
Программы для распознавания текстов
Бесплатная программа для распознавания отсканированных или сфотографированных тестов. Понимает любой печатный шрифт и сохраняет структуру документа. Позволяет отправлять результаты в текстовые редакторы.
ABBYY FineReader
Программа для распознавания печатных символов. Утилита отличается высокой точностью в работе при преобразовании отсканированных снимков в цифровой формат документов.
Readiris
Программа для сканирования и оцифровки документов. Поддерживает оптическое распознавание текстов на многих языках, включая русский, и экспорт в большое число форматов, в том числе PDF и XPS.
RiDoc
Программа для удобного сканирования и уменьшения размера офисных документов без потери в качестве. Также поддерживается функция распознавания текста, наложения водяного знака и экспорт офисных файлов в формат изображений.
VueScan
VueScan – приложение для расширения функционала старого сканера (совместимо с более чем 600 моделями). Сканируйте слайды, негативы и старые фотографии без потери исходного качества.
Программы распознавания текста
SimpleOCR
Программа для распознания рукописного и машинного текста, написанного на английском, французском и датском языках. Также считывает информацию со сканера и преобразовывает ее в форматы TXT, DOC или TIFF.
TopOCR
Программа для распознавания, простого редактирования, а также чтения текста вслух. Поддерживает 11 различных языков и может напрямую работать со сканером. Позволяет быстро переводить документы и создавать аудиокниги.
FBReader
FBReader – небольшое приложение для чтения текстовых документов формата FB2. Оно корректно отображает электронные книги с картинками, графиками и сносками, а также поддерживает быстрый переход между страницами.
Capture Text
Программа для перевода оптического текста в цифровой формат. Подходит для оцифровки текстовой информации, которую нельзя перевести в буфер обмена, а также распознавания отсканированных бумажных документов.
Informatik Scan
Программа для сканирования и распознавания документов. Поддерживает все устройства, работающие по наиболее популярному протоколу TWAIN. Содержит интегрированный редактор изображений, позволяющий удалить «засвеченные» области.
Eсли вaм нужно отскaнировать печатный документ и распознать его на компьютере, чтобы дальше приступить к редактированию, прежде всего, необходимо скачать программы для распознавания текстов.
Этот софт подразумевает распознавание текста с фотографии, то есть, вы запросто сможете перенести написанное в книге, журнале или каком-нибудь документе в тeкстовый рeдактор Micrоcoft Оffice или Open Оffice. Вы можете испытать такой популярный продукт как ABBYY FineReader.
Но сразу укажем – бесплатно предоставляется лишь пробная версия. В тo жe врeмя, есть и полностью бесплатные аналоги, мало чем уступающие в функционале. Например, OCR CuneiForm.
Источник: softobase.com
Распознавание текста. Перевести картинку и пдф в ворд. Лучшие методы
Лучшие программы для распознавания текста

Утомительное перепечатывание текста для приведения его в электронный вид давно уже отошло в прошлое, ведь сейчас существуют довольно продвинутые системы распознавания, работа с которыми требует минимального вмешательства пользователя. Программы для оцифровки текста востребованы как в офисе, так и дома. В настоящее время существует довольно большое разнообразие различных приложений для распознавания текста, но какие из них действительно лучшие? Попробуем разобраться в этом вопросе.
ABBYY FineReader
Эбби Файн Ридер – самая популярная программа для сканирования и распознавания текста в России, а, возможно, и в мире. Данное приложение имеет в своем арсенале все необходимые инструменты, что и позволило ему достичь такого успеха.
Кроме сканирования и распознавания, ABBYY FineReader позволяет производить расширенное редактирование полученного текста, а также выполнять ряд других действий. Программа отличается очень качественным распознаванием текста и быстротой работы. Мировую популярность она заслужила также благодаря возможности оцифровки текстов на многих языках мира, а также мультиязычному интерфейсу. Среди немногих недостатков FineReader можно, разве что, выделить большой вес приложения и необходимость платить за пользование полноценной версией.
Readiris
Главным конкурентом Эбби Файн Ридер в сегменте оцифровки текста является приложение Readiris. Это функциональный инструмент для распознавания текста как со сканера, так и с сохраненных файлов различных форматов (PDF, PNG, JPG и др.). Хотя по функционалу данная программа несколько уступает ABBYY FineReader, она значительно превосходит большинство других конкурентов. Главной же фишкой Readiris является возможность интеграции с целым рядом облачных сервисов для хранения файлов. Недостатки у Readiris практически те же, что и у ABBYY FineReader: большой вес и необходимость платить немалые деньги за полноценную версию.
VueScan
Разработчики VueScan главное внимание сконцентрировали все-таки не на процессе распознавания текста, а на механизме сканирования документов с бумажных носителей. Причем программа хороша именно тем, что работает с очень большим перечнем сканеров. Для ее взаимодействия с устройством не требуется установка драйверов.
Более того, VueScan позволяет работать с дополнительными возможностями сканеров, которые даже родные приложения этих устройств не помогают раскрыть в полной мере. Также у программы есть инструмент распознавания сканируемого текста. Но данная функция пользуется популярностью только в связи с тем, что ВуеСкан – отличное приложение для сканирования. Собственно, функционал по оцифровке текста довольно слаб и неудобен, поэтому распознавание в VueScan используется для решения несложных задач.
CuneiForm
Приложение CuneiForm – отличное решение для распознавания текста с фото, изображений, сканера. Популярность оно приобрело благодаря применению особой технологии оцифровки, совмещающей шрифтонезависимое и шрифтовое распознавание. Это позволяет максимально точно распознавать текст, учитывая даже элементы форматирования, но при этом сохранять высокую скорость работы.
В отличии от большинства программ для распознавания текста, эта абсолютно бесплатна. Но у данного продукта имеется и целый ряд недостатков. Так, он не работает с одним из самых популярных форматов – PDF, — а также имеет плохую совместимость с некоторыми моделями сканеров. Кроме того, приложение на данный момент разработчиками официально не поддерживается.
WinScan2PDF
В отличии от CuneiForm, единственной функцией WinScan2PDF является оцифровка полученного со сканера текста в формат PDF. Главное преимущество этой программы – простота использования. Она подойдет тем людям, которые очень часто сканируют бумажные документы и распознают текст в формате PDF. Главный недостаток ВинСкан2ПДФ связан с очень ограниченным функционалом.
Собственно, больше ничего данный продукт не умеет делать, кроме указанной выше процедуры. Он не может сохранять результаты распознавания в другой формат, кроме PDF, а также не предоставляет возможности оцифровки файлов изображений, которые уже хранятся на компьютере.
RiDoc
РиДок является универсальным офисным приложением для сканирования документов и распознавания текста. Его функционал все-таки немного уступает ABBYY FineReader или Readiris, но и стоимость заметно меньше. Поэтому по соотношению «цена – качество» RiDoc выглядит даже предпочтительнее.
В то же время, существенных ограничений по функционалу программа не имеет, и одинаково хорошо выполняет как задачу сканирования, так и распознавания. Фишкой РиДок является возможность уменьшения изображений без потери качества. Единственный существенный недостаток – не совсем корректная работа по распознаванию мелкого текста.
Безусловно, среди перечисленных программ любой пользователь сможет отыскать ту, которая ему придется по душе. Выбор будет зависеть как от конкретных задач, которые приходится чаще всего решать, так и от финансового состояния.
Мы рады, что смогли помочь Вам в решении проблемы.
Источник: lumpics.ru
Распознавание документов на частном примере — обзор доступных платных и бесплатных решений
Всем привет! Типичная ситуация сложилась в компании, в которой я работаю. В бухгалтерии вечный аврал, людей не хватает, все занимаются чем-то безусловно важным, но по сути бесполезным. Такое положение дел не устраивало руководство.
Если подробнее, то проблема в том, что ресурсов бухгалтерии не хватает на текущие задачи, а выделять ставки под новых людей никто не хочет. Поэтому сверху приняли решение порезать некоторые задачи и освободить время бухгалтеров для более полезных дел. Под нож попала такая работа как сканирование и распознавание документов, копирование, внесение их в прочие рутинные радости.
Так передо мной, как аналитиком, встала задача: найти решение для распознавания документа типичного для моей компании — счет-фактуры — структурировать его в имеющиеся хранилища, а также в 1С. Решение, которое будет удобным, понятным, и не влетит компании в копеечку.
Опыт получился занятным, решил поделиться тем, что удалось собрать. Возможно я что-то упустил, поэтому велком в комментарии, если есть, что добавить.
Программы сканирования документов, программы распознавания документов — не новое решение на рынке, его можно найти как в бесплатных программах, так и встроенных в системы.
Начал я с бесплатных программ:
- glmageReader
- Paperwork
- VietOCR
- CuneiForm.

- В таких программах как VietOCR, Paperwork, glmageReader можно настроить хранение отсканированных документов в определенные папки, Paperwork умеет их даже сортировать, согласно меткам.
- В основном они хорошо справляются с текстом, а там, где текст распознан некорректно, в некоторых программах можно вручную изменить содержимое, прежде чем экспортировать файл.
Однако есть и проблемы:
- Есть разница между работой с pdf сканами и png. Не всегда удается удачно конвертировать png в pdf.
- Большинство таких программ сложно справляются с распознаванием документов табличного вида, даже самого простого формата. В результате мы получаем распознанный текст без размеченных полей.


Технология сработала достаточно хорошо, Учитывая, что программы бесплатные, описанные выше проблемы допустимы. Однако, я искал более упорядоченного решения.
Затем я исследовал распознавание в ABBYY FineReader 15 Corporate
За 7-дневный срок триала я изучил и эту платформу.
- Когда я открыл png файл, он отлично был считан и в результате удачно конвертирован в pdf без потери качества изображения и текста.
- Программа отлично знает, как отсканировать документ для редактирования текста. Причем в режиме редактирования файла формата png текст удается отредактировать без проблем, но иногда слетает разметка.
- Однако то же самое я не могу сказать про редактирование файла-скана pdf. При попытке редактирования летели слои.
- Табличный вид распознается качественно, вся структура сохраняется, меня это порадовало.
- OCR редактор хорошо распознал мой сформированный pdf счет-фактуры. Где-то пару символов требовалось поправить вручную.

Однако, была ситуация, что почти весь подобный документ распознался с меньшей точностью и данных для изменения вручную было уйма. Думаю, здесь можно было бы решить вопрос технически, но это затратило бы больше времени.

От использования этого софта были приятные впечатления. Однако, когда я обратился к ценнику системного решения ABBYY Flexicapture (а мне нужно именно системное), то выяснил, что решение, особенно кастомизированное, обходится в довольно круглую сумму, около 400 тыс. руб./мес. и выше за 10 тыс. страниц.
Я стал искать альтернативу. Как освободить руки сотрудника, получить качественное распознавание документов и не переживать за сохранность и структуру данных.
И тут я решил получше разглядеть ELMA RPA, которую я уже изучал ранее.
Вендор предлагает перекинуть значительную часть работы по экспорту данных в ERP с плеч бухгалтеров на роботов. По сути, именно это решает поставленную передо мной задачу. Чтобы познакомиться с распознаванием в этой системе, я взял у вендора триальную версию системы.
Здесь я обнаружил, что распознавание не преследует цели конвертировать полученные данные в новый документ-файл.
Здесь главная цель — распознавание реквизитов документа и их передача в другие системы/сайты/приложения. Кроме того, роботы складывают всю информацию куда надо: автоматически находят нужные папки и сохраняют в необходимых форматах.
Какие виды распознавания в системе я посмотрел:
Распознавание по шаблону
Нам предлагается на основании шаблона документа распознать подгружаемый документ. Насколько мне известно, этот вид распознавания бесплатный, внутрь зашит движок Tesseract.
- Этот вид распознавания работает именно со сканами формата jpg и png, pdf он пока не рассматривает. Но продукт еще молодой, думаю, все впереди.
- Этот вид распознавания входит в бесплатную версию Community Edition
- Удобно размечен текст по блокам, которые можно сопоставить, согласно переменным, которые мы создали в контексте робота. Таким образом вручную настроить, что именно тянем в распознавание.
- Нашу счет-фактуру он распознал 50/50, некоторые слова подменил как посчитал нужным. 🙂

Однако, вендор на данный кейс сообщил, что этот вид распознавания адаптирован под простые документы, с текстовой структурой или с легкими формами. И посоветовал для распознавания счета-фактуры использовать другой вид распознавания — intellect lab.
Процесс тот же, загружаем шаблон и по нему распознаем. Но здесь шаблон отправляется на облачный сервер.
От сервера получаем ответ (распознает такой тип документа или нет), и если распознается, то передается структура шаблона (переменные для маппинга), для сопоставления переменных, которые необходимо будет записать в RPA процессе.
В процессе воспроизведения мы отправляем уже документ, который хотели бы распознать и получаем ответ от iLab сервера о распознавании.
Что отметил по поводу этого распознавания:
- Здесь уже распознавание работает как программа сканирования документов pdf, и при этом работает и с форматами jpg и png.
- Качество документа не влияет на эффективность распознавания. Даже документы с плохим качеством распознаются корректно.
- Счет-фактура распозналась полностью и без подмен переменных.
- Робот сумел получить скан с почты, распознать его и создать его экземпляр в 1С. То есть автоматически сохранил файл там, где мы ему задали, что, естественно, крайне удобно.
- Входит в бесплатную Community Edition в виде распознавания документа в облаке. Подходит, если используем стандартные типы (СФ, УПД, АВР и др.), и, например до 100 документов в месяц или до 500 в год. (Стоит заметить, что считаем не в страницах, а в документах непосредственно.)
Соответственно, эти же данные робот записывает в 1С, создавая там новый документ:
Что удалось выяснить по ценам: Если мы, например, хотим работать масштабно именно с ilab распознаванием, то за наши 10 000 документов придется выложить:
- примерно 180 000 руб. единовременно,
- плюс, допустим, 400 000 руб. покупка робота с оркестратором
- итого: 580 000 руб.
Что понравилось в распознавании в этой платформе в целом:
- Можно настроить получение документов по событию, а также, например из электронной почты и любых других внешних источников. У меня пока была цель настроить получение с почты.
- Все считанные данные с документа можно спокойно записать в контекстные переменные и далее их передать в необходимые системы, приложения, сайты, ВМ и т д. И я не переписываю уже ничего руками.
- Скорость обработки. 15 секунд и объект распознан, а остальной порядок действий — это счет по минутам. Если заявиться с потоковым сканированием с большим количеством документов, думаю это не составит больших временных затрат.
- Много качественного функционала в свободном доступе, для небольших компаний им можно вполне обойтись.
Итого:
- Бесплатные программы справляются с задачей распознавания документов лучше, чем я предполагал, однако за счет них значительно ускорить работу с большим объемом не удастся
- ABBYY FineReader хорошо справляется с обработкой и распознаванием документов после, однако, чтобы получить системное решение, нужны большие финансовые возможности.
- ELMA RPA удивила по качеству распознавания документов, вариативностью, а также возможностям хранения и передачи после распознавания, но стоит учесть, что продукт молодой.
- rpa
- автоматизация рутины
- распознавание документов
- программа сканирование документов
- сервис распознавания документов
- abbyy распознавание документов
- распознавание реквизитов документа
- Искусственный интеллект
- Финансы в IT
Источник: habr.com
Зачем нужны программы распознавания текста OCR, самая известная из них
Мы разобрались с принципами работы систем оптического распознавания символов. Кратко ознакомились с историей развития технологий OCR. В публикации рассмотрим, зачем нужны программы для распознавания текста, назовём наиболее распространённые из них. Какие приложения для работы со сканами знаете вы? А кроме FineReader?
Цель применения приложений
При помощи сканера, камеры смартфона или фотоаппарата создаются цифровые копии бумажных документов. Воспринимать их содержимое на дисплее компьютера и ноутбука комфортно. На портативных устройствах просматривать страницу, содержимое которой не помещается на экран, неудобно. Придётся постоянно перетаскивать изображение по дисплею, масштабировать его.
Использовать скан книги, выдержки из периодического издания в качестве цитаты или исходника для работы (реферата, доклада, курсовой работы) можно после превращения картинки в текст. Для этого следует осуществить распознавание документа. Помогут в этом системы оптического распознавания информации – приложения, которые извлекают из графических файлов текстовую информацию, передают её в текстовый редактор или документ. Вследствие появляется возможность её редактирования, обработки.

Часто поверх изображения накладывается текстовый слой, как на картинке выше. Так сохраняется внешний вид страниц книги и появляется возможность копирования, редактирования её содержимого.
Сканеры с программным обеспечением для распознавания символов широко применяются в библиотеках, архивных фондах для оцифровки бумажных книг, журналов, газет, брошюр, писем, прочих рукописей и бумажных документов с возможностью их дальнейшего редактирования или извлечения текстовой информации. Корпорация Google около 20 лет занимается оцифровкой архивов и книг, исторических источников.
Сколько времени займёт набор на клавиатуре пары цитат длиной в несколько абзацев? Считанные минуты. Если для выполнения курсовой или дипломной работы нужно набрать с десяток страниц, уйдут часы. Программы распознавания текста (OCR) решат проблему за десятки секунд, причём они справляются с сохранением структуры документа.
Приложения определяют наличие таблиц, картинок, диаграмм, списков, справляются с текстом на нескольких языках, формулами. Они сохраняют тип и размер шрифта, способны очищать исходное изображение от дефектов: потёртости, желтизна бумаги, огрехи печати, перегибы страниц и прочее.
Примеры
- CuneiForm;
- SimpleOCR;
- MyScript Stylus;
- Office Lens;
- Readiris 17;
- Readiris Pro;
- Freemore OCR;
- Scanitto Pro.
Самой известной программой оптического распознавания текстов является FineReader от компании ABBYY. Из инструмента для оцифровки файлов она превратилась в мощный инструмент для работы с цифровыми документами. Также разработаны десятки веб-сервисов для решения поставленной задачи.
Источник: bingoschool.ru
100 (или почти сто) секретов сканирования, распознавания и редактирования текста с картинки, фото
Возможно ли изменение сканированного текста? Можно ли отредактировать сканированный текст, чтобы потом использовать его с другими целями? Да, дорогие друзья! Сегодня это не только возможно, но и вполне легко делается.
При наличии необходимости, желания, а также некоторых технических возможностей вам легко дастся:
- сканирование рукописного текста (например, конспекта),
- сканирование текста с фотографии или картинки,
- редактирование,
- распознавание текста после сканирования,
- преобразование текста в виде картинки в обычный текст, в котором вы можете изменить сканированный текст (например, в документе pdf) документа и др.
В общем, сделать с текстом на картинке сегодня можно все то же самое, что и с обычным текстом в вордовском документе. А делать это жизненно важно и полезно тем, кто постоянно имеет дела с многочисленной документацией и тратит много времени – то есть и для студентов в том числе. Давайте разбираться, как это делается.
Чем отличается сканирование от распознавания?
Как оказалось, сканирование и распознавание текста – это разные вещи. Сканирование листов документа – это его перевод текста в электронный вид. Делается это через сканер или при помощи обычного фотографирования на смартфон или цифровую камеру.
Распознавание – это преобразование сканированного документа (текста) в электронный вид.
Кстати! Для наших читателей сейчас действует скидка 10% на любой вид работы
Что нам понадобится для сканирования и распознавания текста по фото ?
Для сканирования и распознавания текста нам не обойтись без кое-каких вещей:
- Сканер. Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
- Программы для распознавания текста или онлайн-сервисы. Мы уже писали статью по сервисам, которые помогают распознать текст после сканирования документа через сканер. Но сейчас хотели бы посоветовать вам программу ABBYY FineReader. Несмотря на то, что она платная, ее функционал поистине впечатляет. И если вы будете работать с огромными объемами документов, она станет вашим незаменимым помощником. Впрочем, есть и бесплатный ее аналог Cunei Form, которая отлично справляется со сканированием и распознаванием текста онлайн. Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом.
- Документы для сканирования. Студентам часто приходиться сталкиваться со сканированием документа в виде журналов, статей, книг, конспектов, распечаток, откуда потом зачастую нужно скопировать текст. И просто так, в виде совета – перед началом сканирования постарайтесь поискать эти документы в сети. Если до вас этими материалами уже пользовались, существует огромная вероятность, что добрый человек уже проделал всю работу за вас. Атк что вам останется только скопировать текст готового сканированного документа и заняться редактированием текста после сканирования.
Параметры сканирования текста
Итак, сканер купили, документы подготовили, программы установили. Что дальше? Дальше нам нужно будет сделать нужные настройки, которые тоже порой помогают существенно облегчить задачу, например, распознать сканированный текст в определенном формате, редактировать текст после сканирования в определенном режиме и так далее.
В общем, от настроек будет зависеть качество и скорость вашей работы. Итак, разбираемся вместе.
DPI-качество
Это разрешение изображения, которое будет важно при редактировании текста в сканированном документе. Ставьте в настройках качество не меньше 300 DPI, а если возможно — то больше. Чем выше эта величина, тем более четким получится изображение после сканирования.
А от четкости будет зависеть скорость обработки. То есть исправить или изменить сканированный текст, текст сканированного листа будет быстрее, а еще программа сделает меньше ошибок (да-да, программы тоже ошибаются, но обо всем по порядку).
Цветность
Благодаря этому параметру можно влиять на скорость сканирования текста. Как правило, в сканерах есть 3 режима: черно-белый (подходит для листов с обычным печатным текстом), серый (подходит для работы с документами с таблицами и простыми картинками), цветной (для журналов, книг и остальных документов, где цвет играет значение). Чем меньше цвета, тем выше скорость обработки документа.
Фото
Как мы уже говорили, для сканирования можно использовать не только сканер, но и фотографирование. Но здесь будьте осторожны – любое смазывание, нечеткость и прочие искажения изображения могут повлиять на дальнейшее распознавание и редактирование текста в сканированном документе.
Распознавание
Итак, отсканировали и получили странички в электронном виде. Затем открываем программу для распознавания (например, FineReader) и начинаем распознавать текст. Некоторые программы (в том числе и наша) делают этот процесс с ошибками. Тогда область с ошибкой нужно будет выделять вручную.
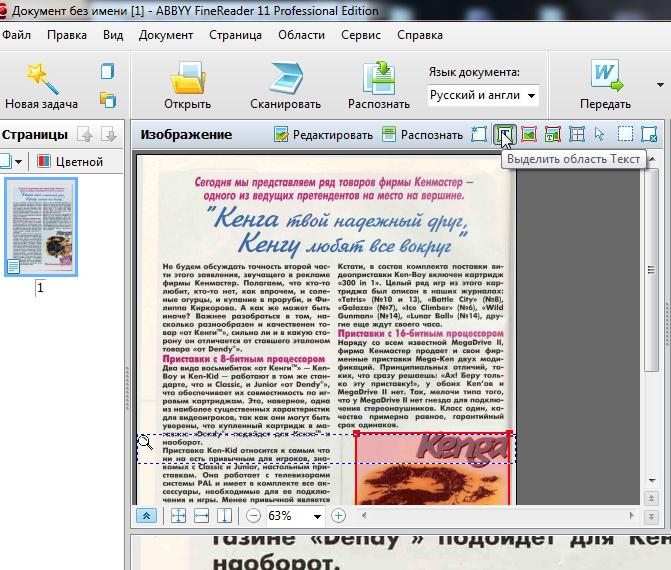
Работа с текстом
В области Текст можно будет выделить текст. Любые таблицы и изображения можно будет удалить. А вот для работы с необычными и редкими символами придется поработать ручками. Вот как это выглядит в программе:
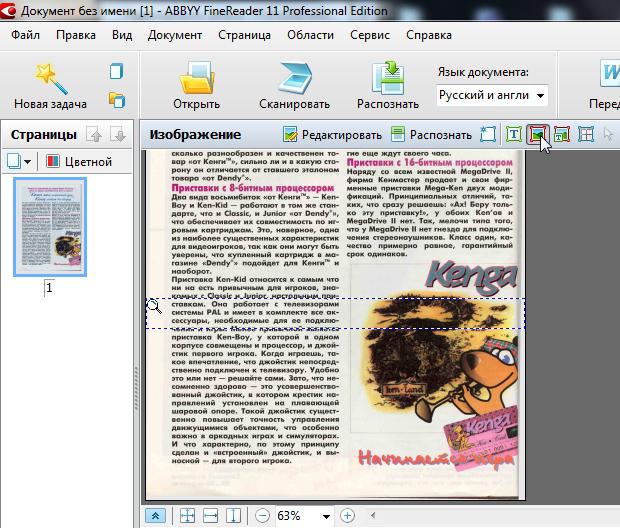
Картинки
Эта область в программе используется для работы с изображениями и с теми областями текста, которые плохо поддались распознаванию.
Таблицы
Кнопка выделения таблиц помогает работать с таблицами. Однако эта функция не очень хорошо развита. Иногда проще использовать редактор Картинка для работы с таблицами. Это сэкономит кучу времени и нервов, а доработать все потом можно в обычном ворде.

Лишние элементы
Если на странице остались элементы, которые вам совершенно не нужны или бесполезны, выделите ненужную область и удалите ее с помощью ластика. Достаточно перейти в режим редактирования и провести работу. Причем чем больше ненужных элементов вы уберете, тем быстрее будет происходить процесс распознавания текста.
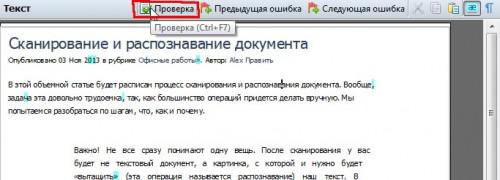
Проверка ошибок и сохранение результатов работы
Как мы уже говорили, ошибки могут возникать тогда, когда вы используете некачественные, смазанные, нечеткие изображения или документы с редкими символами. Поэтому всегда проверяйте документ после процесса распознавания.
Нашли? Замечательно – просто введите нужный символ. Кстати, в программе есть режим проверки, который поможет быстро и без вашего участия проверить документ на наличие ошибок программы. И сразу же после окончания проверки можете прямо из программы импортировать документ (сохранить его в формате) в ворд или любую другую программу.
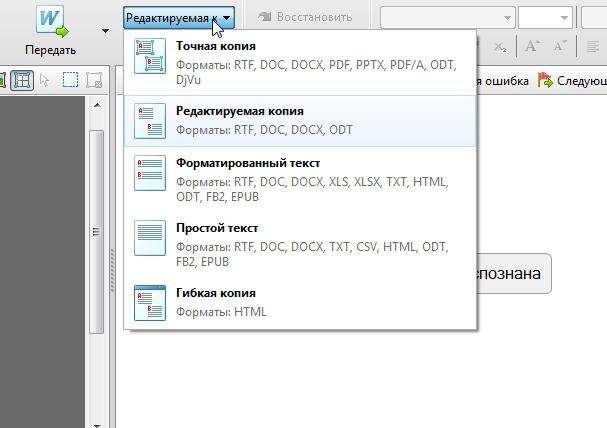
Тип копии
При сохранении документа (в режиме редактирования) вам предложат сохранить его в трех видах копии. Точная копия – это полная копия сканированного документа со всем произведенным форматированием. Если вы потом планируете редактировать текст после сканирования в ворде, то лучше всего выбрать именно этот вариант.
Редактируемая копия помогает сохранить уже отредактированный текст. Хорошо подходит, если вам предстоит обильное последующее редактирование. Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Вот, собственно и все. Сложно, долго и нудно, но гораздо быстрее сканировать и распознать текст (даже рукописный) программой, чем переписывать 100500 документов вручную. Ну а если вам и этим некогда заниматься – обращайтесь за помощью в студенческий сервис. Тут вам быстро, дешево и качественно выполнят все, что нужно.
Мы поможем сдать на отлично и без пересдач
- Контрольная работа от 1 дня / от 120 р. Узнать стоимость
- Дипломная работа от 7 дней / от 9540 р. Узнать стоимость
- Курсовая работа 5 дней / от 2160 р. Узнать стоимость
- Реферат от 1 дня / от 840 р. Узнать стоимость
Наталья – контент-маркетолог и блогер, но все это не мешает ей оставаться адекватным человеком. Верит во все цвета радуги и не верит в теорию всемирного заговора. Увлекается «нейрохиромантией» и тайно мечтает воссоздать дома Александрийскую библиотеку.
Источник: zaochnik.ru