
KTNI_Козлов(ответы) / 11
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные — последовательность кодов, использующихся для представления символов в компьютере (например, в текстовом редакторе).
Задача оптического распознавания
— Перевод документов, научных публикаций, социальной информации, исторических изданий в электронный вид.
— Накопление и хранение электронных документов.
- 1929 году — Густав Таушек (Gustav Tauschek) получил патент на метод оптического распознавания текста в Германии;
- 1933 год — Гендель (Paul W. Handel) получил патент на свой метод в США ;
- 1935 год – Г. Таушек также получил патент США на свой метод;
- 1950 год — Дэвид Х. Шепард (David H. Shepard) — построил машину, решающую задачу преобразования печатных сообщений в машинный язык для обработки компьютером.
- 1955 год — Первая коммерческая система была установлена на «Ридерс Дайджест»
- 1965 год — «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений.
- 1965 год — Почтовая служба Соединённых Штатов для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым.
- 1971 год — Почта Канады использует системы оптического распознавания символов
- 1974 год — Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом.
- 1978 год — Компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов.
- 1992 год – Начало продажи первой коммерчески успешной программой, распознающей кириллицу, «AutoR» российской компании «ОКРУС» (ОС DOS).
- Конец 60-х годов – разработка и испытание шрифтонезависимого алгоритма распознования текста выпускниками МФТИ, биофизиками: Г. М. Зенкиным и А. П. Петровым
При создании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов. С помощью сканера несложно получить изображение страницы текста в графическом файле. Однако для получения документа в формате текстового файла необходимо провести распознавание текста, т. е. преобразовать элементы графического изображения в последовательности текстовых символов. -Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и т. д. -Далее выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст. Хорошее качество текстаРастровый метод распознавания текста Если исходный документ имеет типографское качество (достаточно крупный шрифт, отсутствие плохо напечатанных символов или исправлений), то задача распознавания решается методом сравнения с растровым шаблоном. -Сначала растровое изображение страницы разделяется на изображения отдельных символов. -Затем каждый из них последовательно накладывается на шаблоны символов, имеющихся в памяти системы, и выбирается шаблон с наименьшим количеством точек, отличных от входного изображения. 
 Программы распознавания текста Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR). Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами, но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word. Наиболее распространенные системы оптического распознавания символов, например, ABBYY FineReader и CuneiForm от Cognitive, используют как растровый, так и структурный методы распознавания. Кроме того, эти системы являются «самообучающимися» (для каждого конкретного документа они создают соответствующий набор шаблонов символов) и поэтому скорость и качество распознавания многостраничного документа постепенно возрастают. Существует также системы On-line распознавания текста: OnlineOCR и ABBYYFineReaderOnline (http://www.onlineocr.ru, http://finereader.abbyyonline.com) Системы оптического распознавания форм При проведении Единого государственного экзамена, при заполнении налоговых деклараций и т. д. используются различного вида бланки с полями. Рукописные тексты (данные вводятся в поля печатными буквами от руки) распознаются с помощью систем оптического распознавания форм и вносятся в компьютерные базы данных. Сложность состоит в том, что необходимо распознавать символы, написанные от руки, а они довольно сильно различаются у разных людей. Кроме того, система должна определить, к какому полю относится распознаваемый текст. Системы распознавания рукописного текста. С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ. OCR-приложения-Это приложения, которые производят сканирование и распознавание текста, от англ. Optical Character Recognition — Оптическое распознавание символов -Это программы для перевода изображений документов в редактируемый текст, который можно затем обрабатывать в текстовых и табличных редакторах. По сравнению с ручной перепечаткой текста, такие программы дают существенный выигрыш в скорости работы, к тому же делают меньше ошибок. Еще одно достоинство — возможность сохранить иллюстрации, а они иногда не менее важны, чем текст документа. OCR CUNEIFORM -Это бесплатная программа сканирования и распознавания текста российского разработчика Cognitive Technologies. -OCR CuneiForm обеспечивает быстрое, удобное и качественное распознавание текста с сохранением исходного вида документа. Поддерживается распознавание с более 20 языков, среди них русский, украинский, английский, немецкий, французский, испанский, итальянский, португальский, шведский, финский, сербский, хорватский, польский, а также распознавание смешанного русско-английского текста. ABBYY FineReader
Программы распознавания текста Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR). Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами, но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word. Наиболее распространенные системы оптического распознавания символов, например, ABBYY FineReader и CuneiForm от Cognitive, используют как растровый, так и структурный методы распознавания. Кроме того, эти системы являются «самообучающимися» (для каждого конкретного документа они создают соответствующий набор шаблонов символов) и поэтому скорость и качество распознавания многостраничного документа постепенно возрастают. Существует также системы On-line распознавания текста: OnlineOCR и ABBYYFineReaderOnline (http://www.onlineocr.ru, http://finereader.abbyyonline.com) Системы оптического распознавания форм При проведении Единого государственного экзамена, при заполнении налоговых деклараций и т. д. используются различного вида бланки с полями. Рукописные тексты (данные вводятся в поля печатными буквами от руки) распознаются с помощью систем оптического распознавания форм и вносятся в компьютерные базы данных. Сложность состоит в том, что необходимо распознавать символы, написанные от руки, а они довольно сильно различаются у разных людей. Кроме того, система должна определить, к какому полю относится распознаваемый текст. Системы распознавания рукописного текста. С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ. OCR-приложения-Это приложения, которые производят сканирование и распознавание текста, от англ. Optical Character Recognition — Оптическое распознавание символов -Это программы для перевода изображений документов в редактируемый текст, который можно затем обрабатывать в текстовых и табличных редакторах. По сравнению с ручной перепечаткой текста, такие программы дают существенный выигрыш в скорости работы, к тому же делают меньше ошибок. Еще одно достоинство — возможность сохранить иллюстрации, а они иногда не менее важны, чем текст документа. OCR CUNEIFORM -Это бесплатная программа сканирования и распознавания текста российского разработчика Cognitive Technologies. -OCR CuneiForm обеспечивает быстрое, удобное и качественное распознавание текста с сохранением исходного вида документа. Поддерживается распознавание с более 20 языков, среди них русский, украинский, английский, немецкий, французский, испанский, итальянский, португальский, шведский, финский, сербский, хорватский, польский, а также распознавание смешанного русско-английского текста. ABBYY FineReader
- Популярная программа распознавания текста российской компании ABBYY
- Программа производит распознавание текста с более 180 языков, для 38 из них предусмотрена встроенная проверка орфографии. Начиная с версии Professional, распознаются иврит, японский, тайский, китайский языки. Finereader открывает файлы графических форматов (TIFF, JPG, PFD, PNG и др.) в том числе DjVu – компактный формат для хранения отсканированных документов, книг.
- Стоимость программы 3990 рублей
OmniPage
- Популярная программа распознавания текста российской компании ABBYY
- Программа отличается высокой скоростью и точностью распознавания. Распознаются более 120 языков с различными алфавитами: латинский, греческий алфавиты, кириллица, китайский, японский и корейский языки. Как и FineReader, OmniPage уверенно распознает документы, полученные с помощью цифровых камер с помощью технологии коррекции изображения «3D Correction».
- Стоимость программы 6090 рублей
- (150 евро)
Readiris
- Программа сканирования и распознавания текста компании I.R.I.S.
- Поддерживается распознавание текста с более 120 языков распознавания, включая русский, а также ближневосточные языки — арабский, иврит, фарси (в версии Middle-East) и японский, китайский, корейский (в версии Asian). Есть версия Readiris для Macintosh.
- Вместе с поддержкой распознавания популярных форматов картинок, распознаются файлы PDF и DjVu.
- Стоимость программы
- 3845-14875 рублей (129 $-499 $)
Microsoft Office Document Imaging
- Программа распознавания текста компании Microsoft
- Программа Document Imaging способна работать только с двумя языками: английским и языком локализации самого MS Office. Для поддержки других языков необходимо дополнительно устанавливать пакет Multilingual User Interface (MUI). OCR настроек в программе практически нет, программа в автоматическом режиме поддерживает распознавание типа и размера шрифтов, картинок и простых таблиц.
- Стоимость программы входит в стоимость пакета MS Office.
Распознавание текста в FineReader
Урок 6: Сканирование и распознавание
Источник: studfile.net
8 приложений для сканирования документов и распознавания текста
Смартфоны могут быть полезны много для чего, однако для оцифровки документов их используют не так уж и часто. Иногда очень нужно отсканировать бланк в аккуратный PDF-файл, оцифровать чек или отправить отсканированную форму по email.
Если вы здесь, значит, вы попали в одну из подобных ситуациях. Я составил рейтинг лучших приложений для сканирования документов с функцией распознавания текста под Android и iOS. Ситуации бывают разные, поэтому я разделил приложения на 2 группы: с поддержкой русского языка и английского языка. Первая группа включает в себя оба языка, а последняя — только английский.
С поддержкой русского языка
CamScanner
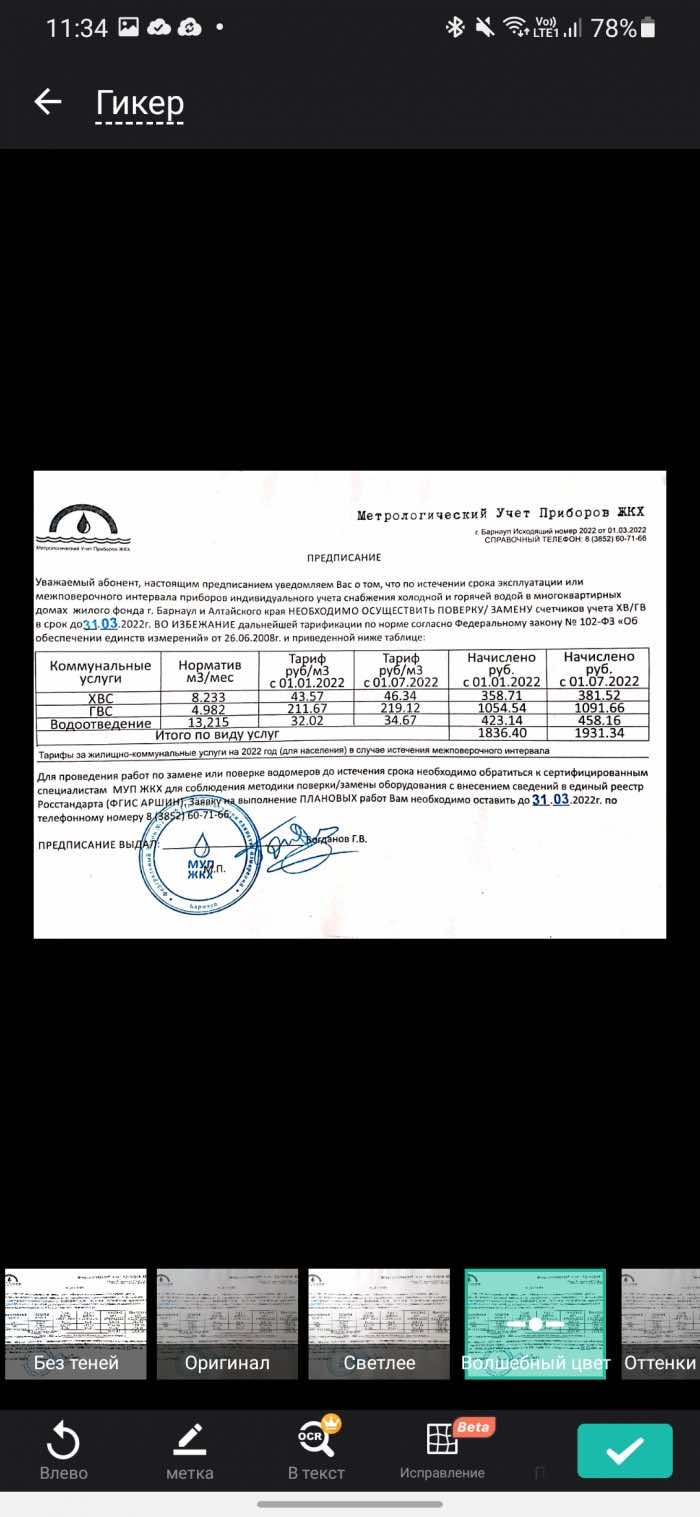
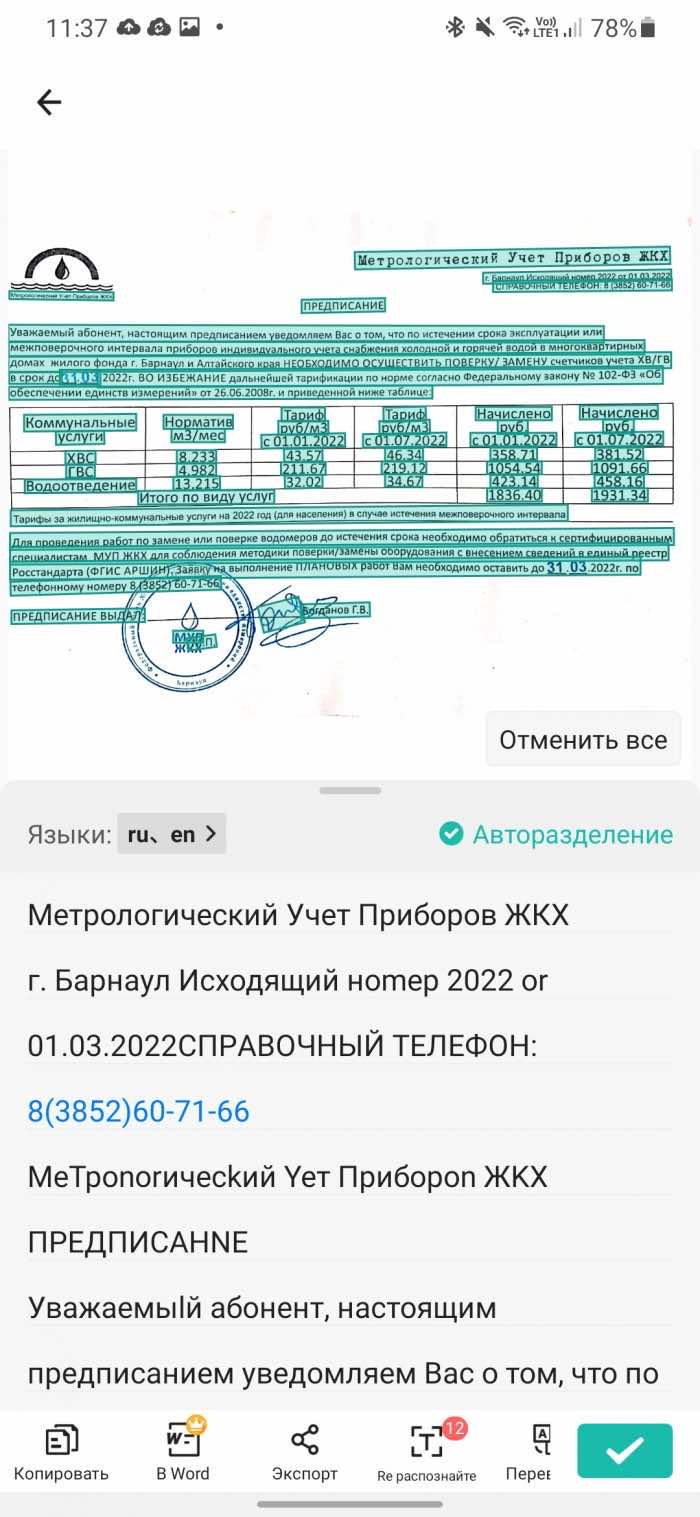
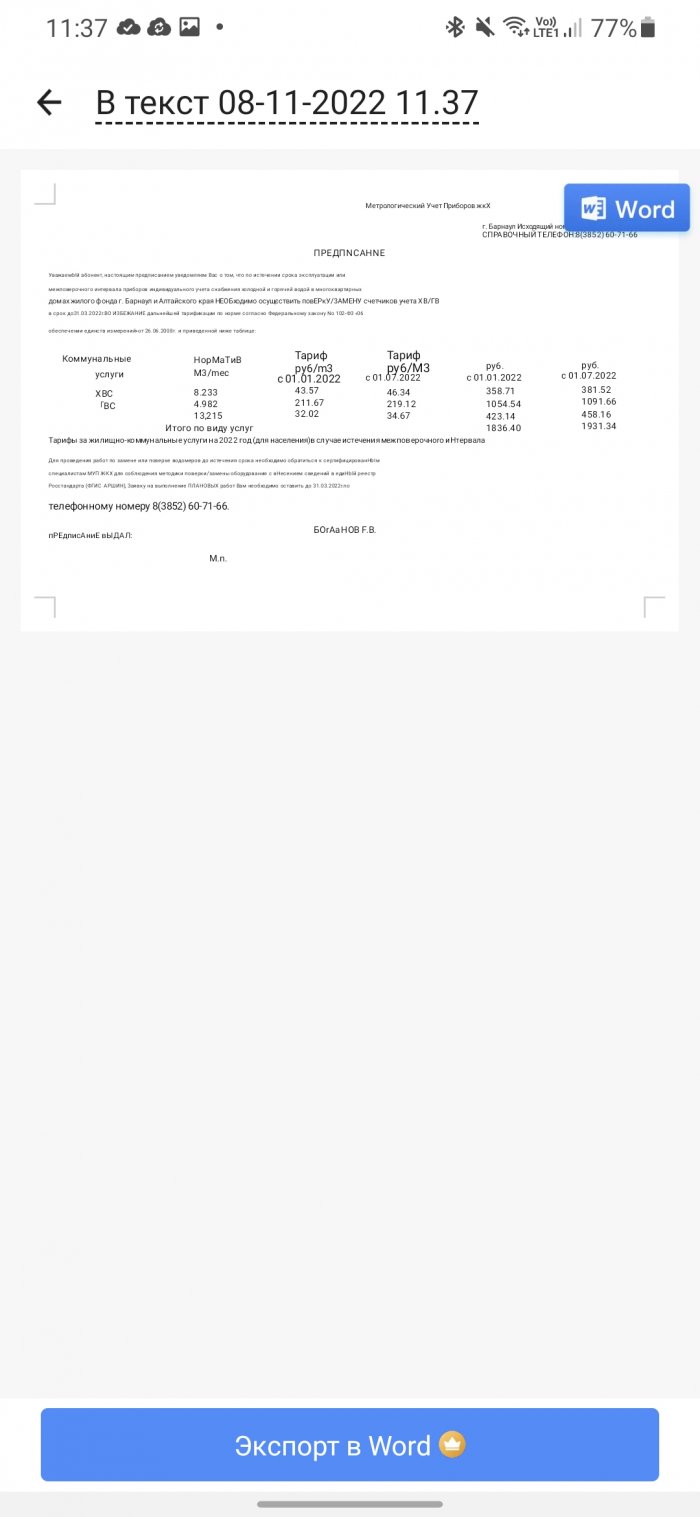
CamScanner приятно удивил. Он отлично справился с тестовым заданием: определил таблицу на фото и правильно сверстал ее для Word, распознал русский текст и дал возможность бесплатно сохранить результат в формате Word. После сканирования можно сразу посмотреть, как будет выглядеть документ (см. 3 скриншот).
Зарегистрированные пользователи (доступна авторизация через Gmail) могут бесплатно распознать 12 страниц в месяц. И 4 раза перевести документ на нужный язык.
А теперь подробней про распознавание текста. Чтобы у вас не было мешанины русских и английских букв как на втором скриншоте (оставил его для примера), вам нужно указать, что документ содержит текст только на русском языке.
По умолчанию там стоит английский, чтобы распознать русский текст — тапните на серое поле «Языки», выберите из списка «Русский» и снимите галочку с «Английский». Это нужно, чтобы приложение понимало, что отсканированный документ содержит только русские буквы. В противном случае, программе будет сложно понять, например, это русская «л» или английская «n». Это происходит потому, что система OCR обрабатывает каждый символ по отдельности, а не все слово сразу. И даже если слово на русском языке, OCR из-за этой особенности может перепутать буквы.
Doc Scanner


Doc Scanner позиционирует себя как универсальное решение для сканирования «всё в одном». Оно включает в себя все базовые функции, такие как конвертация в PDF, поддержку OCR (технология оптического распознавания символов). Недавно появилась функция пакетного редактирования для обрезки и применения фильтров для нескольких страниц. После сканирования файл можно сразу отредактировать. Есть ластик для удаления ненужной информации.
Это одно из немногих приложений, которое автоматически определяет язык текста и выполняет распознавание. Поэтому не будет мешанины русских и английских букв, как это случается в CamScanner. Для работы с русским языком нужно в настройках приложения скачать языковый пакет размером 15 МБ. Результат можно посмотреть на 3 скриншоте. К большому сожалению, приложение не разделяет текст и таблицы.
С премиум тарифом, стоимостью 440 рублей за 3 месяца можно сканировать документы без ограничений, создавать коллаж документов из нескольких изображений, копировать текст с изображений, сохранять файлы в облако, добавлять подпись (даже можно нарисовать подпись на экране) и устанавливать пароль. Кроме подписи, можно добавить водяной знак.
Tiny Scanner



Tiny Scanner полностью оправдывает свое название. Это небольшое приложение, без большого функционала. Если вам нужно просто распознавание текста, без таблиц — это хороший вариант. Так как приложение не распознает таблицы, весь текст с документа выводится в виде «простыни» текста, хоть и с сохранением регистра слов.
Распознанный текст можно сохранить в формате обычного txt-файла или в Word-формате. Бесплатно доступно распознавание текста только для 2 страниц.
Премиум-план за 369 рублей в месяц (бесплатно 3 дня) дает доступ к OCR на базе AI (разные языки, распознавание рукописного текста), удаляет рекламу и снимаете ограничение на количество сканирования.
Microsoft Lens
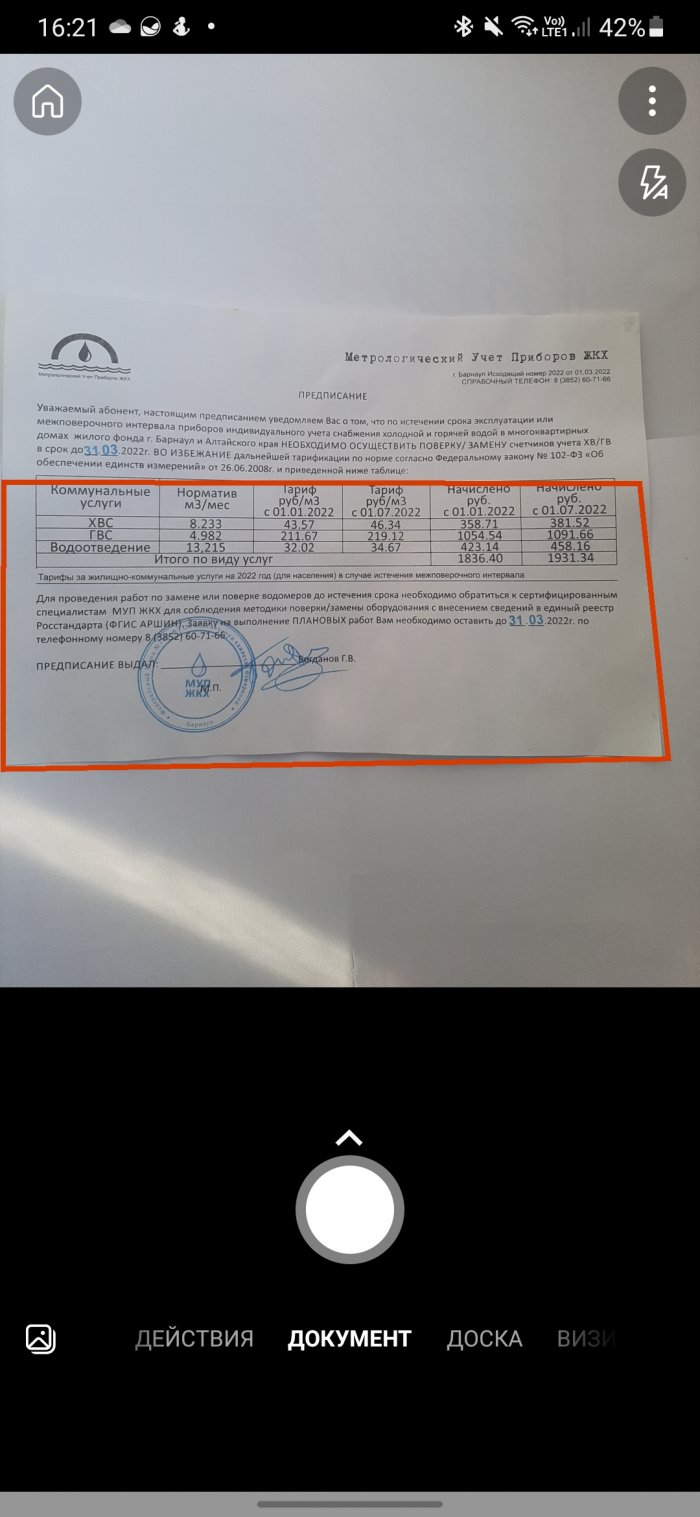
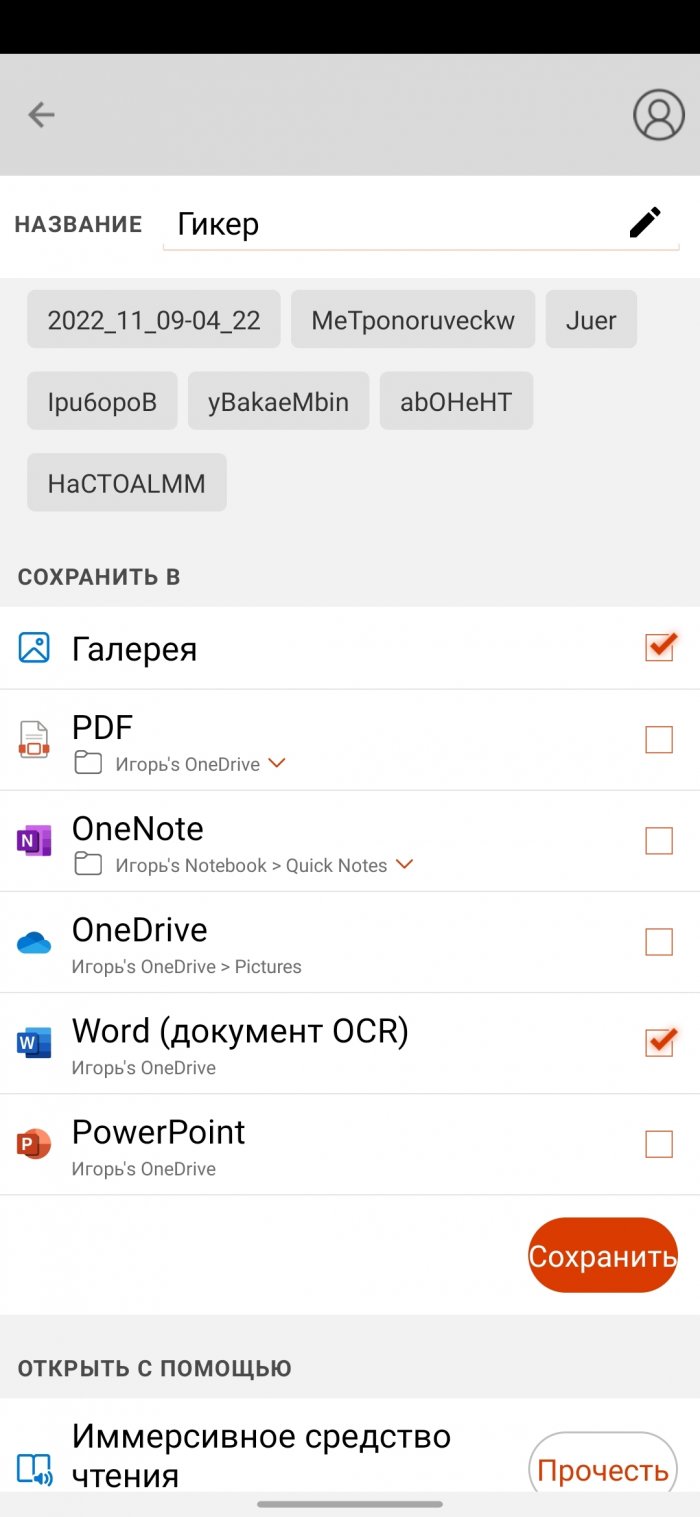
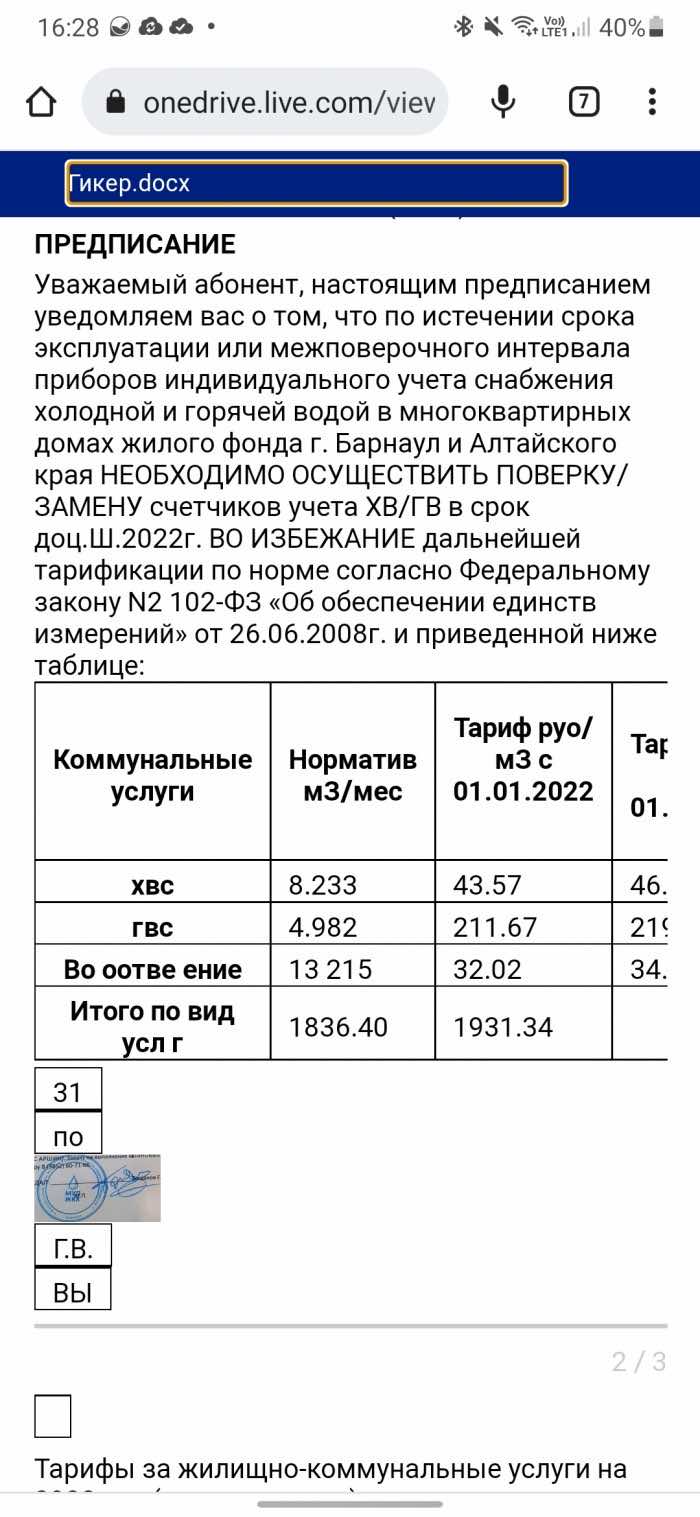
Хотя MS Lens поддерживает 30 языков, в том числе русский, и умеет распознавать таблицы в изображении, что уже большая редкость, но конечный результат нельзя назвать идеальным. В недостатки я бы также еще записал необходимость загружать документ в облако для распознавания текста. Лучше было бы, если это происходило сразу на телефоне. Но учитывая, что это приложение полностью бесплатное, все эти минусы уже не кажутся настолько большими. Подписка на Office 365 также не требуется.
Функционал по редактированию тоже небогатый: фильтры, обрезка фото, возможность добавить текст или рукописный ввод, ну и изменить порядок страниц. Все отсканированные документы сохраняются в одну кучу, поэтому в плане организации — это большой минус. Если много сканируете, и нужен порядок в документах, то лучше обратить внимание на приложение Doc Scanner.
С поддержкой английского языка
Fast Scanner



Fast Scanner — это настоящая находка, если вам не нужно распознавание русского текста. Даже в бесплатной версии, для текста на латинице, китайском, корейском или японском — нет ограничений на количество страниц для распознавание текста (но нет массового режима). При этом приложение отлично работает без доступа в интернет.
Вы можете бесплатно отсканировать неограниченное количество документов, отсортировать их в нужном порядке и за пару секунд создать PDF-файл. Платная версия ничем не отличается от бесплатной, кроме возможности автоматической загрузки в облачное хранилище и отсутствие рекламы.
Clear Scan

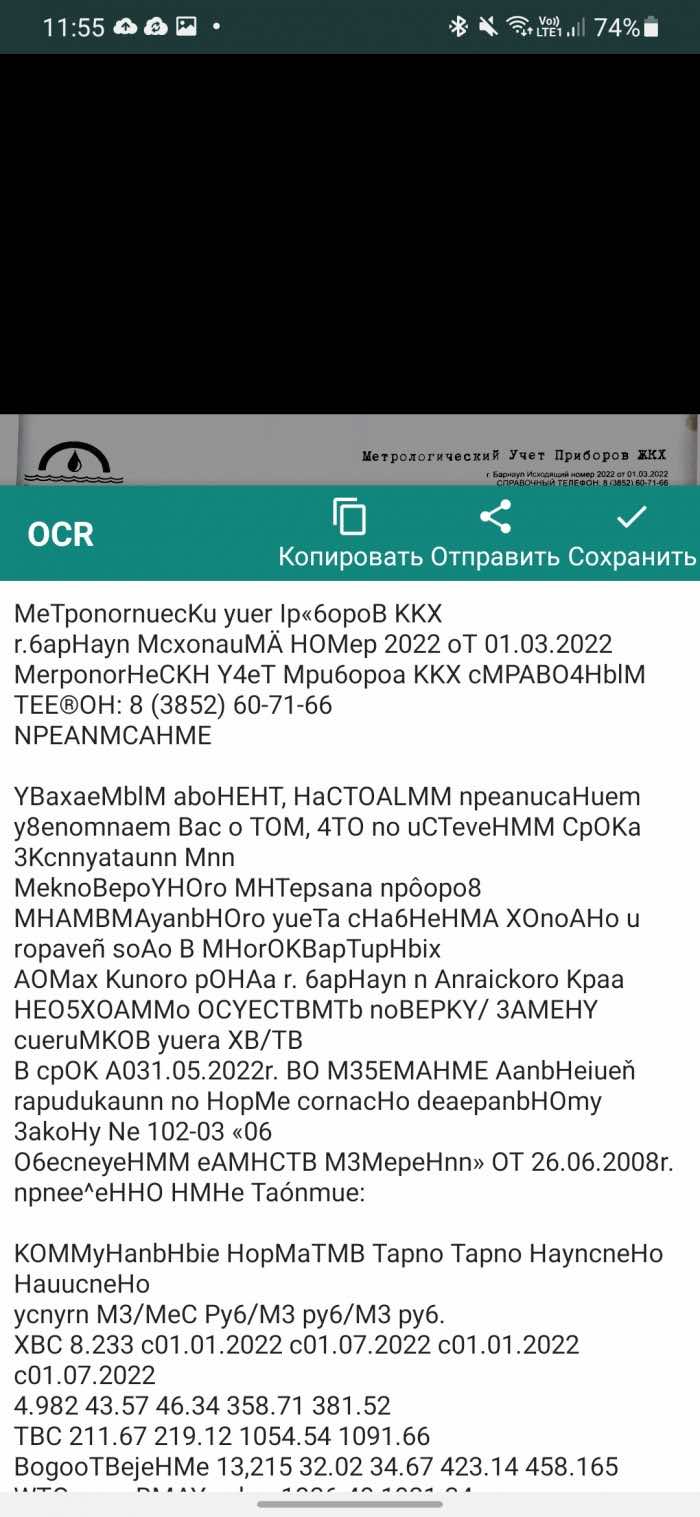
Начну с главного, Clear Scanner поддерживает распознавание текста на 18 языках, но не русского. Английский язык распознает отлично, за считаные секунды. Можно импортировать PDF, изображение, создавать папки для организации документов.
TurboScan



TurboScan – одно из вспомогательных приложений для сканирования. Включает в себя все основные функции. Также предоставляет возможность корректировки перспективы и датчик краёв страницы для более качественного сканирования. Обладает высокой скоростью обработки и может сохранять документы в форматы PDF, JPEG и PNG.
Поддерживает работу с многостраничными элементами, однако бесплатная версия ограничивает работу до 3-х страниц. Полная версия снимает все ограничения.
Adobe Scan


От Adobe Scan я ожидал максимального функционала, самую лучшую систему распознавания текста и возможность экспорта отсканированного документа в PDF. Но я был разочарован — это всё есть, но только на платном тарифе за 899 рублей в месяц. Есть бесплатный пробный период в 7 дней, но использовать его в данный момент нельзя из-за приостановки обработки платежей из РФ в Google Play.
Поэтому пользователи из России могут только сфотографировать документ, применить различные фильтры, повернуть картинку, изменить ее размер, и всё. Если у вас есть возможность оплатить платную подписку, то для вас открываются новые возможности:
- Экспорт в Word, Excel и PowerPoint.
- Распознавание текста (до 100 страниц).
- Установка пароля на документ.
- Объединение нескольких файлов.
К сожалению, мне протестировать это не удалось. Тем не менее я оставляю приложение в рейтинге для пользователей из других стран. Возможно, что вы останетесь им довольны. Ведь это Adobe и все должно быть на высшем уровне.
Бонус: OpenScan


OpenScan – это бесплатный сканер для Android с открытым исходным кодом. Максимально простое приложение для сканирования документов и сохранения сканов в виде изображений или PDF-файлов. Исходный код находится в открытом доступе на GitHub – с ним вы можете создать собственную версию приложения, если умеете программировать на C++ и Java.
OpenScan ориентирован именно на приватность. В нём нет распознавание текста. Результат можно сохранить только в PDF-формате. Если вы ищете максимально конфиденциальное приложение, то OpenScan – хороший выбор, оно не собирает данные, всё остаётся внутри телефона.
Источник: geeker.ru
Программы для распознавания и сканирования текста
Нужно отредактировать на компьютере сфотографированный документ или распечатанный текст, и вы хотите знать, какое приложение справится с этим лучше всего? Представляем вам лучшие бесплатные программы для сканирования и распознавания текста.
ABBYY FineReader: Home Edition
WinScan2PDF
Capture Text
Informatik Scan
Вопросы:
Как защитить PDF документ от копирования?
Как распознать текст из фотографий книги?
Как редактировать текст в PDF файлах?
Другие вопросы по работе с текстом
ABBYY FineReader: Home Edition
Функционал
Перед нами профессиональная система оптического распознавания текста. Её устанавливают не только для домашнего использования, но также и в крупных компаниях. Пожалуй, это самый популярный софт в данном сегменте. Единственное, что следует иметь в виду – в полной версии программа платная.
Однако, можно скачать и бесплатный вариант, так называемую испытательную версию ABBYY FineReader: Home Edition. Она будет работать в течение 15 дней и за это время сможет распознать 50 страниц.
Программа позволит из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст. Она распознает 179 языков и экспортирует тексты в Word, Excel, PowerPoint или Outlook. Программа для сканирования и распознавания текста ABBYY FineReader очень удобна в использовании, поскольку во время сканирования сохраняет внешний вид документа, а также его структуру.
То есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале. Во время установки выберите язык интерфейса (к примеру, русский). Меню составлено логично и понятно, так что разобраться в нём не сложно.
Функционал
А вот это совершенно бесплатная программа от российского разработчика Cognitive OpenOCR. Земляки позиционируют своё творение как интеллектуальную систему преобразования бумажных документов и графических файлов в редактируемый вид. В результате мы получим сохраненные структуру и гарнитуры шрифтов оригинала. Обрабатывать документы можно как в одиночном, так и в пакетном режиме.
Среди возможностей CuneiForm — сканирование текста и изображений; распознавание текста на 20 языках; работа с различными шрифтами (книжными, газетными, с пишущих машинок); распознавание таблиц и их содержимого (в том числе без сетки); «понимание» как чёрно-белых, так и цветных документов.
Программа отлично справляется даже с не очень качественными исходниками. Алгоритм оптического распознавания (именно так расшифровывается OCR), составляющий основу CuneiForm, преобразует в редактируемый вид и такие непростые оригиналы как текст с матричного принтера, плохие ксерокопии и факсы. А для улучшения качества распознания в CuneiForm предусмотрена опция словарной проверки.
При этом пользователь может сам добавить новые слова, встречаемые в текстах, если таковые не найдутся в словаре. А для удобства обработки теста в электронном варианте к нашим услугам интегрированный текстовый редактор. Само меню представлено большими понятными кнопками (которых не так уж много), так что работать с ним сможет даже неискушенный юзер.
Все основные функции заложены в кнопку, на которой изображена «волшебная палочка», — это своеобразный мастер-проводник. Нажав на неё, вы пройдёте все этапы — от сканирования до редактирования и сохранения, лишь подтверждая операции. Единственный минус программы – это то, что она не поддерживает файлы формата PDF. В остальном, CuneiForm – превосходная программа для сканирования и распознавания текста. Скачать бесплатно её можно на любую версию Windows.
Источник: softobase.com
Как сканировать и распознать текст
В данной статье мы рассмотрим, как переделать «бумажный» текст в цифровой, то есть разберем процесс сканирования документа. Сканировать документ просто так нельзя, для этого, естественно, необходимо такое оборудование, как сканер. Сканер должен быть подключен к компьютеру и на него должны быть установлены драйвера.
Для того чтобы иметь возможность сканировать документ, должна быть установлена программа Fine Reader. Программа, к сожалению, платная. Если вы приобретали данную программу, то с установкой проблем не будет.
Для того чтобы начать сканировать документ, кладем его под крышку сканера, естественно, текстом вниз. Запускаем Fine Reader. Я запускаю 7-ю версию, вы какую есть, принцип работы везде одинаковый. Нажимаем «Файл – Сканировать изображение».
Внимание. Если у вас уже есть готовая картинка с текстом, которую вы где-то взяли либо файл PDF, то в таком случае никакой сканер вообще не нужен и вы должны выбрать пункт «Открыть изображение» и далее просто распознать его.

Далее запускаются настройки сканера, и я выбираю пункт «Черно-белый рисунок или текст», потому что для меня важен именно текст.

Через некоторое время страница отсканируется, и изображение появляется на экране. Я выделяю необходимую мне область текста и кликаю по выделенному участку правой кнопкой мыши. Выбираю «Тип блока — Текст». Если вам нужна картинка, то, значит, ее и выбирайте.

Блок выделяется зеленой границей. Я опять кликаю по нему правой кнопкой мыши и выбираю пункт «Распознать блок».

Справа в окошке появляется уже необходимый нам текст, который можно копировать и вставлять в любой документ. Для того чтобы передать отсканированный текст в Word, необходимо нажать «Файл – Передать все страницы в – Microsoft Word»

На самом деле программа Fine Reader очень мощная и в этой статье я показал лишь небольшую долю ее возможностей.
Источник: comp-profi.com