
Цель работы: научиться сканировать, распознавать, редактировать и сохранять (в различных форматах) документ, пользуясь одной из наиболее популярных программ, поддерживающих процесс сканирования и перевода текстовых и графических изображений с бумажных носителей в электронный вид.
Формируемые компетенции
Для студентов, обучающихся по направлению подготовки 09.03.03 – «Прикладная информатика», профиль подготовки «Прикладная информатика в юриспруденции».
Способность использовать современные информационные технологии для решения учебных, исследовательских и профессиональных задач в области юриспруденции (ПВК-3):
— уметь эффективно использовать персональные компьютеры для решения задач, возникающих в процессе обучения в вузе, а также в области своей будущей деятельности (юриспруденции);
— уметь пользоваться современными программными средствами работы с информацией в текстовом представлении;
— владеть навыками компьютерной обработки служебной документации.
Scan documents into Excel with ABBYY Finereader by Chris Menard
Для студентов, обучающихся по специальности 40.05.01 «Правовое обеспечение национальной безопасности» и направлению подготовки «Юриспруденция».
Способность работать с различными источниками информации, информационными ресурсами и технологиями, применять основные методы, способы и средства получения, хранения, поиска, систематизации, обработки и передачи информации (ОК-16):
— владеть навыками компьютерной обработки служебной документации;
— умеет применять современные информационные технологии для обработки правовой информации, оформления юридических документов.
ЗАДАНИЕ
1. Отсканировать предложенный преподавателем документ (текст и/или рисунок) с помощью оптической системы распознавания – OCR FineReade.
2. Текст распознать и перенести в текстовый процессор Word.
3. Отсканированный рисунок сохранить в своей папке с именем «рис» в формате tiff, т.е. рис.tiff, скопировать и перенести в Word под текст.
4. Документ оформить следующим образом: шрифт Times New Roman, размер 11, выравнивание по ширине, абзацный отступ 1,5 см., заголовок (если он есть) по центру, прописными буквами, полужирным шрифтом. Рисунок по центру с подрисуночной подписью.
5. Готовый документ сохранить в свою папку с именем, состоящем из фамилии исполнителя и номера работы.
ПОМОЩЬ
Алгоритм действий
1. С помощью ярлыка на рабочем столе отрыть редактор FineReader.
Вставить документ в сканер (документом вниз на стекло) и нажать на панели инструментов FineReader кнопку-команду СКАНИРОВАТЬ (см. рис. 11, 12. На рис. 11 представлена структура окна FineReader, рабочая область которого состоит из четырёх окон.
Для сравнения на рисунках представлены две версии редактора FineReader, 7 и 12), в рабочее окно загрузиться «Менеджер задач» (пользователем «Менеджер задач» может быть отключён, тогда после вызова функции сканировать сразу начнётся данный процесс). На рис. 12 «Менеджер задач» открыт в окне программы, поэтому для сканирования можно воспользоваться как кнопкой-командой СКАНИРОВАТЬ на панели инструментов, так и функциями представленными в окне менеджера задач.
@Technological knowledge | ABBYY FineReader PDF 15 | Software to convert PDF files, image files
2. Полученное изображение текста распознать (все или выделенный фрагмент), щелкнув мышкой кнопку-команду РАСПОЗНАТЬ.
3. Распознанный документ можно: сохранить с нужным форматом; перенести в текстовый процессор Word либо с помощью операции копирования, либо экспортировать с помощью кнопки-команды MS-WORD, а в 12 версии можно также сразу выбрать команду «Сканировать в Microsoft Word».

Рис. 11. Окно редактора FineReader 7
Полный алгоритм сканирования и переноса документа в необходимый редактор представлен в учебном пособии «Прикладные программы», указанном в списке литературы под номером 3.
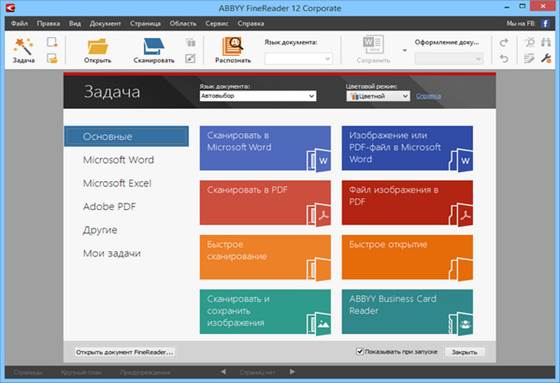
Рис. 12. Окно редактора FineReader 12
Теоретический материал
Основные возможности версии OCR FineReader:
— улучшенная точность распознавания и сохранения, форматирования исходных документов; распознавание и сохранение документов в удобном для пользователя формате, в том числе в формате PDF;
— экспорт распознанного текста в офисные приложения;
— возможность воспроизводить такие сложные элементы верстки, как непрямоугольные картинки, обтекание картинок текстом, различные шрифты, таблицы. Версия FineReader 12 имеет технологию адаптивного распознавания ADRT®2.0 (Adaptive Document Recognition Technology), благодаря которой программа точно распознаёт документы со сложным форматированием. Данная версия редактора анализирует документ как единое целое, при этом полностью сохраняя его логическую структуру: оглавление и гиперссылки, разноуровневые заголовки, номера страниц, нижние и верхние колонтитулы, подписи к картинкам, а также стили шрифтов и заголовков;
— версия ABBYY FineReader 12 распознает изображения, сделанные с помощью цифрового фотоаппарата или фотокамеры мобильного телефона.
Пакетная обработка – облегчает работу с многостраничными документами. Такие функции, как «распознать», «повернуть изображение», «очистка изображения», «сохранить» можно применять ко всем страницам, т.е. пакету в целом. Пиктограммы позволяют контролировать процесс пакетной обработки документов.
Система проверки орфографии – позволяет легко проверить и отредактировать распознанный текст. Неуверенно распознанные символы и слова, которых нет в словаре, выделяются различными цветами.
Распознавание многоязычных документов – редактор FineReader 12 распознает тексты на 190 языках, включая английский, русский, немецкий, французский и др., причём данная версия программы автоматически определяет язык распознавания. В ранних версиях программы, чтобы распознать документ, состоящий текста на разных языках, необходимо было выделить нужный текстовый блок и установить язык, на котором он представлен, затем распознать его, и так по очереди выбирать языки для разноязычных текстовых блоков и после этого выполнять процесс распознания.
Редактор распознает любой тип шрифта, если он есть в его библиотеке, рукописный текст (свободный стиль, т.е. не текст, написанный печатными ровными буквами) процессор воспринимает как рисунок.
FineReader полностью совместим с операционными системами компании Мiсrоsоft.
Прямой экспорт в Microsoft Word, Ехсеl и Оиtlооk – FineReader легко и быстро экспортирует результаты распознавания в офисные приложения.
Обработка изображений различных форматов – FineReader поддерживает большое количество входных форматов файлов. Можно распознавать изображения, полученные из самых разных источников, в том числе факсы.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что такое OCR?
2. Какие окна содержит рабочая область редактора FineReader, в чём их назначение?
3. Имеется ли в редакторе FineReader возможность форматировать документ?
4. Перечислите функциональные возможности OCR FineReader.
5. Способен ли FineReader распознать изображение текста, содержащего фрагменты на разных языках?
6. Распознают ли оптические системы распознавания рукописный текст?
7. Объясните процедуру переноса фрагмента распознанного текста в MS Word.
Лабораторная работа 5
ПРОГРАММЫАВТОМАТИЗИРОВАННОГО ПЕРЕВОДА ДОКУМЕНТОВ
Цель работы: научиться, пользуясь одним из существующих онлайн переводчиков (например, Promt), переводить исходный текст с одного языка на другой, например, с русского на английский, немецкий или французский..
Формируемые компетенции
Для студентов, обучающихся по направлению подготовки 09.03.03 – «Прикладная информатика», профиль подготовки «Прикладная информатика в юриспруденции».
Способность использовать современные информационные технологии для решения учебных, исследовательских и профессиональных задач в области юриспруденции (ПВК-3):
— уметь эффективно использовать персональные компьютеры для решения задач, возникающих в процессе обучения в вузе, а также в области своей будущей деятельности (юриспруденции);
— уметь пользоваться современными программными средствами работы с информацией в текстовом представлении;
— владеть навыками компьютерной обработки служебной документации.
Для студентов, обучающихся по специальности 40.05.01 «Правовое обеспечение национальной безопасности» и направлению подготовки «Юриспруденция».
Способность работать с различными источниками информации, информационными ресурсами и технологиями, применять основные методы, способы и средства получения, хранения, поиска, систематизации, обработки и передачи информации (ОК-16):
— владеть навыками компьютерной обработки служебной документации;
— умеет применять современные информационные технологии для обработки правовой информации.
ЗАДАНИЕ
1. Текст документа «Фамилия-6.dос» перенести в переводчик, например, Promt.
2. Выполнить перевод текста на предложенный преподавателем язык.
3. Перевод добавить к документу «Фамилия-6», оформить в соответствии с правилами его оформления и сохранить с именем, состоящим из фамилии исполнителя и номера работы.
4. Чтобы ответить на контрольные вопросы, необходимо самостоятельно изучить тему «Программы автоматизированного перевода документов» в учебном пособии «Прикладные программы» (см. список литературы под номером 3).
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Какие программы автоматизированного перевода документов Вы знаете?
2. Возможен ли перенос текста из стационарного компьютерного переводчика Promt в WordPad?
3. Как в стационарной программе Promt из исходного текста перевести только одно слово или фразу?
4. Существует ли в онлайн и/или стационарной программе Promt возможность редактирования исходного/итогового текста?
5. Можно ли сохранить итоговый документ в самом компьютерном переводчике онлайн и/или стационарном (если нет, то почему; если да, то как)?
Лабораторная работа 7
Источник: poisk-ru.ru
Инструменты для распознавания текстов и системы компьютерного перевода. Оценка количественных параметров текстовых документов

Программы оптического распознавания
документов
Для ввода текстов в память компьютера с бумажных носителей
используют сканеры и программы распознавания символов.
Одной из наиболее известных программ такого типа является
ABBYY FineReader.
Работа с программой распознавания текста
Бумажный носитель
помещается под крышку сканера
В программе отдаётся команда
Сканировать и распознать
(заранее необходимо выбрать языки распознавания)
Распознанный текст появляется
в окне текстового редактора
3.
Программы оптического распознавания
документов
Вместо сканера можно использовать цифровой фотоаппарат или
камеру мобильного телефона.
Фотографии
текста
4.
Программа ABBYY FineReader
Одна из лучших в мире программа для
оптического распознавания текста (192 языка).
Разработана для операционных систем Microsoft
Windows, macOS и Linux
(проприетарное
программное обеспечение).
Программа позволяет сканировать и преобразовывать с
оптическим распознаванием изображения документов (фотографий,
результатов сканирования, PDF-файлов) в электронные редактируемые
форматы:
• Microsoft Word
• Microsoft Excel
• Microsoft Powerpoint
• RTF
• HTML
• PDF
• текстовый файл
Программа распознаёт множество языков, в том числе в одном тексте.
5.
Компьютерные словари
Компьютерные словари выполняют перевод отдельных слов и
словосочетаний.
Компьютерные словари обеспечивают мгновенный поиск
словарных статей.
Многие словари предоставляют пользователям возможность
прослушивания слов в исполнении носителей языка.
Компьютерный словарь
Установлен на компьютер
как самостоятельная программа
Встроен в текстовый процессор
В on-line-режиме в сети Интернет
6.
Программа ABBYY Lingvo
Одной из наиболее известных программсловарей. Имеются пакеты для многих популярных
операционных систем, таких как Windows, Windows
Mobile, Symbian OS, Mac OS X, iOS, Android
(проприетарное программное обеспечение).
Включает сотни общелексических и тематических
словарей для перевода и толковых словарей.
В ABBYY Lingvo нет функции полнотекстового
перевода, но возможен пословный перевод текстов из
буфера обмена.
7.
Компьютерные
программы-переводчики
Для
перевода
текстовых
программы-переводчики.
Техническая
документация
документов
применяются
Деловая
переписка
Программа-переводчик
Формальное знание языка
Анализ текста
на исходном языке
Конструирование текста
на требуемом языке
!
Художественный литературный перевод текста пока не
возможен.
8.
Программа PROMT
Одной из наиболее известных у нас программпереводчиков является PROMT от одноимённой
российской компании PROMT (проприетарное
программное обеспечение).
Существует множество различных пакетов для дома и
бизнеса. Множество языков.
9.
Google Переводчик
Google Переводчик (англ. Google Translate) — веб-служба
компании Google, предназначенная для автоматического
перевода части текста или веб-страницы на другой язык.
translate.google.com
На сегодня в переводчике доступны 103 языка.
10.
Представление текстовой информации
в памяти компьютера
Текст состоит из символов — букв, цифр, знаков
препинания и т.д., которые компьютер различает по их
двоичному коду.
• на экране (символы)
• в памяти – двоичные коды
01000001
01000010
01000011
01000100
65
66
67
68
Соответствие между изображениями символов и кодами
символов устанавливается с помощью кодовых таблиц.
11.
Фрагмент кодовой таблицы ASCII
Символ
Десятичный
код
Двоичный
код
Символ
Десятичный
код
Двоичный
код
Пробел
32
00100000
0
48
00110000
!
33
00100001
1
49
00110001
Соответствие
между изображениями
символов
и кодами
35
2
50
00100011
00110010
символов
устанавливается
с помощью
кодовых
таблиц.
$
36
3
51
#
00100100
00110011
*
42
00101010
4
52
00110100
=
43
00101011
5
53
00110101
,
44
00101100
6
54
00110110
—
45
00101101
7
55
00110111
_
46
00101110
8
56
00111000
/
47
00101111
9
57
00111001
A
65
01000001
N
78
01001110
B
66
01000010
O
79
01001111
C
67
01000011
P
80
01010000
12.
8-битные коды русских букв
Код ASCII содержит изначально 128 символов (0–127). Среди
них нет русских букв. 8-битные коды имеют 256 кодовых
комбинаций (28 = 256). Коды от 128 до 255 использовали для
кодирования букв национального алфавита (в разных странах по
разному, в одной стране оказалось несколько разных кодовых
таблиц).
Кодовая таблица
0–31 – управляющие символы
ASCII
32 – пробел
33–127 – латинские буквы, знаки
препинания, цифры, знаки
арифметических операций
128–255 – буквы национального
алфавита
13.
Коды русских букв в разных кодовых таблицах
Кодовые таблицы
Символ
КОИ-8
Windows
десятичный
код
двоичный
код
десятичный
код
двоичный
код
А
192
11000000
225
11100001
Б
193
11000001
226
11100010
В
194
11000010
247
11110111
14.
Увеличение мощности кода
Кодовая таблица символов Unicode позволяет
пользоваться более чем двумя языками в одном
тексте.
В Unicode каждый символ кодируется
шестнадцатиразрядным двоичным кодом. Такое
количество разрядов позволяет закодировать
65 536 различных символов: 216 = 65 536.
При использовании кодовой таблицы Unicode в
тексте одновременно могут содержаться любые
символы всех языков мира.
15.
Информационный объём фрагмента текста
Информационный объём фрагмента текста – это
количество бит, байт (килобайт, мегабайт), необходимых для
записи фрагмента оговорённым способом кодирования.
I = K i
I – информационный объём сообщения
K – количество символов
i – информационный вес символа
В зависимости от разрядности используемой кодировки
информационный вес символа текста может быть равен:
• 8 бит (1 байт) — восьмиразрядная кодировка;
• 16 бит (2 байта) — шестнадцатиразрядная кодировка.
16.
Задача 1
Задача 1. Считая, что каждый символ кодируется одним
байтом, определите, чему равен информационный
объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине – только один.
Решение
В данном тексте 57 символов (с учётом знаков препинания и
пробелов). Каждый символ кодируется одним байтом.
Следовательно, информационный объём всего текста – 57 байт.
Ответ: 57 байт.
17.
Задача 2
Задача 2. В кодировке Unicode на каждый символ отводится
два байта. Определите информационный объём слова из 24
символов в этой кодировке.
Решение.
I = 24 2 = 48 (байт).
Ответ: 48 байт.
18.
Задача 3
Задача 3. Автоматическое устройство осуществило
перекодировку информационного сообщения на русском языке,
первоначально записанного в 8-битовом коде, в 16-битовую
кодировку Unicode. При этом информационное сообщение
увеличилось на 2048 байтов. Каков был информационный
объём сообщения до перекодировки?
Решение
Информационный вес каждого символа в 16-битовой кодировке в два раза
больше информационного веса символа в 8-битовой кодировке. Поэтому при
перекодировании исходного блока информации из 8-битовой кодировки в 16битовую его информационный объём должен был увеличиться вдвое,
другими словами, на величину, равную исходному информационному
объёму. Следовательно, информационный объём сообщения до
перекодировки составлял 2048 байтов = 2 Кб.
Ответ: 2 Кбайта.
19.
Задача 4
Задача 4. Выразите в мегабайтах объём текстовой информации в
«Современном словаре иностранных слов» из 740 страниц, если
на одной странице размещается в среднем 60 строк по 80
символов (включая пробелы). Считайте, что при записи
использовался алфавит мощностью 256 символов.
Решение
K = 740 80 60
N = 256
I=K i
N = 2i
I -?
256 = 2i = 28, i = 8
К = 740 80 60 8 = 28 416 000 бит = 3 552 000 байт =
= 3 468,75 Кбайт 3,39 Мбайт.
Ответ: 3,39 Мбайт.
20. Задание
• Откройте стр. 193 – Задание 4.16.
• Создайте в личной папке (папка Фамилия)
файл типа документ Word
с именем Формулы.
• Выполните задание 4.16.
• Закройте файл с сохранением.
21.
Работаем за компьютером
22.
Домашнее задание
Прочитать §4.5 (стр. 174–177). Задания 2–6 (стр. 177) – устно. Задание 3
(стр. 177) – письменно.
Выучить § 4.6 (стр. 178–183). Повторить § 1.6 (стр. 45–50). Задания 2-7
(стр. 183–184) – устно.
Задания 8 (стр. 184) – письменно.
Написать конспект по презентации, выучить, выполнить задания.
Готовый файл пришлите мне на электронную почту [email protected]
Источник: ppt-online.org
Программы-переводчики (Promt XT Professional)
Профессиональная система Promt XT Professional предоставляет комплексное решение задачи автоматизированного перевода больших объемов информации:
Пакетный перевод файлов для работы с большими объемами информации;
Расширенные возможности работы со словарями: сравнение двух словарей, если необходимо проверить информацию и перенести ее из одного словаря в другой; получение полной информации о словаре (количество слов, оборотов, размер словаря и т.п.); слияние двух выбранных словарей в один;
Извлечение терминологии. Широкие возможности настройки: управление алгоритмами сбора терминов, различные отображения сформированного списка;
Автоматизация с помощью макро-процедур. Система предоставляет возможность создания макро-процедур на основе встроенного языка макросов, что существенно повышает производительность работы;
Promt XT Professional предоставляет возможности настройки систем машинного перевода — для целей повышения эффективности всего процесса перевода.
Компьютерные программы для образования
(1С: Репетитор. Физика, версия 1.5а).
В мультимедийном учебном комплексе «1С: Репетитор. Физика» версии 1.5а изложен весь школьный курс:
Программа представляет собой учебник, задачник и справочник, объединенные гипертекстовой структурой, и включает детальное изложение теоретического материала, 70 интерактивных моделей, 100 видеофрагментов и компьютерных анимаций физических опытов и явлений, 300 тестов и задач, 60 минут дикторского текста, биографии известных физиков, справочник, таблицы, формулы, словарь основных терминов.
Программы распознавания текста. (Abbyy FineReader)
Система Abbyy FineReader предназначена для ввода текстов в компьютер с помощью сканера. Она позволяет быстро и точно переводить бумажные документы или PDF-файлы в редактируемый формат с максимально полным сохранением исходного оформления документа.
Как работает программа?
Вы вставляете документ в сканер, нажимаете кнопку Scanhttps://studbooks.net/2070322/informatika/programmy_perevodchiki_promt_professional» target=»_blank»]studbooks.net[/mask_link]