
Апельсиновый Data Mining
Хотим познакомить вас с Orange, системой визуального программирования для отображения данных, машинного обучения и интеллектуального датамайнинга.
4886 просмотров
Многие из тех, кто когда-либо сталкивался с Python-ом, наверняка знают и видели Anaconda Navigator, пакет языков, библиотек и приложений для DS. В числе всего прочего в его состав входит и Orange, который можно узнать по иконке в виде улыбающегося апельсина в очках. Однако из-за того, что по умолчанию он с дистрибутивом Anaconda не поставляется и его, прежде чем запустить, нужно установить (хоть и нажатием одной кнопки), большинство пользователей до его использования не доходят.
Orange позволяет сразу «из коробки» приобщиться к увлекательному миру анализа данных даже тем, кто раньше не решался это сделать из-за опасений, что не сможет разобраться в сложных математических построениях или в программировании. Теперь вам достаточно ориентироваться в своей предметной области и иметь небольшое – совсем небольшое, буквально обзорное – представление о методах статистики и моделирования. А дальше вы просто рисуете в Orange схему обработки ваших данных.
Оранж 5 обзор программы
Вот так выглядит в Orange типичный поток («workflow») обработки данных:
Процесс построения workflow в Orange происходит путём манипуляций с иконками-виджетами, которые мышкой выкладываются на холст – рабочий стол приложения. Каждый виджет представляет собой программный блок, который каким-либо образом обрабатывает поступившую на его вход информацию и передаёт её дальше, для обработки, визуализации или сохранения следующим виджетом. Связи между виджетами протягиваются мышкой, двойной щелчок открывает окно его настроек: например, отображаемые оси и масштаб для графика и сам график, гиперпараметры для алгоритма машинного обучения, имя файла для виджета загрузки или сохранения данных и т.д. и т.п.
В левой части окна Orange находится блок меню для выбора виджетов. Изначально они сгруппированы в пять разделов:
- Data: виджеты для ввода/вывода данных, фильтрации, выделения и манипулирования выборками, а также (sic!) – большое количество учебных наборов данных (от классических Titanic и Iris, до статистики ДТП в Словении за 2014 год);
- Visualize: виджеты для общей (прямоугольная диаграмма, гистограммы, точечная диаграмма) и многомерной визуализации (мозаичная диаграмма, диаграмма-сито);
- Model: набор алгоритмов машинного обучения для классификации и регрессии;
- Evaluate: кросс-валидация, процедуры на основе выборки, оценка методов предсказания;
- Unsupervised: алгоритмы кластеризации (k-средние, иерархическая кластеризация) и проекции данных (многомерное масштабирование, анализ главных компонент, анализ соответствия).
В комплекте начальной установки Orange не содержит, но при необходимости даёт возможность дополнительно загрузить ещё несколько наборов виджетов:
- Associate: датамайнинг повторяющихся наборов элементов и обучение ассоциативным правилам;
- Bioinformatica: анализ наборов генов и доступ к библиотекам геномов;
- Data fusion: объединение различных наборов данных, коллективная матричная факторизация и исследование скрытых факторов;
- Educational: обучение концепциям machine learning;
- Geo: работа с геоданными;
- Image analytics: работа с изображениями, анализ нейронными сетями;
- Network: графовый и сетевой анализ;
- Text mining: обработка естественного языка и анализ текста;
- Time series: анализ и моделирование временных рядов;
- Spectroscopy: анализ и визуализация спектральных наборов данных.
3.1. Обзор платформы Orange Data Mining
А если и этого недостаточно, то у Orange есть виджет для окончательного решения всех вопросов — Python Script, который позволяет вам написать на Python любой обработчик входных данных.
Для примера, чтобы вы представляли себе, как работает Orange, попробуем решить в нём классическую задачу обработки данных «Titanic» с Kaggle. Решать будем самыми простыми, насколько это будет возможно, методами, чтобы просто показать сам процесс создания решения.
Вот так в Orange выглядит workflow решения (один из вариантов):
Последовательно пройдём по шагам построения workflow.
Напомню, что исходными данными в этой задаче являются два набора данных, поставляемых в виде CSV-файлов:
- файл Train.csv с частью данных о пассажирах «Титаника» (возраст, семейное положение, номер каюты и т.д.) и информацией о том, выжили эти пассажиры или погибли в результате столкновения корабля с айсбергом;
- файл Test.csv, с частью информации об оставшихся пассажирах, но без указания того, остались ли они в живых.
Наша задача — используя методы DS, реализуемые виджетами Orange, предсказать, какова была судьба пассажиров из выборки Test.
- Для каждого из наборов данных выложим на холст виджет File из раздела Data. В свойствах каждого виджета пропишем пути, по которым находятся наши файлы, укажем, какие поля у загружаемых наборов будут target и features и каких типов будут эти поля – числовые, категориальные, временные или текстовые, а какие поля вообще не надо обрабатывать. Данный процесс можно оставить на усмотрение виджета, но автоматическое определение типа полей часто даёт некорректные результаты, поэтому лучше сделать всё руками:
2. Выложим виджет Data Table из раздела Data для отображения загруженного набора данных и соединим его с виджетом File набора Train. Откроем виджет Data Table и посмотрим на загруженную таблицу с данными. Обратите внимание, что в верхней левой части виджета отобразилась некоторая статистика по полям и записям загруженного набора данных:
3. К сожалению, больше века назад, когда произошла трагедия «Титаника», дела со сбором информации о пассажирах, пострадавших в кораблекрушении, обстояли не очень. Данные о многих людях были не полными, не точными, а о некоторых отсутствовали вовсе. Для очистки полученных данных выложим на холст виджет Impute из раздела Data. В его настройках укажем метод среднего, которым будем заменять отсутствующие или некорректные значения. Также передадим данные с выхода этого виджета на вход виджета Data Table, чтобы во второй вкладке, которая там появится, посмотреть на результат работы очистки:
4. Пришло время построить модель классификации, которая по известным признакам на тренировочном наборе будет пытаться предсказать, выжил пассажир или нет. Для этого выложим на холст виджеты Logistic Regression, Random Forest и Neural Network из раздела Model. При этом, для ускорения процесса, подкручивать метапараметры этих алгоритмов не будем, оставим их настройки как есть, по умолчанию:
5. Теперь нужно проверить результаты работы выбранных алгоритмов и рассчитать их оценочные метрики. Для этого выложим на холст виджет Test and Score из раздела Evaluate и подадим на его вход данные с виджетов Impute, Logistic Regression, Random Forest и Neural Network. На основе этих данных виджет Test and Score автоматически начнёт рассчитывать результаты работы моделей, построенных из очищенного набора данных этими алгоритмами, а также оценки их работы. Двойным щелчком откроем виджет Test and Score и посмотрим на рассчитанные результаты:
Как видно в левой части настроек виджета, для расчёта модели был использован метод сэмплирования, когда исходная обучающая выборка случайным образом разбивается на 80% рабочей обучающей выборки и 20% валидационной выборки; данный цикл повторяется 10 раз.
6. Судя по результатам, лучшие результаты, за исключением метрики AUC, дал метод логистической регрессии, поэтому в дальнейшем будем использовать его.Для построения рабочей модели классификации выложим на холст ещё один виджет Logistic Regression из раздела Model, виджет Data Sampler из раздела Data и виджет Predictions из раздела Evaluate. Виджет Data Sampler будет делить обучающую выборку на две части случайным образом в соотношении 80/20%, а виджет Predictions будет делать в наборе данных Test собственно предсказание целевого поля на основании модели, построенной виджетом Logistic Regression.
Подадим на вход виджета Data Sampler выход виджета Impute, выход Data Sampler подадим на вход Logistic Regression, а на вход Predictions подадим выходы с File Test и Logistic Regression. Откроем Predictions и в первом столбце таблицы посмотрим на поле, заполненное предсказанными значениями целевого поля:
7. Добавим на холст последний виджет – Save Data из раздела Data и сохраним результат выполненного предсказания:
8. Откроем сохранённый файл, оставим в нём только целевое поле и поле идентификатора пассажира, как того требует условие конкурса, и загрузим полученный submission на Kaggle:
9. И, наконец, наступил момент истины: посмотрим, насколько хорошо мы двигали мышкой для того, чтобы сделать реальный Data Science.
Жмём на «Make submission», и…
Достаточно неплохо для решения, в котором мы совершенно не делали анализ и редизайн фич, не подбирали метапараметры обучения моделей, не собирали модели в ансамбли, да и вообще не делали ничего, за исключением нескольких кликов мышью.
Конечно же, мы лишь поверхностно рассмотрели работу с системой Orange и использовали в процессе решения несколько процентов его возможностей. Для того, чтобы их изучить, в саму систему встроили очень подробную справку и множество примеров использования в разных кейсах обработки данных.
Кроме того, сообщество разработчиков Orange ведёт на YouTube блог «Orange Data Mining», в котором выкладывает видео с примерами решения задач практически на любой случай из жизни.
К сожалению, все эти материалы представлены только на английском языке. На русском языке документации по Orange практически нет, кроме пары обзорных презентаций, и ещё на YouTube есть видео, в котором очень подробно шаг за шагом рассматривается решение задачи классификации, как это делали мы с «Титаником», но для более сложного тестового датасета.
Поэтому лучше всего начать разбираться с тем, что может Orange — установив его, загрузив в примеры использования свои наборы данных, попробовав обработать их всеми возможными виджетами и посмотрев, что из этого получится. А Google поможет понять названия настроек виджетов, если у вас до сих пор по каким-либо причинам плохо с английским.
И, возможно, для вас это будет самый простой и быстрый способ почувствовать себя DS-специалистом, а там, глядишь, и до питона недалеко.
Источник: vc.ru
Интеллектуальный анализ данных — используем Orange

Orange — это инструмент для визуализации и анализа данных с открытым исходным кодом. Orange разрабатывается в лаборатории биоинформатики на факультете компьютерных и информационных наук Университета Любляны, Словения, вместе с сообществом открытого исходного кода.
Orange — это библиотека Python. Интеллектуальный анализ данных (Data mining) осуществляется с помощью визуального программирования или сценариев Python. Сценарии Python могут выполняться в окне терминала, интегрированных средах, таких как PyCharm и PythonWin, или оболочках, таких как iPython.
Категория — Data Mining Software.
Лицензия — Open Source.
Стоимость — бесплатно.
Преимущества Orange для машинного обучения и анализа данных
• Для всех — начинающих и профессионалов.
• Выполнить простой и сложный анализ данных.
• Создавайте красивую и интересную графику.
• Использование в лекции анализа данных.
• Доступ к внешним функциям для расширенного анализа.
Лучшая и отличительная черта Orange — это замечательные визуальные эффекты.
Этот инструмент содержит компоненты для машинного обучения, дополнения для биоинформатики и интеллектуального анализа текста, а также множество функций для анализа данных. Orange состоит из интерфейса Canvas, на который пользователь помещает виджеты и создает рабочий процесс анализа данных.
Виджеты предлагают базовые функции, такие как чтение данных, отображение таблицы данных, выбор функций, предикторы обучения, сравнение алгоритмов обучения, визуализация элементов данных и т. д. Пользователь может интерактивно исследовать визуализации или передавать выбранное подмножество в другие виджеты.
В Orange процесс анализа данных (Data mining) может быть разработан с помощью визуального программирования.
Orange запоминает выбор, предлагает часто используемые комбинации. Orange имеет функции для различных визуализаций, таких как диаграммы рассеяния, гистограммы, деревья, дендрограммы, сети и тепловые карты.
Комбинируя виджеты, создайте структуру аналитики данных. Существует более 100 виджетов с охватом большинства стандартных и специализированных задач анализа данных для биоинформатики.
Orange читает файлы в собственном и других форматах данных.
Классификация использует два типа объектов: ученики и классификаторы. Учащиеся рассматривают данные, помеченные классом, и возвращают классификатор.
Методы регрессии в Orange очень похожи на классификацию. Они предназначены для интеллектуального анализа данных (Data mining), помеченных классом.
Обучение базовых наборов обучающих данных включает прогнозы отдельных моделей, чтобы достичь максимальной точности.
Модели могут быть получены из разных выборок обучающих данных или могут использовать разных учеников в одних и тех же наборах данных.
Учащиеся также могут быть разнообразны, изменяя свои наборы параметров.
Чем Orange поможет SEO-специалисту:
• Анализ и визуализация данных при аудите своего сайта или сайтов конкурентов;
• Анализ ссылочного, выявление связей в группе сайтов;
• Интеллектуальный анализ текстового контента (text-mining).
• Кластеризация данных.
Настройка системы Orange для анализа данных
Orange поставляется со встроенным инструментом Anaconda, если вы его предварительно установили. Если нет, выполните следующие действия для загрузки Orange.
Шаг 1: Перейдите на https://orange.biolab.si и нажмите «Скачать».
Шаг 2: Установите платформу и установите рабочий каталог, в котором Orange будет хранить свои файлы.
Прежде чем углубимся в работу Orange, давайте определим ключевые термины, которые помогут в дальнейшем понимании:
Виджет — основная точка обработки любых действий с данными. Виджет выполняет действия в зависимости от того, что вы выберете в селекторе виджетов в левой части экрана.
Рабочий процесс — это последовательность шагов или действий, которые вы выполняете на платформе для решения задачи.
Перейдите к разделу «Примеры рабочих процессов» на начальном экране, чтобы изучить варианты дополнительных рабочих процессов и используемых моделей.
Создание первого рабочего процесса
Нажмите «New» и создайте первый рабочий процесс.
Это первый шаг на пути к решению любой задачи. Обдумайте, какие шаги необходимо предпринять для достижения конечной цели — алгоритм построения процесса.

Импорт данных в Orange
Шаг 1: Нажмите на вкладку «Data» в меню выбора виджетов и перетащите виджет «File» в пустой рабочий процесс.
Шаг 2: Дважды щёлкните виджет «File» и выберите файл с данными, который вы хотите загрузить в рабочий процесс.
Шаг 3: Как только вы сможете увидеть структуру набора данных с помощью виджета, вернитесь, закрыв это меню.
Шаг 4: Поскольку нам нужна таблица данных, чтобы лучше визуализировать наши результаты, мы нажимаем на виджет «Data Table».
Шаг 5. Теперь дважды щёлкните виджет, чтобы визуализировать таблицу.

Визуализация данных при помощи Orange
Виджет Scatter Plot один из самых популярных в среде Orange. Нажмите на полукруг перед виджетом «File», перетащите его в пустое место в рабочем процессе и выберите виджет «Scatter Plot».
Как только создадите виджет Scatter Plot, дважды щёлкните по нему и изучите данные. Вы можете выбрать оси X и Y, цвета, формы, размеры и другие настройки.

Экспериментируйте, добавляя или меняя виджеты в вашем рабочем процессе.
Это только первая (вводная) статья об интеллектуальном анализе данных (Data mining) с использованием Orange. В следующей статье рассмотрим пример использования Orange для поисковой оптимизации сайтов.
Источник: pro100blogger.com
Визуализация данных
Система Orange является инструментом для визуализации и анализа данных с открытым исходным кодом. Интеллектуальный анализ данных проводится путем визуального программирования и с помощью Python сценариев.
На рисунке представлен скриншот главного окна программы Orange3.
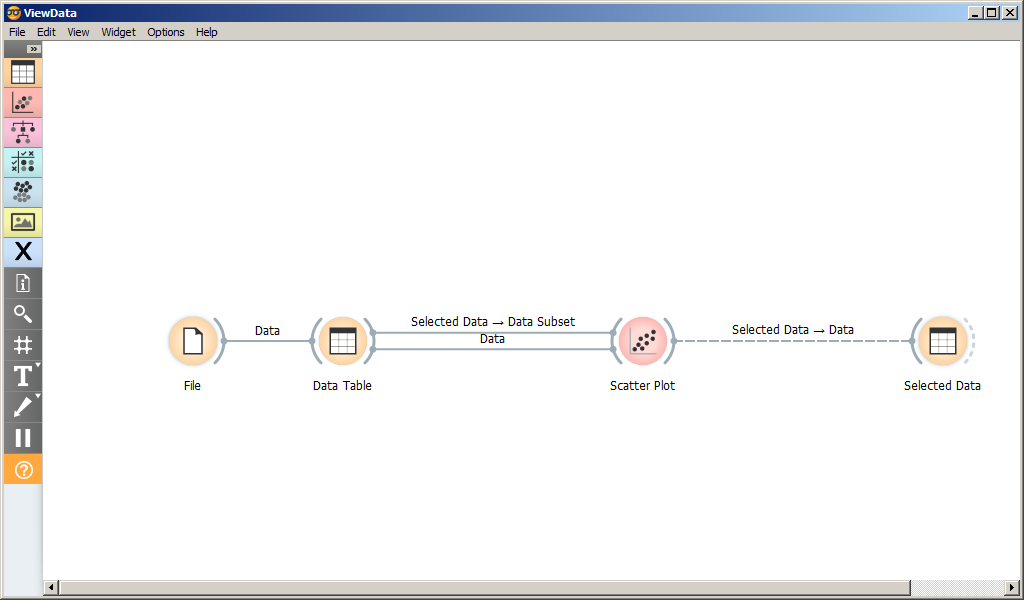
Рабочее пространство состоит из виджетов и связей между ними.
Каждый виджет имеет свой тип. Тип виджета можно определить по его иконке.
Виджеты сгруппированы по разделам: Data, Visualization, Predictions и пр. Группа виджета определяет цвет иконки.
Каждый виджет имеет множество (возможно, пустое) входных и множество выходных сигналов. Сигнал определяет данные, которые поступают на вход виджету или являются его результатом. При получении входного сигнала виджет выполняет определенные действия и оповещает связанные с ним виджеты путем отправки им соответсвующих сигналов.
Сигнал представляет собой экземпляр класса-наследника Orange.util.Reprable .
Для загрузки датасета имеется множество виджетов. Самый простой (File) считывает данные из файла или загружает по URL. Существуют виджеты для получения данных из базы данных PostgreSQL, Google Docs и других источников.
Скриншот параметров виджета File представлен на рисунке. Виджет позволяет выбрать файл с жесткого диска или загрузить из интернета по URL, а также выводит основные параметры датасета.
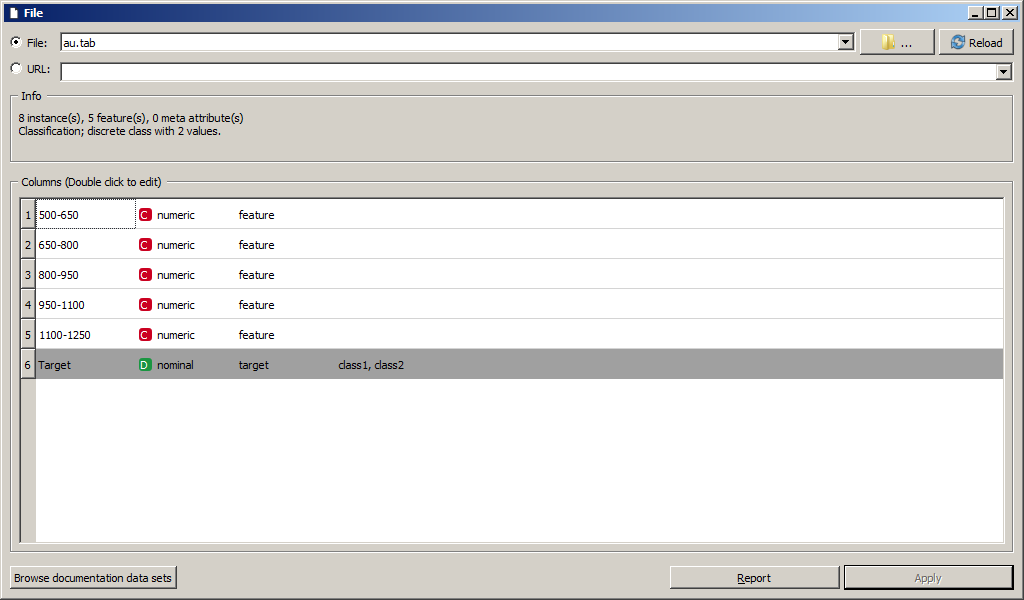
Виджет File имеет единственный выходной сигнал Data (тип Orange.data.Table ). Он связан с единственным входным сигналом Data виджета Data Table.
Виджет Data Table выводит данные из файла на экран.
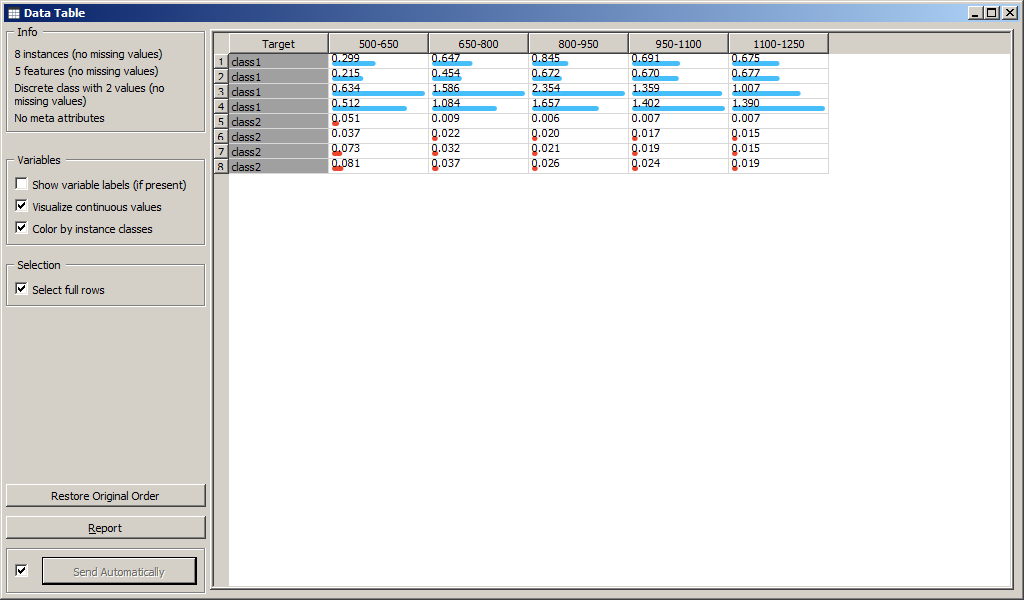
При обновлении файла обновляется Data Table. При создании связи между виджетами входной и выходной сигналы выбираются автоматически. Если сигналов виджета много, то могут возникнуть ошибки. Для редактирования связи необходимо дважды кликнуть по ней мышью (рисунок [view1a]).
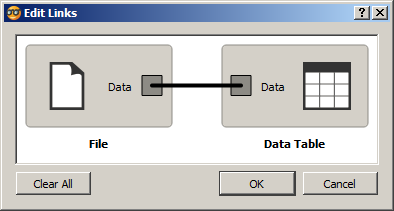
Связь между двумя виджетами подписывается над стрелкой. Если названия входного и выходного сигнала совпадают, то указывается это название. Если не совпадают, то указываются оба сигнала.
Виджет Scatter Plot позволяет строить двумерные графики по выбранным признакам.
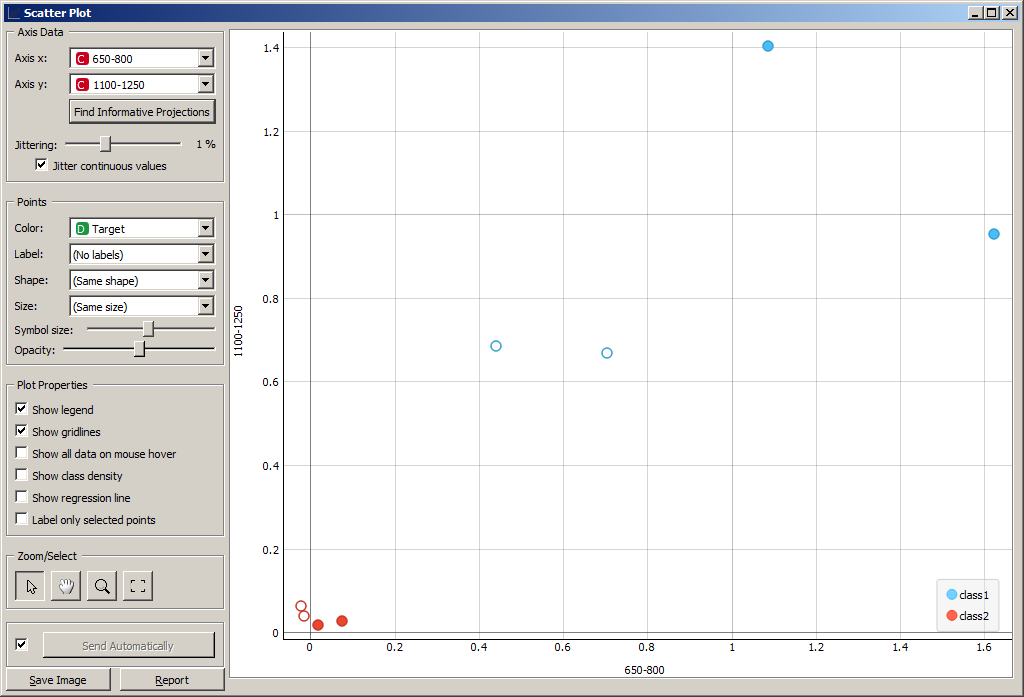
Виджет Scatter Plot имеет три входных сигнала:
- Data ( Orange.data.Table );
- Data Subset ( Orange.data.Table );
- Features ( Orange.widgets.widget.AttributeList ).
Сигнал Data принимает данные для отображения на графике, а сигнал Data Subset – подмножество данных. Если Data Subset определен, то на графике будут заштрихованы точки, соответствующие Data Subset.
Так, можно выбрать некоторые элементы из таблицы данных Data Table, и увидеть, как они расположены на графике по отношению к другим точкам. В примере на рисунке выбраны образы 3, 4, 5, 6.
Можно выделить некоторые точки на графике и изучить значения признаков соответствующих им объектов в таблице.
Система Orange содержит большое количество виджетов для визуализации данных, не рассмотренных выше. Среди них:
- Box Plot для построения диаграммы размаха (>);
- Distributions для построения диаграммы частотного распределения признака;
- Heat Map для построения тепловой диаграммы;
- Venn Diagram для построения диаграммы Венна;
- Sieve Diagram для построения паркетной диаграммы Ридвиля и Шюпбаха;
- Pythagorean Tree и Pythagorean Forest для построения деревьев Пифагора;
- Mosaic Display для построения мозаичной диаграммы;
- Tree Viewer для визуального представления древовидных структур;
- FreeViz и Radviz для визуализации многомерных данных;
Тестирование классификаторов
Схема программы для тестирования классификаторов приведена на рисунке.
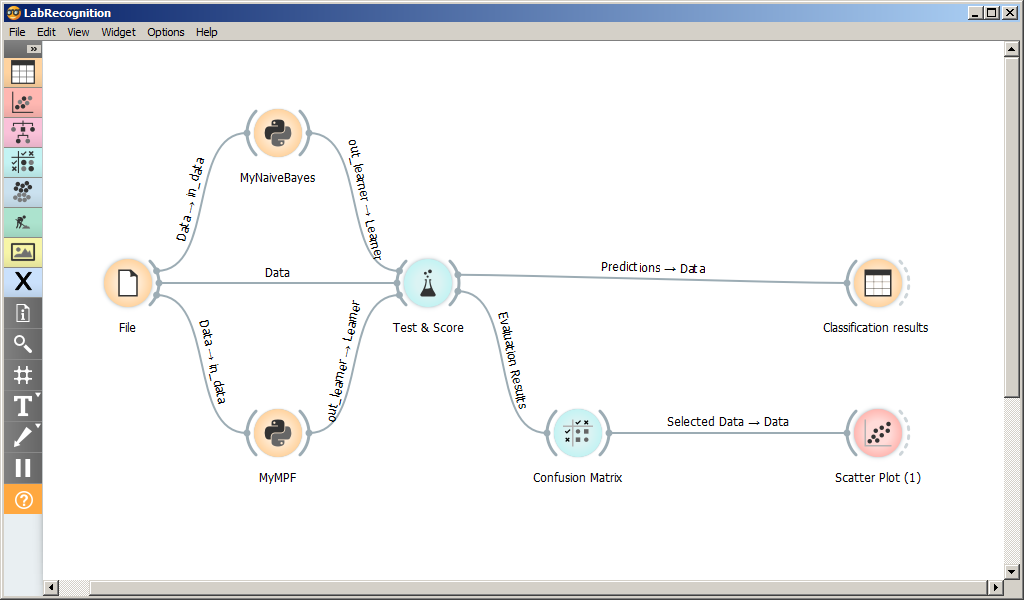
На форме размещены следующие виджеты:
- File для чтения датасета из файла;
- Python-скрипты MyNaiveBayes и MyMPF, классификаторы Байеса и методом потенциальных функций;
- Test and Score, виджет для сравнения и оценки классификаторов;
- Confusion Matrix, Scatter Plot, Classification results виджет для вывода результатов классификации;
MyNaiveBayes и MyMPF подробно рассмотрены в следующем разделе.
- Data ( Orange.data.Table ) – данные, на которых будет обучена модель;
- Test Data ( Orange.data.Table ) – данные для проверки модели;
- Learner ( Orange.classification ) – один или несколько > – обученных моделей классификации, которые будут тестироваться.
В качестве результата виджет имеет следующие выходные сигналы:
- Evaluation results ( Orange.evaluation.Results ) – результаты проверки классификаторов;
- Predictions ( Orange.data.Table ) – размеченная тестовая выборка.
Виджет Test and Score позволяет тестировать классификаторы одним из следующих методов:
- кросс-валидация;
- выделение одного;
- случайная разбивка в заданном соотношении;
- проверка на обучающей выборке;
- проверка на тестовой выборке.
Проверка классификатора осуществлялась методом случайного деления обучающей выборки в соотношении 33:66, т.е. треть данных была выделена для тестирования. Операция повторится два раза без сохранения промежуточной информации.
Результаты классификации приведены на рисунке.
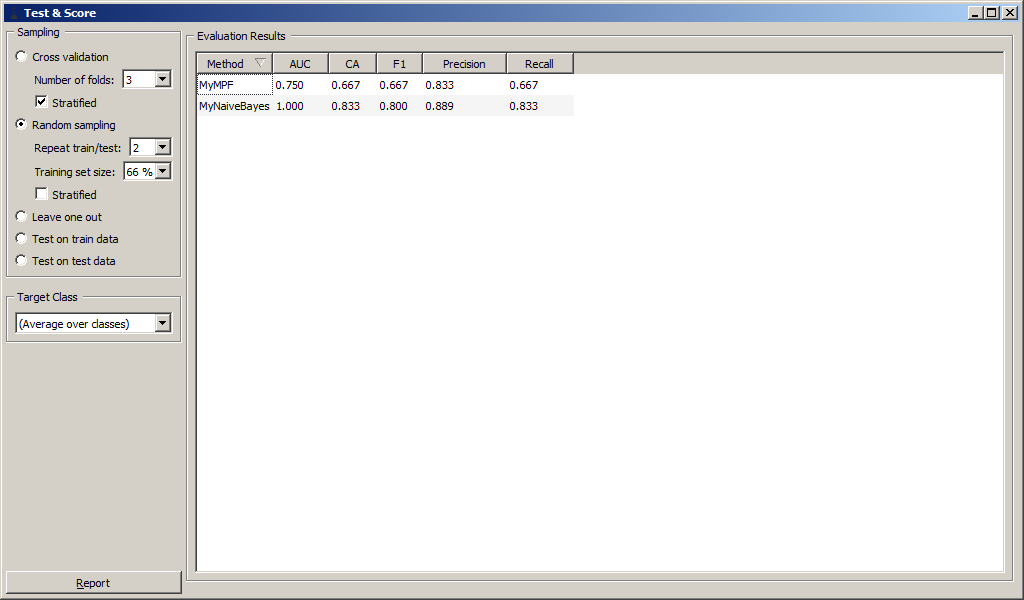
Были вычислены численные характеристики классификации:
- Area under ROC;
- Classification accuracy;
- F-1;
- Precision;
- Recall.
Для более детального анализа воспользуемся виджетом Confusion Matrix для сравнения количества правильно и неправильно распознанных образов. Результаты классификации MyMPF и MyNaiveBayes приведены на рисунках.
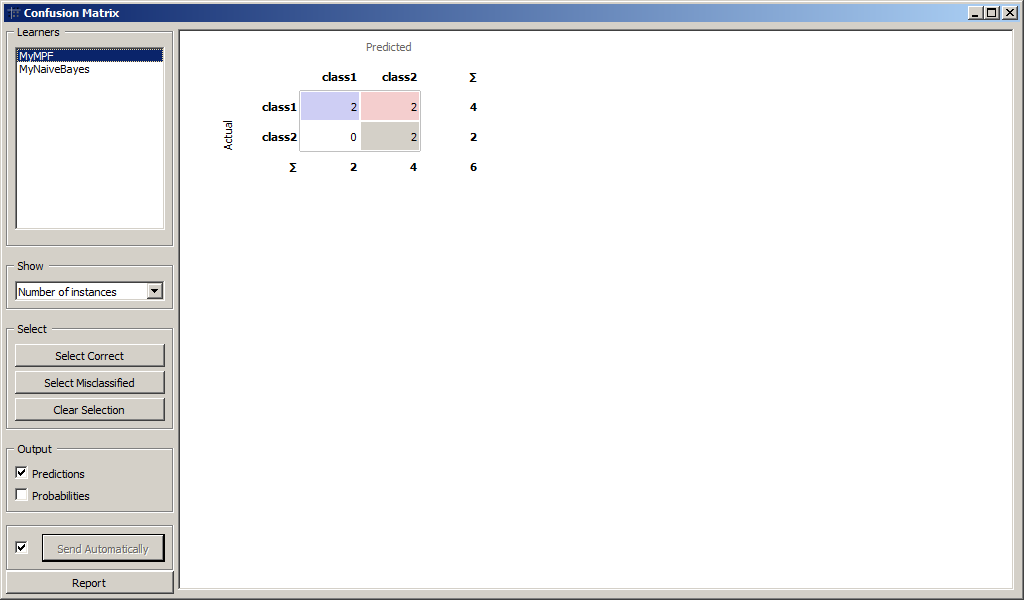
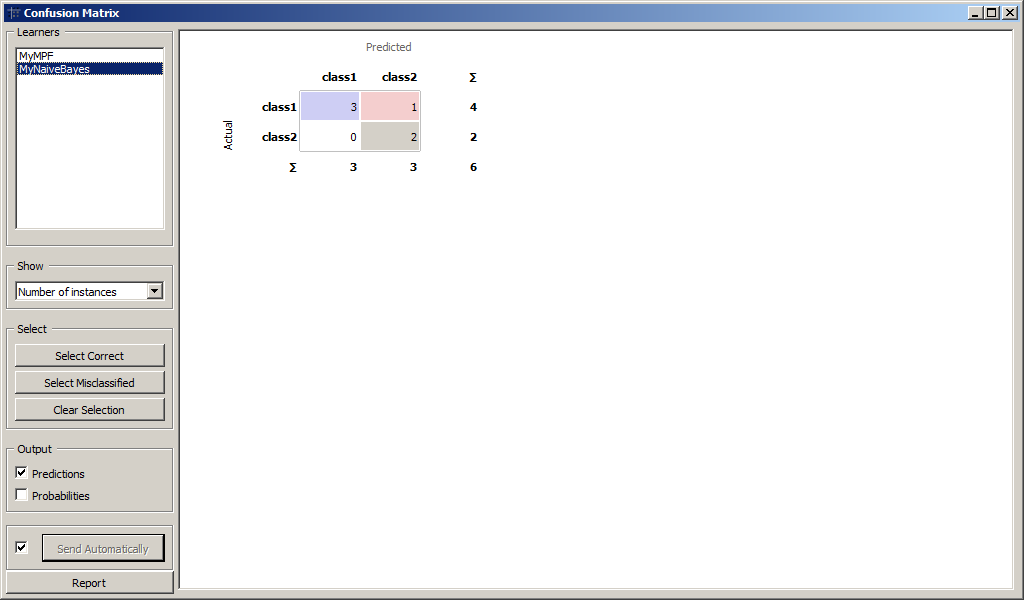
Образы, которые были подвергнуты классификации приведены на рисунках.
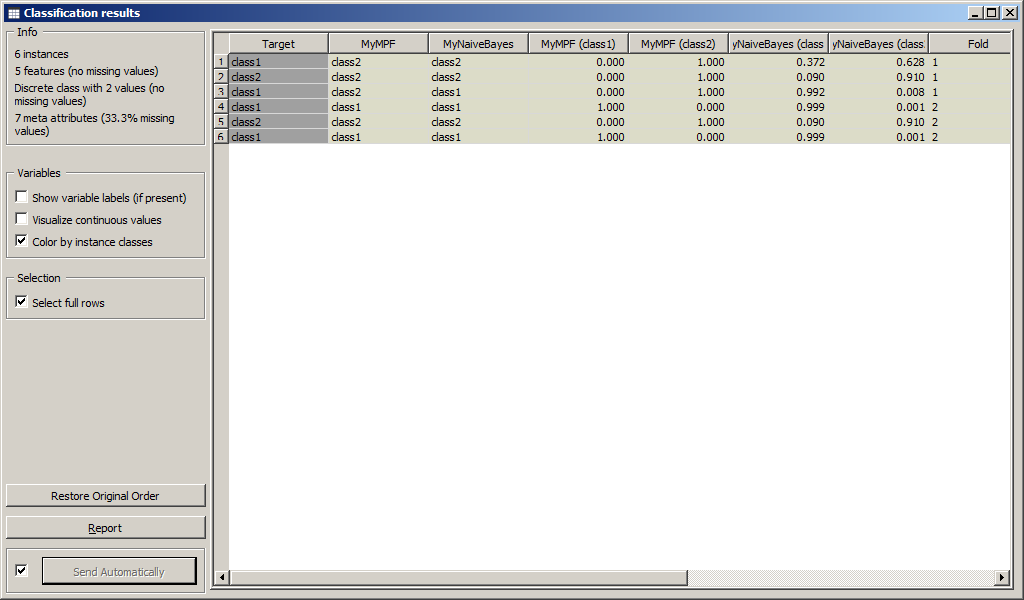
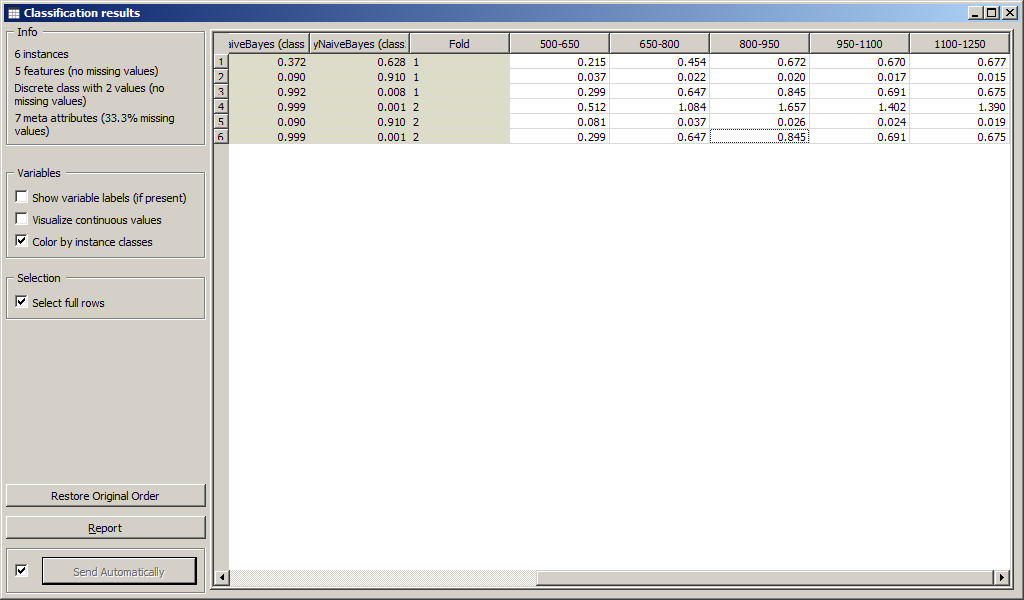
Результаты
Файлы orange-проектов можно скачать по ссылкам:
Источник: ansmirnov.ru
АПЕЛЬСИНОВЫЙ DATA MINING

Я хочу познакомить вас с Orange, системой визуального программирования для отображения данных, машинного обучения и интеллектуального датамайнинга.
Многие из тех, кто когда-либо сталкивался с Python-ом, наверняка знают и видели Anaconda Navigator, пакет языков, библиотек и приложений для DS. В числе всего прочего в его состав входит и Orange, который можно узнать по иконке в виде улыбающегося апельсина в очках. Однако из-за того, что по умолчанию он с дистрибутивом Anaconda не поставляется и его, прежде чем запустить, нужно установить (хоть и нажатием одной кнопки), большинство пользователей до его использования не доходят.
Orange позволяет сразу «из коробки» приобщиться к увлекательному миру анализа данных даже тем, кто раньше не решался это сделать из-за опасений, что не сможет разобраться в сложных математических построениях или в программировании. Теперь вам достаточно ориентироваться в своей предметной области и иметь небольшое – совсем небольшое, буквально обзорное – представление о методах статистики и моделирования. А дальше вы просто рисуете в Orange схему обработки ваших данных.
Вот так выглядит в Orange типичный поток («workflow») обработки данных:

Процесс построения workflow в Orange происходит путём манипуляций с иконками-виджетами, которые мышкой выкладываются на холст – рабочий стол приложения. Каждый виджет представляет собой программный блок, который каким-либо образом обрабатывает поступившую на его вход информацию и передаёт её дальше, для обработки, визуализации или сохранения следующим виджетом. Связи между виджетами протягиваются мышкой, двойной щелчок открывает окно его настроек: например, отображаемые оси и масштаб для графика и сам график, гиперпараметры для алгоритма машинного обучения, имя файла для виджета загрузки или сохранения данных и т.д. и т.п.
В левой части окна Orange находится блок меню для выбора виджетов. Изначально они сгруппированы в пять разделов:
- Data: виджеты для ввода/вывода данных, фильтрации, выделения и манипулирования выборками, а также (sic!) – большое количество учебных наборов данных (от классических Titanic и Iris, до статистики ДТП в Словении за 2014 год);
- Visualize: виджеты для общей (прямоугольная диаграмма, гистограммы, точечная диаграмма) и многомерной визуализации (мозаичная диаграмма, диаграмма-сито);
- Model: набор алгоритмов машинного обучения для классификации и регрессии;
- Evaluate: кросс-валидация, процедуры на основе выборки, оценка методов предсказания;
- Unsupervised: алгоритмы кластеризации (k-средние, иерархическая кластеризация) и проекции данных (многомерное масштабирование, анализ главных компонент, анализ соответствия).
В комплекте начальной установки Orange не содержит, но при необходимости даёт возможность дополнительно загрузить ещё несколько наборов виджетов:
- Associate: датамайнинг повторяющихся наборов элементов и обучение ассоциативным правилам;
- Bioinformatica: анализ наборов генов и доступ к библиотекам геномов;
- Data fusion: объединение различных наборов данных, коллективная матричная факторизация и исследование скрытых факторов;
- Educational: обучение концепциям machine learning;
- Geo: работа с геоданными;
- Image analytics: работа с изображениями, анализ нейронными сетями;
- Network: графовый и сетевой анализ;
- Text mining: обработка естественного языка и анализ текста;
- Time series: анализ и моделирование временных рядов;
- Spectroscopy: анализ и визуализация спектральных наборов данных.
А если и этого недостаточно, то у Orange есть виджет для окончательного решения всех вопросов — Python Script, который позволяет вам написать на Python любой обработчик входных данных.
Для примера, чтобы вы представляли себе, как работает Orange, попробуем решить в нём классическую задачу обработки данных «Titanic» с Kaggle. Решать будем самыми простыми, насколько это будет возможно, методами, чтобы просто показать сам процесс создания решения.
Вот так в Orange выглядит workflow решения (один из вариантов):

Последовательно пройдём по шагам построения workflow.
Напомню, что исходными данными в этой задаче являются два набора данных, поставляемых в виде CSV-файлов:
- файл Train.csv с частью данных о пассажирах «Титаника» (возраст, семейное положение, номер каюты и т.д.) и информацией о том, выжили эти пассажиры или погибли в результате столкновения корабля с айсбергом;
- файл Test.csv, с частью информации об оставшихся пассажирах, но без указания того, остались ли они в живых.
Наша задача — используя методы DS, реализуемые виджетами Orange, предсказать, какова была судьба пассажиров из выборки Test.
- Для каждого из наборов данных выложим на холст виджет File из раздела Data. В свойствах каждого виджета пропишем пути, по которым находятся наши файлы, укажем, какие поля у загружаемых наборов будут target и features и каких типов будут эти поля – числовые, категориальные, временные или текстовые, а какие поля вообще не надо обрабатывать. Данный процесс можно оставить на усмотрение виджета, но автоматическое определение типа полей часто даёт некорректные результаты, поэтому лучше сделать всё руками:

- Выложим виджет Data Table из раздела Data для отображения загруженного набора данных и соединим его с виджетом File набора Train. Откроем виджет Data Table и посмотрим на загруженную таблицу с данными. Обратите внимание, что в верхней левой части виджета отобразилась некоторая статистика по полям и записям загруженного набора данных:

- К сожалению, больше века назад, когда произошла трагедия «Титаника», дела со сбором информации о пассажирах, пострадавших в кораблекрушении, обстояли не очень. Данные о многих людях были не полными, не точными, а о некоторых отсутствовали вовсе. Для очистки полученных данных выложим на холст виджет Impute из раздела Data. В его настройках укажем метод среднего, которым будем заменять отсутствующие или некорректные значения. Также передадим данные с выхода этого виджета на вход виджета Data Table, чтобы во второй вкладке, которая там появится, посмотреть на результат работы очистки:

- Пришло время построить модель классификации, которая по известным признакам на тренировочном наборе будет пытаться предсказать, выжил пассажир или нет. Для этого выложим на холст виджеты Logistic Regression, Random Forest и Neural Network из раздела Model. При этом, для ускорения процесса, подкручивать метапараметры этих алгоритмов не будем, оставим их настройки как есть, по умолчанию:

- Теперь нужно проверить результаты работы выбранных алгоритмов и рассчитать их оценочные метрики. Для этого выложим на холст виджет Test and Score из раздела Evaluate и подадим на его вход данные с виджетов Impute, Logistic Regression, Random Forest и Neural Network. На основе этих данных виджет Test and Score автоматически начнёт рассчитывать результаты работы моделей, построенных из очищенного набора данных этими алгоритмами, а также оценки их работы. Двойным щелчком откроем виджет Test and Score и посмотрим на рассчитанные результаты:

Как видно в левой части настроек виджета, для расчёта модели был использован метод сэмплирования, когда исходная обучающая выборка случайным образом разбивается на 80% рабочей обучающей выборки и 20% валидационной выборки; данный цикл повторяется 10 раз.
- Судя по результатам, лучшие результаты, за исключением метрики AUC, дал метод логистической регрессии, поэтому в дальнейшем будем использовать его.Для построения рабочей модели классификации выложим на холст ещё один виджет Logistic Regression из раздела Model, виджет Data Sampler из раздела Data и виджет Predictions из раздела Evaluate. Виджет Data Sampler будет делить обучающую выборку на две части случайным образом в соотношении 80/20%, а виджет Predictions будет делать в наборе данных Test собственно предсказание целевого поля на основании модели, построенной виджетом Logistic Regression.
Подадим на вход виджета Data Sampler выход виджета Impute, выход Data Sampler подадим на вход Logistic Regression, а на вход Predictions подадим выходы с File Test и Logistic Regression. Откроем Predictions и в первом столбце таблицы посмотрим на поле, заполненное предсказанными значениями целевого поля:

- Добавим на холст последний виджет – Save Data из раздела Data и сохраним результат выполненного предсказания:

- Откроем сохранённый файл, оставим в нём только целевое поле и поле идентификатора пассажира, как того требует условие конкурса, и загрузим полученный submission на Kaggle:

- И, наконец, наступил момент истины: посмотрим, насколько хорошо мы двигали мышкой для того, чтобы сделать реальный Data Science.
Жмём на «Make submission», и…

Достаточно неплохо для решения, в котором мы совершенно не делали анализ и редизайн фич, не подбирали метапараметры обучения моделей, не собирали модели в ансамбли, да и вообще не делали ничего, за исключением нескольких кликов мышью.
Конечно же, мы лишь поверхностно рассмотрели работу с системой Orange и использовали в процессе решения несколько процентов его возможностей. Для того, чтобы их изучить, в саму систему встроили очень подробную справку и множество примеров использования в разных кейсах обработки данных.
Кроме того, сообщество разработчиков Orange ведёт на YouTube блог «Orange Data Mining», в котором выкладывает видео с примерами решения задач практически на любой случай из жизни.
К сожалению, все эти материалы представлены только на английском языке. На русском языке документации по Orange практически нет, кроме пары обзорных презентаций, и ещё на YouTube есть видео, в котором очень подробно шаг за шагом рассматривается решение задачи классификации, как это делали мы с «Титаником», но для более сложного тестового датасета.
Поэтому лучше всего начать разбираться с тем, что может Orange — установив его, загрузив в примеры использования свои наборы данных, попробовав обработать их всеми возможными виджетами и посмотрев, что из этого получится. А Google поможет понять названия настроек виджетов, если у вас до сих пор по каким-либо причинам плохо с английским.
И, возможно, для вас это будет самый простой и быстрый способ почувствовать себя DS-специалистом, а там, глядишь, и до питона недалеко.
Источник: newtechaudit.ru