
Распознавание текста (OCR)
С развитием Интернета стало широко применяться преобразование книг, брошюр, бланков и различных документов, напечатанных на бумаге, в электронную форму. Для этого применяются такие устройства, как сканеры.
Сканер создает точную копию сканируемых бумажных страниц со всем их содержимым — рисунками, текстом (рукописным, машинописным или печатным), таблицами и пр.
Иногда такого преобразования бывает достаточно, чтобы хранить документы в электронном виде. Но чаще всего требуется, чтобы была возможность редактирования текста, что невозможно сделать в отсканированных документах (потому что текст в них — это часть изображения).
Чтобы решить задачу извлечения текста из изображения. применяют программы оптического распознавания символов (программы OCR — от англ. optical character recognition).
Программы OCR чаще всего работают в связке со сканером. Сканер создает изображение страницы, программа OCR извлекает из этого изображения текст (правда, при этой операции теряется все остальное оформление страницы).
Распознование текста на фото и на видео в iOS 16
Текст как изображения можно получить не только со сканеров, но из любых мест (например — из печатного объявления на улице). Для этого достаточно иметь фотоаппарат или фотокамеру.
Часто извлечение текста применяется, когда нужно перевести текст с одного языка на другой язык, используя программы- переводчики текста .
Некоторые программы OCR совмещают функции извлечения текста и перевода.
Оптическое распознавание символов позволяет редактировать текст, осуществлять поиск слов или фраз, хранить текст в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь.
Обычно программы OCR хорошо справляются со своей задачей, когда текст напечатан типографским способом и составляет четкий контраст с бумагой (например. текст черного цвета на белой бумаге).
Хуже, когда текст расположен на пестром многоцветном фоне, или когда текст неразборчивый машинописный, или типографский, но очень старый. Снижает качество распознавания также смесь шрифтов, используемых в просматриваемых документах, например смесь курсивных и подчеркнутых шрифтов.
И вообще беда с распознаванием и извлечением рукописного текста. В настоящее время вряд ли найдется программа OCR, которая бы удовлетворительно выполняла эту задачу.
В данном обзоре приведены некоторые из программ по распознаванию текста.
Источник: htmleditors.ru
Как распознать текст в формате pdf
При работе с документами, отсканированными книгами и пдф файлами часто возникает необходимость их редактирования. Для этого надо распознать текст в формате pdf и конвертировать его в обычный текстовой формат. Это можно сделать несколькими способами.
Распознавание текста с картинки на Python | Оптическое распознавание символов Tesseract

Статьи по теме:
- Как распознать текст в формате pdf
- Как распознать текст
- Как распознать сканированный текст
Распознать текст PDF
Электронные документы, созданные текстовым редактором, легко распознает бесплатная программа Adobе Rеadеr. Откройте в программе нужный PDF файл, зайдите в меню «редактировать», в выпадающем окне выберите строку «копировать в буфер обмена». Создайте в «ворде» новый документ, вставьте в него из буфера обмена текс и редактируйте, затем сохраните в нужном формате.
Также конвертировать и редактировать пдф-файлы можете при помощи многофункциональной утилиты Acrobat Reader DC. Программный продукт располагает большим количеством инструментов для работы с электронными документами.
Это хорошие программы, но они не смогут распознать текст, если pdf-документы защищены от редактирования или отсканированы с бумажного носителя. В этом случае нужна специальная программа оптического распознавания символов.
Оптическое распознавание текста
Безусловным лидером является ABBYY FineReader, программа распознает и отдельные страницы, и работает в пакетном режиме. Обработанный текст можно сохранить в txt, doc, html и других форматах. Программа довольно качественно распознает текст pdf. Возможен небольшой процент неправильно распознаных символов и документу потребуется ручная доработка, результат зависит от качества сканов. У этой программы один недостаток – она платная.
Существуют и другие платные, а также бесплатные программы, позволяющие распознать и конвертировать текст из pdf в word: бесплатные – CuneiForm, Freemore OCR, FreeOCR; платные – Readiris Pro, Nitro PDF Professional.
Распознать текст онлайн
Если не каждый день преобразовываете электронные документы, просто возникла необходимость один раз поработать с форматом пдф, в этом случае нет смысла устанавливать на компьютер программу. Для таких эпизодов существуют онлайн сервисы. Также удобно пользоваться ими на работе, в путешествии, когда нет рядом компьютера с установленной программой. Онлайн сервисы позволяют распознать текст бесплатно и быстро. Вот некоторые:
— Online OCR — www.onlineocr.net
В распознавании текста онлайн много положительных моментов, но есть и минусы: на сервисе надо зарегистрироваться; не все сервисы имею функцию экспорта, надо самому распознанный текс копировать с веб-страницы; на некоторых сервисах установлен лимит на количество обрабатываемых документов; качество конечного результата зависит от скорости интернета.
Как выяснилось, распознать текст pdf несложно, существуют разные програмы, можите выбирать любую.
Совет полезен?
Статьи по теме:
- Как перевести текст со сканера
- Как из pdf извлечь текст
- Как из картинки вытащить текст
Добавить комментарий к статье
Похожие советы
Источник: www.kakprosto.ru
Информационные технологии в профессиональной деятельности
В практической деятельности часто встречаются ситуации, когда необходимо перевести в электронный вид документ, напечатанный на бумаге. В этом случае можно просто набрать документ на компьютере, что довольно трудно, либо воспользоваться сканером — устройством, специально предназначенным для перевода документов в электронный вид. Для организации сканирования изображения помимо непосредственно сканера требуется одна из специальных программ систем оптического распознавания текста.
Системы оптического распознавания текста (Optical Character Recognition — OCR-системы) предназначены для автоматического ввода печатных документов в компьютер.
Современные программы распознавания текста не только ошибаются реже, чем живой человек, но и обеспечивают проверку
орфографии, автоматическое форматирование текста и массу других дополнительных удобств.
Последние годы ведущие позиции на российском рынке ≪распознавалок≫ удерживают программы FineReader и CuneiForm.
Несмотря на свои замысловатые названия, обе программы отечественного производства вполне хорошего качества. По своим возможностям и сервису они примерно равноценны.
ВОЗМОЖНОСТИ ПРОГРАММЫ FINEREADER
Одной из популярных программ оптического распознавания текстов является программа FineReader, созданная компанией
ABBYY Software House.
FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии ≪целостного целенаправленного адаптивного распознавания≫.
Программа позволяет распознавать с высокой точностью тексты более чем на 175 языках, выводить на печать исходное изо-
бражение и распознанный текст, сохранять отсканированное изображение в различных форматах, настраивать панели инструментов программы, а также отвечает требованиям совместимости с новыми операционными системами Microsoft и Macintosh. Версия программы FineReader 6.0 Professional совместима с Windows-2000,-ХР, a FineReader 5.0 Pro for Mac предназначена для владельцев компьютеров Apple Macintosh. Кроме того, отсканированный файл можно сразу же отправить
электронным письмом или загрузить в браузер в виде Web-странички.
Программа FineReader, начиная с третьей версии, оказалась настолько удачной, что завоевала широкое признание и в России, и за ее пределами. Именно в связи с выходом на мировую арену фирма получила свое новое имя ABBYY, ранее называясь Bit Software.
Программные продукты ABBYY FineReader представлены в настоящее время следующими программами: FineReader Sprint, FineReader 6.0 Professional , FineReader 6.0 Corporate Edition и ABBYY FineReader 5.0 Pro for Mac . FineReader Sprint поставляется в комплекте со сканерами. Это продукт для тех, кто только начинает работать с системами распознавания OCR. Версия обладает ограниченной функциональностью по сравнению с версиями Professional и Corporate Edition.
FineReader 6.0 Corporate Edition разработана с учетом запросов корпоративных клиентов и поддерживает такие функции, как работа в локальной сети, пакетный поиск и индексирование, распознавание штрих-кодов и разбивка изображений. FineReader Scripting Edition позволяет создавать интегрированные решения,обладающие всеми возможностями Corporate Edition. Интерфейс программы ABBYY FineReader 5.0 Pro for Mac ,включая панели управления, пиктограммы и диалоговые окна,создавался непосредственно для Mac OS. Поддержаны все основные технологии Apple, включая QuickTime, Speech, Drag and Drop и Navigation Services. Продукт разработан компаниями ABBYY Software House и Sound
• операционная система Microsoft Windows XP/2000/NT 4.0 (SP6 или выше), Windows ME/98/95 (для работы с локализованным интерфейсом операционная система должна обеспечивать необходимую языковую поддержку);
• размер оперативной памяти для Windows XP/2000 — 64 Мбайт,Windows ME/98/95/NT 4.0 — 32 Мбайт;
• 160 Мбайт свободного места на жестком диске, включая 90 Мбайт для установки системы в минимальной конфигурации и
70 Мбайт для работы системы;
• браузер Microsoft Internet Explorer 5.0 или выше (на компакт-диске находится дистрибутив MS IE 5.5);
• 100 %-й Twain-совместимый сканер, цифровая камера или факс-модем;
• дисковод для компакт-дисков;
• дисковод 3,5 дюйма или возможность произвести активацию продукта через Интернет, по электронной почте или по телефону.
Мастер установки FineReader предельно прост — пользователю предлагается выбрать язык интерфейса, вариант установки и
каталог для файлов программы. Для инсталляции на диске должно быть свободно 90 Мбайт. Для удаления программы из компьютера имеются средства деинсталляции.
ТЕХНОЛОГИЯ РАСПОЗНАВАНИЯ
Сложность машинного распознавания текстов заключается в том, что его невозможно построить по жесткому алгоритму хотя бы потому, что для написания одной д той же буквы существует множество вариантов написания. Значит, чтобы компьютер корректно прочитал символы, он должен их ≪осмыслить≫. Иными словами, для распознавания текста требуется моделирование рассуждений человека в подобной ситуации, а это принято обозначать термином ≪искусственный интеллект≫.
Исходя из принципа целостности распознаваемое изображение рассматривается как единый объект, состоящий из частей,
связанных между собой пространственными соотношениями. По принципу целенаправленности распознавание строится как процесс выдвижения и целенаправленной проверки гипотез об объекте, а принцип адаптивности подразумевает способность системы к самообучению.
Каким образом строится распознавание символов?
Для выдвижения гипотез о том, что может представлять собой изображение, применяются так называемые признаковые классификаторы. Они используют ряд признаков, на основе которых программа вычисляет степень близости распознаваемого изображения и известных ей классов изображений, после чего выдает список подходящих классов, т. е. гипотезу о принадлежности объекта к тому или иному классу.
Кроме того, признаковые классификаторы применяются также и для повышения точности распознавания изображений с дефектами. Полученный набор классов последовательно проверяется структурным классификатором, анализирующим каждый символ. Скажем, если FineReader полагает, что на странице изображена буква ≪Ф≫, он специально проверяет те признаки, которые должны быть именно у буквы ≪Ф≫, а не у какой-либо другой, сравнивая этот символ со структурным эталоном. Структурный эталон описывает символ как комбинацию структурных элементов (отрезок,дуга, кольцо, точка), находящихся в определенных отношениях между собой. Процесс распознавания делится на этапы выделения структурных элементов в изображении и сопоставлении их с
эталоном.Если в окончательный список попало более одной гипотезы, они попарно сравниваются с помощью дифференциальных классификаторов. Если структурный классификатор при распознавании символов не может однозначно выбрать одну из двух букв с похожим написанием, то между этими конкурирующими гипотезами делается дифференциальный выбор. Например, есть две гипотезы: распознаваемый символ представляет собой строчную букву ≪твердый знак≫ или ≪мягкий знак≫. Чтобы сделать выбор, FineReader целенаправленно проанализирует левый верхний угол буквы, где имеется единственная отличительная деталь между этими буквами.
С завершением работы дифференциального классификатора заканчивается распознавание и начинается этап проверки итого-
вого списка гипотез. Окончательная стадия распознавания осуществляется системой контекста — при наличии некоторого количества распознанных букв из слова программа, используя словарь, может ≪догадаться≫, что это за слово.
Базовые принципы целостности, целенаправленности и адаптации остаются неизменными от версии к версии программы
FineReader, ведь именно они позволяют компьютеру приблизитсся к логике мышления человека.
ОРГАНИЗАЦИЯ РАБОТЫ В FINEREADER
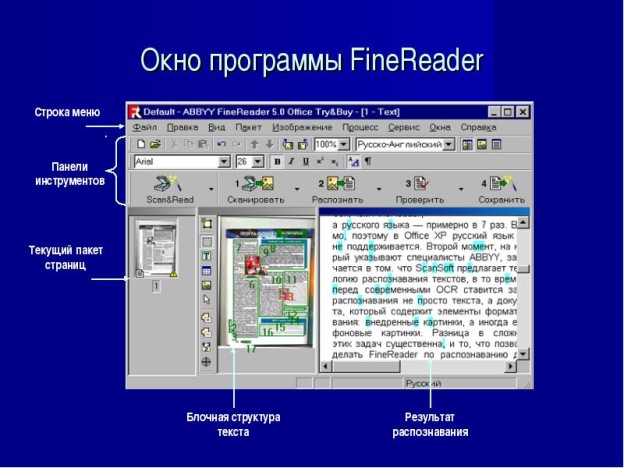
Основой работы FineReader является так называемый пакет,содержащий всю информацию о распознаваемом документе. Пакет представляет собой набор страниц документа и может содержать около тысячи страниц. В один пакет для удобства работы рекомендуется объединять изображения, логически связанные между собой, например страницы одной книги.
Пользователь импортирует в пакет изображение страниц со сканера или непосредственно из файлов графических форматов.
В окне Пакет виден список страниц, входящих в открытый пакет. Для просмотра страницы нужно щелкнуть мышью по ее
изображению или номеру, при этом откроются файлы, которыми данная страница представлена в пакете. Страницы в окне Пакет могут быть представлены пиктограммами или уменьшенным изображением страницы.
Импортированные изображения подвергаются графической обработке. Если исходное изображение представляет собой негатив, оно может быть инвертировано, далее производится очистка от ≪мусора≫ — мелких дефектов изображения. Если не нужна цветность, то цветные изображения сводятся к черно-белым, что экономит место на диске и ускоряет процесс распознавания.
Следующий шаг — анализ макета страниц пакета, т. е. выделение областей, подлежащих распознаванию. На этом этапе FineReader анализирует ориентацию страницы и переворачивает изображение, если это необходимо, а также выделяет блоки — области,которые при дальнейшем анализе будут интерпретироваться как текст, таблицы или рисунки.
После анализа макета страниц, входящих в пакет, проводится собственно распознавание текста и таблиц. Именно технология
распознавания является ≪сердцем≫ FineReader и обеспечивает ее уникальность, однако этот процесс совершенно незаметен пользователю — он видит только бегущее по тексту выделение и типовую строку состояния, указывающую, сколько информации обработано, а сколько осталось.
Далее производится проверка правописания, после чего ≪на суд≫ пользователя выносятся слова, которых нет в словаре системы, а также символы, в точности распознавания которых программа не уверена, при этом такие слова и буквы выделяютсв цветом.
Завершающий этап работы программы — сохранение и экспорт результатов распознавания. На самом деле, в сохранении
результатов нет нужды, поскольку вся информация, включая распознанный текст и его форматирование, автоматически сохраняются в пакете вместе с исходным изображением и сведениями о макете страниц. Пользователь может просто закрыть FineReader, не опасаясь потери данных, однако отдельно сохраненный текст можно импортировать в различные форматы для дальнейшей работы с ним в других приложениях.
Это интересно
Каждый из описанных шагов — импорт изображений, анализ документа и распознавание, проверка орфографии и сохранение результатов — представлены кнопками в панели инструментов программы, что значительно упрощает работу.
Источник: itpd06.blogspot.com