
Компьютерная лексикография — прикладная научная дисциплина в языкознании, которая изучает методы использования компьютерной техники для составления словарей. Это временная дисциплина периода перехода от ручной и рукописной лексикографической практики к новым безбумажным информационным технологиям.
Компьютерная лексикография представлена совокупностью методов и программных средств обработки текстовой информации для создания словарей. В рамках компьютерной лексикографии разрабатываются компьютерные технологии составления и эксплуатации словарей. Специальные программы — базы данных, компьютерные картотеки, программы обработки текста — позволяют в автоматическом режиме формировать словарные статьи, хранить словарную информацию и обрабатывать её.
Множество различных компьютерных лексикографических программ разделяются на две большие группы: программы поддержки лексикографических работ и электронные словари различных типов, включающие лексикографические базы данных.
История компьютерной лексикографии
Термин «Компьютерная лексикография» был придуман для обозначения области изучения машиночитаемых (электронных) словарей и появился в середине 1960-х годов. Этой дисциплине уделяли мало внимания вплоть до начала 1990-х годов. Термин «машиночитаемый словарь» означает, что данные из словаря (хранящиеся в электронном виде) могут быть обработаны и исследованы с помощью современной вычислительной техники.
Топ 35 вопросов на собеседовании IT — спецу | Что тебя ждет и как отвечать, чтобы получить оффер?
Новаторские работы Эвенса и Амслера (1980) послужили толчком для расширения исследований электронных словарей, например, была проведена практическая работа с использованием Седьмого Энциклопедического словаря Вебстера. Стимулом для этих исследований послужило также широкое использование Longman Dictionary of Contemporary English в 1980-х, этот словарь по-прежнему является одним из лучших электронных словарей.
Первоначально электронные словари имели такую же форму записи, как обычные словари, и исследователям приходилось тратить много времени для интерпретации такой формы записи (например, чтобы определить, к какой части речи относится определенное слово). С развитием технологий издатели решили отделить базу данных электронного словаря от того, как он выглядит при печати. Сегодня существуют более удобные формы записи, например расширяемый язык разметки XML. Используя XML, исследователи получают быстрый доступ к информации, хранящейся в электронном словаре.
Основные понятия компьютерной лексикографии
- Автоматический словарь — это словарь в специальном машинном формате, предназначенный для использования на ЭВМ пользователем или компьютерной программой обработки текста. Иными словами, различают автоматические словари пользователя-человека и автоматические словари для программ обработки текста. Автоматические словари, предназначенные для человека, по интерфейсу и структуре словарной статьи существенно отличаются от автоматических словарей, включённых в системы машинного перевода, системы автоматического реферирования, информационного поиска и т. д.
- Гипертекст — это множество текстов со связывающими их отношениями (системой переходов).
- Средства навигации по словарю — ссылки, внедрённые в различные элементы электронной среды — часть гипертекстового устройства электронного словаря, представляющего собой соединение смысловой структуры, структуры внутренних связей некоего содержания и технической среды и технических средств, дающих человеку возможность осваивать структуру смысловых связей, а также осуществлять переходы между взаимосвязанными элементами.
Электронные словари
Электронный словарь — это любой упорядоченный, относительно конечный массив лингвистической информации, представленный в виде списка, таблицы или перечня, удобного для размещения в памяти ЭВМ и снабженного программами автоматической обработки и пополнения.
Как читать чужие переписки?
Термин электронный словарь может быть использован для обозначения любого справочного материала, хранящегося в электронном виде и предоставляющего информацию о написании, значении или использовании слов. Таким образом, система проверки правописания в текстовом редакторе, устройство, которое сканирует и переводит напечатанные слова и электронная версия бумажного словаря — всё это электронные словари, имеющие сходные системы хранения и поиска.
В работе (Неси, 2000) выделяют несколько категорий электронных словарей для изучения языков: интернет-словари, глоссарии для учебных онлайн-курсов, словари на компакт-дисках и карманные электронные словари. Неси перечисляет несколько наиболее известных словарей на CD:
- Collins Cobuild Student’s Dictionary
- Cambridge International Dictionaries
- Оксфордский словарь английского языка
Онлайн-словари
Эпоха Интернета сделала онлайн-словари доступными непосредственно с рабочего стола компьютера, а затем и со смартфона. Скинер в 2013 году отметил: «В список слов, которые чаще всего ищут в онлайн-версии словаря Merriam-Webster, сейчас входят слова „holistic“, „pragmatic“, „caveat“, „esoteric“ и „bourgeois“. Исторически целью лексикографии было разъяснение неизвестных слов читателям. И современные словари успешно с этим справляются.»
Существует большое количество веб-сайтов, работающих в качестве онлайн-словарей, обычно специализирующихся в каком-либо направлении. Некоторые из них содержат только те данные (часто включая неологизмы), которые были добавлены самими пользователями. Вот несколько наиболее известных примеров:
- Dictionary.com
- Double-Tongued Dictionary (данные добавлены пользователями)
- Free On-line Dictionary of Computing
- LEO (website)
- Logos Dictionary
- Pseudodictionary (только юмористические неологизмы, добавленные пользователями)
- Urban Dictionary (словарь англоязычного сленга)
- WWWJDIC (японский онлайн-словарь)
- Визуальный словарь (для каждого слова строится его понятийное окружение).
- Викисловарь
- Русский ассоциативный тезаурус, полученный на основе психолингвистических экспериментов. Интернет-сервис для работы с базой данных ассоциативного эксперимента на русском языке, проведенного в 1988—1997 гг. Ключевой особенностью веб-версии русского ассоциативного тезауруса является возможность проведения компаративного анализа ассоциаций по полу, возрасту и профессии. Тезаурус содержит свыше 1 млн ассоциаций, более 6 тыс. уникальных стимулов и 100 тыс. реакций от более чем 11 тыс. респондентов.
Взаимосвязь с задачами автоматической обработки текста
От традиционных методов обработки естественного языка компьютерная лингвистика отличается тем, что в первом случае внимание сосредоточено на моделировании всего того, что изучает лингвистика в целом, тогда как во втором основное внимание обращается на расчленение процесса понимания языка и на теоретическую лингвистическую корректность и адекватность предложенных моделей.
Компьютерная лингвистика тесно связана с центральной проблемой искусственного интеллекта — электронным представлением знаний. Основная задача компьютерной лингвистики — построение логико-лингвистических моделей и соответствующих им алгоритмов и программ.
Разрешение лексической многозначности
Решение задачи разрешение лексической многозначности (WSD) и развитие лексикографии, приносят пользу друг другу: WSD обеспечивает эмпирическую группировку смыслов и статистически значимые показатели контекста для новых или существующих значений. Кроме того, WSD позволяет создать семантическую сеть по данным машиночитаемых словарей. С другой стороны, лексикография предоставляет больший и лучший набор смыслов и собрание аннотаций к значениям слов, что может принести пользу WSD.
Извлечение информации
Извлечение информации (англ. information extraction) — это задача автоматического извлечения структурированных данных (автоматическая идентификация выбранных типов объектов, отношений, или событий) из неструктурированных или слабо структурированных машиночитаемых документов. Проблема IE была обозначена на Message Understanding Conferences, где основной задачей было извлечь из текста определённые данные и поместить в заданные слоты шаблонов. Заполнение шаблонов не требует полного разбора текста, этого можно достигнуть путём сопоставления с неким образцом(например, с помощью регулярных выражений). Слоты шаблонов заполняются серией слов, обычно классифицированных. Например, имена людей, названия организаций, химические элементы и т. д.
Для извлечения имён людей, например, могут применяться шаблоны, использующие электронные словари, содержащие списки имён и сокращений, предшествующих именам людей. Часто списки могут быть очень большими, например такие, как список названий компаний или записи географического справочника. Названия можно определить достаточно надежно, не выходя за рамки простых списков, так как в тексте они появляются в качестве просто существительных. Распознать и охарактеризовать событие в тексте тоже можно с помощью такой модели, но необходимо использование дополнительный лексической информации.
События обычно описываются глаголами, и это описание может быть выражено в виде различных синтаксических шаблонов. Несмотря на то, что эти модели могут быть выражены с некоторой степенью достоверности (например, компания наняла человека или человек был нанят компанией) в качестве основы для сравнения строк, этот подход не позволяет достичь желаемого уровня общности. Распознание события влечет за собой частичный разбор предложения.
Большей общности можно достигнуть путём расширения шаблонов требуемых семантических классов. Электронный словарь WordNet широко используется в IE, в частности, с использованием гиперонимических отношений как основы для определения семантических классов. Дальнейшее развитие в IE, вероятно, будет сопровождаться использованием более сложных вычислительных словарей.
Ответы на вопросы
Несмотря на то, что большая часть исследований в теме «Ответы на вопросы» была проведена ещё в 1960-е годы, добавление тематики «Ответы на вопросы» на конференции TREC в 1998 г. позволило значительно продвинуться в этом направлении. С самого начала исследователи рассматривали эту задачу как включающую в себя семантическую обработку и предоставляющую удобный инструмент для определения значения слов. Это в целом оказалось так, но возникло много нюансов в обработке различных типов вопросов. Тезаурус WordNet стал использоваться практически во всех системах «Ответы на вопросы».
Вопросы анализируются для определения того, какого «типа» требуется ответ, например, вопрос: «Какая длина …?» требует, чтобы ответ содержал номер и единицу измерения; кандидат в ответ использует данные WordNet, чтобы определить, существует ли термин для единицы измерения. Изучение способов использования WordNet в задаче «Ответы на вопросы» продемонстрировало полезность иерархических и других видов отношений в машиночитаемых словарях.
За много лет ведения темы «Ответы на вопросы» на конференции TREC методы решения данной задачи постоянно совершенствовались, что позволяло задавать всё более сложные вопросы. Было придумано множество вопросов, для ответа на которые требуется как минимум разбор коротких текстов, содержащих ответ. Множество вопросов для получения ответов требуют более абстрактных рассуждений. Улучшения в решении задачи «Ответы на вопросы» по-прежнему в большой степени будут зависеть от достижений в компьютерной лексикографии.
Реферирование текстов
Область исследования автоматического реферирования текстов также выиграла от ряда оценочных мероприятий, известных как Document Understanding Conferences (в 2004 г.). При «добывающем реферировании» (англ. extractive summarization) (из текста извлекаются предложения, разительно отличающиеся от прочих) компьютерные словари используются существенно меньше, чем при построении аннотаций (англ. abstractive summarization). Во втором случае нужен более глубокий анализ текста, что ставит серьёзные требования перед машиночитаемым словарём.
Распознавание и синтез речи
Использование электронных словарей в технологиях распознавания речи ограничено. Машиночитаемые словари обычно содержат произношение, но эта информация обеспечивает только первый шаг в решении проблемы распознавания и синтеза речи. Электронный словарь речевой лексики включает в себя орфографическую форму слов или каноническое произношение. Словарь полных форм также содержит в словарной статье все формы слов; форм могут генерироваться на основе правил, но обычно все формы слов просто хранятся в словаре.
Знания канонического произношения недостаточно для обработки разговорного языка. Необходимо учитывать варианты произношения, являющиеся результатом областных различий, влияние родного языка для иностранцев, зависимость произношения и ударения от порядка слов.
Некоторые из этих трудностей можно решить алгоритмически, но решение большинства из них возможно только благодаря более обширному набору информации. В результате речевые базы данных содержат эмпирические данные о фактическом произношении, фрагменты разговорной речи и её нотацию в письменной форме. Эти базы данных включают информацию о тех, чьи голоса записаны, типе речи, качестве записи и прочие данные. Самое главное, что эти базы данных содержат речевые данные в виде сигнала, записанного в аналоговой или цифровой форме. В связи с большими объёмами данных, участвующих в реализации основных систем распознавания и синтеза речи, эти системы ещё не содержат полный спектр семантических и синтаксических возможностей обработки озвученных данных.
Преимущества
Электронные словари превосходят бумажные аналоги по своей функциональности, имея при этом ряд преимуществ:
- Многофункциональность — разнообразие дополнительных функций, которые упрощают обращение к словарю. Например, можно указать части речи, происхождение, а так же словообразование, табуированность лексики.
- Использование средств мультимедиа — озвучивание заголовочных слов, введение иллюстративного материала с фотографиями, анимацией, видеофрагментами, а так же использование разнообразных графических средств.
- Актуальность и динамичность — возможность постоянного обновления информации, а так же изъятия устаревших данных. Это одно из важных преимуществ перед «бумажными» словарями, так как они неизбежно становятся устаревшими на момент их выпуска.
- Большой объем словарной базы. У большинства электронных словарей терминологическая база превышает базу бумажных словарей и предоставляет более удобный доступ к информации за счет использования гиперссылок.
- Вариативность в использовании — возможность использования словарей в локальной и глобальной сетях. А именно, использование оффлайновой и онлайновой версии.
- Универсальность — как правило, программы позволяют работать сразу с несколькими языками и направлениями перевода. Возможно использование любого из включённых в словарь языков в качестве входного.
- Удобный поиск — возможность использования эффективной системы поиска (полнотекстовый поиск, одновременный поиск в нескольких словарях, высокая скорость поиска). Так же пропадает необходимость помнить слово в точности, программа сама предложит варианты по первым буквам. В электронных словарях для доступа к содержимому используются разнообразные лингвистические технологии, такие как: морфологический и синтаксический анализ, полнотекстовый поиск, распознавание и синтез речи.
Задачи компьютерной лексикографии
Перед учёными и программистами при преобразовании бумажных словарей в машиночитаемые словари (w:Machine-readable dictionary) встает множество проблем:
Источник: ctcmetar.ru
6.2.1. Экспертные системы
Экспертная система (ЭС) – компьютерная программа, способная заменить специалиста-эксперта в решении проблемной ситуации. ЭС начали разрабатываться исследователями ИИ в 1970-х годах, а в 1980-х получили коммерческое подкрепление. Обобщенная структура экспертной системы может быть выражена следующей схемой (рис. 2).
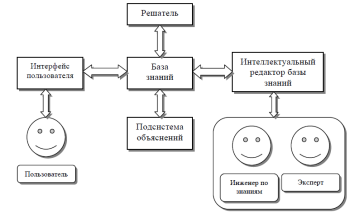
Рис. 2. Обобщенная структура экспертной системы
Главным элементом экспертной системы является база знаний (БЗ),
состоящая из правил анализа информации от пользователя по конкретной проблеме.
Решатель, называемый также блоком логического вывода, представляет собой программу, моделирующую ход рассуждений эксперта на основании знаний, содержащихся в БЗ.
Подсистема объяснений – программа, позволяющая пользователю получать ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла то или иное решение?» Ответ на вопрос «как» – это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ, т.е. всех шагов цепи умозаключений. Ответ на вопрос «почему» – ссылка на умозаключение, непосредственно предшествовавшее полученному решению, т.е. отход на один шаг назад.
ЭС создается при помощи инженеров по знаниям (аналитиков), которые разрабатывают ядро ЭС и, зная организацию базы знаний, заполняют ее при помощи эксперта по специальности. Интеллектуальный редактор БЗ – программа, предоставляющая инженеру по знаниям возможность создавать БЗ в диалоговом режиме. Интерфейс пользователя – комплекс программных средств, реализующих диалог пользователя с ЭС как для ввода информации, так и для получения результатов работы ЭС.
Задачи, решаемые при помощи экспертных систем, чаще всего относятся к одной из следующих областей:
• Интерпретация данных – это одна из традиционных задач для экспертных систем. Под интерпретацией понимается определение смысла данных, результаты которого должны быть согласованными и корректными. Примеры существующих ЭС: SIAP (обнаружение и идентификация различных типов океанских судов), АВТАНТЕСТ, МИКРОЛЮШЕР (определение основных свойств личности по результатам психодиагностического тестирования).
• Диагностика – это обнаружение неисправности в некоторой системе. Трактовка неисправности как отклонения от нормы позволяет с единых теоретических позиций рассматривать и неисправность оборудования в технических системах, и заболевания живых организмов, и всевозможные природные аномалии. Примеры существующих ЭС: ANGY (диагностика и терапия сужения коронарных сосудов), CRIB (диагностика ошибок в аппаратуре и математическом обеспечении компьютера).
• Мониторинг – это непрерывная интерпретация данных в реальном масштабе времени и сигнализация о выходе тех или иных параметров за допустимые пределы. Главные проблемы – «пропуск тревожной ситуации» и инверсная задача «ложного» срабатывания. Сложность этих проблем состоит в размытости симптомов тревожных ситуаций и необходимости учета временного контекста. Примеры существующих ЭС: СПРИНТ (контроль за работой электростанций), REACTOR (помощь диспетчерам атомного реактора), FALCON (контроль аварийных датчиков на химическом заводе).
• Проектирование состоит в подготовке спецификаций на создание «объектов» с заранее определенными свойствами. Под спецификацией понимается весь набор необходимых документов – чертеж, пояснительная записка и т.д. Примеры существующих ЭС: XCON (проектирование конфигураций ЭВМ), CADHELP (проектирование БИС), SYN (синтез электрических цепей).
• Прогнозирование – это логический вывод вероятных следствий из заданных ситуаций. В прогнозирующей системе обычно используется параметрическая динамическая модель, в которой значения параметров «подгоняются» под заданную ситуацию. Выводимые из этой модели следствия составляют основу для прогнозов с вероятностными оценками. Примеры существующих ЭС: WILLARD (предсказание погоды), PLANT (оценки будущего урожая), ECON (экономические прогнозы).
• Планирование – нахождение планов действий, относящихся к объектам, способным выполнять некоторые функции. В таких ЭС используются модели поведения реальных объектов с тем, чтобы логически вывести последствия планируемой деятельности. Примеры существующих ЭС: STRIPS (планирование поведения робота), ISIS (планированиепромышленных заказов), MOLGFN (планирование эксперимента).
• Обучение – процесс диагностирования ошибки при изучении какой-либо дисциплины с помощью компьютера и подсказывают правильные решения. Они аккумулируют знания о гипотетическом «ученике» и его характерных ошибках, а затем в ходе работы способны диагностировать слабости в знаниях обучаемых и находить соответствующие средства их ликвидации. Кроме того, они планируют процесс общения с учеником в зависимости от успехов ученика с целью передачи знаний. Примеры существующих ЭС: PROUST (обучение языку программирования Pascal).
Источник: studfile.net
Создание интеллектуальной вопросно-ответной системы
В последнее время все больше крупных компаний выделяют свои ресурсы на создание искусственных диалоговых помощников (Алиса от Яндекса, Ассистенты Салют от Сбер и др). С такими системами можно, хоть и не в полной мере, поддерживать диалог. Ассистенты умеют выполнять простые команды: ставить таймер или будильник, вызывать такси, управлять умным домом.
Но в то же время разработка таких систем стоит больших денег, а также ресурсов на поддержку. В большинстве своем многим предприятиям не требуется, чтобы система умела поддерживать диалог, а просто отвечала на конкретный вопрос. Аналог современных вопросно-ответных систем появился в 60-х годах XX века и назывался экспертными системами.
Экспертная система включала в себя оболочку на естественном языке и позволяла задавать вопросы на узкую тематику. С развитием методов обработки естественного языка вопросно-ответные системы стало возможным выделить в отдельный класс и не акцентировать их под решение специализированной задачи. В статье описан процесс создания вопросно-ответной системы, в частности, с какими трудностями пришлось столкнуться, какие технологии использовались, и приведен реальный пример практического использования на базе поступающих заявок в Приемную комиссию МТУСИ.
Проблемы чат-ботов
В начале стоит разобраться с вопросом, а почему вопросно-ответная система на данный момент не может быть частью чат-бота. Современные диалоговые системы, как российские, так и иностранные, предназначены в первую очередь для проведения человека по какому-то заранее заготовленному сценарию, к примеру при проведении опроса. В таких системах чаще всего анализируются короткие фразы пользователей, не превышающие 10–12 слов. В основе таких систем чаще всего лежит использование регулярных выражений и простейшей статистической обработки, так как ответ необходимо выдавать почти моментально, особенно в голосовых каналах. Такой подход почти невозможно применить при обработке длинных сообщений, например, для автоматизации первой и второй линии техподдержки.
Вторым существенным недостатком чат-ботов является именно неправильное позиционирование их как системы. Люди в большинстве своем ожидают увидеть короткие ответы, которые решат их проблему, к примеру, инфо-бот для поликлиники, который по запросу клиента сообщает время работы того или иного врача, но при этом любую систему способную “отвечать на вопросы“ называют чат ботом.

Архитектура решения
Для того чтобы определиться с архитектурой решения, сначала нужно решить как система будет использоваться: преимущественно только в облаке или же на стороне клиента. От этого зависит, можно ли делать архитектуру основанной на микросервисах, или стоит прибегнуть к монолитной архитектуре. Конкретно в случае построения вопросно-ответной системы с большим потоком заявок монолитная архитектура отпадает, так как намного проще использовать уже готовые сервисы по контейнеризации системы и ее масштабированию.
Вопросно-ответная система должна:
- принимать заявки из различных каналов (CRMсистемы, Социальные сети, Телефония и др.).
- производить классификацию текста на заданные тематики, соблюдая SLA < 1 секунды на ответ.
- записывать логи своей работы.
- иметь интуитивно понятный интерфейс.
Разберем подробнее каждый из пунктов.
Вопросно-ответная система должна уметь принимать заявки из различных каналов связи пользователей.
На этом этапе есть несколько проблем. Первая из них состоит в том, что люди в разных каналах общаются по-разному. Это можно наблюдать на примере любого текстового канала и голосового. В голосовом канале человек хуже формулирует свои мысли, и поэтому длина вопроса становится больше.
Голосовой канал, прежде всего, должен предусматривать диалог между двумя пользователями, а не четко сформулированный вопрос и заранее заготовленный ответ. Это же касается и сравнения, к примеру, почтовых обращений (через электронную почту) и обращений в социальной сети, где сообщения пользователя подразумевает диалог. Все перечисленные моменты стоит учитывать при проектировании вопросно-ответных систем и в дальнейшем правильном их позиционировании на рынке.
Вторая проблема техническая. При постановке требования к системе о возможности ответа и в голосовом канале появляется проблема синтеза и распознавания речи. Решить задачу можно с использованием сторонних сервисов по синтезу и распознаванию, такими как Yandex SpeechKit, Speech-To-Text от компании Google и другими похожими сервисами. Однако при этом возникает дополнительная финансовая нагрузка.
Сюда также стоит отнести проблематику формирования выборки для классификации. При использовании голосового канала в ней обязательно должны присутствовать примеры вопросов, взятые непосредственно из телефонии.
Классификатор
Классификатор является основным компонентом вопросно-ответной системы. Так как этот компонент является самым ресурсозатратным, то необходимо ввести ограничение на ответ классификатора в 1 секунду. Такое ограничение вносит трудности при разработке классификатора и влечет дополнительные финансовые затраты, так как современные алгоритмы классификации текста преимущественно работают на GPU, а при таком ограничении их использование становится необходимостью. В блок с классификацией также стоит добавить и все дополнительные программы для обработки текста и исправления ошибок (пользователя или ASR). Более подробно о классификаторе мы поговорим ниже.
Вопросно-ответная система должна записывать логи
Логирование можно сделать с помощью стандартных реляционных баз данных, но, к сожалению, быстрые исправления в них потом могут стать довольно проблемной частью. Поэтому лучше на первом этапе работы, когда до конца не ясны все взаимосвязи между таблицами, использовать NoSql данных, к примеру MongoDB. MongoDB позволяет хранить неструктурированную информацию.
Реализация

Система в общем виде состоит из 4 компонентов, а именно:
- BotServer – микросервис для обработки текстовых сообщений и их классификации.
- ApiGateway – микросервис для маршрутизации всех запросов в системе между микросервисами.
- База данных MongoDB, которая содержит всю необходимую информацию для работы системы, а также логи ее работы.
- Сайт для возможности удобного использования системы.
Разберем подробнее, из чего состоит каждый из микросервисов, за исключением MongoDB, так как данная СУБД является стандартными сервисом, и кроме коллекций в ней ничего нет.
BotServer
Микросервис для классификации, написанный на языке программирования Python. Позволяет проводить классификацию текста с возможностью изменить способ векторизации. Базовый функционал микросервиса может векторизовать текст несколькими способами: Word2Vec, FastText, STS, ElMO и BERT.Такой объёмный выбор алгоритмов позволяет разработчику тонко настроить (в удобном интерфейсе) работу системы.
Каждый из алгоритмов может быть удобно применять в зависимости от ситуации.К примеру, у пользователя системы пока нет большого количества данных для обучения классификатора, поэтому он может воспользоваться базовой моделью, основанной на OneHot encoding. Также BotServer содержит в себе дополнительные скрипты для обработки текста, поиск и исправление опечаток, интеллектуальный поиск дублирования текста в разных классах, лемматизацию текста и выделение именованных сущностей. Классификация текста осуществляется с помощью метода опорных векторов с линейный ядром. Стоит отметить, что тонкая настройка алгоритма классификации тут не нужна, так как выборка в системе не статична и постоянно изменяется. Микросервис работает в режиме многопоточности и способен обрабатывать до 50 запросов в секунду.
ApiGateway
Микросервис для маршрутизации запросов внутри системы, создания коллекций в базе данных и тд. Написан на языке программирования Go. Выбор языка Go при разработке микросервиса обусловлен тем, что необходим был очень быстрый язык программирования, чем не может похвастаться Python, хотя разработка на нем происходит в разы быстрее.ApiGateway является единственным незаменимым микросервисом системы, так как является связующим звеном между остальными элементами. ApiGateway способен маршрутизировать более 1000 запросов в секунду.
Frontend
Главное требование в Fronted части – это интуитивно понятный интерфейс пользователя. Написан на языке программирования Javascript с использованием фреймворка Vue. Интерфейс позволяет проводить обучение классификатора, заносить новые статьи, вопросы и ответы к ним и многое другое. Ниже на картинках представлен интерфейс системы.



Результаты работы

Вопросно-ответная система участвовала в работе приемной комиссии 2021 года в МТУСИ (Московской технический университет связи и информатики). Вопросы в адрес приемной комиссии поступают из 3 различных каналов: голосовой канал, социальные сети (преимущественно ВКонтакте) и CRM-система Jivosite, виджет которой размещен на сайте приемной комиссии.
Сотрудники приемной комиссии обучили вопросно-ответную систему ответам на часто задаваемые вопросы, число которых к началу приемной компании составило 49 штук, автоматизировав таким образом два из трех каналов поступления заявок. Система в пиковой нагрузке (последние дни подачи согласий на зачисление) обрабатывала по 5000 заявок в день.
За все время приемной кампании было обработано более 45000 тысяч обращений. Процент правильных ответов системы составил 33,7%, что для первого этапа системы можно оценить как «хорошо». В дальнейшем сотрудники приемной комиссии будут расширять базу ответов, и этот результат будет улучшен. Примеры ответов системы.


Вопросно-ответная система может быть довольно быстро внедрена в похожие заведения. В июле 2021 года в экспериментальном порядке система была развернута в университете МАИ за 2 дня. При этом сотрудникам университета понадобилось только изменить ответы на статьи.
- вопросно-ответные системы
- чат бот
- обработка естественного языка
- разработка
- Блог компании Unistar Digital | Юнистар Диджитал
- Семантика
- Машинное обучение
- Natural Language Processing
Источник: habr.com