
Метод создания искусственной речи человека с помощью машин называется синтезом речи. Компьютерная система, которая используется для выполнения этой процедуры, называется синтезатором речи. Система требует дальнейшей реализации в программном или аппаратном обеспечении, и мы можем заметить одно ее применение в системе преобразования текста в речь (TTS). Система преобразования текста в речь принимает повседневный человеческий язык в текстовой форме как ввод и преобразует его в речь как вывод.
Синтез речи осуществляется путем упорядочивания записанной речи в виде единиц, которые хранятся в базе данных. Системы различаются по размеру хранимых голосовых единиц; самый широкий диапазон выходного сигнала обеспечивается системой, в которой хранятся телефоны или дифоны с возможностью потери четкости.
Хранение целых слов или предложений позволяет производить высококачественную продукцию для определенных пользовательских доменов. Этот метод может быть заменен включением модели речевого тракта и различных других характеристик, принадлежащих человеческому голосу, и генерации искусственного голосового вывода.
Как сделать свой бесплатный синтезатор речи + заработать на этом. Обращаемся к ChatGPT за помощью

Обзор системы TTS
Качество вывода синтезатора речи зависит от его близости к реальному человеческому голосу и от того, насколько легко его понять. Использование устройства синтеза речи стало очевидным с 1990-х годов, которое было тщательно разработано, чтобы помочь людям с особыми ограничениями и нарушениями.
Обзор системы преобразования текста в речь

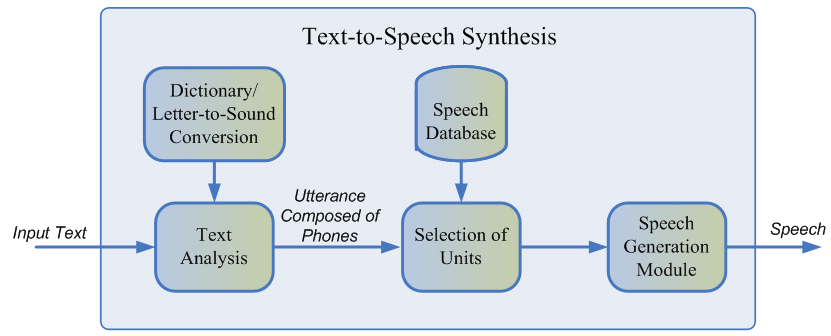
Преобразование текста в речь состоит из двух важных частей:
- Передняя часть- Он отвечает за преобразование вводимого текста, содержащего различные символы, числа и сокращения, в эквивалентную форму понятных и конвертируемых данных. Этот процесс называется нормализацией текста или предварительной обработкой данных. Затем каждому слову присваивается фонетическая транскрипция, он разделяет и помечает текст на просодические единицы, такие как предложения, предложения и фразы, посредством процесса, называемого преобразованием текста в фонему или графемы в фонему. Затем эти два аспекта объединяются для создания выходных данных, содержащих символическое лингвистическое представление.
- Back End- Эта часть, которую обычно называют «синтезатором», отвечает за символическое лингвистическое представление звука. В продвинутой системе за этим процессом далее следует вычисление целевой просодии (контур высоты тона, времена фонем), которая будет использоваться в выходной речи.
Технологии, задействованные в синтезе речи
Естественность и разборчивость являются наиболее важными атрибутами, определяющими качество устройства синтеза речи. Естественность определяется способностью устройства максимально точно воспроизводить человеческий голос, а разборчивость определяет, насколько легко устройство может понимать выходной звук. Синтезаторы речи стремятся достичь оптимальных результатов в обоих этих аспектах.
Как работает cинтез речи
Конкатенативный синтез и формантный синтез — две основные технологии, которые генерируют синтетические речевые сигналы. У каждой технологии есть свои сильные и слабые стороны, и обычное использование метода синтеза обычно диктует выбор одного из этих подходов.
Конкатенативный синтез
Последовательность фрагментов записанной речи определенным образом называется конкатенативным синтезом. Этот процесс обычно обеспечивает наиболее естественное звучание синтезированной речи. Однако несоответствие между вариациями естественной речи и схемой автоматизированных методов сегментации сигналов часто приводит к звуковым сбоям на выходе.
Существует три важных подтипа конкатенативного синтеза.
- Синтез выбора агрегата- Входными данными для этого метода селекции является обширная база данных записанной речи. Сегментация базы данных осуществляется с помощью распознавателя речи, установленного в режим принудительного выравнивания. Результатом сегментации являются такие единицы, как телефоны, дифоны, слова, фразы, слоги, морфемы, предложения и т. Д. Индексирование этих единиц основано на различных параметрах, таких как высота звука, продолжительность, положение в слоге и соседние телефоны. Процесс дерева решений выбирает наиболее подходящие единицы для формирования цепочки для выполнения. Чем обширнее база данных, тем естественнее будет речь на выходе. Этот метод обеспечивает необычайную естественность выходной речи на основе записанных данных.
- Дифонный синтез- База данных по этой технике состоит только из дифонов, что делает ее относительно небольшой. Фонотактика выбранного языка определяет набор всех уникальных дифонов, которые необходимо учитывать. База данных речи состоит из одной записи каждого дифона. Различные методы обработки цифровых сигналов, такие как PSOLA, MBROLA, кодирование с линейным предсказанием, используются для наложения целевого предложения на эти дифоны. Использование дифонного синтеза ограничено исследованиями, потому что речи не хватает естественности, она звучит очень роботизированно и содержит звуковые сбои.
- Доменно-специфический синтез База данных для этой техники ограничена заранее записанными словами и фразами. Применимость этого метода синтеза ограничена областью, на основе которой создается база данных, например, объявления на вокзалах, сводки погоды, говорящие часы и т. Д. Реализация этой технологии проста и в то же время требует высокого уровня производительности. естественность может быть достигнута за счет ограниченного количества выводимых предложений. Чтобы добиться плавного сочетания слов с естественной речью, необходимо учитывать множество языковых вариаций.
Формантный синтез
Для многих приложений естественность речи не является целью; скорее, важнее надежность, интеллект и высокая скорость точности. Этого можно достичь с помощью формантного синтеза, который создает синтезированную речь с использованием аддитивного синтеза и акустического моделирования. Этот метод, также называемый синтезом на основе правил, создает искусственную речевую форму волны путем изменения таких параметров, как частота, уровни шума и голос.
Искусственная, роботизированная речь, созданная с помощью технологии формантного синтеза, вряд ли будет ошибочно принята за человеческую речь. Акустические помехи, которые часто встречаются в конкатенативных системах, в первую очередь устраняются с помощью этой техники. Из-за отсутствия обширной базы данных речевых записей эти программы относительно малы, поскольку находят применение во встроенных системах, где возможности обработки ограничены.
Можно передать множество голосовых тонов и эмоций помимо стандартных вопросов и утверждений, поскольку системы на основе форматов демонстрируют полный контроль над всеми аспектами вывода. Например, многие известные видеоигры использовали технологию синтеза форматов для интерактивной речи.
Артикуляционный синтез
Метод, используемый для генерации звуков речи на основе модели речевого тракта человека, называется артикуляционным синтезом. Он нацелен на имитацию артикуляторов речи одним или несколькими способами. Он предлагает способ получить представление о развитии речи и изучить фонетику.
Коартикуляция является естественным эффектом в такой модели, и теоретически должно быть возможно правильно рассматривать свойства голосового источника, связь речевого тракта с голосовыми связками, а также то, как подсвязочная система, носовой тракт и полости носовых пазух влияют на формирование человеческой речи через эту модель.
Артикуляционный синтез обычно включает два отдельных компонента: голосовой тракт, который разделен на несколько субкомпонентов, и соответствующие области поперечного сечения, используемые параметрически для отражения характеристик голосовых связок. В акустической модели электрическая аналоговая линия передачи аппроксимирует каждое поле поперечного сечения.
Моделирование речевого тракта подвержено изменениям, возникающим в функциях области относительно времени. Целевая конфигурация, назначенная каждому звуку, определяет темп движения голосового тракта. При правильной конструкции артикуляционный синтезатор может воспроизводить все соответствующие эффекты при разработке фрикативных и взрывных звуков и моделирования переходов коартикуляции, чтобы воспроизвести процессы, задействованные в производстве реальной речи.
В середине 1970-х годов в Haskins Laboratories Филип Рубин, Том Баер и Пол Мермельштейн создали первый артикуляционный синтезатор, обычно используемый для лабораторных экспериментов.
Синтез на основе HMM
Это статистический параметрический синтез, основанный на «скрытых марковских моделях». HMM одновременно моделируйте частотный спектр, основную частоту и длину речи в этом методе. Речевые сигналы, созданные по критерию максимального правдоподобия, создаются из самих HMM.
Скрытая марковская модель (HMM) в вычислительной биологии — это математический метод, который в основном используется для моделирования биологической последовательности. Последовательность моделируется как результат дискретного стохастического метода в его реализации, который проходит через набор последовательных состояний, которые «скрыты» от наблюдателя.
Синтез синусоидальных волн
Синтез синусоидального сигнала или синусоидального голоса — это метод синтеза речи путем замены формант (видных энергетических полос) свистками чистого тона. Филип Рубин создал первое программное обеспечение синусоидального синтеза (SWS) для автоматизированного производства стимулов для перцепционных экспериментов в Haskins Laboratories в 1970-х годах.
Синусоидальная речь — это своеобразное явление, при котором некоторые особенности речи передаются небольшому количеству синусоид, собранных вместе, на которые они совершенно не похожи во многих отношениях. Высокая разборчивость достигается с помощью трех синусоид, отслеживающих частоту и амплитуду первых трех речевых формант.
Синтез на основе глубокого обучения
В отличие от подхода на основе HMM, метод на основе глубокого обучения явно сопоставляет лингвистические характеристики с акустическими характеристиками с помощью глубоких нейронных сетей, которые оказались чрезвычайно успешными в изучении внутренних характеристик данных. Люди предлагали различные модели в рамках давней традиции исследований, основанных на методах синтеза речи на основе глубокого обучения.

Полезным инструментом для синтеза речи стал глубокое обучение способен использовать огромное количество обучающих данных. В последнее время проводится все больше и больше исследований методов глубокого обучения или даже сквозных систем, и достигнуты современные успехи.
Сентябрь 2016 ознаменовал начало WaveNet. DeepMind, глубокая генеративная модель необработанных звуковых сигналов. Это сделало очевидным, что модели, основанные на глубоком обучении, могут моделировать необработанные формы сигналов и хорошо работать с акустическими характеристиками, такими как спектрограммы или определенные предварительно обработанные лингвистические характеристики для генерации выражения.
- Ограниченные возможности анализа текста с помощью единой системы.
- Ограниченное количество функций.
- Обширное кондиционирование существующих атрибутов и легкая адаптация к новым.
- Повышенная естественность и понятность
- Более прочный по сравнению с многоступенчатыми моделями.
Недостатки сквозных систем-
- Существование проблемы медленного вывода.
- Меньшее количество данных приводит к менее устойчивой выходной речи.
- Ограниченная контролирующая способность, чем конкатенативный подход.
- Плоская просодия разработана с усреднением по тренировочным данным.
Проблемы, связанные с синтезом речи
- Размещение по-разному произносимых слов с одинаковым написанием в зависимости от контекста.
- Вывод о том, как расширить нет. на основе окружающего слова, числа и знаков препинания. Например, 1465 может быть «одна тысяча четыреста шестьдесят пять» или может также читаться как «один четыре шесть пять», «четырнадцать шестьдесят пять» или «четырнадцатьсот шестьдесят пять».
- Неоднозначность сокращений. Например, «in» вместо «дюймов» нужно отличать от слова «in».
- Подход на основе словаря (поиск каждого слова в словаре и замена написания произношением, указанным в словаре, чтобы выбрать правильное произношение каждого слова) процесса преобразования текста в фонемы полностью не работает для любого слова, которое можно найти в словарь.
- Подход, основанный на правилах (чтобы оценить их произношение на основе их написания, правила произношения применяются к словам или подход «научиться читать») процесса преобразования текста в фонемы не удается, поскольку схема учитывает необычное написание или произношение, поскольку сложность правил значительно возрастает.
- Сложность надежной оценки систем синтеза речи из-за отсутствия общепринятых объективных стандартов производительности.
- Смещение контура высоты тона предложения, в зависимости от того, утвердительное ли это выражение, вопросительное или восклицательное.
Для предыдущей статьи о колесном роботе Mecanum, Нажмите здесь.
Источник: ru.lambdageeks.com
Обзор технологий синтеза речи
Всем привет! Меня зовут Влад и я работаю data scientist-ом в команде речевых технологий Тинькофф, которые используются в нашем голосовом помощнике Олеге.
В этой статье я бы хотел сделать небольшой обзор технологий синтеза речи, использующихся в индустрии, и поделиться опытом нашей команды построения собственного движка синтеза.

Синтез речи
Синтез речи — это создание звука на основе текста. Эту задачу сегодня решают двумя подходами:
- Unit selection [1], или конкатенативный подход. Он основан на склейке фрагментов записанного аудио. С конца 90-х долгое время он считался де-факто стандартом для разработки движков синтеза речи. Например, голос, звучащий по методу unit selection, можно было встретить в Siri [2].
- Параметрический синтез речи [3], суть которого состоит в построении вероятностной модели, предсказывающей акустические свойства аудиосигнала для данного текста.
Речь моделей unit selection имеет высокое качество, низкую вариативность и требует большого объема данных для обучения. В то же время для тренировки параметрических моделей необходимо гораздо меньшее количество данных, они генерируют более разнообразные интонации, но до недавнего времени страдали от общего достаточно низкого качества звука по сравнению с подходом unit selection.
Однако с развитием технологий глубокого обучения модели параметрического синтеза достигли существенного прироста по всем метрикам качества и способны создавать речь, практически неотличимую от человеческой.
Метрики качества
Прежде чем говорить о том, какие модели синтеза речи лучше, нужно определить метрики качества, по которым будет проводиться сравнение алгоритмов.
Поскольку один и тот же текст можно прочитать бесконечным количеством способов, априори правильного способа для произношения конкретной фразы не существует. Поэтому зачастую метрики качества синтеза речи субъективны и зависят от восприятия слушающего.
Стандартная метрика — это MOS (mean opinion score), усредненная оценка естественности речи, выданная асессорами для синтезированных аудио по шкале от 1 до 5. Единица означает совсем неправдоподобное звучание, а пятерка — речь, неотличимую от человеческой. Реальные записи людей обычно получают значения примерно 4,5, и значение больше 4 считается достаточно высоким.
Как работает синтез речи
Первый шаг к построению любой системы синтеза речи — сбор данных для обучения. Обычно это аудиозаписи высокого качества, на которых диктор читает специально подобранные фразы. Примерный размер датасета, необходимый для обучения моделей unit selection, составляет 10—20 часов чистой речи [2], в то время как для нейросетевых параметрических методов верхняя оценка равна примерно 25 часам [4, 5].
Обсудим обе технологии синтеза.
Unit selection
Обычно записанная речь диктора не может покрыть всех возможных случаев, в которых будет использоваться синтез. Поэтому суть метода состоит в разбиении всей аудиобазы на небольшие фрагменты, называющиеся юнитами, которые затем склеиваются друг с другом с использованием минимальной постобработки. В качестве юнитов обычно выступают минимальные акустические единицы языка, такие как полуфоны или дифоны [2].
Весь процесс генерации состоит из двух этапов: NLP frontend, отвечающий за извлечение лингвистического представления текста, и backend, который вычисляет функцию штрафа юнитов для заданных лингвистических признаков. В NLP frontend входят:
- Задача нормализации текста — перевод всех небуквенных символов (цифр, знаков процентов, валют и так далее) в их словесное представление. Например, “5 %” должно быть переведено в “пять процентов”.
- Извлечение лингвистических признаков из нормализованного текста: фонемное представление, ударения, части речи и так далее.
Обычно NLP frontend реализован с помощью вручную прописанных правил для конкретного языка, однако в последнее время происходит все больший уклон в сторону использования моделей машинного обучения [7].
Штраф, оцениваемый backend-подсистемой, — это сумма target cost, или соответствия акустического представления юнита для конкретной фонемы, и concatenation cost, то есть уместности соединения двух соседних юнитов. Для оценки штраф функций можно использовать правила или уже обученную акустическую модель параметрического синтеза [2]. Выбор наиболее оптимальной последовательности юнитов с точки зрения выше определенных штрафов происходит с помощью алгоритма Витерби [1].
Примерные значения MOS моделей unit selection для английского языка: 3,7—4,1 [2, 4, 5].
Достоинства подхода unit selection:
- Естественность звучания.
- Высокая скорость генерации.
- Небольшой размер моделей — это позволяет использовать синтез прямо на мобильном устройстве.
- Синтезируемая речь монотонна, не содержит эмоций.
- Характерные артефакты склейки.
- Требует достаточно большой тренировочной базы аудиоданных для покрытия всевозможных контекстов.
- В принципе не может генерировать звук, не встречающийся в обучающей выборке.
Параметрический синтез речи
В основе параметрического подхода лежит идея о построении вероятностной модели, оценивающей распределение акустических признаков заданного текста.
Процесс генерации речи в параметрическом синтезе можно разделить на четыре этапа:
- NLP frontend — такая же стадия предобработки данных, как и в подходе unit selection, результат которой — большое количество контекстно-зависимых лингвистических признаков.
- Duration model, предсказывающая длительность фонем.
- Акустическая модель, восстанавливающая распределение акустических признаков по лингвистическим. В акустические признаки входят значения фундаментальной частоты, спектральное представление сигнала и так далее.
- Вокодер, переводящий акустические признаки в звуковую волну.
Для обучения duration и акустической моделей можно использовать скрытые марковские модели [3], глубокие нейронные сети или их рекуррентные разновидности [6]. Традиционный вокодер — это алгоритм, основанный на source-filter модели [3], которая предполагает, что речь — это результат применения линейного фильтра шума к первоначальному сигналу.
Общее качество речи классических параметрических методов оказывается достаточно низким из-за большого количества независимых предположений об устройстве процесса генерации звука.
Однако с приходом технологий глубокого обучения стало возможным обучать end-to-end модели, которые напрямую предсказывают акустические признаки по буквам. Например, нейронные сети Tacotron [4] и Tacotron 2 [5] принимают на вход последовательность букв и возвращают мел-спектрограмму с помощью алгоритма seq2seq [8]. Таким образом шаги 1—3 классического подхода заменяются одной нейросетью. На схеме ниже показана архитектура сети Tacotron 2, достигающей достаточно высокого качества звука.
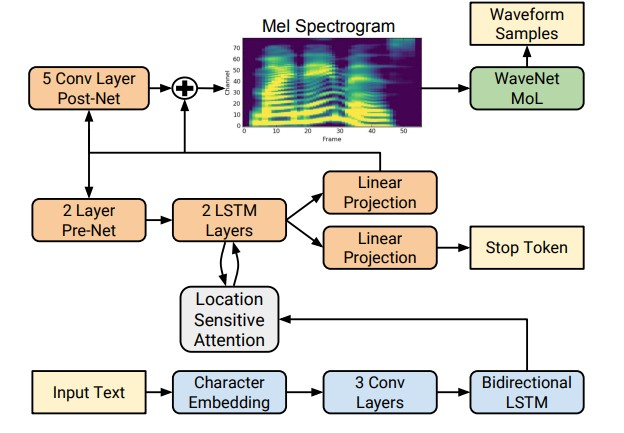
Другим фактором существенного прироста в качестве синтезируемой речи стало применение нейросетевых вокодеров вместо алгоритмов цифровой обработки сигналов.
Первым таким вокодером была нейронная сеть WaveNet [9], которая последовательно, шаг за шагом, предсказывала значения амплитуды звуковой волны.
Благодаря использованию большого количества сверточных слоев с пропусками для захвата большего контекста и skip connection в архитектуре сети удалось достичь примерно 10%-го улучшения MOS по сравнению с моделями unit selection. На схеме ниже представлена архитектура сети WaveNet.

Главный недостаток WaveNet — низкая скорость работы, связанная с последовательной схемой сэмплирования сигнала. Эту проблему можно решить либо с помощью инженерной оптимизации для конкретной архитектуры железа, либо заменой схемы сэмплирования на более быструю.
Оба подхода были успешно реализованы в индустрии. Первый — в Tinkoff.ru, а в рамках второго подхода компания Google представила сеть Parallel WaveNet [10] в 2017 году, наработки которой используются в Google Assistant.
Примерные значения MOS для нейросетевых методов: 4,4—4,5 [5, 11], то есть синтезируемая речь практически не отличается от человеческой.
Достоинства параметрического синтеза:
- Естественное и плавное звучание при использовании end-to-end подхода.
- Большее разнообразие в интонациях.
- Использование меньшего объема данных по сравнению с моделями unit selection.
- Низкая скорость работы по сравнению с unit selection.
- Большая вычислительная сложность.
Как работает синтез речи в Tinkoff
Как следует из обзора, методы параметрического синтеза речи, основанные на нейросетях, на текущий момент существенно превосходят по качеству подход unit selection и гораздо проще для разработки. Поэтому для построения собственного движка синтеза мы использовали именно их.
Для обучения моделей было использовано около 25 часов чистой речи профессионального диктора. Тексты для чтения были специально подобраны так, чтобы наиболее полно покрыть фонетику разговорной речи. Кроме того, чтобы добавить синтезу большее разнообразие в интонации, мы попросили диктора читать тексты с выражением, зависящим от контекста.
Архитектура нашего решения концептуально выглядит так:
- NLP frontend, в который входит нейросетевая текстовая нормализация и модель по расстановке пауз и ударений.
- Tacotron 2, принимающий на вход буквы.
- Авторегрессионный WaveNet, работающий в real time на CPU.
Благодаря такой архитектуре наш движок генерирует выразительную речь высокого качества в режиме реального времени, не требует построения фонемного словаря и дает возможность управлять ударениями в отдельных словах. Примеры синтезированных аудио можно прослушать, перейдя по ссылке.
Ссылки:
[1] A. J. Hunt, A. W. Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio, R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, A. W. Black. Statistical parametric speech synthesis, Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous. Tacotron: Towards End-to-End Speech Synthesis.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Statistical parametric speech synthesis using deep neural networks.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Neural Models of Text Normalization for Speech Applications.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Fast High-Fidelity Speech Synthesis.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech.
[12] Dario Rethage, Jordi Pons, Xavier Serra. A Wavenet for Speech Denoising.
- Блог компании TINKOFF
- Машинное обучение
- Искусственный интеллект
Источник: habr.com
ТОП 8 лучших синтезаторов речи на русском языке
Синтезированная речь уже давно окружает нас, она звучит их телефона, из телевизора, из ютуба и инстаграмма. А что удивительно многим людям синтезированная речь действительно нравится или по крайней мере не вызывает негативных эмоций. В данной статье мы подробно расскажем при помощи каких инструментов можно синтезировать речь на русском языке.
- Для чего чаще всего применяют синтезатор речи
- ТОП лучших синтезаторов речи на ПК
- Онлайн синтезаторы речи на русском языке
Кстати, авто данной статьи чаще всего использует синтезаторы речи для прослушивания книг и для поиска по интернету, да-да, это то-самое «Ok, google!»
Благодаря этому можно учить новые иностранные слова с правильным произношением, читать книги не отвлекаясь от своих дел или, например, находясь в транспорте. Изначально разработкой таких программ занимались организации, специализирующиеся на технике для людей с проблемами зрения.
Сейчас же, любой пользователь может скачать одну из программ, установить ее на свой компьютер или телефон и синтезировать речь, в том числе и русскую.

Для чего чаще всего применяют синтезатор речи
Программный синтез речи – это создание звука на основе написанного текста. Современные разработчики выполняют эту задачу в своих продуктах двумя известными способами:
- Монтируют фрагменты аудиозаписи. Это конкатенативный подход, применяемый в начальных версиях синтезатора Siri.
- Создают вероятностную модель, которая может предсказать акустические свойства того или иного записанного текста. Данный подход именуется параметрическим синтезом речи.
Параметрические модели обладают более развитым искусственным интеллектом, используют сравнительно небольшое количество информации и способны генерировать различные интонации. Сегодня синтезированная речь практически не отличается от естественного человеческого произношения.
Эти программы успешно применяются для изучения новых иностранных слов, чтения книг без отвлечения от повседневных дел, полноценной работы пользователей с серьезными нарушениями зрения.
ТОП лучших синтезаторов речи на ПК
Лучшие программы поддерживают огромное количество распространенных языков, в том числе они подойдут и русскоязычным пользователям.
Voice Reader 15
Этот синтезатор речи Android использует встроенную систему TTS мобильной платформы для чтения электронных писем, текста из буфера обмена, сохраняет статьи для будущего прослушивания, создает списки статей для непрерывного воспроизведения. Возможность синхронизации с Dropbox дает возможность пользователю прослушивать документы, сохраненные в облачном сервисе. Слушатель может регулировать громкость, скорость и тембр чтения, останавливать и возобновлять его механическими кнопками гарнитуры.
Смотри наши инструкции по настройке девасов в ютуб!

Ivona
Эта программа читает текст вслух прямо с экрана мобильного устройства с разной скоростью и несколькими голосами. Чтение текста возможно из любых текстовых файлов, программ и браузеров. Программа может преобразовывать текстовый файл в формат mp3, читать письма и Rss-ленты, поддерживает SAPI5-голоса, синтезирует речь для множества языков. Доступны настройки громкости и скорости чтения.
ГОЛОС
Голос – это синтезатор речи, работающий с текстами на русском украинском языках. В программе можно настраивать частоту, тембр и скорость голоса. Приложение может читать текст из буфера обмена, создавать аудиокниги в форматах mp3 и wav, менять размер шрифта, хранить в памяти несколько десятков текстов и последние настройки. Программа Voice оснащена дополнительными опциями для незрячих и слабовидящих пользователей. Текст для синтеза загружается в окно редактора. «Голос» способен распознать до семи текстовых форматов.
Vocalizer
Этот синтезатор не встраивается в системную TTS Android и может использоваться исключительно русскоязычной локализацией Code factory. Программа быстро откликается, обладает достойным качеством звучания. Но движок синтезатора встроен в конкретное приложение, что сужает возможности пользователя и заставляет его работать в ограниченной среде.
Но данная особенность имеет и положительные стороны. Например, программу можно более тонко настроить, отрегулировать чтение пунктуационных знаков или фонетическое произношение символов. Латинский текст читается с редкими ошибками в произношении, но всегда грамматически верно.
ESpeak
Синтезатор от разработчиков специального ПО для Android оказался довольно мощны некоммерческим продуктом с широким набором функций, но русскоязычных пользователей он может разочаровать. Приложение не может прочитать слова на русском в верхнем регистре, а длинные строки из кириллических символов разбивает на маленькие фрагменты. Некоторые из таких фрагментов состоят всего из одной буквы. В итоге речь рассыпается и с трудом воспринимается. Среди преимуществ стоит отметить сравнительно высокую скорость отклика, четкость и правильность произношения слов на английском языке.
Онлайн синтезаторы речи на русском языке
Количество русскоязычных пользователей мобильных устройств Android и IOS постоянно растет. Разработчики давно уловили эту тенденцию: русский язык есть фактически в каждом синтезаторе речи. Но Google Переводчик, Text-to-speech и Яндекс.Алиса занимают особое место в данной категории за счет богатого набора слов и широкого набора функций.
Google Переводчик
Бесплатное приложение от Google переводит текст на несколько десятков языков после ввода символов в электронную форму или фокусировки камеры мобильного устройства на конкретном слове и предложении. Несмотря на то, что программа предназначена для перевода, она может синтезировать речь. Чтобы услышать слова робота на русском языке, нужно ввести текст в электронную форму. Робот прочитает текст на русском после активации клавиши «прослушать». Качество синтеза относительно хорошее, но иногда речь получается рваной.

Text-to-speech
Text-to-speech – приложение, предназначенное для простого преобразования печатного текста в устную речь. Программа читает разные тексты и электронные документы, даже если в них перемешаны слова из разных языков. Преобразованный текст можно сохранить для дальнейшего применения в формате wav. Здесь, по аналогии с подобными программами, настраивается скорость речи, размер шрифта, есть опции для пользователей с ограниченными возможностями.
Яндекс Алиса
Яндекс.Алиса – многофункциональный синтезатор речи на русском языке, способный поддержать разговор с пользователем на множество тем, выполнять голосовые команды, запускать некоторые приложения, Используемые здесь технологии нельзя назвать инновационными, они уже были ранее применены Google. Пользователь отправляет «Алисе» свое сообщение, записанное голосом или текстом.
Сообщение распознается, выбирается один из нескольких тысяч шаблонных ответов и отправляется в виде ответа пользователю. По уровню развития искусственного интеллекта этот бот немного впереди предшественников – голосовой движок работает хорошо, разрывов в речи фактически нет. Но периодически бот выдает ответы, не имеющие связи с заданным вопросом. Разработчикам еще предстоит много работы над оптимизацией данного приложения, но уже сейчас ясно, что у него отличные перспективы.
Сан Саныч / Инженер (Математик-программист)
Эксперт в ИТ области, с высшим образованием и научными статьями. Уже более 15 лет занимаюсь ремонтом мобильных телефонов и персональных копьютеров, специализируюсь на настройке ПО и сетей. С 2013 года веду ютуб-канал.
Телеграм-канал проекта — https://t.me/hardtekru
- Как посмотреть сохраненные пароли в андроид
- Топ 40 Игр без интернета на Андроид телефон
Источник: www.hardtek.ru