
В настоящее время к статистическому программному обеспечению принято относить пакеты программ статистического анализа общего и специального назначения, пакеты программ табулирования, пакеты программ редактирования, пакеты программ управления данными, пакеты программ для выборочных обследований, а также многие графические пакеты, пакеты эконометрического моделирования и прогнозирования, имитационного моделирования, распознания изображений и т.д.
Появление персонального компьютера третьего поколения послужило базой для создания сложных пакетов программ статистического анализа, и в настоящее время существует около тысячи статистических пакетов, универсальных или ориентированных на использование в каких-либо специальных областях, и число их продолжает расти.
Конструкция пакетов статистического анализа зависит в значительной степени от типа используемого персонального компьютера, его конфигурации, оперативной системы, а также от уровня подготовки пользователя пакета в области программирования для персонального компьютера.
Все, что нужно знать о профессии аналитика данных
Основным требованием, предъявляемым к организации решения задач экономики и управления, научных, социологических и других задач, является минимизация ресурсов, потребляемых для достижения поставленной цели. В зависимости от характера задачи на объём потребляемых ресурсов оказывают влияние временные и стоимостные ограничения. Соблюдению этих ограничений может в значительной степени способствовать использование персонального компьютера на всех или отдельных этапах решения задачи.
Эффективность автоматизации решения задачи может проявляться как в сокращении расходов на обработку информации (прямая эффективность), так и в улучшении функционирования управляемого объекта (косвенная эффективность) за счёт таких факторов, как повышение достоверности и сокращение времени обработки информации, что позволяет более обоснованные и качественные решения. Применение персонального компьютера является предпосылкой реализации принципа новых задач, развития новых способов исследования, проникновения в сущность социально-экономических процессов, и это оказывает влияние на оценку важности критериев выбора между ручными способами обработки данных и способами и использованием персонального компьютера.
При обработке статистических данных обычно используются одинаковые или в значительной степени сходные по своей мощности и разнообразию технические средства, программное обеспечение и режимы обработки данных. Подключение к мощным базовым персональным компьютерам с развитыми операционными системами разнообразных периферийных устройств, включая средства дистанционной передачи данных, оптические считывающие/записывающие устройства, графические дисплеи, графопостроители, средства вывода на микрофильм, позволяет обрабатывать данные в пакетном и интерактивном режимах с прямым доступом к рабочим и постоянным файлам и выводом результатов на различные носители в соответствии с разнообразными требованиями пользователей, а также создаёт предпосылки для реализации интегрированных систем обработки статистических данных.
Что такое базы данных? ДЛЯ НОВИЧКОВ / Про IT / Geekbrains
Социологические исследования являются сложной деятельностью, которая нередко осуществляется на протяжении длительного промежутка времени, в географически отдалённых друг от друга местах, с привлечением большого числа специалистов, с использованием различных методик сбора и обработки данных. Это требует применения к планированию и контролю за его проведением программного обеспечения сетевого планирования и управления, а также других средств автоматизации.
Новые типы вычислительной техники, и прежде всего персональные компьютеры (ПК), позволяют проводить оперативный и более тонкий анализ информации. Теперь диалог специалиста в конкретной области с вычислительной машиной может проходить без посредничества программиста и операторов.
Новые графические средства обеспечивают наглядное представление результатов применения различных методов, что значительно облегчает их восприятие. Однако для реализации преимуществ ПК необходимо специальное программное обеспечение. Практика показывает, что адаптация пакетов программ, созданных для больших ЭВМ, на ПК (SPSS, BMDP, SPAD) не обладает должным уровнем «дружелюбия».
Использование таких продуктов требует долгого обучения и солидной подготовки в области математической статистики. При этом следует отметить, что несмотря на широту имеющихся методов и программ, относительно слабо продвинут предварительный анализ данных. Между тем, специфика социологических данных (неоднородность, зависимость наблюдений друг от друга и от времени, обилие качественных признаков) в первую очередь требует его применения. Имеются в виду методы, не опирающиеся на вероятностные предположения о природе данных, например детерминационный анализ и анализ соответствий, которые в отличие от классических методов математической статистики дают результаты, относящиеся к выборке, а не к генеральной совокупности. Их можно эффективно использовать как на предварительном этапе изучения данных (для выявления аномальных наблюдений и возможных кластеров), так и для интерпретации результатов моделирования.
Кроме того, отсутствует адекватное статистическое и программное обеспечение анализа динамики качественных показателей, который особенно актуален в связи с проводимыми в последнее время лонгитюдными обследованиями.
Эти соображения легли в основу развития некоторых методов и создания Системы анализа нечисловой информации (САНИ).
Система анализа нечисловой информации предназначена для обработки данных, измеренных в разнородных шкалах: номинальной, порядковой, интервальной и количественной. В первую очередь она ориентирована на социально-экономические задачи, но может использоваться в биологии, медицине, других областях, где приходится иметь дело с нечисловой информацией.
САНИ реализована на совместимых с IBM персональных компьютерах и требует около 1 МБайта памяти на жестком диске. Она предполагает лишь элементарное знакомство пользователя с ПК. Работа осуществляется в диалоговом режиме с помощью иерархического меню или непосредственно нажатием определенных комбинаций клавиш.
Система позволяет одновременно обрабатывать до 320 признаков (вопросов); число объектов (респондентов) не должно превосходить 32000 для категоризованного признака и 8000 – для числового. Однако приведенные ограничения, имеют чисто технический характер, и допустимый объем данных зависит от используемого метода и типа компьютера.
В любой момент доступны: справка об используемом методе со ссылкой на литературу или разъяснение сложившейся ситуации; справки обо всех активных переменных, содержащие информацию, полученную от пользователя при первом вводе, и некоторые результаты проделанного анализа; данные об объектах (соответствующие значения переменных). Результаты анализа выводятся на экран и могут быть распечатаны или скопированы в файл для последующего включения в отчет.
Функциональное наполнение. Методы, используемые САНИ, распадаются на три группы. Первая — реализует возможности базы данных, вторая – объединяет средства предварительного анализа, позволяющие сформировать гипотезы о структуре данных, выявить «выбросы». При этом эффективно применяются графические возможности современной вычислительной техники.
Методы, входящие в третью группу, используют вероятностные предположения о природе данных и позволяют проверять различные гипотезы. Особое внимание уделено анализу нечисловых признаков, изменяющихся во времени.
Работа с данными. Они могут быть введены вручную, импортированы из прямоугольных таблиц «объект-признак» или «признак-объект» в кодах ASCII или из общего статистического пакета SYSTAT. Имеется возможность экспортировать данные в виде таблиц ASCII или в системном формате SYSTAT.
В системе «САНИ» каждому признаку соответствует справка, содержащая сведения о шкале, в которой он измерен, код и число пропущенных значений, имена и частоты категорий, историю создания и комментарии пользователя. Кроме того, в справке хранятся некоторые результаты предыдущей обработки: имена независимых и тесно связанных с данной переменных. Они предостерегают исследователя от мало осмысленных шагов, например от использования независимых переменных в анализе соответствий.
Имеется возможность получать подвыборки: отбирать или удалять объекты с фиксированной комбинацией значений переменных. Можно создавать новые переменные в виде фиксированных комбинаций значений имеющихся переменных, агрегированием категорий, разбиением количественных переменных на интервалы, всевозможными комбинациями двух переменных (для снижения размерности). Все преобразования фиксируются в справках. Мощный редактор позволяет вводить и проверять данные вручную, а также изменять имя, комментарий, шкалу и значения переменных.
Программное обеспечение IP Sociologist 2.03-3.05 – профессиональное программное обеспечение для обработки и анализа данных социологических и маркетинговых исследований.
Представляет собой клиент-серверный продукт, ориентированный на использование в исследовательских центрах и маркетинговых отделах предприятий. Устанавливается только серверное программное обеспечение, после чего на всех (количество сетевых рабочих мест не ограничивается лицензией) рабочих станциях в пределах локальной сети предприятия возможен графический ввод без установки дополнительного программного обеспечения на клиентские машины.
Преимуществом данной программы являются большие возможности анализа и интуитивно понятный интерфейс как оператора, так и социолога. Все операции максимально визуализированы, реализованы с помощью удобного графического интерфейса и не требуют глубокого понимания их статистической сущности.
- Контекстное CDD-взвешивание (Pro);
- Детерминационный анализ (Pro);
- Произвольное расширение выборки по признаку (Pro);
- Расчет распределения Хи-квадрат (Standard, Pro);
- Расчет коэффициентов Крамера и Чупрова (Standard, Pro);
- Расчет коэффициента корреляции Пирсона (Standard, Pro);
- Расчет коэффициента корреляции Пирсона для ранговых признаков с использованием явных рангов (Standard, Pro);
- Экспорт данных в MS Excel и текст, разделенный табуляциями;
- 6 типов вопросов (номинальная и ранговая шкала – одиночный выбор, номинальная шкала с совместимыми альтернативами – множественных выбор, количественная шкала, таблица номинальных признаков, таблица номинальных признаков с совместимыми альтернативами – таблица с множественным выбором, таблица метрических признаков);
- Анализ произвольного количества двумерных зависимостей ответов на один вопрос в зависимости от ответов на другой, как в текстовой форме, так и в виде диаграмм MS Excel;
- Построение трехмерных диаграмм зависимости одного фактора от 2-х других;
- Графический ввод с неограниченного количества компьютеров в пределах одного сегмента ЛВС предприятия с помощью интуитивно понятного интерфейса MS Internet Explorer или Opera;
- Повопросный и поанкетный ввод с возможностью условных запретов;
- Просмотр и редактирование уже введенных анкет с помощью графического интерфейса;
- Возможность задания множественного фильтра анкет и вывод с его учетом отчета (работа в произвольном контексте);
- Работу с отдельными сессиями повопросного (в том числе и множественного) и поанкетного ввода анкет и формирование отчета по каждой из них (например, по каждому интервьюеру);
- Расчет частот и процентов для номинальных вопросов; мат. ожидания, стд. отклонения, вариации, ошибки среднего, минимума, максимума — для метрических признаков по каждой проекции;
- Выдачу отчетов в формате HTML, пригодном как для печати, так и для публикаций в сети Интернет;
- Выдача отчетов в Word;
- Подготовка и передача анкеты в Word;
- Работа с базой стандартных вопросов (репозиторием);
- Работа с несколькими социологическими исследованиями одновременно.
Программа Vortex предназначена для разработки инструментария сбора данных (анкеты, бланка интервью, теста, html-формы и т.п.), ввода, обработки и анализа информации, представления полученных результатов в виде таблиц, текстов и диаграмм с возможностью их переноса в другие приложения.
Области применения: любые исследования связанные с опросами населения, сотрудников или экспертов, анализ данных наблюдений, статистики.
Социологические исследования: комплекс наиболее востребованных процедур обработки и анализа количественных социологических данных, в том числе:
- расчет объема выборки и определение ошибки репрезентативности;
- экстраполяция данных на генеральную совокупность;
- обработка вопросов с множественным выбором, открытых и полузакрытых вопросов;
- обработка табличных вопросов, ранговых методик и полярных профилей;
- множество методик разработки вторичных показателей;
- одномерный, двухмерный и многомерный частотный анализ;
- регрессионный, кластерный, детерминационный и другие виды многомерного анализа.
Политические исследования: оценка и прогнозирование электоральной активности и политических предпочтений, выявление факторов влияющих на политическое поведение, разработка типологий политического поведения, сегментация электората по актуальным проблемам и информационным источникам.
Социально-психологические исследования: обработка данных, полученных в ходе опроса, наблюдения или тестирования сотрудников организации, оценка социально-психологического климата, неформальной структуры группы.
Социально-медицинские исследования: обработка данных, полученных в ходе опроса пациентов, наблюдения или оценки результатов анализов.
Конструирование и обработка данных психологических тестов:
- стандартизация тестов для различных групп испытуемых;
- оценка дискриминативности исходных и объективных показателей;
- расчет результатов тестирования;
- определение процентилей и СТЭНов.
Источник: studfile.net
Основные инструменты для работы с данными: от сбора до анализа
История просмотров в интернете, список задач на день, подписчики в социальных сетях и даже селфи в телефоне — это данные, которые мы создаём, храним и которыми иногда делимся с другими, чтобы рассказать о себе.
Ключевая задача анализа данных в бизнесе — автоматизировать процессы и помочь найти правильные решения на основе данных. Чтобы на данные можно было ссылаться, они должны быть собраны и проанализированы. Здесь в дело вступают дата сайентисты и аналитики данных. В этой статье мы поговорим об основных инструментах для сбора и анализа данных.
Анализ данных — не только новая профессиональная область, но и актуальный навык для специалистов из разных областей. Эту статью мы подготовили совместно с образовательной онлайн-платформой OTUS.
Что такое данные?
Данные — это совокупность наблюдений, качественных или количественных, которая призвана сообщить некую информацию.
Данные бывают структурированные и неструктурированные. Фотографии, голосовые сообщения, отзывы клиентов — это неструктурированные данные. Чтобы их можно было использовать для анализа, они должны быть обработаны, то есть структурированы.
Фотографии, например, могут превратиться в таблицу, содержащую информацию о месте и времени съёмки, именах модели и фотографа и технических характеристиках получившихся снимков. Голосовые сообщения могут быть расшифрованы, отсортированы по отправителю и получателю, теме послания или длительности. А отзывы клиентов могут подвергнуться сентимент-анализу и визуализированы в виде облака слов или графов.
Зачем вообще анализировать данные? Зависит от конкретной области. Маркетинговые показатели помогают в планировании и оценке эффективности рекламных кампаний. Продуктовая аналитика изучает опыт взаимодействия пользователей с продуктом, измеряя частоту обращения к продукту, период взаимодействия с ним и другие данные, анализ которых помогает совершенствовать продукт.
HR-аналитика помогает собрать портрет кандидата и оценить заинтересованность в компании разных категорий соискателей. Но эти и другие области объединяет цель найти эффективное решение, опираясь на данные и не ограничиваясь интуицией и личным опытом.
Какими бывают инструменты для работы с данными?
Работа с данными не осуществляется вручную, она предполагает использование специальных инструментов и состоит из нескольких этапов: сбора, анализа, визуализации и прогнозирования данных.
Анализ данных в MS Excel
Excel — базовый инструмент, которым должен владеть каждый, кто хочет работать с данными. Это не только таблицы и формулы: Excel даёт большие возможности для обработки данных и помогает решать задачи разного масштаба, вплоть до обработки большого массива данных с помощью плагинов.
Помимо базовых функций, условного форматирования, сводных таблиц и диаграмм аналитику важно овладеть надстройкой Power Query: она позволяет интегрировать в Excel и обрабатывать данные из внешних источников.
Чтобы научиться принимать решения на основе больших данных, освойте инструменты аналитики на курсе «Аналитик данных» от OTUS. В конце курса у вас будет законченный проект, на котором вы отработаете разные методы анализа данных. Пройдите входное тестирование на сайте, чтобы определить свой текущий уровень знаний.
MS Power BI для бизнес-аналитики
Power BI — мощный инструмент для бизнес-аналитики и визуализации данных. Платформа собирает, структурирует и преобразовывает огромные объемы информации из широкого спектра источников в понятные и наглядные дашборды.
Технически система Power BI состоит из нескольких сервисов, которые взаимодействуют между собой, создавая платформу для полного цикла работы с данными: от сбора и обработки до визуализации и распространения. Power BI Gateway отвечает за установку безопасного соединения между локальными данными и облачным сервисом Power BI Service. Создавать отчёты и дашборды можно в приложении Power BI Desktop, инструменты Power BI Embedded помогают встроить эти отчёты в веб-приложения и встроенные системы, а Power BI Mobile предоставляет доступ к данным и отчётам из любой точки мира.
Power BI популярен не просто так: у него много преимуществ в сравнении с другими инструментами. Он позволяет работать с данными, собранными их самых разных источников, будь то базы данных, файлы Excel, облачные хранилища данных или сервисы веб-аналитики. Легко интегрируется с другими продуктами Microsoft, такими как Excel, SharePoint, Dynamics 365, Azure, что обеспечивает совместимость и единообразие в работе с данными. А ещё его можно настроить так, чтобы данные собирались и обновлялись автоматически: это полезная функция для среднего и крупного бизнеса и производств. Собранные с помощью Power BI данные помогут автоматизировать бизнес-процессы и повысить эффективность работы компании.
Освоить современные методы работы с большими данными поможет курс «BI-аналитика» от OTUS. Он подойдёт как начинающим аналитикам, так и опытным product-, маркетинг- и project-менеджерам, которые хотят освоить инструменты визуализации метрик и глубже разобраться в аналитике проектов. Пройдите вступительный тест на сайте, чтобы получить специальную скидку.
Язык SQL для управления данными
SQL — язык для создания, чтения, обновления и удаления данных в реляционных базах данных, то есть таких, в которых данные хранятся в виде связанных таблиц. SQL позволяет создавать, изменять и удалять таблицы, индексы, хранимые процедуры и другие объекты базы данных, а также извлекать и модифицировать данные в этих таблицах.
SQL подходит для работы с реляционными базами данных в разных индустриях и сферах бизнеса: от здравоохранения до розничной торговли и банковского дела.
Если вы хотите построить карьеру в аналитике данных, обратите внимание на специализацию «Системный аналитик» от OTUS. Вы научитесь анализировать дату, предлагать гипотезы и предсказывать показатели. А ещё — прокачаете резюме и сможете претендовать на позиции Middle+. Узнать больше и оставить заявку можно по ссылке.
Библиотеки Python для обработки и анализа данных
Язык программирования Python — универсальный инструмент работы с данными. Достаточно написать скрипт или программу, чтобы выгрузить данные, создать machine learning модель, построить нейронную сеть или собрать статистику. Для каждой задачи Python имеет свою библиотеку.
Самая популярная — Pandas, она собирает данные из базы данных SQL и создаёт двумерную таблицу. Pandas полезна, когда нужно проанализировать неструктурированные данные, и использует для этого готовые методы индексирования, манипулирования, сортировки и объединения данных.
Для работы с однородным многомерным массивом подойдёт библиотека NumPy. Она используется для обработки массивов, в которых хранятся значения одного и того же типа данных. NumPy облегчает математические операции с массивами, тем самым повышая производительность и ускоряя время выполнения запроса.
С помощью дополнительных пакетов Matplotlib и Seaborn можно визуализировать данные в разных формах: гистограммах, круговых и линейных диаграммах, диаграммах рассеяния, тепловых картах, диаграммах размаха и многих других. Разница между ними в том, что Matplotlib позволяет представить данные преимущественно в столбцовых, круговых и линейных формах, а Seaborn расширяет эти возможности, предлагая больше шаблонов визуализации с более простыми синтаксическими правилами.
Язык R для анализа статистических данных
R — главный конкурент Python, когда дело касается работы со статистическими данными. Это язык программирования, который позволяет манипулировать данными, применяя основные методы статистического анализа: корреляцию, линейную и логистическую регрессию, дисперсионный и регрессионный анализ.
Это универсальный инструмент для сбора, обработки и визуализации любых данных — культурных, медицинских или экономических. Другое преимущество языка R в том, что он прост в освоении и подойдёт даже тем, кто не имеет опыта в программировании.
Обучиться R для работы с данными можно на курсе «Язык R для анализа данных» от OTUS. Уже через 4 месяца вы сможете обрабатывать большие массивы, строить дашборды, автоматизировать задачи и достигнуть новых высот в аналитике.
Дата-специалисты: в чём разница и кем быть?
Навык работы с данными полезен сам по себе — и эйчару, и экономисту, и маркетологу. Но есть и отдельные профессии, сконцентрированные на работе с данными в той или иной форме. Они имеют свою специфику работы и отличаются по требованиям к знаниям разных инструментов.
Аналитики данных часто обращаются к программированию на Python, R или SQL, а ещё используют альтернативные инструменты для анализа и визуализации, такие как Power BI, Tableau или Metabase. Например, собирают у отдела продаж данные о клиентах, сегментируют их по частоте обращений, сумме чека и количеству позиций, а затем исследуют взаимосвязи между этими данными.
Специалисты по Data Science преимущественно занимаются обработкой неструктурированных данных, кодят на Python и создают модели машинного обучения для обнаружения общих категорий данных. Например, создают алгоритм, строящий прогнозы на основании загруженных данных. Данные о клиентах от отдела продаж помогут принять решение, на какой продукт стоит сделать ставку, потому что его чаще покупают клиенты, а какой стоит доработать из-за низких продаж.
Как стать специалистом по работе с данными? На образовательной онлайн-платформе OTUS более 10 курсов и специализаций для тех, кто хочет научиться управлять данными и находить эффективные решения. Выбирайте из курсов по продуктовой аналитике, бизнес-аналитике, системному анализу, HR-аналитике и другим подходам к работе с данными, оставляйте заявку, — и первый шаг будет сделан!
Реклама ООО «Отус Онлайн-Образование» LjN8KTDCG
Следите за новыми постами по любимым темам
Подпишитесь на интересующие вас теги, чтобы следить за новыми постами и быть в курсе событий.
Поделиться
Что думаете?
Комментирую от имени компании
Показать все комментарии
Фотография
Обсуждают сейчас
Увеличиваем конверсию в собеседования бесплатно, онлайн, без регистрации
39 минут назад
У вас отличный опыт.
Карьерный путь: из 1C специалиста в Тимлида разработки на Python
6 часов назад
Источник: tproger.ru
Платформы обработки данных: какие бывают и всем ли нужны
Рассказываем, в какой момент бизнесу стоит организовать платформу для обработки данных и какие варианты есть в России.
Эта инструкция — часть курса «Выстраиваем работу с ML».
Смотреть весь курс

Обрабатывают данные, то есть вытаскивают из них пользу, совершенно разнопрофильные компании. Даже сеть семейных парикмахерских на районе может вести отчеты в Excel, используя ее как CRM-систему. На основе данных вывели список клиентов, давно не приходивших на стрижку? Самое время кинуть им sms с «индивидуальной» скидкой.
В какой момент бизнесу стоит организовать целую платформу для обработки данных? Всегда ли обработка данных — это про big data? И какие варианты есть сейчас в России? Рассказываем в тексте.
От Excel до ML — уровни зрелости дата-аналитики
В начале текста мы упомянули семейную парикмахерскую. Хороший пример, чтобы продолжать рассказывать про то, что вообще происходит в мире аналитики данных. Для дальнейшего повествования пусть это будет сеть барбершопов «Бородатый сисадмин».
Ниже — график зрелости аналитических систем, основанный на классификации компании Gartner. На нем можно выделить четыре уровня. Далеко не каждая компания линейно проходит эволюцию от начала до конца. Есть те, что «с ноги» врываются на 3-4 уровни. Главное, чтобы были необходимые ресурсы — деньги и специалисты, а также соответствующие бизнес-задачи.
А есть компании, которые за все время существования так и останутся на Excel-таблицах и простенькой BI-системе. Это тоже нормально.
Наш «Бородатый сисадмин» пройдет по каждому этапу, чтобы было проще понять разницу уровней зрелости.

Первый уровень: описательный
Первые три пункта объединим в один блок: сырые и очищенные данные, стандартные отчеты. Это самый низкий уровень работы с данными, который чаще всего производится в Google Таблицах или Excel.
Так, наш барбершоп начал собирать данные о клиентах, которые приходят на стрижку, и считать посещения. Администратор вбивает информацию вручную, некоторые данные стягиваются из формы регистрации на сайте. Менеджер может очистить данные от дублей, поправить ошибки, которые были совершены при регистрации, и даже структурировать данные по количеству и разнообразию оказанных услуг в месяц.
На основе этого можно делать обычные отчеты. Узнать, растет ли количество клиентов месяц к месяцу, что дало больше дохода за лето — стрижка бороды и волос.
Эти данные отвечают на вопрос: что случилось? На основе них можно формулировать гипотезы и принимать решения. В большинстве своем — в ручном режиме и за счет когнитивных усилий менеджера.
К этому же уровню относятся такие форматы аналитики, как Ad hoc reports и OLAP. Ad hoc reports — это отчеты, сделанные под конкретный бизнес-запрос. Чаще всего это что-то нестандартное, чего нет в обычной отчетности. Например, перед менеджером «Бородатого сисадмина» стоит задача узнать, сколько продаж случилось за три месяца для когорты лысых, но бородатых посетителей (с разбивкой по дням).
Второй уровень: диагностический
На этом уровне — так называемая аналитика самообслуживания (self-service BI). Она подразумевает, что выполнять запросы к нужным данным и генерировать обобщающие отчеты могут специалисты разных профилей, а не только аналитики данных. Такой подход также проявляется в использовании BI-cистем типа Power BI, Qlik или Tableau. При этом дашборды в них, как правило, настраивают специалисты по работе с данными.
Здесь данные отвечают на вопрос, почему это случилось? Они не просто описывают нынешнее состояние компании, но являются источником аналитических выводов. Например, выручка «Бородатого сисадмина» выросла в 2 раза в сравнении с предыдущим месяцем. Данные показывают, что случилось это из-за нескольких рекламных постов в Telegram об акции барбершопа.
На этом уровне компания может перейти от Excel-таблиц к Python-скриптам и SQL-запросам. Также здесь уже не обойтись без одного-двух дата-аналитиков в команде.
Зачем вообще переходить на более сложные инструменты?
Причины могут отличаться для каждой конкретной компании:
- Увеличился объем работы с данными. Компания стала не только подсчитывать прибыль и расходы за месяц, но и собирать данные по маркетинговым активностям, фиксировать отток клиентов и так далее. Плодить десятки новых Excel-таблиц становится нерационально — в них легко запутаться и сложно проводить корреляции между событиями.
- Появилась потребность в автоматизации. Сотрудники тратят много времени, чтобы собирать данные вручную. Это время они могут посвятить более полезной для роста бизнеса работе.
- Нужно повысить качество данных. Чем меньше автоматизации процессов, тем больше поле для человеческих ошибок. Какие-то данные могут перестать собирать или вносить с ошибками. Автоматизация и BI-системы помогут лучше «чистить» данные и находить новые направления для аналитики.
- Увеличилось число аналитиков. Например, компания стала развиваться в нескольких регионах. В каждом — свой аналитик, но сводить данные им нужно в одном месте. Для унификации инструментов и подходов можно использовать единую BI-систему и общее хранилище (или хотя бы базу данных).
Третий уровень: предикативный и предписательный
На этом уровне начинается работа с более сложными концептами. Речь о предсказательной и предписательной аналитике.
В первом случае данные отвечают на вопрос, что будет дальше. Например, можно спрогнозировать рост выручки или клиентской базы через полгода. Тут алгоритм анализа может лечь в основу ML-модели.
Предписательная аналитика строится на вопросе, что стоит оптимизировать. Данные показывают: чтобы показатели выручки барбершопа выросли на 60%, нужно увеличить бюджет на рекламное продвижение на 15%.
На этом этапе речь уже не о нескольких аналитиках, а о целой команде, которая может работать на несколько бизнес-направлений. Как правило, в этой точке у компаний появляется необходимость в платформах для обработки данных.
Четвертый уровень
«Вышка» — это автономные системы аналитики на основе искусственного интеллекта. Тут машина предлагает некоторое предположительно верное решение по результату анализа больших данных, а человек принимает финальное решение.
Подобные системы могут использовать банки. Например, это могут быть скоринговые системы для выдачи кредитов. А наш барбершоп может использовать Lead scoring — технологию оценки базы данных клиентов с точки зрения их готовности приобрести продукты компании.
Третий и четвертый уровни только для больших данных?
Короткий ответ — нет.
Объем данных не так важен, как задачи, которые стоят перед компанией
Конечно, чем больше данных, тем репрезентативнее результаты. Но оперировать доводами в духе «у меня база всего на миллион человек, вся эта платформенная обработка — не для меня» тоже неверно.
Данных может быть немного, но они могут быть очень разнообразными: записи бесед с клиентами, записи с камер наблюдения, пользовательские изображения и т.д. Все это нужно систематизировано хранить, чтобы успешно извлекать из них ценные для компании, применимые в бизнес-задачах знания.
Объем данных не так важен, как количество аналитики и аналитических команд
Если в компании несколько аналитических команд по разным бизнес-направлениям, это приводит к проблемам. Команды могут использовать один источник данных, но при этом разные инструменты аналитики, разные хранилища. Иногда они могут анализировать одно и то же или по-разному считать один и тот же показатель, что не очень рационально. Если добавить новую аналитическую команду, она рискует начать дублировать часть уже сделанной работы.
Разнородность аналитических пайплайнов также приводит к задержкам в выполнении требований бизнеса. Продакт-менеджер попросит починить дашборд с выручкой по продукту, а фикс получит только через 1,5 месяца.
Когда растут сложность аналитических задач и число аналитиков, компании задумываются о платформах обработки данных. Они дают общую базу, общепринятые договоренности: с помощью каких инструментов и как мы забираем данные из источников, куда их складываем, каким образом организуем хранилище.
Из чего состоят платформы обработки данных
В целом, дата-платформа — это набор интегрированных между собой инструментов, которые позволяют компаниям делать регулярную и воспроизводимую аналитику данных.
Набор инструментов может быть разнообразным, но вкладываются они примерно в один и тот же пайплайн работы с данными:
- Источники. Весь набор источников данных — от простых файлов и реляционных БД до SaaS-решений, собирающих какую-либо потенциально полезную для бизнеса информацию.
- Обработка и трансформация данных. Здесь в работу вступают ETL- или ELT-инструменты. Данные забираются из источника, подвергаются преобразованиям, если это необходимо, и направляются в хранилище. Здесь могут быть задействованы такие инструменты, как Apache Spark, Kafka, Airflow.
- Хранение данных в формате, подходящем для дальнейшей работы c ними. Самыми популярными тулзами для этого являются Greenplum, Clickhouse, Vertica, инструменты из экосистемы Hadoop.
- Непосредственно анализ данных — описательный и/или предсказательный. В качестве инструмента тут может использоваться SQL, Python или любые другие языки.
- Вывод/визуализация данных для конечных пользователей. Чаще всего какая-то принятая в компании BI-система (Power BI, Qlik, Tableau, Apache Superset или их аналоги).
Это грубое деление на этапы работы, которые охватывает платформа для обработки данных. Архитектура конкретного решения может быть более сложной. Один инструмент может охватывать несколько этапов работы, а какой-то определенный этап, например, хранение или трансформация данных, может быть более комплексным.
Как построить дата-платформу
Здесь вернемся к нашему «Бородатому сисадмину». Довольно сложно представить барбершоп, которому нужна платформа обработки данных, но мы уже слишком далеко зашли. Представим, что им управляет Федор Овчинников. Филиалы барбершопа открыты в 4 регионах страны и 22 городах. А еще он запустил онлайн-курсы по уходу за бородой в домашних условиях и всероссийскую платформу для барберов с системой личных кабинетов.
В общем, данных много, запросов для роста бизнеса тоже, аналитические команды не справляются. Какие есть варианты?
Создаем самостоятельно, с нуля
Самый трудно реализуемый вариант, но исключать его полностью нельзя. В таком случае компании нужно нанимать дорогостоящих на рынке специалистов — DevOps- или дата-инженеров. И надеяться, что они справятся без дата-архитектора (или нанять и его тоже).
Также нужно будет арендовать или закупать инфраструктуру под платформу. Понадобятся быстрые серверы и хорошие пропускные каналы. Если инфраструктура on-premises, серверы, естественно, нужно будет еще обслуживать (+ сменные инженеры в техническую команду для обслуживания 24/7).
Весь набор выбранного для платформы ПО нужно будет настроить и «подружить» между собой, чтобы обработка данных проходила максимально автономно и без сбоев. Отраслевого стандарта по факту нет, готовых инструкций очень мало.
В общем, проект масштабный — нужно вложить большие средства в то, что не будет приносить прибыли до и немного после окончания «стройки». А работа может растянуться в лучшем случае на несколько месяцев.
Нашему барбершопу не подходит. Нужных специалистов нет, IT-бренда, чтобы привлекать хороших специалистов, нет, а профит от анализа данных нужен как можно быстрее.
Нужно искать что-то более готовое. Какие есть варианты?
Идем к облачному провайдеру
У зарубежных компаний, которые нередко cloud native, есть один распространенный сценарий. Когда нужна платформа для обработки данных, они идут к одному из популярных иностранных облаков — например, AWS, Google Cloud, Azure — и там из отдельных «кубиков» собирают себе систему.
У них много продуктов, и там можно найти нужное «коробочное» решение для каждого из этапов пайплайна, который мы рассмотрели выше. «Кубики», впрочем, тоже нужно будет связать — с помощью собственных cloud-архитекторов или соответствующего managed-сервиса от провайдера.
Приобретаем готовую платформу
Еще один вариант — обратиться, например, к компании Cloudera, которая на данный момент является единственным адекватным поставщиком Hadoop. У них можно получить готовую, уже собранную платформу и даже техническое сопровождение. Но будет дорого. Ценник сможет принять только крепко стоящий на ногах энтерпрайз.
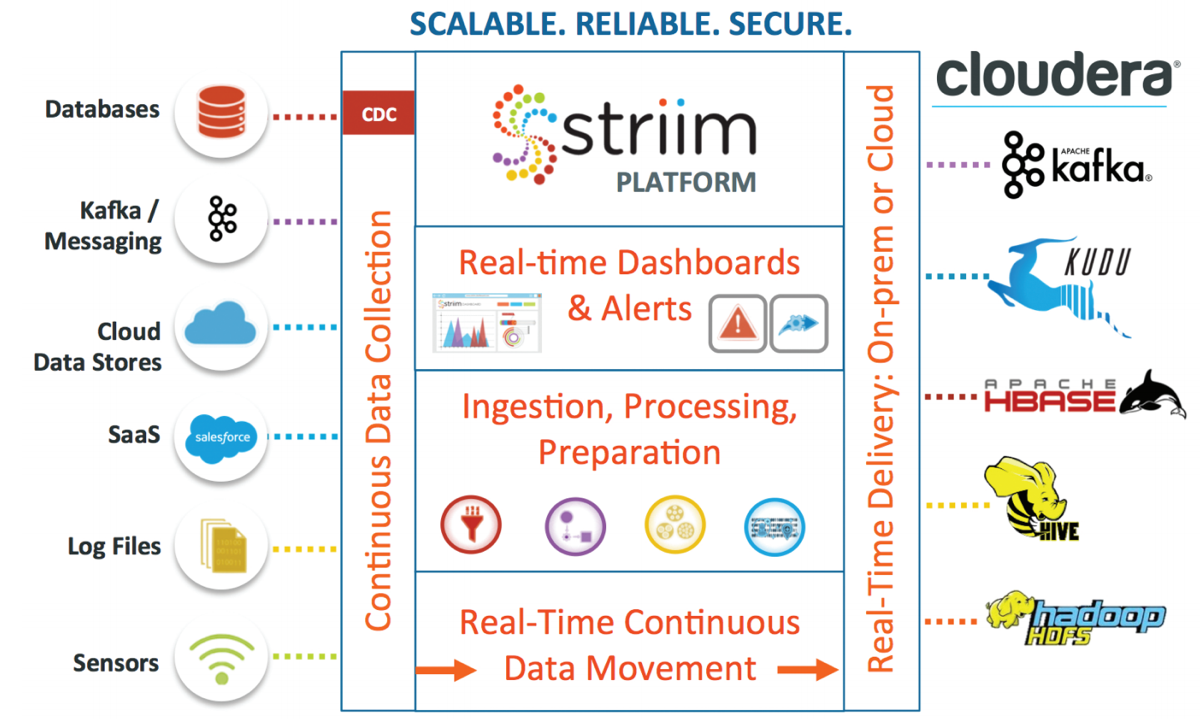
Где проблема? Владелец «Бородатого сисадмина» понимает, что оплата сервисов сейчас затруднена, платить нужно в долларах, а данные безопаснее хранить на территории России. Нужно рассматривать отечественные альтернативы.
Что в России?
В стране есть альтернативы обоим «западным» форматам: и набор необходимых PaaS-решений в облаке, не связанных между собой, и варианты, что ближе к «коробочным». В этом тексте не будет подробного обзора российских решений — этому стоит посвятить отдельный текст (кстати, напишите в комментариях, если вам будет интересно почитать такой обзор).
Здесь мы сосредоточимся на варианте, который обособлен от существующих решений и может быть полезен тем, кто ищет баланс между ценой и качеством.
Арендуем инфраструктуру с предустановленным ПО для обработки данных
Наша ситуация: у «Бородатого сисадмина» нет компетентных архитекторов и нескольких миллионов на интеграцию «коробочного» решения. Какие есть еще варианты?
У Selectel появилась платформа обработки данных — сервис, который снимает с бизнеса сразу две боли: необходимость связывать сервисы в одной инсталляции и заниматься вопросами безотказной работы инфраструктуры.
Работает как ателье. Клиент — это может быть CTO, DevOps, главный аналитик, дата-инженер — рассказывает о своих потребностях. Указывает «мерки»: сколько данных обрабатывается, какой вид обработки нужен — потоковая или пакетная (можно обе), что хочется получать на выходе.
Под требования подбирается инфраструктура — выделенные серверы на высокочастотных процессорах (до 3,6 ГГц) с большим объемом RAM и быстрыми дисками. На ней дата-инженеры из ITSumma поднимают все необходимое ПО под платформу обработки данных — настраивают сетевую связность и все необходимые каналы их взаимодействия.
Минимально достаточное число серверов — четыре машины. Это необходимо для обеспечения отказоустойчивости. Большинство из систем, устанавливаемых в платформу, — распределенные, нужно несколько мастер-нод, размещенных на разных «железных» хостах. Верхняя граница не устанавливается. Инфраструктура под платформу может масштабироваться горизонтально под запросы клиента.
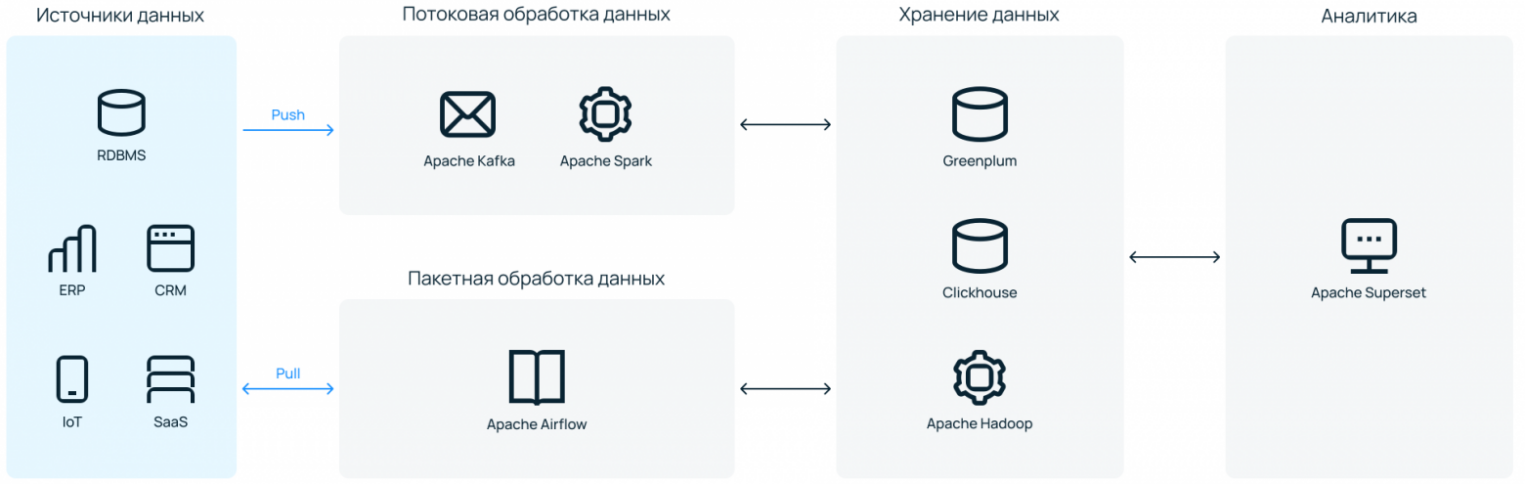
Выбранное ПО — инструменты, которые можно встретить в большинстве эволюционно зрелых дата-платформах. Это open source, поэтому можно не переживать из-за вендор-лока.
Другие особенности
Умеренная кастомизируемость. Клиент может подключать любой источник данных, который ему удобен. Также можно синхронизировать вывод данных в BI-систему клиента, если он, например, использует не Apache Superset. В остальном стек негибкий: поменять один инструмент на другой или добавить инструмент к существующему списку не получится.
Можно удалить лишние элементы — например, Kafka и Spark, если компания не занимается потоковой обработкой данных. Это позволит снизить нагрузку на инфраструктуру и сэкономить место для хранения данных.
Контроль на каждом этапе. Клиент получает доступ ко всему: от физической инфраструктуры до интерфейсов каждого из входящего в нее инструмента. Всегда можно добавить новый источник данных или запланировать выполнение нового Python-скрипта в Airflow. Это можно сделать также через поддержку в ITSumma. Если компании это не надо, такой вариант тоже рабочий.
И инфраструктура, и софт будут настроены для работы с данными без участия ее сотрудников.
Отдельный бонус — можно добавить к платформе сопровождение дата-инженеров ITSumma, исключив необходимость нанимать in-house специалистов. Все через панель управления Selectel.
Платформа обработки данных Selectel
Инфраструктура для хранения и обработки больших данных, сделанная по вашим меркам.
Не обязательно быть клиентом. Чтобы построить платформу обработки данных в Selectel, не обязательно хостится на инфраструктуре компании. Сетевую связность можно настроить как on-prem-площадки. Единственное — при этом сценарии могут быть ожидаемые задержки при трансфере данных из источников. Для высоконагруженных систем и систем, чувствительных к latency, лучше перевезти обрабатываемые данные ближе к месту размещения платформы.
Стоимость платформы складывается из стоимости инфраструктуры и работы дата-инженеров ITSumma. Оплата помесячная. Время построения платформы зависит от сложности запроса конкретной компании. На выходе клиент получает отказоустойчивую, хорошо отлаженную систему для регулярной обработки данных.