
Оптическое распознавание текста позволяет преобразовывать изображения текста PDF документа в редактируемый текстовый формат, который поддерживает возможность поиска текста в документе, его копирование и редактирование. Распознавание текста будет осуществляться только в том случае, если в PDF документе не установлен запрет на редактирование.
Для включения оптического распознавания текста выберите в главном меню Документ > Распознавание текста. В диалоговом окне укажите следующие параметры:
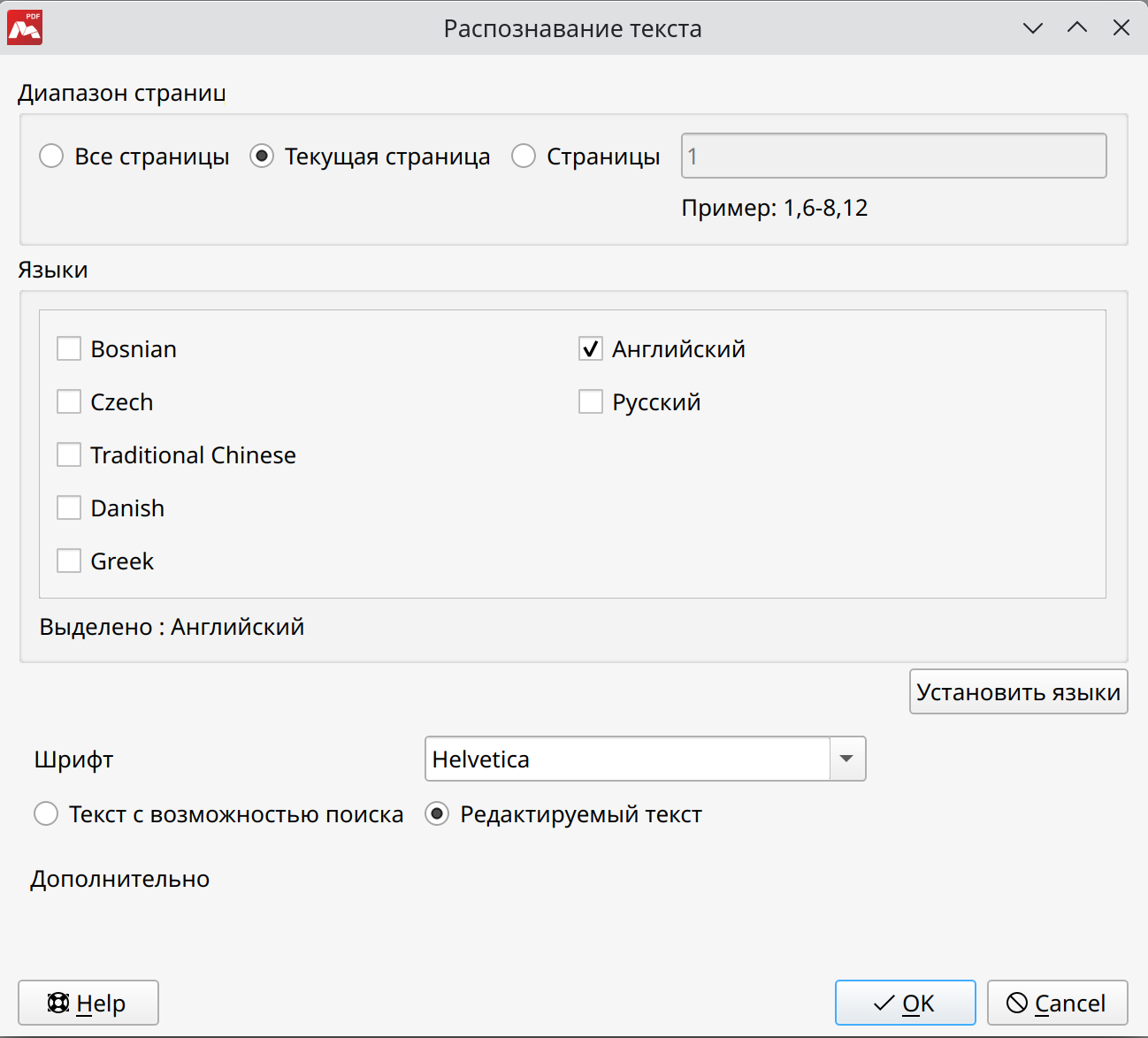
- Диапазон страницУкажите диапазон страниц, на которых необходимо произвести распознавание текста.
- Языки Укажите язык/языки распознаваемого текста. Желательно выбирать минимальное количество вариантов. Это улучшит качество распознавания текста.

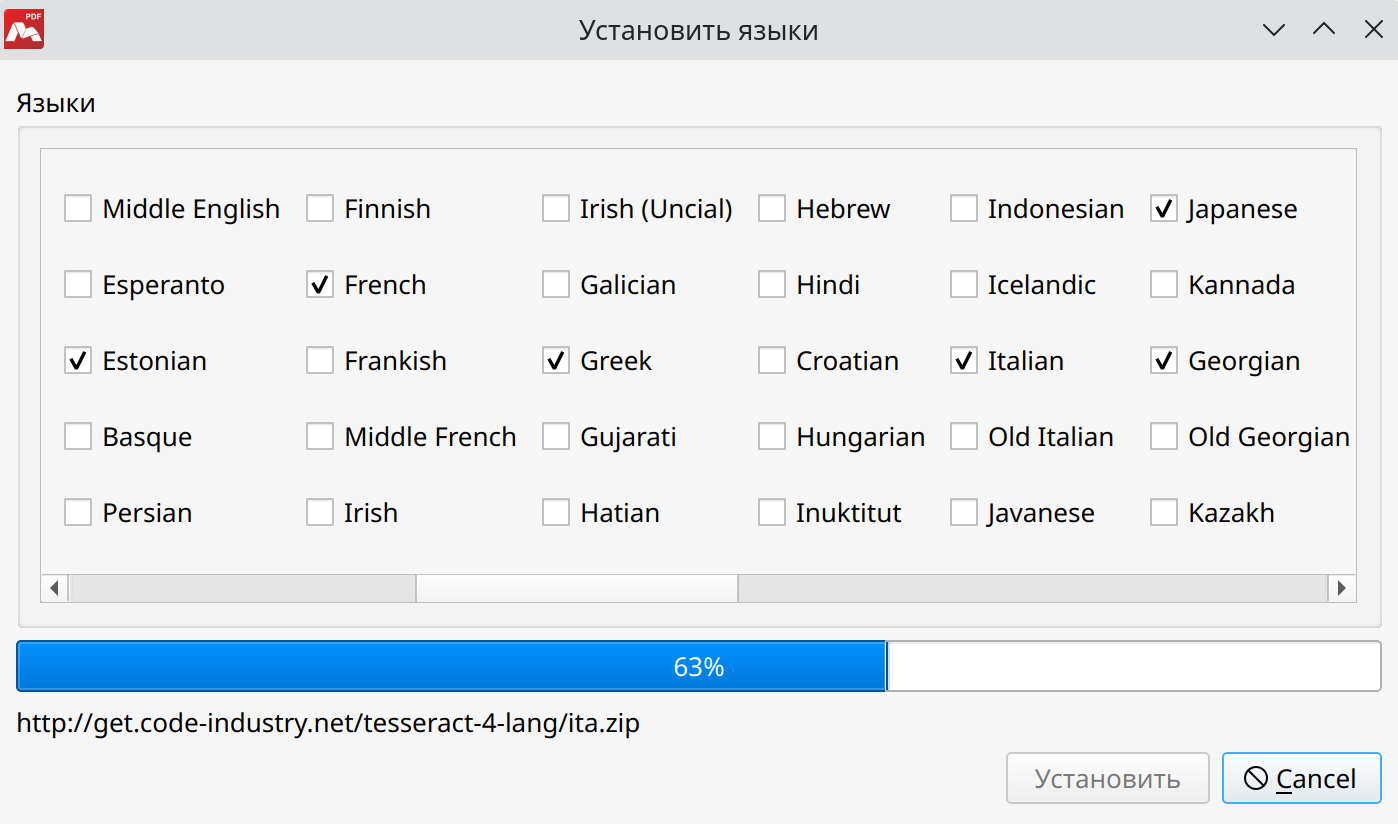
Если распознавание текста используется первый раз, данный список будет пустым. Для добавления языков нажмите кнопку Установить языки.
Распознавание сканов документов
- Установить языки Установите маркеры, чтобы выбрать необходимые варианты. В диалоговом окне перечислены языки, для которых поддерживается распознавание текста в Master PDF Editor.
- Шрифт Выберите вариант шрифта, который будет использоваться в документе после распознавания текста. При выборе Автоматически программа сама подберет шрифт наиболее подходящий для данного документа.
- Текст с возможностью поиска При выборе данной опции после завершения процедуры распознавания текст будет доступен для поиска и копирования. Распознанный текст вставится в документ как невидимый под своим изображением.
- Редактируемый текст При выборе данной опции после завершения процедуры распознавания текст будет доступен для редактирования. Распознанный текст вставится поверх изображения с данным текстом. Само изображение при этом затирается фоном.
В нижней части окна Распознавание текста находятся дополнительные настройки.
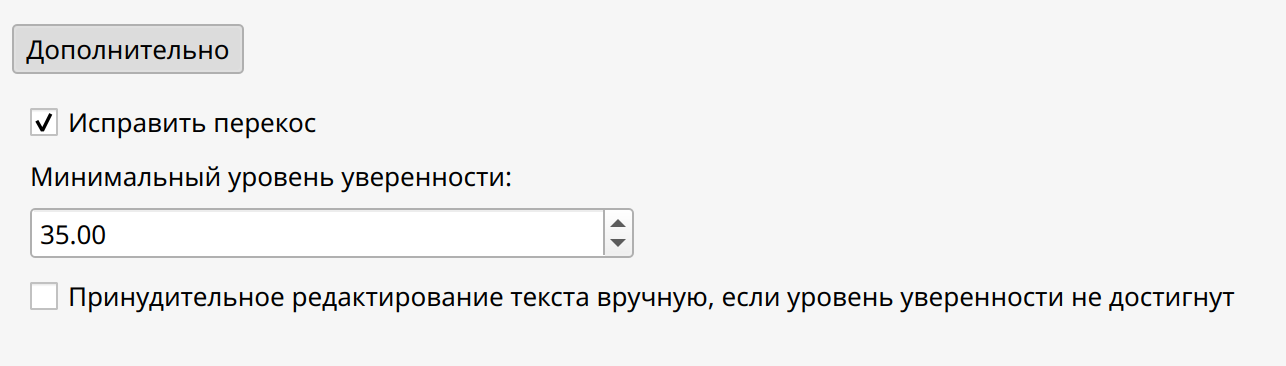
- Исправить перекосПри выборе данной опции автоматически выпрямляется и выравнивается всё содержимое документа. Кроме того, у содержимого отсканированного документа также можно исправить перекос.
- Минимальный уровень уверенностиЧисловое значение, указывающее степень уверенности механизма в том, что он правильно распознал компонент.
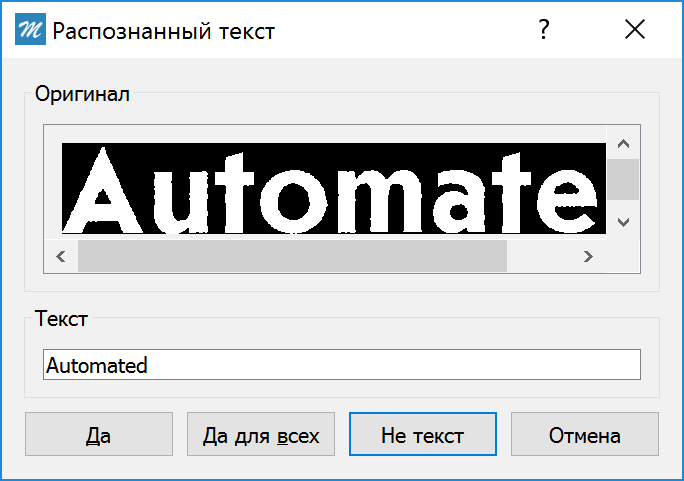
- Вручную редактировать весь распознанный текст При выборе данной опции во время процедуры распознавания текста открывается диалоговое окно, в котором будет отображаться:
Лучшие программы для распознавания текста. Рейтинг OCR.
- Оригинал Фрагмент изображения с текстом
- Текст Соответствующий изображению автоматически распознанный текст.
В диалоговом окне поочередно будет отображаться каждый фрагмент изображения PDF документа с соответствующим ему распознанным текстом. Здесь можно редактировать распознанный текст перед вставкой в документ.
- Да Автоматически распознанный/редактированный текст запишется в документ. В диалоговом окне отобразится следующее изображение и текст к нему.
- Да для всех Все изображения будут распознаны автоматически и записаны в документ. Данное диалоговое окно больше не появится
- Не текст Текущий распознанный текст не является текстовым фрагментом. Отменяет вставку текста в текущем фрагменте.
- Отмена Отмена распознавания текста
- Master PDF Editor — Онлайн руководство
- Функциональные характеристики
- Установка и удаление в Windows
- «Тихая» установка
- Онлайн Активация
- Оффлайн Активация
- Деактивация Лицензии
- Меню Файл
- Меню Правка
- Меню Вид
- Меню Объекты
- Меню Комментарии
- Меню Формы
- Меню Документ
- Меню Инструменты
- Меню Справка
- Создать пустой PDF документ
- Создать новый PDF документ из файлов
- Сканирование
- Оптимизация и сохранение
- Резервное копирование
- Функция автосохранения
- Экспорт PDF в изображение
- Экспорт PDF в текстовый формат
- Экспорт PDF в CSV
- Спецификация PDF
- Навигация по PDF документу
- Вставка страниц
- Удаление страниц
- Перемещение страниц
- Изменение размера страницы и ее обрезка
- Поворот PDF страницы
- Свойства страницы
- Экспорт и импорт PDF страниц
- Редактирование текста
- Возможные проблемы при работе с текстом
- Общие свойства PDF форм.
- Создание и редактирование интерактивных PDF форм
- Шифрование PDF паролем
- Шифрование PDF сертификатом
- Подпись PDF документа сертификатом
- Затирание конфиденциальной информации в PDF документах
Источник: code-industry.ru
Программы оптического распознавания документов (8 класс)


Кроме текстовых процессоров, предназначенных для создания и обработки текстов на компьютере, существует ряд программ, позволяющих автоматизировать работу человека с текстовой информацией. К ним можно отнести программы оптического распознавания документов, компьютерные словари и программы-переводчики.
Очень часто возникает необходимость ввести в компьютер несколько страниц текста из книги, статью из журнала или газеты и т. д. Конечно, можно затратить определённое время и просто набрать этот текст с помощью клавиатуры. Но чем больше исходный текст, тем больше времени будет затрачено на его ввод в память компьютера.
Судите сами. Предположим, кто-то из ваших одноклассников, освоивших клавиатурный тренажёр, может вводить текстовую информацию со скоростью 150 символов в минуту. Выясним, сколько времени ему понадобится для того, чтобы ввести в память компьютера текст романа А. Дюма «Три мушкетёра». Одно из изданий этого романа выполнено на 590 страницах; каждая страница содержит 48 строк, в каждую строку входит в среднем 53 символа.
Вычислим общее количество символов в романе: 590 • 48 • 53 = 1 500 960 (симв.).
Вычислим время, необходимое для ввода этого массива символов в память компьютера: 1500960 : 150 ≈ 10000 (мин.). А это приблизительно 167 часов.
При этом мы не обсуждаем вопрос о времени на исправление возможных ошибок при таком способе ввода текста, не принимаем в расчёт усталость человека.
Для ввода текстов в память компьютера с бумажных носителей используют сканеры и программы распознавания символов. Одной из наиболее известных программ такого типа является АВВУУ Fine Reader. Упрощённо работу с подобными программами можно представить так:
- Бумажный носитель помещается под крышку сканера.
- В программе отдаётся команда Сканировать и распознать. Сначала создаётся цифровая копия исходного документа в формате графического изображения. Затем программа анализирует структуру документа, выделяя на его страницах блоки текста, таблицы, картинки и т. п. Строки разбиваются на слова, а слова – на отдельные буквы. После этого программа сравнивает найденные символы с шаблонными изображениями букв и цифр, хранящимися в её памяти. Программа рассматривает различные варианты разделения строк на слова и слов на символы. В программу встроены словари, обеспечивающие более точный анализ и распознавание, а также проверку распознанного текста. Проанализировав огромное число возможных вариантов, программа принимает окончательное решение и выдает пользователю распознанный текст.
- Распознанный текст переносится в окно текстового редактора (например, Microsoft Word).
Вместо сканера можно использовать цифровой фотоаппарат или камеру мобильного телефона. Например, при работе с книгами в библиотеке вы можете сфотографировать интересующие вас страницы. Скопировав снимки на компьютер, вы можете запустить АВВУУ Fine Reader, распознать тексты и продолжить работу с ними в текстовом процессоре.

Самое главное:
- Для ввода текстов в память компьютера с бумажных носителей используют сканеры и программы распознавания символов.
Вопросы и задания:
- В каких случаях программы распознавания текста экономят время и силы человека?
- Сколько времени потребуется для ввода в память компьютера текста романа А. Дюма «Три мушкетёра» с помощью сканера и программы АВВУУ Fine Reader, если известно, что на сканирование одной страницы уходит 3 с, на смену страницы в сканере — 5 с, на распознавание страницы — 2 с?
(Решение:
Для ввода одной страницы требуется: 3 + 5 + 2 = 10 секунд;
Для всей книги: 590 • 10 = 5900 (сек) ≈ 98 (мин)
Ответ: ≈ 98 мин) - Найдите в Интернете информацию о технологии сканирующего листания. В чём её суть?
Источник: ikthelp.ru
Как выполнить OCR для извлечения текстов из PDF [Полное руководство]

Последнее обновление 27 сентября 2022 г. by Тина Кларк Просто сделайте несколько снимков для презентации и хотите легко извлечь из них тексты, что вам делать? Оптическое распознавание PDF-файлов на основе изображений — это простой способ получить нужные файлы.
Когда вам нужно превратить файл PDF в файл с возможностью поиска и редактирования, что является самым сложным для применения алгоритма OCR к файлам PDF? База данных языков должна быть правильным ответом. Вы можете обнаружить, что функция OCR работает для одного языка, но не для другого. Просто узнайте больше о 6 часто используемых Распознавание PDF решения и выберите подходящий в соответствии с вашими требованиями.
- Часть 1. Простой способ конвертировать PDF в текст с помощью PDF OCR
- Часть 2: 5 решений OCR PDF для извлечения слов из PDF
Часть 1. Простой способ конвертировать PDF в текст с помощью PDF OCR
PDFelement это универсальный PDF-редактор для выполнения алгоритма OCR, который поддерживает 23 различных языка с передовыми технологиями. Он выполняет решение OCR PDF, чтобы сохранить тот же макет, что и исходный контент, а текст будет доступен для поиска и выбора. Он также предоставляет буквально тысячи функций, которые упрощают понимание идей, связанных с PDF, и позволяют применять их в самых разных ситуациях.
1. Применяйте алгоритмы OCR как к отсканированным PDF-файлам, так и к PDF-файлам на основе изображений.
2. Извлекайте нужные тексты из файлов PDF на более чем 20 языках.
3. Преобразование на основе изображений PDF к Слову, Excel, PPT и другие форматы файлов.
4. Сохраняйте исходное содержимое PDF-файла, чтобы сделать его доступным для поиска и редактирования.
Шаг 1: импортируйте PDF-файлы на основе изображений или отсканированные PDF-файлы в PDFelement. Вы также можете использовать PDFelement iOS для захвата PDF-файлов с помощью камеры вашего iPhone или iPad. Существуют различные стратегии, которые можно использовать для обеспечения отображения изображения.

Шаг 2: После того, как вы импортировали нужный PDF-файл, вы можете найти Выполнить OCR кнопку для извлечения нужных текстов. Более того, нажмите кнопку OCR кнопку, чтобы выбрать режим OCR, и нажмите кнопку Изменить язык кнопку, чтобы выбрать другой язык для содержимого изображения.

Шаг 3: решение OCR PDF распознает текст на вашем изображении, что позволит вам изменить текст. Кроме того, он сохраняет тот же макет, что и ваш исходный PDF-контент, и текст будет доступен для поиска и выбора. После этого вы можете внести некоторые изменения в тексты PDF.
Шаг 4: после преобразования PDF-файла на основе изображения с помощью алгоритма OCR будет создан полностью редактируемый PDF-файл. Чтобы мгновенно изменить текст, выберите значок Редактировать в раскрывающемся меню в верхнем левом углу экрана перед сохранением.

Win Скачать Mac Скачать
Часть 2: 5 решений OCR PDF для извлечения слов из PDF
Sejda — онлайн-решение для оптического распознавания символов PDF
Sejda это онлайн-решение OCR PDF для извлечения текста из PDF-файлов. Он поставляется с настольным клиентом для Windows, macOS и Linux, а также с программой OCR на основе браузера для использования в Интернете. Вы можете получить документ PDF с возможностью поиска, где невидимый текст должен быть наложен на исходные изображения в правильных местах.
1. Обеспечьте простой и быстрый способ применения некоторых основных функций OCR.
2. Бесплатный сервис для PDF-файлов до 10 страниц или 50 МБ и 3 задач в час.
3. Поддерживайте нерегулируемые сервисы и вольны делать то, что хотите редактировать.
1. Ограниченные задачи в течение дня и ограниченный размер файла до 50 МБ.
2. Необходимо оптимизировать яркость и контрастность PDF перед распознаванием PDF.

Omni Page — OCR PDF на 120 языках
Омни-страница позволяет быстро и эффективно использовать возможности OCR. Алгоритм OCR PDF работает не только с PDF, но и BMP и GIF-файлы изображений легко для более чем 120 языков. Кроме того, он также предоставляет расширенный алгоритм для сохранения исходного контента, включая столбцы, таблицы, маркеры, графику и т. д.
1. Обеспечьте сохранение исходного макета и общее результирующее форматирование.
2. Усовершенствованные механизмы OCR обеспечивают превосходную точность преобразования PDF.
3. Включите расширенный облачный коннектор Nuance Cloud Connector на базе Gladinet.
1. Рекламное ПО загружается в систему при использовании функции OCR.
2. Пользовательский интерфейс программы не такой интуитивно понятный, как у других программ.

Microsoft Word — встроенный OCR PDF для Office
Нет необходимости загружать и устанавливать отдельную программу OCR, если вы уже подписаны на Microsoft Office. Для преобразования PDF-файлов и фотографий в текст в Microsoft интегрирована технология оптического распознавания символов PDF, включая Microsoft Word, Excel и OneNote. Все, что вам нужно сделать, это открыть файл PDF в Word, чтобы преобразовать его в редактируемый файл.
1. Преобразуйте текст в формате PDF на основе отсканированного изображения в документ Word.
2. Скопируйте текст с изображений и распечаток файлов с помощью OCR в OneNote.
3. Добавляйте текст непосредственно в свои заметки после извлечения таблиц в Excel/Word.
1. Требовать подписки на Office 365 для извлечения таблиц в онлайн-версии.
2. Невозможно сохранить исходные PDF-таблицы, маркеры, графику и т. д.

Tesseract — мощный движок OCR PDF
Тессеракт — еще один профессиональный пакет OCR PDF с открытым исходным кодом. Пользуется высоким уровнем уважения среди профессионалов бизнеса. Вы можете использовать его для преобразования отсканированных бумажных документов в виде файлов PDF или изображений в редактируемые данные с возможностью поиска. Обычно это включает в себя сканер, который преобразует документ во множество разных цветов, известный как растровое изображение.
1. Предоставьте бесплатное решение OCR PDF для Windows, Mac и Linux бесплатно.
2. Внесите некоторые базовые изменения в программу, чтобы сделать ее более многоязычной.
3. Работайте с частью документа, а не со всем документом.
1. Используйте интерфейс командной строки, это не простая программа.
2. Оптическое распознавание символов менее точное, чем думают его разработчики.

Fine Reader — решение для оптического распознавания символов PDF на основе искусственного интеллекта
Прекрасный читатель является одним из самых опытных сервисов оптического распознавания символов PDF. Он широко известен как одно из приложений на основе ИИ, которое способствовало общему улучшению качества жизни пользователей. Он предоставляет как онлайн, так и автономные функции OCR для быстрого извлечения текста из отсканированных изображений в формат TXT на вашем устройстве без подключения к Интернету.
1. Поддержка 192 различных языков и проверка орфографии для 47.
2. Определить размер документа в AR для нестандартных документов и дальнейшей печати.
3. Преобразуйте в другой формат и сохраните исходное форматирование документа.
1. Невозможно эффективно работать из-за медлительности программы.
2. Эта программа не может выполнять распознавание документов TXT напрямую.

Заключение
Вот некоторые популярные решения OCR PDF, доступные на рынке. Если вам нужно преобразовать какой-либо файл PDF на основе изображения или отсканированный файл в формат PDF с возможностью поиска и редактирования, вы можете узнать больше о специальных функциях решений OCR PDF, особенно о поддерживаемых языках. PDFelement — это один из лучших способов гарантировать, что при сканировании и оцифровке документов используется самое лучшее программное обеспечение для оптического распознавания символов, написанное от руки.
Вы можете быть заинтересованы
- Бесплатные редакторы PDF для Windows и Mac — вот окончательный обзор, который вы должны знать
- PDF-принтер — 6 эффективных методов печати PDF-файла на разных устройствах
- Ищете лучший конвертер PDF в Word? Вот ваша ссылка
Источник: ru.widsmob.com