
7. Память переводов и вспомогательные программы для перевода
Блог
Что такое Translation Memory (TM), или память переводов?
- Создано: 13 Май 2021
В чем ее преимущества? А также почему так выгодно использовать TM?
Память переводов (англ. Translation memory, TM, иногда также называемая «накопитель переводов») – это база данных, содержащая набор ранее переведенных сегментов текста.
- Что такое память переводов?
- Как формируется память переводов?
- Как работает память переводов?
- Пример расчета стоимости перевода в компании Benevox с памятью перевода и без.
- Почему Benevox выбирает память переводов?

Что такое память переводов?
Память переводов (англ. Translation memory, TM, иногда также называемая «накопитель переводов») – это база данных, содержащая набор ранее переведенных сегментов текста.
Studio 2017: cоздание памяти переводов на основе ранее переведенных документов
Одна запись в базе данных памяти переводов (TM) соответствует сегменту, или «единице перевода» (англ. Translation unit), за которую обычно принимается одно предложение (реже – часть сложносочиненного предложения, абзац, значение в ячейке таблицы или обособленная подпись к рисунку).

Каждый переведенный сегмент попадет в память переводов заказчика. Как только данный сегмент обнаруживается вновь, его перевод подставляется из накопленной памяти переводов автоматически. Переводчику или редактору останется только подтвердить корректность подстановки. Такая подстановка возможна как из переводов, выполненных ранее, так и из той части переводимого документа, работа с которой уже завершена. Это существенно сокращает время и, как итог, стоимость и срок выполнения всего перевода.
Как формируется память переводов (TM)?
Память переводов накапливается с помощью специального программного обеспечения. Это происходит как в процессе перевода, так и путем формирования вручную из пары документов на исходном языке и языке перевода.
В процессе перевода накопление памяти переводов (ТМ) происходит автоматически, каждый переведенный сегмент сохраняется в ТМ, как только переводчик перешел к переводу следующего сегмента. После завершения работы переводчика выполняется редактура, корректура и финальная вычитка, все изменения, внесенные в текст на этих этапах, также попадают в ТМ, либо автоматически (если работа ведется посегментно), либо переносятся вручную в тех случаях, когда работа ведется уже с полной или печатной версией документа.
Чтобы сформировать ТМ из перевода, выполненного ранее, потребуется исходный документ и его перевод на требуемый язык. Наш специалист сегментирует текст и объединит каждый исходный сегмент с его переводом, получив таким образом ТМ. Данная услуга называется «элаймент». Сформированная таким образом память переводов может серьезно сократить расходы на новый перевод, а также позволит сохранить единство терминологии и стиля изложения вашей документации.
Память переводов (Translation memory). Общие сведения
Для накопления и последующей работы с памятью переводов наша компания использует программы Trados и Memsorce.
Как работает память переводов?
Получив заказ на перевод, мы выполняем анализ текста, показывающий % совпадений как внутри текста, так и по отношению к накопленной по данному заказчику памяти. Учитывается не только текст, но и скрытые непечатные символы, цифры и знаки препинания. Программа находит совпадающие сегменты текста и предоставляет статистику по словам (подсчитывая количество слов в сегментах).
Слова, входящие в состав сегментов, совпадающих на 100%, мы называем «повторения», работа с ними – это только проверка, занимающая существенно меньше времени, чем перевод, и оцениваемая в 25% от тарифа за перевод нового текста. Помимо «повторений», в тексте всегда есть сегменты, совпадающие почти полностью, но все же не на 100%.
Например, в предложении, переведенном ранее и присутствующем в ТМ, изменили одно слово или поставили знак препинания, такие предложения считаются «частичными совпадениями». Программа оценивает % совпадающих слов или знаков, что позволяет отделить почти полные совпадения от тех, где процент совпадения совсем низкий (например, совпадает 2 слова из 10). Переводчику проще работать с сегментами, совпадающими на 85–99%. Нужно переводить меньше текста, в связи с чем на слова, входящие в состав таких сегментов, также предоставляется скидка.
Чтобы наглядно понять, как текст разделяется на «повторения», «частичные совпадения» и «новые слова», рассмотрим пример из нашей практики.
Агентство переводов «ЛИНГВАКОНТАКТ»
![]()
+7 921 967-94-88
+7 812 967-94-88


Опыт перевода
более 10 лет!
Множество довольных
клиентов. Проверьте!


Переведём все
что угодно более чем
по 50 языковым парам

Время клиента —
ценнейший ресурс.
Мы гарантируем качество
нашей работы.

Нужен срочный перевод?
Переведем с листа за 60 минут.
Или 100 страниц на следующий
день. Проверить!

Сэкономим Ваш бюджет,
используя высокотехнологичные
программные решения:
CAT, Xbench, Verifika и др.

Конфиденциальность
для нас — синоним
профессии переводчика.
Работаем в соответствии с
Этическим кодексом
переводчика

Мастерство, оточенное
временем. Ведем
сложные переводческие
проекты с 2008 года.


Качественный сервис —
это вдумчивые и
внимательные менеджеры.
А также удобный Вам способ
оформления сделки и оплаты.
Проверьте!

Гибкая ценовая политика —
неотъемлемая часть
умного сервиса.
У нас Вы всегда
будете понимать
за что платите.

«ЛингваКонтакт» —
это еще и крупнейшие
переводческие курсы России.
Профессию переводчика
мы знаем со всех сторон!
Технология translation memory

В наш век стремительного развития информационных технологий и невиданного до сих пор тесного взаимодействия самых, казалось бы, отдалённых культур потребность в предоставлении быстрых и качественных переводческих услуг становится особенно актуальной. И не удивительно, что сфера письменного перевода , считавшаяся до недавнего времени территорией приложения исключительно человеческого интеллекта, с появлением уже первых компьютеров начала медленно, но заметно видоизменяться. И не могло быть иначе, ведь облегчение труда и постоянный поиск новых решений заложен в самой сути человека.
Как это часто бывает, технический прогресс в сфере коммуникаций не только поставил перед человечеством новые задачи, но и принёс с собой средства для их решения. В сфере письменных переводов одним из таких решений стала технология под названием Translation Memory (ТМ) и использующие её средства автоматизированного перевода (CAT — computer assisted translation).

Важно заметить, что средства автоматизированного перевода ни в коем случае нельзя путать с машинным переводом. Это два совершенно разных подхода к автоматизации перевода компьютерными средствами, две совершенно разные «философии» переводческого процесса.
В случае машинного перевода весь перевод — от начала и до конца — делает машина, компьютер, используя для этого имеющиеся в её распоряжении словари и алгоритмы перевода. Как следствие, результат такой работы далёк от того, что можно назвать «качественным переводом» ровно по той причине, что искусственный интеллект до сих не изобретен человечеством. Во втором же случае речь идёт только об инструментах, облегчающих и ускоряющих традиционный процесс человеческого перевода, который выполняется и контролируется непосредственно переводчиком. Бюро переводов «ЛингваКонтакт» никогда не занималось и не занимается машинным переводом.
Translation Memory (TM) или «память переводов» (ПП) представляет собой базу данных, где хранятся все ранее выполненные переводы с её использованием. Для удобства переводчика программы, использующие технологию Translation Memory, разбивают переводимый текст на так называемые сегменты — фрагменты текста, оригинал и перевод которых и хранится в памяти. За единицу сегментирования (минимальную единицу перевода) такие программы обычно принимают предложение или часть сложноподчинённого предложения, но в зависимости от настроек ею также могут быть слово, фраза либо целый абзац.
Принцип работы большинства средств автоматизированного перевода прост. Во время перевода программа, во-первых, «запоминает» все переводы сегментов, подтверждённые переводчиком, а во-вторых, постоянно сверяет каждый новый непереведённый сегмент с уже имеющимися в памяти переводов и в случае обнаружения идентичного или похожего сегмента «напоминает» его перевод. Таким образом, переводчику остаётся только подтвердить предложенный программой перевод или исправить/дополнить его в соответствии с контекстом.
Кроме собственно создания и работы с памятью переводов, современные программы автоматизированного перевода позволяют:
— создавать и использовать глоссарии и словари пользователей;
— создавать памяти переводов из пар уже ранее переведенных текстов без использования средств автоматизированного перевода;
— проводить анализ текста и делать выборку из его ключевых слов, которые потом можно добавлять в глоссарии;
— осуществлять так называемый «предварительный перевод» (pretranslation) на основе уже имеющихся баз ПП.
Наиболее эффективно применение данной технологии для перевода:
— больших проектов, содержащих много однотипных фрагментов и терминов: разного рода научных и технических текстов, документаций, финансовых и юридических текстов;
— одного проекта группой из нескольких переводчиков — в этом случае технология ПП (облачная) позволяет добиться единообразия терминологии и стиля;
— новых версий уже ранее переведённых текстов — это значительно сокращает время на поиск и перевод новых фрагментов;
— файлов, содержащих разметку: файлы с веб-контентом (HTML, XML и др.) и файлы издательских систем (FrameMaker, Interleaf, Pagemaker и др.).
В то же время эта технология оказывается практически бесполезной при переводе художественных, публицистических и рекламных текстов. Другими словами, всего того, что требует творческого подхода и незаурядных решений.
Вот так выглядит интерфейс SDL Trados, интегрированной в MS Word:
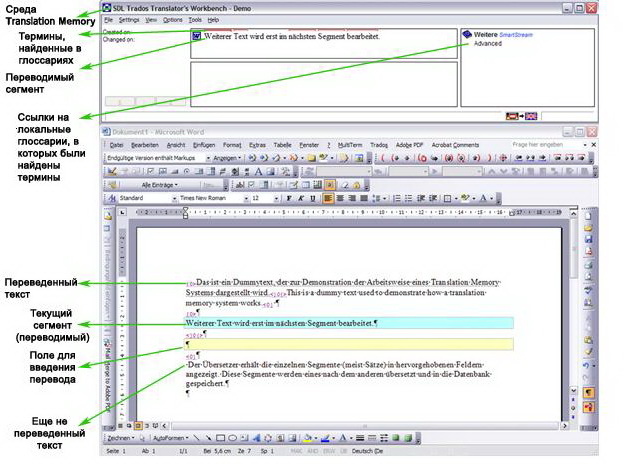
Краткий обзор основных средств автоматизированного перевода
Сегодня на рынке представлено несколько десятков программ, поддерживающих работу с технологией Translation Memory. Самыми известными из них являются SDL Trados, Déjà vu, Wordfast, MultiTrans, STAR Transit и Omega-T. Кроме самого очевидного — цены (например, программа Omega-T является полностью бесплатной) — эти программные среды отличаются:
— интерфейсом редактирования текста: некоторые программы интегрируются в MS Word (например, все версии SDL Trados до версии SDL Trados 2007 включительно), другие же имеют свой собственный интерфейс;
— алгоритмами разбиения текста на сегменты (сегменты состоят из предложений, фраз или слов);
— наличием дополнительных функций (например, в программе MemoQ, в отличии от других, существует возможность оценки в процентном отношении однородности текста, т.е. наличия в нём повторяющихся элементов на уровне слов и фраз);
— возможностью интеграции средств машинного перевода;
— количеством поддерживаемых форматов файлов;
— наличием возможности работать с памятью переводов в режиме он-лайн.
Выбор CAT-программы часто зависит больше от личных предпочтений переводчика или требований бюро переводов, с которым он сотрудничает (к примеру, многие западные бюро переводов работают с форматом TTX, а он полноценно поддерживается только средой SDL Trados).
Переводчики бюро переводов «ЛингваКонтакт» знают и владеют на высоком уровне самыми распространенными CAT-инструментами. Кроме того, в нашем арсенале «помощников переводчика» есть не только средства работы с памятью переводов, но также и множество других программ и утилит (инструменты Quality Assurance, создание терминологических баз, межформатная конвертация и пр.), без которых едва ли можно добиться высокого качества и скорости работы. На счету «ЛингваКонтакт» десятки тысяч переведённых страниц с использованием TM-средств!
Вы можете быть уверены, что Ваш текст будет переведён качественно и в срок, в каком бы формате и какой бы сложности он ни был!
Источник: linguacontact.com