все 9 различных вариантов RSS). Обычные парсеры RSS хрупкие, но только не этот.
Надежная инфраструктура
Инфраструктура платформы является самой современной и предназначена для масштабирования. Все размещено на сверхбыстрых дисках SSD. Более 150 серверов в постоянной работе и компания хранит более 40 ТБ текстового контента. Каждый элемент инфраструктуры спроектирован с тройным резервированием и дополнительным оборудованием в режиме ожидания в случае сбоя. Data streamer контролируется 24/7 на предмет возможных ошибок в системе.
- Интегрированный полнотекстовый поиск на базе Kibana и Elasticsearch.
- Интегрированное удаление шаблонов и контента на основе методов поиска информации.
- Построен на отказоустойчивой инфраструктуре и обеспечивает высокую доступность информации.
- Простая в использовании и всеобъемлющая консоль администратора.
Источник: parsing-cloud.ru
Что такое парсинг сайтов
«Парсинг сайтов» или «парсинг контента» — это процесс извлечения данных любого сайта в сети Интернет.
Типичным примером парсинга контента является копирование списка контактов из некоего веб-каталога. Однако извлечение и сохранение данных с веб-страницы в таблицу Excel работает только с небольшими объемами данных и занимает значительное время. Чтобы обработать крупные массивы данных, нужна автоматизация. И здесь в дело вступают веб-парсеры.
Парсинг сайтов осуществляется при помощи специальной программы «веб-парсера» или «бота» или «веб-паука» (обычно все эти понятия используются как синонимы). Веб-парсер сканирует веб-страницы, загружает контент, извлекает из него нужные данные и затем сохраняет их в файлах или базе данных.
Для чего используется парсинг сайтов
Парсинг сайтов может использоваться для автоматизации всевозможных задач по сбору данных. Веб-парсеры вместе с другими программами могут делать практически все то же самое, что делает человек в браузере и многое другое. Они могут автоматически заказать вашу любимую еду, купить билеты на концерт, как только они станут доступны, периодически сканировать сайты электронной коммерции и отправлять вам текстовые сообщения, когда цена на интересующий вас товар снизится, и т. д.
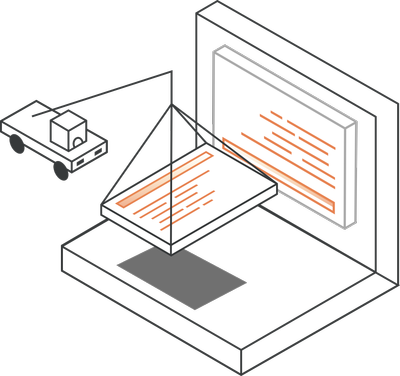
Как работает веб-парсер
Веб-парсер — это программа или скрипт, который используется для загрузки контента веб-страниц (обычно текста отформатированного на HTML) и извлечения из него данных.
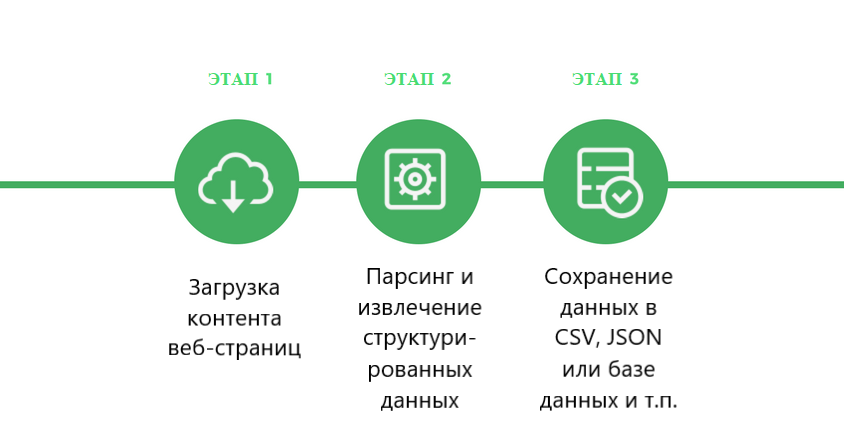
В действительности веб-парсеры имеют несколько более сложную структуру, чем показанная на диаграмме. Они состоят из множества модулей, которые выполняют различные функции.
Какие компоненты могут быть в веб-парсере
Веб-парсер сканирует веб-сайты, извлекает из ни данные, преобразует их в удобный структурированный формат и сохраняет в файле или базе данных для последующего использования.
1. «Сфокусированный» модуль веб-сканирования
Модуль веб-сканера перемещается по целевому веб-сайту, отправляя HTTP или HTTPS запросы на URL-адреса, следуя определенному шаблону или некоторой логике разбиения на страницы. Сканер загружает объекты ответа в виде содержимого HTML и передает эти данные в экстрактор. Например, сканер запустится на странице с адресом https://example.com и просканирует сайт, переходя по ссылкам на главной странице.
2. Модуль извлечения (экстрактор) или анализатор
Полученный HTML обрабатывается с использованием синтаксического анализатора, который извлекает необходимые данные из HTML в полуструктурированную форму. Существуют разные методы разбора:
- Регулярные выражения — набор регулярных выражений (RegExes) может использоваться для поиска по шаблону во время обработки текста в HTML данных. Этот метод полезен решения для простых задач, вроде извлечения списка всех электронных адресов на веб-странице. Но не подходит для решения более сложных задач, таких как получение различных полей на странице с описанием товара на сайте электронной коммерции. Тем не менее, регулярные выражения бывают крайне полезны при последующих преобразовании и очистке данных.
- Анализ HTML — это наиболее часто используемый метод анализа данных с веб-страницы. Большинство веб-сайтов опираются на некую базу данных, из которой они читают контент и создают разные страницы по одинаковым шаблонам. HTML анализаторы преобразуют код HTML в древовидную структуру, по которой можно перемещаться программно с использованием полуструктурированных языков запросов, таких как XPath или CSS-селекторы.
- Анализ DOM с использованием полных или «безголовых» (без визуального интерфейса) браузеров — Поскольку Интернет превратился в сложные веб-приложения, которые сильно зависят от JavaScript, простой загрузки веб-страницы и кода HTML стало недостаточно. Такие страницы динамически обновляют данные внутри браузера, не отправляя вас на другую страницу (используя запросы AJAX). Загружая HTML код таких веб-страниц, вы получаете только внешнюю HTML оболочку веб-приложения. Она будет содержать только относительные ссылки и не слишком релевантный контент или данные. Для таких веб-сайтов проще использовать полноценный браузер, такой как Firefox или Chrome. Этими браузерами можно управлять с помощью инструмента автоматизации браузера, такого как Selenium (пример см. на сайте http://lsreg.ru/parsing-sajtov-na-c/) или Puppeteer. Данные, получаемые этими браузерами, могут затем запрашиваться с помощью селекторов DOM, таких, например, как XPath.
- Автоматическое извлечение с использованием искусственного интеллекта — эта продвинутая техника более сложна и в основном используется, когда сканируется несколько сайтов, подпадающих под определенную вертикаль. Вы можете обучать веб-парсеры, используя модели машинного обучения по извлечению данных. Например, можно использовать модели распознавания именованных объектов для получения данных, таких как контактные данные, с просканированных веб-страниц.
3. Модуль преобразования и очистки данных
Данные, извлеченные синтаксическим анализатором, не всегда имеют формат, подходящий для немедленного использования. Большинство извлеченных наборов данных нуждаются в той или иной форме «очистки» или «преобразования». Для выполнения этой задачи используются регулярные выражения, операции со строками и методы поиска.
Если веб-парсер извлекает данные с небольшого количества страниц, то обычно извлечение и преобразование выполняются в одном модуле.
4. Модуль сериализации и сохранения данных
После получения очищенных данных их необходимо сериализировать в соответствии с заданными моделями данных. Это последний модуль, который выводит данные в стандартном формате, который может храниться в базах данных (Oracle, SQL Server, MongoDB и т.д.), в файлах JSON/CSV или передаваться в хранилища данных.
Как написать веб-парсер
Есть много способов написать веб-парсер. Вы можете написать код с нуля для всех вышеперечисленных модулей или использовать интегрированные среды с абстрактными слоями этих модулей. Написание кода с нуля отлично подходит для решения небольших задач по парсингу данных. Но как только парсинг выходит за рамки нескольких разных типов веб-страниц, лучше воспользоваться фреймворком.
Кроме этого, существуют инструменты для парсинга веб-страниц с помощью визуального интерфейса, где вы можете задавать необходимые для извлечения данные, и сервис автоматически создаст веб-парсер с этими инструкциями. Однако, подобные веб-инструменты находятся еще в сыром состоянии. Для более менее сложных задач вам все же придется написать код веб-парсинга самостоятельно.
Источник: msiter.ru
Что такое парсинг и как правильно парсить

Понятие «парсинг» в рунете имеет отчетливо негативный оттенок. Его считают чем-то вроде хакинга. При этом парсерами пользуются многие компании: и небольшие стартапы, и серьезные бизнес-игроки.
Почитать позже

Поможем вашему бизнесу оптимизировать расходы на маркетинг и увеличить прибыль!
Парсинг – это автоматизированный сбор информации (товаров, услуг, прайсов, тарифов, компаний и т.д.) из интернета и ее систематизация. Простыми словами, это быстрое получение нужных данных из выдачи с помощью программ.
В законодательстве РФ нет статьи, запрещающей автоматический сбор. Если заимствованная из выдачи информация используются законным образом, то в этом нет ничего аморального или криминального. Например, когда вы парсите прайс для анализа цен конкурентов, это часть стандартного маркетингового исследования.
Собирая и размещая список услуг компаний на своем агрегаторе, вы способствуете продажам и развитию бизнеса. Другое дело, когда вы делаете сбор данных с сайта-конкурента, и полученный контент размещаете у себя на страницах. Воровство фотографий и текстов конкурентов – это нарушение авторских прав. Но это уже не про процесс сбора, а про использование результата.
В чем преимущества
В отличие от того же хакинга, при парсинге собираются данные из открытых источников – из выдачи поисковых систем, которые компания не скрывает ни от потребителей, ни от конкурентов. То же самое (например, собрать несколько тысяч позиций товаров) можно сделать и вручную, но на это будут потрачены неадекватно большие ресурсы – временные и человеческие.
Поэтому сбор информации «поручают» программам. Эта процедура страхует от ошибок, которые бывают при ручном сборе. Ее можно регулярно повторять, чтобы корректировать полученные данные. Информацию легко структурировать, привести к заданному формату, меняя настройки.
Какую информацию можно собирать
Практически любую, которая находится в открытом доступе:
- Товары и услуги. Парсинг товаров часто используют интернет-магазины.
- Цены и тарифы. Парсинг цен маркетологи применяют для корректировки ценообразования в своей компании.
- Контент: характеристики, текстовые описания, картинки.
- Объявления.
- Ссылки. Например, парсер ссылок может понадобиться для анализа структуры интернет-магазина через карту сайта.
- Контакты и данные конкурента.
- Телефоны организаций.
- Объемы продаж. Некоторые сайты публикуют данные об остатках товаров на складе, а это полезная маркетинговая информация.
- Новости. Парсер новостей из СМИ применяют новостные агрегаторы.
- SEO-специалисты используют парсер позиций сайта-конкурента и проводят сбор ключевых слов. Для них же разработали несколько программ-парсеров поисковых запросов. Есть сервисы, которые могут выгрузить title, description, keywords и заголовки сайтов-конкурентов.
- Можно парсить даже собственный проект, чтобы навести порядок, например, чтобы избавиться от битых ссылок, увидеть, где не хватает фотографий, текстовых описаний и т.д.
Какие алгоритмы задействованы
Программы для парсинга сайтов работают по одной общей схеме:
- Программа ищет данные по заданным параметрам или ключевым словам.
- Все это собирается и систематизируется по заданным критериям.
- Формируется отчет. Он может быть в любом формате: CSV, Excel, XML, JSON, pdf, docx, zip и других.
Для получения контента и данных с сайта нужна специальная программа. Это может быть универсальный парсер (например, облачные русскоязычные сервисы Xmldatafeed, Диггернаут, Catalogloader). У большинства таких программ есть бесплатные и платные версии. Стоимость большинства сервисов невысока. В некоторых случаях, например, для сбора нескольких десятков характеристик товаров, достаточно пробной версии.
Иногда требуется сервис, разработанный под ваши конкретные задачи. Он может быть написан на любом языке программирования. Для парсинга страницы, если нужна не полная информация, а только отдельные элементы (например, только цена), применяют язык XPath.
Как парсить сайты и обрабатывать данные
Для примера расскажем, как спарсить товары с сайта интернет-магазина.
- Нужно четко понять, что именно надо собрать. Программы имеют множество фильтров, которые позволяют сразу отсечь все лишнее. Например, вам нужны только товары из конкретного раздела или с определенными ключевыми словами. Возможно, будет достаточно каталога и прайса без текста и характеристик.
- Найти сайт-донор (или несколько). Донора нужно указать в специальном окне программы.
- Выставляем фильтры, меняем настройки (в каждом сервисе они свои) и запускаем сбор данных.
- Полученные данные формируются в файл (текстовый, в форме таблицы, архива и т.д.). Удобный формат файла задается в настройках сервиса.
Использовать полученную информацию можно по-разному. Данные по ценам, тарифам, объемам продаж применяют для маркетингового анализа конкурентов.
Список ключевых слов из топа выдачи поисковых систем используют для сбора семантического ядра.
Контент можно импортировать на собственную площадку (например, на агрегатор). Текстовые данные иногда перерабатывают (например, с помощью синонимайзера). Уникальный авторский контент использовать нельзя, это нарушение авторских прав.
Полезна связка «парсинг конкурента-самопарсинг», когда сравнивается информация на двух сайтах. Процедура позволяет получить недостающее (например, товарные позиции) и импортировать их на свою площадку.
Читайте на AskUsers
В топе выдачи поисковиков по коммерческим запросам все чаще оказываются сайты-агрегаторы. Это платформы в виде каталога, где собраны товары, услуги, сервисы или новости. Рассказываем, как создать и продвинуть агрегатор.
Google Sheets – удобный инструмент, с которым можно планировать (например, прибыль и затраты), проводить маркетинговый анализ, вести учет доходов и т.д. Мы составили большой гайд по работе с Google Таблицами.
Источник: askusers.ru