
Записки программиста
RabbitMQ — приложение, предоставляющее шину для обмена сообщениями по протоколу AMQP. Написан «кролик» на Erlang, а следовательно автоматически масштабируем, отказоустойчив и учится за две недели 🙂 RabbitMQ используют в таких компаниях, как VMware, Mozilla и AT
Еще
Опубликовано: 22.12.2021
Используемые термины: RabbitMQ, Linux, Ubuntu. В данной инструкции мы разберемся, как работать с брокером сообщений RabbitMQ. Для начала мы выполним установку программного обеспечения на Linux Ubuntu, после настроим его и рассмотрим пример использования.
Rabbit — Программа для учета кроликов. Как работать
Установка
Сервер RabbitMQ есть в стандартном репозитории Ubuntu, поэтому можно сразу выполнить установку с помощью apt. Однако, версия в репозитории может быть не самой актуальной. Поэтому мы рассмотрим процесс с настройкой официального репозитория для установки RabbitMQ. Для начала установим curl:
apt install curl
После выполныем две команды:
curl -s https://packagecloud.io/install/repositories/rabbitmq/rabbitmq-server/script.deb.sh | sudo bash
curl -s https://packagecloud.io/install/repositories/rabbitmq/erlang/script.deb.sh | sudo bash
В нашу систему будут добавлены репозитории для установки RabbitMQ и erlang. Теперь можно устанавливать брокер:
apt install rabbitmq-server
Однако, в моем случае возникла проблема с репозиторием erlang. Если вы столкнетесь с той же проблемой, можно вручную установить необходимые пакеты или отказаться от использования официального репозитория.
После установки брокера на Ubuntu, он автоматически будет запущен и настроен для автозапуска. Проверить можно командой:
systemctl status rabbitmq-server
Переходим к настройке.
Первичная настройка
Нам нужно создать виртуальный хост для изоляции рабочего пространства, а также пользователя, которому дадим полный доступ на созданный виртуальный хост. Создание последнего выполняется командой:
rabbitmqctl add_vhost test_host
* в данном примере мы создадим тестовый хост test_host. Список всех хостов можно увидеть командой:
rabbitmqctl list_vhosts
Создаем пользователя:
rabbitmqctl add_user test_user
Система запросит ввод пароля.
Придумываем и вводим его.
Поменять пароль мы можем командой:
rabbitmqctl change_password test_user
* в данном примере мы поменяем пароль для пользователя test_user.
Теперь дадим права созданному пользователю к созданному виртуальному хосту:
rabbitmqctl set_permissions -p test_host test_user «.*» «.*» «.*»
Сделаем нашего пользователя администратором:
rabbitmqctl set_user_tags test_user administrator
Разрешаем консольную команду rabbitmqadmin:
rabbitmq-plugins enable rabbitmq_management
Брокер сообщений RabbitMQ | Tutorial для начинающих на русском | Урок 1 | Введение
Выполним тестовый запрос
rabbitmqadmin -u test_user -p test list vhosts
Мы должны увидеть что-то на подобие:
Использование по сети
По умолчанию, сервис запускается для работы как на локальном сервере, так и обработки запросов по сети. Но нам нужно убедиться в работоспособности прохождения сетевых запросов. Если на нашем сервере используется брандмауэр, разрешаем порт 5672:
iptables -I INPUT -p tcp —dport 5672 -j ACCEPT
Для сохранения правила используем утилиту iptables-persistent:
apt-get install iptables-persistent
netfilter-persistent save
Пример подключения с использованием Python
Для простоты, мы запустим скрипт для отправки сообщения в очередь и приемки на одном и том же компьютере, куда установили сервер rabbitmq. Сам пример, в большей степени, взят с официального сайта. Установим питон и необходимые компоненты:
apt install python3 python3-pip
Обновляем менеджер пакетов pip:
pip3 install —upgrade pip
Устанавливаем библиотеку pika для работы с RabbitMQ:
pip3 install pika
Создадим каталог, в котором мы создадим скрипты:
mkdir /scripts
Создадим скрипт для отправки информации в очередь:
vi /scripts/rabbit_test_send.py
Пример скрипта:
- #!/usr/bin/env python3
- # -*- encoding: utf-8 -*-
- import pika
- credentials = pika.PlainCredentials(‘test_user’, ‘test’)
- parameters = pika.ConnectionParameters(‘localhost’, 5672, ‘test_host’, credentials)
- connection = pika.BlockingConnection(parameters)
- channel = connection.channel()
- channel.queue_declare(queue=’hello’)
- channel.basic_publish(exchange=», routing_key=’hello’, body=’Hello World!’)
- connection.close()
- print(«Your message has been sent to the queue.»)
- строки 6-8: задаем параметры для подключения к нашему серверу сообщений. Обратите внимание, что мы используем логин и пароль для созданного ранее пользователя test_user. Также мы подключаемся к созданному хосту test_host.
- строки 10-12: подключаемся к серверу, создаем очередь с названием hello и отправляем в очередь сообщение Hello World!
Разрешаем запуск скрипта:
chmod +x /scripts/rabbit_test_send.py
Теперь мы можем посмотреть состояние очереди из командной строки Linux.
rabbitmqadmin -u test_user -p test list queues
Мы увидим, примерно, такую картину:
* обратите внимание, что сообщение в очередь могут попадать с задержкой (2-3 секунды). Если мы увидим 0 сообщений, немного подождем.
Теперь создадим скрипт для получения сообщения:
- #!/usr/bin/env python3
- # -*- encoding: utf-8 -*-
- import pika
- credentials = pika.PlainCredentials(‘test_user’, ‘test’)
- parameters = pika.ConnectionParameters(‘localhost’, 5672, ‘test_host’, credentials)
- connection = pika.BlockingConnection(parameters)
- channel = connection.channel()
- channel.queue_declare(queue=’hello’)
- def callback(ch, method, properties, body):
- print(«Received %r» % body)
- channel.basic_consume(queue=’hello’, auto_ack=True, on_message_callback=callback)
- channel.start_consuming()
- print(‘To exit press CTRL+C’)
- connection.close()
- строки 6-8: задаем параметры для подключения к нашему серверу сообщений. Обратите внимание, что мы используем логин и пароль для созданного ранее пользователя test_user. Также мы подключаемся к созданному хосту test_host.
- строки 10-11: подключаемся к серверу, подключаемся к очереди с названием hello.
- строки 13-14: функция для отображения содержимого очереди.
- строка 16: параметры чтения очереди. Обратите внимание, что мы передаем данные очереди в нашу функцию callback, которую определили в строке 13,
- строка 18: запускаем процесс чтения данных в очереди.
Разрешаем запуск скрипта:
chmod +x /scripts/rabbit_test_recieve.py
На экране должно появиться наше сообщение. Чтобы прервать выполнение скрипта, нажимаем CTRL+C (на экране появится некрасивый вывод, но это не страшно в рамках нашего теста).
Снова смотрим очередь:
rabbitmqadmin -u test_user -p test list queues
Она должна стать пустой.
Источник: www.dmosk.ru
Краткое введение в RabbitMQ

RabbitMQ — это полноценная и щедро удобренная фичами очередь сообщений. В отличие от ZeroMQ, который встраивается в приложения, RabbitMQ — сервис-посредник. Он разграничивает права доступа, поддерживает шифрование, сохранение сообщений на диск (чтобы пережить плановое отключение электричества), работу в кластерах и даже дублирование сервисов для повышенной живучести. К тому же он написан на Erlang, за что автоматически становится неубиваемым и поддерживаемым на большинстве популярных ОС.
В этом посте мы посмотрим, насколько тяжело отправлять и получать сообщения с RabbitMQ, да и вообще, на что он похож вблизи. В качестве платформы будет Убунта (запертая внутри Docker контейнера), но сгодился бы и Mac, и Windows.
Установка
Я не буду фокусироваться на установке слишком сильно, тем более что официльная документация весьма ничего, но самый простой способ получить работающий RabbitMQ на своей машине — через Docker и rabbitmq образ.
Run RabbitMQ in Docker
$ docker run — ti rabbitmq bash
Внутри получившегося контейнера будет полностью рабочий сервер сообщений, который нужно просто запустить:
Start RabbitMQ server
$ service rabbitmq — server start
#[ ok ] Starting message broker: rabbitmq-server.
Если с Докером у вас не сложилось, то на настоящей машине установить RabbitMQ тоже не проблема. Вот на что это похоже на Убунте:
Install RabbitMQ at Ubuntu
echo ‘deb http://www.rabbitmq.com/debian/ testing main’ | sudo tee / etc / apt / sources .list .d / rabbitmq .list
wget — O — https : //www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add —
sudo apt — get update
sudo apt — get install rabbitmq — server
На других системах, возможно, будет даже легче, но я всё равно очень рекомендую потратить немного времени и разобраться с Docker, потому что он идеально подходит для изучения таких вот вещей. Просто берем образ с уже установленным RabbitMQ, Redis, Elasticsearch, Jenkins — да вообще с чем угодно, играемся вволю, а потом удаляем контейнер целиком.
Отправка и получение сообщений с rabbitmqadmin
Отправить и получить сообщение можно не написав ни строчки кода. В комплект с RabbitMQ идёт management plugin, в котором есть милая python-утилитка — rabbitmqadmin . С ней можно создавать и удалять очереди сообщений, проверять их статус, а так же отправлять, собственно, сами сообщения. Management plugin выключен по умолчанию, так что его придётся сначала включить. Правда, можно было бы просто взять rabbitmq:management образ, где это уже сделано, но мы бы сэкономили всего одну команду.
Включаем rabbitmqadmin
Enable management plugin
$ rabbitmq — plugins enable rabbitmq_management
#The following plugins have been enabled:
# webmachine
# rabbitmq_web_dispatch
# amqp_client
# rabbitmq_management_agent
# rabbitmq_management
..и всё. rabbitmqadmin расположен в удивительной глубины и непроизносимости папке, так что его сразу стоит добавить либо в PATH переменную, либо сразу в /usr/local/bin/.
Create shortcut to rabbitmqadmin
find / var / lib / rabbitmq — name rabbitmqadmin | xargs — I < >sudo ln — s < >/ usr / local / bin / rabbitmqadmin
sudo chmod + x / usr / local / bin / rabbitmqadmin
Теперь попробуем что-нибудь создать.
Играем с очередями и сообщениями
RabbitMQ — сервис-посредник, который создаёт и управляет очередями сообщений. В архитектуре распределенного приложения он будет где-то посередине:

Во-первых, давайте посмотрим, какие очереди в нём есть по-умолчанию:
List RabbitMQ queues
$ rabbitmqadmin list queues
Никаких. Но это вполне себе поправимо:
Create message queue
$ rabbitmqadmin declare queue name = demoqueue durable = false
#queue declared
$ rabbitmqadmin list queues
| name | messages |
| demoqueue | 0 |
Теперь у нас есть новая очередь с названием «demoqueue». Так как она держит сообщения в памяти ( durable = false ), то падение сервиса похоронит под собой все сообщения, которые он не успел отправить. Если это проблема, то можно сделать durable = true .
Кстати о сообщениях — отправим-ка чего:
Publish RabbitMQ message
$ rabbitmqadmin publish exchange = amq .default routing_key = demoqueue
payload = «Behold! This is the message»
# Message published
$ rabbitmqadmin list queues
| name | messages |
| demoqueue | 1 |
Команда отправки сообщения не содержит ни одного слова, хоть отдалённо напоминающего «отправка» и «сообщение», так что стоит чуть-чуть углубиться в терминологию.
Кто такой AMQP
В мире очередей сообщений есть попытка прийти к общему стандарту, и эта попытка сегодня называется AMQP (Advanced Message Queuing Protocol). По этому стандарту между отправителем сообщения и очередью должен быть еще один игрок — exchange. Отправитель кладёт сообщение в exchange, а уже exchange в зависимости от своего типа и того, какие очереди к нему привязаны, решает, куда оно отправится.
Например, в AMQP есть exchange типа «fanout», который отправляет копии сообщения сразу всем «своим» очередям.
Другой тип exchange — «direct» — отправляет сообщение только одной очереди. Какой именно — определяет маршрутный ключ (routing key), подорожником прикладываемый к сообщению.
Наконец, чтобы полностью соответствовать протоколу AMQP, у брокера должны быть несколько exchange по-умолчанию. Один из них — amq.default — должен иметь тип ‘direct’. Как только создаётся новая очередь, она автоматически к нему привязывается, и routing key будет совпадать с её именем.
Так как RabbitMQ поддерживает AMQP полностью, то в нём есть и exchange, и amq.default, так что отправка сообщения такой странной командой теперь выглядит чуть-чуть более логичной:
Источник: dotsandbrackets.com
Apache Kafka vs RabbitMQ в Big Data: сходства и различия самых популярных брокеров сообщений

Apache Kafka – не единственный программный брокер сообщений и система управления очередями, используемая в высоконагруженных Big Data проектах. Кафка часто сравнивают с другим популярным продуктом аналогичного назначения – RabbitMQ. В сегодняшней статье мы рассмотрим, чем похожи и чем отличаются Apache Kafka и RabbitMQ, а также поговорим о том, что следует выбирать в конкретных случаях для практического применения.
Что такое RabbitMQ и как он работает
RabbitMQ – это программный брокер сообщений на основе стандарта AMQP, написанный на языке Erlang и состоящий из следующих основных компонентов [1]:
- Mnesia – распределенная СУБД реального времени для хранения сообщений, также написанная на языке Erlang – надстройка над ETS- и DETS-таблицами, предоставляющая уровень транзакций и распределённого выполнения [2];
- сервер;
- библиотеки поддержки протоколов HTTP, XMPP и STOMP, клиентские библиотеки AMQP для Java и .NET Framework [1];
- различные плагины (для мониторинга и управления через HTTP и веб-интерфейс, для передачи сообщений между брокерами и др.) [1].
RabbitMQ поддерживает несколько языков программирования (Perl, Python, Ruby, PHP), а также обеспечивает горизонтальное масштабирование для построения кластерных решений [1]. Поэтому RabbitMQ, который неформально называют «Кролик», довольно часто применяется в различных Big Data проектах. Однако, в связи с некоторыми его технологическими особенностями реализации, он не является полноценной заменой Apache Kafka.
В упрощенном виде управление сообщениями выполняется в RabbitMQ следующим образом [3]:
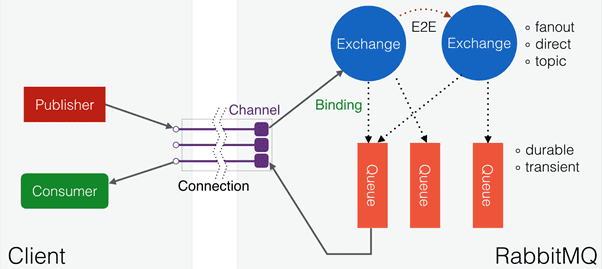
- отправители (publishers) отправляют сообщения на обменники (exchange);
- обменники отправляют сообщения в очереди и в другие обменники;
- при получении сообщения RabbitMQ отправляет подтверждения отправителям;
- получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь они получают;
- RabbitMQ проталкивает (push) сообщения получателям;
- получатели отправляют подтверждения успеха или ошибки получения сообщения;
- после успешного получения сообщение удаляется из очереди.
Сходства Apache Kafka и RabbitMQ
Несмотря на принципиальные отличия этих систем обмена сообщениями, между ними довольно много общих моментов [4]:
- Прикладное назначение – Apache Kafka и RabbitMQ являются брокерами программных сообщений и используются для обмена информацией между различными приложениями.
- Схема обмена сообщениями – оба брокера работают по схеме «издатель-подписчик» (отправитель-получатель), когда источники данных направляют потоки информации, а получатели обрабатывают их по мере потребности.
- Потоки и пакеты сообщений – Кафка и Кролик в первую очередь позиционируются для работы с непрерывными потоками информации, однако, они позволяют объединять сообщения в пакеты. Kafka делает это более явно, повышая эффективность от пакетирования благодаря своим возможностям по распределению пакетов, а в RabbitMQ пакетирование является скорее «мнимым» из-за пассивной модели приёма, не препятствующей конфликтам получателей.
- Уведомления о сообщениях — Kafka и RabbitMQ обмениваются сигналами с отправителями и получателями при отправке и получении сообщений.
- Стратегии доставки – оба брокера способны реализовать стратегии «как максимум однократная доставка» и «как минимум однократная доставка», что позволяет сократить риски потери или дублирования сообщений.
- Репликация – обе системы обеспечивают репликацию сообщений.
- Гарантии отправки – Apache Kafka и RabbitMQ гарантируют порядок отправки сообщений с помощью уведомлений и стратегий доставки.
Чем Кафка отличается от Кролика
Основные отличия Apache Kafka и RabbitMQ обусловлены принципиально разными моделями доставки сообщений, реализуемыми в этих системах. В частности, Kafka действует по принципу вытягивания (pull), когда получатели (consumers) сами достают из топика (topic) нужные им сообщения. RabbitMQ, напротив, реализует модель проталкивания, отправляя необходимые сообщения получателям. В связи с этим Кафка отличается от Кролика по следующим критериям [3]:
- Сохранение сообщений – RabbitMQ помещает сообщение в очередь FIFO (First Input – First Output) и отслеживает статус этого сообщения в очереди, а Kafka добавляет сообщение в журнал (записывает на диск), предоставляя получателю самому заботиться о получении нужной информации из топика. Кролик удаляет сообщение после доставки его получателю, а Кафка хранит сообщение до тех пор, пока не наступит момент запланированной очистки журнала. Таким образом, Apache Kafka сохраняет текущее и все прежние состояния системы и может использоваться в качестве достоверного источника исторических данных, в отличие от RabbitMQ.
- Балансировка – благодаря pull-модели доставки сообщений RabbitMQ сокращает время задержки, однако возможно переполнение получателей, если сообщения прибудут в очередь быстрее, чем те могут их обработать. Поскольку в RabbitMQ каждый получатель запрашивает/выгружает разное количество сообщений, то распределение работы может стать неравномерным, что повлечет задержки и потерю порядка сообщений во время обработки. Для предупреждения этого каждый получатель Кролика настраивает предел предварительной выборки (QoS) – ограничение на количество скопившихся неподтвержденных сообщений. В Apache Kafka балансировка нагрузки выполняется автоматически путем перераспределения получателей по разделам (partition) топика.
- Пропускная способность – Kafka гарантирует порядок сообщений в разделе топика (partition) без конкурирующих получателей, что позволяет объединять сообщения в пакеты для более эффективной доставки и повышает пропускную способность системы.
- Масштабируемость – Кафка считается более адаптивной к масштабированию, обеспечивая ежедневный обмен миллиардами сообщений. Однако, стоит отметить, что далеко на каждый Big Data проект нуждается в таких высоких цифрах.
- Маршрутизация – RabbitMQ включает 4 способа маршрутизации на разные обменники (exchange) для постановки в различные очереди, что позволяет использовать мощный и гибкий набор шаблонов обменов сообщениями. Кафка реализует лишь 1 способ записи сообщений на диск, без маршрутизации.
- Упорядочивание сообщений – Кролик позволяет поддерживать относительный порядок в произвольных наборах (группах) событий, а Кафка обеспечивает простой способ поддержания упорядочения с поддержкой масштабирования путем последовательной записи сообщений в реплицированный журнал (топик).
- Работа с клиентом – про Apache Kafka говорят «тупой сервер, умный клиент», что означает необходимость реализации логики работы с сообщениями на клиентской стороне, т.е consumer заботится о получении нужных сообщений. RabbitMQ – наоборот, «умный сервер, тупой клиент», поскольку этот брокер сам обеспечивает всю логику работы с сообщениями.
Кафка или Кролик: что выбирать для Big Data проекта
Обратной стороной широких и разнообразных возможностей RabbitMQ по гибкому управлению очередями сообщений (маршрутизация, шаблоны доставки, мониторинг получения) является повышенное потребление ресурсов и, соответственно, снижение производительности в условиях увеличенных нагрузок. А, поскольку именно такой режим работы характерен для Big Data систем, то в большинстве случаев Apache Kafka является наилучшим средством для управления сообщениями.
Например, в случае сбора и агрегации множества событий от IoT-устройств, клиентских метрик, лог-файлов и аналитики Big Data с перспективой увеличения источников информации понадобится Кафка. А если необходим быстрый сообщениями между несколькими сервисами, RabbitMQ отлично справится с этой задачей [5]. Кролик можно использовать для обработки событий в режиме реального времени, т.е. этот брокер — решение только для реагирования на события, которые происходят сейчас. Кафка, напротив, обеспечивает полную историческую достоверность и сохранность всех данных, а также упрощает их распространение. Исходные данные принадлежат только отправителю, но каждый получатель может их фильтровать, трансформировать, дополнять данными из других источников и сохранять в собственных базах данных [6].
Подводя итог сравнению Apache Kafka и RabbitMQ, можно сделать вывод, что выбор того или иного брокера в первую очередь зависит от нагрузки, в которой предполагается его использование. В случае адекватного применения каждая из этих систем обмена сообщениями будет эффективным инструментом реализации Big Data проекта.

О другой популярной альтернативе Kafka, Apache Pulsar, читайте здесь. А еще больше прикладных сведений по Кафка и других технологиях больших данных на практических курсах в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов, для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
Источник: www.bigdataschool.ru
Программа рэббит что это
В этом разделе помещены уроки по PHP скриптам, которые Вы сможете использовать на своих ресурсах.

Фильтрация данных с помощью zend-filter
Когда речь идёт о безопасности веб-сайта, то фраза «фильтруйте всё, экранируйте всё» всегда будет актуальна. Сегодня поговорим о фильтрации данных.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 10 Июня 2017 Просмотров: 22966 Комментариев: 0

Контекстное экранирование с помощью zend-escaper
Обеспечение безопасности веб-сайта — это не только защита от SQL инъекций, но и протекция от межсайтового скриптинга (XSS), межсайтовой подделки запросов (CSRF) и от других видов атак. В частности, вам нужно очень осторожно подходить к формированию HTML, CSS и JavaScript кода.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 9 Июня 2017 Просмотров: 18247 Комментариев: 0

Подключение Zend модулей к Expressive
Expressive 2 поддерживает возможность подключения других ZF компонент по специальной схеме. Не всем нравится данное решение. В этой статье мы расскажем как улучшили процесс подключение нескольких модулей.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 7 Июня 2017 Просмотров: 12095 Комментариев: 0

Совет: отправка информации в Google Analytics через API
Предположим, что вам необходимо отправить какую-то информацию в Google Analytics из серверного скрипта. Как это сделать. Ответ в этой заметке.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 6 Июня 2017 Просмотров: 20134 Комментариев: 0

Подборка PHP песочниц
Подборка из нескольких видов PHP песочниц. На некоторых вы в режиме online сможете потестить свой код, но есть так же решения, которые можно внедрить на свой сайт.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 4 Июня 2017 Просмотров: 28891 Комментариев: 0

Совет: активация отображения всех ошибок в PHP
При поднятии PHP проекта на новом рабочем окружении могут возникнуть ошибки отображение которых изначально скрыто базовыми настройками. Это можно исправить, прописав несколько команд.
Источник: ruseller.com