
Только сегодня: 300 рублей в подарок на первый заказ.
Какую работу нужно написать?
Другую работу
Помощник Анна
Кратко о том, как совершить основные действия в программеStatistica6.0Подготовка данных к обработке Все данные должны быть представлены в виде таблицы. Каждая строка таблицы – один участник исследования.
То есть, если всего обследованы, например, 42 человека (и экспериментальная, и контрольная группа вместе), то таблица содержит 42 строки плюс заголовки. (В примере, о котором пойдет речь дальше, 78 участников исследования) Каждый столбец таблицы – переменная. При подготовке данных переменной будем считать любую информацию об участнике исследования.
Например, первой переменной – первым столбиком таблицы – может стать порядковый номер или даже какое-то уникальное имя испытуемого. Само по себе имя в исследовании НЕ требуется. Оно может пригодиться только для того, чтобы точно и аккуратно внести всю информацию по этому конкретному человеку.
Логистическая регрессия в программе Statistica
Следующей переменной может являться тип группы – экспериментальная или контрольная. Можно так и назвать переменную – «группа». Для всех участников исследования надо заполнить эту переменную. Обратите внимание: для всех участников ОДНОЙ группы следует использовать ОДНО И ТО ЖЕ обозначение. Например, эксп.г. – для всех участников экспериментальной группы, контр.г.
– для всех участников контрольной группы. Далее можно указать пол участников исследования. В файле с примером данных первой переменной является пол (Pol). Следующей переменной является возраст (Age). Здесь просто указан возраст в годах. Далее следует переменная Edu – уровень образования.
Эта переменная может принимать только 3 значения – «средне-спец.», «высшее», «неполное высшее». Далее указан стаж в годах. Следующая переменная – семейное положение, тоже может принимать несколько значений. В этом примере первые шесть переменных содержат общую социально-демографическую информацию; это еще не методики. Далее идут методики.
Переменная номер 7 – Результат методики «Уровень профессионального стресса», может принимать значения от 0 до 60. Переменная 8 – уровни проф.стресса, рассчитанные по данным методики. Следующие три переменные – №9, 10, 11 – соответствуют трем шкалам методики Маслач (название шкал сейчас нам не важны).
Каждая из них может принимать значения от 0 до определенного уровня, сейчас это не важно. Переменные 12, 13 и 14 – оценки компонентов социально-психологического климата: эмоциональный, когнитивный и поведенческий компоненты. Рассчитываются по методике. Могут принимать только три значения -1, 0, 1. Итого в нашем примере получаем 14 переменных.
Обращаю Ваше внимание на то, что переменные бывают разные. Нас будет интересовать в первую очередь разделение переменных на метрические и номинативные.
Метрические переменные – например, возраст, показатели по шкале интеллекта, и др. – могут принимать разные значение в определенном диапазоне, причем большее или меньшее значение соответствует большему или меньшему уровню измеряемого признака. Номинативные переменные могут принимать фиксированное число значений. Например, переменная «пол».
Ввод данных STATISTICA #01 | СТАТИСТИКА STATISTICA
Может принимать два значение – М или Ж. Переменная «уровень образования»: может принимать три значения – средне-спец., высшее, неполное высшее. Переменная «тип группы» – тоже номинативная, она задает принадлежность участника к экспериментальной или к контрольной группе. Вопрос: определите, какие переменные из Вашего исследования являются метрическими, какие – номинативными.
Это крайне важно для выбора методов исследования. Результатом данного этапа работы является таблица с данными (составленная на бумаге или – лучше – в программе Excel), плюс понимание, какие переменные являются метрические, какие – номинативными.
Создание нового файла в программеStatistica6.0 Откройте программу и выберите в верхнем меню File – New. (Рекомендую пользоваться английской версией программы) 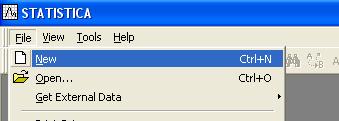 Появится окно, в котором можно выбрать необходимое количество переменных (Number of Variables) и количество наблюдений (Number of Cases). В нашем примере будет 14 переменных и 78 наблюдений.
Появится окно, в котором можно выбрать необходимое количество переменных (Number of Variables) и количество наблюдений (Number of Cases). В нашем примере будет 14 переменных и 78 наблюдений.
Нажмите ОК. 
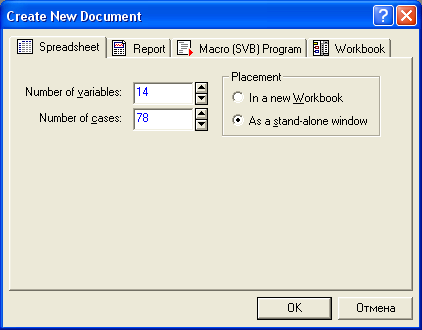 Получим чистый файл, в который можно вносить результаты исследования. Возможно, этот лист будет виден не полностью, поэтому снизу и справа есть полосы прокрутки. Результатом данного этапа является чистый лист, на который можно вносить результаты исследования.
Получим чистый файл, в который можно вносить результаты исследования. Возможно, этот лист будет виден не полностью, поэтому снизу и справа есть полосы прокрутки. Результатом данного этапа является чистый лист, на который можно вносить результаты исследования.
Пример такого листа ниже.  Ввод данных Если Вы создавали таблицу данных в программе Excel, то можно будет скопировать данные оттуда в статистику. (Вообще говоря, программа Statistica поддерживает импорт данных из Excel, но для этого нужно очень правильно организовать данные и очень правильно выполнять сам импорт. Можно наделать ошибок.
Ввод данных Если Вы создавали таблицу данных в программе Excel, то можно будет скопировать данные оттуда в статистику. (Вообще говоря, программа Statistica поддерживает импорт данных из Excel, но для этого нужно очень правильно организовать данные и очень правильно выполнять сам импорт. Можно наделать ошибок.
Поэтому предлагаю переносить данные «вручную».) Как создать названия переменных При создании нового файла все переменные в нем уже подписаны и называются Var1, Var2, Var3 и т.д. Чтобы работать было удобнее, нужно их переименовать. Для этого на заголовках переменных щелкните дважды левой кнопкой мышки (обозначение – 2ЛКМ). Откроется окно.
В нём щелкните на кнопку «All Specs…», как показано на рисунке. 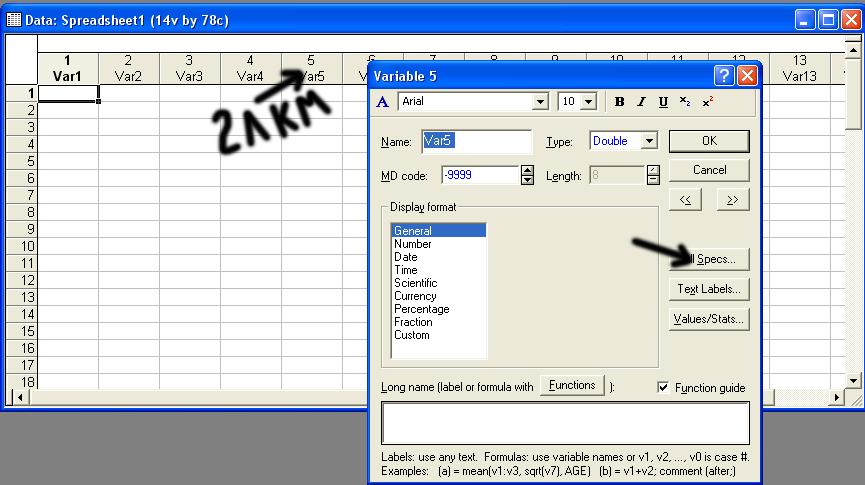 Откроется окно, в котором можно подписать все переменные.
Откроется окно, в котором можно подписать все переменные. 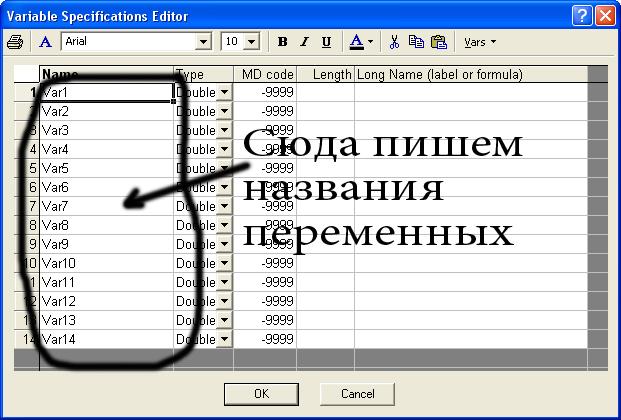 После этого нажмите ОК. Названия переменных, которые Вы напишете, появятся вместо Var1 и т.д. Нумерация переменных останется, и это нормально.
После этого нажмите ОК. Названия переменных, которые Вы напишете, появятся вместо Var1 и т.д. Нумерация переменных останется, и это нормально.
Далее нужно заполнить данными всю таблицу. Если Вы уже вносили данные в программу Excel, то можно там выделить диапазон с данными (без какой-либо нумерации и без названий переменных), копировать, и вставить в программу Statistica. После этого желательно сохранить файл с данными: меню File – Save As…, далее укажите, куда следует поместить данный файл и как назвать.
Тип файла программа пишет автоматически. Для сохранения нажмите кнопку «Сохранить». После сохранения файла его название появляется на экране, на синем фоне в строке заголовка. Это выглядит примерно так: 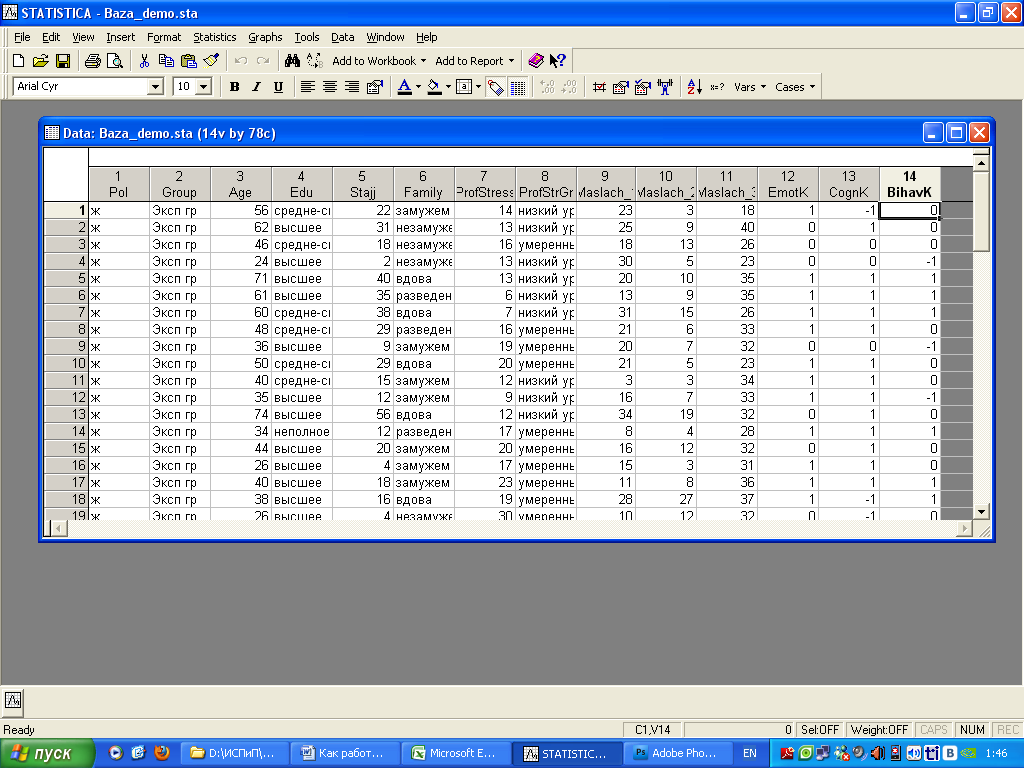
- №3 –Age – возраст
- №5 – Stajj – стаж работы
- №7 – ProfStress – показатель профессионального стресса
- №9 – Maslach_1 – первый показатель методики Маслач
- №10 – Maslach_2 – второй показатель методики Маслач
- №11 – Maslach_3 – третий показатель методики Маслач
Переменная «Пол» делит всех участников на две группы – мужчины и женщины. Переменная «Group» делит всех участников на две группы – экспериментальная группа и контрольная группа.
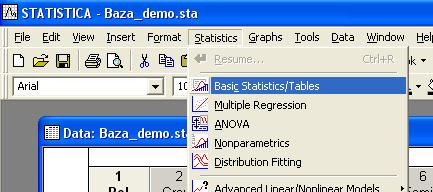
Соответственно, в нашем примере с помощью Т-критерия Стьюдента можно проверить, 1) отличаются ли средние значения перечисленных выше переменных у мужчин и женщин; 2) отличаются ли средние значения перечисленных выше переменных у участников экспериментальной и контрольной группы. В верхнем меню выберите пункт Statistics – в нём Basic Statistics/Tables.
 Далее как на рисунке – t-test, independent, by groups. Это критерий Стьюдента.
Далее как на рисунке – t-test, independent, by groups. Это критерий Стьюдента. 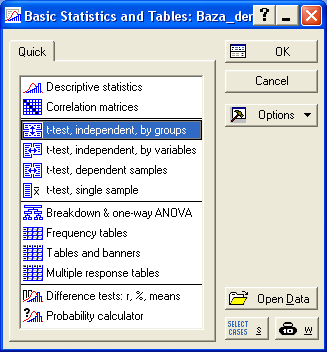 выберите, нажмите ОК. Появляется окошко с настройками. Прежде всего, нужно выбрать переменные, для которых хотим провести расчет.
выберите, нажмите ОК. Появляется окошко с настройками. Прежде всего, нужно выбрать переменные, для которых хотим провести расчет.
Для этого щелкните кнопку Variables как показано на рисунке: 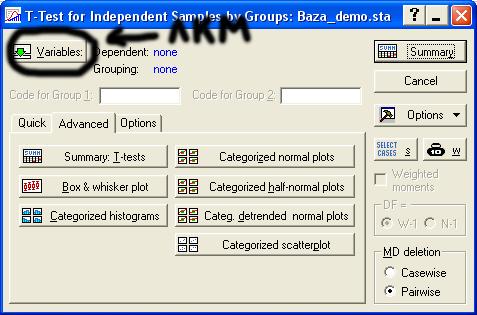 Появляется окно выбора переменных.
Появляется окно выбора переменных. 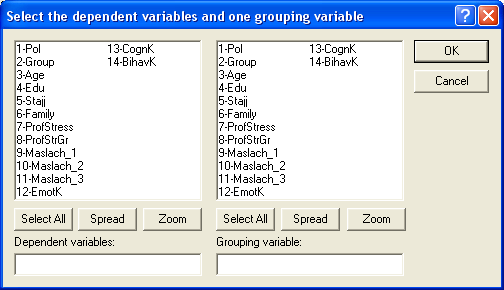 Здесь в левой части – Dependent variables – нужно указать те метрические переменные, средние значения которых хотим сравнить. Например, это переменные 3, 5, 7, 9-11 (возраст, стаж, стресс, и т.д.).
Здесь в левой части – Dependent variables – нужно указать те метрические переменные, средние значения которых хотим сравнить. Например, это переменные 3, 5, 7, 9-11 (возраст, стаж, стресс, и т.д.).
Можно выбрать переменные из списка или в пустом окне напечатать номера. В правой части – Grouping variable – указываем ОДНУ переменную, которая делит нашу выборку на две группы. Например, можно выбрать переменную 1-Pol, тогда будем сравнивать показатели мужчин и женщин. Либо можно здесь выбрать переменную 2-Group, тогда будем сравнивать экспериментальную и контрольную группы.
Если нас интересуют оба варианта, то придется дважды применять Т-критерий. Но за один раз выбирается только одна переменная в правой части окна. Сейчас рассмотрим пример с переменной 1-Pol. Это будет выглядеть так: 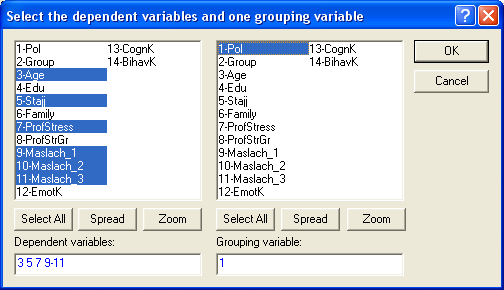
Для выполнения расчетов нужно нажать кнопку Summary, одну из двух, они показаны на картинке. 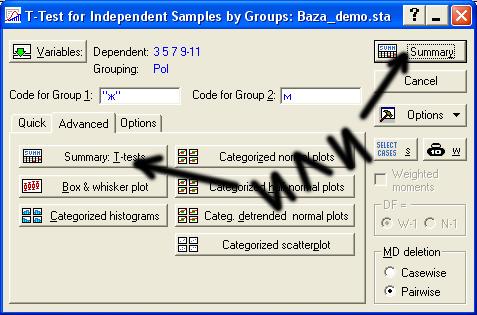 На экране появится еще одно окно – Workbook1. В этот файл программа будет записывать все результаты вычислений.
На экране появится еще одно окно – Workbook1. В этот файл программа будет записывать все результаты вычислений. 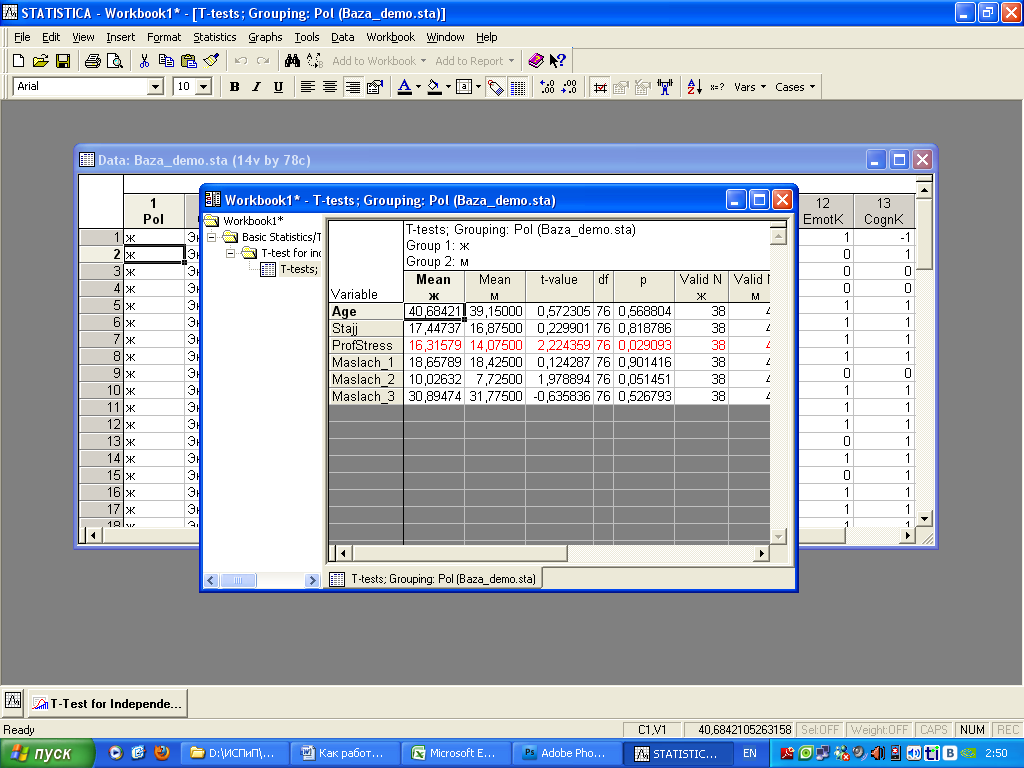 Рассмотрим подробно полученные результаты.
Рассмотрим подробно полученные результаты.
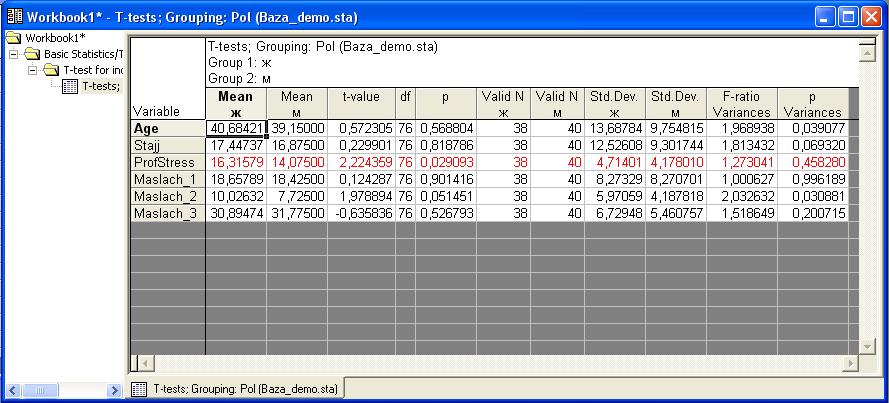 В таблице слева на сером фоне перечислены переменные, средние значения которых мы сравнивали. Столбцы «Mean ж» и «Mean м» содержат средние значения переменных для женщин и мужчин соответственно. То есть, средний возраст женщин составляет 40,68, средний возраст мужчин – 39,15 лет. Средний стаж женщин 17,44, мужчин – 16,87 лет.
В таблице слева на сером фоне перечислены переменные, средние значения которых мы сравнивали. Столбцы «Mean ж» и «Mean м» содержат средние значения переменных для женщин и мужчин соответственно. То есть, средний возраст женщин составляет 40,68, средний возраст мужчин – 39,15 лет. Средний стаж женщин 17,44, мужчин – 16,87 лет.
Далее столбец t-value содержит значение t-критерия, нам оно не надо. Столбец df обозначает количество степеней свободы, нам тоже это не надо. (То есть, приводя в работе результаты статистической обработки данных, неплохо бы эти цифры указать, но расшифровывать не надо). Следующий столбец –p – нужен обязательно. Это то самый уровень достоверности различий средних значений.
Наверное, самый важный столбик из этой таблицы. Теоретическое отступление. Чтобы проверить, различаются ли средние значения в двух группах, сначала мы рассчитываем эти значения. И почти всегда средние значения в двух группах будут хоть сколько-нибудь отличаться. То есть, мы почти всегда получаем НЕ ОДИНАКОВЫЕ средние значения.
В нашем примере то же самое – средние значения для женщин и мужчин по всем переменным разные. Но где-то они отличаются больше, где-то – меньше. И «на глаз» мы не можем определить, отличаются ли средние значения «чуть-чуть» или «сильно». Определить это можно только с помощью статистических критериев, например, по t-критерию Стьюдента.
Не вдаваясь в подробности расчетов, предлагаю запомнить: Средние значения в двух группах по какой-либо переменной достоверно отличаются, если показатель p(в программе эти переменные выделены красным цветом) В этом случае говорят также, что различия средних значений являются достоверными (или – статистически значимыми) на 5% уровне. Иногда, если p больше 0,05, но меньше, чем 0,1, то говорят, что различия есть на уровне статистической тенденции.
То есть, это менее выраженные различия. Но обычно если р>0,05, то говорят, что достоверных различий не выявлено /не установлено /не обнаружено. Но ДАЖЕ ЕСЛИ p>0,1, НЕЛЬЗЯ ГОВОРИТЬ, ЧТО СРЕДНИЕ ЗНАЧЕНИЯ ОДИНАКОВЫЕ. Таким образом, в данном случае для мужчин и женщин достоверно отличаются только показатели профессионального стресса (значение р=0,029, это меньше, чем 0,05).
На уровне тенденции есть различия по показателю Маслач_2 (здесь р=0,051, это больше, чем 0,05, но меньше, чем 0,1). Для других переменных достоверных отличий не выявлено. Теперь рассмотрим сравнение средних значений в экспериментальной и контрольной группе. Снова в верхнем меню выберите пункт Statistics – в нём Basic Statistics/Tables.
Поскольку мы уже запустили этот модуль программы, то на экране появится окно 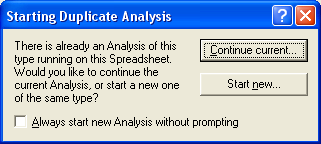 Можно выбрать «Continue current», чтобы продолжить расчет. Чтобы перейти к сравнению экспериментальной и контрольной группы, щелкните кнопку Variable. В правой части окна – Grouping variable – выберите переменную номер 2. Нажмите ОК. Нажмите Summary, как на картинках выше.
Можно выбрать «Continue current», чтобы продолжить расчет. Чтобы перейти к сравнению экспериментальной и контрольной группы, щелкните кнопку Variable. В правой части окна – Grouping variable – выберите переменную номер 2. Нажмите ОК. Нажмите Summary, как на картинках выше.
Получим такой результат. 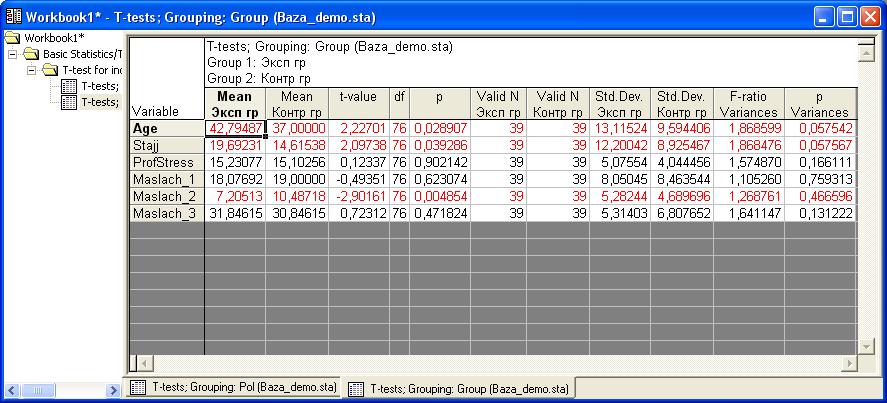 Обратите внимание, что для участников экспериментальной и контрольной группы достоверно отличается средний возраст, средний стаж и средние значения по показателю Маслач_2. По другим переменным достоверных отличий не выявлено. Как закрыть программу.
Обратите внимание, что для участников экспериментальной и контрольной группы достоверно отличается средний возраст, средний стаж и средние значения по показателю Маслач_2. По другим переменным достоверных отличий не выявлено. Как закрыть программу.
 Сначала надо закрыть все расчеты. Для этого в нижнем левом углу щелкните на прямоугольник, откроется окно расчетов, закрывайте его крестиком или кнопкой Cancel. Вторым шагом закрывайте окно Workbook1 – тоже крестиком. Этот файл можно сохранить, но это не обязательно. Третий шаг – закрывайте файл с данными.
Сначала надо закрыть все расчеты. Для этого в нижнем левом углу щелкните на прямоугольник, откроется окно расчетов, закрывайте его крестиком или кнопкой Cancel. Вторым шагом закрывайте окно Workbook1 – тоже крестиком. Этот файл можно сохранить, но это не обязательно. Третий шаг – закрывайте файл с данными.
Четвертое – закрывайте программу. Позже допишу: Сравнение средних значений в двух группах – непараметрический метод. Сравнение средних значений в трех и более группах – дисперсионный анализ Анализ таблиц сопряженности – Хи-квадрат.
| Любят мороженое | Не любят мороженое | |
| М | 10 | 20 |
| Д | 19 | 11 |
По критерию Хи-квадрат здесь получим, что достоверно отличается распределение по признаку «любят/не любят мороженое» среди мальчиков и девочек. То ест, они «по-разному» относятся к мороженому.
| Любят ирать в комп | Не любят играть в комп | |
| М | 16 | 14 |
| Д | 15 | 15 |
Здесь по Хи-квадрату получим, что достоверных различий не обнаружено. То есть мальчики и девочки «не отличаются» по любви/не любви к комп играм. Проверяем, отличатся ли уровень образования участников экспериментальной и контрольной группы. 
 Коэффициенты корреляции. Перенос результатов в Excel 11
Коэффициенты корреляции. Перенос результатов в Excel 11
Ограничение
Для продолжения скачивания необходимо пройти капчу:
Источник: studfile.net
Statistica 6.0 скачать бесплатно

Statistica 6.0 – многофункциональное программное обеспечение, качественно осуществляющее статистический анализ данных. Утилита позволяет пользователям строить разнообразные графики и уравнения множественной регрессии, производить дисперсионный, ковариационный, корреляционный анализ, оценку критериев Стьюдента, Фишера, обладает вероятностным калькулятором.
Софт имеет открытый исходный код, который дает возможность пользователям добавлять собственные операции. Программа найдет свое применение в разнообразных сферах жизни: промышленность, финансы, образование. Статистика – современное приложение, которое быстро решит задачи из области математики и статистики, обработает большие массивы данных.
Советуем Statistica 6.0 скачать бесплатно с официального сайта без регистрации, смс, вирусов и рекламы.
Отзывы пользователей
Новые программы
- Comodo Dragon
- Total Doc Converter
- Process Explorer
- RealPlayer
- Adobe Captivate
- PDF2Word
- Norton
- SMPlayer
- GPU-Z
- ACDSee
- Браузеры
- Антивирусы
- Графические редакторы
- Программы для общения
- Архиваторы
- Плееры
- Образы и запись дисков
- Загрузка файлов
- Файловые менеджеры
- Текстовые редакторы
- Аудио и видео обработка
- Системные программы
- PowerISO для Windows 8.1
- Mouse Recorder 2
- Scratch для Windows 8
- PhotoZoom Pro 6
- FlashBoot 2.3
- Google Earth Portable
- DAEMON Tools Ultra 2
- Opera 27
- SPSS 64 bit
- Pidgin для Windows 10
- Torch Browser 64 bit
- RealTime Landscaping Architect 2014
- Adobe Premiere Pro CC 2015
- DAEMON Tools Ultra 5
- Adobe After Effects 6.5.1
Источник: moiprogrammy.com
ППП Statistica 6.0
1. Загрузка ППП Statistica 6.0: Пуск – Программы – STATISTICA6.0 STATISTICA Слайд 1 2. Ввод данных 2.1. Настройка таблицы Для создания базы данных в Statistica необходимо увеличить число строк (Cases) и столбцов (Vars) до нужного количества, то есть настроить таблицу Слайд 2 Слайд 3 В нашем примере 7 переменных (показателей) и 20 наблюдений (регионов).
Добавим необходимое количество ячеек таблицы кнопка VARS – команда ADD. Добавить число переменны х (показателей). Слайд 4 кнопка CASES – команда ADD. Добавить число наблю дений (регионов) Слайд 5 Двойным щелчком по названию переменной вызвать окноVariable 1. Ввести имена переменных Слайд 6 Слайд 7 С помощью контекстного меню Case определить длину названия регионов.
В поле Case name length выставить, например, 35. OK. Строки будут готовы для ввода названия регионов. Двойным щелчком по названию строки входим в режим Слайд 8 редактирования и вводим название региона, например, Калмыкия. По Enter переходим к следующей строке.
Слайд 9 После ввода имен переменных и названия регионов получим таблицу: Операцией копирования через буфер обмена Слайд 10 скопируем данные из таблицы Excel в Statistica командой Edit – Paste: Командой File – Save As сохраним данные в файл primer 2003. Настройка таблицы окончена Слайд 11 2.2.
Разведочный анализ Слайд 12 Основные этапы разведочного анализа: Получение описательных статистик и исследование степени однородности рассматриваемых социально-экономических процессов; Выявление «выбросов» и исключение их из совокупности данных; Анализ на соответствие распределения совокупности эмпирических данных нормальному закону. Загрузка модуля Основные статистики: Слайд 13 пункт меню Statistics — Basic Statistics / Tables Выбираем пункт Описательные статистики – Слайд 14 Descriptive Statistics.
Получаем окно: Назначаем переменные для получения статистических характеристик (кнопка Variable – Select All): Слайд 15 В окне Descriptive statistics закладка Advanced можно назначить вывод необходимых статистик Слайд 16 После нажатия кнопки Summary Descriptive statistics получаем результат: Слайд 17 Слайд 18 Полученную таблицу скопируем в Excel (выделить таблицу, команда Edit – Copy). Определим степень однородности рассматриваемых совокупностей с помощью коэффициента вариации: коэффициент вариации V=σ/Xср. • 100% Слайд 19 В результате расчета 3 из 7 совокупностей неоднородны (Y, X2, X3): Descriptive Statistics (primer 2003.sta) Y X1 X2 X3 X4 X5 X6 N 20 20 20 20 20 20 20 mean 46,95 2577,50 5,34 424,50 61,60 9890,00 10940,00 min 13,000 900,000 1,500 100,000 45,000 7100,000 6000,000 max 76,00 3900,00 19,00 750,00 79,00 15000,00 18900,00 Std.Dev 17,837 805,324 4,337 197,630 9,714 2299,634 3172,480 V 37,99128 31,24437 81,29831 46,55596 15,76915 23,25211 28,99891 Слайд 20 В неоднородных совокупностях определим визуально с помощью 2D графиков наличие выбросов. Командой Graphs – 2D Graphs – Line Plots Variable загружаем окно: Кнопкой Variable назначаем переменные, для которых построим графики, например X3: Слайд 21 Слайд 22 подозрение на «выброс» 900 -1 0 0 Áåëãî ðî ä Áðÿí ñêàÿ Âëàäèì èð Âî ðî í åæñ Èâàí î âñê Êàëóæñêà Êî ñòðî ì ñ Êóðñêàÿ Ëèï åöêàÿ Ì î ñêî âñê Î ðëî âñêà Ðÿçàí ñêà Ñì î ëåí ñê Òàì áî âñê Òâåðñêàÿ Òóëüñêàÿ ßðî ñëàâñ ã. Ì î ñêâ Êàðåëèÿ Êî ì è Àðõàí ãåë Âî ëî ãî äñ Êàëèí èí ã Ëåí èí ãðà Ì óðì àí ñê Í î âãî ðî ä Ï ñêî âñêà ã. Ñàí êò Àäû ãåÿ Äàãåñòàí Èí ãóø åòè × å÷åí ñêà Êàáàðäèí Êàëì û êèÿ Êàðà÷àåâ Ñåâåðí àÿ Êðàñí î äà Ñòàâðî ï î Àñòðàõàí Âî ëãî ãðà Ðî ñòî âñê Áàø êî ðòî Ì àðèé Ýë Ì î ðäî âèÿ Òàòàðñòà Óäì óðòñê × óâàø ñêà Êèðî âñêà Í èæåãî ðî Î ðåí áóðã Ï åí çåí ñê Ï åðì ñêàÿ Ñàì àðñêà Ñàðàòî âñ Óëüÿí î âñ Êóðãàí ñê Ñâåðäëî â Òþ ì åí ñêà × åëÿáèí ñ Àëòàé Áóðÿòèÿ Òû âà Õàêàñèÿ Àëòàéñêè Êðàñí î ÿð Èðêóòñêà Êåì åðî âñ Í î âî ñèáè Î ì ñêàÿ î Òî ì ñêàÿ × èòèí ñêà Ñàõà (ßê Ï ðèì î ðñê Õàáàðî âñ Àì óðñêàÿ Êàì ÷àòñê Ì àãàäàí ñ Ñàõàëèí ñ Åâðåéñêà × óêî òñêè X1 Правило Х ср-4 Х ср+4 Слайд 23 D a ta : B a s e 1 .S T A 3 5 v * 8 0 c Òþ ì å í ñ êà 700 500 Х ср 300 100 Слайд 23 3. Определение степени близости эмпирических распределений нормальному закону осуществляется в модуле Подгонка распределений (Distribution Fitting) командой Statistics — Distribution Fitting Слайд 24 Появится окно, в котором необходимо выбрать закон распределения (Normal). OK Слайд 25 ПО кнопке ОК появится окно, в котором необходимо выбрать переменную (кнопка Variable), например Х1: Кнопкой Plot of observed end expected distribution, получим гистограмму: Слайд 26 Перем-я X1 ; распределение:Нормальное статистика Колм-См. d =,0349582, p = н.з. хи-квадрат: 1,467318, сс = 2, p = ,4801570 (ст.св. скор.) 26 24 22 20 18 N набл. 16 14 12 10 8 6 4 2 30,00 38,75 47,50 56,25 65,00 Группа (верх. границы) 73,75 82,50 91,25 100,00 Ожидаемые Слайд 27 Хи-квадрат достаточно мал ( 1,47) следовательно эмпирическое распределение соответствует нормальному закону f ( x) 1 2 ( x x )2 2 2 e
В закладки
Разместил пособие
ladova.2022
Эксперт по предмету «Информационные технологии»
Поделись лекцией и получи скидку 30% на платформе Автор24
Заполни поля и прикрепи лекцию. Мы вышлем промокод со скидкой тебе на почту
Твоя лекция отправлена! Жди скидку на почте. Есть еще материалы? Загрузи прямо сейчас
Загрузить еще лекции
Поделись лекцией и получи промокод на скидку 30% на платформе Автор24
Заполни поля и прикрепи лекцию. Мы вышлем промокод со скидкой тебе на почту
Твоя лекция отправлена! Жди скидку на почте. Есть еще материалы? Загрузи прямо сейчас
Источник: spravochnick.ru