
Use saved searches to filter your results more quickly
Cancel Create saved search
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window.
Reload to refresh your session.
Распознавание диктора по голосовой записи
stanislavlyalin/speaker_recognition
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more about the CLI.
НЕЙРОСЕТЬ ПИШЕТ БИТЫ
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
fc588ac Nov 10, 2019
Git stats
Files
Failed to load latest commit information.
Latest commit message
Commit time
November 10, 2019 20:48
November 10, 2019 20:47
October 11, 2018 20:41
October 11, 2018 22:40
November 8, 2019 16:43
November 9, 2019 15:44
October 11, 2018 20:32
November 8, 2019 16:51
November 8, 2019 16:21
README.md
Реализация методов идентификации диктора по голосу на Python.
Функции предобработки сигнала.
normalize — нормализация сигнала. Из каждого элемента вычитается среднее, затем разности делятся на среднеквадратическое отклонение.
remove_silence — удаление пауз. Модуль сигнала сглаживается окном заданного размера. Затем сохраняются только те отсчёты, для которых сглаженный массив оказался выше заданного порога.
Функции извлечения признаков из речевых сигналов.
lpc — вычисление коэффициентов линейного предсказания. Будущий отсчёт можно выразить как сумму p предыдущих отсчётов, умноженных на коэффициенты a. Эти коэффициенты можно вычислить, решив задачу регрессии.
Функция lpc принимает на вход отсчёты сигнала, частоту дискретизации, размер блока сигнала в семплах, на которые будет разбиваться исходный сигнал, количество рассчитываемых коэффициентов. Коэффициенты рассчитываются отдельно для каждого блока сигнала. Таким образом, получается таблица коэффициентов, число строк в которой соответствует числу блоков в сигнале, число столбцов соответствует числу признаков. Затем из таблицы формируется вектор средних значений коэффициентов по столбцам и вектор дисперсий. Эти два вектора и являются итоговым вектором признаков для данного файла.
ДИКТОФОН на Телефоне Всегда ВКЛЮЧЕН и СЛИШИТ Абсолютно ВСЕ что Говорите Как Очистить эту Настройку
mfcc — вычисление мел-частотных кепстральных коэффициентов. Функция принимает на вход отсчёты сигнала, частоту дискретизации и количество рассчитываемых коэффициентов. Как и в случае с lpc, сигнал разбивается на блоки, и коэффициенты MFCC считаются для каждого блока.
В результате получается таблица с числом строк, соответствующим числу блоков сигнала, и числом столбцов, соответствующим количеству коэффициентов. Затем из таблицы формируется вектор средних значений коэффициентов по столбцам и вектор дисперсий. Эти два вектора и являются итоговым вектором признаков для данного файла.
Различные вспомогательные функции.
files — формирует список структур с информацией о голосовых записях в заданной директории. На вход принимает путь к директории. Возвращает список структур с полями .
make_data_set — формирует обучающую и тестовую выборку. Принимает на вход список файлов, полученный с помощью функции files, количество пользователей (на случай, если нужно обработать голосовые записи не всех пользователей из директории с файлами), количество записей каждого пользователя, которые идут на обучение, callback-функция, в которой будет выполняться расчёт признаков. callback-функция принимает отсчёты сигнала и частоту дискретизации и возвращает вектор признаков для данного файла.
samples_to_data_sets — разбивает исходный сигнал samples на блоки по data_set_len отсчётов, а затем в каждом блоке упорядочивает данные столбиком с n входными значениями и одним выходным. Функция полезна при формировании выборок для, например, коэффициентов линейного предсказания (lpc) или коэффициентов, полученных в результате обучения нейронной сети.
mistakes_to_folders — раскладывает по каталогам файлы, на которых классификатор ошибся.
Формирование обучающей и тестовой выборок
Для этого необходимо запустить скрипт all_features.py . Скрипт вычислит признаки и сохранит их в файлах train_set.npy и test_set.npy . Описание признаков приведено в файле features_description.txt .
Раскладывание по каталогам файлов для ошибочных примеров
Если на признаках, которые были почерпнуты из публикаций и интернета, качество классификации недостаточно, нужно вручную проанализировать файлы, на которых классификатор ошибся с целью найти различия и представить их в виде признаков. Для этого удобно разложить файлы с правильным классом и файлы с неправильным классом, но предсказанным как правильный, по каталогам для последующего ручного анализа. Для этого используется функция mistakes_to_folders из каталога utils`. В качестве параметров принимает:
- model — модель (классификатор).
- X_test, y_test — тестовая выборка. Число признаков (столбцов) должно соответствовать обучающей выборке, на которой училась модель.
- wav_files — файлы, по которым формировалась обучающая и тестовая выборка.
- mistakes_dir — каталог, в который будет помещён результат — подкаталоги с файлами
import os import pickle import glob import numpy as np from sklearn.preprocessing import StandardScaler from utils.mistakes_to_folders import mistakes_to_folders # 1. создание и обучение классификатора # подготока обучающей и тестовой выборок train_set = np.
load(‘train_set.npy’) test_set = np.load(‘test_set.npy’) X_train = np.nan_to_num(train_set[:, :-1]) X_test = np.nan_to_num(test_set[:, :-1]) y_train = train_set[:, -1].astype(int) y_test = test_set[:, -1].
astype(int) # стандартизация признаков scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # создание и обучение классификатора from sklearn.
svm import SVC # признаки, которые оказались значимы при тренировке модели indexes = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 27, 28] model_filename = ‘model_svc.dump’ if os.path.
exists(model_filename): with open(model_filename, ‘rb’) as file: model = pickle.load(file) else: model = SVC(C=10) model.fit(X_train[:, indexes], y_train) with open(model_filename, ‘wb’) as file: pickle.
dump(model, file) wav_files = glob.glob(‘i:/aspirantura/samples_16kHz_train_test_100/*.wav’) mistakes_dir = ‘./mistakes_dir/’ mistakes_to_folders(model, X_test[:, indexes], y_test, wav_files, mistakes_dir)
About
Распознавание диктора по голосовой записи
Источник: github.com
Как аудиозапись перевести в текст — ТОП8 сервисов и програм
К сожалению, на данный момент не существует ни одной программы, которая могла бы автоматически распознать аудиозапись и превратить ее в текст. Поэтому расшифровкой аудиозаписей по-прежнему необходимо заниматься вручную.
Но существует ряд программ, которые помогают выполнить транскрибацию немного быстрее и проще. Именно о них, а также об одном довольно интересном способе расшифровки аудиофайлов, поговорим сегодня.
RSplayer V1.4

Эта программа имеет довольно обширный функционал, но подробнее остановимся именно на том, который поможет выполнить расшифровку аудиофайлов.
Для более удобного и быстрого перевода аудиофайлов в текст, программа имеет встроенный текстовый редактор. С помощью комбинации клавиш можно легко управлять плеером:
- Alt (слева) + стрелка вниз – остановка воспроизведения;
- Alt (слева) + стрелка вверх – начало воспроизведения с позиции -5 секунд от последней.
Горячие клавиши работают независимо от того, активным ли будет окно программы, поэтому проигрыватель можно использовать совместно с сторонними текстовыми редакторами.
Данная программа очень проста в использовании – достаточно всего лишь применять указанные комбинации клавиш и записывать услышанный текст.
RSplayer является бесплатной программой, которую можно скачать на сайте разработчика.
Express Scribe
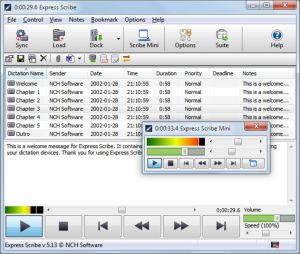
Этот профессиональный софт используют практически все, кто занимается транскрибации. Благодаря встроенному функционалу, процесс перевода аудио или видео в текст выполняется максимально комфортно.
Данная программа имеет встроенный текстовый редактор, поэтому у пользователей нет необходимости постоянно переключаться между окнами. Помимо регулировки громкости и настройки аудиоканалов для большей четкости звука, программа имеет также ползунок для изменения скорости воспроизведения.
Помимо программ, которые требуют установки на ПК, существует также ряд онлайн сервисов, работать с которыми можно прямо из окна браузера.
Dragon Dictate
Эта программа от американских разработчиков применяется для распознавания английской речи и дальнейшего перевода ее в текст. Также с ее помощью можно управлять компьютером с помощью голосовых команд.
Именно на основе данной программы были созданы такие популярные русскоязычные версии, как «Диктограф», «Диктант», «Горыныч» и «Комбат». Отечественные программы не могут похвастаться точной работой – для корректной работы необходимо провести предварительные настройки, чтобы софт мог правильно распознавать тембр голоса. Незнакомые слова, англицизмы и неологизмы необходимо будет вручную занести в словарь.
Для одноразовой транскрибации рекомендовать такие программы не стоит, а вот те, кто занимается такой деятельностью регулярно, могут потратить время на тонкую настройку, чтобы упростить этот процесс. Но необходимо учитывать, что даже тщательно настроенные, эти программы не можно назвать полноценным софтом для транскрибации – они выдают слишком много ошибок.
AIMP

Для расшифровки текста отлично подойдет также известный всем аудиопроигрыватель AIMP. Благодаря гибким настройкам, в нем можно задать требуемые интервалы для перехода назад и вперед, что помогает прослушивать последний фрагмент записи или переходить далее. На эквалайзере можно изменять скорость воспроизведения, чтобы она соответствовала скорости набора.
Speechpad.ru

Как набрать текст голосом на компьютере
Здравствуйте, уважаемые читатели. Сегодня я подробно расскажу про технические настройки и нюансы речевого набора текста голосом на компьютере. Как вы знаете способ, который я предложил в своём бесплатном видеокурсе «Как набрать текст голосом» — является мобильным и не требует наличие компьютера и платных программ.
По многочисленным письмам можно судить, что курс очень понравился. Но также есть много вопросов, — А как набирать тексты голосом на компьютере? Причём из писем я понимаю, что интересен не, только способ набора текста голосом на компьютере, но и перевод аудио в текст.
Конечно, в комментариях и письмах я отвечал и рекомендовал единственный, на мой взгляд, подходящий для этого онлайн сервис «Блокнот для речевого ввода». И теперь я уже получаю письма с просьбой рассказать о технических настройках компьютера (микрофона и звуковой карты) и как аудио перевести в текст.
В общем, секрет работы с данным сервисом очень прост, — у вас должен быть хороший, чувствительный микрофон. Иначе, качество распознания очень сильно хромает. Но и на этот случай есть выход.
Итак, к делу, при работе с голосовым редактором есть два варианта:
1. Набор текста через микрофон.
2. Набор текста через виртуальный аудио кабель.

Прежде чем приступить к набору текста голосом при помощи голосового блокнота, нужно сделать кое какие настройки браузера Google Chrome. На данный момент, только в этом браузере доступна возможность набирать текст голосом. Нам понадобится установить два дополнительных расширения.

Перейдя по указанным выше ссылкам, Вам достаточно нажать одну кнопку и расширение будет установлено.

Как набрать текст голосом в голосовом блокноте
Для первого способа, дополнительных настроек делать не надо. Всё готово к набору текста голосом через голосовой блокнот.
Переходим на главную страницу блокнота, выставляем нужные параметры, и можно диктовать текст голосом. Иконка микрофона используется для ввода отдельных фраз или предложений. Для непрерывного ввода текста используйте кнопку «Включить запись».

Примечание: при первой попытке набрать текст голосом в верхней части браузера появится предупреждение с запросом на доступ к микрофону. Вам нужно нажать на кнопку «Разрешить».

Как заполнять любые поля и формы голосом в браузере Google Chrome
С помощью установленного ранее расширения «Голосовой ввод текста» Вам доступна функция заполнения любых полей в браузере. Например, в регистрационной форме или оставляя комментарий.
Для того чтобы заполнить отдельное поле в форме, — нажмите правую кнопку мышки в данном поле и в контекстно-зависимом меню выберите пункт «SpeechPad».
Разрешите доступ к микрофону и диктуйте текст.
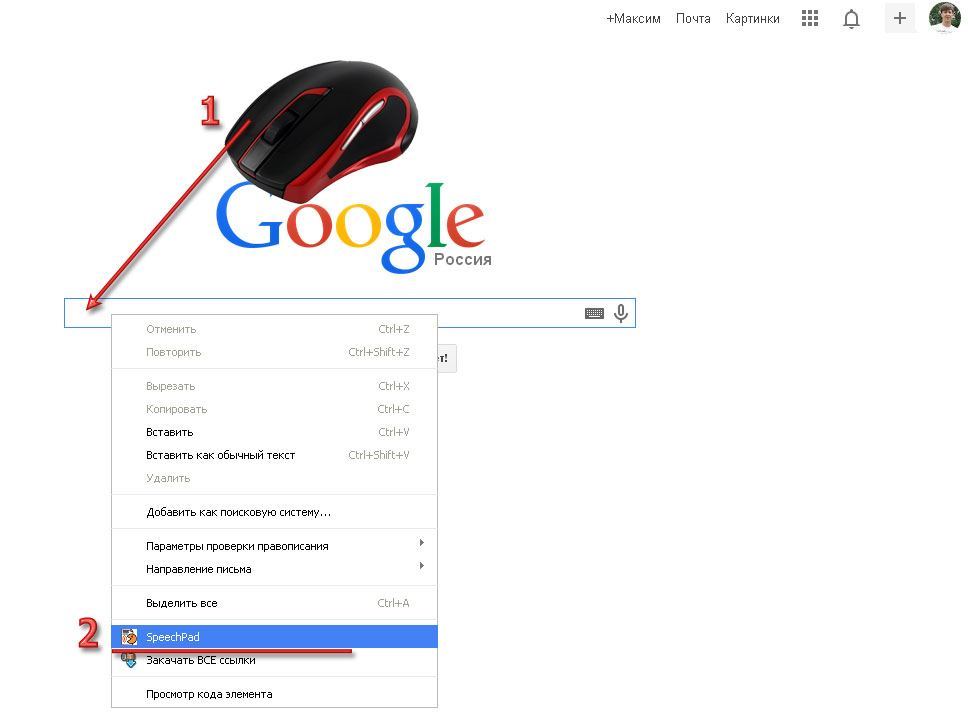
А если вам нужно надиктовать несколько предложение, к примеру, комментарий или сообщение на форуме, нужно выполнить следующие действия.
Нажать правую кнопку мышки рядом с полем для ввода и выбрать в контекстно-зависимом меню все тот же пункт «SpeechPad». Но на этот раз откроется новое окно и включится запись. Диктуйте текст, а затем используя буфер обмена перенесите текст в нужную форму.

Комбинация клавиш для работы с буфером обмена:
Ctrl+A – выделить текст
Ctrl+C – скопировать в буфер обмена
Ctrl+V – вставить из буфера обмена
Вот так вот без особых хитрых настроек, при наличии доступа в Интернет можно вводить текст голосом на компьютере. Качество распознания будет зависеть от микрофона и Вашей дикции.
А теперь разберём возможность перевода аудио в текст. Этот метод называется – транскрибация. Данный сервис позволяет переводить аудио в текст из звуковых и видео файлов. И опять же упор делается на хороший микрофон.
Но в технических характеристиках микрофонов я не разбирался, и говорить какой хороший а какой нет, не стану. Скажу лишь, что у меня был обычный настольный микрофон Genius и он меня устраивал. Ещё вчера я начал подготовку к данной статье с использование этого микрофона, ошибок при распознании голоса было не много. За ночь, наш домашний питомец (кот) совершил диверсию и перегрыз провод микрофона. Не подумайте, что только микрофона, — нет, не только.
И для продолжения подготовки к статье я воспользовался наушниками с микрофоном. И должен сказать, это просто земля и небо. Микрофон на наушниках, — это просто труба. Толи от старости, толи он такой убогий и был, ну это просто убийца нервных клеток. Так, что делайте выводы.
Ну, да ладно, давайте переходить в к выполнению поставленной задачи.