
Добрый день.
Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Простой способ распознать текст
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.

ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк).
Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети!
Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
Важно! Не все сразу понимают, что после открытия документа в программе, слева в окне отображается исходный документ, в котором вы и выделяете различные области. После нажатия на кнопку «распознавания» программа в окне справа выведет вам готовый текст. После распознавания, кстати, целесообразно проверить текст на ошибки в том же самом FineReader.
3.1 Текст
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
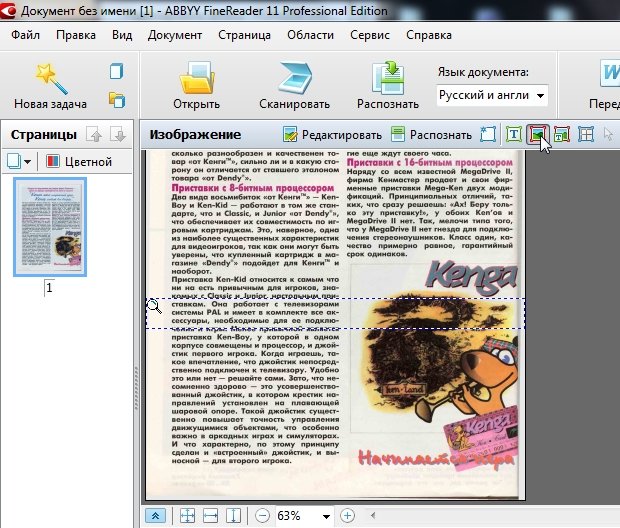
Для выделения текстовой области, обратите внимание на панель в верхней части FineReader. Там есть кнопка «Т» (см. скриншот ниже, указатель мышки как раз на этой кнопке). Щелкаете по ней, затем на картинке ниже выделяете аккуратно прямоугольную область, в которой располагается текст. Кстати, в некоторых случаях нужно создавать текстовых блоков по 2-3, а иногда по 10-12 на страницу, т.к. форматирование текста может быть разным и одним прямоугольником всю область не выделить.
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-07-33](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-07-33.jpg)
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
На скриншоте ниже указатель мышки находится на кнопке, используемой для выделения области «картинка». Кстати, в эту область можно выделить абсолютно любую часть страницы, а FineReader вставит ее потом в документ как обычную картинку. Т.е. просто «тупо» скопирует…
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
3.3 Таблицы
На скриншоте ниже показана кнопка для выделения таблиц. Вообще, лично я ее использую крайне редко. Дело в том, что вам придется довольно рутинно рисовать (фактически) каждую линию на таблице и показывать что и как программе. Если таблица небольшая и в не очень хорошем качестве, я рекомендую для этих целей использовать область «картинка». Тем самым сэкономите кучу времени, а таблицу можно потом в Word сделать быстренько на основе картинки.
![]()
3.4 Ненужные элементы
Важно отметить. Иногда на странице есть ненужные элементы, которые мешают распознать текст, или вообще не дают вам выделить нужную область. Их можно при помощи «ластика» удалить вовсе.
Для этого переходим в режим редактирования изображения.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-11](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-11.jpg)
Выбираем инструмент «ластик» и выделяем ненужную область. Она сотрется и на ее месте будет белый лист бумаги.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-21.jpg)
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
2. Включите опция «обрезки».
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-19-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-19-21.jpg)
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
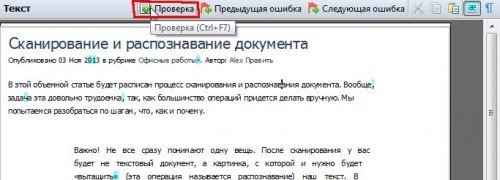
Во-первых, нужна проверка документа!
Чтобы ее включить, после распознавания, в окне справа, будет кнопка «проверка», см. скриншот ниже. После ее нажатия программа FineReader будет автоматически показывать вам те области, где у программы возникли ошибки и она не смогла достоверно определить тот или иной символ. Вам останется только выбирать, либо вы согласны с мнением программы, либо вводите свой символ.
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-24-08](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-24-08.jpg)
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Этот вариант хорош тем, что вы получите уже форматированный вариант текста. Т.е. отступов с «километр», которые возможно были в исходном документе — вы не встретите. Полезная опция, когда вы будете значительно редактировать информацию.
Правда, не стоит выбирать, если вам важно сохранить стилистику оформления, шрифты, отступы. Иногда, если распознавание прошло не очень успешно — ваш документ может «перекосить» из-за измененного форматирования. В этом случае целесообразно выбрать точную копию.
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…
Источник: pcpro100.info
Как работает программа, считывающая текст с картинки
Программа-распознаватель текста позволяет получить электронную копию с печатной страницы. Без нее (как и было ранее) придется действовать методом ручного набора на клавиатуре.
Сейчас достаточно лишь просканировать или сфотографировать печатный экземпляр. Нажатием одной кнопки получим электронную копию. Как работает программа, считывающая текст с картинки, распознавая его, рассмотрим далее.
Как распознается текст
Программа превращает графическое изображение в текстовый файл
Программы, считывающие текст с картинки или изображения страницы, оптически распознающие его, конвертируют сфотографированные или отсканированные документы в слова и предложения.
Графический формат превращается в текстовый файл.
Ведь на изображении каждая буква состоит из точек или пикселей, а средства OCR (Optical Character Recognition или оптического распознавания символов) воспринимают это.
Затем приводят изображения отдельных букв в соответствие с символами алфавита, сравнивая с базой элементов. В результате получается обычный текст с расширением, удобным для редактирования и сохранения.
Кому и зачем нужны такие программы
Программы, считывающие текст с картинки, помогают автоматически вводить документы в ОС (операционную систему) компьютера. Так можно составить файл из страниц книги, журнала или учебной литературы.
Хотя объект копирования представлен в напечатанном виде и лишь переведен в изображение сканером. Системы OCR считывают не только тексты, но и такие его элементы, как таблицы, иллюстрации. Нужно лишь подготовить электронное изображение, получив его сканированием или фотографированием документа.
Зависит ли результат от качества картинки
Программа, считывающая текст с картинки, применяет алгоритм, с помощью которого обрабатывает скан (снимок) страницы. При этом производится выделение областей относящихся к тексту, таблицам и иллюстрациям.
Следующим шагом символы сравниваются со словарем. При наличии соответствия буква считается распознанной. Так образуется весь текст, который требовалось преобразовать в электронную форму.
Сейчас системы OCR — достаточно сложные программы. Считывая текст с картинок, они справляются с искажениями, помарками, загрязнениями. Проблемные ситуации учитываются и обрабатываются максимально правильно.
Также электронные копии печатных документов получаются с сохранением размеров текста, шрифтов, стилей, форматирования.
Результат и его качество зависит от ряда факторов. Это размер исходного файла и его читаемость. Распознаваемое изображение должно быть как можно более четким, о чем надо позаботиться во время его сканирования или фотографирования.
Не каждая программа, считывая текст с картинки, а также не во всех случаях справится с чрезмерно сложной задачей в виде нечеткого изображения.
Бесплатные программы, считывающие текст
Есть бесплатные варианты. Например, CuneiForm, отличающаяся простотой и удобством. Необходимо скачать и установить на компьютер данный инструмент преобразования текста.
Одна из полезных программ — ABBYY FineReader
Рассмотрим подробнее перечень бесплатных (или условно бесплатных) программ с их возможностями, функциями и особенностями:
- Программа, считывающая текст с картинки, — ABBYY FineReader 10. Она лидирует по популярности, что обусловлено качеством распознавания, четкостью обработки кириллицы. Хотя версии могут включать до 179 языков. Недостатком можно назвать факт, что бесплатный период пользования предоставляется лишь на 15 дней по пробной версии. При этом есть ограничение на считывание — до 50 страниц. FineReader справляется с картинками, имеющими пониженное (но не чрезмерно) качество. Если на изображении имеются буквы, программа точно распознает их.
- OCR CuneiForm — бесплатная программа, считывающая текст с картинки. Точность несколько ниже, чем у FineReader. Имеется способность распознавать таблицы, текстовые блоки и изображения, сохранять шрифт, заложенный в достаточно обширной базе. Для пополнения словарного запаса подключаются словари. Программа справляется с ксерокопиями неважного качества. Недостатком является ограниченная точность, а также поддерживается не так уж много языков.
- SimpleOCR может читать даже рукописи, но не имеет русского интерфейса и распознавания языка. Применяется для преобразования иностранных текстов. При этом удаляет «шум», имеет встроенный редактор.
- Утилита WinScan2PDF не требует установки на компьютер и весит очень мало. При быстром распознавании сохраняет файлы лишь в PDF. Достаточно трижды нажать кнопки: выбирая источник, указывая место сохранения, для запуска процесса. Программа, считывая текст с картинки, быстро обрабатывает целые пакеты файлов. Интерфейс WinScan2PDF работает на многих языках. Скорость, портативность и простота — основные достоинства. К недостаткам относится результат, представленный в единственном формате.
- Freemore OCR весьма оперативна, но не работает на русском языке. Имеет большую производительность, обслуживает несколько сканеров. Будучи бесплатной, программа не снабжена русским интерфейсом. А также нужно дополнительно загружать русскоязычный пакет для считывания текстов.
Большие текстовые объемы обычно обрабатываются специальными OCR-программами, считывающими текст с картинки, имеющими немалую стоимость.
Онлайн-сервисы для считывания текста с картинки
Программы, считывающие текст с картинки, функционируют в режиме онлайн. Ряд сервисов занимается технологией OCR по распознаванию документов в виде фото или отсканированной страницы.
Причем предоставляют эту возможность бесплатно или с частичным ограничением. Можно преобразовывать в электронный вид фотографии, книги.
Обычно на обработку допускается загрузка небольших текстовых объемов в несколько страниц. Но необходимость покупать дорогую программу с установкой ее на компьютер при этом отпадает.
При небольших потребностях, не очень часто возникающих, вполне можно пользоваться подобной программой, считывающей текст с картинки онлайн. Если услуга по распознаванию не бесплатна, сумма оплаты весьма символическая.
Десятки сервисов могут ее предложить, работая по схожему принципу:
- загрузка картинки jpg, jpeg, png или файла pdf;
- выбор требуемого формата;

У OCR есть плюсы и минусы
В каждом варианте OCR онлайн отмечаются хорошие и плохие стороны. Обычно при выборе пользователи предъявляют требования по следующим критериям:
- распознавание текста на русском языке;
- неограниченное число страниц;
- бесплатность;
- удобство и качество.
Можно выделить следующий перечень сервисов OCR, работающих по программам, считывающим текст с картинки, онлайн:
- Google Диск распознает русскоязычные текстовые изображения. Нужна регистрация аккаунта Google. На преобразование берутся файлы с форматами JPG, PNG, GIF, PDF, если файл до 2 Мб. В последнем случае можно обработать 10 страниц. Сохранение документов производится в DOC, PRT, PDF, TXT, ODT.
- Программа OCR Convert считывает текст с картинки бесплатно без регистрации. Принимаются файлы JPEG, PDF, GIF, BMP. Результат предоставляется в виде ссылки (URL), где нужно скопировать текст формата TXT. Далее можно переводить его на другие языки, вставлять в редакторы. Ресурс загружает за один раз до пяти документов объемом 5 Мб.
- NewOCR загружает файлы на оптическое распознание без ограничений и регистрации. Принимаются любые графические форматы с загрузкой по несколько страниц одновременно. Имеет функцию выделения области текста. А также может делать переводы (от Google), включая около 60 языков. Сохранение происходит в RTF, PDF, TXT, DOC, ODT, HTML.
Для получения внятного результата необходимо предоставить снимок текста максимально хорошего качества.
В заключение
Распознавание буквенных символов позволяет создавать цифровые электронные копии документов, печатных и даже рукописных книг. Понятно, что метод позволяет намного быстрее осуществлять процесс по сравнению с перепечатыванием вручную.
Технология OCR с применением программ, считывающих текст с картинки, нашла широкое применение в архивах и библиотеках, удобна при домашнем использовании.
В этом видео вы узнаете об автоматизации обработки документов с рукописным текстом:
Заметили ошибку? Выделите ее и нажмите Ctrl+Enter, чтобы сообщить нам.
Источник: vyuchit.work
Как в СССР придумали распознавание рукописного текста для Apple. Сотрудничество было засекречено


Не все поклонники компании Apple и следящие за развитием технологий люди знают о таком довольно необычном и странном альянсе.
В долгой истории яблочной компании был интересный прецедент сотрудничества с нашими отечественными разработчиками, который завершился неоднозначно.
Сейчас подробнее расскажем эту малоизвестную историю.
Как появилась компания ПараГраф и чем она занималась

Основатель компании ПараГраф Степан Пачиков
Компания ПараГраф (сокращение от “параллельная графика“) была основана в 1988 году нашим соотечественником Степаном Пачиковым. Любопытно, что через 20 лет, проживая и работая в США, он же основал известный большинству из вас веб-сервис для создания и хранения заметок Evernote.
Изначально деятельность компании ПараГраф началась в СССР в 1988 году. Сотрудники трудились на базе отдельного подразделения кооператива Контур, а затем уже в качестве самостоятельного кооператива МикроКонтур.
В 1989 году официально создается организация СП «Параграф», продолжая труды указанных выше подразделений.
Основными направлениями деятельности компании были распознавание текста (на основе оптического распознавания символов) и трёхмерное моделирование. Кроме Пачикова среди основателей компании числились:
► Антон Чижов, программист, занимавшийся локализацией зарубежного ПО, а позднее менеджер по коммуникациям ПараГраф, который отвечал за связи с представителями Apple.
► Георгий Пачиков, сооснователь и разработчик 2D/3D технологий. Позднее принимал участие в создании проектов для компании Disney. В 2000 году основал Parallel Graphics Ltd, услугами которой пользовались компании Boeing, Airbus, МКС, Rolls Royce и Камаз.
► Шеля Губерман, ученый в области ядерной физики, информатики, геологии. Изобретатель технологии распознавания рукописного ввода, реализованной в коммерческом продукте компании ПараГраф.
► Илья Лосев, разработчик языка программирования для функционирования технологии оптического распознавания символов.

Основатель компании ПараГраф Степан Пачиков
В компании ПараГраф работали Евгений Веселов (позднее сотрудник Microsoft, архитектор направления Internet Explorer), Алексей Пажитнов (программист, геймдизайнер, создатель игры Тетрис), Ольга Дергунова (позднее президент “Майкрософт Рус”, заместитель министра экономического развития РФ).
Кроме этого одним из совладельцев ПараГрафа был шахматист Гарри Каспаров.
Разработки компании ПараГраф в 1990 году были представлены на крупных международных компьютерных выставках Comdex (Лас-Вегас, США) и CeBIT (Ганновер, Германия). Примечательно, что ПараГраф стал первым представителем на данных выставках от СССР.
Все началось с детского компьютерного клуба

Степан Пачиков и Гарри Каспаров в детском клубе «Компьютер», 1987. Фото: РИА Новости
Эпоха Советского Союза подходила к концу, предприимчивым кооператорам все чаще удавалось “приоткрыть” железный занавес и заглянуть в мир “загнивающего капитализма”. Власть ослабила хватку, позволив научным деятелям и сотрудникам посещать международные выставки и мероприятия. В столицу нашей страны тоже зачастили иностранные журналисты, политики и агенты по “переманиванию мозгов”.
Такая благоприятная почва способствовала судьбоносной встрече. Американская журналистка и организатор международных технологических конференций Эстер Дайсон во время одного из визитов в Москву посетила единственный на тот момент детский компьютерный клуб в СССР. Клуб этот был организован основателем ПараГраф Степаном Пачиковым.
Журналистка была удивлена обилием идей и наличием энергии воплощать их у советского программиста. Эстер убедила отечественного разработчика посетить ближайшую выставку технологий в Будапеште, помогла оформить приглашение и документы для визита.
Пачиков вместе с делегацией не заключили никаких важных соглашений и не завели ключевых связей в этой поездке, но во время проведения конференции уловили главный тренд на рынке технологий.

Степан Пачиков. Фото: gettyimages
Ключевые сотрудники и менеджеры многих компании во всю обсуждали грядущую эру мобильных гаджетов, называя новое поколение устройств “pen computers”. Такие устройства должны были сменить привычную клавиатуру и манипулятор для ввода на более компактную и удобную электронную ручку (позднее устройство получило название “стилус”).
Подобный ход должен был хорошо продвинуть компьютеры в массы, сделав его более простым и доступным. Гаджет, напоминающий обычный блокнот, мог привлечь гораздо больше обычных покупателей, чем технически сложный и требующие навыков работы персональный ПК.
Главной сложностью подобного девайса была система перевода написанного пользователем текста в понятные для компьютера символы. По счастливой случайности, именно такой разработкой занимались специалисты из ПараГраф.
С пониманием четкого направления для своей дальнейшей деятельности советские специалисты вернулись в Москву и продолжили разработку перспективной технологии.
Судьбу компании решила визитка
Продолжая работу, сотрудники ПараГраф по своим каналам связи узнают о визите в столицу вице-президента Apple Эла Айзенштата. Вычислить место пребывания американского предпринимателя и попасть к нему на встречу было делом техники.
Хоть в те годы власти и пытались всячески оградить советских жителей от контакта с капиталистическими гостями, Степану Пачикову все-таки удалось преодолеть все трудности и лично постучаться в дверь номера Айзенштата.
Встреча оказалась очень скомканной и суматошной, но в результате у советского программиста оказалась визитка вице-президента Apple с телефонным номером, на который когда-нибудь можно было позвонить.
Этот номер пригодился уже через несколько месяцев.

Коллектив ПараГраф на выставке в Лас-Вегасе
Находясь на выставке компьютерных технологий Comdex в Лас-Вегасе, делегация из Москвы демонстрировала публике первые прототипы своей системы. Она позволяла распознавать отсканированный текст и надписи, сделанные электронной ручкой.
Стенд ПараГраф посетил глава компании Lotus Development Corporation – Митч Капор. Сам он в конце 80-х был фигурой масштаба Стива Джобса или Билла Гейтса, а компания входила в тройку крупнейших производителей ПО, выполняя контракты для IT-гигантов, в том числе и для Apple.

Стив Джобс, Митч Капор и Билл Гейтс
Капор с интересом протестировал разработки советских программистов и остался доволен работой технологии распознавания рукописного ввода. Он продемонстрировал увиденное Джерри Каплану, сооснователю компании GO Corporation, которая разрабатывала портативные компьютеры.
Интерес и одобрение технологии со стороны крупных предпринимателей подтолкнули Пачикова к важному звонку. Он нашел ту самую судьбоносную визитку и набрал телефонный номер Эла Айзенштата.
В коротком разговоре Степан напомнил вице-президенту Apple о встрече в Москве, рассказал о привезенных в США технологиях и одобрении разработок ПараГраф со стороны Капора и Каплана.
Упоминание интереса со стороны прямых конкурентов Apple сделало свое дело. В то время купертиновцы соперничали с GO Corporation, пытаясь первыми выпустить мобильный гаджет с распознаванием рукописного ввода на рынок.
Уже через 15 минут Степану Пачикову перезвонили из Apple и назначили встречу с ответственными за разработку гаджетов топ-менеджерами. Так первый советский стартап получил возможность продемонстрировать свою технологию руководству одной из ведущих компьютерных компаний мира.
Первый контракт с Apple едва не сорвался
На назначенной встрече представители ПараГраф продемонстрировали рабочий прототип системы распознавания текста высшему руководству компании Apple.
Презентация не заладилась с первых минут, а во время тестовой проверки системы случались досадные ошибки и сбои. Ни одно введенное цифровой ручкой слово не распознавалось корректно.
Когда демонстрация почти провалилась, Пачиков попытался найти оправдание такой работе системы. Он сослался на отсутствие хорошего английского цифрового словаря в СССР, который мог бы лечь в основу программы для распознавания текста.
Советские разработчики для тестирования и обучения системы использовали самодельный словарь, который в основном состоял из текстов песен группы The Beatles. Найти такой словарь в электронном виде в конце 80-х было проще, чем любой другой оцифрованный английский текст.
Представители Apple после такого рассказа начали вводить в тестовую систему слова и фразы из песен ливерпульской четверки. Результат оказался ошеломительным. Практически все введенные словосочетания без проблем были распознаны системой и переведены в цифровой вид.

Результатом встречи стал первый контракт советской компании с Apple на сумму $75 000. Никаких сложных обязательств или передачи прав на интеллектуальную собственность от ПараГраф не требовалось. Нужно было лишь организовать прием делегации из Купертино в Москве.
Представители Apple хотели лично увидеть работу компании, познакомиться с сотрудниками и пощупать все имеющиеся наработки.
Двухнедельный визит в Москву доказал подлинность компании и наличие у нее нужных разработок для будущих яблочных продуктов. Купертиновцы увидели типичный гаражный стартап, с поправкой на советский менталитет, который был готов для поглощения крупной компанией.
Как продолжалось сотрудничество Apple и ПараГраф

Московский офис ПараГраф. Фото: gettyimages
После удачного визита в Москву, купертиновцы решили сделать предложение компании ПараГраф и полностью приобрести все отечественные наработки. В Apple верили, что смогут перевести систему распознавания на свою ОС и доработать под нужды будущего проекта самостоятельно.
После долгих дискуссий и переговоров представители Apple согласились на вариант сотрудничества с советскими разработчиками. Те в свою очередь пообещали открыть офис в США и перевезти в Кремниевую долину всех отвечавших за проект сотрудников.
Составление и согласование контракта тянулось еще почти полгода. Наконец все стороны были довольны и поставили свои подписи под соглашением. Контракт на несколько сотен тысяч долларов между первой компанией из СССР и Apple был заключен, а через месяц в стране случился августовский путч.
Технология распознавания рукописного текста компании ПараГраф стала основой для операционной системы Newton. Под ее управлением была выпущена целая линейка портативных устройств Apple под названием MessagePad.
Что в итоге вышло из такого сотрудничества

Сотрудники ПараГраф в США
Дальнейшее сотрудничество между компаниями находится под грифом корпоративной секретности. Купертиновцы, как и любая другая крупная компания, хранят в строжайшей секретности свои разработки и не спешат делиться подробностями с прессой.
Линейка MessagePad просуществовала более шести лет и включала восемь разнообразных гаджетов двух классов: наладонник и портативный ноутбук. Гаджеты не имели ожидаемого успеха на рынке, а продажи каждого из устройств были весьма скромными, как для такой крупной компании.
В итоге разработку и выпуск портативных устройств закрыл лично Стив Джобс после своего возвращения в Apple. Ошибки и наработки проекта были позже учтены при разработке первого iPhone и iPad.
Низкий интерес покупателей аналитики объясняют высокой ценой гаджета (от $900 до $1000), большими размерами (184,75 × 114,3 × 19,05 мм) и нереализованным функционалом. За год до старта продаж первой модели MessagePad глава Apple Джон Скалли провел презентацию устройства и рассказал о феноменальных возможностях будущего гаджета в области распознавания рукописного текста.
Первые модели устройств и сопутствующего ПО не давали большей части обещанных фишек, за разработку которых частично отвечали советские программисты из ПараГраф.

MessagePad 2100 и его потомок iPhone
Прямой вины отечественных разработчиков в таком провале нет. Все дело в той самой корпоративной конфиденциальности Apple, которая была призвана минимизировать утечки информации о разрабатываемых продуктах.
Долгое время команда ПараГраф даже не знала, для какого устройства они разрабатывают ПО и под какие технические параметры им нужно адаптировать свою систему распознавания ввода. Лишь после появления первого гаджета на рынке и выявленных недочетов готового устройства разработчики смогли более точно понять поставленную задачу и начать устранение недостатков системы.
К моменту выпуска более поздних моделей MessagePad недостатки технологии распознавания рукописного ввода были устранены, а пользователи получили отлично справляющийся с подобной задачей гаджет в виде MessagePad 2000 и MessagePad 2100. Но момент был упущен, покупатели успели получить негативный опыт, а на рынке во всю властвовал главный конкурент наладонника Apple – Palm Pilot.
Возможно, если бы советские разработчики изначально стали полноценными членами команды Newton, к выходу первой модели удалось бы избежать большей части допущенных ошибок и косяков. Это могло бы положительно сказаться на развитии линейки и дальнейшем векторе разработок всей компании Apple.
Однако случилось так, как случилось и отечественные разработки забыли в Apple как страшный сон.
Куда пропали технологии ПараГраф

Большая часть сотрудников так и осталась жить и трудиться в США. Кто-то продолжил карьеру в других крупных компаниях Кремниевой долины, а кто-то основал еще несколько успешных стартапов.
Две компании Пачикова Paragraph и Parascript пошли по разному пути развития. Первая прошла разные стадии поглощения и перестала существовать в виде самостоятельного субъекта уже через несколько лет, а вторая – существует и сегодня. В 2008 году при содействии Пачикова был запущен веб-сервис Evernote.
Любопытно, что технология распознавания рукописного текста, представленная компанией ПараГраф, была приобретена правительством США и внедрена для сортировки писем на почте. С некоторыми доработками и изменениями она до сих пор состоит на вооружении национальной почтовой службы в Америке.
Ежедневно она помогает обрабатывать миллионы почтовых отправлений внутри страны и за ее пределы.
В Купертино тоже окончательно не похоронили все идеи и наработки за времена сотрудничества с отечественными программистами. Проект был просто отложен в долгий ящик, его в итоге “воскресили” с выходом iPadOS 14.
Опция под названием Scribble базируется на технологиях 30-летней давности. Лишь при наличии современных процессоров, нейронных сетей и машинного обучения удалось довести её до совершенства.
Это позволяет пользователям iPad при использовании Apple Pencil превращать рукописный текст в распознанный электронный. По иронии судьбы, придуманная нашими программистами технология, до сих пор не поддерживает русский язык. Но это уже претензия к региональной политике Apple.
(30 голосов, общий рейтинг: 4.87 из 5)
Хочешь больше? Подпишись на наш Telegram.
Источник: www.iphones.ru