
Вы можете сохранить веб-страницу и веб-сайт в форматах HTML, JSS, CSS и Txt, которые вы сможете просмотреть позже в любое время, когда захотите.
Просмотр файлов из файлового менеджера.
Лучшие способы сохранить веб-страницы, чтобы прочитать их позже.
Особенности Website Saver: —
— Сохранить веб-страницу и веб-сайты.
— Сохранить в формате HTML, JSS и CSS.
— Просмотр в любое время.
— Резервное копирование и восстановление данных
— Веб-браузер.
— Просмотр исходного кода.
— Просмотр файлов cookie и очистка файлов cookie.
— Просмотр журнала консоли.
— Очистить журнал консоли.
— Копирование журнала консоли и файлов cookie.
— Хороший интерфейс для телефонов и планшетов.
— Посмотреть историю.
— Просмотр в режиме рабочего стола.
— Функция закладки.
— Загрузить веб-сайт.
— Сохраняется за несколько секунд.
Более 25+ функций, которые помогут вам загружать веб-страницы.
Чем это приложение отличается от других?
Как скачивать файлы с помощью Python
— В нашем приложении есть все необходимые функции, которые помогут вам использовать все желаемые функции в нашем приложении.
Шаги по использованию веб-сайта Saver: загрузчик веб-сайта и заставка: —
1.) Вам необходимо поместить URL в текст URL.
2.) После этого нужно нажать Просмотр.
3.) Теперь вы можете нажать кнопку «Загрузить», чтобы загрузить веб-страницу.
4.) После завершения загрузки вы можете просмотреть веб-страницу.
Источник: play.google.com
Создаём личный «Архив интернета»
Как показала история, сеть из миллиардов связанных между собой документов — очень хрупкая и эфемерная система. Странички живут недолго. Если нашли интересную страницу, сайт или видео — нельзя просто сделать закладку и надеяться, что контент по ссылке останется доступен в будущем. Не останется.
Информация исчезнет, ссылки изменятся, домены сменят владельцев, статьи на Хабре спрячут в черновики. У каждой страницы свой срок жизни. Ничто не вечно под луной, и ничего с этим не поделать.
К счастью, у нас есть инструменты, чтобы сохранить информацию на десятилетия. Свой персональный архив, полностью под контролем, со всеми сайтами и актуальными страницами. Отсюда никто ничего не удалит без вашего ведома, никогда.
Вымирание ссылок
Вымирание ссылок — известный феномен. У большинства СМИ и других организаций нет политики долговременного сохранения информации. Они просто публикуют веб-страницы — и забывают про них. На старые страницы всем плевать, сменят они адреса или исчезнут навсегда. Неудивительно, что именно так и происходит.
Анализ внешних ссылок New York Times с 1996 по 2019 годы показал вымирание ссылок на уровне примерно 6% в год. По итогу с 1996 года пропало около 70% веб-страниц.
Как скачать видео с GetCourse или любого сайта на компьютер?✅

Проверка ссылок в научных статьях показала вымирание 23—53% в статьях с 1993 по 1999 годы.

Проверка проводилась в 2001 году. Наверняка сейчас, двадцать лет спустя, в тех статьях осталось ещё меньше живых ссылок. В 2016 году другая проверка источников в научных статьях с 1997 по 2012 годы показала, что по 75% ссылкам контент исчез или изменился, а снапшоты в веб-архивах остались только для трети пропавших страниц.
Для решения этой проблемы был создан Архив интернета и знаменитая Машина времени (Wayback Machine). Мотивация такая, что мы обязаны сохранить существующий контент для будущих поколений, иначе он безвозвратно исчезнет.
Но в Архив интернета попадают далеко не все страницы. В кэш Google попадает больше, но там определённый срок хранения. И никакой гарантии, что сохранится именно нужная информация. Так что лучше взять дело в свои руки — и создать собственный архив.
Инструменты для веб-архивирования
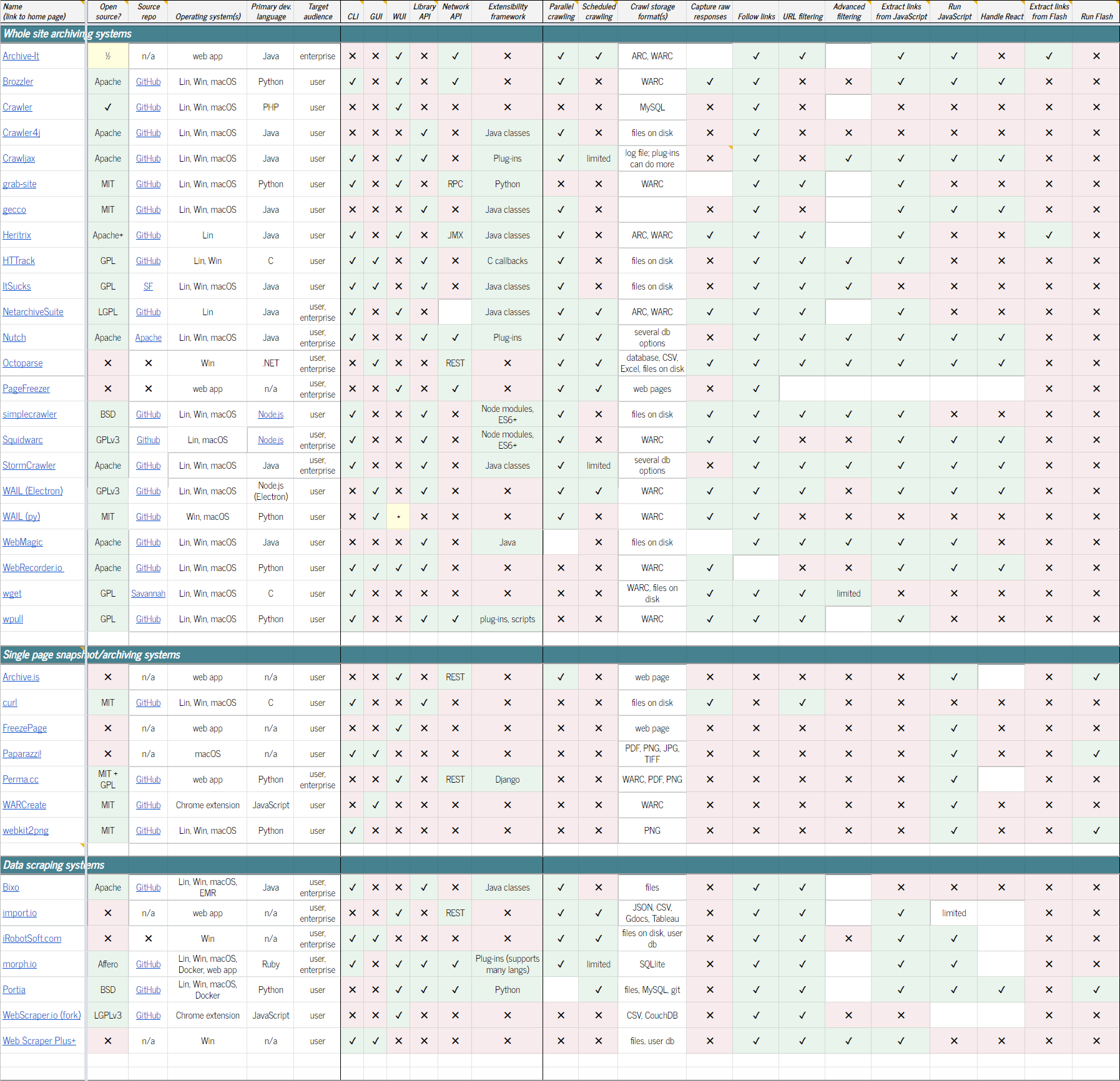
Существует ряд опенсорсных программ для веб-архивирования. Возможно, самый полный список таких проектов собран здесь. Есть также таблица со сравнением функциональности инструментов. Вот небольшой список некоторых проектов:
Архивирование целых сайтов
- Archive-It: курируемая служба веб-архивирования. Предлагает годовую подписку на доступ к своему веб-приложению с различными услугами: полнотекстовый поиск, краулинг контента с различной частотой, выдача отчётов и т. д.
- ArchiveWeb.page: десктопная программа и расширение для Chrome для создания веб-архивов. Расширение можно поставить на «запись», то есть на автоматическое сохранение всех страниц, которые открывались в браузере или в конкретной вкладке. Просматривать архивы в форматах WARC, WACZ, HAR или WBN можно даже в онлайне, для этого создан сайт ReplayWeb.page

Архивирование отдельных страниц
- Archive.is: общедоступный сервис для съёмки снапшотов страниц, которые получают новые URL, сохраняются в архиве для всеобщего просмотра
- curl: известная утилита командной строки для скачивания страничек
- FreezePage: веб-интерфейс для скачивания страничек, сохранять их можно в облаке или на диске
- Paparazzi!: маленькая утилита под macOS, которая делает графические скриншоты страниц
- Perma.cc: сокращатель ссылок и веб-архиватор позиционируется как инструмент для школьников, студентов, юристов и всех остальных, кто хочет получить надёжную ссылку на документ с гарантией, что он не исчезнет и не изменится
- WARCreate: расширение Google Chrome, которое сохраняет любую страницу в формате Web ARChive (WARC)
- webkit2png: утилита командной строки для сохранения скриншотов простой командой типа webkit2png http://www.google.com/
Системы скрапинга данных
- Import.io: платная корпоративная система для скрапинга преимущественно финансовой информации с интеграцией собранных данных в сторонний софт
- iRobotSoft.com: персональный «менеджер», который автоматизирует рутинные ежедневные задачи в интернете: созданные «роботы» могут в том числе ходить по сайтам, кликать по ссылкам и собирать данные с веб-страниц
- morph.io: инструментарий для написания скраперов на Ruby, Python, PHP, Perl и Node.js, коллекция более 10 800 публичных скраперов
- Zyte (бывш. Scrapinghub): платный сервис дата-скрапинга через Extraction API
- WebScraper.io: расширение Chrome и Firefox для удобного скрапинга, экспорт в CSV, XLSX и JSON. Поддерживает работу в облаке по расписанию, через API, с продвинутым парсингом и т. д.
Выбор данных для скрапинга в расширении Chrome
Отдельно стоит отметить приложения для хранения закладок с распределением по папкам, категориям, с тегами. Здесь же копии всех веб-страниц. Такие программы можно назвать «архивами закладок». Например, LinkAce или Wallabag.

LinkAce (платная)
ArchiveBox: личный архив
ArchiveBox — одно из самых функциональных решений для архивирования веб-страниц на своём хостинге. Программа отличается тем, что у неё одновременно есть и веб-интерфейс, и продвинутая утилита командной строки (официально поддерживаются macOS, Ubuntu/Debian и BSD). Скоро появится десктопное приложение на электроне под Linux, macOS и Windows (оно пока в альфе).
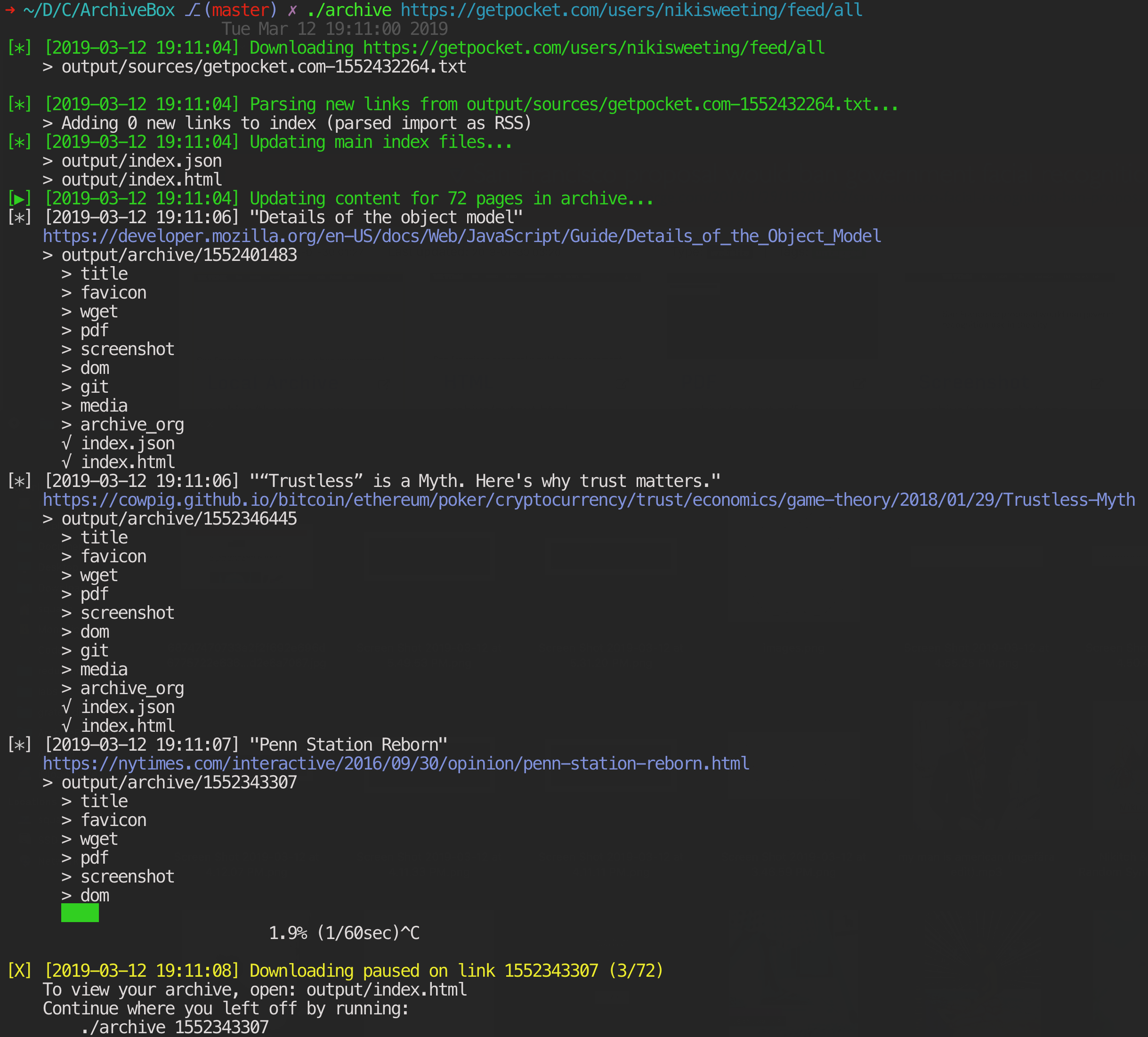
В ArchiveBox можно скинуть URL и указать формат сохранения: HTML, PDF, скриншот PNG или WARC. Автоматически сохраняется вся контекстная информация вроде заголовков, фавиконов и т. д. Грамотно скачивает медиафайлы с помощью youtube-dl, статьи (readability), код (git) и другие типы контента: всего около 12 модулей-экстракторов.
По умолчанию «для надёжности» все страницы вашего архива сохраняются также на archive.org. Опцию можно (и нужно) отключить.
Инструмент командной строки работает очень просто.
Добавить ссылку в архив:
archivebox add ‘https://example.com’
Добавлять контент раз в день:
archivebox schedule —every=day —depth=1 https://example.com/rss.xml
Аргумент depth=1 означает, что сохраняется эта страница, а также все страницы, на которые она ссылается.
Импорт списка адресов из истории посещённых страниц:
./bin/export-browser-history —chrome archivebox add < output/sources/chrome_history.json # или ./bin/export-browser-history —firefox archivebox add < output/sources/firefox_history.json # или ./bin/export-browser-history —safari archivebox add < output/sources/safari_history.json
Импорт списка адресов из текстового файла:
cat urls_to_archive.txt | archivebox add # или archivebox add < urls_to_archive.txt # или curl https://getpocket.com/users/USERNAME/feed/all | archivebox add
Самые популярные настройки из командной строки:
TIMEOUT=120 # default: 60 добавить больше секунд на скачивание для медленной сети или тормозного сайта CHECK_SSL_VALIDITY=True # default: False True = allow сохранение URL с некорректным SSL SAVE_ARCHIVE_DOT_ORG=False # default: True отключить дублирование на Archive.org MAX_MEDIA_SIZE=1500m # default: 750m увеличить/уменьшить максимальный размер файлов для youtube-dl PUBLIC_INDEX=True # default: True публичный доступ к индексу PUBLIC_SNAPSHOTS=True # default: True публичный доступ к страницам (снапшотам) PUBLIC_ADD_VIEW=False # default: False разрешение/запрет всем пользователям добавлять URL в архив
Как вариант, можно добавлять ссылки через веб-интерфейс на локалхосте:

Сервер с веб-интерфейсом тоже запускается из командной строки:
archivebox manage createsuperuser archivebox server 0.0.0.0:8000 # открыть http://127.0.0.1:8000 # опции, упомянутые выше archivebox config —set PUBLIC_INDEX=False archivebox config —set PUBLIC_SNAPSHOTS=False archivebox config —set PUBLIC_ADD_VIEW=False
По сохранённому архиву работает полнотекстовый поиск.
Накопители
На чём хранить личный архив? Теоретически можно сбрасывать архив на компакт-диски или магнитную ленту. Но с ними возникнет проблема поиска в реальном времени. Ведь это основная функция информационного архива — выдавать информацию мгновенно по запросу. Так что самым реалистичным вариантом видится информационное хранилище на HDD (с резервированием по типу RAID).
Многое зависит от объёмов архива. Если у вас скачаны все голливудские фильмы за последние 50 лет в разрешении 4K, то не остаётся вариантов, кроме магнитной ленты. Современные картриджи формата LTO-9 объёмом 45 терабайт стоят не очень дорого.

Копия памяти человека
Кто-то считает, что нужно сохранять в архиве всю информацию, какую человек когда-либо увидел или прочитал, в том числе фотографии, видеоролики, заметки, книги, веб-страницы, статьи. Возможно, даже записи с видеорегистратора, который постоянно работает и записывает всё, что происходит вокруг. Желательно свои мысли тоже записывать (в которых есть смысл).
Такой архив — это своеобразная «цифровая память» человека, копия его жизни, всех событий и воспоминаний, с полнотекстовым поиском. Цифровая копия всего, что попадало в мозг или возникало в нём самопроизвольно. Впрочем, это уже ближе к киберпанку.
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
- 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS .
- — 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC .
- Блог компании FirstVDS
- Хостинг
- Поисковые технологии
- Софт
- Накопители
Источник: habr.com
Лучшие инструменты для сохранения веб-страниц
Узнайте о лучших программных инструментах и сервисах веб-архивирования, которые помогут сохранить любую веб-страницу. А также о том, как скопировать страницу сайта .
Веб-страницы со временем изменяются, они могут даже исчезнуть. Поэтому если вы хотите сохранить веб-страницу навсегда, нужно скачать ее на свой компьютер ( и загрузить на Dropbox ) или использовать сервис веб-архивирования, который будет бесплатно хранить копию этой страницы на своих серверах.
Существует много способов сохранять веб-страницы навсегда, и выбор инструмента будет зависеть от вида контента, который вы хотите сохранить в архив:

Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper . Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы ( или расширения ), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы , которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов . Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер . Также можно использовать Google Cloud Print . На сервис добавлен новый виртуальный принтер » Сохранить в Google Drive «. В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print , вы сможете сохранить ее PDF-копию в Google Drive . Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от Google . Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive . Дополнение может сохранять веб-страницы в формате веб-архива ( MHT ), который поддерживается в IE и Firefox .
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения.
Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is . Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива . Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы , а также связанные с ней изображения, CSS и JavaScript . Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB , чтобы загрузить любую веб-страницу в формате EPUB или MOBI . Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве , но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов , решением может стать Wget . Также существует Google Script для автоматической загрузки веб-страниц в Google Drive , но таким образом можно сохранить только HTML-контент .
Источник: www.internet-technologies.ru