
Реалии современного мир таковы, что аналитику всё чаще приходится прибегать к помощи новейших алгоритмов машинного обучения для выявления тех или иных отклонений в работе исследуемой системы. Наибольшей востребованностью пользуются алгоритмы компьютерного зрения для обработки фото и видео информации, а также техники работы с естественными языками для анализа текстов. Однако не стоит забывать о такой важной сфере, как работа с аудио, о которой и пойдет речь в этой статье.
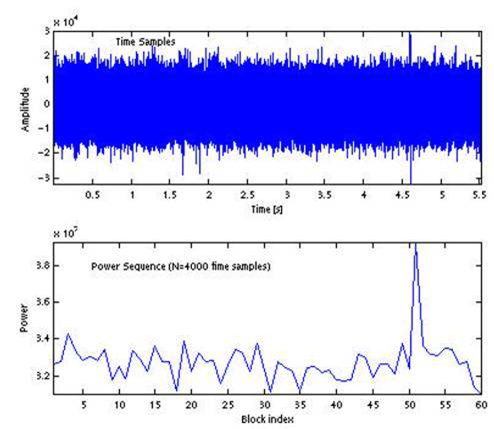
Перед нашей командой стояла задача проанализировать большое число телефонных звонков от клиентов, с целью выявления фактов псевдодоверительного управления, т.е. тех случаев, когда один и тот же человек представляет по телефону интересы нескольких клиентов. Суммарный объем аудиоданных составлял более 500Гб, а общая продолжительность 445 дней (11 тыс. часов). Естественно, прослушать все записи силами нескольких человек невозможно, поэтому решением задачи мы видели автоматическую кластеризацию похожих голосов с последующим анализом полученных групп.
ПРОГРАММА ДЛЯ ИЗМЕНЕНИЯ ЗВУКА И ГОЛОСА В ВИДЕО
В качестве модели для получения векторов голоса была выбрана модель SincNet. Но прежде чем перейти к описанию примененного метода давайте рассмотрим какие вообще существуют подходы к извлечению признаков из звука и почему мы остановились именно на SincNet.
Пожалуй, самым простым подходом в обработке звука является амплитудно-временно анализ.
В данном подходе звуковой сигнал рассматривается как одномерное представление колебаний звуковой волны с определенной частотой семплирования (рис 1). Одним из главных преимуществ данного подхода является сохранение полной информации о сигнале, т.е. сигнал анализируется «как есть», без отказа от важной информации. К сожалению, это одновременно является и недостатком подхода – сигнал сложно разделить на полезный и шум, а высокая размерность данных затрудняет их быструю и качественную обработку. Извлечь большое число полезных свойств из сигнала при подобном подходе, к сожалению, сложно.
Альтернативным подходом является спектральный анализ. Его суть заключается в том, что исходный сигнал со сколь угодно необходимой точностью возможно декомпозировать на составляющее. Другими словами, любой сложный сигнал может быть представлен в виде составляющих его синусоид с определенными частотами и амплитудами. Таким образом, спектр сигнала это уже двумерное представление сигнала, позволяющее судить как именно во времени распределяется энергия сигнала по частотам.

Чтобы понимать, почему анализ спектра позволил существенно продвинуться в обработке аудио давайте вспомним, что такое звук и из чего он состоит на примере человеческого голоса (рис. 3)
КАК ГОВОРИТЬ ЖЕНСКИМ ГОЛОСОМ В VALORANT / CS:GO

При прохождении воздуха через голосовые связки возникают вибрации, которые в виде упругих волн распространяются в среде. Каждый звук (если конечно он не искусственный) представляет собой целый набор таких волн. Изучая основной тон звука, его обертоны и форманты можно успешно решать те или иные задачи, связанные с анализом аудио.
Так, например, частота основного тона (самая низкая частота в сигнале) часто используется в задачах определения пола, так как среднее значение основного тона мужчин и женщин отличается, и составляет в среднем 130 Гц у мужчин против 235 Гц у женщин. Анализ набора обертонов голоса зачастую полезен в задачах идентификации спикера, т.к. этот набор зависит от речевого аппарата, который у каждого индивидуален. И наконец анализ формант (областей усиления определенных частот) активно используется в задачах, связанных с переводом речи в текст.
Спектрограмма позволяет успешно анализировать все вышеописанные составляющие, и во многом благодаря именно этому модели созданные на основе данных о распределении энергии по частотам в сигнале имеют достаточно неплохую точность.
Но есть и третий подход к обработке данных в аудио сигнале, и подход этот связан с нынче модным понятием – нейронные сети. Идея проста – давайте подавать на вход сети аудио и будем ожидать, что сеть научится самостоятельно выявлять закономерности в данных и решать необходимые нам задачи, будь то извлечение признаков, идентификация говорящего, распознавания речи, анализ эмоций и т.д.

В качестве архитектуры для извлечения первичных признаков из сигнала часто используют свёрточные нейронные сети, которые показывают хорошие результаты не только в задачах компьютерного зрения, но и в задачах компьютерного слуха. В процессе обучения CNN учит такие свёртки, которые, по мнению сети наилучшим образом подходят для описания данных. При этом сами данные не обязательно представлять в виде исходного сигнала. Например, представления сигнала в виде спектра, fbank или mfcc дают существенный прирост в качестве и скорости обучения сети.
Проблема в том, что, заменяя исходный сигнал на его представление, мы с одной стороны упрощаем задачу для сети, а с другой лишаем ее возможности самой найти наилучшее представление сигнала. Своего рода компромиссом в данной проблеме стал подход энтузиастов Mirco Ravanelli и Yoshua Bengio, о котором они написали в статье “Speaker Recognition from raw waveform with SincNet”.
Суть их подхода в том, что на вход сети подается сигнал в исходном виде, а в качестве свёрток используются полосовые фильтры, параметры которых сеть подбирает в процессе обучения. Для каждого фильтра тренируются лишь 2 параметра – верхняя и нижняя частоты. Таким образом мы с одной стороны позволяем алгоритму видеть сырые данные, а с другой стороны учим сеть смотреть на данные в контексте только определенных частотных диапазонов.
Сами полосовые фильтры можно представить, как разность двух низкочастотных фильтров (рис. 5), а переходя во временную область фильтр является соответственно разностью двух sinс-функций (отсюда и название сети – SincNet). Умножение исходного сигнала на полученную свёртку равнозначно выделению в сигнале определенной полосы частот.

Сравнение сверток, выученных стандартной CNN с теми, которые учит SincNet, наталкивает на вывод, что обе сети учатся в конечном счете одному и тому же, а именно выделению определенных интересующих частот в сигнале, однако у SincNet есть определенный козырь – в ее первый слой добавлена информация о том, как именно выглядит фильтр, в то время как обычная CNN вынуждена подбирать наилучшую форму фильтра самостоятельно (рис. 6)

Благодаря такому подходу SincNet имеет целый ряд преимуществ над стандартными свёрточными сетями, а именно:
- Меньшее число параметров (каждая свертка SincNet всегда зависит лишь от 2х параметров – нижней и верхней частоты);
- Меньше операций на расчет фильтра, поскольку свёртка симметрична. Первую половину рассчитываем, вторую – зеркалим;
- Быстрая сходимость. Это является следствием первых двух пунктов.
- Хорошая интерпретируемостьсети – каждая свёртка — фильтр с четкими границами. При этом нормализированная сумма фильтров свидетельствует о фокусе внимания на основном тоне и формантах.
Все эти преимущества подкрепляются сравнениями метрик качества, где SincNet показывает лучшие результаты, чем классические связки DNN-MFCC, CNN-FBANK, CNN-RAW. Обо всём этом более подробно можно прочесть в оригинальной статье авторов[1].
С учетом всего вышеизложенного в качестве модели для анализа звонков и была выбрана модель SincNet. Последовательность обработки представлялась нам следующим образом (рис. 7):

В качестве входных данных мы использовали wav-файлы с частотой семплирования 16кГц. В качестве разметки использовалась информация о номере звонящего, подразумеваясь, что с одного и того же номера звонит один и тот же человек. Первичная предобработка данных включает в себя помимо разметки удаление пауз и тишины с помощью сторонней модели Voice Activity Detection, а также нормализацию громкости:
def audio_normalization(source_file, norm_file): [signal, fs] = sf.read(source_file) signal = signal.astype(np.float64) signal = signal / np.max(np.abs(signal)) sf.write(norm_file, signal, fs) # загружаем модель VAD model = torch.jit.load(r’D:\caller_cluster\sincnet\silero-vad\files\model_mini.jit’) model.eval() empty_file = [] for wav in tqdm(wavs): way = os.path.join(‘calls’, wav) wav = read_audio(way) speech_timestamps = get_speech_ts_adaptive(wav, model, step=500, num_samples_per_window=4000) if len(speech_timestamps) > 0: # убираем паузы save_audio(way, collect_chunks(speech_timestamps, wav), 16000) # нормализуем audio_normalization(way, way) else: # удаляем файл, если там нет речи empty_file.append(way) !rm — r
Вся математика SincNet Layout прописана в файле dnn_models.py из репозитория модели SincNet (Github). Настройки сети взяты дефолтные, изменения коснулись лишь путей к тренировочным датасетам:
from dnn_models import MLP from dnn_models import SincNet as CNN options=read_conf(‘SincNet_TradeDesk.cfg’)
По своей сути SincNet состоит из 3х моделей. Первая модель это CNN с ядрами свёрток на основе sinc, которая используется для извлечения первичных фич. Вторая модель собирает все фичи и трансформирует их в вектор меньшей размерности. Задача третьей модели на основании полученного в результате работы первых двух моделей 2048-мерного вектора сделать предикт о принадлежности голоса тому или иному спикеру:
# Feature extractor CNN trunk_arch = trunk = torch.nn.DataParallel(CNN(trunk_arch).to(device)) # Set embedder model. This takes in the output of the trunk and outputs embeddings embedder_arch = embedder=torch.nn.DataParallel(MLP(embedder_arch).to(device)) # Set the classifier. The classifier will take the embeddings and output a dimensional vector. classifier_arch = classifier=torch.nn.DataParallel(MLP(classifier_arch).to(device)) OUTPUT=classifier(embedder(trunk(INPUT)))
Поскольку в нашей задаче конечной целью была не классификация, а кластеризация нам было необходимо таким образом натренировать этот стек, чтобы вектора с выхода второй модели (по сути — эмбеддера) были близки в n-мерном пространстве, если они принадлежат одному человеку и далеки, если принадлежат разным людям. Для этого процесс обучения был изменен с применением техники MetricLearning. Пример кода обучения можно найти тут.
Поскольку с одного и того же номера могут звонить разные люди и с разных номеров может звонить один и тот же человек на первом этапе было решено предобучить модель на датасете, в разметке которого мы были уверены на все 100%. Данный датасет был собран из голосов сотрудников и размечен автоматически, благодаря служебной информации об операторе в смене.
Для оценки близости полученных векторов был применен метод понижения размерности UMAP (рис. 8). Уже после нескольких эпох обучения стало понятно, что модель работает правильно и успешно отделяет голос одного человека, от голоса другого. Визуально это проявляется в том, что точки одного и того же цвета (один и тот же голос) организуются в обособленные группы.

Несмотря на явно неплохую работу векторизатора точность классификатора составила всего 0.225 (err = torch.mean(predict!=label)), что изначально может смутить. Однако стоит понимать, что эта точность считается в разрезе batch, а в batch попадают случайные части из аудио, в том числе те, по которым нельзя однозначно судить, кому принадлежит голос (например, короткая пауза перед следующим словом или посторонний шум).
Для оценки качества модели используется немного другой подход: фраза от спикера разбивается на короткие участки, каждый участок классифицируется, и после этого всему набору присуждается наиболее часто предсказанная метка. Такой подход к оценке модели показывает, что, оказывается, наша модель имеет достаточно высокую точность. На графике ниже показан процесс обучения. В данном случае обучение проходило уже на выборке из 208 голосов с общей продолжительностью не менее 10 секунд на спикера.

Как видно, ошибка test_sent_error полученной модели уже к 32-ой эпохе снизилась всего до 0.055, что можно трактовать как accuracy = 0.945. Это явно достойный результат. Обучение одной эпохи заняло около 6 минут, если учить модель на single GTX2070 и около 2 минут если использовать лабораторию данных с Tesla V100. Таким образом менее чем за сутки удалось получить модель приемлемым для наших целей качеством.
В итоге с помощью модели было обработано немыслимое число телефонных переговоров. Обработка позволила выявить порядка 55 групп от 2 до 5 клиентов, заявки за которых подавал один голос. О данном факте было проинформировано руководство и приняты соответствующие меры.
Источник: habr.com
Лучшие приложения для преобразования голоса в текст
Согласитесь, записать голосовую заметку куда проще, чем «набивать» сообщение вручную. Только вот если вы используете телефон в качестве замены диктофону для того, чтобы наговорить длинный текст или записать лекцию, в дальнейшем у вас, что логично, не будет «текстового варианта». Что же делать? Перепечатывать все вручную на слух? Не отчаивайтесь!
Ведь на ваш Android-смартфон всегда можно установить приложение, которое распознает голос и сделает из него удобный для прочтения и редактирования текстовый файл.

Voice Notes — Удобные голосовые заметки
Это приложение представляет собой именно то, что и заявлено в названии. Это голосовые заметки для Android-смартфонов. Все, что вам нужно сделать — это начать запись звука, а программа уже самостоятельно поймет, что вы говорите и сохранит это в текстовом формате.
Кроме того, программа синхронизирована с календарем и вы легко можете сделать из текстовой заметки напоминание на будущее, что довольно удобно. А еще довольно удобно читать самые интересные материалы в нашем новостном канале в Телеграм. Подписывайтесь, чтобы ничего не пропустить. А мы, меж тем, двигаемся дальше.
Speechnotes — Умеет не только распознавать текст, но и кое-что еще

Speechnotes по своей функциональности практически аналогично предыдущему нашему гостю. За тем лишь исключением, что в комплекте тут имеется довольно удобная клавиатура для редактирования получившихся заметок и расстановки знаков препинания. Плюс ко всему Speechnotes хорошо умеет работать с подключенными к сети принтерами, что позволяет прямо из интерфейса приложения распечатать документ.
Evernote — Самая популярная программа в своей категории
В отличие от других приложений транскрипции, о которых шла речь выше, это дает больше возможностей для создания заметок, чем какое-либо другое приложение. Оно позволяет как производить обработку звука «на лету», так и конвертировать в текстовый формат уже имеющиеся аудиофайлы. А еще тут есть отличная опция по синхронизации с облачными сервисами, которая не позволит вам потерять ваши важные записи.
ListNote — Удобный вариант сохранения ваших файлов
Это приложение для расшифровки аудиофайлов может похвастаться более, чем 1 миллионом загрузок в Google Play Store. Интерфейс этого транскрипционного приложения очень удобен и дружелюбен. А отличает ListNote от других то, что программа может не просто распознавать речь, но и сохранять полученные в результате текстовые документы на SD-карту.
Программы для распознавания английской речи
Все вышеупомянутые приложения, как вы понимаете, поддерживают русский язык. Но если вам вдруг понадобится перевести из звукового в текстовый формат что-то, сказанное на английском, то стоит воспользоваться программами, которые работают с иностранными языками куда лучше, чем с русским. В этом случае рекомендуем вам присмотреться к приложениям Otter.ai, SpeechTexter и Lyra Virtual Assistant. Первые два позволяют вам сохранять текстовые заметки в самых разных форматах текстовых файлов, а последнее — это и вовсе не просто расшифровщик текста, а полноценный голосовой ассистент, который, увы, понимает лишь язык Туманного альбиона.

Теги
- Новичкам в Android
- Операционная система Android
Источник: androidinsider.ru
Машинный слух. Как работает идентификация человека по его голосу
Ты, возможно, уже сталкивался с идентификацией по голосу. Она используется в банках для идентификации по телефону, для подтверждения личности на пунктах контроля и в бытовых голосовых ассистентах, которые могут узнавать хозяина. Знаешь ли ты, как это работает? Я решил разобраться в подробностях и сделать свою реализацию.
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
Предобработка звука
Человеческий голос — это не одинокая волна, это сумма множества отдельных частот, создаваемых голосовыми связками, а также их гармоники. Из-за этого в обработке сырых данных волны тяжело найти закономерности голоса.
Нам на помощь придет преобразование Фурье — математический способ описать одну сложную звуковую волну спектрограммой, то есть набором множества частот и амплитуд. Эта спектрограмма содержит всю ключевую информацию о звуке: так мы узнаем, какие в исходном голосе содержатся частоты.
Но преобразование Фурье — математическая функция, которая нацелена на идеальный, неменяющийся звуковой сигнал, поэтому она требует практической адаптации. Так что, вместо того чтобы выделять частоты из всей записи сразу, эту запись мы поделим на небольшие отрезки, в течение которых звук не будет меняться. И применим преобразование к каждому из кусочков.
![]()
WWW
Выбрать длительность блока несложно: в среднем один слог человек произносит за 70–80 мс, а интонационно выделенный вдвое дольше — 100–150 мс. Подробнее об этом можно почитать в исследовании.
Следующий шаг — посчитать спектрограмму второго порядка, то есть спектрограмму от спектрограммы. Это нужно сделать, поскольку спектрограмма, помимо основных частот, также содержит гармоники, которые не очень удобны для анализа: они дублируют информацию. Расположены эти гармоники на равном друг от друга расстоянии, единственное их различие — уменьшение амплитуды.
Давай посмотрим, как выглядит спектр монотонного звука. Начнем с волны — синусоиды, которую издает, например, проводной телефон при наборе номера.
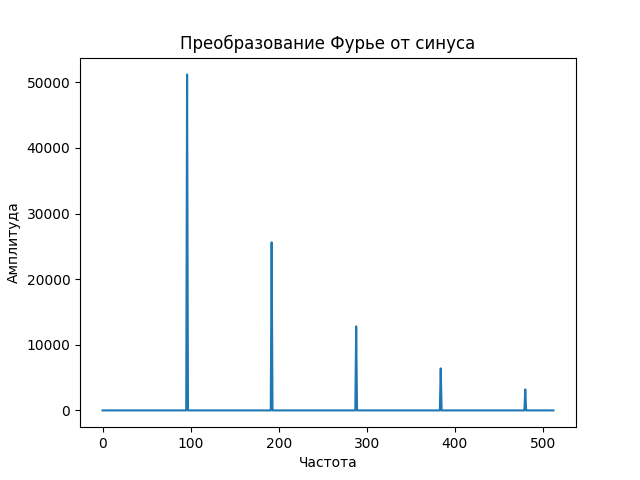
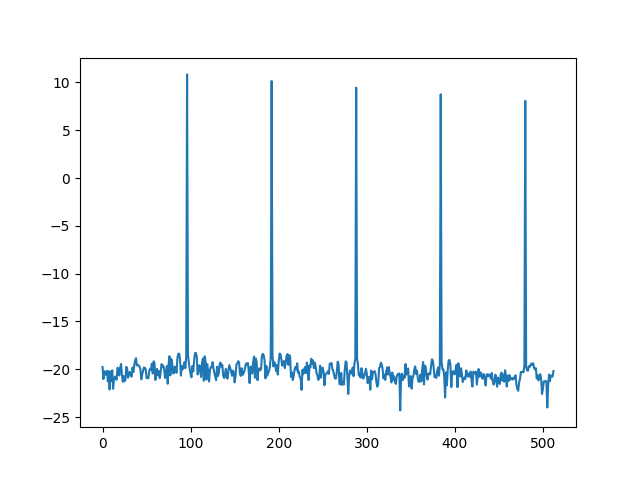
Видно, что, кроме основного пика, на самом деле представляющего сигнал, есть меньшие пики, гармоники, которые полезной информации не несут. Именно поэтому, прежде чем получать спектрограмму второго порядка, первую спектрограмму логарифмируют, чем получают пики схожего размера.
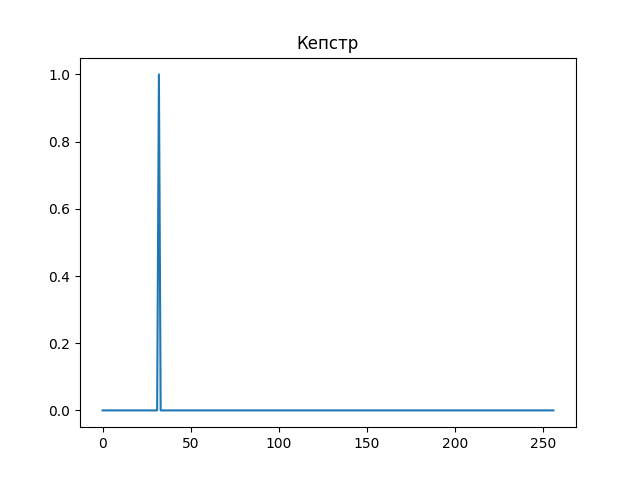
Теперь, если мы будем искать спектрограмму второго порядка, или, как она была названа, «кепстр» (анаграмма слова «спектр»), мы получим во много раз более приличную картинку, которая полностью, одним пиком, отображает нашу изначальную монотонную волну.
Одна из самых полезных особенностей нашего слуха — его нелинейная природа по отношению к восприятию частот. Путем долгих экспериментов ученые выяснили, что эту закономерность можно не только легко вывести, но и легко использовать.
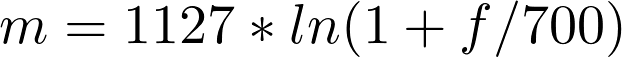
Эту новую величину назвали мел, и она отлично отражает способность человека распознавать разные частоты — чем выше частота звука, тем сложнее ее различить.

Теперь попробуем применить все это на практике.