
Программа распознования документов что это такое
Содержание:
- А упала, Б — пропала
- Что такое оцифровка?
- Роль ABBYY
- Кейс без обновлений
- Как действовать?
- Где импортозамещение необходимо?
- Как найти системы импортозамещения?
- Оцифровка документов в цифровизации государства и бизнеса
А упала, Б — пропала
В январе 2022 года российский пионер разработки и крупный поставщик программного обеспечения для интеллектуальной обработки документов — компания ABBYY — отозвала свой софт из реестра отечественного ПО, курируемого Минцифрой.
Права на свои программы компания передала американским юридическим лицам. Таким образом разработчик решил сконцентрироваться на продажах за рубежом. Что это значит для отечественного рынка оцифровки документов?
Что такое оцифровка?
Оцифровка бумажного документа — это его сканирование с одновременным автоматическим переносом данных в информационную систему, базу данных. Простое сканирование не равно оцифровке. Скан для машины — всего лишь картинка.
Программы распознавания текста
Чтобы определить информацию на ней, нужно специальное ПО, благодаря которому машинный интеллект «считывает» текст, распознает картинку, переносит данные в систему, «поняв», какие данные и в каком поле документа соответствуют полям базы данных и т.д.
Роль ABBYY
Такое ПО для распознавания документов с прицелом на частных и корпоративных заказчиков разрабатывает ABBYY и ряд других российских и зарубежных компаний. Вендор занимал заметную долю рынка, связанного с оцифровкой стандартизированных документов — бухгалтерской первички, счетов-фактур, актов, накладных и т.д.
Компания продавала лицензии на модули для распознавания определённого количества таких документов. Это было удобно при расчетах, особенно в рамках госзакупок (ФЗ-44), хоть и стоило не дёшево.
Если для частного бизнеса перепрописка разработчика из России в США может не играть роли, то госведомствам и бизнесу с госучастием, среди которых много клиентов компании, есть о чем поразмыслить.
Готов ли российский IT-рынок предоставить конкурентоспособную замену — разбираемся с МегаФоном и экспертами по ссылке
Кейс без обновлений
Одна из структур очень крупной государственной компании, которая связана с большим оборотом первички, в 2015-2016 годах приобрела сервера и лицензии вендора на шаблоны обработки документов. К 2021 году стало понятно, что система распознаёт и обрабатывает 80% документопотока, а 20% — только частично.
Возник вопрос: как автоматизировать обработку этого остатка? Обновить лицензии может стоить около 30 млн. рублей, не считая доработок шаблонов на оставшиеся 20%, которые могут вылиться ещё в 15-20 млн. Итоговая сумма существенна.
Такая автоматическая обработка, безусловно, удобна и современна, но редко может окупиться. Если раньше компания или ведомство могли хотя бы продемонстрировать, что направляют расходы на импортозамещение, поддерживают отечественного производителя, сейчас так не получится.
Как действовать?
Хорошая новость для корпоративных заказчиков-представителей среднего и малого бизнеса — совсем не обязательно раздувать штат сотрудников для механической обработки типовых документов.
На рынке есть много точечных российских разработок и сервисов, направленных на типовое распознавание первички, транспортных накладных и т.д. Ту же систему документооборота 1С внедряет у себя — модуль для распознавания бухгалтерских документов.
Есть компании, профиль которых полностью связан с распознаванием и обработкой разных видов документов. Они предлагают и SDK-софт, и облачное распознавание по сервисной модели — Smart Engines, «Дибрейн» (Dbrain), «Биорг».
Компании ориентируются на корпоративных заказчиков, для которых автоматизируют обработку документов, заявляя интеллектуальное распознавание документов в связке с последующей верификацией данных силами операторов, подключенных удаленно.
Такой симбиоз технологий и человеческого труда дает высокое качество оцифрованных данных и всё больше применяется на рынке.
Безусловно, готовых «коробочных» продуктов уровня, который предлагал «вышедший» с рынка вендор, пока нет. Однако отечественные разработчики быстро смогут довести до высокого качество своих систем распознавания и скоро закрыть потребность рынка в работе с шаблонными документами.
Дополнительный позитив в том, что «коробочные» предложения альтернативных компаний в среднем могут оказаться в 1,5 раза дешевле, чем у раскрученного поставщика. Крупные интеграторы могут по OEM-лицензии встраивать движки таких разработчиков в свой более масштабный продукт.
Где импортозамещение необходимо?
- Проблема возникает, когда в компании очень большой объём документов или они крайне разнообразны.
Так, в банке может быть до 850 видов документов в потоке. Тут на лицензиях можно разориться. Расчет должен быть другим — проще нанять специалистов для доработки приобретенного «движка».
- Силами отечественных ИТ-компаний придется закрывать область разработки систем распознавания и анализа комплектов документов для государства.
Они актуальны в контексте автоматизации госуслуг. Здесь и до выхода ABBYY из реестра отечественного ПО не было готовых систем, потому что в отношениях «государство-гражданин» сравнительно мало структурированных документов, к которым можно применить шаблонное распознавание. Большинство данных не структурированы.
- Может стоять задача оцифровать и проанализировать комплект «договор + доверенность».
Программой надо не только выделить в этих документах информацию о сторонах сделки, но и сопоставить эти данные в документах, проверить актуальность. Другая задача — распознать многостраничную табличную бухгалтерскую документацию.
- Сложность для машины состоит в длинной таблице, когда необходимо определить вид документа и нужные поля для распознавания, а она «видит» внутренние листы таблицы, где нет заголовка, а есть только строки с данными.
Для таких задач нужны гораздо более сложные системы распознавания и анализа, так называемые «цифровые помощники» на базе ИИ. Это нейросетевые комплексы, которые умеют ориентироваться без шаблонов, их обучают под конкретный бизнес-процесс, постепенно наращивая функционал «помощника». Они способны «понимать» смысловые сущности в тексте, анализировать их.
Для обучения таких нейросетей требуется ручная разметка реальных наборов данных. В итоге цифровой помощник способен взять на себя до 95% рутинных проверок по документам.
Как найти системы для импортозамещения?
На рынке много игроков, которые занимаются ИИ-системами и цифровыми помощниками, но они сфокусированы на разных задачах.
- Одна цифровая «личность» умеет проверять 60% типовых договоров. Другая — анализировать и разбирать товарные позиции, автоматически определять стратегию закупок.
- Кадровые помощники всесторонне анализируют кандидатов. Другие системы — кастомные, под нестандартные задачи для государства.
Компании, занимающиеся вопросами ИИ-распознавания и оцифровки, есть в числе резидентов фонда «Сколково», который сегодня становится одним из форпостов технологического суверенитета России: «Энтера», Soica, «Дибрейн», мы — «Биорг».
Разработчики платформ на базе ИИ предлагают как аутсорсинг услуг, так и создают системы в контуре заказчика. В последнем случае взаимоотношения разворачиваются по знакомой в госзакупках схеме — приобретают лицензии на ПО.
Поставщики также берут на себя задачу разметки данных, обучения нейросетевых комплексов с последующим анализом качества их работы и дообучением.
Оцифровка документов в цифровизации государства и бизнеса
Автоматическая обработка бумажных документов и аккуратный перенос данных из них в информационную систему — значительная точка для оптимизации различных процессов в бизнесе и государстве.
Большие компании и ведомства сталкиваются с грандиозными потоками документов. Это бухгалтерская первичка, трудовые документы, паспорта, договоры, комплекты кредитных документов (ипотечный конвейер), акты, обращения граждан и т.д.
Даже если часть этих взаимоотношений уже перевели в электронный вид, другая часть всё равно остаётся в бумаге. А где-то (госведомства, обращения граждан, регистрация сделок с недвижимостью и т.д.) уйти от бумаги пока не представляется возможным.
Кроме того, и у бизнеса, и у государства накоплены колоссальные объёмы архивных единиц, которые они обязаны хранить и следить за их сохранностью. Тут можно вспомнить недавнее поручение президента, которое он дал Росархиву, РАН и Минцифре — подумать об оцифровке архивных фондов РФ с применением технологий искусственного интеллекта.
Автоматическая оцифровка и анализ документов — это не только способ порезать «косты» на обработку данных вручную, но и принципиальный момент в автоматизации госуслуг, где весомую роль отводят концепции автоматического межведомственного взаимодействия на основе реестров данных.
Согласно задумке, обмен информацией между государственными ведомствами должен происходить автоматически, на основе взаимодействия баз данных, реестров. Роль людей в процессе значительно снизится. Как следствие, время оказания госуслуг гражданам должно существенно сократиться. Появятся проактивные госуслуги.
Важный этап, который надо пройти — это наполнить реестры качественной и непротиворечивой информацией. Для этого нужно оцифровать архивы и научиться работать с нетривиальными комплектами документов. Это как раз и есть рынок для сложных систем распознавания и анализа, где теперь остаются только игроки из реестра отечественного ПО.
Фото на обложке: Shutterstock / Nuk2013
Подписывайтесь на наш Telegram-канал, чтобы быть в курсе последних новостей и событий!
- Бухгалтерия
- Бизнес
- Кейсы
- Импортозамещение
- Технологии для регуляторов
- Разработка ПО
Источник: rb.ru
Лучшие программы для сканирования и распознавания текста
Это одна из первых и наиболее известных программ для сканирования с акцентом именно на распознавание текстов. Вместо сканера вполне подойдет любая цифровая камера или камера смартфона.
 Программа поддерживает все версии Windows и порядка 180 языков для распознавания, что позволяет использовать ее для перевода текстов даже с экзотических азиатских языков.
Программа поддерживает все версии Windows и порядка 180 языков для распознавания, что позволяет использовать ее для перевода текстов даже с экзотических азиатских языков. 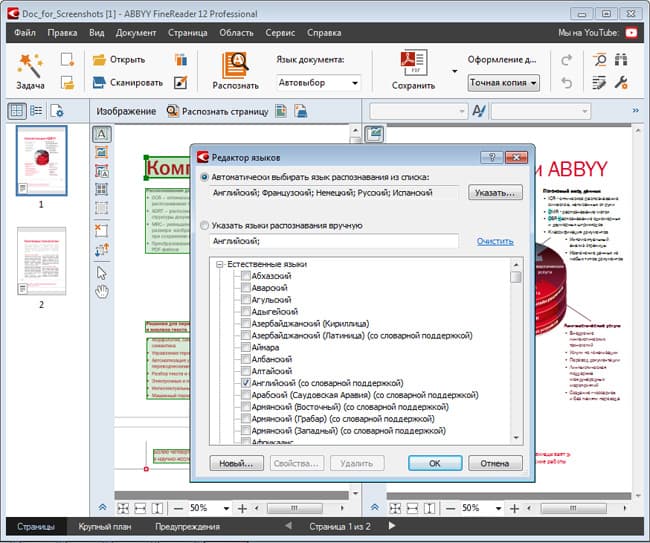
 Программа умеет обрабатывать документы отснятые на камеру, захватывать изображение с экрана, улучшать качество картинок, полностью сохранять форматирование распознанного документа, имеет множество других возможностей и настроек.
Программа умеет обрабатывать документы отснятые на камеру, захватывать изображение с экрана, улучшать качество картинок, полностью сохранять форматирование распознанного документа, имеет множество других возможностей и настроек.
VueScan
Программа, изначально не предназначалась для распознавания текстов, хотя и имеет базовый функционал в этом плане. Основное ее преимущество это невероятные функции по сканированию и обработке фото и других изображений.
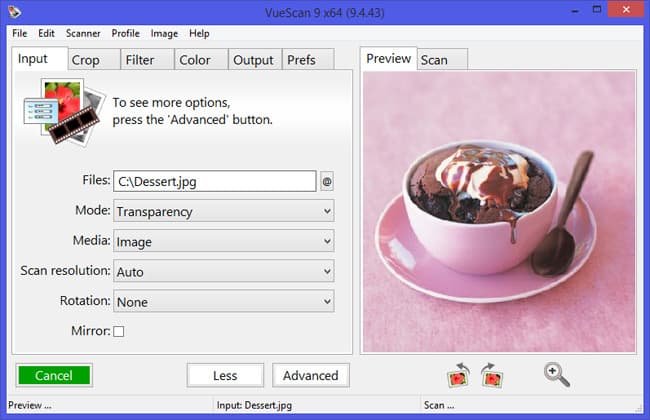 Она умеет работать с любыми сканерами и призвана расширить возможности весьма ограниченного ПО от производителя. В программе доступна регулировка множества параметров – яркости, контрастности, глубины цвета и более продвинутых профессиональных настроек.
Она умеет работать с любыми сканерами и призвана расширить возможности весьма ограниченного ПО от производителя. В программе доступна регулировка множества параметров – яркости, контрастности, глубины цвета и более продвинутых профессиональных настроек. 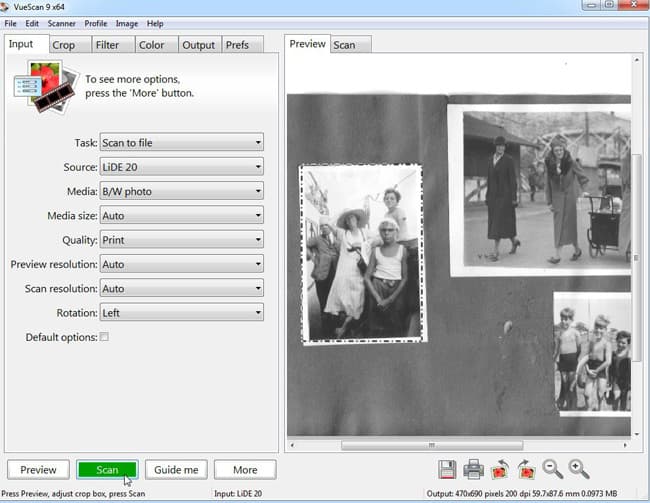 Есть пакетное, многопроходное сканирование и встроенный фоторедактор, позволяющий улучшать качество изображения не тратя время на повторное сканирование. В упрощенном интерфейсом с программой справится и неопытный пользователь, а расширенный режим не оставит равнодушным даже профессионала.
Есть пакетное, многопроходное сканирование и встроенный фоторедактор, позволяющий улучшать качество изображения не тратя время на повторное сканирование. В упрощенном интерфейсом с программой справится и неопытный пользователь, а расширенный режим не оставит равнодушным даже профессионала.
Scanitto Pro
Еще одно универсально решение, отличающееся простым интерфейсом и высокой скоростью работы, позволяющее получить сканы максимально приближенные по качеству к оригиналу. 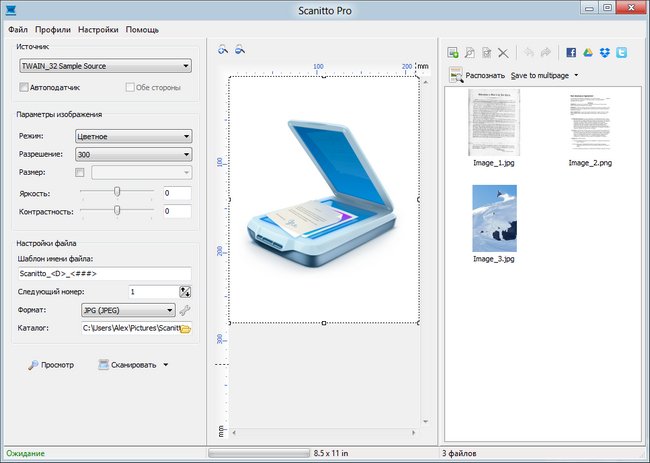 Полученные изображения можно быстро сохранять на диск, что удобно при большом объеме материала. Также доступен встроенный графический редактор для последующей обработки сканов.
Полученные изображения можно быстро сохранять на диск, что удобно при большом объеме материала. Также доступен встроенный графический редактор для последующей обработки сканов. 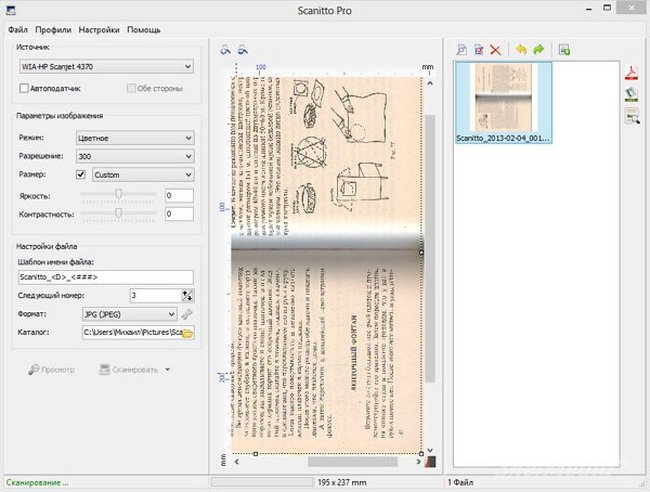 Это идеальное решение для тех, кому нужно часто делать большие объемы сканов, не отвлекаясь на обработку, которую можно отложить на другое время.
Это идеальное решение для тех, кому нужно часто делать большие объемы сканов, не отвлекаясь на обработку, которую можно отложить на другое время.
Readiris
Хорошо умеет извлекать текст с фото и распознавать его, когда другие подобные приложения не справляются с поставленной задачей. При этом поддерживается больше ста языков распознавания и множество выходных текстовых форматов. 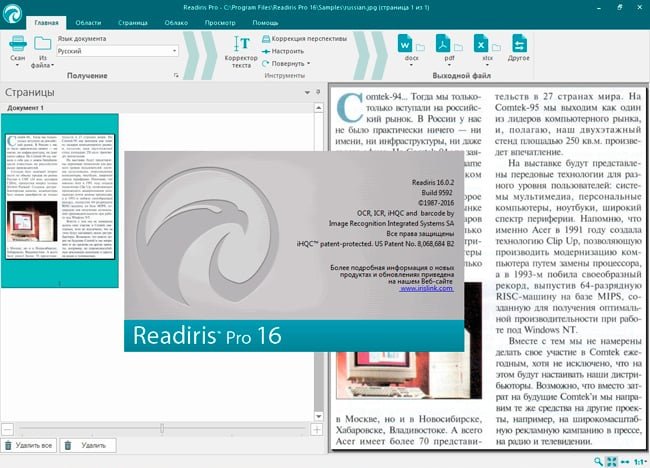 Интересно, что данная программа может работать не только со стандартными форматами картинок, но и с многостраничными файлами PDF и DJVu, плюс быстро конвертировать эти форматы в обе стороны.
Интересно, что данная программа может работать не только со стандартными форматами картинок, но и с многостраничными файлами PDF и DJVu, плюс быстро конвертировать эти форматы в обе стороны. 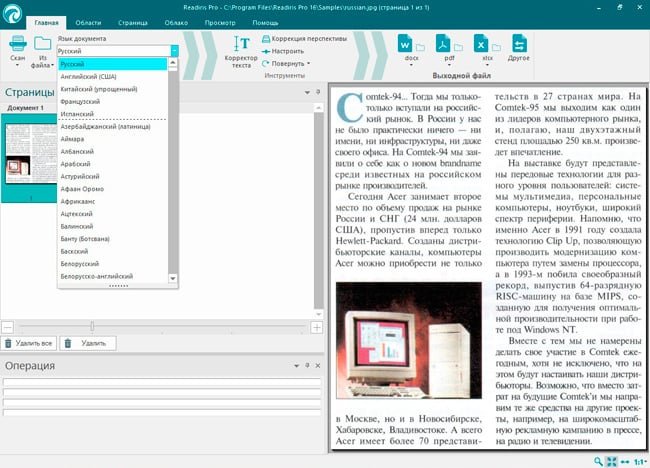 Можно указывать отдельные области для распознавания и их язык, использовать пакетное сканирование с последующей автоматической конвертацией изображений в текст.
Можно указывать отдельные области для распознавания и их язык, использовать пакетное сканирование с последующей автоматической конвертацией изображений в текст.
RiDoc
Простая и в то же время имеющая достаточно много возможностей программа, которая позволяет быстро отсканировать и сохранить любой текст или изображение на внешний диск или флешку. 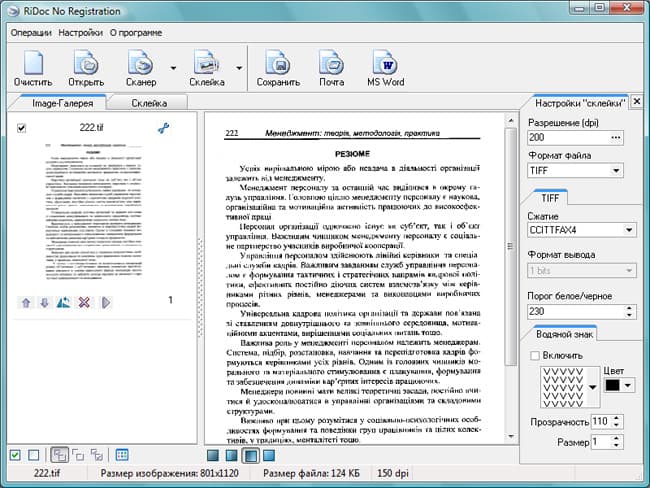 Есть возможность задать желаемое качество скана и оптимизировать размер файла, распознавать тексты и вести учет отсканированных документов для их систематизации, упрощения дальнейшего поиска и использования.
Есть возможность задать желаемое качество скана и оптимизировать размер файла, распознавать тексты и вести учет отсканированных документов для их систематизации, упрощения дальнейшего поиска и использования. 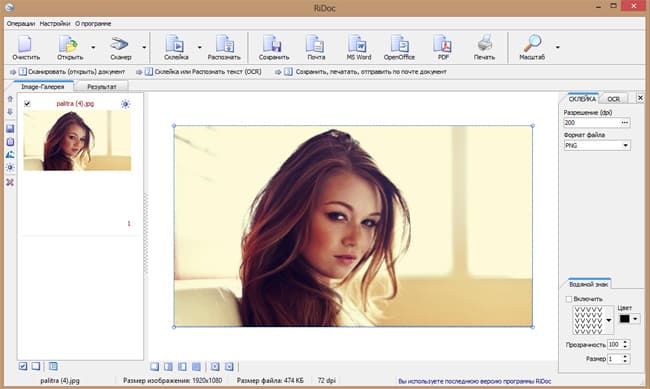 Помимо этого, отсканированные файлы можно быстро отправлять по электронной почте или загружать в облако с последующим предоставлением общего доступа одному или группе пользователей.
Помимо этого, отсканированные файлы можно быстро отправлять по электронной почте или загружать в облако с последующим предоставлением общего доступа одному или группе пользователей.
CanoScan Toolbox
Предназначена специально для использования с МФУ от Canon, значительно упрощает процесс сканирования, копирования, печати документов и изображений. Имеет базовый набор функций с простым понятным интерфейсом.
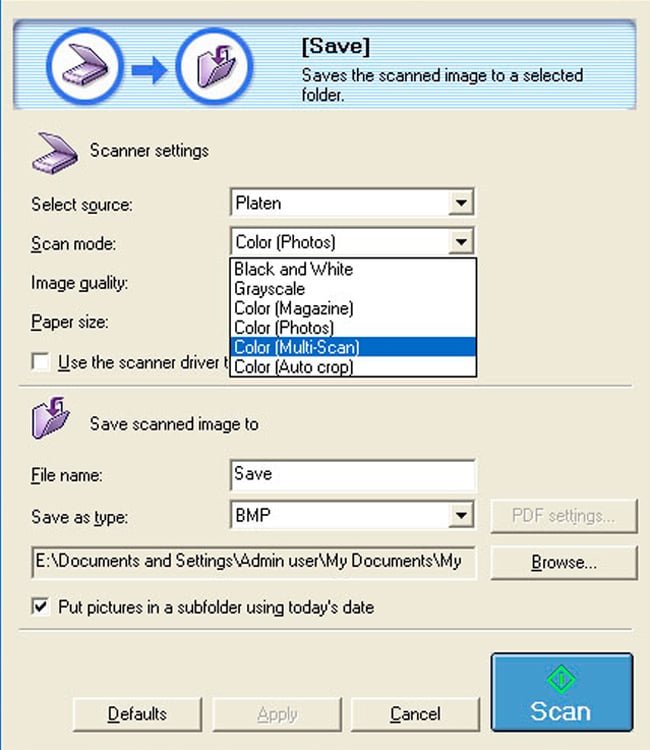 В программе есть возможность настройки области сканирования, масштаба изображения, регулировки яркости и контрастности. Поддерживается создание пользовательских профилей для быстрого сканирования, распознавания и отправки сканов по электронной почте.
В программе есть возможность настройки области сканирования, масштаба изображения, регулировки яркости и контрастности. Поддерживается создание пользовательских профилей для быстрого сканирования, распознавания и отправки сканов по электронной почте. 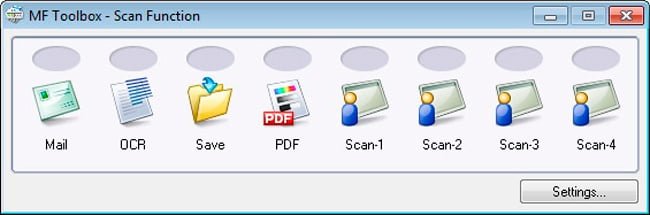 Но основной фишкой является все-таки возможность быстрого копирования документов с регулировкой параметров копирования. Это также может работать с устройствами от некоторых других производителей.
Но основной фишкой является все-таки возможность быстрого копирования документов с регулировкой параметров копирования. Это также может работать с устройствами от некоторых других производителей.
Источник: ironfriends.ru
Как работает программа, считывающая текст с картинки
Программа-распознаватель текста позволяет получить электронную копию с печатной страницы. Без нее (как и было ранее) придется действовать методом ручного набора на клавиатуре.
Сейчас достаточно лишь просканировать или сфотографировать печатный экземпляр. Нажатием одной кнопки получим электронную копию. Как работает программа, считывающая текст с картинки, распознавая его, рассмотрим далее.
Как распознается текст
Программа превращает графическое изображение в текстовый файл
Программы, считывающие текст с картинки или изображения страницы, оптически распознающие его, конвертируют сфотографированные или отсканированные документы в слова и предложения.
Графический формат превращается в текстовый файл.
Ведь на изображении каждая буква состоит из точек или пикселей, а средства OCR (Optical Character Recognition или оптического распознавания символов) воспринимают это.
Затем приводят изображения отдельных букв в соответствие с символами алфавита, сравнивая с базой элементов. В результате получается обычный текст с расширением, удобным для редактирования и сохранения.
Кому и зачем нужны такие программы
Программы, считывающие текст с картинки, помогают автоматически вводить документы в ОС (операционную систему) компьютера. Так можно составить файл из страниц книги, журнала или учебной литературы.
Хотя объект копирования представлен в напечатанном виде и лишь переведен в изображение сканером. Системы OCR считывают не только тексты, но и такие его элементы, как таблицы, иллюстрации. Нужно лишь подготовить электронное изображение, получив его сканированием или фотографированием документа.
Зависит ли результат от качества картинки
Программа, считывающая текст с картинки, применяет алгоритм, с помощью которого обрабатывает скан (снимок) страницы. При этом производится выделение областей относящихся к тексту, таблицам и иллюстрациям.
Следующим шагом символы сравниваются со словарем. При наличии соответствия буква считается распознанной. Так образуется весь текст, который требовалось преобразовать в электронную форму.
Сейчас системы OCR — достаточно сложные программы. Считывая текст с картинок, они справляются с искажениями, помарками, загрязнениями. Проблемные ситуации учитываются и обрабатываются максимально правильно.
Также электронные копии печатных документов получаются с сохранением размеров текста, шрифтов, стилей, форматирования.
Результат и его качество зависит от ряда факторов. Это размер исходного файла и его читаемость. Распознаваемое изображение должно быть как можно более четким, о чем надо позаботиться во время его сканирования или фотографирования.
Не каждая программа, считывая текст с картинки, а также не во всех случаях справится с чрезмерно сложной задачей в виде нечеткого изображения.
Бесплатные программы, считывающие текст
Есть бесплатные варианты. Например, CuneiForm, отличающаяся простотой и удобством. Необходимо скачать и установить на компьютер данный инструмент преобразования текста.
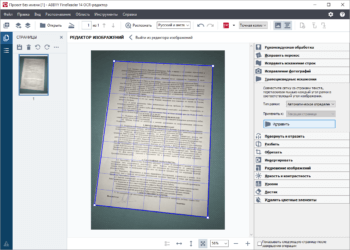
Одна из полезных программ — ABBYY FineReader
Рассмотрим подробнее перечень бесплатных (или условно бесплатных) программ с их возможностями, функциями и особенностями:
- Программа, считывающая текст с картинки, — ABBYY FineReader 10. Она лидирует по популярности, что обусловлено качеством распознавания, четкостью обработки кириллицы. Хотя версии могут включать до 179 языков. Недостатком можно назвать факт, что бесплатный период пользования предоставляется лишь на 15 дней по пробной версии. При этом есть ограничение на считывание — до 50 страниц. FineReader справляется с картинками, имеющими пониженное (но не чрезмерно) качество. Если на изображении имеются буквы, программа точно распознает их.
- OCR CuneiForm — бесплатная программа, считывающая текст с картинки. Точность несколько ниже, чем у FineReader. Имеется способность распознавать таблицы, текстовые блоки и изображения, сохранять шрифт, заложенный в достаточно обширной базе. Для пополнения словарного запаса подключаются словари. Программа справляется с ксерокопиями неважного качества. Недостатком является ограниченная точность, а также поддерживается не так уж много языков.
- SimpleOCR может читать даже рукописи, но не имеет русского интерфейса и распознавания языка. Применяется для преобразования иностранных текстов. При этом удаляет «шум», имеет встроенный редактор.
- Утилита WinScan2PDF не требует установки на компьютер и весит очень мало. При быстром распознавании сохраняет файлы лишь в PDF. Достаточно трижды нажать кнопки: выбирая источник, указывая место сохранения, для запуска процесса. Программа, считывая текст с картинки, быстро обрабатывает целые пакеты файлов. Интерфейс WinScan2PDF работает на многих языках. Скорость, портативность и простота — основные достоинства. К недостаткам относится результат, представленный в единственном формате.
- Freemore OCR весьма оперативна, но не работает на русском языке. Имеет большую производительность, обслуживает несколько сканеров. Будучи бесплатной, программа не снабжена русским интерфейсом. А также нужно дополнительно загружать русскоязычный пакет для считывания текстов.
Большие текстовые объемы обычно обрабатываются специальными OCR-программами, считывающими текст с картинки, имеющими немалую стоимость.
Онлайн-сервисы для считывания текста с картинки
Программы, считывающие текст с картинки, функционируют в режиме онлайн. Ряд сервисов занимается технологией OCR по распознаванию документов в виде фото или отсканированной страницы.
Причем предоставляют эту возможность бесплатно или с частичным ограничением. Можно преобразовывать в электронный вид фотографии, книги.
Обычно на обработку допускается загрузка небольших текстовых объемов в несколько страниц. Но необходимость покупать дорогую программу с установкой ее на компьютер при этом отпадает.
При небольших потребностях, не очень часто возникающих, вполне можно пользоваться подобной программой, считывающей текст с картинки онлайн. Если услуга по распознаванию не бесплатна, сумма оплаты весьма символическая.
Десятки сервисов могут ее предложить, работая по схожему принципу:
- загрузка картинки jpg, jpeg, png или файла pdf;
- выбор требуемого формата;

У OCR есть плюсы и минусы
В каждом варианте OCR онлайн отмечаются хорошие и плохие стороны. Обычно при выборе пользователи предъявляют требования по следующим критериям:
- распознавание текста на русском языке;
- неограниченное число страниц;
- бесплатность;
- удобство и качество.
Можно выделить следующий перечень сервисов OCR, работающих по программам, считывающим текст с картинки, онлайн:
- Google Диск распознает русскоязычные текстовые изображения. Нужна регистрация аккаунта Google. На преобразование берутся файлы с форматами JPG, PNG, GIF, PDF, если файл до 2 Мб. В последнем случае можно обработать 10 страниц. Сохранение документов производится в DOC, PRT, PDF, TXT, ODT.
- Программа OCR Convert считывает текст с картинки бесплатно без регистрации. Принимаются файлы JPEG, PDF, GIF, BMP. Результат предоставляется в виде ссылки (URL), где нужно скопировать текст формата TXT. Далее можно переводить его на другие языки, вставлять в редакторы. Ресурс загружает за один раз до пяти документов объемом 5 Мб.
- NewOCR загружает файлы на оптическое распознание без ограничений и регистрации. Принимаются любые графические форматы с загрузкой по несколько страниц одновременно. Имеет функцию выделения области текста. А также может делать переводы (от Google), включая около 60 языков. Сохранение происходит в RTF, PDF, TXT, DOC, ODT, HTML.
Для получения внятного результата необходимо предоставить снимок текста максимально хорошего качества.
В заключение
Распознавание буквенных символов позволяет создавать цифровые электронные копии документов, печатных и даже рукописных книг. Понятно, что метод позволяет намного быстрее осуществлять процесс по сравнению с перепечатыванием вручную.
Технология OCR с применением программ, считывающих текст с картинки, нашла широкое применение в архивах и библиотеках, удобна при домашнем использовании.
В этом видео вы узнаете об автоматизации обработки документов с рукописным текстом:
Заметили ошибку? Выделите ее и нажмите Ctrl+Enter, чтобы сообщить нам.
Источник: vyuchit.work
Упрощаем работу контент-менеджера: программы и сервисы для распознавания текста с картинки

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Часто у пользователей возникает необходимость распознавания текста с картинки в печатный вариант. Это может быть сканированный документ, который следует преобразовать в электронный вид, книга или фотокарточка.
Распознавание — довольно простой и удобный инструмент. Он избавляет от необходимости вручную перепечатывать большие объемы информации из печатных изданий: будь то газета, журнал, книга, реферат или обычный лист с надписями — для последующей публикации на сайте или применения в других целях. Инструмент удобен для всех категорий пользователей: от простых людей, использующих инструмент распознавания в бытовых целях, до преподавателей, студентов, владельцев веб-ресурсов, научных сотрудников и т.д.
Для выполнения этих целей существует несколько инструментов: установочные программы на ПК, онлайн-сервисы и мобильные приложения. Их выбор зависит от индивидуальных характеристик исходного документа: качества, объема, размера.
- Для частого использования и большого объема распознавания текста с картинки используются программы. Они обычно дорогие и сложны в использовании: системы оптического распознавания требуют калибровки для работы с конкретным шрифтом.
- Если необходимость возникает не так часто и размеры документов небольшие, разумнее использовать специальные онлайн-сервисы. Они могут предоставлять услуги бесплатно или по недорогой подписке. В интернете довольно много подобных предложений. Чтобы сделать выбор между предлагаемыми вариантами, необходимо узнать, какие возможности предлагает тот или иной сайт, его преимущества и недостатки.
В зависимости от этого и индивидуальных требований пользователя происходит выбор распознавания текста с картинки. В частности, руководствоваться можно следующими факторами:
- Стоимость услуги. В идеале веб-ресурс или программа должны быть бесплатными.
- Максимально возможный объем распознавания. Некоторый софт предлагает неограниченные возможности, другие предоставляют услуги по подписке: при достижении определенного лимита необходимо покупать еще один пакет.
- Поддержка русского языка. В большинстве случаев действительно качественный софт представлен на английском языке без возможности распознавания на русском.
Не существует общих критериев, по которым можно признать программу качественной или нет. В конечно счете результат зависит от индивидуальных показателей: размера исходного документа, формата изображения, качества и т.д.
Содержание скрыть
- Как работает распознаватель текста с картинки
- Бесплатное распознавание текста с картинки в онлайн-режиме
- Программы для распознавания текста с картинки
Как работает распознаватель текста с картинки
Каждое изображение представляет собой сетку пикселей, то есть набор точек, из которых складываются образы. Программное обеспечение или онлайн-сервисы выделяют на общем фоне отдельные буквы и осуществляют перевод в печатный формат. В процессе работы структура документа детально анализируется специальным алгоритмом, который выделяет блоки, проставляет линии делений на слова, а затем символы.
Полученные знаки и буквы сравниваются с имеющимися шаблонами алфавита и цифр, после чего алгоритм принимает решение, что именно это за символ, и выдает готовый результат. Поскольку надписи бывают некачественными, а алгоритмы — несовершенными, возникают ошибки в интерпретации отдельных букв (целые слова редко путаются с другими).
Бесплатное распознавание текста с картинки в онлайн-режиме
Файловый хостинг Google Диск. Доступ к сервису осуществляется с общей учетной записи Google. Если ее нет, необходимо зарегистрироваться, чтобы воспользоваться инструментом.
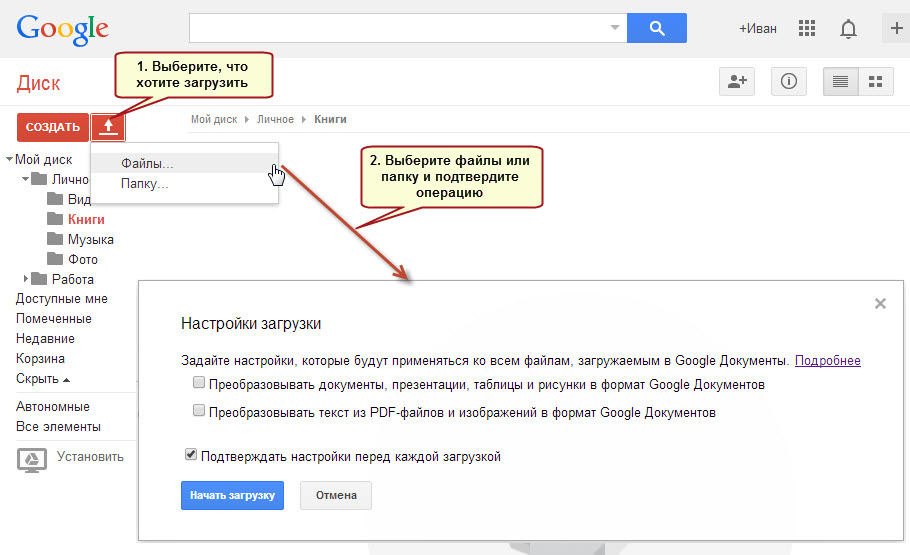
Пользователи могут загружать изображения в разных форматах: PNG, JPG и GIF. Их размер не должен превышать двух мегабайт. Помимо этого, есть возможность распознавать данные с документов в формате PDF, но с некоторыми ограничениями. Так, если загрузить файл PDF с несколькими десятками страниц, то обработаются только первые десять листов. Результат сохраняется во все популярные форматы файлов.
OCR Convert. Онлайн-сервис предоставляет полностью бесплатные услуги по преобразованию картинок в электронный редактируемый формат. Изначально сайт был для англоязычных пользователей, но сейчас доступен на многих европейских и восточных языках. Чтобы воспользоваться инструментом, не нужно регистрировать учетную запись. Существует несколько способов загрузить исходный материал:
- Через нажатие кнопки «Выбрать файлы». Далее открывается проводник, предлагающий выбрать документ на компьютере. Можно использовать PDF, GIF, BMP и JPEG-форматы.
- Через ссылку на изображение, размещенное на сайте или в файлообменнике.
К примеру, для распознавания китайского текста с картинки в онлайн-режиме принцип работы будет следующий: после загрузки документа следует выбрать язык, на котором напечатан материал (доступно более 30 различных языков), а также формат конвертирования — только TXT. Пользователь может добавлять на сайт до пяти материалов, размером не более 5 мегабайт каждое.
NewOCR. Бесплатный сайт, не требующий регистрации. По мнению пользователей, является наиболее интересным и полезным инструментом. Связано это с тем, что веб-сервис поддерживает все популярные форматы и может распознать текст с картинки в Word. При этом можно загружать несколько изображений разных форматов одновременно.
В NewOCR есть интерфейс для работы: с помощью встроенных инструментов можно увеличивать «нужное место», отделять его от неиспользуемой области.
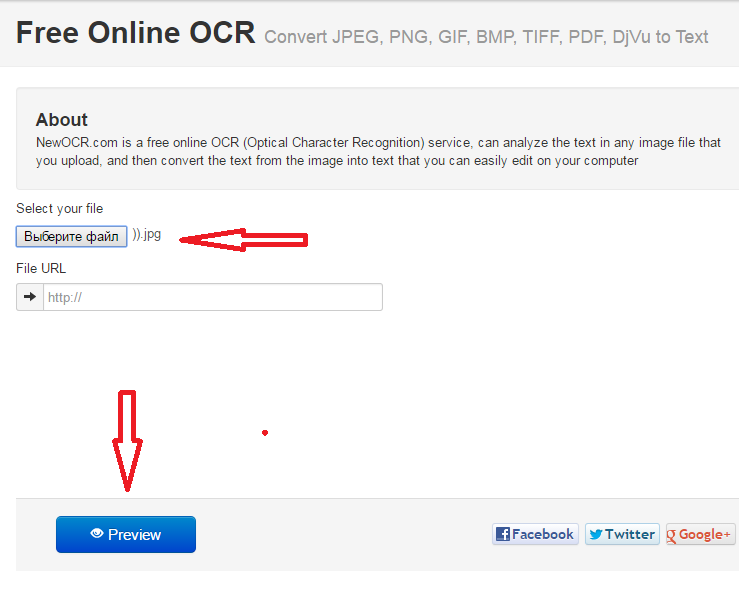
Интерфейс представлен только на английском языке, но преобразование происходит на более чем 50 языках. Благодаря плагину Google-переводчика можно переводить на другие языки.
OCRonline. Это один из самых неудобных сайтов, поскольку требует, чтобы фотографии были высокого разрешения. И, хотя загружать можно документы с низким качеством, он довольно плохо справляется с распознаванием текста с такой картинки онлайн. Еще одним недостатком является еженедельный лимит — не более пяти страниц в семь дней. Результаты можно сохранять на ПК в популярных форматах.
Чтобы получить доступ к неограниченному числу операций, необходимо купить подписку и зарегистрировать учетную запись.
Free-Ocr. Еще один бесплатный сервис, пользоваться которым можно без учетной записи. Однако получить результат можно только после ввода капчи. В отличие от OCRonline, где ограничение после пяти операций продолжается в течение недели, здесь лимит установлен на каждый час. Другими словами, пользователь может распознать текст с десяти картинки в Word, после чего придется ждать, когда по истечении времени ограничения можно будет преобразовать следующие 10 документов.
Программы для распознавания текста с картинки
OCR CuneiForm. Это открытая система оптического преобразования сканированных документов. Особенностью программы является то, что в ней можно распознавать в печатные страницы с одновременным использованием разных языков. Скачать OCR CuneiForm можно бесплатно на официальном сайте компании. Процесс установки на ПК стандартный.
Рабочее пространство довольно удобно, а интерфейс, представленный на русском языке, интуитивно понятен. Недостатком OCR CuneiForm является то, что разноцветные надписи практически не выводятся, а если черно-белое изображение плохого качества, результат получится с большим количеством ошибок.
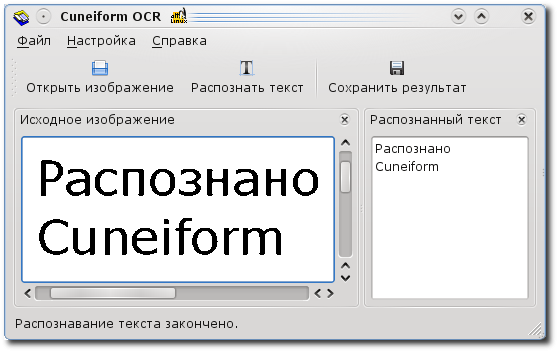
Среди преимуществ можно отметить то, что данную программу распознавания текста с картинки можно скачать бесплатно с сайта, тогда как другие русифицированные клиенты доступны только после покупки.
RiDoc. Программа качается на ПК бесплатно, однако пользоваться основными функциями можно только в течение 30 дней. Далее необходимо платить. RiDoc удобен в использовании и имеет большой инструментарий для получения качественного результата. Чтобы преобразовать, необходимо нажать на кнопку «Открыть», загрузить документ и начать процесс.
Результат можно загрузить в документ Word.
ABBYY FineReader. На сегодняшний день это наиболее популярная и раскрученная российская программа, распознающая текст с картинки. Для удобства пользователей здесь предусмотрен бесплатный тестовый период. Полная подписка стоит 7 тысяч рублей. Отличительной чертой является то, что с ее помощью можно преобразовывать таблицы и математические формулы, конвертируя данные в документы различных форматов.
Источник: semantica.in
Технология распознавания текста: базовые принципы, программы и сервисы
Технология распознавания текста — это технология механического или электронного перевода разных текстов в последовательность кодов, используемых для представления в текстовом редакторе.
Введение
Если пользователю необходимо выполнить оцифровку журнальной статьи или распечатанного договора, то он может или провести несколько часов, перепечатывая документ, или же перевести все необходимые материалы в редактируемый формат за короткий интервал времени, задействовав сканер (или цифровую камеру) и программу для оптического распознавания символов, то есть, Optical Character Recognition (OCR).
Оптическим распознаванием символов является технология, позволяющая преобразовать разные виды документов, а именно, отсканированные документы, PDF-файлы или фото с цифровых камер, в редактируемые форматы с возможностью поиска. Передовые системы оптического распознавания символов подразделяются на следующие категории:
Решим твою учебную задачу всего за 30 минут
Попробовать прямо сейчас
- Классические OCR-системы, призванные решать типовую задачу распознавания печатных символов, которые нанесены на бумагу с помощью принтера, плоттера или пишущей машинки. Причем предполагается, что любая система распознавания использует электронные изображения документов, как правило, полученные при помощи сканера.
- Класс ICR-систем (intelligent character recognition), предназначением которых является обработка документов, заполненных печатными символами и цифрами от руки, то есть, это распознавание рукописей.
В обоих вариантах качественный уровень работы системы распознавания может оцениваться по разным параметрам, но самым важным параметром системы любого вида считается точность распознавания.
Технология распознавания текста: базовые принципы, программы и сервисы
В течение последних лет на мировом рынке предлагаются OCR и ICR-системы, которые построены на основе технологий фирмы ABBYY. На текущий момент они являются хорошо известными и пользующимися постоянным спросом. Например, программное ядро (engine) OCR -системы ABBYY FineReader обладает лицензией и успешно применяется такими популярными корпорациями, как Cardiff Software, Inc., Cobra Technologies, Kofax Image Products, Kurzweil Educational Systems, Inc., Legato Systems, Inc., Notable Solutions Inc., ReadSoft AB, Saperion AG, SER Systems AG, Siemens Nixdorf, Toshiba Corporations.
«Технология распознавания текста: базовые принципы, программы и сервисы»
Готовые курсовые работы и рефераты
Консультации эксперта по предмету
Помощь в написании учебной работы
Корпорация ABBYY, используя результаты многолетних исследований, смогла реализовать принципы IPA (International Phonetic Alphabet, то есть, международного фонетического алфавита) в компьютерной программе. Система оптического распознавания символов ABBYY FineReader является единственной в мире системой OCR, действующей согласно с описанными выше принципами на каждом этапе обработки документа. Данные принципы обеспечивают программе максимальную гибкость и интеллектуальность, что приближает ее работу к тому, как распознают символы люди.
На начальном этапе распознавания система должна выполнить постраничный анализ изображений, из которых составлен документ, определить структуру страниц, выделить текстовые блоки, таблицы. Помимо этого, современные типы документов могут содержать различные компоненты дизайна, такие как:
- Совокупность иллюстраций.
- Набор колонтитулов.
- Цветной фон или фоновые изображения.
По этой причине мало просто определить и распознать найденный текст, необходимо изначально выяснить устройство обрабатываемого документа, а именно:
- Наличие в нем разделов и подразделов.
- Наличие ссылок и сносок.
- Наличие таблиц и графиков.
- Наличие оглавления.
- Присутствие нумерации страниц и так далее.
Далее в текстовых блоках следует выделить строки, поделить отдельные строки на слова, а слова поделить на символы. Следует заметить, что выделение символов и процесс их распознания также реализован в форме составных частей общей процедуры. Это предоставляет возможность в полном объеме применять преимущества принципов IPA. Выделенные изображения символов должны поступить на рассмотрение механизмов распознавания букв, именуемых классификаторами.
В системе ABBYY FineReader используются классификаторы следующих типов:
- Классификатор растрового типа.
- Классификатор признакового типа.
- Классификатор контурного типа.
- Классификатор структурного типа.
- Классификатор дифференциального признакового типа.
- Классификатор структурно-дифференциального типа.
Растровый и признаковый классификаторы призваны анализировать изображение и выдвигать ряд гипотез о том, какой именно символ на нем изображен. В процессе анализа каждой гипотезе должна быть присвоена некоторая оценка, именуемая весом. По результатам проверки формируется перечень гипотез, обладающий ранжированием по весам, а именно, по уровню уверенности в том, что распознан как раз данный символ. Иначе говоря, в этот момент система строит догадки, на что больше похож изучаемый символ.
Затем согласно принципам IPA ABBYY FineReader должен провести проверку имеющихся гипотез. Эта процедура осуществляется при помощи дифференциального признакового классификатора. Необходимо заметить, что ABBYY FineReader способен поддерживать сто девяносто два языка распознавания. Объединение системы распознавания со словарным запасом осуществляет помощь программе при анализе документов, то есть, распознавание выполняется более точно и делает проще последующую проверку итоговых результатов с учетом данных об основном языке документа и словарной проверки отдельных предположений. По завершении подробной обработки огромного количества гипотез программа должна принять решение и предоставить пользователю конечный вариант распознанного текста.
Преобразование документа в электронный формат исполняется OCR-системами поэтапно, в следующем порядке:
- Этап сканирования и предварительной обработки изображения.
- Этап анализа структуры документа.
- Этап распознавания.
- Этап проверки результатов.
- Этап реконструкции (воссоздание исходного вида) документа, и осуществление экспорта.
Источник: spravochnick.ru