
Этот калькулятор определяет длину волны звуковых колебаний (только звуковых!), если известны их частота и скорость распространения звука в среде. Он также может рассчитать частоту, если известны длина волны и скорость или скорость звука, если известны частота и длина волны.
Пример: Рассчитать длину звуковой волны, распространяющейся в морской воде от гидроакустического преобразователя с частотой 50 кГц, если известно, что скорость звука в соленой воде равна 1530 м/с.
f
Длина волны
λ
Скорость звука
v
Поделиться ссылкой на этот калькулятор, включая входные параметры
Для расчета выберите среду или введите скорость звука, затем введите частоту и нажмите кнопку Рассчитать для расчета длины волны. Можно также ввести длину волны и рассчитать частоту.
Определения и формулы
Звук — это волновой процесс. Если струна скрипки или арфы колеблется, в окружающем ее воздуха образуются зоны сжатия и разрежения, которые и представляют собой звук. Эти зоны сжатия и разрежения перемещаются по воздуху в форме продольных волн, которые имеют ту же частоту, что и источник звука. В продольных волнах молекулы воздуха движутся параллельно движению волны.
Тест на Самый Острый Слух в Мире
Воздух сжимается в том же направлении, в котором распространяются звуковые волны. Эти волны передают энергию голоса или колеблющейся струны. Отметим, что воздух не перемещается, когда звуковая волна проходит через него. Перемещаются только колебания, то есть зоны сжатия и разрежения. Более громкие звуки получаются при более сильных сжатиях и разрежениях.

Спектр звуковых колебаний. 1 — землетрясения, молнии и обнаружение ядерных взрывов; 2 — акустический диапазон; 3 — Слух животных; 4, Ультразвуковая очистка; 5. Терапевтическое применение ультразвука; 6 — Неразрушающий контроль и медицинская ультразвуковая диагностика; 7 — Акустическая микроскопия; 8 — Инфразвук; 9 — Слышимый диапазон; 10 — Ультразвук
Количество этих колебаний в секунду называется частотой и измеряется в герцах. Период колебаний — это длительность одного цикла колебаний, измеренная в секундах. Длина волны — это расстояние между двумя соседними повторяющимися зонами волнового процесса. Если предположить, что скорость распространения волны в среде постоянная, то длина волны обратно пропорциональна частоте.
При 20 °C звук распространяется в сухом воздухе со скоростью около 343 метра в секунду или 1 километр приблизительно за 3 секунды. Звук распространяется быстрее в жидкостях и еще быстрее в твердых телах. Например, в воде звук распространяется в 4,3 раза быстрее, чем в воздухе, в стекле — в 13 раз и в алмазе в 35 раз быстрее, чем в воздухе.
Тест на проверку слуха. Какому возрасту соответствует ваш слух
Хотя звуковые волны и морские волны движутся намного медленнее электромагнитных волн, уравнение, описывающее их движение будет одинаковым для всех трех типов волн:
f — частота волны,
v — скорость распространения волны и
λ — длина волны
Продольные и поперечные волны
В различных средах звук распространяется в виде различных видов волн. В жидкостях и газах звук распространяется в виде продольных волн. В твердых телах звук может распространяться как в виде продольных, так и в виде поперечных волн.
Для лучшего понимания обоих типов волн удобно воспользоваться механическим аналогом, которым послужит пружина Слинки. Эта пружина представляет собой модель среды (жидкости или газа). Если ее растянуть, а затем сжимать, а затем отпускать один конец, сжатие в форме волны перемещается вперед, передавая таким образом энергию с одного конца пружины в другой. Если звук распространяется в жидкости или газе, он идет от источника в форме периодических сжатий и разрежений газа или жидкости, которые перемещаются от источника звука.
Конвертируйте музыку с частотой 440 Гц в 432 Гц с помощью Audacity

Если вы поищите в Google или YouTube информацию о частоте 432 Гц, вы найдете несколько демонстраций эффекты Que Cette fréquence имеет на здоровье экстрасенс и телосложение слушателя.
Прежде чем стандартизировать fréquence из 440hz музыканты использовали каждый свой частота, причина, по которой международная организация закрепилась на частоте 440hz по их мнению, последнее более ясно, но имеет нежелательные последствия для психическое здоровье.
Лично я слушаю частоту 432hz все время, даже Windows я использую конвертер частота в реальном времени ан utilisant Эквалайзер APO.
В этом руководстве вы узнаете, как использовать дерзость (Бесплатно) это программное обеспечение, разработанное Google к трансформатор et изменять любая музыка (mp3, wav, m4a, flac, . ) 440hz en 432 Гц.
Преобразование музыки 440 Гц в 432 Гц
Влияние частоты 432 Гц на тело и психическое здоровье
La музыка на частоте 432 Гц увеличивает восприятие, повышает ясность ума человека и разблокировать интуицию. Как правило, эта частота оказалась исцеляющей, поскольку она уменьшает тревогу, снижает частоту сердечных сокращений и кровяное давление.
Вы можете найти больше на YouTube, выполнив поиск: 440 Гц против 432 Гц

Как узнать, какая песня в 440 или 432 Гц?
Существует очень полезный инструмент для определения частоты, который называется «Хроматический тюнер», лично я купил его у японского продавца на eBay (ХРОМАТИЧЕСКИЙ ТЮНЕР KORG CA-50).
Вот как это работает:

Короче говоря, я устанавливаю частоту, которую хочу обнаружить, затем внутренний Micro подхватывает частоту и дает мне зеленый светодиод. (с центральной иглой) когда частота музыки»матч»Заданная частота.
Использование Audacity для преобразования песни 440 Гц в 432 Гц
Вы можете попробовать это руководство на любой музыке, доступной на YouTube en 440 Гц. Вы также можете искать уже преобразованные песни, чтобы проверить частоту, прежде чем конвертировать свои собственные песни.

Начните с загрузки музыки в формате MP3 с YouTube с помощью онлайн-сайта загрузки MP3.
Скачать дерзость затем установите его. (вот официальная ссылка)
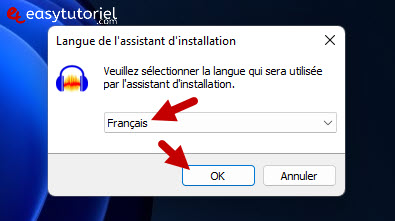
Программное обеспечение полностью поддерживает французский язык.
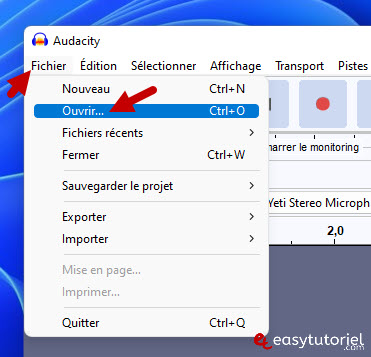
Давайте начнем с импорта аудиофайла, перейдя в «Файл»>»открытый»
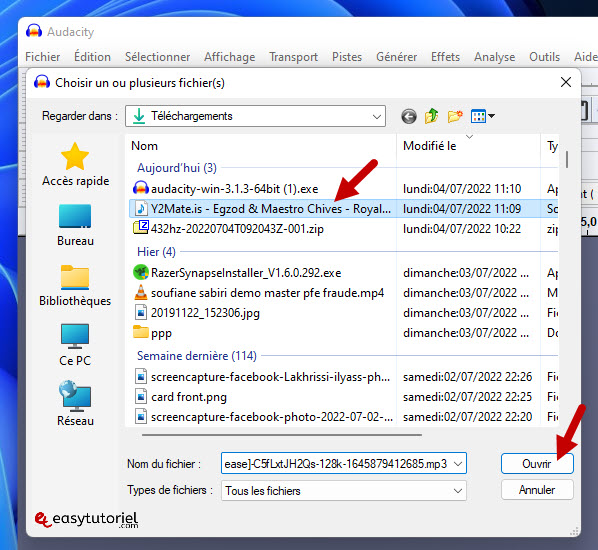
Выберите аудиофайл (mp3, m4a, wav, . ) затем нажмите «открытый»
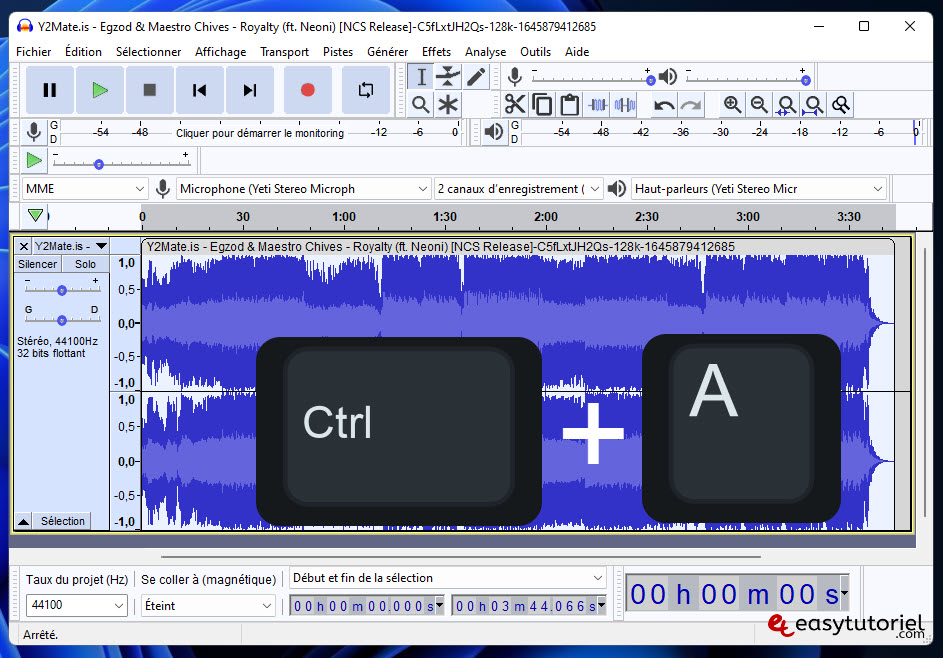
пресс CTRL + A чтобы выделить всю звуковую дорожку.
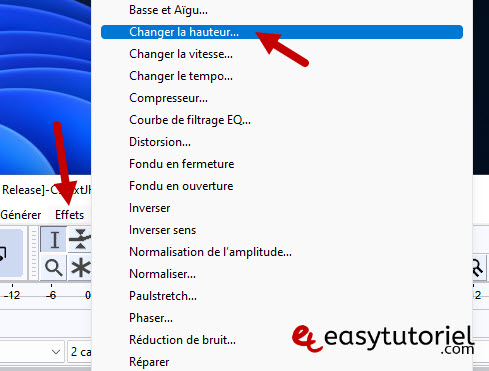
Затем перейдите к «эффекты»Puis Cliquez сюр»Изменить высоту. » (Изменить высоту тона)
Вставить «от»> 440
И вставить «К»> 432
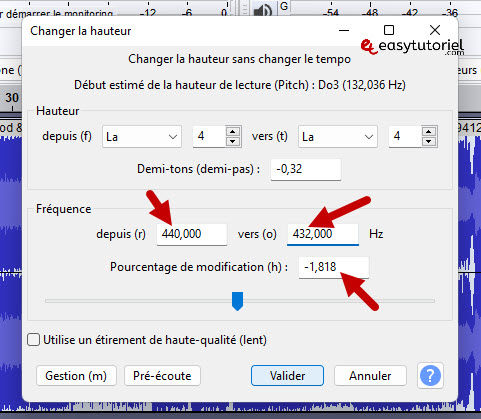
Вы должны иметь «Процентное изменение»Из -1,818
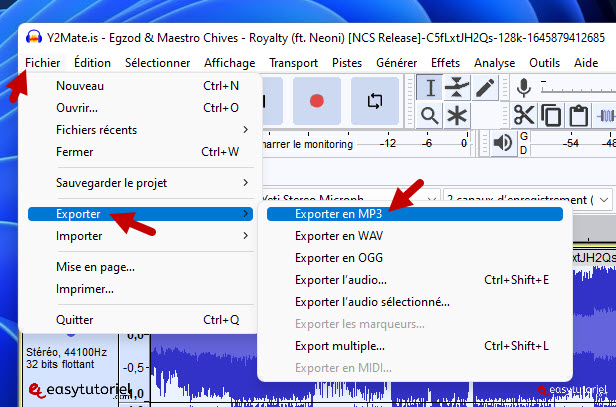
Нажмите на «Файл»>»Экспортер»>»Экспорт в MP3″
Преобразование нескольких песен в формат 432 Гц с помощью макроса Audacity
Чтобы конвертировать несколько файлов одновременно, мы будем использовать функциональность макросов. Audacity предлагает эту возможность, чтобы облегчить конвертацию и обработку данных значительного размера, что сводит к минимуму время и максимизирует производительность.
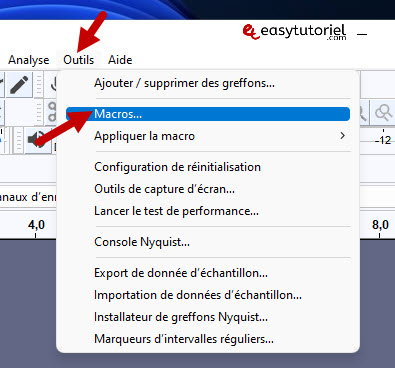
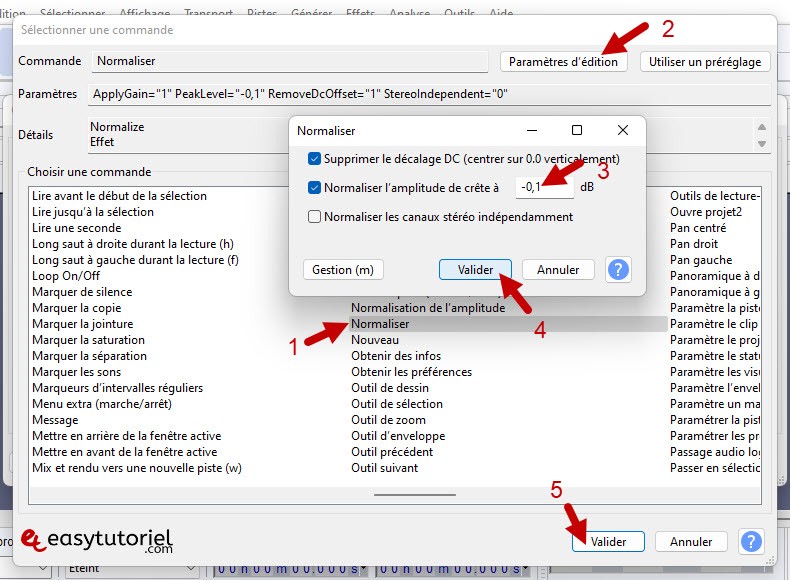
Нажмите на «Outils»>»Макрос»
Создать новый Макрос нажав на «Модерн»
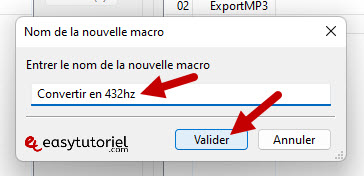
Введите имя для нового макроса, затем нажмите «Представлять»
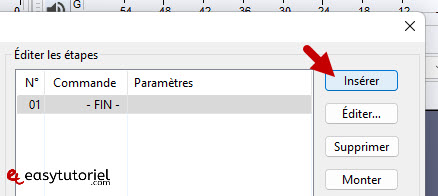
Нажмите на «вставить»
Выбирать «Скользкая растяжка»Puis Cliquez сюр»Изменить настройки»
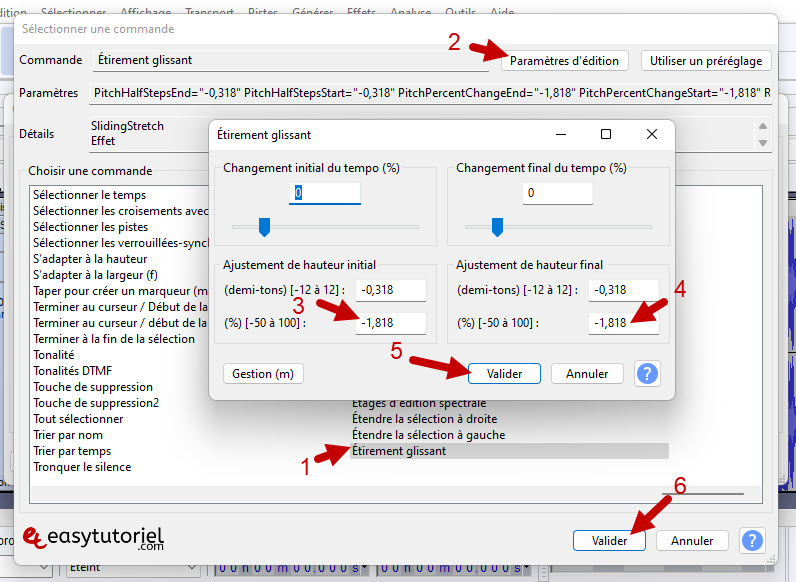
Поместите в текстовое поле внизу значения «-1.818″Puis Cliquez сюр»Представлять» дважды.
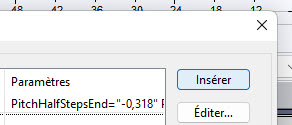
Затем нажмите «вставить»добавить»Нормализовать» (произносится как нормализатор)
Выберите «Нормализовать»Puis Cliquez сюр»Изменить настройки» затем введите значение «-0.1 ДБ»
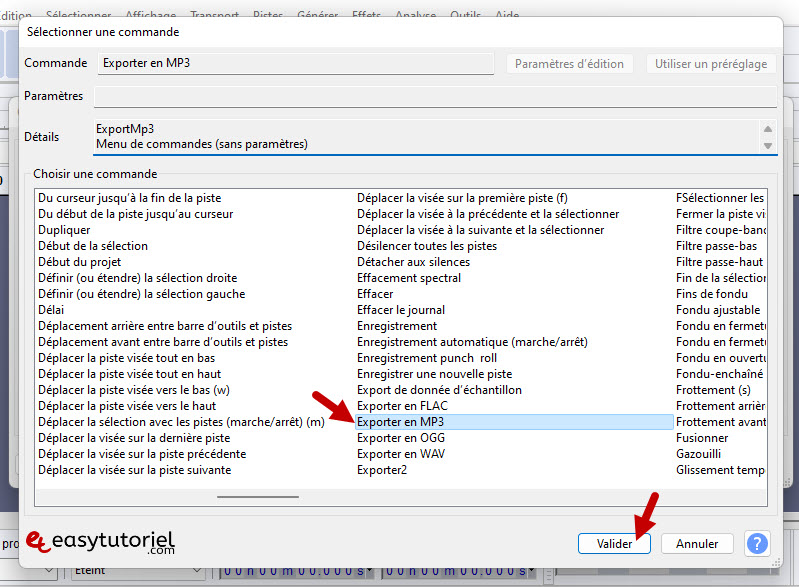
Наконец вставьте команду «Экспорт в MP3″Puis Cliquez сюр»Представлять»
Нажмите на «экономить», чтобы сохранить новый макрос, который вы только что создали.
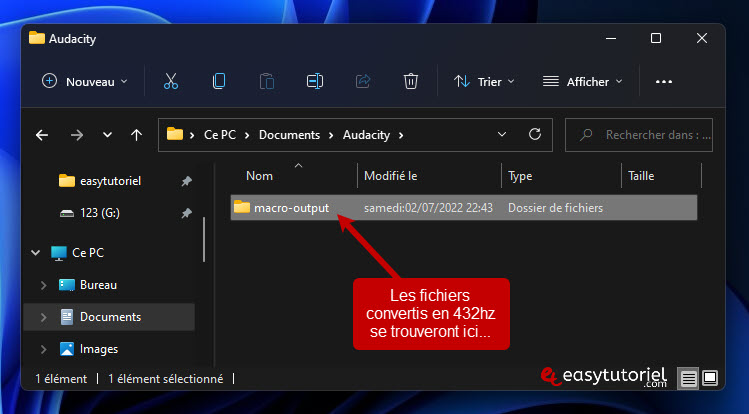
Чтобы преобразовать MP3 или любой поддерживаемый аудиофайл, просто выберите «Макрос».Преобразовать в 432 Гц»Puis Cliquez сюр»Файлы. «
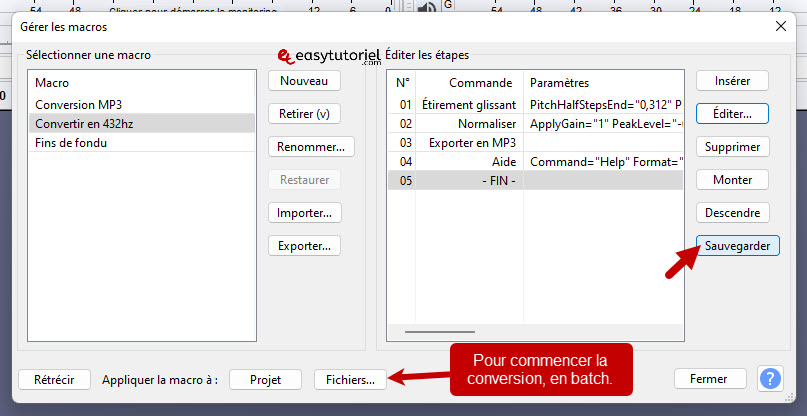
Преобразованные файлы будут находиться по следующему пути:
C:UsersNOM_UTILISATEURDocumentsAudacitymacro-output
Бонус: что произойдет, если мы преобразуем 432 Гц в 432 Гц?
Я сделал математику, чтобы перейти от 440 Гц к 432 Гц, мы вычтем 8 Гц, и если мы преобразуем песню 432 Гц обратно в 432 Гц, мы получим частоту 424 Гц (432 — 8 = 424 Гц), что тоже хорошо.
Не конвертируйте 424гц, это предел хорошей частоты. Но 432 Гц — это собственная частота. Частота Вселенной.
Заключение
Если вы страдаете каким-либо психическим или психологическим заболеванием, послушайте музыку в режиме 432 Гц, на YouTube есть несколько других аудиозаписей под ключевым словом бинауральные ритмы, которые могут помочь вам облегчить и вылечить несколько болезней, но поддерживайте связь со своим врачом и говорите им. об этом открытии, чтобы узнать, что они думают об этом.

Вам понравился этот урок? Не стесняйтесь оставлять комментарии поддержки

Спасибо, что прочитали и поделились.
Источник: www.easytutoriel.com
Pitch-tracking, или определение частоты основного тона в речи, на примерах алгоритмов Praat, YAAPT и YIN

В сфере распознавания эмоций голос – второй по важности после лица источник эмоциональных данных. Голос можно охарактеризовать по нескольким параметрам. Высота голоса – одна из основных таких характеристик, однако в сфере акустических технологий корректнее называть этот параметр частотой основного тона.
Частота основного тона имеет непосредственное отношение к тому, что мы называем интонацией. А интонация, например, связана с эмоционально-экспрессивными характеристиками голоса.
Тем не менее, определение частоты основного тона является не совсем тривиальной задачей с интересными нюансами. В этой статье мы обсудим особенности алгоритмов для ее определения и сравним существующие решения на примерах конкретных аудиозаписей.
Введение
Для начала вспомним, чем, по сути, является частота основного тона и в каких задачах она может понадобиться. Частота основного тона, которую еще обозначают как ЧОТ, Fundamental Frequency или F0 – это частота колебания голосовых связок при произнесении тоновых звуков (voiced). При произнесении нетоновых звуков (unvoiced), например говорении шепотом или произнесении шипящих и свистящих звуков, связки не колеблются, а значит эта характеристика для них не релевантна.
* Обратите внимание, что деление на тоновые и не тоновые звуки не эквивалентно делению на гласные и согласные.
Вариабельность частоты основного тона довольно велика, причем она может сильно отличаться не только между людьми (для более низких в среднем мужских голосов частота составляет 70-200 Гц, а для женских может достигать 400 Гц), но и для одного человека, особенно в эмоциональной речи.
Определение частоты основного тона применяется для решения широкого спектра задач:
- Распознавание эмоций, как мы уже сказали выше;
- Определение пола;
- При решении задачи сегментации аудио с несколькими голосами или разделения речи на фразы;
- В медицине для определения патологических характеристик голоса (например, с помощью акустических параметров Jitter and Shimmer). Например, определение признаков заболевания Паркинсона [1]. Jitter and Shimmer также могут быть использованы для распознавания эмоций [2].
Кстати, помните историю про Laurel и Yanny? Различия в том, какие слова слышат люди при прослушивании одной и той же аудиозаписи, возникли как раз из-за разницы в восприятии F0, на которую влияют много факторов: возраст слушающего, степень усталости, устройство воспроизведения.
Так, при прослушивании записи в колонках с качественным воспроизведением низких частот, вы будете слышать Laurel, а в аудиосистемах, где низкие частоты воспроизводятся плохо, Yanny. Эффект перехода можно заметить и на одном устройстве, например здесь. А в этой статье в качестве слушателя выступает нейросеть. В другой статье можно почитать, как объясняется феномен Yanny/Laurel с позиций речеобразования.
Поскольку подробный разбор всех методов определения F0 был бы чересчур объемным, статья носит обзорный характер и может помочь сориентироваться в теме.
Методы определения F0
Методы определения F0 можно разделить на три категории: основанные на временной динамике сигнала, или time-domain; основанные на частотной структуре, или frequency-domain, а также комбинированные методы. Предлагаем ознакомиться с обзорной статьей по теме, где подробно разбираются обозначенные методы выделения F0.
Отметим, что любой из обсуждаемых алгоритмов состоит из 3 основных шагов:
Препроцессинг (фильтрация сигнала, разделение его на фреймы)
Поиск возможных значений F0 (кандидатов)
Трекинг — выбор наиболее вероятной траектории F0 (поскольку для каждого момента времени мы имеем несколько конкурирующих кандидатов, нам необходимо найти среди них наиболее вероятный трек)
Очертим несколько общих моментов. Перед применением методов time-domain сигнал предварительно фильтруют, оставляя только низкие частоты. Задаются пороги – минимальная и максимальная частоты, например от 75 до 500 Гц. Определение F0 производится только для участков с гармонической речью, поскольку для пауз или шумовых звуков это не только бессмысленно, но и может внести ошибки в соседние фреймы при применении интерполяции и/или сглаживании. Длину фрейма выбирают так, чтобы в ней содержалось как минимум три периода.
Основной метод, на базе которого впоследствии появилось целое семейство алгоритмов – автокорреляционный. Подход достаточно прост — необходимо рассчитать автокорреляционную функцию и взять ее первый максимум. Он и будет отображать самую выраженную частотную компоненту в сигнале.
В чем может быть сложность в случае использования автокорреляции и почему далеко не всегда первый максимум будет соответствовать нужной частоте? Даже в близких к идеальным условиям на записях высокого качества метод может ошибаться из-за сложной структуры сигнала. В условиях близких к реальным, где помимо прочего мы можем столкнуться с исчезновением нужного пика на шумных записях или записях изначально низкого качества, число ошибок резко возрастает.
Несмотря на ошибки, автокорреляционный метод довольно удобен и привлекателен своей базовой простотой и логичностью, поэтому именно он взят за основу во многих алгоритмах, в том числе в YIN (Инь). Даже само название алгоритма отсылает нас к балансу между удобством и неточностью метода автокорреляции: “The name YIN from ‘‘yin’’ and ‘‘yang’’ of oriental philosophy alludes to the interplay between autocorrelation and cancellation that it involves.” [4]
Создатели YIN попытались исправить слабые места автокорреляционного подхода. Первое изменение – использование функции Cumulative Mean Normalized Difference, которая должна снизить чувствительность к амплитудным модуляциям, сделать пики более явными:
begin
d’_t(tau)=
begin
1, text
end
end
Также YIN пытается избежать ошибок, возникающих в случаях, когда длина оконной функции не делится нацело на период колебания. Для этого используется параболическая интерполяция минимума. На последнем шаге обработки аудиосигнала выполняется функция Best Local Estimate для предотвращения резких скачков значений (хорошо это или плохо – вопрос спорный).
Frequency-domain
Если говорить о частотной области, то на первый план выходит гармоническая структура сигнала, то есть наличие спектральных пиков на частотах, кратных F0. “Свернуть” этот периодический паттерн в явный пик можно при помощи кепстрального анализа. Кепстр — преобразование Фурье от логарифма спектра мощности; кепстральный пик соответствует наиболее периодической компоненте спектра (про него можно почитать здесь и здесь).
Гибридные методы определения F0
Следующий алгоритм, на котором стоит остановиться поподробнее, имеет говорящее название YAAPT — Yet Another Algorithm of Pitch Tracking — и фактически является гибридным, потому что использует как частотную, так и временную информацию. Полное описание есть в статье, здесь мы опишем только основные этапы.

Рисунок 1. Схема алгоритма YAAPTalgo (ссылка).
YAAPT состоит из нескольких основных этапов, первым из которых является препроцессинг. На этом этапе значения изначального сигнала возводят в квадрат, получают вторую версию сигнала. Этот шаг преследует ту же цель, что и Cumulative Mean Normalized Difference Function в YIN – усиление и восстановление “затертых” пиков автокорреляции. Обе версии сигнала фильтруют — обычно берут диапазон 50-1500 Гц, иногда 50-900 Гц.
Затем по спектру преобразованного сигнала рассчитывается базовая траектория F0. Кандидаты на F0 определяются с помощью функции Spectral Harmonics Correlation (SHC).
begin
SHC(t,f) = sumlimits_^ prodlimits_^S(t,rf+f’)
end
где S(t,f) — магнитудный спектр для фрейма t и частоты f, WL — длина окна в Гц, NH — число гармоник (авторы рекомендуют использовать первые три гармоники). Также по спектральной мощности происходит определение фреймов voiced-unvoiced, после чего ищется наиболее оптимальная траектория, при этом учитывается возможность pitch doubling/pitch halving [3, Section II, C].
Далее, как для изначального сигнала, так и для преобразованного производится определение кандидатов на F0, и вместо автокорреляционной функции здесь используется Normalized Cross Correlation (NCCF).
begin
NCCF(m) = frac<sumlimits_^ x(n)*x(n+m)><sqrt<sumlimits_^ x^2(n) * sumlimits_^ x^2(n+m)>>text hspace 0 < m < M_
end
Следующий этап — оценка всех возможных кандидатов и вычисление их значимости, или веса (merit). Вес кандидатов, полученных по аудио сигналу, зависит не только от амплитуды пика NCCF, но и от их близости к траектории F0, определенной по спектру. То есть частотный домен считается хоть и грубым в плане точности, но зато устойчивым [3, Section II, D].
Затем для всех пар оставшихся кандидатов рассчитывается матрица Transition Cost — цены перехода, по которой в итоге и находят оптимальную траекторию [3, Section II, E].
Теперь применим все вышеописанные алгоритмы к конкретным аудиозаписям. В качестве отправной точки будем использовать Praat — инструмент, который является основным для многих исследователей речи. А затем на Python посмотрим реализацию YIN и YAAPT и сравним полученные результаты.
В качестве аудио-материала можно использовать любые доступные аудио. Мы взяли несколько отрывков из нашей базы RAMAS — мультимодального датасета, созданного при участии актеров ВГИК. Можно также воспользоваться материалом из других открытых баз, например LibriSpeech или RAVDESS.
Для наглядного примера мы взяли отрывки из нескольких записей с мужским и женским голосами, как нейтральными, так и эмоционально-окрашенными, и для наглядности соединили их в одну запись. Посмотрим на наш сигнал, его спектрограмму, интенсивность (оранжевый цвет), и F0 (синий цвет). В Praat это можно сделать при помощи Ctrl+O (Open — Read from file) и затем кнопки View Edit) получившийся файл Pitch. Видно, что помимо выбранной траектории были еще довольно значимые кандидаты с частотой ниже.
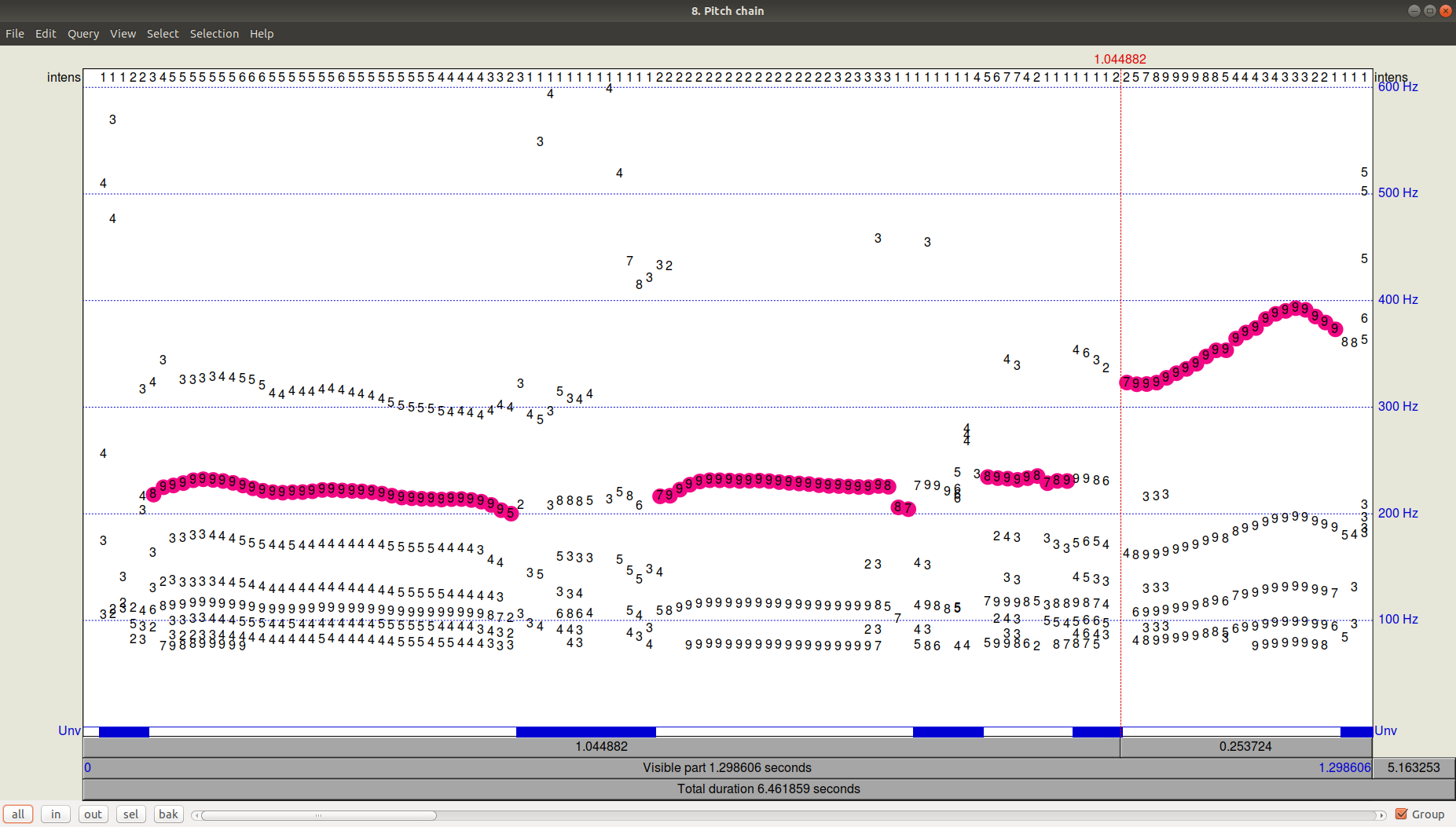
Рисунок 3. PitchPath для первых 1,3 секунд аудиозаписи.
А что же в Python?
Возьмем две библиотеки, предлагающих питч-трекинг – aubio, в которой алгоритмом по умолчанию является YIN, и библиотеку AMFM_decompsition, в которой есть реализация алгоритма YAAPT. В отдельный файл (файл PraatPitch.txt) вставим значения F0 из Praat (это можно сделать вручную: выбрать звуковой файл, нажать View yin», win_s, hop_s, samplerate) pitch_o.set_unit(«midi») pitch_o.set_tolerance(tolerance) pitchesYIN = [] confidences = [] total_frames = 0 while True: samples, read = s() pitch = pitch_o(samples)[0] pitch = int(round(pitch)) confidence = pitch_o.get_confidence() pitchesYIN += [pitch] confidences += [confidence] total_frames += read if read < hop_s: break # load PRAAT pitches praat = np.genfromtxt(‘/home/eva/Documents/papers/habr/PraatPitch.txt’, filling_values=0) praat = praat[:,1] # plot fig, (ax1,ax2,ax3) = plt.subplots(3, 1, sharex=True, sharey=True, figsize=(12, 8)) ax1.plot(np.asarray(pitchesYIN), label=’YIN’, color=’green’) ax1.legend(loc=»upper right») ax2.plot(pitchY.samp_values, label=’YAAPT’, color=’blue’) ax2.legend(loc=»upper right») ax3.plot(praat, label=’Praat’, color=’red’) ax3.legend(loc=»upper right») plt.show()

Рисунок 4. Сравнение работы алгоритмов YIN, YAAPT и Praat.