
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
гугл создали программу для распознавания почерка врачей.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
2be91db Jun 6, 2022
model parameters fixed
Git stats
Files
Failed to load latest commit information.
Latest commit message
Commit time
README.md
Handwritten text recognition
Распознавание рукописного текста
Usage with Docker
- install docker
- open terminal and go to project directory
- build
docker build -t htr/tfgpu .
- change to your absolute path to project and run:
docker run -it -p 8888:8888 -v /absolute/path/to/HTR:/home/htr htr/tfgpu
- open jupyter via url
Использование с помощью Docker
- установите Docker
- откройте терминал и перейдите в данный каталог
- введите в терминале (это займет несколько минут):
docker build -t htr/tfgpu .
- введите в терминале (измените путь на свой абсолютный путь к репозиторию HTR):
docker run -it -p 8888:8888 -v /absolute/path/to/HTR:/home/htr htr/tfgpu
- скопируйте ссылку в браузер и наслаждайтесь проектом в Jupyter!
Постановка задачи и актуальность
С каждым днем все больше достижений в области информатики, особенно в машинном обучении и анализе изображений, находят свое применение в реальной жизни. Компьютерное зрение, зарекомендовавшее себя как один из самых эффективных способов анализа изображений и видео, облегчающий или заменяющий работу человека, давно интегрировано во множество сфер деятельности. Распознавание рукописного текста (РРТ) является одной из ключевых задач компьютерного зрения и имеет следующие преимущества:
Доступ к данным: возможность поиска и удобство использования
РРТ значительно повысил доступность данных. После сканирования и преобразования информации в любой редактируемый формат, такой как MS Word или Adobe PDF, программное обеспечение позволяет хранить или копировать файл в любом месте, где вы хотите, что означает, что файлы затем могут быть найдены в системе вашей компании, и любой человек, имеющий разрешение, может получить к ним доступ. Банковская отрасль и торговые компании получат возможность оптимизировать трудоемкую бумажную работу.
КАК ПЕРЕВЕСТИ РУКОПИСНЫЙ ТЕКСТ В ПЕЧАТНЫЙ!
Экономия времени и памяти
Хранение в облаке — правильный путь, если вы хотите иметь доступную для поиска информацию и сэкономить. Управление бумажной информацией является неэффективной задачей. Этот процесс является одним из самых трудоемких и дорогих. Но самое худшее в этой ручной работе — вероятность человеческой ошибки. Доступ к цифровым данным улучшает рабочие процессы компаний.
Используя РРТ, компании могут сократить количество ошибок. Это особенно ценится страховыми компаниями из-за большого количества документов, с которыми им приходится работать каждый день.
Повышение Удовлетворенности Клиентов
Улучшение качества обслуживания клиентов — это то, к чему стремится каждая компания, и РРТ действительно может помочь в этом. Давайте подумаем о зоне поддержки клиентов, где агенты постоянно получают звонки или электронные письма с запросами. Используя технологию программного обеспечения РРТ, они могут представить себе все услуги, которые клиент имеет в компании, потому что информация доступна в один клик. Это не только уменьшает время, затрачиваемое на каждое дело, но и позволяет службе поддержки клиентов решать любые проблемы, требующие немедленного решения.
Цифровая среда требует повышения безопасности, особенно для конфиденциальной информации, управляемой полицейскими департаментами, гражданскими учреждениями или обработки персональных данных. Технология РРТ запрограммирована на предотвращение попыток мошенничества путем сравнения предоставленной информации с сохраненными данными с минимумом ошибок, что невозможно сделать вручную.
Технической задачей данного проекта является создание модели для распознавание русского рукописного текста, качество которой оценивается посредством метрик CER и accuracy, а бизнесс задачей — оптимизация документооборота, качество которой можно оценить в денежных единицах на обработку одного изображения с помощью сервисов, доступных на рынке.
HKR (https://github.com/abdoelsayed2016/HKR_Dataset) — закрытая база данных, содержащая фрагменты русского и казахского рукописного текста. Помимо 33 символов русского алфавита в наборе присутствуют 9 символов казахского алфавита. HKR представляет собой набор форм. Все формы были созданы с помощью LATEX и впоследствии были заполнены людьми. База данных состоит из более чем 1400 заполненных форм.
Всего около 63000 предложений, более 715699 символов, написанных примерно 200 разными авторами.
Набор данных полностью соотвествует требованиям для решения поставленной задачи, поскольку имеет распределение по символам, аналоличное словарю русского языка.
Подключение словаря русского языка (или предметной области) для повышения качества распознавания — при анализе ошибок работы модели на тестовых данных были найдены закономерности, на основе которых можно сделать вывод, что подключение словаря позволит значительно уменьшить CER, соответственно, повысить accuracy.
Оценка экономического эффекта
При использовании ручного труда:
n * (profit — r_t * salary_h — err_h * fail_cost)
При использовании технологий сторонних компаний:
n * (profit — cost — err_1 * fail_cost)
При использовании собственных технологий:
n * (profit — err_2 * fail_cost) — r_ds * r_t * salary_ds
все расчеты производятся на месяц
- n — количество изображений для обработки. Могут представлять из себя анкеты, документы, заявки и т.п.
- profit — прибыль компании от одного обработанного изображения
- fail_cost — цена ошибки
- salary_h — з/п в час при ручной обработке
- salary_ds — з/п в час разработчика технологии
- r_t — время работы одного человека при ручной обрабатывании
- r_ds — количество разработчиков (2 < r_ds < 6)
- r_t_ds — время работы разработчика (r_t_ds < r_t в общем случае)
- salary_ds — з/п в час разработчика технологии
- err_h — ошибка при работе человека
- err_1 — ошибка сторонней технологии (err_h < err_1)
- err_2 — ошибка нашей технологии (err_h < err_2)
Как можно видеть из формул, затраты первых двух решений растут линейно с увеличением n. При успешном внедрении технологии, err_1 ~ err_2 ~ err_h. С учетом того, что err_2 принимает малые значения, которые могут становится еще меньше, наша прибыль растет при неизменных затратах. Это позволяет масштабировать бизнес.
Ошибка err_2 обратно пропорциональна качеству нашей модели, поэтому при увеличении точности на 1 или на 10 процентов, прибыль вырастет на 0.01 и 0.1 стоимости ошибки соответсвенно. Данная гибкость вносит ясность вопрос: стоит улучшать модель или нет.
Готовые решения и их стоимость
Сколько стоит распознать текст с одной картинки? В Google и Яндексе — 10 копеек, в Microsoft — 5 копеек при точности в районе 96%. Кажется, не так уж дорого. Но что, если нужно распознать не одну картинку, а, скажем, десятки миллионов? Например, при объемах 50 млн загружаемых изображений в день, нам бы приходилось тратить от 2.5 млн рублей ежедневно.
За год получается 1-2 млрд рублей. Это очень дорогое удовольствие для многих компаний.
Применение РРТ в Российских компаниях
Одним из самых показательных примеров применения распознавания бумажных документов с рукописным текстом – это опыт сети «Спортмастер», где покупателями от руки оформляется сотни тысяч анкет ежемесячно, при этом магазины сети расположены не только по всей России, от Калининграда до Петропавловска-Камчатского, но и странах СНГ и Китае, в сумме это более 400 магазинов. Внедрение технологии распознавания рукописного текста в анкетах покупателей позволило в 2 раза увеличить скорость обработки этих анкет и полностью отказаться от доставки бумажных экземпляров в центральных офис для обработки. Важно отметить, что обработка китайских иероглифов оказалась дешевле и качественнее, чем через китайских подрядчиков.
В «Ситимобил»: для осуществления задачи по фотоконтролю такси — распознаем госномер автомобиля на фото. Распознанные данные сравниваются с данными в карточке водителя. Таким образом мы определяем правильная машина пришла на контроль или нет.
В сервисе для объявлений «Юла»: с помощью OCR мы находим лекарственные препараты, которые запрещены к продаже на Юле. Для этого распознанный текст сравнивается со справочником лекарственных средств. Кроме того, мы определяем номера телефонов, ссылки на сторонние сайты, ник Инстаграма и т. д.
Для рекламной платформы myTarget: мы группируем рекламные баннеры по наличию одинакового текста на изображении. Это позволяет сократить количество ручной модерации, а также использовать текстовые классификаторы для определения рекламы низкого качества.
Все поставленные задачи были выполнены: разработана модель для распознавания русского рукописного текста, качество которой на тестовых данных — CER: 4.64%, accuracy: 77.95%, экономический эффект внедрения данной модели был рассмотрен в пункте «Оценка экономического эффекта». Использование технологий распознавания текста позволяет легко соответствовать внутренним стандартам документооборота и полностью или частично устраняет необходимость в бумажном документообороте. Высокоуровневые услуги оптического распознавания символов могут помочь многим средним и крупным компаниям получить прибыль от использования специально разработанных алгоритмов. Такие отрасли, как банковское дело и финансы, здравоохранение, туризм и логистика, могут извлечь наибольшую выгоду из успешного внедрения РРТ. И с каждым годом потребность такой услуги будет только возрастать.
About
Handwritten text recognition
Источник: github.com
Топ 10: Системы распознавания рукописного текста

Машинное обучение позволяет создать нейросети, которые умеют распознавать рукописный текст. Как правило, речь идет о распознавании текста в бумажных формах с квадратиками для букв. Таким образом, рукописного текста сводится к распознаванию отдельных букв. Примеры использования распознавания рукописного текста для бизнеса — даны ниже.

2022. Google хочет научиться распознавать почерк врачей

Google всерьез взялся за вторую важнейшую проблему современной медицины, после лечения рака — распознавание почерка врачей. Оказывается, эта проблема существует не только у нас, но и во всем мире. ИТ гигант уже некоторое время сотрудничает с фармацевтами, чтобы научиться автоматически распознавать почерк врачей. Функция распознавания почерка будет работать в приложении Google Lens, что позволит пациенту (или фармацевту) легко сфотографировать и распознать рецепт. На фотографии рецепта приложение обнаруживает лекарство и сверяет его название в интернете.
2022. В России создали нейросеть, которая распознает рукописный текст на русском языке с 99-процентной точностью

Специалисты Сибирского федерального университета и Санкт-Петербургского государственного электротехнического университета «ЛЭТИ» разработали нейросеть, которая распознает рукописный текст на русском языке. Речь идет о так называемой свёрточной нейросети (CNN). Она способна читать рукопись на русском языке с точностью до 99%, утверждают разработчики.
По их словам, алгоритм ориентируется независимо от почерка, защищён от утечки информации и не требует подключения к интернету. Обучение нейросети проводилось с помощью предварительно обработанных данных хранилища CoMNIST — известной базы данных, содержащей образцы рукописного написания букв на латинице и кириллице. Первым делом учёные создали новый набор данных с помеченным изображением для 33 букв русского алфавита, затем разработали новую архитектуру CNN для обнаружения рукописных букв и сравнили её с уже существующими моделями. После этого выложили на Github полное описание свёрточной нейросети и исходного кода, чтобы другие исследователи имели возможность воспроизводить эти данные.
2020. Приложение Google Lens научилось читать вслух и распознавать рукописный текст
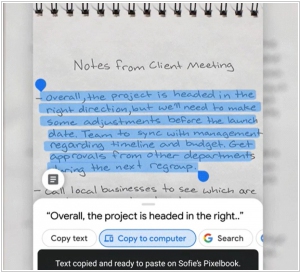
Google Lens — это приложение для визуальных запросов. Например, вы наводите камеру телефона на интересующий вас объект и получаете информацию о нем из Гугла. Приложение также умеет обрабатывать текст, на который вы наведете камеру. Например, переводить его. А теперь еще и умеет прочитать вслух.
Но самая крутая новая фича — распознавание рукописного текста. Да, пока она работает только на английском и только если почерк нормальный, но это уже большой шаг вперед. А если вы используете браузер Chrome на компьютере, то распознанный текст можно одним кликом вставить с телефона в документ Google Docs на компьютере.
Топ 3 лучших Helpdesk

Топ 3 лучших Service Desk

2019. Samsung представила смартфон Galaxy Note 10 со стилусом и рукописным вводом

Samsung представила смартфоны Galaxy Note 10 с 6,3-дюймовым дисплеем и Galaxy Note 10+ c экраном 6,8 дюйма. Смартфоны поддерживают стандарты связи 5G и LTE. Оба устройства получили электронное перо S Pen. Оно позволяет преобразовывать рукописный текст в заметки и дистанционно управлять смартфоном с помощью жестов.
Оба устройства получили модуль из трёх камер: основной на 12 мегапикселей, телеобъектив на 12 мегапикселей и широкоугольной на 16 мегапикселей. Galaxy Note 10+ также оснащён 3D-сканером объектов, позволяющим копировать объекты для 3D-принтеров или создания трёхмерных видео. В России Galaxy Note 10 будет стоить от 76 900 рублей, Galaxy Note 10+ — от 89 990 рублей.
2019. Microsoft представила сервисы для распознавания рукописного текста и заполненных форм
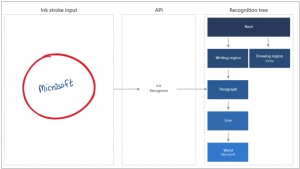
Microsoft представила несколько новых когнитивных сервисов на своей облачной платформе Azure Machine Learning. Во-первых, это подарки для компаний, имеющих дело с документами, формами и служебными записками с рукописным текстом. Сервисы Ink Recognizer и Form Recognizer позволяют переводить все эти бумажки в цифровой текст и данные.
Сервис Conversation Transcription — переводит в текст диалоги по телефону с распознаванием автора каждой фразы. К сожалению, это все пока только на английском. Еще один новый сервис Personalizer позволяет подбирать персонализированные рекомендации для посетителей сайта или интернет-магазина на основании поведенческих факторов.
Кроме того, Microsoft представила новый визуальный конструктор для создания моделей машинного обучения. Теперь даже маркетологи смогут поиграться. Нужно всего лишь загрузить базу данных и указать, какой параметр требуется спрогнозировать.
2016. Анкета24 — сервис по распознаванию рукописных анкет

К сожалению программ, которые бы достаточно точно распознавали рукописный текст — пока нет. Для этого нужен искусственный интеллект. Поэтому, анкеты, заполненные вручную (например, клиентами в торговой точке, партнерами на выставке, кандидатами на работу в отделе кадров) — приходится вводить самостоятельно. Но сервис Анкета24 может решить эту проблему.
Он использует живых операторов (которые справляются с задачей распознавания рукописного текста не хуже искусственного интеллекта). Причем, сервис конвертирует отсканированную или сфотканную анкету в электронный вид почти в реальном времени (от 60 секунд). Стоимость — от 2 до 12 рублей за анкету. Создатели сервиса говорят, что один и тот же текст набирают много операторов дважды (для скорости и точности), при этом каждый оператор видит только отдельные слова, а не всю анкету в целом — таким образом, конфиденциальные данные не будут раскрыты.
Источник: www.doc-online.ru
Как конвертировать изображение с почерком в текст с помощью OCR

Вам нужно оцифровать рукописные заметки, чтобы отредактировать или проиндексировать их? Или вы хотите скопировать текст с картинки рукописной цитаты? Что вам нужно, так называемый инструмент оптического распознавания символов (OCR).
Инструменты OCR анализируют рукописный или напечатанный текст на изображениях и преобразуют его в редактируемый текст. Некоторые инструменты даже имеют средства проверки орфографии, которые дают дополнительную помощь в случае неузнаваемых слов.