
Модуль OCR в антиплагиате — что это простыми словами
В 2018 году Антиплагиат анонсировал большую новость. Сайт внедряет в свою систему проверки, модуль OCR. По заявлениями разработчиков компании Анти-плагиат, внедрение данного модуля автоматически означает, что искусственное повышение уникальности текста (кодирование, макросы, технический подъем) теперь будут неэффективны.
Так ли это? Давайте разбираться. В статье мы расскажем, что такое модуль OCR в антиплагиате и так ли он страшен и непроходим, как о нем говорят.
01 Модуль ОCR в Антиплагиате — что это простыми словам
OCR – дословно, переводится как “оптическое распознавание символов”. Для лучшего понимания приведем пример. Все знают, что такое сканер. И многие не раз делали такую процедуру – сканировали какой нибудь текст с книги, а затем, с помощью программы (самая известная Abbyy FineReader) производили распознавание текста. В результате текст с книги оказывался в печатном виде на компьютере.
Именно это и внедрил Антиплагиат в свою систему проверки, пока правда, только в платную его версию Антиплагиат ВУЗ.
Лайфхак
На нашем сервисе вы можете заказать проверку документа через Антиплагиат ВУЗ вместе с модулем ОCR. Также мы поможем вам повысить уникальность текста. За пару минут ваша работа получить высокий процент оригинальности до 80-90%. При этом ваш текст не изменится, только файл будет перекодирован незаметно для человеческого глаза.
Заказывайте повышение прямо сейчас и мы пришлем вам готовый вариант бесплатно. Сначала выубедитесь в том, что кодировка текста реально работает. Заранее ничего платить не нужно.
02 Модуль ОCR — как это работает?
По замыслу разработчиков Антиплагиата, при анализе текста с помощью модуля OCR (оптическое распознование текста), система будет, по простому говоря, делать фотографию проверяемого – видимого текста, после чего он будет распознаваться онлайн и именно уже распознанный текст, будет подвергаться проверке на уникальность в программе.
Логично, что если это действительно будет работать, то все фишки со скрытым текстом, символами и прочими махинациями с текстом, направленные на повышения уникальности, будет неэффективны. Они попросту не будут распознаны.
03 Модуль ОCR на практике (при проверке)
На практике, дела обстоят совершенно иначе.
Данная функция уже больше года присутствует в системах проверки антиплагиата и ей уже можно пользоваться, однако, алгоритм с распознаванием не работает.
Антиплагиат заявляет, что оптическое распознавание символов внедрено, но по факту его нет. Это мы проверили на практике.
На деле, никакого оптического рапознавания не происходит, а вместо OCR происходит более глубокий анализ документа с показанием более низкого процента.
Включение модуля OCR действительно делает процесс технического повышения уникальности текста более сложным, но все равно обойти антиплагиат возможно, без больших проблем.
К тому же данный модуль в антиплагиате не включен автоматически. Чтобы его активировать, нужно нажать на галочку(см.фото)
На практике преподаватели практически не пользуются OCR при проверках. Лишь 1 преподаватель из 10000 подключает данную функцию перед проверкой документа.
Несколько десятков вузов вообще отказались от данной функции, ведь стоит она дорого, а эффекта особого не приносит.
Настоящее оптическое распознавание символов (ОКР) в антиплагиате это утопия. Кто активно пользуется системой Антиплагиат, часто сталкиваются с дикими перегрузками на сайте, даже в обычные месяцы.
А в месяцы сессии, одну работу система может проверять по часу. Сервера по-просту не выдерживают нагрузки.
Если же внедрить полноценный модуль OCR в антиплагиат, чтобы он работал, действительно используя распознавание текста, процесс анализа документов затянется на часы.
Системе антиплагиат нужно будет вначале сделать фото текста, затем совершить онлайн распознавание текст и лишь затем, провести его проверку на оригинальность.
Проверять работу по несколько десятков минут и даже часов никому не интересно, в результате от системы Антиплагиат будут отказываться. Речь идет именно о вузовской версии Антиплагиат вуз, за которую ежегодно, компания получает около 1 миллиона рублей с учебного заведения.
Более того, создать непроходимую систему антиплагиата, элементарно, невыгодно самим разработчикам.
Сегодня более 80% студентов повышают антиплагиат, используя кодирование и технический подъем. Если система станет не проходимой, нас ждет миллионы отчисленных студентов, что вызовет огромный общественный резонанс и возможно, отмену системы Антиплагиат в принципе.
“Хозяевам” антиплагиата это совершенно не выгодно. Ведь кормушка под названием “Антиплагиат” приносит колосальные прибыли их владельцам.
Вы наверняка часто слышали фразу «В нашем вузе используется супер-мега-крутой антиплагиат, и никто не сможет его обмануть». Мы решили узнать, что конкретно может помешать пройти проверку на уникальность, кроме OCR. Посмотрите наше видео, чтобы узнать правду.
04 Как обойти ОCR в Антиплагиат
Обойти модуль OCR в антиплагиате может программа Антиплагиат киллер , которая выпускается разработчиками компании Анти-антиплагиат.
Если вам необходимо повысить уникальность текста таким образом, чтобы при проверке с OCR процент показало высокий, можете обратиться к нам, мы поможем сделать это каждому клиенту.
Мы имеет доступ к системе Антиплагиат ВУЗ в которой подключен данный модуль, и сделаем кодировку таким образом, что документ пройдет проверку на уникальность даже с подключением OCR.
Мы работаем без предоплаты. Сначала специалисты делают повышение уникальности текста . Затем мы высылаем работу вперед, а оплатить услугу можно после проверки текста на уникальность.
Другие полезные статьи по теме:
Источник: xn—-7sbbaar5acc1ard1a0beh.xn--p1ai
Программы для распознавания текста

Как правило, если речь заходит о программах для распознавания сканированного текста (OCR, оптическое распознавание символов), большинство пользователей вспоминают единственный продукт — ABBYY FineReader, который, бесспорно, является лидером среди такого программного обеспечения в России и одним из лидеров в мире.
Тем не менее, FineReader — не единственное такого рода решение: есть бесплатные программы для распознавания текста, онлайн-сервисы для этих же целей и, более того, такие функции присутствуют и в некоторых знакомых вам программах, которые, возможно, уже установлены на вашем компьютере. Обо все этом я и постараюсь написать в этой статье. Все рассмотренные программы работают в Windows 7, 8 и XP.
Лидер распознавания текстов — программа ABBYY Finereader
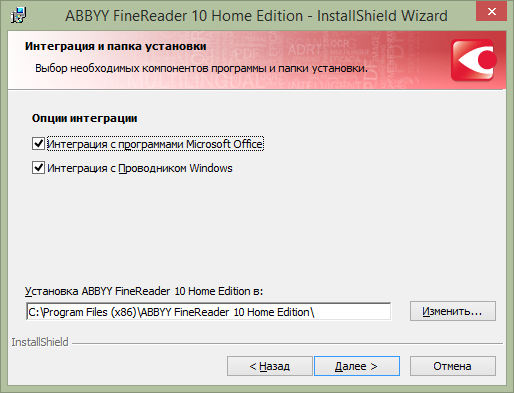
Установка пробной версии FineReader не вызвала никаких проблем. ПО может интегрироваться с Microsoft Office и Проводником Windows, для того чтобы было удобнее запустить распознавание. Из ограничений бесплатной пробной версии — 15 суток использования и возможность распознать не более 50 страниц.

Снимок для тестирования программ распознавания
Так как сканера у меня нет, то для проверки я воспользовался снимком с некачественной камеры телефона, в котором немного отредактировал контрастность. Качество никуда не годное, посмотрим, кто справится.

Меню программы FineReader
FineReader может получать графическое изображение текста напрямую со сканера, из графических файлов или камеры. В моем случае, достаточно было открыть файл изображения. Результат порадовал — всего пара ошибок. Сразу скажу, что это лучший результат из всех проверенных программ при работе с данным образцом — похожее качество распознавания было только на бесплатном онлайн сервисе Free Online OCR (но в этом обзоре мы говорим только о программных средствах, не онлайн распознавании).
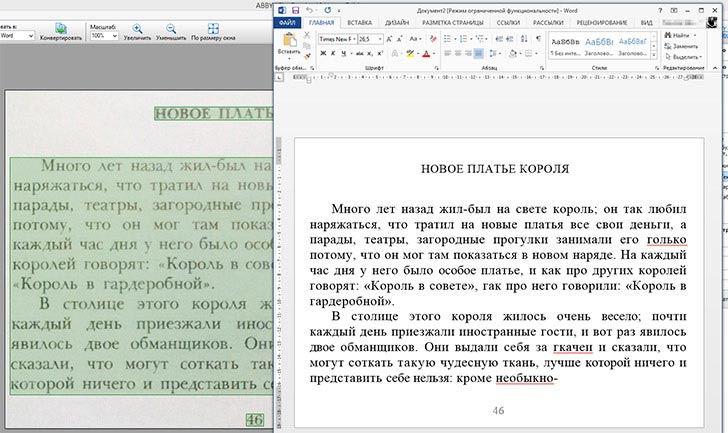
Результат распознавания текста в FineReader
Откровенно говоря, для кириллических текстов у FineReader, наверное, нет конкурентов. Плюсами программы является не только качество распознавания текстов, но и широкая функциональность, поддержка форматирования, грамотный экспорт во множество форматов, включая Word docx, pdf и другие возможности. Таким образом, если задачи OCR — это то, с чем вы сталкиваетесь постоянно, то не пожалейте сравнительно небольшого количества денег и это вполне окупится: вы сэкономите огромное количество времени, быстро получая качественный результат в FineReader. Я, кстати, не рекламирую ничего — действительно считаю, что тем, кому нужно распознать больше десятка страниц, стоит задуматься о покупке такого ПО.
CuneiForm — бесплатная программа для распознавания текста
Установка программы также очень проста, никакого стороннего софта (как многое бесплатное ПО) она установить не пытается. Интерфейс лаконичен и понятен. В некоторых случаях проще всего воспользоваться мастером, для чего предназначена первая из иконок в меню.
С образцом, которым я пользовался в FineReader, программа не справилась, или, точнее, выдала что-то плохо читаемое и ошметки слов. Вторая попытка была предпринята со скриншотом текста с сайта самой этой программы, который, правда, пришлось увеличить (ей нужны сканы с разрешением 200dpi и выше, скриншоты с толщиной линий шрифтов 1-2 пикселя она не читает). Тут она справилась хорошо (часть текста не распознана, так как был выбран только русский язык).

Распознавание текста в CuneiForm
Таким образом, можно предположить, что CuneiForm — это то, что следует попробовать, особенно если у вас качественно отсканированные страницы и вы хотите распознать их бесплатно.
Microsoft OneNote — программа, которая у вас, возможно, уже есть
В состав Microsoft Office, начиная с версии 2007 и заканчивая текущей, 2013, присутствует программа для ведения заметок — OneNote. В ней также присутствуют функции распознавания текста. Для того, чтобы воспользоваться ею, просто вставьте отсканированное или любое другое изображение текста в заметку, кликните правой клавишей мыши по ней и воспользуйтесь контекстным меню. Отмечу, что по умолчанию для распознавания установлен английский язык.
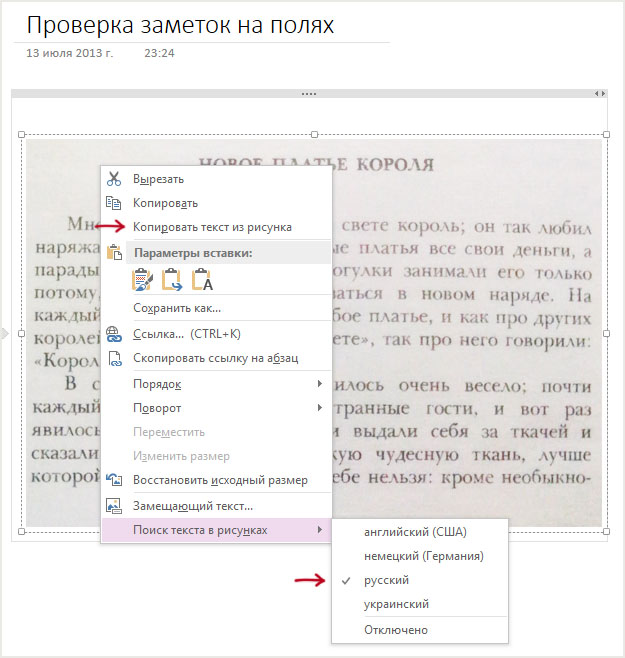
Распознавание в Microsoft OneNote
Не могу сказать, что текст распознается идеально, но, насколько я могу судить, несколько лучше даже чем в CuneiForm. Плюс программы, как уже было сказано, в том, что с немалой вероятностью она уже установлена на вашем компьютере. Хотя, конечно, ее использование в случае необходимости работы с большим количеством отсканированных документов навряд ли будет удобным, скорее она подойдет для быстрого распознавания визиток.
OmniPage Ultimate, OmniPage 18 — должно быть, что-то очень крутое
Цена на ПО OmniPage
Если ознакомиться с характеристиками и отзывами, в том числе и в русскоязычных изданиях, в них отмечается, что OmniPage действительно обеспечивает качественное и точное распознавание, в том числе и на русском языке, сравнительно легко разбирает не самые качественные сканы и предоставляет набор дополнительных инструментов. Из недостатков выделяют не самый удобный, особенно для начинающего пользователя, интерфейс. Так или иначе, на западном рынке OmniPage — прямой конкурент FineReader и в англоязычных рейтингах они борются именно между собой, а потому, думаю, программа должна быть достойной.
Это далеко не все программы данного типа, существуют также различные варианты небольших бесплатных программ, но, пока экспериментировал с ними нашел два главных недостатка им свойственных: отсутствие поддержки кириллицы, либо различное, не слишком полезное ПО в комплекте установки, а потому решил не упоминать их здесь.
А вдруг и это будет интересно:
- Лучшие бесплатные программы для Windows
- Как скрыть файлы внутри других файлов в Windows — использование OpenPuff
- Как включить режим экономии памяти и энергосбережения в Google Chrome
- Как удалить пароли в Яндекс Браузере
- Программы для анализа дампов памяти Windows
- Как вернуть меню Пуск из Windows 10 или 7 в Windows 11
- Windows 11
- Windows 10
- Android
- Загрузочная флешка
- Лечение вирусов
- Восстановление данных
- Установка с флешки
- Настройка роутера
- Всё про Windows
- В контакте
- Одноклассники
-
Владимир 12.11.2018 в 14:51
- Dmitry 28.07.2020 в 13:11
Источник: remontka.pro
Распознавание текста с помощью решений ABBYY — все гениальное просто для бизнеса

Программы для распознавания текста знакомы всем, кто в процессе работы сталкивался с необходимостью перевода печатных символов в электронный формат. Современные решения от лидера отрасли ABBYY давно вышли за рамки массового сегмента: теперь они помогают бизнесу. Разработки в области распознавания текста востребованы в банковском деле, в образовании, энергетике и т. д. В этой статье мы расскажем о том, какие задачи бизнеса позволяют решать технологии ABBYY.
Система оптического распознавания текста ABBYY OCR: пара слов о технологии
В XXI веке программы распознавания текста востребованы не только у частных пользователей, но и в бизнесе. Главным образом они служат для автоматизации ввода и обработки данных из документов, за счет чего помогают экономить время и деньги. Десятки тысяч компаний во всем мире используют решения ABBYY для повышения конкурентоспособности. А начиналось все в 1993 году, когда была создана технология оптического распознавания символов (OCR — Optical Character Recognition) ABBYY. Поясним вкратце, в чем принцип ее работы.
Текст отсканированного документа, его фотографию или PDF-файл можно просматривать с экрана компьютера, но их содержимое нельзя копировать и изменять. Технология оптического распознавания переводит изображение в формат, доступный для редактирования. Программа находит буквы, объединяет их в слова и предложения, воссоздавая текст. Каким образом она это делает?
Сначала система определяет структуру документа: выделяет текстовые блоки, таблицы, графики, сноски, ссылки, колонтитулы, номера страниц и другие элементы оформления. Этот процесс производится постранично. Затем программа делит текст на строки, слова и символы. После этого в работу включаются механизмы распознавания — классификаторы.
Они анализируют каждый символ и предлагают ряд гипотез о том, на какую букву или знак он похож. Из списка предположений классификаторы выбирают то, которому присвоен наибольший вес, и программа выдает распознанный текст.
Отличительные особенности технологии оптического распознавания текста от ABBYY:
- Быстрота и точность распознавания.
- Полное сохранение исходной структуры и форматирования документа. Программа восстанавливает не только сам текст, но и все элементы оформления, включая иллюстрации, гиперссылки, сноски, колонтитулы и т. п.
- Поддержка более 190 языков. Система распознавания текста интегрирована со словарями, и при проверке гипотез учитываются данные о языке документа. Это ускоряет процесс распознавания и сводит к минимуму вероятность ошибок.
- Распознавание символов, набранных любым шрифтом.
- Возможность сохранения текста почти во всех редактируемых форматах (DOC, TXT, RTF, XLS, HTML, PDF), автоматической передачи документа в другие приложения.
- Автоматизация однотипных операций, что позволяет распознавать и обрабатывать документы еще быстрее.
ABBYY OCR: от теории к практике
Какова же прикладная польза от технологий оптического распознавания текста? Процесс оптимизации бизнеса с их помощью идет сразу в нескольких направлениях:
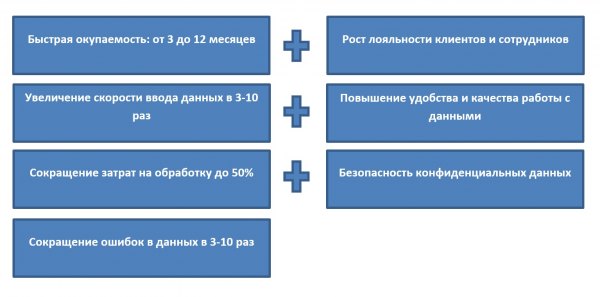
- Уменьшение времени на обработку документов. С программой оптического распознавания текста ручные операции сводятся к минимуму. За счет этого процессы ввода и обработки данных идут быстрее, а сотрудники освобождают рабочее время для более важных задач.
- Повышение качества ввода данных. Автоматизация практически исключает ошибки, неизбежные при выполнении операций вручную.
- Снижение материальных затрат на обработку документов.
- Повышение скорости и качества обслуживания клиентов, что ведет к росту лояльности.
Все это в комплексе влияет на конкурентоспособность компании и помогает бизнесу стать успешнее. Наглядно представить преимущества внедрения программы позволяет статистика:
Посмотрим, какие задачи решает программа распознавания текста в конкретных отраслях.
Банковская сфера
Сотрудники банков ежедневно работают с колоссальным объемом бумажной документации. Технологии распознавания текста позволяют экономить массу времени, труда и средств при осуществлении этих операций. Уже 80 российских банков, входящих в топ-100 [1] , оценили решения ABBYY. Вот примерный перечень задач, с которыми справляются решения ABBYY для распознавания текста:
Оптимизация сбора, хранения и обработки клиентских данных
Программа сканирует поступающие документы и автоматически проверяет, правильно ли они заполнены. После этого программа отправляет скан-образы сотруднику банка для верификации. При этом система умеет распознавать ключевые поля в зависимости от типа документа и сравнивать их содержимое с учетными данными. Верифицированные сотрудниками скан-образы автоматически сохраняются в архив. Любые данные из документов можно передавать в информационные системы банка.
Система потокового ввода клиентских данных от ABBYY успешно используется «Россельхозбанком». Решение позволило создать централизованное хранилище документов с онлайн-доступом, минимизировать потерю информации, ускорить взаимодействие между головным офисом и 78 филиалами. Благодаря автоматизированному вводу данных сотрудники банка теперь ежемесячно обрабатывают 4 млн страниц [2] .
Быстрая обработка документов для выдачи кредита
Когда клиент предоставляет документы для получения кредита, система сканирует их и автоматически проверяет правильность оформления. Также программа определяет, все ли необходимые данные имеются. Автоматизация ввода и анализа документов позволяет как минимум в два раза сократить сроки обработки кредитных заявок [3] .
Автоматический ввод данных при открытии счета юрлица
До внедрения технологий распознавания текста сотрудник банка вносил данные для открытия расчетного счета вручную. Для этого было необходимо проверить комплектность документов, удостовериться в корректности заполнения, отсканировать их, извлечь необходимые данные и передать на дальнейшую обработку в информационные системы банка. Программа выполняет все эти операции автоматически.
Автоматизация расчетно-кассовых операций
Чтобы провести платеж, сотрудник банка вводит в систему данные из платежных документов. В организациях, использующих решения ABBYY, этот процесс протекает в 5–10 раз быстрее [4] . Программа сканирует документы, распознает и извлекает необходимые данные, а потом выдает их оператору. При автоматическом вводе устраняется человеческий фактор, и ошибок практически не бывает.
Автоматизация валютного контроля
Финансовые операции с использованием иностранной валюты относятся к особо трудоемким и сложным банковским процессам, поскольку их осуществление требует строгого соблюдения норм валютного законодательства. Сотрудник банка должен проявлять особое внимание при вводе и проверке данных. Решения от ABBYY позволяют автоматизировать обработку документов валютного контроля, ускорить операции и практически полностью исключить ошибки.
Энергетика
Возможности технологий распознавания текстов востребованы и в энергетической отрасли. Прежде всего они используются для автоматизации обработки бумажных и электронных документов.
Автоматизированный ввод данных с приборов
Показания приборов используются и при коммерческом учете потребления электроэнергии, и при техническом обслуживании оборудования (результаты проведения испытаний). Данные чаще всего поступают на бумажных носителях. Показания приборов учета и измерительных устройств вводятся в информационную систему для обработки. Благодаря решениям ABBYY этот процесс происходит автоматически. Программа позволяет сократить сроки обработки документов, исключить ошибки ввода, уменьшить затраты труда персонала.
Автоматизация бухгалтерских операций
Через отделы бухгалтерии электросетевых компаний ежедневно проходит огромное количество финансовых документов. Каким бы внимательным ни был сотрудник, при таком объеме данных неизбежно возникают ошибки. Это приводит к потерям времени и средств, особенно при несвоевременном обнаружении. Не говоря уже о длительности самого процесса ручного ввода.
Внедрение решения по распознаванию текста на 50% сокращает затраты при обработке счетов-фактур [5] , минимизирует ошибки ввода, предотвращает потерю данных. Программа сканирует, распознает и проверяет документы, автоматически извлекает из них нужную информацию и вводит ее в систему. Бухгалтеру остается только подтвердить, правильно ли распознаны данные.
Компания КЭС-Энергостройсервис, занимающаяся ремонтом объектов энергетики, столкнулась с проблемой чрезмерных затрат на документооборот. Чтобы получить нужные запчасти, приходилось ждать 3–7 дней: именно столько времени занимал процесс обработки и согласования документов. После внедрения платформы ABBYY FlexiCapture бухгалтеры стали выполнять эту работу за 1–3 часа [6] .
Быстрая обработка заявок по технологическому присоединению физических и юридических лиц к электросетям
Прежде чем заключить с потребителем договор на технологическое присоединение к электросетям, сотрудники энергетической компании принимают и обрабатывают заявку. Несмотря на то что этот документ разрешается подавать в электронном виде, многие заявители по-прежнему предпочитают традиционные бумажные носители. Персоналу приходится вводить данные вручную, затрачивая лишнее время и труд.
С внедрением решения ABBYY все упрощается: бумажная заявка сканируется, затем программа помещает скан-копию в электронное хранилище, а распознанные данные передает в информационную систему, где они автоматически обрабатываются. Рутинная работа сотрудников сводится к минимуму, и они могут уделять время другим задачам.
Нефтегазовая отрасль
Нефтегазовые компании в своей работе тоже сталкиваются с большим объемом бумажной документации. Данные нужно оперативно и точно вносить в систему и обрабатывать. При этом необходимо, чтобы сотрудники имели к ним быстрый доступ. Понимая, что от этих процессов зависит эффективность бизнеса, руководители компаний стремятся автоматизировать обработку и хранение документов.
Наиболее практичным решением представляется создание удобного электронного архива с широким спектром функциональных возможностей. ABBYY уже реализовала несколько таких проектов в нефтегазовой отрасли.
Например, в ОАО «Востокгазпром» удалось за короткое время оптимизировать ввод учетных и финансовых документов с помощью платформы ABBYY FlexiCapture. Перед разработчиками стояла задача обеспечить точность внесения данных, быстрый доступ к нужной информации. С этой целью было создано 25 шаблонов для обработки актов, накладных, кассовых ордеров и других стандартных типов документов предприятия.
Система автоматически вписывает реквизиты документа в его архивную карточку, прикрепляет скан-копию и результат распознавания в доступном для полнотекстового поиска формате. Текстовые данные программа вносит в нужные поля, проверяет их в соответствии с заданными правилами, подсвечивает возможные ошибки. В результате работа сотрудника сводится к итоговому контролю и подтверждению экспорта документа.
Другие отрасли
Применение программ распознавания текста не исчерпывается перечисленными сферами. Решения от ABBYY востребованы и во многих других отраслях экономики, в частности в образовании, государственном секторе, производстве, логистике и транспорте, ритейле, телекоммуникациях и др.
Возможности программы по распознаванию текста позволяют оптимизировать бизнес-процессы и за счет этого повысить конкурентоспособность компании. Автоматизированная обработка документов экономит время сотрудников и снижает затраты на обработку данных. Удобство и функциональность решений ABBYY уже оценили многие предприятия из разных сфер бизнеса.
P.S. ABBYY — мировой лидер в области технологий интеллектуальной обработки информации. С продуктами и отраслевыми решениями компании можно ознакомиться на сайте www.abbyy.com.
Источник: www.kp.ru
Программы для распознавания текста из изображений
Программы
Несмотря на то, что в цифровую эпоху все идет в цифровую форму, вы возможно заметили, что бумага не исчезла. У нас все еще есть стопки распечаток, книг, счетов, листовок, журналов, выписок и других газет, с которыми нам приходится иметь дело ежедневно.
Как текстовые документы могут идти в ногу с текущими технологическими изменениями
Вот тут-то и появляется оптическое распознавание символов (OCR). Программное обеспечение OCR позволяет оцифровывать печатные или рукописные документы, делая их редактируемыми с помощью программ обработки текста.
Оптическое распознавание символов (OCR) — это программа, которая может конвертировать отсканированные, распечатанные или рукописные файлы изображений в машиночитаемый текстовый формат. Или если говорить более просто это программы для распознавания текста из изображений.
Возможно, у вас есть книга или квитанция, которую вы напечатали или напечатали несколько лет назад, и вы хотите, чтобы она была в цифровом формате, но вы не хотите ее перепечатывать. OCR может быть очень полезным в таком случае.
В этой статье, мы поговорим про лучшие программы для распознавания текста из изображений. Это основной вопрос, который у вас может возникнуть перед загрузкой OCR. Мы поможем вам выбрать, ответив на более конкретные вопросы:
- Поддерживает ли программа несколько форматов файлов?
- Есть ли в программе OCR распознавание разных языков?
- Можете ли вы использовать инструмент OCR онлайн?
- Распознает ли текст из файлов изображений?
Программы для распознавания текста из изображений
Сразу стоит отметить, что в этом списке, присутствуют программы не только для Ubuntu но и с поддержкой Windows/macOS.
Программы для распознавания текста из изображений для Ubuntu
Чтобы запустить Tesseract Goto откройте Terminal и введите следующее
tesseract imagefile.tif outputfile.txt
Readiris 17
Readiris 17 — последняя версия этого высокопроизводительного программного обеспечения для распознавания текста. Он поставляется с новым интерфейсом, новым механизмом распознавания и более быстрым управлением документами. Вы можете легко конвертировать во многие различные форматы, в том числе в аудиофайлы благодаря его устному распознаванию.
Readiris — это одно из самых мощных программ для распознавания текста, которое требует меньше усилий для начала работы. Хотя это платная программа, вы получаете то, за что платите. Readiris поддерживает большинство форматов файлов и поставляется с другими привлекательными функциями, которые упрощают процесс преобразования.
Например, изображения могут быть получены из подключенных устройств, таких как сканеры, и приложение также позволяет настраивать параметры обработки, такие как настройки DPI.
После завершения обработки Readiris определяет текстовые разделы или зоны и позволяет извлекать тексты либо из определенной зоны, либо из всего файла.
Readiris имеет редкую функцию сохранения в облаке, которая позволяет пользователям сохранять извлеченный текст в различные сервисы облачного хранения, такие как Google Drive, OneDrive, Dropbox и другие.
Он также имеет множество функций редактирования и обработки текста, что позволяет пользователям даже сканировать штрих-коды. Подписка начинается от 99 долларов, и предоставляется 10-дневная бесплатная пробная версия. Использование программы на Ubuntu возможно через Wine.
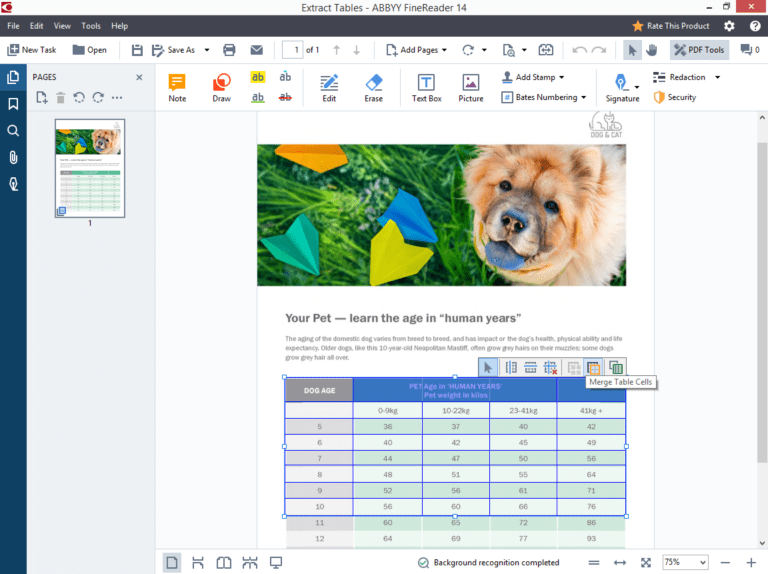
ABBYY FineReader 14
ABBYY FineReader 14 — это самое мощное программное обеспечение для распознавания текста на рынке и лучший инструмент для тех, кому нужно быстрое и точное распознавание текста.
Этот оптический распознаватель прекрасно справляется с работой с большими объемами и оснащен передовыми инструментами коррекции для сложных задач.
Превосходный инструмент проверки легко исправляет сомнительные показания, делая аккуратное сравнение между текстами OCR и оригиналом.
ABBYY Finereader 14 делает больше, чем вы ожидаете от распознавания текста. Вы хотите конвертировать старую книгу на 500 страниц в PDF с возможностью поиска? ABBYY справится с этим с максимальной точностью.
ABBYY извлечет самые точные тексты из изображений, найденных в Интернете.
Кроме того, он может конвертировать отсканированный документ в HTML или в формат ePub, используемый электронными читателями. Использование программы на Ubuntu возможно через Wine.
Microsoft OneNote (бесплатно)
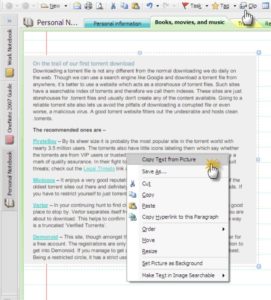
Microsoft OneNote также можно использовать в качестве OCR, несмотря на его функциональность в качестве хранителя заметок. Существует опция «Копировать текст из изображения», которая позволяет извлекать текст из изображений.
Его простота — вот что делает его уникальным; просто вставьте картинку в OneNote, затем щелкните правой кнопкой мыши на картинке и выберите «Копировать текст из картинки», а OneNote сделает все остальное. Он сохраняет текст в буфер обмена, а затем вы можете вставить текст в Microsoft Word или любую другую программу по вашему выбору.
Тем не менее, он не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Simple OCR (Free)
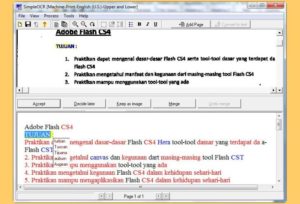
Если говорить про программы для распознавания текста из изображений, то это приложение является очень удобным. Simple OCR — это удобный инструмент, который вы можете использовать для преобразования распечаток в печатном виде в редактируемые текстовые файлы.
Если у вас много рукописных документов и вы хотите преобразовать их в редактируемые текстовые файлы, тогда Simple OCR будет вашим лучшим вариантом.
Тем не менее, рукописное извлечение имеет ограничения и предлагается только как 14-дневная бесплатная пробная версия. Машинная печать бесплатна и не имеет ограничений.
Существует встроенная проверка орфографии, которую вы можете использовать для проверки расхождений в преобразованном тексте. Вы также можете настроить программное обеспечение для чтения непосредственно со сканера.
Как и Microsoft OneNote, Simple OCR не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Free OCR
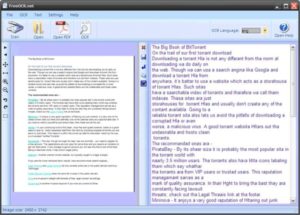
Free OCR использует Tesseract Engine, который был создан HP и теперь поддерживается Google.
Tesseract — очень мощный движок, и сегодня он считается одним из самых точных механизмов распознавания текста в мире. Free OCR отлично справляется с форматами PDF и поддерживает устройства TWAIN, такие как цифровые камеры и сканеры изображений.
Кроме того, он поддерживает практически все известные файлы изображений и многостраничные файлы TIFF. Вы можете использовать программное обеспечение для извлечения текста из картинок, и оно делает это с высокой степенью точности.
И, как и другое программное обеспечение Free OCR, Free OCR не поддерживает вывод таблиц и столбцов.
Boxoft Free OCR (Бесплатно)
Boxoft Free OCR — еще один удобный инструмент, который вы можете использовать для извлечения текста из всех видов изображений.
Эта бесплатная программа проста в использовании и способна анализировать многостолбцовый текст с высокой степенью точности.
Он поддерживает несколько языков, включая английский, испанский, итальянский, голландский, немецкий, французский, португальский, баскский и многие другие.
Это программное обеспечение OCR позволяет вам сканировать ваши бумажные документы и конвертировать их в редактируемые тексты в течение очень короткого времени.
Хотя существуют опасения, что это средство распознавания текста не справляется с извлечением текста из рукописных заметок, оно исключительно хорошо работает с печатными копиями.
Top OCR (Платный)
TopOCR отличается от типичного программного обеспечения OCR во многих аспектах, но выполняет работу точно. Лучше всего работает с цифровыми камерами и сканерами. Если говорить про лучшие программы для распознавания текста из изображений, то обязательно стоит и рассказать про эту программу более детально.
Его интерфейс также отличается, поскольку у него есть два окна — окно изображения (источника) и текстовое окно.
Как только изображение получено с камеры или сканера с левой стороны, извлеченный текст появляется с правой стороны, где находится текстовый редактор.
Программное обеспечение поддерживает форматы GIF, JPEG, BMP и TIFF. Вывод также может быть преобразован в несколько форматов, включая PDF, HTML, TXT и RTF.
Программное обеспечение также поставляется с настройками фильтра камеры, которые можно применять для улучшения изображения.
ABBYY FineReader Online (бесплатно)
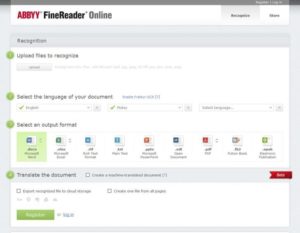
Если вы хотите насладиться мощными функциями, которые ABBYY предлагает, но не хотите идти дорогим путем, то вы можете попробовать бесплатную онлайн-версию.
FineReader Online поддерживает множество входных файлов, таких как PDF, JPEG, JPG, PNG, DCX, PCX, TIFF, TIF и BMP. Поддерживаемые выходные файлы включают PDF, Word, Excel, e-Pub и Powerpoint.
Бесплатная версия позволяет вам конвертировать до 10 страниц в месяц, и она требует сначала сделать регистрацию, которая также бесплатна.
Однако, если вы интенсивный пользователь и хотите конвертировать больше страниц в месяц, вам необходимо подписаться на платную версию.
Распознавание текста онлайн
Еще один отличный способ, это распознавать текст онлайн. Сайт img2txt предлагает очень удобный, легкий и быстрый для распознавания текста.
Готово! В этой статье, мы поговорили про лучшие программы для распознавания текста из изображений. Рынок наводнен программами OCR, которые могут извлекать текст из изображений и сэкономить вам много времени, которое вы могли бы потратить на перепечатывание документа.
Однако хорошие программы для распознавания текста из изображений должно делать больше, чем извлекать текст из печатных документов. Оно должно поддерживать макет, текстовые шрифты и текстовый формат в качестве исходного документа.
Мы надеемся, что эта статья поможет вам найти лучшее программное обеспечение для распознавания текста. Не стесняйтесь комментировать и делиться.
Источник: linuxinsider.ru