

Сфотографировать документ на телефоне и перевести его затем в редактируемый документ (хотя бы в word) иногда становится настоящим приключением. Андроид “из коробки” не умеет перевести текст с картинки, поэтому здесь необходимы дополнительные инструменты. Существует довольно много способов, каким образом это сделать и в этой статье я расскажу, каким образом можно бесплатно сделать вордовский документ по фото на телефоне через программу FineScanner.
FineScanner
FineScanner — программа для Андроида, которая позволяет распознавать сфотографированные тексты. После этого, документы можно будет редактировать в популярных приложениях для документов, например, Word. Разработана программа компанией ABBYY, которая уже давно работает на рынке распознавания. Многие из вас могли пользоваться программами этого производителя на компьютерах. Не будем ходить вокруг да около и сразу приступим к распознаванию.
Как перевести отсканированный текст в Microsoft Word
Качаем программу с плеймаркета.
Настройки и работа с FineScanner
После первого запуска хотелось бы остановится на некоторых настройках программы. В частности на экране согласия с соглашением.
На этом экране смело оставляем второй пункт без галочки, чтобы не получать рекламные сообщения. Первые два при этом нужно оставить включенными, иначе продолжить будет нельзя.
После того как прошли первые этапы знакомства с программой, сразу появится окно сканирования, где у вас попросят разрешения на работу с камерой. Разрешаем. Окно для работы выглядит следующим образом:

1 — Самая главная кнопка, с помощью которой мы будем фотографировать наши документы.
2 — Автозахват. С его помощью программа сама проанализирует происходящее и найдет документ. Потом сама его и cфотографирует. Ведет Автозахват себя не всегда предсказуемо, поэтому включать я его не всегда рекомендую. Но если вы не знаете, каким образом правильно сфотографировать документ, то можно эту настройку включить.
3 — Фонарик. Если освещение плохое, то с помощью этой кнопки можно включить фонарик на телефоне.
4 — Здесь будут показываться сфотографированные документы.
5 — Удаление последнего документа.
Переделать фотографию в вордовский документ в FineScanner можно следующим образом. Наводим нашу камеру на документ. В идеальной ситуации, в месте, где вы фотографируете, должно быть светло. Чем хуже освещение, тем хуже распознавание. Стараемся навести камеру на документ под прямым углом. Фотографировать под углом не рекомендуется.
Можете включить инструмент Автозахвата, если не уверены в себе.
После того, как навели камеру на документ, фотографируем его по центральной кнопке внизу (1). Аналогичным образом фотографируем другие страницы документов. Справа внизу будет показано количество сфотографированных страниц (4). Если вы случайно сделали ошибку и сфотографировали не тот документ, то удалить его можно по значку корзины (5). Закончив фотографирование переходим на окно редактирования документа, нажав на значок справа внизу (4).
Как распознать текст с фото. Как перевести фото в формат Word.

На этом экране можно обрезать, повернуть изображение или наложить фильтры. Сразу будет применен черно-белый фильтр. Такой фильтр сделает распознавание фото в документ более быстрым и точным. На качество распознавания также влияет сама страница. Если на странице много заметок или таблиц, то распознавание будет не таким точным.
Лучше всего распознаются страницы в одну колонку без таблиц. Свайпами влево/вправо можно настроить каждую страницу по отдельности. Закончив с документом, нажимаем вверху сохранить.
После этого можно приступать к созданию вордовского документа по фото.
Распознавание текста
Сейчас наш документ это просто набор изображений. Для того, чтобы перевести текст с картинки в ворд на телефоне, надо его распознать. Возле нашего документа находим кнопку Распознать и нажимаем ее.
На этом экране нам необходимо выбрать, каким образом мы будем извлекать текст. Есть два варианта, простой текст и текст с форматированием.
При распознавании простого текста, с фотографий будет извлечен только текст. Если ваши фотографии документа также содержат какие-то графики или таблицы, то этот вариант не подходит. Если у вас довольно простой текст и вы собираетесь его потом куда-то вставлять, то вариант с простым текстом более предпочтительный. Работает он быстрее, но документ сохраняется в текстовый формат. Если вам нужен вордовский документ, то выбирайте Сохранить форматирование.
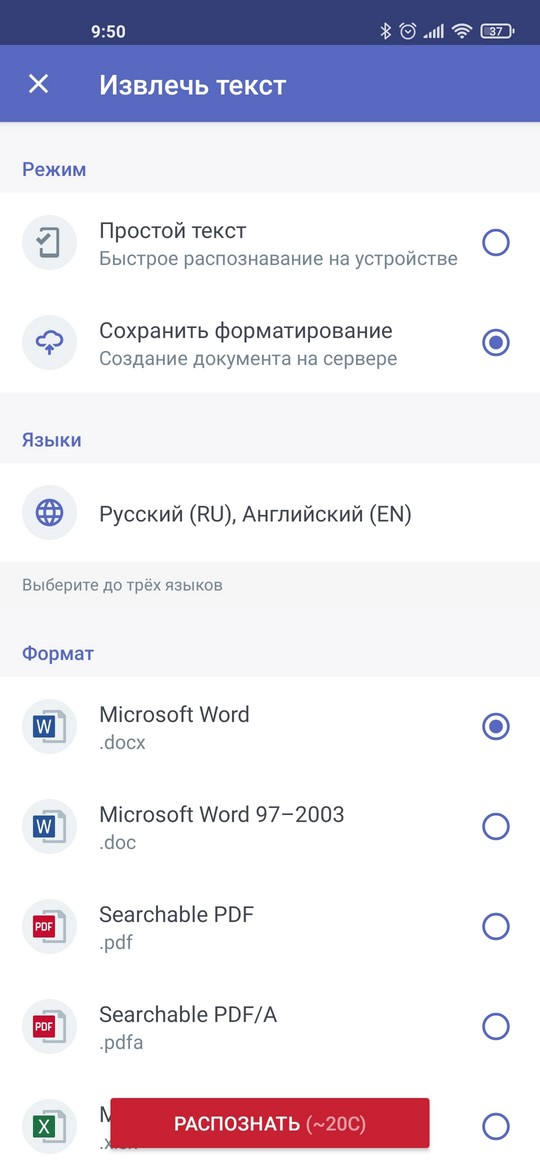
Вариант с сохранением форматирования подходит когда верстка в вашем документе не такая простая. Есть графики, изображения или таблицы. Кроме того, вариант с форматированием может быть сохранен в разные форматы: Word, PDF, Exel и др. Распознавание займет некоторое время, потому что документ будет отправлен на сервер по интернету.
После того, как выбрали нужный для вас формат, нажимаем на кнопку Распознать. Перед тем, как начнется распознавание, появится окошко, которое покажет, сколько бесплатных распознований вам осталось.
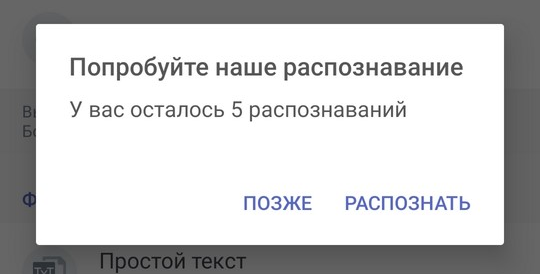
В программе есть встроенная подписка. Для бесплатного использования доступно ограниченное количество распознаваний. Но есть небольшой лайфхак, если обнулить приложение до изначальных настроек, то счетчик распознавания сбросится. Нажимаем распознать и процесс перевода в вордовский документ по фото запустится. Обрабатываемые документы помечаются специальным значком.
Как только обработка закончится, то значок изменится.
После этого, документ можно отправить куда вам нужно. Для этого нажимаем на три точки справа около документа и выбираем Поделиться.
Затем появится окно, в каком виде мы будем отправлять документ. Выбираем Отправить в формате.
В следующем окне нужно выбрать формат отправки.
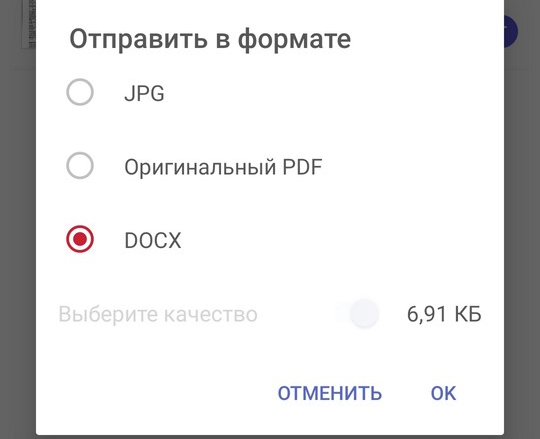
Если вы переводили фотографию в документ ворд, то оставляйте doc или docx. Если сканировали в простой текст, то на выбор будет txt формат. Жмем ок и делимся документом через то приложение, которое вам удобно.
Вот и все. Возможно, процесс создания вордовского документа по фото на телефоне кажется вам слишком мудреным, но это не так. Сделав это один раз, дальше вы будете делать все на “автомате”. Кроме того, простых инструментов, как перевести текст с картинки в ворд на телефоне — нет, а это один из самых быстрых.
Источник: softandroid.net
Как отсканировать документ и распознать его в MS Word

Если Вы выбрали быстрый путь написания теоретической главы, о котором мы говорили в параграфе 2.1., вероятней всего Вам не обойтись без сканирования документов. В ином случае, этот пункт можете пропустить и начинать конспектировать материалы найденные в библиотеке.
Перед началом сканирования нужно определиться, что именно Вы хотите использовать при написании работы. А для этого нужно сначала просмотреть имеющуюся литературу и выделить карандашом нужные моменты.
Когда я впервые сканировал статью из журнала для своей первой курсовой, для меня это занятие было невообразимо сложным. В результате нескольких часов работы со сканером и FineReader’ом у меня на выходе вышла бредятина, не поддающаяся редактированию. В итоге пришлось все набирать руками. Чтобы у Вас не случилось подобного, рассмотрим подробнее все технические моменты сканирования.
Для сканирования вам понадобится:
- Книга или журнал, который нужно отсканировать
- Компьютер с установленным FineReader’ом
- Качественный сканер
Сканер не обязательно покупать. Можно, например, взять на время у товарища. Я пользуюсь сканером CanoScan Lide 60. Это хоть и не самая новая модель, но мне очень нравится этот компактный, быстрый и удобный в работе “девайс”. Если Вы взяли на время сканер, для того чтобы он работал нужно сначала установить программу-драйвер.
Драйвера и руководство по установке всегда можно найти на установочном диске, который прилагается к устройству или скачать на сайте у производителя. После установки драйвера, подключите сканер к компьютеру с помощью соединительного шнура. Теперь можно уже непосредственно приступить к сканированию.
Но сначала немного теории. Вы должны знать, что процесс сканирования состоит из двух этапов:
1. Непосредственно сканирование документа. На этом этапе сканнер как бы фотографирует поверхность сканируемого документа и сохраняет полученное изображение на компьютер в виде обычного файла .jpg .gif или в другом формате;
2. Распознавание документа. Это процесс преобразования текста из изображения сделанного сканером в обычный тест, который потом можно сохранить в Word и редактировать. Распознавание осуществляется без участия сканера, с помощью специальной программы (самая популярная Adobe FineReader). Таким образом, Вы можете сначала отсканировать несколько листов текста и сохранить их в виде изображения и только потом преобразовывать в текст.
Итак, начнем этап первый – сканирование:
Запускаем драйвер сканера:

Пуск – Все программы – Canon – ScanGear (название драйвера я указываю для своего сканера). Появится окно драйвера:
Открываем крышку сканера и кладем книгу. Книгу, журнал или что у вас там есть нужно класть текстом вниз, как можно ровнее по отношению к краям рабочей поверхности сканера:

Очень важно сделать так, чтобы крышка сканера как можно плотнее прижимала сканируемый документ, не допуская попадания внешнего освещения не рабочую поверхность сканера, которая соприкасается с документом.
Выполним необходимые установки в драйвере сканера.
Первым делом нужно установить разрешение, в котором будет отсканирован документ. Разрешение – это показатель, который определяет уровень детализации объекта при сканировании и определяется в точках на дюйм (dpi, или т/д). Чем больше разрешение, тем качественнее получается изображение.
Но, при сканировании текстовых документов нет смысла устанавливать максимальное разрешение, поскольку толку от этого будет ноль. Кроме того, сканирование с большим разрешением занимает больше времени. Я рекомендую устанавливать разрешение в пределах 400-500 т/д (dpi). При такой настройке изображения получаются достаточно качественными для хорошего их распознания, а сам процесс сканирования не занимает много времени. Посмотрите скриншот установок моего сканера:

Для начала нужно перейти в “Расширенный режим”. Источником всегда будет “Планшет” (планшетный сканер). Цветной режим лучше установить “Черно-белый”, ведь для сканирования текста нам цвета не нужны, а это уменьшит размер изображений на выходе. Разрешение, как я уже сказал, следует установить 400 т/д.
Выходной размер изображения – обязательно “А4”. Теперь можно смело жать на кнопку “Сканировать”. Мой сканер устроен таким образом, что сначала запоминает отсканированные изображения во внутренней памяти, и только при закрытии окна драйвера предлагает сохранить их на компьютер. Мне остается только указать место, куда будут сохранены результаты работы.
У вас должны получаться файлы такого типа:

При увеличении такого изображения должен быть отчетливо виден текст.
Второй этап – распознание полученных изображений и их преобразование в текст. Как я уже говорил, для этого понадобится специальная программа – FineReader. Скачайте программу по этой ссылке (72Мб). Чтобы скачать нажмите на стрелочку в правом верхнем углу окна. Распакуйте архив и в папке afr_lrp найдите файл – ABBYY FineReader 12.0.101.exe.
Двойной клик на этом файле запустит установку программы на вашем компьютере. Эта версия программы достаточно новая. Все скриншоты ниже я делал используя более старую версию, поэтому интерфейс программы будет немного отличаться от скриншотов. Учтите это при изучении данной инструкции.
Окно FineReader имеет следующий вид:

После установки языка, на котором напечатаны отсканированные Вами ранее документы, можно начинать распознание. Если в тексте присутствует сразу два языка (например, русский и английский) установку сделайте соответственно.
Чтобы начать распознание нажмите на стрелку справа от первой кнопки Сканировать – а затем – Открыть изображение:

Откроется окно выбора изображений. Откройте папку в которую Вы сохранили отсканированные изображения, нажмите CTRL + A (английское) на клавиатуре и нажмите на кнопку Открыть.

После этого слева в окне FineReader’а появятся эскизы добавленных файлов, по центру – на данный момент выделенный эскиз в увеличенном виде, снизу – еще большее увеличение, а справа результат распознания:

Для примера я взял всего два изображения. На скриншоте выше выделено первое из них, его сейчас и распознаем. Как видите, изображение отсканировано вертикально, чтобы распознать текст снимок нужно сначала развернуть на 90 градусов. Для этого воспользуемся кнопками и . Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно: . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:

Как видите, все текстовые блоки в примере выше выделены зеленым, а рисунки – красным. Таблицы подготавливаются к распознанию аналогично. Для этого предназначена кнопка . Для того, чтобы перейти к следующему снимку, кликните левой кнопкой мыши на его эскизе слева. Таким образом подготавливаются к распознанию все полученные в результате сканирования изображения.
После того, как подготовка изображений завершена, следует выделить их все. Для этого кликните левой кнопкой в пустом месте на панели эскизов (она называется Пакет) и нажмите Ctrl+A (английское) на клавиатуре. Далее кликните на кнопку и подождите пока FineReader преобразует изображения в текст. После этого можно сохранять полученный текст в Word с помощью кнопки , после нажатия на которую откроется окно Мастер сохранения результатов. В нем необходимо выбрать формат для сохранения – Microsoft Word, а также поставить отметку чтобы сохранились все страницы:

После нажатия кнопки ОК программа создаст документ Word и вставит в него текст из распознанных страниц в том порядке, в котором они находятся на панели эскизов (Пакет). Полученный документ сразу же сохраните в папку в файловой структуре дипломной работы и можете приступать к редактированию. Как это делается, описано в моем бесплатном курсе.
И последний момент. Эсли Вы сканировали газету или журнал, текст там часто дается в виде колонок (как в рассматриваемом примере выше). Эти колонки в Ворде нужно преобразовать в одну. Выделите текст в виде колонок и выполните команду: Формат – Колонки – Одна – ОК. Только после этого можно ставить Книжную ориентацию в Параметрах страницы, отступы полей, шрифт и т.д.
Источник: diplomguide.ru
Сканирование документов в программе RiDoc
Простой и доступный способ отсканировать документ на компьютер — это воспользоваться вспомогательной программой. Она позволит из бумажных документов сделать редактируемый текст в электронном варианте. При необходимости можно воспользоваться функцией редактирование скопированного текста или фото.
С такой задачей легко справляется программа RiDoc. В программе без проблем можно отсканировать документ в формате PDF. Ниже будет рассказано, как с помощью RiDoc отсканировать документ на компьютер.
Как установить RiDoc?

- Перейдя по выше указанной ссылке, в конце статьи можно найти ссылку на скачивание программы, открываем её.
- Перейдя на сайт для скачивания программы RiDoc, следует нажать «Скачать RiDoc», сохраняя инсталлятор.
Сканирование документов
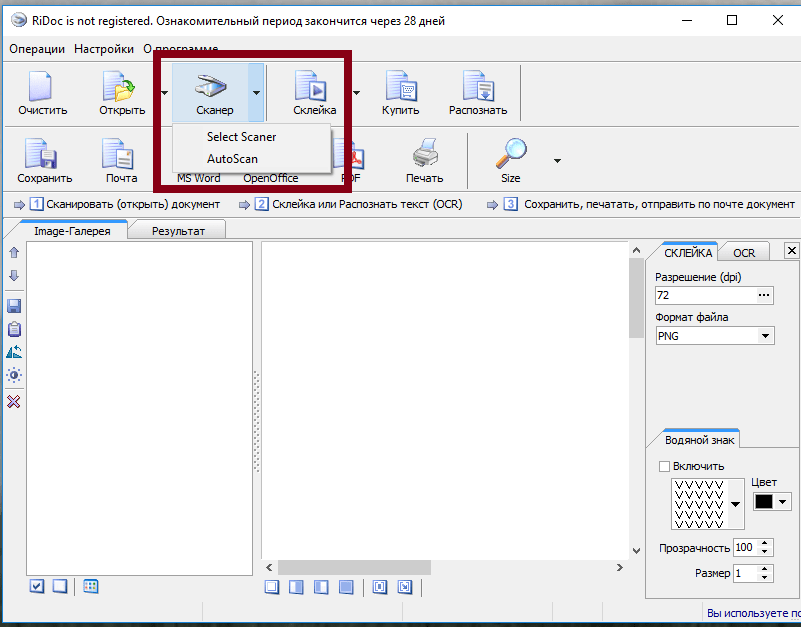
Для начала выбираем, какое устройство будем использовать для копирования информации. На верхней панели открываем «Сканер» — «Select scanner» и выбираем нужный сканер.
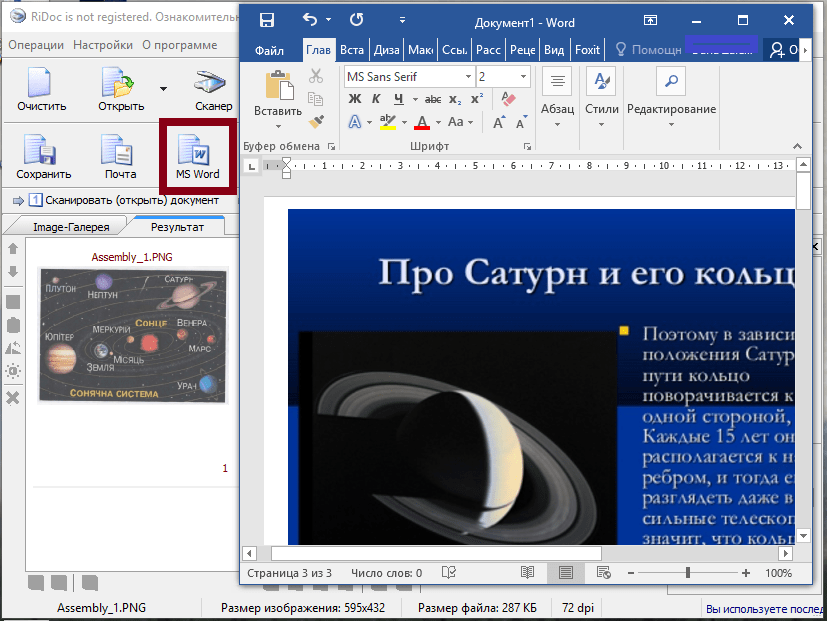
Сохранение файла в Word и PDF формат
- Для того чтобы отсканировать документ в Word, следует выбрать «MS Word» и сохранить файл.
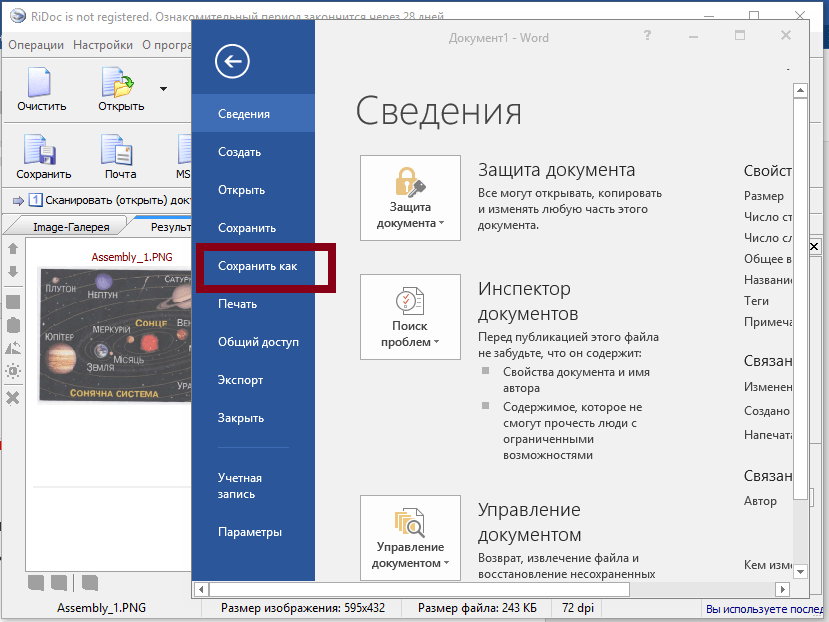
- Для сканирования документов в один файл PDF, следует отсканированные изображения склеить, нажав на верхней панели «Склейка».
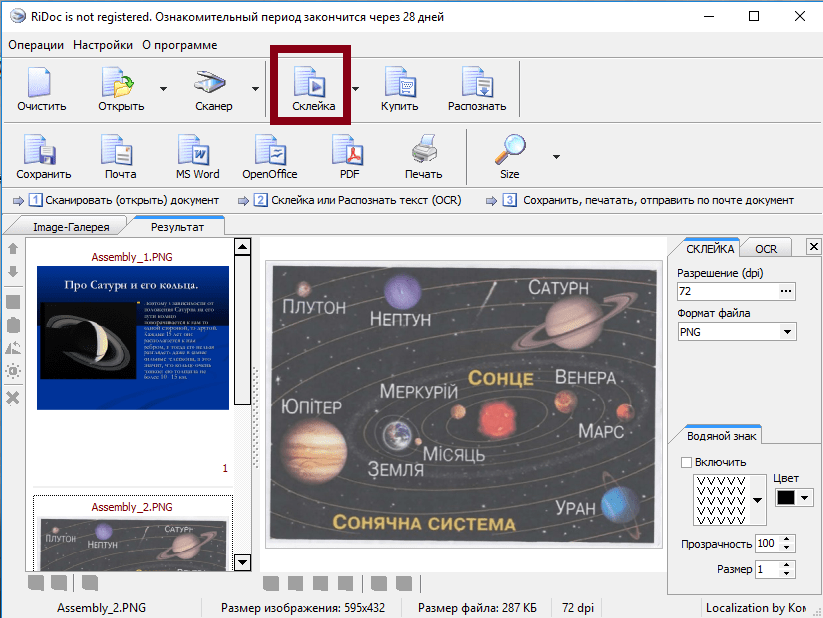
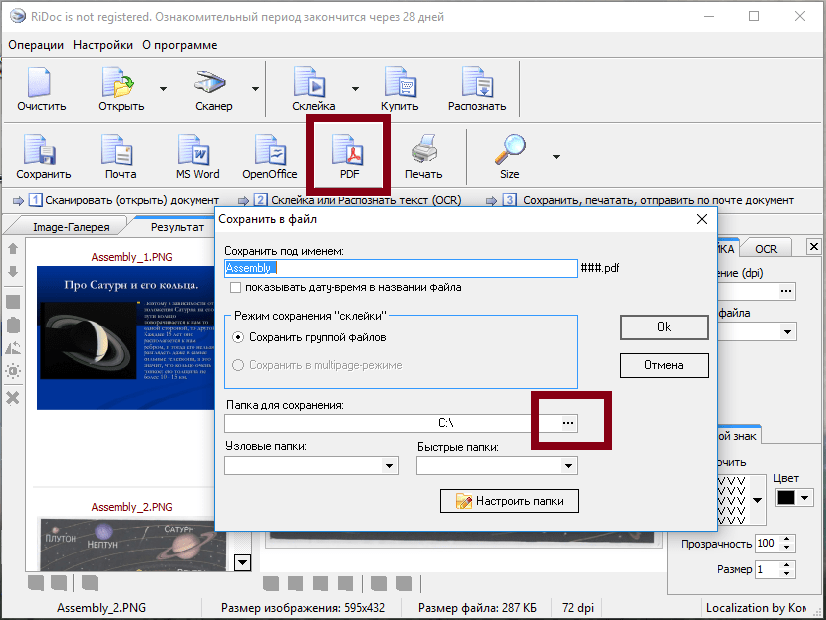
Программа RiDoc обладает функциями, которые помогают успешно сканировать и редактировать файлы. Пользуясь вышеуказанными рекомендациями, можно с лёгкостью отсканировать документ на компьютер.
Источник: lumpics.ru