
При работе на ПК мы очень часто сталкиваемся с различными документами, которые имеют неудобный формат для дальнейшей обработки. Например, это могут быть сканы печатных документов. Или PDF книги, инструкции или техническая документация.
Возникает необходимость просканировать их, чтобы текстовый контент перевести в электронный формат для последующего перевода, копирования, редактирования и печати. Как это можно осуществить? Для этого можно использовать специальное программное обеспечение — ABBYY Finereader. Программа сочетает в себе сразу несколько инструментов: переводчик, сканер и пр. Если вам по работе или учебе приходится часто работать с различной документацией, то задумайтесь над тем, чтобы купить ABBYY Finereader.
Как сканировать и переводить текст
Функционал программы в плане перевода в текстовый формат достаточно широк. Это позволяет работать с различными источниками и сохранять текст в разных видах файлов. Именно поэтому доступны широкие настройки, которые позволяют как переводить в ABBYY Finereader, так и сохранять готовые материалы. Рассмотрим несколько популярных направлений работы. Первое – это перевод бумажного документа в электронный. Порядок действий следующий:
ABBYY FineReader 14.0.107.212 | ВЗЛОМ ПРОГРАММЫ | ЛИЦЕНЗИЯ+КЛЮЧ
- Поместите документ в устройство;
- Запустите программу;
- Выберите функцию «Сканирование»;
- Нажмите «Распознать все»;
- Нажмите «Сохранить», выберите пункт «Передать все страницы в» и выберите нужный формат (например, так можно как скан перевести в Ворд, так и сохранить контент в PDF).
Если у вас есть скан печатного документа, и вы хотите перевести текст из него в цифровой формат, то выберите файл из программы, а затем повторите процедуру с распознаванием.
Также стоит отметить, что этот способ прекрасно подходит для работы с PDF документами: книги, инструкции, гарантийные талоны и пр. Очень часто этот формат предполагает защиту от копирования, поэтому стандартным способом перенести текст в Word или куда-то передать не получится. Но эту проблему решит данная программа, позволяющая просканировать PDF, получить текст и сохранить его в нужном формате, который допускает копирование или редактирование.
Другое популярное направление – это перевод документов из картинки. К примеру, у вас есть скриншот страницы сайта, фотография или скан печатного журнала с изображениями. Вам нужно из него достать текст, игнорируя графические элементы. Все это также можно выполнить в ABBYY Finereader. Для этого сделайте следующие шаги:
- Откройте в программе картинку, которую нужно обработать;
- Нажмите кнопку «Редактировать» в панели;
- Обрежьте нужные области, чтобы оставить только рабочий текст, а картинки и другие элементы удалить (здесь доступен большой набор настроек для обрезки и выделения нужных фрагментов);
- Выйдите из редактора соответствующей кнопкой;
- На панели выберите пункт «Текст», чтобы программа выделила области с текстовым наполнением и просканировала их. ПО выделит нужную секцию зеленым цветом;
- Нажмите «Распознать». Дополнительно после можете нажать кнопку «Проверка», чтобы исправить ошибки, вызванные неточностью сканирования;
- Нажмите «Передать», чтобы сохранить текст в нужном формате. Например, Word.
Все готово. Стоит добавить, что во время всех этих операций можно дополнительно переводить текст на нужный язык (как перевести текст в ABBYY Finereader вы можете узнать из инструкции к ПО и тематических статей). В настройках можно выбрать языки и другие параметры работы.
Demo: What’s new in the latest version of FineReader PDF
При работе со сканами или фотографиями документов не забывайте, что чем лучше качество исходного материала, тем выше точность перевода.
Источник: el-store.biz
ABBYY Lingvo скачать бесплатно русская версия
ABBYY Lingvo – утилита для качественного перевода неизвестных слов на 19 языков.
Переводчик содержит более 50 грамматических и общелексических словарей, 138 тематических словарей для английского, татарского, латинского, португальского, русского, финского, испанского, немецкого, греческого, украинского, французского, венгерского, датского, китайского и многих других языков.
Благодаря встроенным в софт качественным словарям, пользователь может быстро узнать перевод нужного слова, его антонимы и синонимы, устойчивые выражения и значения идиом, прослушать как правильно произносится это слово носителем языка, проверить написание и узнать значение в учебном словаре.
Также в функционале доступна утилита АББИ Тутор для запоминания слов и заучивания новых, строка поиска с автодополнениями и вариантами замены, использование фразеологических и сленговых словарей, разговорников, тематических словарей для перевода узконаправленных и предметных терминов разных отраслей и сфер деятельности.
АББИ Лингво мгновенно переводит наведением курсора на слово в письмах, на картинках, сайтах, PDF-файлах и субтитрах к фильму. Если вам необходим оптимальный электронный словарь с достойной базой перевода, предлагаем abbyy lingvo скачать бесплатно русская версия и оценить его возможности.
Отметим, что пробный период активен 15 дней и включает в себя все языки версий и словарей. Если вы решите купить лицензию, то инсталлировать её необходимо поверх пробной. Оцените также доступные на нашем сайте аналоги – PROMT, MultiTranse или Dicter.
Источник: tvoiprogrammy.ru
Возможности программы finereader кратко
А чуть более года назад очередное детище IBM, в свое время положившей начало триумфальным шахматным победам компьютеров (знаменитый Deep Blue), под названием Watson совершило новый прорыв, с большим отрывом победив сразу двух чемпионов популярной американской викторины Jeopardy. Показательно, однако, что хотя Watson самостоятельно озвучивал ответы, вопросы ему все же передавались в текстовом виде. Это говорит о том, что успехи во многих сферах приложения ИИ — распознавании речи и образов, машинном переводе — достаточно скромны, хотя это и не мешает нам уже сегодня применять их на практике. Наибольшие же успехи, пожалуй, демонстрируют системы оптического распознавания символов (OCR, Optical Character Recognition), с которыми наверняка так или иначе знакомы почти все пользователи ПК. Тем более, что российские разработки в данной области занимают достойное место в мире — я имею в виду ABBYY FineReader.
Немного истории
Базовые принципы
- Целостность (integrity) — объект рассматривается как совокупность своих частей и (для зрительных образов) пространственных отношений между ними. В свою очередь и части получают толкования только в составе всего объекта. Этот принцип помогает строить и уточнять гипотезы, быстро отсекая маловероятные.
- Целенаправленность (purposefulness) — поскольку любая интерпретация данных преследует определенную цель, то и распознавание представляет собой процесс выдвижения гипотез об объекте и целенаправленной их проверки. Система, действующая в соответствии с этим принципом, будет не только экономнее расходовать вычислительные мощности, но и реже ошибаться.
- Адаптивность (adaptability) — система сохраняет накопленную в процессе работы информацию и использует ее повторно, т. е. самообучается. Этот принцип позволяет создавать и накапливать новые знания и избегать повторного решения одних и тех же задач.
FineReader — единственная в мире OCR-система, которая действует в соответствии с вышеописанными принципами на всех этапах обработки документа. Соответствующая технология носит название IPA — по первым буквам английских терминов. К примеру, согласно принципу целостности, фрагмент изображения будет интерпретироваться как символ, только если в нем присутствуют все структурные части подобных объектов, причем находящиеся в определенных взаимоотношениях. Это помогает заменить перебор большого числа эталонов (в поисках более-менее подходящего) целенаправленной проверкой разумного количества гипотез, причем опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Однако принципы IPA применяются при анализе не только фрагментов, соответствующих (предположительно) отдельным символам, но и всего исходного изображения страницы. Большинство OCR-систем основываются на распознавании иерархической структуры документа, т. е. страница разбивается на основные структурные элементы, такие как таблицы, изображения, блоки текста, которые, в свою очередь, разделяются на другие характерные объекты — ячейки, абзацы — и так далее, вплоть до отдельных символов.
Такой анализ может проводиться двумя основными способами: сверху-вниз, т. е. от составных элементов к отдельным символам, или, наоборот, снизу-вверх. Чаще всего применяется один из них, но в ABBYY разработали специальный алгоритм MDA (multilevel document analysis, многоуровневый анализ документа), который сочетает оба. Вкратце он выглядит следующим образом: структура страницы анализируется методом сверху-вниз, а воссоздание электронного документа по окончании распознавания происходит снизу-вверх, однако на всех уровнях дополнительно действует механизм обратной связи. В результате резко снижается вероятность грубых ошибок, связанных с неверным распознаванием высокоуровневых объектов.
- основной текст;
- верхние и нижние колонтитулы;
- номера страниц;
- заголовки одного уровня;
- оглавление;
- текстовые вставки;
- подписи к рисункам;
- таблицы;
- сноски;
- зоны подписи/печати;
- шрифты и стили.
Процесс распознавания
Но наиболее интересное, конечно, начинается, когда процесс распознавания опускается на самые нижние уровни. Так называемая процедура линейного деления разбивает строки на слова, а слова на отдельные буквы; далее, в соответствии с принципом IPA, формирует набор гипотез (т. е. возможных вариантов того, что́ это за символ, на какие символы разбито слово и т. д.) и, снабдив каждую оценкой вероятности, передает на вход механизма распознавания символов.
Последний состоит из ряда так называемых классификаторов, каждый из которых также формирует ряд гипотез, ранжированных по предполагаемой степени вероятности. Важнейшей характеристикой любого классификатора является среднее положение правильной гипотезы. Понятно, что чем выше она находится, тем меньше работы для последующих алгоритмов — к примеру, словарной проверки. Но для достаточно отлаженных классификаторов чаще всего оценивают такие характеристики, как точность распознавания по первым трем гипотезам или только по первой — т. е., грубо говоря, способность угадать верный ответ с трех или с одной попытки. ABBYY в своих системах применяет следующие типы классификаторов: растровый, признаковый, признаковый дифференциальный, контурный, структурный и структурный дифференциальный — которые сгруппированы на двух логических уровнях.
Принцип действия РК, или растрового классификатора, основан на попиксельном сравнении изображения символа с эталонами. Последние формируются в результате усреднения изображений из обучающей выборки и приводятся к некой стандартной форме; соответственно, для распознаваемого изображения также предварительно нормализуются размер, толщина элементов, наклон. Этот классификатор отличается простотой реализации, скоростью работы и устойчивостью к дефектам изображений, но обеспечивает сравнительно низкую точность и именно поэтому используется на первом этапе — для быстрого порождения списка гипотез.
Признаковый классификатор (ПК), как и следует из его названия, основывается на наличии в изображении признаков того или иного символа. Если всего таких признаков N, то каждую гипотезу можно представить точкой в N-мерном пространстве; соответственно, точность гипотезы будет оцениваться расстоянием от нее до точки, соответствующей эталону (который также нарабатывается на обучающей выборке).
Понятно, что типы и количество признаков в значительной степени определяют качество распознавания, поэтому обычно их достаточно много. Этот классификатор также сравнительно быстр и прост, но не слишком устойчив к различным дефектам изображения. Кроме того, ПК оперирует не исходным изображением, а некой моделью, абстракцией, т. е. не учитывает часть информации: скажем, сам факт наличия каких-то важных элементов ничего не говорит об их взаимном расположении. По этой причине ПК используется не вместо, а вместе с РК.
Контурный классификатор (КК) представляет собой частный случай ПК и отличается тем, что анализирует контуры предполагаемого символа, выделенные из исходного изображения. В общем случае его точность ниже, чем у полновесного ПК.
Сам по себе ПДК не выдвигает гипотез, а лишь уточняет имеющиеся (список которых в общем случае сортируется пузырьковым методом), так что прямая оценка его эффективности не проводится, а косвенно ее приравнивают к характеристикам всего первого уровня OCR-распознавания. Однако понятно, что она зависит от корректности подобранных признаков и представительности выборки эталонов, обеспечение чего является достаточно трудоемкой задачей.
Качественные характеристики всех классификаторов собраны в следующую таблицу. Они, впрочем, позволяют лишь оценить эффективность алгоритмов друг относительно друга, т. к. не являются абсолютными, а получены на основе обработки конкретной тестовой выборки. Может создаться впечатление, что на последних этапах распознавания борьба идет буквально за доли процента, но на самом деле каждый классификатор вносит существенную лепту в повышение точности распознавания — так, к примеру, СК снижает количество ошибок на ощутимые 20%.
| РК | ПК | КК | ПДК* | СДК** | СК** | |
| Точность по первым трем вариантам, % | 99,29 | 99,81 | 99,30 | 99,87 | 99,88 | — |
| Точность по первому варианту, % | 97,57 | 99,13 | 95,10 | 99,26 | 99,69 | 99,73 |
* оценка всего первого уровня OCR-алгоритма ABBYY
** оценка для всего алгоритма после добавления соответствующего классификатора
Любопытно, однако, что, несмотря на довольно высокую точность, алгоритм собственно распознавания не принимает окончательного решения. В соответствии с принципом MDA, гипотезы выдвигаются на каждом логическом уровне, и число их может расти в геометрической прогрессии. Соответственно, последовательная проверка всех гипотез вряд ли окажется эффективной, и потому в OCR-системах ABBYY применяется метод структурирования гипотез, т. е. отнесения их к тем или иным моделям. Последних существует пара десятков, вот только несколько их типов: словарное слово, несловарное слово, арабские цифры, римские цифры, URL, регулярное выражение — а в каждый может входить множество конкретных моделей (к примеру, слово на одном из известных языков, латиницей, кириллицей и т. д.).
Не только OCR
Печатные документы — далеко не единственные, представляющие интерес с точки зрения их оцифровки и автоматической обработки. Довольно часто приходится работать с формами, т. е. документами с предопределенными и фиксированными полями, которые заполняются вручную, но сравнительно аккуратно (так называемыми рукопечатными символами) — примером могут служить различные анкеты. Технология их обработки имеет отдельное название — ICR (intelligent character recognition) — и достаточно существенно отличается от OCR. Так, поскольку в данном случае задача состоит не в воссоздании всего документа, а в извлечении из него конкретных данных, то она распадается на две основные подзадачи: нахождение нужных полей и собственно распознавание их содержимого.
Это достаточно специфическая область, и ABBYY предлагает для нее совершенно отдельный программный продукт ABBYY FlexiCapture. Он предназначен для создания автоматизированных и полуавтоматизированных систем, предполагает настройку на конкретные типы документов, для которых создаются специальные шаблоны, умеет интеллектуально находить на страницах различные поля и верифицировать данные в них и т. д. Однако в самой основе лежат алгоритмы распознавания символов, аналогичные тем, что применяются в FineReader, да и общая схема весьма похожа:

Впрочем, важное отличие все же имеется: структурный классификатор является обязательным участником процесса — это связано со спецификой рукопечатных символов. Кроме того, ICR предполагает большое число специфических дополнительных проверок: например, не является ли символ зачеркнутым, или действительно ли распознанные символы формируют дату.
Один из популярнейших функционалов по работе со сканированием и обработкой файлов различного типа — Файн Ридер. Функционал программного продукта был разработан российской компанией ABBYY, он позволяет не только распознавать, но и обрабатывать документы (переводить, менять форматы и другое). Многие пользователи могут только установить, а как пользоваться ABBYY FineReader, сразу разобраться не могут. На многие вопросы вы сможете найти ответы в этой статье.

Программа позволяет сканировать и распознавать текст — и не только
Что представляет собой приложение от ABBYY?
Чтобы подробно разобраться, что это за программа ABBYY FineReader 12, необходимо подробно рассмотреть все её возможности. Первой и самой простой функцией является сканирование документа. Существует два варианта сканирования: с распознаванием и без него. В случае обычного сканирования печатного листа вы получите изображение, которое сканировали в указанной папке на вашем компьютерном устройстве.
ВНИМАНИЕ. Лист нужно класть на сканирующую часть принтера ровно, по указанным на принтере контурам. Не допускайте заламывания исходника, это может привести к плохому качеству итогового скана.

Поместите документ в сканер для того, чтобы перевести его в электронный вид
Вы должны самостоятельно решить, для чего нужен FineReader именно вам, так как утилита имеет значительный функционал, например, вы можете самостоятельно выбрать в каком цвете хотите получить изображение, есть возможность перевести все фото в чёрно-белый. В чёрно-белом цвете распознавание происходит быстрее, качество обработки возрастает.
Если же вас интересует функция распознавания текста ABBYY FineReader, перед сканированием вам нужно нажать специальную кнопку. В этом случае есть несколько вариантов получения информации. Стандартно на ваш экран выведется распознанный кусок листа, который вы сможете скопировать или отредактировать вручную.
Если вы выберите другие функции, то сможете сразу получить файл Word-документом или Excel-таблицей. Выбирать функции очень просто, меню интуитивно понятно, легко настраивается благодаря тому, что все нужные вам кнопки перед глазами.
ВАЖНО. Перед тем как распознать текст ABBYY FineReader, вам необходимо точно подобрать язык обработки. Несмотря на то, что утилита работает полностью автоматически, бывает, что низкое качество исходника не позволяет понять, что за язык был в исходнике. Это сильно снижает качество итоговых результатов работы приложения.
Несколько режимов работы
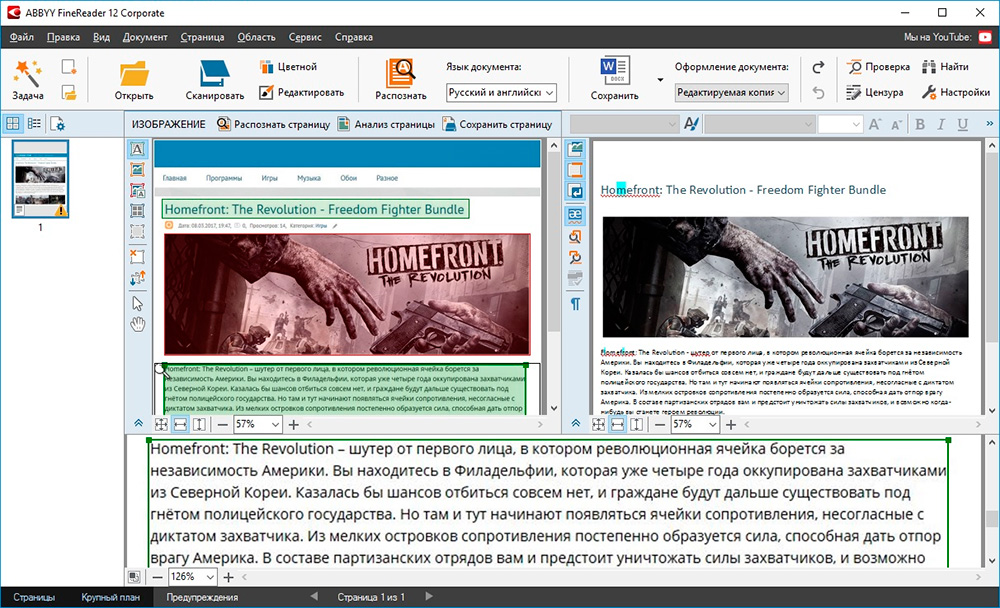
На иллюстрации показан результат работы программы — распознавание текста с изображения
Какие ещё есть функции?
Распознавание текста в программе ABBYY FineReader не единственная полезная функция. Для большего удобства пользователей имеется возможность переводить документ в необходимые пользователю форматы (pdf, doc, xls и др.).
Изменение текста
Теперь вы знаете, для каких целей служит программа FineReader, и сможете правильно её применять у себя дома или в офисе. Функционал приложения огромен, воспользуйтесь им и вы сможете убедиться в незаменимости этого программного продукта при обработке документов и файлов во время офисной работы.
Выполняйте различные задачи в одной программе. Повысьте эффективность за счет уменьшения количества используемых программ и предотвращения необходимости выполнять одну и ту же работу дважды. Наслаждайтесь простым и понятным интерфейсом и высококачественными результатами.
Источник: obrazovanie-gid.ru