
Иногда случается, что программа, установленная в первый раз на компьютер, показывает вместо русских букв «иероглифы». Чаще всего такое бывает в странах, где русский язык не является родным для компьютера, например, в Армении, Азербайджане, Литве. Как это исправить?
Маленькое научное отступление. Юникод.
Как вы наверняка знаете, компьютеры (в современном понимании этого слова — электронные машины для бизнеса) придумали американцы. Для того, чтобы они заработали (компьютеры, а не американцы;), нужно было решить огромное количество технических задач. Одной из таких задач был выбор способа кодирования текстовой информации в компьютере. Проблема состоит в том, что компьютер не хранит текст, картинки, видео и т.п. — компьютер хранит только числа, и нужно было договориться о стандарте кодирования текста числами таким образом, чтобы закодированный на одном компьютере текст мог легко прочитаться на другом компьютере.
В результате было принято решение отвести для хранения каждой буквы текстовой информации один байт компьютерной памяти. В один байт может поместиться одно число от 0 до 255, вот этими-то числами и закодировали буквы алфавита. В результате букве «A» достался код 65, а цифре «7», например, код 55. Таблица соответствия разных символов алфавита числам получила наименование ASCII-таблицы, а сами коды символов стали называть ASCII-кодами. ASCII расшифровывается как American Standard Code for Information Interchange, или Американские Стандартные Коды Для Обмена Информацией.
Символы вместо русских букв | Как убрать иероглифы
Как мы уже говорили, в один байт можно записать число от 0 до 255, так что одним байтом можно закодировать 256 разных значков. Этого диапазона хватило для:
- Букв английского языка — 52 штуки (отдельно строчные и отдельно прописные буквы)
- Цифры — 10 штук
- Знаки препинания и знаки арифметических операций
- Спецсимволы, например, «» и знак табуляции
- Управляющие символы, например, «возврат каретки»
- и т.п.
После перечисленного выше в ASCII-таблице осталось место для букв одного дополнительного национального алфавита, например, кириллицы, и получилось, что программы, кодирующие текстовую информацию по стандарту ASCII, могут показывать символы только двух алфавитов, причем одним из двух алфавитов в любом случае является английский. Разумеется это доставляло определенные неудобства. Так, например, французский историк, пишущий статью про Древнюю Грецию, не мог вставить в текст цитаты на греческом, т.к. из-за ограничений таблицы ASCII его текст мог состоять только из английского и французского либо из английскойго и греческого, но никак не из трех языков одновременно.
Через некоторое время был принят стандард Юникод (Unicode), который отводил под каждую букву бОльшее количество байт, и закодированный по Юникоду текст мог одновременно содержать символы нескольких алфавитов одновременно, включая и иероглифические. Однако осталось довольно много программ, созданных с использованием кодировки ASCII и не поддерживающих Юникод, и эти программы, даже работая в современных операционных системах, умеют показывать символы только двух алфавитов одновременно.
Иероглифы вместо русских букв на Windows. Как исправить?
К сожалению, программа Тирика-Магазин не поддерживает Юникод и работает в кодировке ASCII. Это означает, что она может работать только с двумя алфавитами: английским (поскольку он вшит в таблицу ASCII намертво) и русским (поскольку все меню, окна и т.п. программы «говорят по-русски»). Это означает, что символы национальных алфавитов, например, армянского, будут всегда отображаться в программе некорректно. Мы планируем изменить эту ситуацию и перевести программу в Юникод, но это большая работа, которую не сделаешь вдруг — и она пока не сделана.
Так как же настроить программу для корректного показа русских букв?
Если вы установили программу на свой компьютер и программа показывает русские буквы иероглифами, то вам необходимо донастроить ваш компьютер т.о., чтобы он для программ, не поддерживающих Юникод, в качестве национального алфавита использовал русский язык. Для этого:
1. Откройте Панель Управления Windows
Windows XP и Windows 7: нажмите кнопку Пуск и выберите Панель Управления

Windows 8: Дважды щелкните мышью в иконку Мой Компьютер, слева переключитесь в секцию Компьютер и потом в верхней части окна нажмите кнопку «Запустить Панель Управления»:

2. Откройте окно языковых настроек Windows
Windows XP: Для этого в Панели Управления нужно запустить иконку «Языки И Стандарты»:
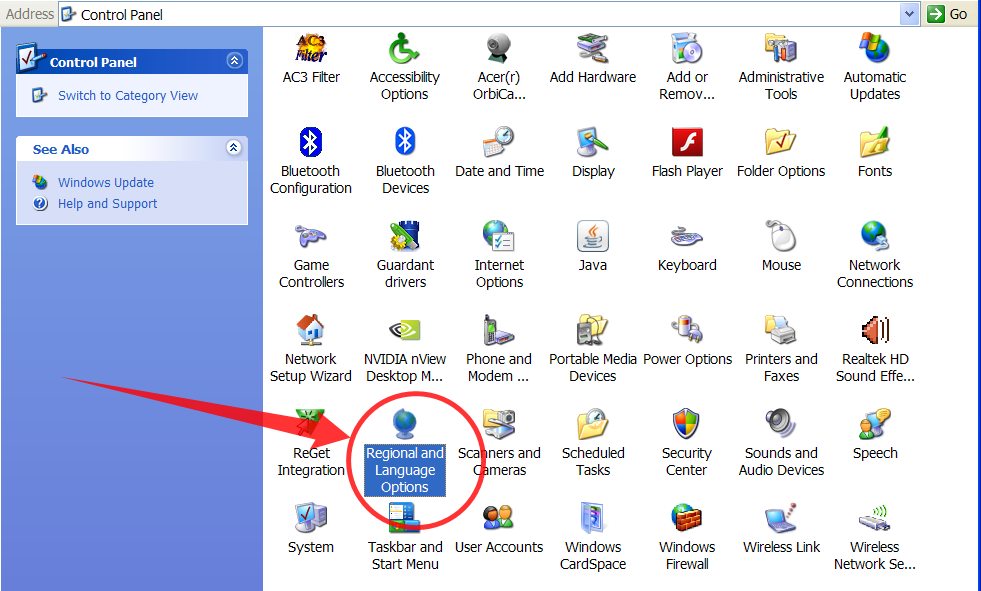
Windows7 и Windows8: В Панели Управления выбрать «Добавление языка» в секции «Часы, язык и регион» и потом щелкнуть «Изменение форматов даты, времени и чисел»:
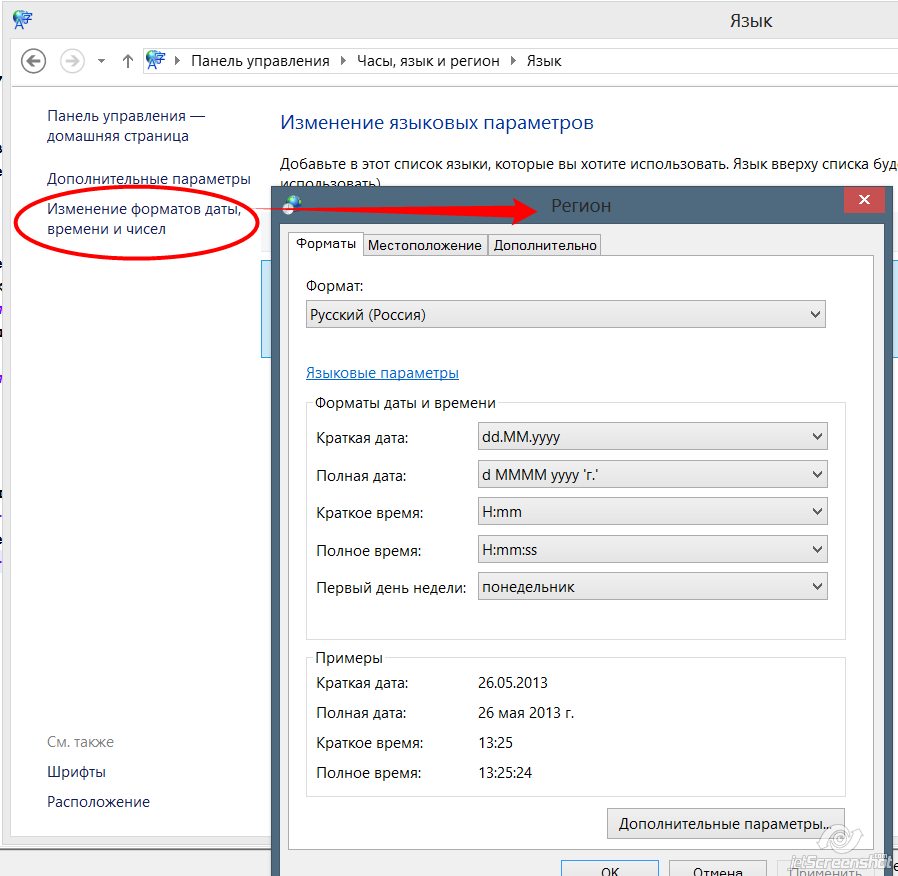
3. Укажите язык для программ, не поддерживающих Юникод:
Windows XP: В открывшемся окне переключитесь на последнюю закладку и выберите русский язык в секции «Язык программ, не поддерживающих Юникод»:
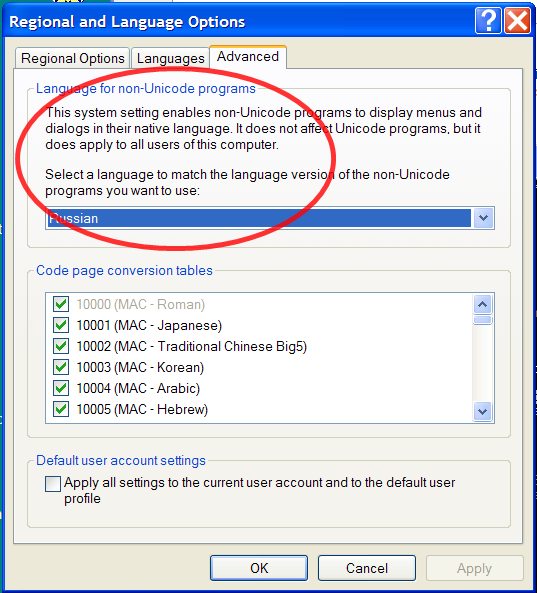
Windows 7 и Windows 8: В открывшемся окне переключитесь на последнюю закладку, найдите секцию «Язык программ, не поддерживающих Юникод», нажмите кнопку «Изменить язык системы» и выберите там русский язык:

После этого программа Тирика-Магазин будет писать русские буквы везде, где это необходимо.
Важные примечания
Примечание 1
Как вы теперь понимаете, по этой инструкции вы можете настроить Windows таким образом, чтобы она использовала русский как второй алфавит во всех программах, не поддерживающих Юникод. Так, например, если у вас таких программ установлено несколько (а Тирика — это далеко не единственная программа, не поддерживающая Юникод) и при этом вы живете не в России, а, например, в Армении, то все такие программы на вашем компьютере разучатся говорить по-армянски. Впрочем, Вам никто не мешает проделать все описанные выше действия, посмотреть, что из этого выйдет и если результат вам не понравится — поменять все настройки обратно.
Примечание 2
Из вышесказанного также следует, что программа Тирика-Магазин не сможет работать с языками, отличными от русского. Так, например, если вы живете в Армении и хотели бы использовать программу Тирика-Магазин, имеющую русский внешний вид, но вписывать наименования товаров по-армянски, у вас ничего не выйдет: работая в стандарте ASCII, программа поддерживает только два языка, и языка эти — русский и английский.
Источник: www.tirika.ru
Freevi
Бесплатная программа для распознавания текста FreeOCR, не дружит с русским языком
25 декабря 2010 Serg Написать комментарий К комментариям
До недавнего времени был уверен, не существует бесплатных программ для распознавания отсканировано текста, когда надо документы, книги пригнать на компьютер. Есть только монстры, вроде, популярного у нас ABBYY FineReader, за который в обязательном порядке придется выкладывать немаленькие деньги. Но, оказалось, есть бесплатные OCR (оптическое распознавание символов) программы, развитие которых поддерживают энтузиасты. Среди таких представителей, абсолютно бесплатное приложение для распознавания текста FreeOCR.
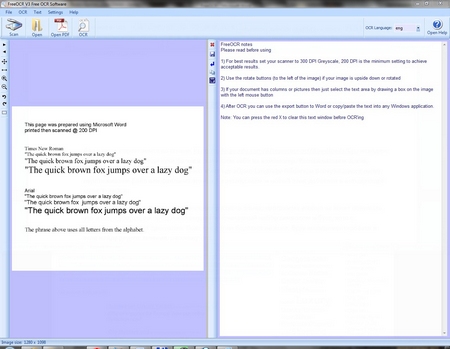
Обязательно проверьте пред началом установки, чтоб компьютер был подключен к интернету, потому-то будем запускать оболочку, которая будет скачивать все необходимые файлы, ведь установочный файл весит всего 150 кб, и туда точно невозможно поместить все необходимое для работы столь сложной программы . Разработчики предупреждают, что будут скачано дополнительно 11 мегабайт, в моем случае папка с установленной программой весит 4 Мб. В остальном стандартный перечень вопросов, в какую папку ставить и подтверждение лицензионного соглашения.
Запустив программу, неожиданно получаем простенький, но вполне современный интерфейс. Даже хотел сказать, что там есть ленточное меню, но его там нет, просто разработчикам удалось все настолько стильно и органично сделать.
FreeOCR может распознавать текст с документов, полученных из pdf файлов (работает с ними довольно медленно и тормознуто, когда перелистываешь страницы), графических фалов (поддерживаются все основные форматы) и со сканера (жмем на кнопку, выбираем один из доступных сканеров, а дальше все на автомате, никаких настроек не предлагается). Собственно этому и посвящено меню с большими иконками, под основным, которые красноречиво расскажут о своем назначении. Кто задается вопросом, зачем нужна кнопка «OSR», собственно поле нажатия на неё и происходит распознавание текста.
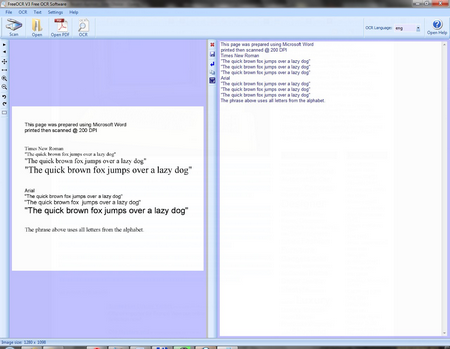
Все окно программы разделено на две половины, в левой стороне находится каретника с текстом которое надо распознать, а с правой, текст, результат работы программы.
Теперь надо рассказать о некоторых нюансах работы FreeOCR. Программа не может автоматически разбивать страницу на колонки, или определить где именно находятся картинки, поэтому для получения нормальных результатов, ту часть изображения, которую надо распознать необходимо, выделить, зажав правую кнопку мыши. На боковой панели есть несколько кнопок, которые позволяют облегчить с картинками, это зум, вращение на 90 градусов (когда текст лежит боком), и перелистывание многостраничных документов.
Весь текст, который распознал FreeOCR, добавляется к уже существующему в самый конец, поэтому желательно каждый раз очищать это окно, чтоб не приходилось искать какие абзацы были переведены. Панель иконок помогает работать с текстом, позволяет быстро стирать текст в правой панели, сохранять в готовый текст в файл, копировать в буфер обмена, убирать разметку страницы и отправлять в текстовый редактор Word (почему именно ему досталась такая честь непонятно).
Только вот с языками вышла заминка, с текстом на английском языке справляется неплохо, но вместо рисских слов выдает нечитаемый набор символов. Как оказалась, какой язык надо использовать при распознавании текста, выбираем вручную из выпадающего меню справа вверху, оно подписано «OSR Language». По умолчанию идет только английский, остальные придется добавлять отдельно.
Для начала оправляемся по ссылке http://code.google.com/p/tesseract-ocr/downloads/list, находим нужный нам язык, среди кучи фалов и скачиваем себе на компьютер. Распаковываем архив, приходим в программе в раздел меню «Settings->Open Language Folder», и в открывшуюся папку перетаскиваем файлы из архива. Перезапускаем и новый язык добавлен в выпадающее меню FreeOCR.
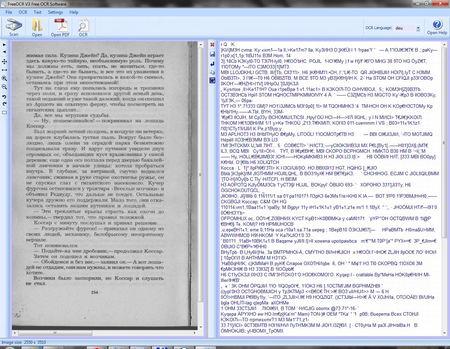
Только вот у меня даже после добавления русского языка, программа упорно не хочет понимать это язык, показывая, что начался процесс обработки, но без результатов, остается пустое место, не распознавания текста, хотя с английским работает прекрасно. Пока как с этим бороться не ясно, буду экспериментировать и если найду рецепт лечения, расскажу его.
Как оказалось движок Tesseract OSR (что это такое, написано ниже) который здесь используется для распознавания текста старой версии 2.04, сейчас актуальный 3.0, и в нем поддержки русского языка, только английский, немецкий, испанский, итальянский, французский и еще несколько экзотических. В общем, при всей своей перспективности, программа в нынешнем виде абсолютно бесполезна в нашей стране, пока не начнет использовать Tesseract OSR 3.0, а там нормально поддерживается русский язык. Вот именно для этой версии готова поддержка распознавания текста большого количества языков.
Настроек в программе нет, все работает в автоматическом режиме.
Теперь хочу немного рассказать, откуда появился FreeOCR. Как оказалось движок, который распознает текст, взят из открытого проекта под названием Tesseract OSR. Разработчики FreeOCR только сделали свою оболочку и все максимально автоматизировали, чтоб не дергать пользователей лишними вопросами.
При всем пессимизме пред началом работы FreeOCR, он действительно работает и оказался очень дружелюбный к пользователям. Во всем можно разобраться в течение нескольких минут. Но это касается только английского языка, который идет по умолчанию, добавление поддержку других языков, можно охарактеризовать моя борьба.
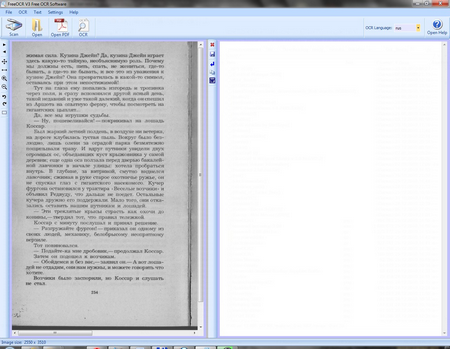
Еще есть достаточно серьезные недостатки, это не уверенное распознавание символов, слишком много возникает ошибок, потом приходиться тратить время на проверку правописания и все перечитывать. Но сама главное это поддержка малого количества языков, русский не входит в список избранных. В нынешнем состоянии не рекомендую использовать. Хотя кто работает с документами на английском языке, может стать неплохим выбором, ведь можно бесплатно использовать даже в коммерческих организациях.
Прекрасно работает в 32-х и 64-х битных операционных системах. Интерфейс программы только на английском языке, но пунктов и надписей немного поэтому не составит труда разобраться.
Сайт для бесплатного скачивания FreeOCR http://www.paperfile.net/
Последняя версия на момент написания FreeOCR 3.0
Размер программы: установочный файл 156 Кб
Совместимость: Windows Vista и 7, Windows Xp
Источник: freevi.net

Почему программы устанавливаются не на русском языке?
Автор benia21, 09-08-2014, 13:51
0 Пользователи и 1 гость просматривают эту тему.
Вниз Страницы 1
Вверх Страницы 1
- HARD NEWS
- ► Форум
- ► ПРОБЛЕМЫ С КОМПЬЮТЕРОМ.
- ► Проблемы с работой компьютера.
- ► Почему программы устанавливаются не на русском языке?
Действия пользователя
Ваши права в разделе
- Вы не можете создавать новые темы.
- Вы не можете отвечать в темах.
- Вы не можете прикреплять вложения.
- Вы не можете изменять свои сообщения.
- BB-тегиВкл.
- СмайлыВкл.
- [IMG] кодВкл.
- HTML код Вкл.
Страница создана за 0.489 сек. Запросов: 27.
Источник: alexsf.ru