
Презентация: «Sphinx — полнотекстовый поиск на сайте, просто и доступно»
Вкратце: хочу сделать презентацию и пару раз выступить на конференциях интернет магазинов. Написал текст презентации, нужны отзывы. Надеюсь на вашу помощь в составлении грамотного и доступного текста.
Текущий текст презентации под катом
Общие сведения о полнотекстовом поиске
Полнотекстовый поиск – это по сути гугл и яндекс технологии: пользователь вводит поисковый запрос – получает ответ в виде определенного набора страниц. На сайте интернет магазина это скорее всего будет список продуктов, наиболее близко подходящих под поисковый запрос. Есть такое понятие – релевантность, так вот, она важна. Также важны: синонимы, опечатки, морфология и обычная логика обычного рядового покупателя.
В интернет магазине, к примеру, слова «купить», «лучший», «качественный» можно просто игнорировать, так как они ничего не значат. А по словам «модный», «дорогой», «епл айфон», «bosh аккумулятор для киа сид» можно однозначно определить, что именно нужно человеку.
Заводчик котов породы канадский сфинкс в программе «УТРО» на СТВ
Вот вкратце о том, для чего нужен полнотекстовый поиск.
Зачем нужен поиск на сайте: достоинства и недостатки
Основная причина и цель – это конверсия посетителя в покупателя, то есть процент покупок относительно посетителей на сайте. Чем проще человеку найти товар – тем больше вероятность, что он станет покупателем. С каждым днем покупатели становятся все ленивее и привыкают к удобным поисковым технологиям других магазинов, поэтому отсутствие такого поиска на своем сайте может очень негативно сказаться на продажах.
Кроме того есть специфичная номенклатура, которую простым проходом по каталогу не найти и нужен именно полнотекстовый поиск: это когда более 1000 наименований, или тяжело подобрать именно тот товар, что нужно. В данном случае компьютер упрощает задачу выбора и помогает человеку сделать покупку зряче, а не методом «научного тыка».
Недостатки: $100-$200 на разработку поискового модуля для сайта.
Реализации поиска на Сфинкс (SphinxSearch): ОС, варианты установки, языки программирования
Сфинкс — продукт с открытым исходным кодом. Это фактически поисковый сервер, разработанный с нуля, для высоконагруженных проектов, с настраиваемой релевантностью (имеется в виду качество поиска), а также простотой интеграцией в любой проект. Он написан на C++ и работает на Linux (RedHat, Ubuntu и т.д.), Windows, MacOS, Solaris, FreeBSD и некоторых других менее популярных системах.
Сфинкс позволяет хранить подготовленные индексы текстовых данных, производить поиск по базе данных SQL, NoSQL хранилища, или просто по файлам на сервере быстро и легко. Он может индексировать данные на лету, добавлять к уже существующим новые индексные данные, работая в режиме онлайн не перегружая сервер.
Различные возможности обработки текста дают программисту тонкую настройку Sphinx для требований вашего приложения, а также ряд функций, гарантирующих, что вы сможете настроить качество поиска именно так, как вам это нужно. Есть два варианта подключения:
Сфинкс — Все о породе
• Поиск по SphinxAPI — обычный АПИ
• SphinxQL — аналог стандартного SQL
Сфинкс кластера могут масштабироваться до миллиардов документов и десятки миллионов поисковых запросов в день. Такого рода нагрузки выдерживаются на сайтах, как Craigslist, DailyMotion, Netlog, и т.д.
Реальный пример поисковых запросов в интернет магазине автозапчастей
Авто запчастями, а точнее продажей интернет магазинов по запчастям, наша компания занимается давно, плодотворно и довольно успешно. Но в силу ряда причин релевантный поиск понадобился только сейчас.
Основная причина, скорее всего в том, что большинству запчастей полнотекстовый поиск не подходит. Но есть 5-10% товаров, для которых он катастрофически нужен и без него уж никак. А наш стандартный поиск с прямыми по своей сути кросс связями и указанием четкой модели и марки авто из каталога запчастей, для этой группы товаров не работает. Пример таких «неправильных» товаров: масла, шины, аккумуляторы, автолампы, дворники и другие подобные часто продаваемые продукты.
Средний прайс по запчастям небольшой рядовой компании — 2-10 млн позиций, соответственно 10% от этой базы и будут занимать нужные нам данные. Поэтому мы решили внедрить движок sphinxsearch.com в своем продукте. Подробнее о данной реализации можно почитать на Хабре: habrahabr.ru/blogs/sphinx/132118
Углубленное изучение поискового языка запросов
Основной функционал поиска – это настраиваемые веса для полей, а также методы поиска. Для того, чтобы работала морфология и в запросе «масла Castrol 5W40» нашлись документы с текстом «Масло» и «15W40» — нужно одновременно использовать символ «*» и поиск по словоформе «масл», а для этого нужен построитель запросов, который работает именно в режиме «SPH_MATCH_EXTENDED2».
Сортировать по-умолчанию можно как по цене, так и по релевантности, так и по комплексу таких параметров. Можно задать для каждой группы товаров свой метод релевантности и порядок выдачи результатов, особенно это актуально, когда документов более сотни.
Инкрементные индексы позволяют добавлять новые продукты и документы на лету, не останавливая работу вашего интернет магазина.
Ну и самое важное: синонимы. В нашем примере можно использовать запрос «масла кастрол 5W40» и он найдет то же, что и «масла Castrol 5W40». В примере с «C#» нужно включать такие нестандартные словоформы, чтобы они не обрабатывались по стандартной схеме индекса и работали вручную именно так, как вы их настроите. Только вы знаете, какой именно смысл в вашем проекте несет фраза, к примеру «C#» = «ДО ДИЕЗ для музыкантов».
Кто сможет сделать такой поиск на базе сфинкс?
Любой джуниор программист, знакомый с английским языком и умеющий читать документацию на сайте sphinxsearch.com/docs
Есть также немного русской документации и пару статей на русском языке.
Никаких ограничений фактически нету, разве что боязнь нового подхода к поиску. Кажется, что это все сложно и очень дорого. На самом деле это все просто, быстро и дешево. На хабре есть специальный блог, в котором отзывчивые программисты, включая русскоязычного разработчика движка, отвечают на все возникающие вопросы.
Спасибо, буду рад ответить на возникшие вопросы
Источник: habr.com
Sphinx. Для чего нужен Sphinx? Основные возможности и применение
Sphinx — это поисковая система с открытым исходным кодом, которая позволяет осуществлять полнотекстовый поиск. Наиболее известен тем, что выполняет поиск по большим данным очень эффективно. Индексируемые данные, как правило, могут поступать из самых разных источников: базы данных SQL, текстовые файлы, файлы HTML, почтовые ящики и так далее.
Основные возможности Sphinx
Sphinx помогает включить и повысить ценность поиска и масштабируемости благодаря следующим характеристикам, которые делают Sphinx не заменимым инструментом для поиска данных на сайте.
- Высокая скорость индексации (до 10-15 МБ/сек на каждое процессорное ядро);
- Высокая скорость поиска (до 150—250 запросов в секунду на каждое процессорное ядро с 1 000 000 документов);
- Высокая масштабируемость (крупнейший известный кластер индексирует до 3 000 000 000 документов и поддерживает более 50 миллионов запросов в день);
- Поддержка распределенного поиска;
- Поддержка нескольких полей полнотекстового поиска в документе (до 32 по умолчанию);
- Поддержка нескольких дополнительных атрибутов для каждого документа (то есть группы, временные метки и т. д.);
- Поддержка стоп-слов;
- Поддержка однобайтовых кодировок и UTF-8;
- Поддержка морфологического поиска — имеются встроенные модули для английского, русского и чешского языков; доступны модули для французского, испанского, португальского, итальянского, румынского, немецкого, голландского, шведского, норвежского, датского, финского, венгерского языков;
- Нативная поддержка PostgreSQL и MySQL;
- Поддержка ODBC совместимых баз данных (MS SQL, Oracle и т. д.).
Как работает Sphinx?
Sphinx в качестве источника данных использует базу данных, на основе этого он создает у себя поисковые индексы которые позволяют осуществлять быстрый поиск данных.
Для работы с Sphinx используется API через которое код сайта получает по поисковому запросу массив идентификаторов найденных записей, которые потом будут сопоставлены в коде с записям в БД сайта.
Какие проблемы решает Sphinx?
Если объем данных в БД сайта достигает несколько сотен тысяч записей или больше, то поиск по ней стандартными средствами БД будет крайней медленный. Поэтому для решения данной проблемы используют Sphinx.
Основная проблема которую решает Sphinx это быстрый поиск в большом объеме данных, а также решает проблему эффективного полнотекстового поиска.
Выводы
Использование Sphinx вместо MySQL может обеспечить значительные преимущества в скорости, Чем просто использование нативных поисковых возможностей баз данных.
Источник: blog-programmista.ru
Использование системы полнотекстового поиска Sphinx
В данной статье мы расскажем что такое Sphinx, его особенности и примеры использования.
Что такое Sphinx?
Sphinx является некоммерческим проектом с открытым исходным кодом, разрабатываемым более 10 лет, автором которого является Андрей Аксенов.
Sphinx (англ. SQL Phrase Index) — система полнотекстового поиска, отличительной особенностью которого является высокая скорость индексации и поиска, а также интеграция с существующими СУБД (MySQL, PostgreSQL) и API для распространённых языков веб-программирования (официально поддерживаются PHP, Python, Java, также существуют реализованные сообществом API для Perl, Ruby, .NET и C++).
Использование Sphinx значительно повышает скорость поиска и снижает затраты ресурсов. Основные возможности Sphinx:
- высокая скорость индексации (до 10-15 МБ/с на каждое процессорное ядро);
- высокая скорость поиска (до 150—250 запросов в секунду на каждое процессорное ядро с 1 000 000 документов);
- высокая масштабируемость (крупнейший известный кластер индексирует до 3 000 000 000 документов и поддерживает более 50 миллионов запросов в день);
- поддержка распределенного поиска;
- поддержка нескольких полей полнотекстового поиска в документе (до 32 по умолчанию);
- поддержка нескольких дополнительных атрибутов для каждого документа (то есть группы, временные метки и т. д.);
- поддержка стоп-слов;
- поддержка однобайтовых кодировок и UTF-8;
- поддержка морфологического поиска — имеются встроенные модули для английского, русского и чешского языков; доступны модули для французского, испанского, португальского, итальянского, румынского, немецкого, голландского, шведского, норвежского, датского, финского, венгерского языков;
- нативная поддержка MySQL (всех типов таблиц, в том числе MyISAM, InnoDB, NDB);
- нативная поддержка PostgreSQL;
- поддержка ODBC совместимых баз данных (MS SQL, Oracle и т. д.).
Описание установки поисковой системы Sphinx можно найти в официальной документации — sphinxsearch.com.
Использование Sphinx на хостинге
В личном кабинете аккаунта (в разделе Сервисы) Sphinx можно установить в пару кликов мышки.
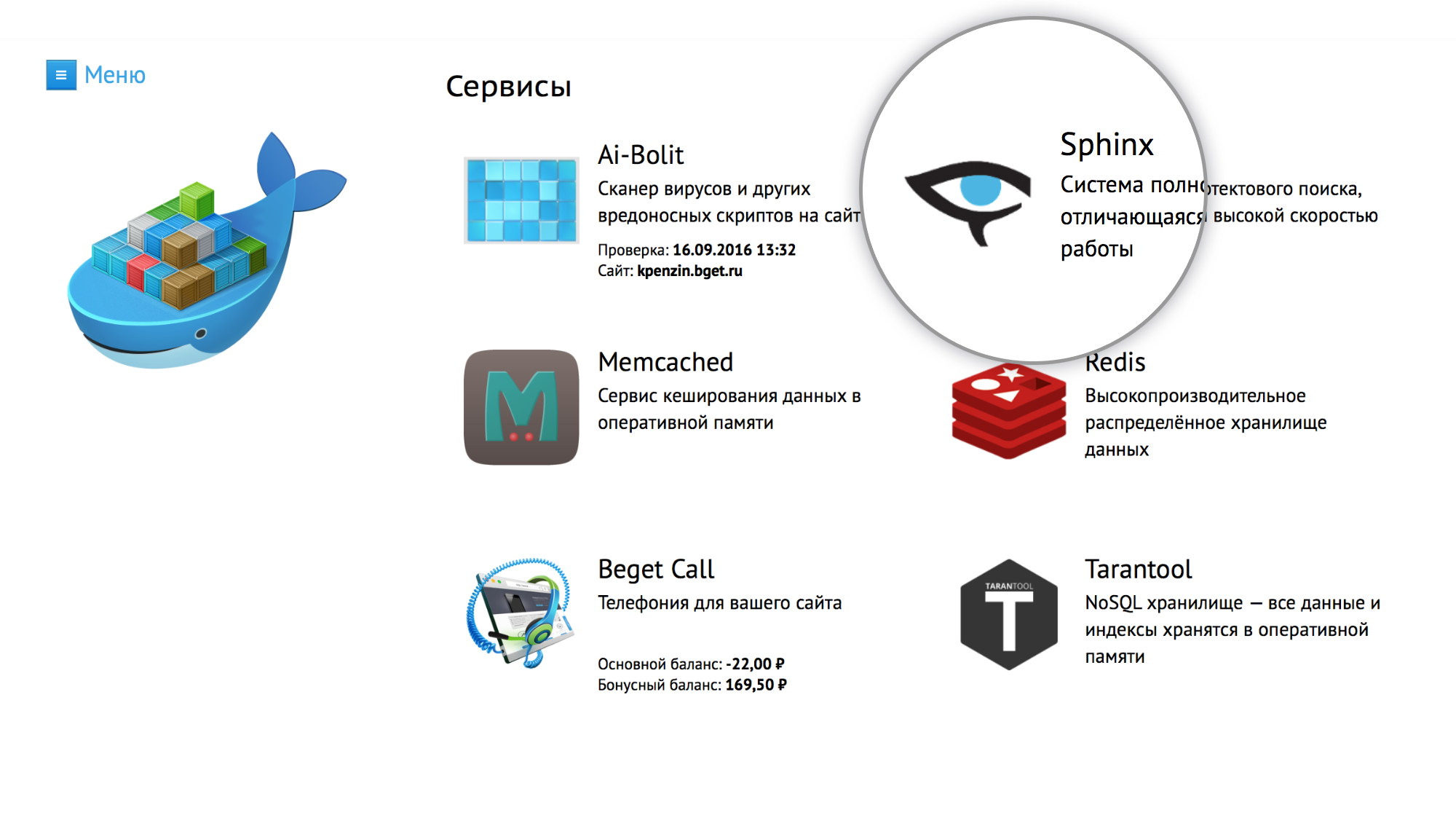
Перед включением есть возможность подобрать оптимальный тариф, в зависимости от примерного количества индексируемых данных, от 300мб до 5 гигабайт.
Квота устанавливается на оперативную память, доступную для использования сервисом Sphinx.
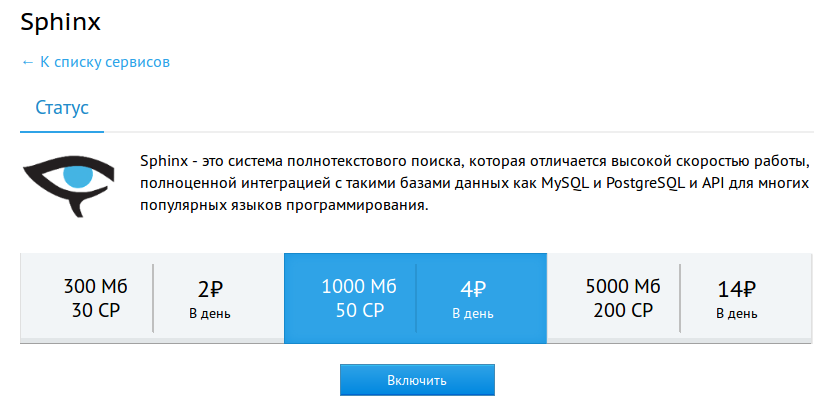
После включения сервиса появятся два подраздела — «Индексация» и «Поисковый сервер».
Sphinx условно состоит из двух ключевых элементов — построение индексов для данных и поисковая машина по этим индексам.
В разделе «Индексация» как раз настраивается конфигурация Sphinx (вкладка «Редактор конфигурации»), то есть правила описывающие с какими данными и как должен работать Sphinx (примеры конфигураций мы рассмотрим чуть позже).
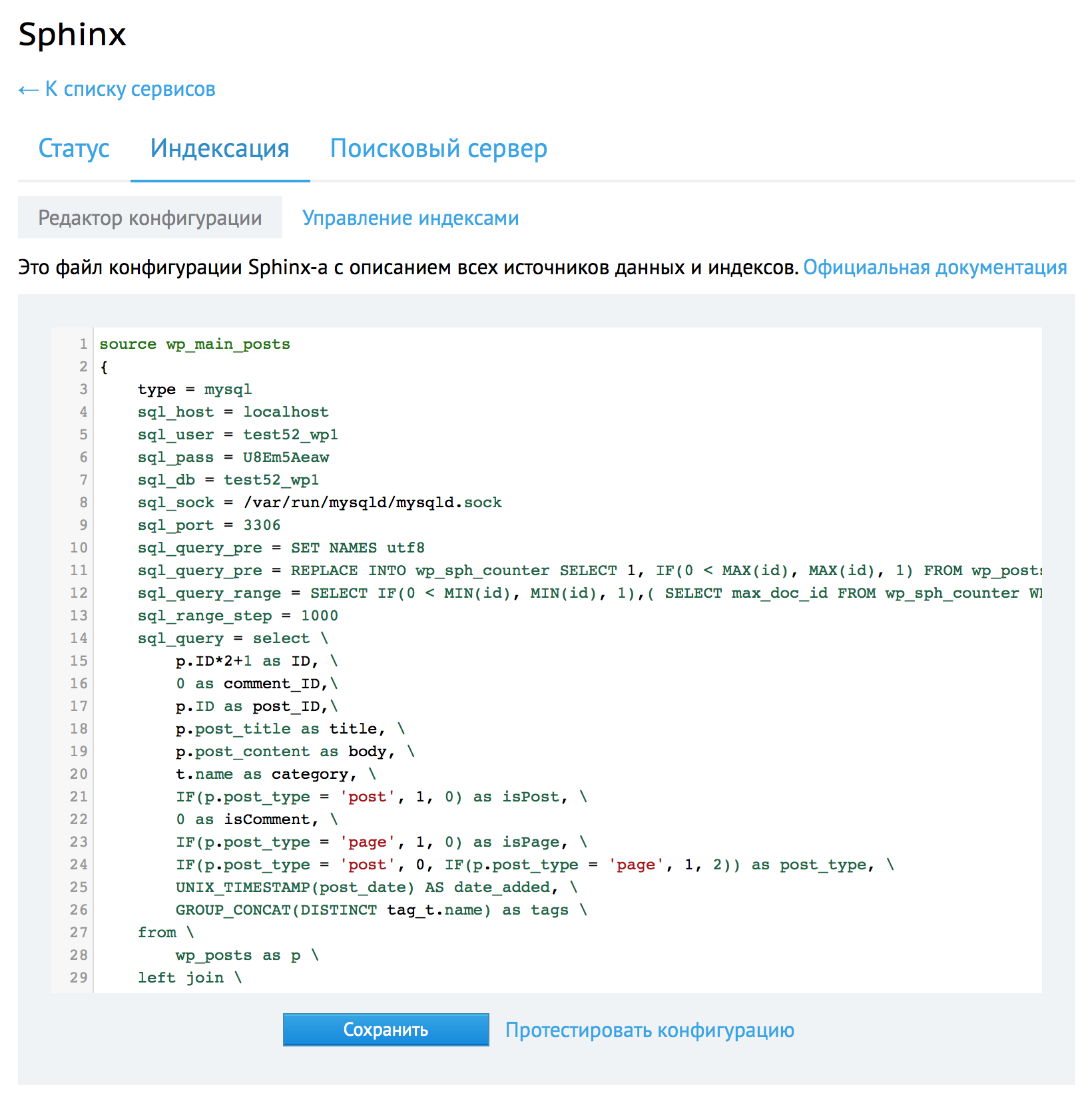
Стоит отдельно отметить подпункт меню «Управления индексами».
В нем отображаются все добавленные на текущий момент индексы, их статус индексации:
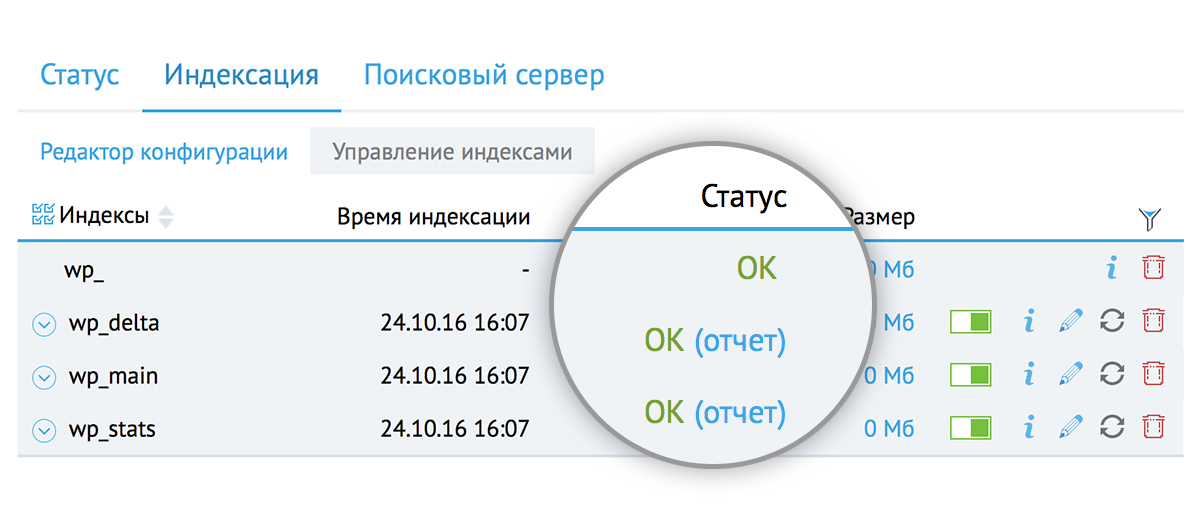
Статус автообновления индексов:
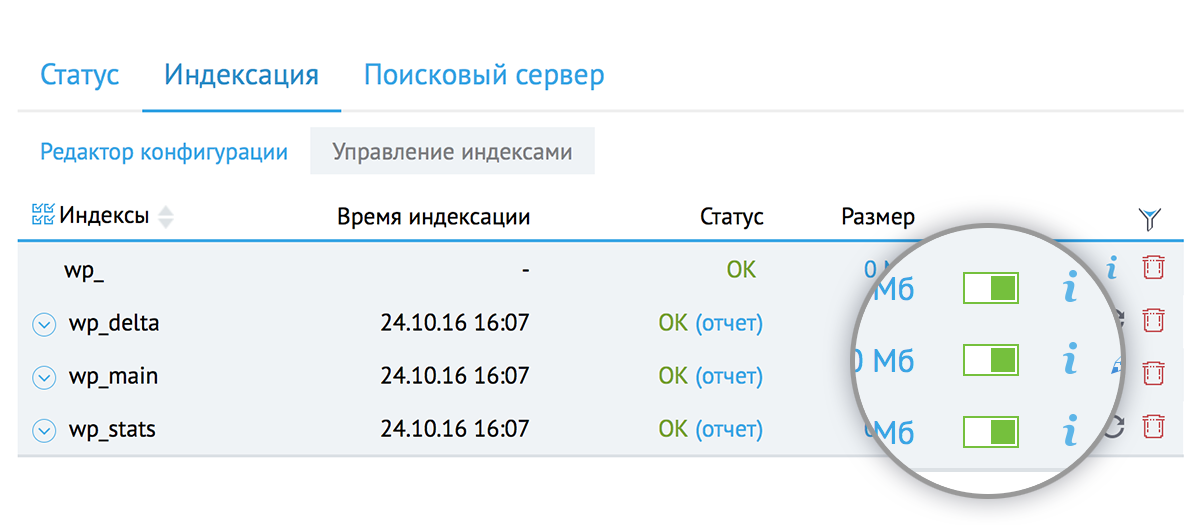
Автообновление индекса по сути является крон заданием, которое запускает переиндексацию.
По умолчанию для всех индексов включено автообновление, с периодичностью в 15 минут.
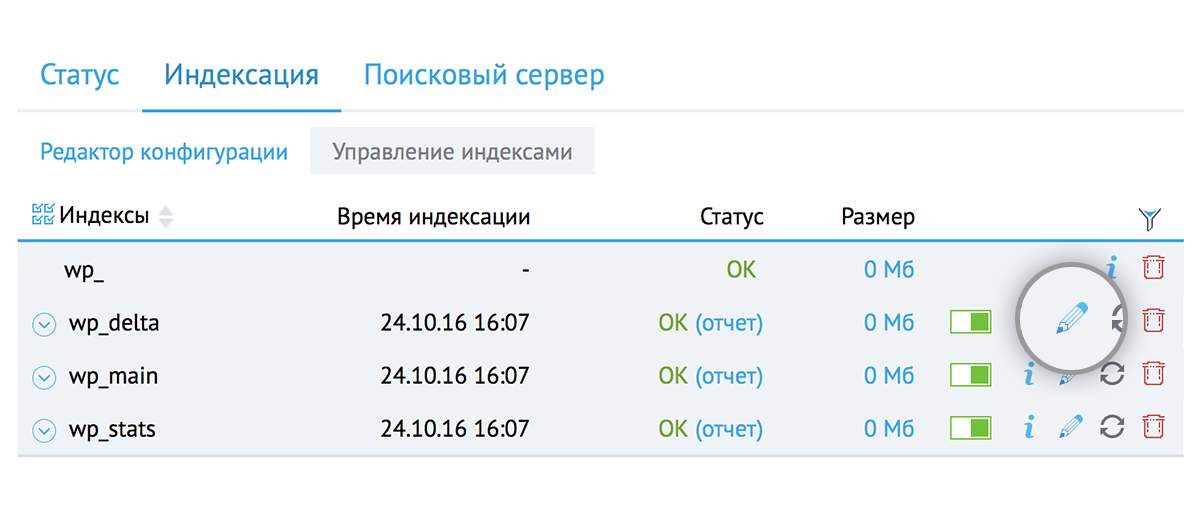
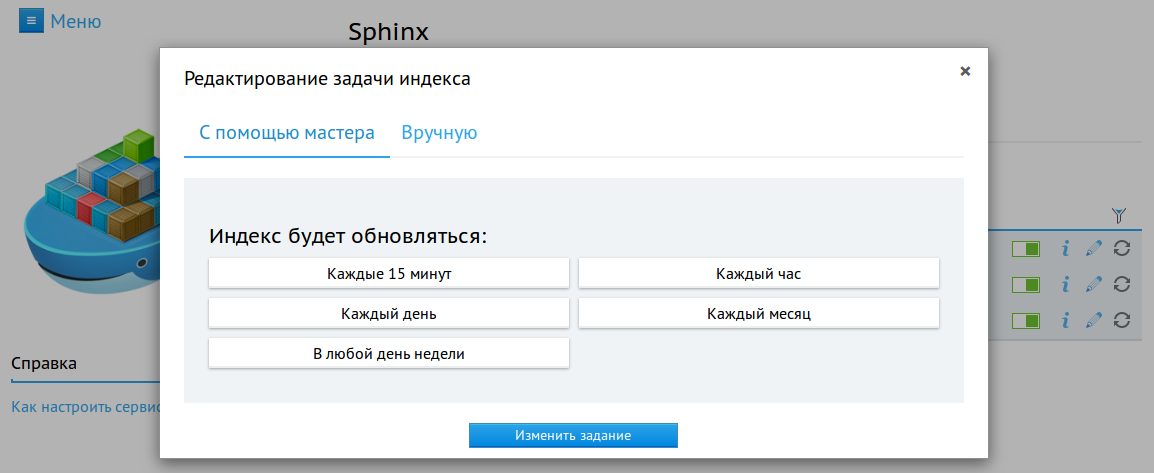
Можно указать свою периодичность обновления индекса:
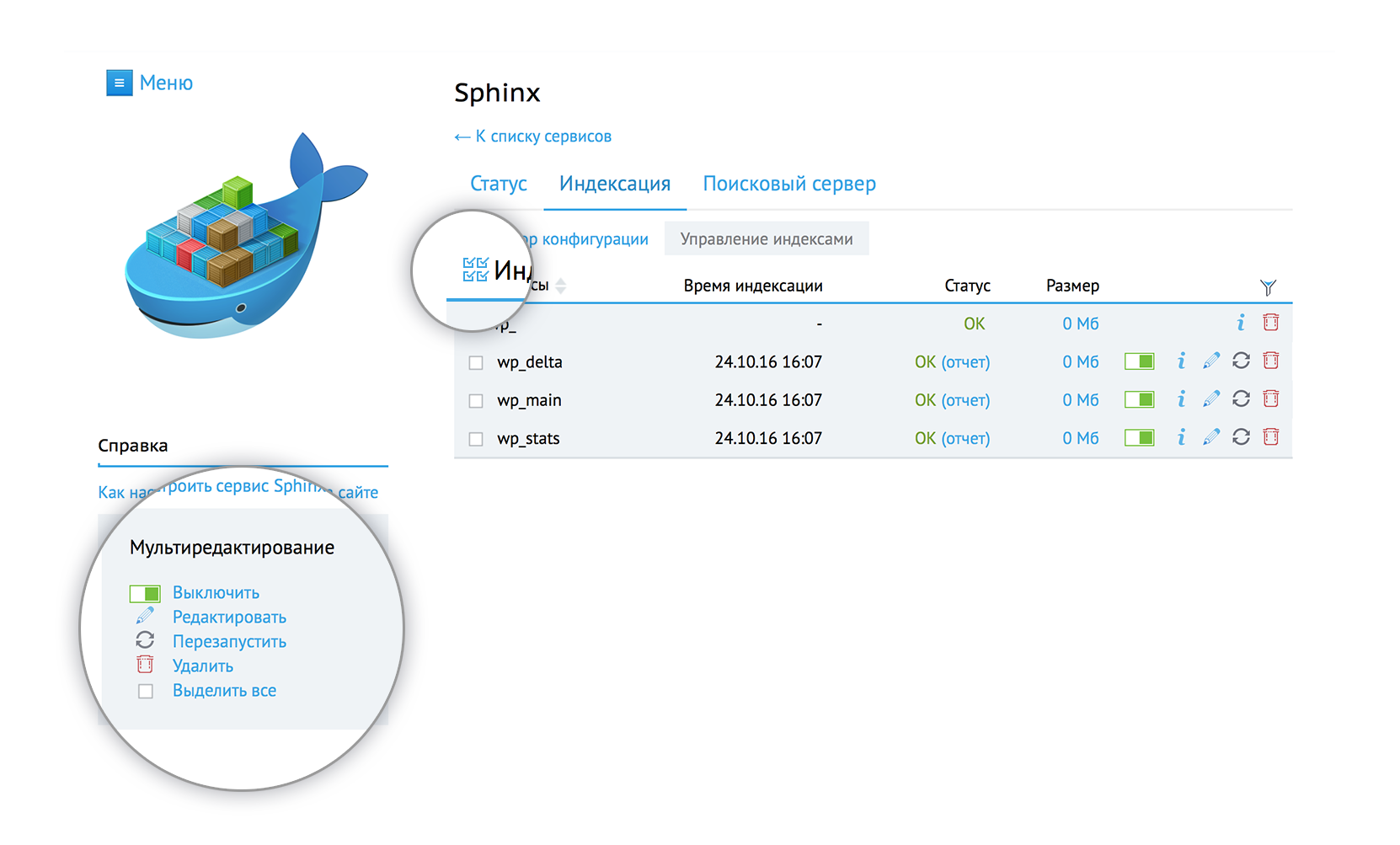
При большом количестве индексов, для удобства, можно воспользоваться мультиредактированием:
При необходимости Вы можете подключать собственные словари. Для этого их необходимо разместить в каталогe .service/sphinx/service-account___sphinx_base/static_data/conf/dict .
Путь указан от корневого каталога учётной записи. В приведённом примере необходимо заменить account на Ваш логин, base — на суффикс имени базы данных (часть имени после символа «_»)
После этого через редактор конфигурации к опции «morphology» добавьте значение «lemmatize_ru» или «lemmatize_ru_all». При указании «lemmatize_ru_all» индексироваться будут все нормальные формы слова, если их несколько.
Обратите внимание!
Код языка зависит от языка словаря, например, если добавляются англоязычные словари, нужно добавить «lemmatize_en» или «lemmatize_en_all».
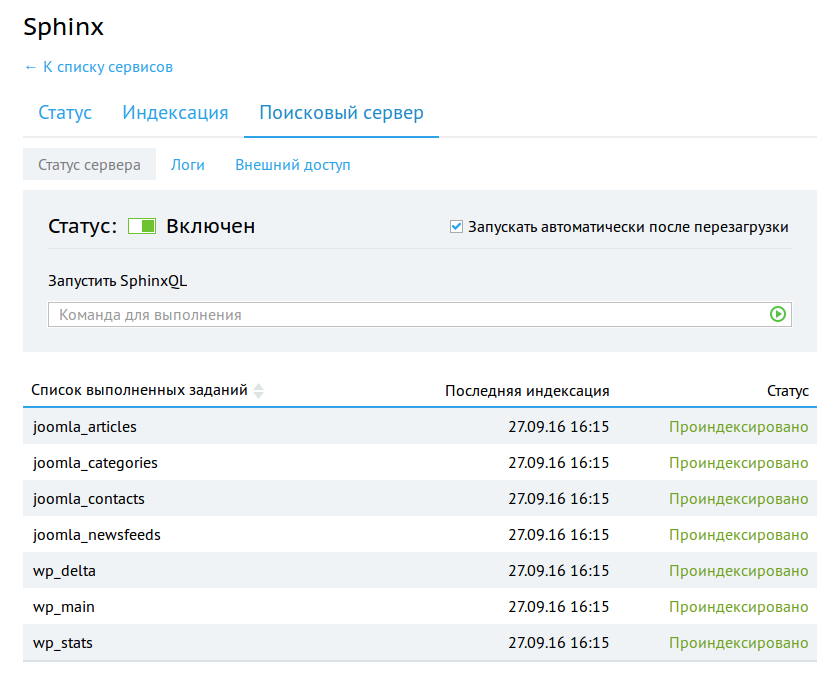
Вкладка «Поисковый сервер» позволяет работать с самой поисковой системой (searchd).
Есть возможность включить или выключить поисковый демон. Выполнить быстрый запрос к индексированным данным с помощью SphinxQL.
Увидеть список последних выполненных заданий по индексации.
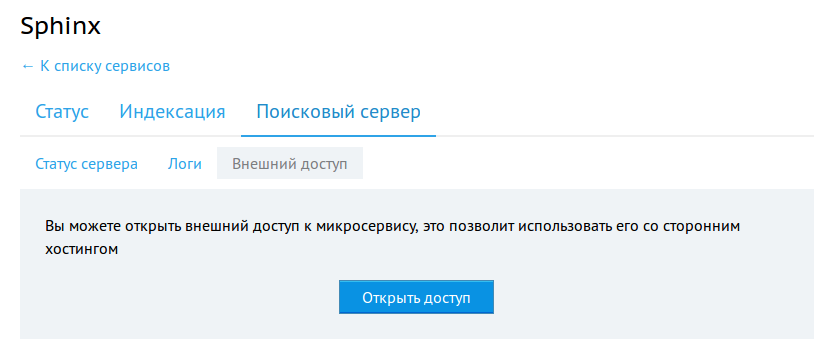
Или же открыть внешний доступ к сервису.
После включения необходимо добавить хотя бы один IP адрес, которому будет разрешено подключение к Sphinx.
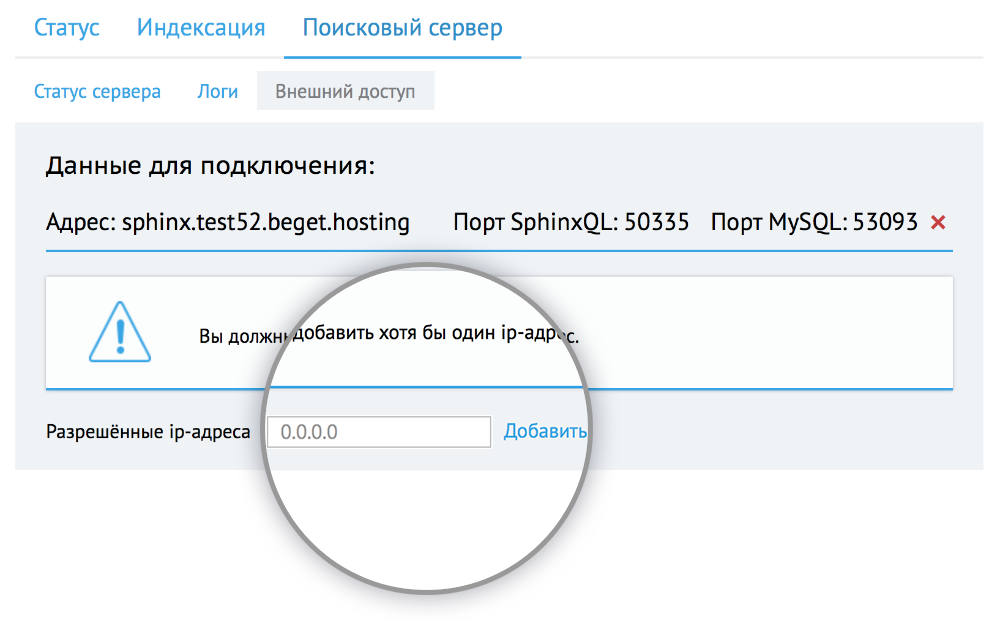
При подключении к Sphinx удаленно следует использовать данные которые указаны на странице.
Хост для подключения — sphinx.ваш_логин.beget.hosting
54729 — порт для подключения к Sphinx
55456 — порт для подключения к SphinxQL
Удачной работы! Если возникнут вопросы — напишите нам, пожалуйста, тикет из Панели управления аккаунта, раздел «Помощь и поддержка».
Источник: beget.com
Поисковая машина Sphinx: основные возможности, применение

В наши дни вряд ли кто-то захочет выбирать товары в интернет-магазине, где нужно разбираться в категориях или прокручивать длинные списки товаров.
Существует множество доступных инструментов, которые могут сделать внутренний поиск по сайту быстрым, интуитивно понятным и адаптированным к любым потребностям клиентов.

Поисковая машина Sphinx, кажется, обещает именно это. Полнотекстовая поисковая система является одновременно гибкой и быстрой.
Sphinx работает как автономный сервер и не хранит текст для себя. Он создает индекс, основанный на запросе SQL, который извлекает документы из базы данных, сохраняет индексы и на более позднем этапе возвращает строки, соответствующие запросу.

Что такое Sphinx
Поисковая машина Sphinx – это полнотекстовая поисковая система, которая бесплатна, быстра и масштабируема. Она предназначена для производительности и актуальности. Не имеет аналогов ни в одной традиционной базе данных.
Большое количество известных сайтов с высоким трафиком полагаются на него для продвинутого уровня поиска и масштабируемости
Основные возможности Sphinx
Sphinx помогает включить и повысить ценность поиска и масштабируемости благодаря следующим характеристикам, которые делают его популярным среди тысяч разработчиков и продавцов электронной коммерции.
- Высокая скорость поиска (до 150-250 Мбит/с на ядре с 1 000 000 документов).
- Поддержка распределенного поиска в реальном времени.
- Высокая скорость индексации (до 10-15 Мбит/с на одно ядро).
- Высокая масштабируемость (самый большой из известных кластеров способен индексировать до 3 000 000 000 документов и может обрабатывать более 50 миллионов запросов в день).
- Одновременная поддержка нескольких полей (до 32 по умолчанию) для полнотекстового поиска документов.
- Возможность поддерживать ряд дополнительных атрибутов для каждого документа (например, группы, метки времени и т. д.).
- Использование стоп-слов.
- Поддержка различных API языков программирования (например, для PHP, Python, Java, Perl, Ruby, .NET и C ++ и т. д.).
- Возможность обрабатывать как однобайтовые кодировки, так и UTF-8.
- Морфологический поиск.
- Интеграция с наиболее популярными системами управления базами данных (например, MySQL, PostgreSQL)
В целом поисковая машина Sphinx имеет более 50 различных функций (и это число постоянно растет).

Как работает Sphinx
Вся сложность схемы работы поисковика суммируется в 2 ключевых моментах:
- используя исходную таблицу, Sphinx создает собственную базу данных индексов;
- затем, когда пользователь отправляет запрос API, Sphinx возвращает массив идентификаторов, которые соответствуют идентификаторам в исходной таблице.
Зачем использовать Sphinx
Основная причина, по которой следует его использовать, — скорость поиска. Обычные поиски пользователя в MySQL занимают значительно больше времени, чем поиск в Sphinx. Пользователь начинает замечать разницу, как только его база данных будет иметь миллионы записей. Если база данных небольшая (например, форум из 100 пользователей), это не совсем то, что нужно. Хотя можно попробовать.
Плюс есть интересные функции, такие как морфология слова (если пользователь ищет кошек, это будет соответствовать кошке, если он ищет бега, это будет соответствовать бегу, бегам и т. д.).
Другая причина – это полнотекстовый поиск. Задумывался ли кто-то о том, что во время осуществления поиска двух слов в Google он будет искать их в том же абзаце или в двух абзацах (или в предложении), но не по всей странице? Sphinx же позволяет делать похожие вещи.

Масштабируемость заключается в следующем. Если у пользователя большие базы данных на многих серверах, Sphinx позаботится об этом. И приложение будет считать, что оно работает на одном сервере. Sphinx может снять большую часть нагрузки с PHP-серверов с точки зрения обработки и поиска информации.
Sphinx немного отличается от того, к чему пользователь привык с запросами MySQL. Так что не стоит ожидать получить все мгновенно.
Что такое индексация
Sphinx извлекает данные из таблицы в базе данных MySQL и выполняет для них процесс, называемый индексацией. Индексация создает файл, который можно легко найти с помощью Sphinx. Например, если пользователь попытается найти документ в Microsoft Word, он будет искать слова одно за другим в тексте документа. В очень больших документах поиск может быть очень медленным.
С другой стороны, Sphinx производит индексацию перед выполнением любых поисков. Это создает индекс, который можно эффективно искать, а не отыскивать слово за словом по всему документу. Хорошим примером является индекс энциклопедии.
Если пользователь хочет найти информацию о кошках, он мог бы делать то же, что и Microsoft Word, и читать каждую страницу энциклопедии в поисках появления слова «кошка». Или он может посмотреть алфавитный указатель в конце книги, где написано, что о кошках информация размещена на страницах 104, 195 и 653. Так гораздо проще.

Можно искать только то, что проиндексировано
Что необходимо помнить, так это то, что Sphinx может искать только в индексе. Это означает, что каждый раз, когда пользователь хочет найти последние результаты, он должен обновить индекс.
Доступ к данным
Если пользователь уже работал с PHP с MySQL, ему будет намного проще. В противном случае ему, вероятно, следует изучить PHP и MySQL.
Поисковая машина Sphinx обычно возвращает идентификаторы MySQL, а не данные.
Главное, что необходимо помнить о Sphinx, это то, что он не извлекает данные. В первую очередь он получает идентификаторы документов. Sphinx делает интенсивную часть, которая ищет конкретные записи. Затем пользователь может выполнить простую часть через MySQL, который получает этот документ.
Так, например, если Sphinx извлекает идентификаторы документов 1, 5 и 7 из индекса, то потребуется выполнить запрос в MySQL для получения записей (вероятно, с идентификаторами 1,5 и 7). Можно подумать, что это примитивно, но MySQL требует очень мало ресурсов для поиска идентификатора документа по сравнению с поиском слова.
Пример. Скажем, Sphinx вытаскивает документы с идентификаторами 1, 5, 7 (SELECT * FROM documents WHERE id IN (1,5,7)).
Пользователь сообщает MySQL, что нужно выбрать все столбцы из таблицы документов (или любой другой, в которой был результат), где идентификатор (или то, что было названо его полем) равен 1, 5 или 7. И затем можно использовать mysql_fetch_array в PHP, дабы посмотреть на данные и делать с ними, что угодно.
После того как будет освоена работа в Sphinx для упорядочивания результатов, можно сохранить порядок следующим образом:
- Сохранение порядка результатов в массиве (просто сохранить свойство id для совпадений).
- Выполнение IMPLODE для массива с использованием $result = implode(«,», $array), где $array – это массив результатов пользователя. Result будет хранить строку идентификаторов результатов, разделенных запятой. · SELECT * FROM documents WHERE id IN ($result) ORDER BY FIELD(id,$result).
Здесь пользователь сообщает MySQL, что необходимо упорядочить результаты по полю id в порядке, указанном в $result.
Это может показаться сложным, но к этому быстро привыкаешь, и вскоре пользователь сам напишет функции, которые справятся со всем этим для него.

Заключительные выводы
Использование Sphinx вместо MySQL может обеспечить значительные преимущества в скорости. Sphinx идеально подходит для поиска статических таблиц. Но в то же время для часто обновляемых строк возможность использования простых индексных файлов отсутствует. Вместо этого нужно либо внедрить дельта-файлы, либо перейти на индексацию в реальном времени.
И то, и другое решение несет дополнительные затраты производительности. И в заключение: для более эффективной работы в Sphinx необходимо планирование, потому что пользователь должен заблаговременно установить все необходимые источники и индексные файлы.
Замена Sphinx для MySQL не тривиальна, но и не так сложна, чтобы отказаться от этой возможности. В случае если необходима высокая скорость поиска, следует подумать о переходе с MySQL на Sphinx, даже когда пользователь не нуждается в полнотекстовом поиске.
Источник: fb.ru
ПО СКУД Sphinx, базовый модуль, до 50 карт доступа
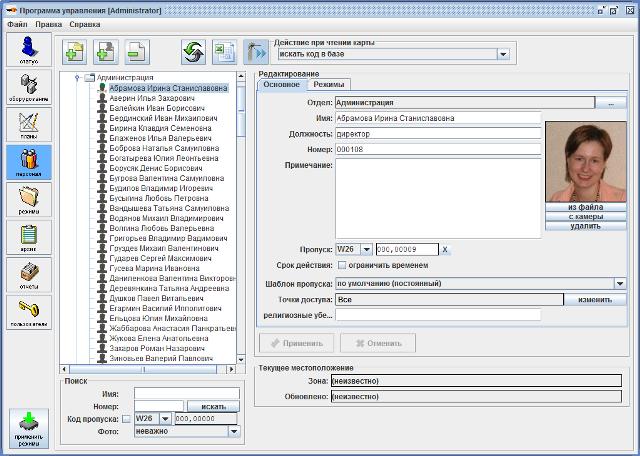
Программное обеспечение «Сфинкс» является фундаментом построения современной системы контроля доступа. Данное ПО обладает мощным функционалом, который может быть расширен при помощи дополнительных модулей.
Базовый модуль обеспечивает основные функции СКУД, с его помощью решаются все основные задачи по настройке системы в целом и контролю статуса ее компонентов:
- наблюдение за состоянием элементов системы
- тонкая настройка параметров контроллера
- организация зонального контроля
- настройка пресечения повторных проходов
- ручное управление преграждающими устройствами
Базовое ПО «Сфинкс» обладает обширным встроенным функционалом для управления учетными записями объектов доступа, которыми могут быть: отдел, сотрудник, посетитель, автомобиль. Возможно назначение объекту доступа фотографии, добавления любых дополнительных полей для сведений, необходимых именно вам.
Список объектов доступа имеет гибкую иерархическую структуру с любой глубиной вложенности. Для каждого из элементов доступно редактирование данных, а также установка режимов ограничения доступа.
Режимы доступа
Режимы доступа используются системой «Сфинкс» для принятия решения о предоставлении или непредставлении доступа объекту. Возможности настройки режимов доступа достаточно широки, можно настроить:
- повторяющуюся последовательность дней заданной длины (от 1 до 32 дней)
- рабочие графики любой периодичности (два через два, сутки через трое и пр.) с возможностью учета праздников и других исключений
- любые сложные схемы доступа (санкция охранника на проход, дополнительный запрос PIN-кода и пр.)
- работу с дополнительным считывателем (картоприемником): разрешать проход на выход только через картоприемник и пр.
Для полноценного учета рабочего времени и создания отчетов за любой исторический период (табель Т13, журнал нарушений рабочей дисциплины и пр.) возможно использование дополнительного модуля программного обеспечения «Учет рабочего времени»
Интеграция СКУД с системой видеонаблюдения
Система «Сфинкс» позволяет осуществлять взаимодействие со следующими системами видеонаблюдения:
- Trassir
- Ewclid
- Domination
- Интеллект
- Axxon Next
- Macroscop
- Линия
- VideoNet
- Каскад-Поток
Интеграция с системой видеонаблюдения обеспечивает возможность привязки событий системы контроля доступа к видеоряду, фотоидентификацию входящих, возможность борьбы с передачей карт доступа сотрудниками друг другу.
Cистемы биометрической идентификации
СКУД «Сфинкс» на глубоком уровне интегрирована с биометрическими считывателями отпечатков пальца «BioSmart». Данная интеграция на стороне СКУД «Сфинкс» обладает следующими функциями:
- занесение отпечатков пальца сотрудников в систему
- поддержка разных типов идентификации: локальной и серверной
Помимо этого, для идентификации в СКУД «Сфинкс» можно использовать любые биометрические считыватели со стандартными выходными интерфейсами, включая другие считыватели отпечатка пальца, радужной оболочки глаза, геометрии руки и прочих.
Поэтажные графические планы (карты территорий)
Для удобного визуального контроля происходящих в реальном времени событий предназначен редактор графических планов. Вы можете загрузить имеющийся план помещения в качестве фона, расставить на нем элементы системы контроля доступа (двери, турникеты, камеры видеонаблюдения) и наглядно видеть происходящие события с привязкой к их местонахождению.
Кроме того, данные элементы не только отображают состояние соответствующих компонент системы, но и позволяют ими управлять (разблокировка точки доступа, просмотр видео с камер и пр.).
Лицензирование
Базовый модуль лицензируется по количеству карт доступа, зарегистрированных на сервере. Количество рабочих мест не лицензируется, приобретенный модуль может использоваться на неограниченном количестве рабочих мест, подключенных к одному серверу «Сфинкс».
. пока нет отзывов. Будете первым?
Чтобы приобрести Сфинкс sphinx_base_50 в розницу или оптом, звоните: +7 (495) 204-16-62 (многоканальный) или присылайте заявку на [email protected]
Источник: www.securecam.ru