
В современном мире все процессы подвергаются цифровизации, даже процесс переноса текста из бумажных носителей в цифровой вид. В этом помогают системы оптического распознавания символов (OCR).
Их существует довольно большое количество, однако если необходимо работать с текстом, написанным кириллическими символами, то часть систем не рассматривается ввиду отсутствия возможности распознавания таких символов. При этом необходимость сделать выбор в пользу той или иной системы остается.
Выбор конкретной системы оптического распознавания символов должен основываться на объективных характеристиках, таких как точность, скорость и используемая память. Исследования, оценивавшие эти параметры для OCR, уже существуют, однако они были проведены на некириллических символах.
Цель этой статьи – провести сравнительный анализ некоторых систем OCR (ABBYY FineReader, CuneiForm, OCRopus, Tesseract, Transym OCR) при работе с текстами, написанными с помощью кириллического алфавита. Исследование проводилось на 20 отсканированных страницах без применения предварительной обработки, чтобы учесть наличие таковой в системах OCR.
Вебинар. 31.10.2022 Система оптического распознавания текста «SETERE OCR»
В результате сравнительного анализа было установлено, что лучшей из рассматриваемых OCR по точности распознавания кириллических символов является ABBYY FineReader, худшие показатели по точности имеет Transym OCR. Самой быстрой системой оказалась Tesseract, самой медленной – OCRopus. Лучший результат по используемой памяти показала система CuneiForm. Худший же – ABBYY FineReader.

оптическое распознавание символов
ABBYY FineReader
Transym OCR
1. Karat C.-M., Halverson C., Horn D., Karat J. Patterns of Entry and Correction in Large Vocabulary Continuous Speech Recognition System. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 1999. P. 568–575. DOI: 10.1145/302979.303160.
3. Vijayarani S., Sakila A. Performance Comparison of OCR Tools. International Journal of UbiComp. 2015. Vol. 6. No.
3. P. 19–30. DOI: 10.5121/iju.2015.6303.
5. Mittal R., Garg A. Text extraction using OCR: A Systematic Review. 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA). 2020. P. 357–362. DOI: 10.1109/ICIRCA48905.2020.9183326.
6. Smith R. History of the Tesseract OCR engine: what worked and what didn’t. Proc. SPIE 8658, Document Recognition and Retrieval XX. 2013. URL: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/8658/1/History-of-the-Tesseract-OCR-engine—what-worked-and/10.1117/12.2010051.full. (дата обращения: 16.02.2022).
DOI: 10.1117/12.2010051.
7. Как мы сделали ABBYY FineReader, или история, произошедшая 20 лет назад. [Электронный ресурс]. URL: https://www.abbyy.com/ru/blog/2015/11/kak-myi-sdelali-abbyy-finereader-ili-istoriya-proizoshedshaya-20-let-nazad/ (дата обращения: 16.02.2022).
8. Tafti A.P., Baghaie A., Assefi M., Arabnia H.R., Yu Z., Peissig P. OCR as a Service: An Experimental Evaluation of Google Docs OCR, Tesseract, ABBYY FineReader, and Transym. International Symposium on Visual Computing. 2016. Vol. 10072.
Оформление титульной страницы, системы оптического распознавания текстов и автоматического перевода
P. 735-746. DOI: 10.1007/978-3-319-50835-1_66.
9. Технологии. 2009. [Электронный ресурс]. URL: https://web.archive.org/web/20090401061559/http://www.cuneiform.ru/tech/index.html (дата обращения: 16.02.2022).
10. Jain P., Taneja K., Taneja H. Which OCR toolset is good and why: A comparative study. Kuwait Journal of Science. 2021. Vol. 48. No. 2. P. 1–12.
DOI: 10.48129/kjs.v48i2.9589.
11. Kainz O., Dujava M., Petija R., Michalko M., Jakab F. Measurement of Water Consumption based on Image Processing. 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). 2021. P. 33–38. DOI: 10.1109/SAMI50585.2021.9378611.
13. Patel C., Patel A., Patel D. Optical Character Recognition by Open source OCR Tool Tesseract: A Case Study. International Journal of Computer Applications. 2012. Vol. 55. No. 10.
P. 50–56. DOI: 10.5120/8794-2784.
14. FAQ. [Электронный ресурс]. URL: https://transym.com/faq/ (дата обращения: 16.02.2022)
В мире наступила эпоха цифровизации, когда бумажные документы переводятся в цифровой вид. Огромное количество текста не позволяет использовать человеческий труд из-за низкой скорости печатания. Исследование, проведенное группой ученых в 1999 г., показало, что средняя скорость ввода слов на клавиатуре человеком – 19 слов в минуту [1].
Если взять за среднее число символов в слове равное 5,1 [2], то в среднем человек вводит 5,1×19=96,9 символов в минуту. Так, чтобы перепечатать документ с 40000 символами (один авторский лист) потребуется 40000/96,9/60=6,88 ч, а таких документов может быть очень много. Поэтому практичным решением будет переложить процесс переноса текста из бумажного вида в цифровой с человека на компьютер, а человеку оставить только редактуру введенного программой текста, однако и тут можно значительно снизить участие человека, если использовать системы корректировки грамотности слов.
Преимущество передачи роли наборщика текста компьютеру также заключается в том, что компьютер не знает усталости, и если человек при долгом наборе текста устает и начинает делать ошибки, то компьютер не подвержен этому и точность вводимого текста не зависит от времени работы.
Примером, когда может понадобиться данный подход, может служить следующий случай: имеется большой объем документации, представленной в бумажном виде, при этом нет цифровых оригиналов. В этой ситуации автоматическое введение текста может сильно упростить жизнь человеку. Такой подход полезен, когда надо оцифровать содержимое старой книги. Ведь постоянное перелистывание страниц может повредить листы старого документа.
В связи с этим встает вопрос: какую систему оптического распознавания символов (OCR) стоит использовать при работе с документами, написанными с помощью кириллического алфавита? Чтобы ответить на этот вопрос, необходимо провести исследование, в ходе которого будут установлены характеристики (точность, скорость, потребление памяти) различных систем оптического распознавания символов при работе с кириллическим алфавитом. В данной статье будет приведено описание такого исследования и результаты его проведения.
В мире существуют исследования, сравнивающие различные системы оптического распознавания символов [3, 4]. Однако все они были проведены на некириллических символах.
В большинстве OCR процесс распознавания символов обязательно содержит следующие этапы [5]:
− определение потенциальной области интереса;
− обнаружение признаков символов в области интереса;
− определение символа по обнаруженным признакам.
В отдельно взятых системах оптического распознавания символов могут присутствовать и дополнительные действия как, например, в Tesseract, который в процессе распознавания текста дополнительно обучается [6].
Материалы и методы исследования
Существуют различные системы оптического распознавания символов, однако часть из них может работать только с текстами, состоящими из одной латиницы. Такие OCR в данной работе рассматриваться не будут. В качестве исследуемых OCR выступают следующие системы оптического распознавания символов, в скобках указана версия: ABBYY FineReader (15.0.117.9681), CuneiForm (1.1.0), OCRopus (1.3.2), Tesseract (5.1.0.20220510) и Transym OCR (5.1). Существуют и другие OCR, которые работают с кириллическими символами, например OmniPage, однако они будут рассмотрены в последующих работах.
ABBYY FineReader – коммерческое программное решение, созданное российской компанией ABBYY. Работа над первой версией программы началась в 1992 г. из-за возникшей потребности при разработке комплекса программ Lingvo Systems [7]. Внутренняя технология распознавания держится в секрете [8]. Программа поддерживается и по сей день, периодически выходят обновления и новые версии.
CuneiForm – бесплатная система OCR, которая изначально разрабатывалась российской компанией Cognitive Technologies. Первая версия программы появилась в 1993 г. и изначально распространялась как коммерческий продукт, однако в 2008 г. Cognitive Technologies решила открыть исходный код CuneiForm всему миру. Система оптического распознавания символов в своей работе использует следующие технологии: адаптивное распознавание, нейронные сети, когнитивный анализ альтернатив распознавания, меридианная сегментация таблиц [9]. Программа CuneiForm способна распознавать тексты на более чем 17 языках, при этом программа может обрабатывать кириллицу и латиницу в одном тексте [10]. На текущий момент эта OCR не развивается.
OCRopus – набор программ с открытым исходным кодом для анализа документов, в том числе для распознавания текста. Первая версия системы анализа документов была выпущена в 2007 г. OCRopus является расширяемой системой, что позволяет изменять ее под свои нужды, стоит отметить, что модульность в его архитектуру закладывалась ещё в самом начале разработки [11]. OCRopus написан на устаревшей на сегодняшний день версии Python – 2.7.
Tesseract – система оптического распознавания символов, изначально разработанная компанией HP для использования в принтерах своего производства. Примечательно, что Tesseract начинался как PhD проект [12]. Первое публичное упоминание датируется 1995 г. на конференции, посвященной системам OCR, после чего Tesseract на какое-то время исчез из информационного поля [12].
В 2005 г. HP открыла исходный код Tesseract [6], после этого с 2006 по 2018 г. система поддерживалась и разрабатывалась компанией Google. Стоит отметить, что Tesseract проходит по тексту два раза, в первый раз он распознает то, что получится, при этом он одновременно дополнительно обучается; и во второй раз Tesseract распознает, то что не было распознано в первый раз [6]. Также Tesseract предлагает три натренированные модели: быстрая, точная и стандартная, которая поддерживается старыми версиями программы.
Transym OCR – коммерческая система оптического распознавания символов, разработанная компанией Transym Computer Services и выпущенная в 2002 г. TOCR разработан специально для встраиваемых систем и различных интеграций. По заявлениям разработчиков для обучения TOCR используется более 108000 файлов изображений документов. Для проверки правильного распознавания слов в системе используется соответствие распознанного слова со списком часто употребляемых слов [10]. Перед распознаванием TOCR проводит предварительную подготовку изображения текста в виде перевода изображения в оттенки серого [13]. При работе с изображением документа программа сама определяет язык, на котором нужно производить распознавание текста [14].
В качестве тестовых данных для исследования использовались отсканированные страницы из книги Джека Лондона «Белый клык» в количестве 20 экземпляров. Для более объективных результатов сравнительного анализа предварительная подготовка изображений страниц книги не проводилась. Сделано это было для того, чтобы на результате распознавания отразилось наличие или отсутствие предварительной обработки изображений, непосредственно встроенной в конкретную систему оптического распознавания символов. Фрагмент одной отсканированной страницы представлен на рис. 1.
Стоит отметить, что никакие настройки в системах оптического распознавания символов не изменялись, за исключением установки русского языка, однако в Transym OCR это не применялось из-за заверений разработчиков, что система может сама определять язык. Вся работа происходила с установленными разработчиком настройками. Некоторые системы OCR являются коммерческим продуктом, в этом случае для сравнительного анализа использовались их пробные версии.
Само исследование проводилось на персональном компьютере, обладающем следующими характеристиками: процессор – Intel Core i5 8500 с частотой 3 ГГц; оперативная память – DDR4 24 Гб с частотой 1 ГГц.
Сравнение различных систем оптического распознавания символов проводилось по определенному алгоритму. Были подготовлены отсканированные страницы книги в формате PNG. Если OCR представлял собой программный фреймворк, то была написана программа, использующая его. Далее одновременно замерялось время выполнения распознавания и расход памяти в диспетчере задач. После распознавания символов полученный текст сравнивался с эталонным, то есть оригинальным; подсчитывалось число ошибок и исходя из этого вычислялась точность распознавания символов. Вычисление точности распознавания текста с кириллическими символами производилось по формуле
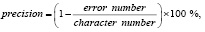
где precision – точность распознавания символов; error number – число ошибок; character number – число символов в эталонном тексте.
В качестве еще одной меры точности распознавания использовалось расстояние Левенштейна, которое представляет собой минимальное количество операций, производимых над символами и необходимых для преобразования одной строки в другую. Чем меньшее значение имеет расстояние Левенштейна, тем больше совпадение распознанного текста и эталонного.
В качестве результирующих данных для каждой OCR были взяты средние арифметические значения результатов, полученных для всех 20 изображений текста.
Графическое представление вышеописанного алгоритма изображено на рис. 2.

Рис. 1. Фрагмент отсканированной страницы
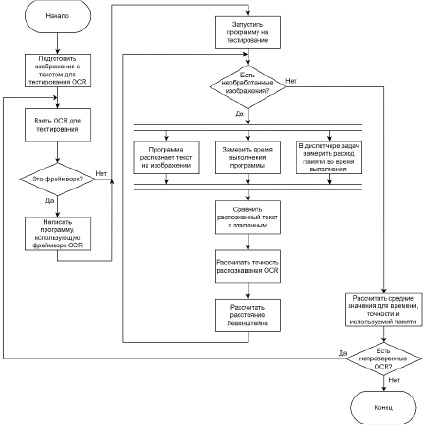
Рис. 2. Алгоритм сравнения систем оптического распознавания символов
Результаты исследования и их обсуждение
В процессе распознавания системами OCR были допущены различные ошибки. Некоторые из них представлены в табл. 1.
Результаты сравнительного анализа представлены в табл. 2.
В процессе проведения сравнительного анализа были отмечены различные особенности некоторых систем OCR. Система OCRopus требует выполнения сложной установки относительно всех остальных систем оптического распознавания символов. Помимо этого, система написана на старой версии языка программирования Python, что накладывает некоторые ограничения при работе с ней. Еще одним выделяющимся аспектом является то, что необходимо вручную запускать множество скриптовых сценариев. Весьма важную особенность также продемонстрировала система Tesseract, при выполнении распознавания текста данная OCR добавляет множество символов переноса в результат своей работы, что следует учитывать при работе с Tesseract.
В процессе распознавания символов OCR допускали различные ошибки, которые были продемонстрированы в табл. 1. Можно предположить, что при проведении аналогичного этой работе исследования при наличии гораздо большей выборки можно будет выделить некоторые частотные характеристики для пар «Правильный символ – Ошибка», наличие этой информации позволит построить систему корректировки слов, опирающуюся на вероятностные значения. Однако стоит отметить, что для каждой OCR будет своя частотная таблица с парами «Правильный символ – Ошибка», связано это с тем, что различные OCR задействуют различные технологии при своём целевом использовании.
Некоторые ошибки, допущенные различными OCR
Источник: top-technologies.ru
Презентация по информатике «Системы оптического распознавания документов»
При coздании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.

Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе.
С помощью сканера несложно получить изображение страницы текста в графическом файле.
Содержимое разработки

Системы оптического распознавания документов

Системы оптического распознавания символов
При coздании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.

Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе.
С помощью сканера несложно получить изображение страницы текста в графическом файле.

Однако для получения документа в формате текстового файла необходимо провести распознавание текста , т. е. преобразовать элементы графического изображения в последовательности текстовых символов.

- Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и т. д.
- Далее выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст.

Хорошее качество текста Растровый метод распознавания текста

- Сначала растровое изображение страницы разделяется на изображения отдельных символов.
- Затем каждый из них последовательно накладывается на шаблоны символов, имеющихся в памяти системы, и выбирается шаблон с наименьшим количеством точек, отличных от входного изображения.
Хорошее качество текста Растровый метод распознавания текста
- Растровое изображение каждого символа последовательно накладывается на растровые шаблоны символов, хранящиеся в памяти системы оптического распознавания. Результатом распознавания является символ, шаблон которого в наибольшей степени совпадает с изображением
Например, распознаваемый символ «Б» накладывается на растровые шаблоны символов (А, Б, В и т. д.)

Плохое качество текста Структурный метод распознавания

- При распознавании документов с низким качеством печати (машинописный текст, факс и т.д.) используется метод распознавания структурных элементов (отрезков, колец, дуг и др.) символов. В искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов.
- Любой символ можно описать через набор параметров, определяющих взаимное расположение eгo элементов. Например, буква «Н» и буква «И» состоят из трех отрезков, два из которых расположены параллельно друг другу, а третий соединяет эти отрезки. Различие между буквами в величине улов, которые составляет третий отрезок с двумя другими.
Плохое качество текста Структурный метод распознавания
При pacпознавании структурным методом в искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов.
В результате выбирается тот символ, для которого совокупность всех структурных элементов и их расположение больше всего coответствуют распознаваемому символу.
Например, распознаваемый символ «Б» накладывается на векторные шаблоны символов (А, Б, В и т. д.)

Системы оптического распознавания форм
При проведении Единого государственного экзамена , при заполнении налоговых деклараций и т. д. используются различного вида бланки с полями. Рукописные тексты (данные вводятся в поля печатными буквами от руки) распознаются с помощью систем оптического распознавания форм и вносятся в компьютерные базы данных.
Сложность состоит в том, что необходимо распознавать символы, написанные от руки, а они довольно сильно различаются у разных людей. Кроме того, система должна определить, к какому полю относится распознаваемый текст.

Системы оптического распознавания форм
FineReader Forms

- Бланком называется стандартный лист бумаги, на котором размещается постоянная информация и отведено место для переменной.
- Сложность состоит в том, что необходимо распознать написанные от руки символы, довольно сильно различающиеся у разных людей.
- Кроме того система должна определить, к какому полю относится распознаваемый текст.
Системы оптического распознавания форм
- Для обработки бланков предназначено специальное приложение FineReader Forms .
- Для распознавания содержимого бланка необходимо предварительно создать шаблон формы .
Сервис/ Шаблоны
- Шаблон используют на этапе сегментации. Сегментация в данном случае состоит в наложении шаблона.
- Положение шаблона корректируется в соответствии с тем, насколько ровно был размещён бланк при сканировании.
- Заключительный этап состоит в распознавании содержимого бланка.
Системы распознавания рукописного текста
С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ.
Системы распознавания рукописного текста

Программы оптического распознавания текста
Программы оптического распознавания документов
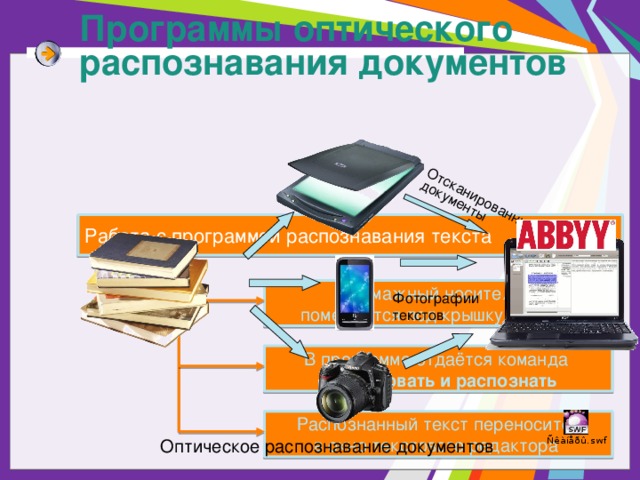
Работа с программой распознавания текста
помещается под крышку сканера
В программе отдаётся команда
Сканировать и распознать
Распознанный текст переносится
в окно текстового редактора
Оптическое распознавание документов

Принцип работы сканера
Принцип работы сканера состоит в следующем: в результате преобразования света получается электрический сигнал, содержащий информацию об активности цвета в исходной точке сканируемого изображения. После оцифровки аналогового сигнала в АЦП цифровой сигнал через аппаратный интерфейс сканера идет в компьютер, где его получает и анализирует программа для работы со сканером. После окончания одного такого цикла (освещение оригинала — получение сигнала — преобразование сигнала — получение его программой) источник света и приемник светового отражения перемещается относительно оригинала.

Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR).
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами, но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы.
И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word.

ABBYY FineReader

- Популярная проприетарная программа распознавания текста компании ABBYY
- Программа производит распознавание текста с более 180 языков , для 38 из них предусмотрена встроенная проверка орфографии. Начиная с версии Professional , распознаются иврит, японский, тайский, китайский языки. Finereader открывает файлы графических форматов (TIFF, JPG, PFD, PNG и др.) в том числе DjVu – компактный формат для хранения отсканированных документов, книг.
Процесс обработки FineReader
- Сканирование (сканер, цифровой фотоаппарат, цифровая видеокамера).
- Сегментация — выделение блоков на изображении.
- Распознавание – неоднозначно опознанные символы выделяются цветом.
- Проверка ошибок — можно провести проверку грамматики.
- Сохранение результатов в виде отформатированного или неотформатированного документа, или прямой передачи в другое приложение — WORD, Excel в буфер обмена Windows.

-82%
Источник: videouroki.net
Системы оптического распознавания текста.
На стадии подготовки и обработки информации, особенно при компьютеризации предприятия, автоматизации бухучета, возникает задача ввода большого объема текстовой и графической информации в ПК. Основными устройствами для ввода графической информации являются: сканер, факс-модем и реже цифровая фотокамера.
Кроме того, используя программы оптического распознавания текстов, можно вводить в компьютер (оцифровывать) также и текстовую информацию. Современные программно-аппаратные системы позволяют автоматизировать ввод больших объемов информации в компьютер, используя, например, сетевой сканер и параллельное распознавание текстов на нескольких компьютерах одновременно.
Большинство программ оптического распознавания текста (OCR Optical Character Recognition) работают с растровым изображением, которое получено через факс-модем, сканер, цифровую фотокамеру или другое устройство. На первом этапе OCR должен разбить страницу на блоки текста, основываясь на особенностях правого и левого выравнивания и наличия нескольких колонок.
Затем распознанный блок разбивается на строки. Несмотря на кажущуюся простоту, это не такая очевидная задача, так как на практике неизбежны перекос изображения страницы или фрагментов страницы при сгибах. Даже небольшой наклон приводит к тому, что левый край одной строки становится ниже правого края следующей, особенно при маленьком межстрочном интервале.
Врезультате возникает проблема определения строки, к которой относится тот или иной фрагмент изображения. Например, для букв j, Й, ё при небольшом наклоне уже сложно определить, к какой строке относится верхняя (отдельная) часть символа (в некоторых случаях ее можно принять за запятую или точку).
Потом строки разбиваются на непрерывные области изображения, которые, как правило, соответствуют отдельным буквам; алгоритм распознавания делает предположения относительно соответствия этих областей символам; а затем делается выбор каждого символа, в результате чего страница восстанавливается в символах текста, причем, как правило, в соответствующем формате. OCR-системы могут достигать наилучшей точности распознавания свыше 99,9% для чистых изображений, составленных из обычных шрифтов.
На первый взгляд такая точность распознавания кажется идеальной, но уровень ошибок все же удручает, потому что, если имеется приблизительно 1500 символов на странице, то даже при коэффициенте успешного распознавания 99,9% получается одна или две ошибки на страницу. Втаких случаях на помощь приходит метод проверки по словарю.
То есть, если какого-то слова нет в словаре системы, то она по специальным правилам пытается найти похожее. Но это все равно не позволяет исправлять 100% ошибок, что требует человеческого контроля результатов. Встречающиеся в реальной жизни тексты обычно далеки от совершенства, и процент ошибок распознавания для нечистых текстов часто недопустимо велик.
Грязные изображения здесь наиболее очевидная проблема, потому что даже небольшие пятна могут затенять определяющие части символа или преобразовывать один в другой. Еще одной проблемой является неаккуратное сканирование, связанное с человеческим фактором, так как оператор, сидящий за сканером, просто не в состоянии разглаживать каждую сканируемую страницу и точно выравнивать ее по краям сканера.
Программное обеспечение OCR обычно работает с большим растровым изображением страницы из сканера. Изображения со стандартной степенью разрешения получаются сканированием с точностью 9600 пикселей на дюйм. Изображение листа формата A4 при этом разрешении занимает около 1МБ памяти.
Основное назначение OCR-систем состоит в анализе растровой информации (отсканированного символа) и присвоении фрагменту изображения соответствующего символа. После завершения процесса распознавания OCR-системы должны уметь сохранять форматирование исходных документов, присваивать в нужном месте атрибут абзаца, сохранять таблицы, графику ит. д. Современные программы распознавания поддерживают все известные текстовые и графические форматы и форматы электронных таблиц, а некоторые поддерживают такие форматы, как HTML и PDF.
На данный момент существует огромное количество программ, поддерживающих распознавание текста как одну из возможностей. . Начнем обзор с лидера в этой области FineReader. Новая технология Intelligent Background Filtering (интеллектуальной фильтрации фона) позволяет отсеять информацию о текстуре документа и фоновом шуме изображения: иногда для выделения текста в документе используется серый или цветной фон.
ABBYY FormReader еще одна распознавалка от ABBYY. Эта программа предназначена для распознавания и обработки форм, которые могут быть заполнены вручную.
OCR CuneiForm выгодно отличается уровнем распознавания, особенно текстов низкого качества; удобным интерфейсом с наличием встроенных мастеров помощников в работе; встроенным текстовым редактором, не уступающим по своей функциональности популярным текстовым процессорам, и многими другими возможностями. способна распознавать любые полиграфические и машинописные гарнитуры всех начертаний и шрифтов, получаемые с принтеров, за исключением декоративных и рукописных. Также программа способна распознавать таблицы различной структуры, в том числе и без линий и границ; редактировать и сохранять результаты в распространенных табличных форматах.
Существенно облегчает работу и возможность прямого экспорта результатов в MS Word и MS Excel (для этого теперь не нужно сохранять результат в файл RTF, а затем открывать его с помощью MS Word). Также программа снабжена возможностями массового ввода возможностью пакетного сканирования, включая круглосуточное, сканирования с удаленных компьютеров локальной сети и организации распределенного параллельного сканирования в локальной сети.
Readiris Pro7 профессиональная программа распознавания текста. отличается от аналогов высочайшей точностью преобразования обычных (каждодневных) печатных документов, таких как письма, факсы, журнальные статьи, газетные вырезки, в объекты, доступные для редактирования (включая файлы PDF). Основными достоинствами программы являются: возможность более или менее точного распознавания картинок, сжатых по максимуму (с максимальной потерей качества) методом JPEG, поддержка цифровых камер и автоопределения ориентации страницы.
OmniPage11 продукт компании ScanSoft. . Разработчики утверждают, что их программа практически со 100% точностью распознает печатные документы, восстанавливая их форматирование, включая столбцы, таблицы, переносы (в том числе переносы частей слов), заголовки, названия глав, подписи, номера страниц, сноски, параграфы, нумерованные списки, красные строки, графики и картинки. Есть возможность сохранения в форматы Microsoft Office, PDF и в 20 других форматов, распознавания из файлов PDF, редактирование прямо в формате PDF.
Система искусственного интеллекта позволяет автоматически обнаруживать и исправлять ошибки после первого исправления вручную. Новый специально разработанный модуль Despeckle позволяет распознавать документы с ухудшенным качеством (факсы, копии, копии копий ит. д.). Преимуществами программы являются возможность распознавания цветного текста и возможность корректировки голосом. Теперь версия OmniPage существует и для компьютеров Macintosh.
Нравится 0
Понравилась работу? Лайкни ее и оставь свой комментарий!
Для автора это очень важно, это стимулирует его на новое творчество!
Посоветуйте статью друзьям!
Случайные работы
Другие работы автора
Параметры подпрограмм
Информационные технологии
Процедуры и функции в pascal
Информационные технологии
Способы адресации
Информационные технологии
Похожие работы
Раздел 3 ФУНКЦИОНАЛЬНЫЕ СТИЛИ СОВРЕМЕННОГО РУССКОГО ЯЗЫКА
Риторика
Статус государственного служащего: права, обязанности, ограничения и запреты.
Политология
Международные правовые акты, международные договоры РФ как источники государственного права.
Политология
Билеты на ГКК для матросов 2 класса.
Иностранные языки
Команды, поданные наруль, рулевой обязан повторить, а вахтенный офицер должен убедиться, что они выполняются немедленно и аккуратно.
Иностранные языки
Источник: lektsia.info