
Извлечение информации из корпуса
Лингвистическая информация из корпуса извлекается при помощи специальных компьютерных программ. Есть два основных источника разработки подобных программ.
Содержание
Методы извлечения информации из корпуса
Лингвистическая информация из корпуса извлекается при помощи специальных компьютерных программ. Есть два основных источника разработки подобных программ. Во- первых, это лингвистические отделы больших коммерческих проектов, в основном, связанных с публикацией словарей. Например, Cobuild Project. Часто это закрытое программное обеспечение, стоящее больших денег.
Второй источник разработки — компьютерная лингвистика и учёные, которые ей занимаются. В её рамках было создано немало программ, осуществляющих автоматический анализ грамматики и семантики, анализ и синтез текста, автоматический перевод и другие приложения для компьютерной обработки естественного языка. Конечно, не был обойдён стороной и анализ корпусов, в том числе, средства автоматической грамматической и синтаксической разметки — вероятностные (probabilistic), либо на основе правил (rule-based). Такие программы, разработанные самостоятельными исследовательскими группами (или даже отдельными учёными) часто бесплатны или вообще открыты для изучения (open source).
Применение конкорданса к редактированию перевода
Типы извлекаемой информации
Для поиска и извлечения информации из корпуса используется некоторое количество довольно стандартных процедур. Самый простой формат отображения информации о корпусе — это простые списки. Эти списки могут быть разных типов — от простых глоссариев до конкордансов. Давайте посмотрим на то, как всё это может быть представлено.
Списки слов и конкордансы
Часто нужно разобраться со словами, которые употребляются в тексте. Список слов (word list) в самой простой своей форме – это попросту список всех слов, содержащихся в исследуемом тексте. Многие программы создают лемматизированные (lemmatized) списки, в которых разные грамматические формы слова показаны, как одно слово. Например, goes и will go будут показаны в одной строке с go. Иногда программа позволяет создать список не только по словам, но и по словосочетаниям из двух или трёх слов.
Часто этот список отсортирован по частоте встречаемости слов или по алфавиту. Такой список даёт базу для терминологических исследований и позволяет составить глоссарий. Например, возьмём такой текст:
There are two possible approaches to automating the translation process:
Machine translation has been a Holy Grail of the IT industry for more than 40 years. There have been significant advances in language technology over this period and we all benefit from these on a day to day basis when we use spelling and grammar checkers and ever more sophisticated search engines.
One of the fundamental reasons why machine translation has not so far produced convincing results is that language is more than mere words and grammar. Language conveys meaning and until you can clearly define and understand what is being conveyed you cannot hope to translate it. A good test of a Machine Translation system is to translate the text into the target language and then back again — the results can be quite comical.
№1 Анализ терминологии переводимого текста с помощью конкорданса
Translation memory works by aligning previously translated text in a target language with the source language. This is accomplished either by the use of a manual tool, or automatically by using a controlled environment for the translation process. Alignment is usually done at a sentence level. This affords the best level of usable granularity. The aligned source and target text is held in a repository.
The next time the document is updated the repository is searched in order to locate any text that has not changed. Where such a sentence is identified the source language text can be replaced with the target language text.
This relatively low tech method can nevertheless provide benefits in terms of translation consistency and reduced costs.
Вот список всех словоформ или типов, которые встречаются в данном тексте, отсортированных по частоте:
| Ранг | Частота | Слово |
| 1 | 14 | the |
| 2 | 10 | is |
| 3 | 9 | a |
| 4 | 9 | and |
| 5 | 7 | language |
| 6 | 6 | of |
| 7 | 6 | text |
| 8 | 6 | translation |
| 9 | 5 | in |
| 10 | 5 | to |
| 11 | 4 | can |
| 12 | 4 | target |
| 13 | 3 | by |
| 14 | 3 | has |
| 15 | 3 | Machine |
| 16 | 3 | more |
| 17 | 3 | source |
| 18 | 3 | This |
| 19 | 3 | Translation |
В целом, в этом тексте 152 словоформы (types) и 259 словоупотреблений (tokens).
Уже по такому простому списку можно получить большое количество информации об употреблении слов в тексте. Например, можно видеть, что 10 самых частотных слов (the, is, a, and, language, of, text, translation, in, to) в целом соответствуют средним значениям для английского языка, за исключением появления трёх слов — language, text и translation. Здесь уже можно говорить о ключевых словах текста.
Однако, формат простого списка не даёт возможности снять полисемию и неоднозначность грамматического класса слова, поскольку это невозможно сделать без контекста. Чтобы разобраться с этим вопросом, нам нужно будет перейти к понятию «конкорданс» (concordance).
Конкорданс — это не просто список слов или словосочетаний. Его ценность в том, что он даёт контекст слова. То есть, мы можем запустить поиск и получить все появления данного конкретного слова в тексте. Результаты поиска показываются в формате, который называется KWIC (key word in context). Обычно при щелчке на строку программа-конкордансер выдаёт полный контекст.
Результаты поиска можно сортировать по-разному. Вы можете настроить программу на показ того или иного количества слов справа и слева от искомого термина. Также возможно изменять порядок строк конкорданса: например, если вы искали существительное, то можете попросить конкордансер, чтобы он отсортировал в алфавитном порядке слова, непосредственно предшествующие слову поиска. Это поможет вам найти подходящие прилагательные, которые можно употреблять со словом поиска. Таким образом можно, например, обнаружить, что справа от слова computer очень часто стоят слова hardware, software и problem.
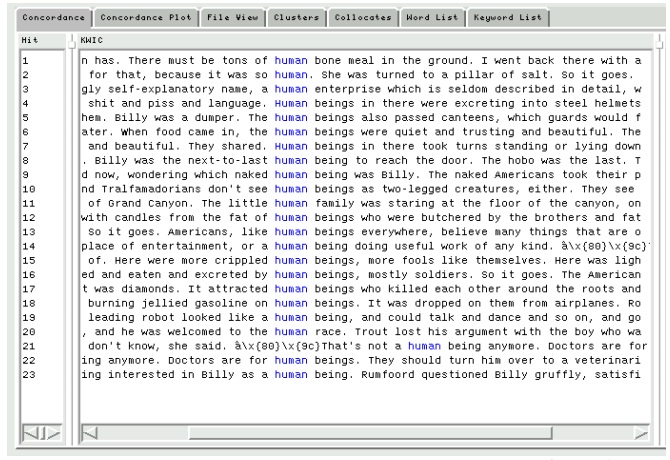
Конкорданс, сгенерированный программой AntConc по слову «human» (поиск по роману Курта Воннегута Slaughterhouse-Five)
Можно видеть, что конкордансы чрезвычайно полезны для изучения устойчивых словосочетаний (коллокаций). Мы можем искать типичные случаи употребления слов в одной коллокации.
Одной из наиболее распространённых программ-конкордансеров является WordSmith Tools1 Майка Скотта из Оксфордского университета, но она платная. Учитывая, что автор живёт в Великобритании, купить её в России затруднительно. Впрочем, можно скачать демонстрационную версию с ограниченными возможностями.
Практически ничем WordSmith не уступает бесплатный AntConc, разработанный японскими учёными2 . В нём реализованы все необходимые функции — список слов, конкорданс, поиск коллокаций. Отечественная лингвистика может гордиться разработками группы «Автоматическая обработка текста»3 , среди которых есть и доступный для свободного скачивания конкордансер Dialing Concordance (DDC). По возможностям он пока значительно уступает AntConc, но зато обладает встроенным морфологическим анализатором и способен понимать русское словоизменение, например, по запросу «студент», находить так же слова «студентов» и «студенткой». Недавно появился полностью свободный конкордансер Corsis1 (ранее назывался Tenka Text), который стремится стать полнофункциональной заменой для WordSmith Tools. Он разрабатывается в Германии.
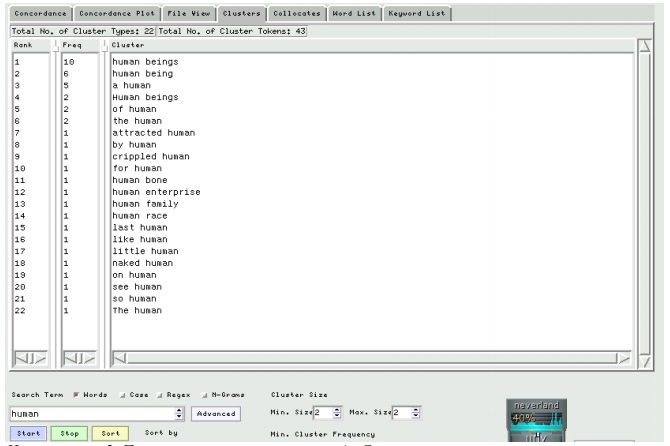
Поиск коллокаций в программе AntConc
Помимо конкордансов программы анализа корпусов обычно отображают и базовую статистическую информацию о корпусе: соотношение числа словоформ и словоупотреблений, среднюю длину предложения, количество предложений и их распределение по длине, индекс исключительности (каков процент слов, употреблявшихся лишь один раз), индекс постоянства (каков процент частых слов) и так далее.
Перед тем, как создавать свой корпус, будет небесполезно прочитать текст Джона Синклера «How to build a corpus», расположенный по адресу http://www.ahds.ac.uk/creating/guides/linguistic-corpora/appendix.htm
1. 1 http://www.lexically.net/wordsmith/
Курс «Корпусная лингвистика» (А.Б. Кутузов), ТюмГУ
Лицензия Creative commons Attribution Share-Alike 3.0 Unported

07.06.2016, 5940 просмотров.
Источник: myfilology.ru
Конкордансы и автоматические конкордансы.
Конкорданс – это список всех употреблений заданного языкового выражения (например, слова) в контексте, возможно, со ссылками на источник. В этом значении данный термин широко используется в корпусной лингвистике. Поиск в корпусе данных позволяет по любому слову построить конкорданс – список всех употреблений данного слова в контексте со ссылками на источник. Обычно конкордансом называют список примеров, полученных в результате поиска по корпусу интересующего пользователя языкового выражения со ссылками на источник.
В первом своем значении этот термин также употребляется для обозначения списка ключевых слов книги или работы, расположенных в алфавитном порядке, с их непосредственными контекстами.
Первый конкорданс, к Вульгате, был создан в 13 веке Хьюго де Сент-Шером (Hugues de Saint-Cher), которому помогали 500 монахов.
Именно из-за объёма работы по составлению конкордансов в докомпьютерные времена конкордансы были созданы только для трудов высочайшей важности – Вед, Библии, Корана или произведений У.Шекспира.
Даже с использованием компьютера создание конкорданса является трудоёмкой работой, так как конкордансы часто включают комментарии, определения слов или интертекстуальные ссылки – материалы, которые пока невозможно получить автоматически.
Двуязычные конкордансы – это конкордансы, основанные на параллельных текстах.
Конкорданс (в первом упомянутом значении) является одним из основных понятий корпусной лингвистики. Конкордансы часто используются в прикладной лингвистике: в лексикографии, при анализе текста, при обучении и изучении языка, при переводе.
Конкордансы используются для решения следующих лингвистических задач:
-сравнение различных использований одного слова,
-анализ ключевых слов,
-анализ частотности слов и словосочетаний,
-поиск и исследование фраз и идиом,
-поиск перевода, например, терминологии,
-создание списков слов (что используется при публикации).
Существуют специальные программы составления конкордансов по некоторому корпусу текстов, так называемые конкордансеры. Они позволяют получать частоту той или иной языковой единицы по произвольному корпусу текстов, список контекстов, в которых данная единица встретилась. Многие из них позволяют также сортировать контексты по ключевому слову (в исходной форме) или по словоформе, по ближайшему контексту.
Примеры конкордансов:
Словарь-конкорданс публицистики Ф.М. Достоевского http://dostoevskii.karelia.ru,
Nave’s Topical Bible http://www.biblestudytools.com/concordances/naves-topical-bible/
В российской лексикографической традиции практически отсутствуют словари конкордансов, являющиеся важным инструментом изучения языка писателя.
Конкорданс в лексикографии понимается пример употребления слова в контексте фиксированной длины.
Конкорданс – список словоформ встречающихся в тексте, расположенных в алфавитном порядке, слово даётся с его словесным окружением.
Словари конкордансов включают примеры употребления всех слов в отдельном произведении или во всем творчестве писателя. Известны словари-конкордансы к поэмам О. Мандельштама, к поэзии А. Пушкина. Относительно недавно опубликован конкорданс к русскому варианту библии. Устройство словаря-конкорданса довольно просто. Словарным входом служит словоформа.
Она помещается в центр строки и отделяется от текста примера дополнительными пробелами слева (разумеется, возможно, использование и других способов выделения). Пример имеет фиксированную длину, поэтому концы приводимого контекста обычно обрезаются. Пример сопровождается индексом, привязанным к какому-то достаточно полному изданию, что позволяет найти пример в тексте произведения.
Конкорданс — традиционный, давно известный, но до сих пор недостаточно оцененный способ изучения текста. Он дает полный индекс слов в ближайших и расширенных контекстах.
Вы хотите знать, что думал Достоевский о счастье? Для этого Вам достаточно открыть конкорданс любого произведения и выйти на все слова с морфемой «счаст».
Компьютерный конкорданс позволит Вам сравнить все контексты употребления слова, проанализировать их, увидеть слово в самом тексте художественного произведения. Это один из эффективных инструментов изучения литературного текста.
Система УНИЛЕКС-Т предназначена как для получения традиционных частотных словарей, словоуказателей и конкордансов, так и для формирования базы данных, позволяющей работать со словником и текстами в режиме «запрос — ответ», то есть в режиме Автоматического конкорданса. В системе не предусмотрено задание параметров для красивой (полиграфической) печати, поскольку основные пользователи системы — филологи-исследователи, для которых частотные словари, словоуказатели и конкордансы являются не конечным продуктом, предназначенным для издания, а промежуточными рабочими материалами. В частности, результаты обработки текста могут быть использованы в качестве заготовок словарных статей или как картотека при создании, пополнении или коррекции словаря, причем вход в картотеку возможен по разным параметрам: по словоформе, частоте словоформы, а при осуществлении лемматизации — дополнительно по лемме, частоте леммы и части речи. Система все же более ориентирована именно на конкордансы, но нет никаких принципиальных препятствий, которые мешали бы использовать ее только для получения частотных словарей.
Работу системы можно разделить на несколько этапов. Первый — первичная обработка текста, которая заключается в составлении словника по тексту, причем каждому слову приписываются адреса и ссылки на исходный текст.
После этого можно либо осуществить лемматизацию, которая припишет словоформам леммы (словарные формы) и части речи, либо обойтись без нее, то есть остаться только со словоформами.Следующий шаг — сортировка словника по алфавиту и подсчет частот для словоформ и, если они есть, для лемм.
Если пользователю не нужен диалоговый режим (автоматический конкорданс), то этим можно и ограничиться, разве что воспользоваться еще возможностью отсортировать словник по разным параметрам: по алфавиту (прямой и обратный словарь), по частоте, а если есть леммы и части речи, то по ним. Для получения словоуказателя или конкорданса по некоторому списку слов пользователь должен составить запрос по определенным правилам (если по всему словнику, то запрос не нужен).
Элементами запроса могут быть словоформы, леммы, части речи, адреса. Размер контекста задается или числом символов, или числом фрагментов (если текст фрагментирован). Так же можно получить и выборку из частотного словаря, при этом подсчитывается вторая относительная частота — относительно общего объема выборки. Мы, однако, рекомендуем загрузить словник в базу данных — это позволит работать в наиболее удобном для пользователя режиме: просматривать словник и контексты на экране и только то, что ему нужно, отправлять в отдельный список — файл.
Источник: poisk-ru.ru
Программа конкорданс что это
Concordance – гибкая система для анализа текстов, которая позволяет получить детальную информацию об электронных текстах и производить глубокий и всесторонний анализ текстов на других языках.
Условия распространения: Платная
Ссылка на скачивание: Скачать Сoncordance
Скриншот окна программы:

Подробное описание:
С помощью Concordance можно подсчитать количество слов и частотность для списка слов. Данный инструмент широко применяется при анализе текстовых данных, в науках, связанных с языками, лингвистике, для извлечения информации, лексикографии, переводе, а также в ряде других коммерческих областей и научных дисциплин.
Concordance может быстро построить соответствия с указанием контекста для каждого из слов, выполнить обработку текстов практически любых размеров. С помощью Concordance можно одновременно просматривать полный список слов, найденные соответствия и исходный текст, а также просматривать оригинальный текст, просто нажав на любое из слов, после чего будут показаны все появления данного слова в контексте. Возможен анализ текстов из любых других программ Windows посредством использования буфера обмена, либо заданием набора входных файлов.
Concordance реализует поиск веб-соответствий, конвертируя после этого результат анализа в HTML файлы, связанные между собой. Наличие списка выбора и « черного списка » позволяет задать слова, которые должны быть включены или исключены из вашего анализа. Concordance работает почти cо всеми языками, поддерживаемыми системой Windows.
Concordance позволяет выбрать вариант сортировки слов: поиск фраз, учет расстановки слов при поиске, а также использовать регулярные выражения для поиска. Просмотреть статистику по тексту можно по типу слов, процентному соотношению, количеству символов и предложений. Полностью поддерживается полноэкранный предпросмотр перед печатью и печать с контролем размера страниц, полей, заголовков, нижних колонтитулов и шрифтов. Concordance, пожалуй, наиболее гибкое и мощное аналитическое программное обеспечение для анализа текстов.
Источник: www.englishelp.ru
Программа конкорданс что это
Блог практических знаний о контент-анализе
Приветствую!
Меня зовут Алексей Рюмин. Вы находитесь на блоге практических знаний в области контент-анализа. Приятного прочтения материала!
Сложность материалов
- Уровень: простой
- Уровень: средний
- Уровень: сложный
Предложения и пожелания
Если у Вас есть предложения по новым публикациям на блоге или по уже опубликованным — буду рад их получить ПО ЭТОЙ ССЫЛКЕ
Отличный софт для контент-анализа

Нужен ли курс о Dedoose? Что такое Dedoose? ПОДРОБНЕЕ ТУТ
Ваши учебные проекты
Проконсультирую по практической части курсовых, дипломных и диссертационных работ, выполняемой методом контент-анализа.. Окажу помощь написании практической части курсовых, дипломных и диссертационных работ. По вопросам сотрудничества пишите через форму обратной связи.
Источник: content-analysis.ru
РКИ and EDUCATION TODAY
Новые технологии в образовании, русский язык как иностранный, когнитивная лингвистика, новости и последние исследования в области преподавания иностранных языков,психолингвистика, педагогический дизайн, digital humanities и second language acquisition.
Что такое «корпусный подход в изучении иностранного языка»?

Коллеги, а вы слышали о корпусной лингвистике и о корпусном подходе в изучении иностранного языка?
В англоязычной методике довольно распространен подход, который носит это название corpus-based language learning. В нашей методике преподавания как РКИ так и других иностранных языков только сейчас совершаются первые шаги в этом направлении.
Кроме этого, разрабатываются ресурсы для изучения русского языка, основанные на корпусных технологиях.
Лингвистика 21 века — это лингвистика корпусов, считают ученые. Действительно, корпусные технологии кардинально изменили ход языковых исследований, предоставили ученым доступ к большим текстовым данным.
А как корпуса повлияли на другую прикладную область лингвистики — преподавание языка?
Далее предлагаю вам прочитать краткую статью о корпусной лингвистике и об этом методе. Статью эту я нашла на сайте «Прикладная лингвистика» и ее автором является Соснина Е.П.
Корпусная лингвистика или корпусный подход в изучении РКИ и иностранных языков.
В настоящее время корпусы письменных и устных текстов успешно применяются при обучении иностранному языку и в лингвистической педагогике. В статье рассматривается «корпусный подход» (Corpus-Based Approach) в задачах, связанных с обучением иностранным языкам, указываются основные характеристики метода, определяющие его надежность и достоверность. Корпусный подход, или метод лингвистического исследования, основанный на корпусах текстов, ориентирован на прикладное изучение языка, его функционирование в реальных средах и текстах, что важно для преподавания языка.
Мировая практика развития этой области доказывает эффективность такого рода приложений, хотя в настоящее время возможности методов корпусной лингвистики в России пока не находят должной реализации в прикладной лингвистике, лингвистическом обучении, обучении родному и иностранному языку.
Определяются типы корпусов, которые возможно использовать в практике преподавания иностранных языков, приводятся примеры корпусов, доступных для рядового преподавателя иностранных языков. В данной статье в качестве примера рассматривается практическое использование параллельных корпусов в обучении языку и переводу, а также учебных корпусов в исследованиях, связанных с проблемами освоения иностранного языка. В докладе также раскрывается эффективность использования такого компьютерного обеспечения корпусной лингвистики как программ-конкордансов в лингвистических задачах, в том числе в «автоматизированном обучении» иностранным языкам. В заключении отмечаются реальные приложения корпусной лингвистики, метода корпусного анализа в лингвистических исследованиях и практике преподавания иностранного языка.
В настоящее время корпусы письменных и устных текстов успешно применяются при обучении иностранному языку и в лингвистической педагогике. На базе корпусов формируются списки активной лексики студентов, частотные списки терминов для использования в профессиональных курсах и т.п. Разработчики академических словарей и учебных пособий опираются на аутентичные массивы текстов (Corpora). Кроме того, коллекции, библиотеки и массивы текстов отражают реальное функционирование того или иного языка, а их перенос в компьютерные среды только активизировал их практическое и широкое использование в прикладной лингвистике [1].
Корпусная лингвистика дает материал для различного рода исследований языка и его вариантов, и определяет основной метод анализа текстов на базе корпусов (Corpus-Based Approach) [3]. Корпусный подход, или метод лингвистического исследования, основанный на корпусах текстов, ориентирован на прикладное изучение языка, его функционирование в реальных средах и текстах, что важно для преподавания языка. Например, лексикографический анализ на базе корпусов явно помогает раскрыть контекстное употребление тех или иных слов, особенно синонимичных (например, small/little, big/large), частотную сочетаемость их с другими словами, регулярность в тех или иных стилях, и четко определить их семантику.
Основные характеристики метода, определяющие его надежность и достоверность, следующие:
— является эмпирическим и анализирует реальные словоупотребления в естественной языковой среде,
— использует достаточно большую, репрезентативную подборку текстов,
— активно использует компьютеры и специальные программы-конкордансы для анализа в автоматическом и интерактивном режимах работы,
— базируется на методах статистического и качественного анализа текста,
— является целевым, т.е. должен быть ориентирован на реальное приложение и результаты.
Одной из важных особенностей метода анализа на базе корпусов текстов является исследование не только чисто лингвистических явлений (грамматических или лексических функций слов, их связей с другими лексемами), но и таких явлений, как, например, частотности лексем или грамматических конструкций в тех или иных жанрах, диалектах.
Электронные корпусы в языковом обучении
Электронные корпусы предоставляют богатый лингвистический материал для учебных и исследовательских целей. В настоящее время в Internet представлено множество классических электронных корпусов на иностранных языках. Наиболее известные из них Британский и Американский национальный корпусы английского языка, немецкоязычные корпуса LIMAS, COSMAS. Из наиболее доступных для рядового пользователя-преподавателя иностранных языков являются Gutenberg Texts, British National Corpus Sampler, The Longman Corpus, LIMAS [4, 5, 6, 7, 8], корпусы новостей Рейтер, электронные архивы крупных газет (например, The Times).
Что касается типологии корпусов текстов, то в прикладной лингвистике возможно использование таких типов как:
Исследовательские — для изучения различных аспектов функционирования языковой системы;
Иллюстративные, в том числе учебные (Learner Corpus) — для подтверждения и обоснования лингвистических фактов;
Мониторные — для исследования динамики языкового материала, проведения контент-анализа, например, корпус по публицистике;
Статические — для исследования стилей, например, авторские корпусы или корпусы текстов писателей;
Мультимедийные — текст + видео + аудио;
Корпусы параллельных текстов — для сопоставительного анализа текстов «оригинал-перевод» для обучения методам и приемам перевода. Существует две базовых формы организации таких корпусов: «оригинал-перевод/ы» (Unidirectional), «оригинал — перевод — обратный перевод» (Bidirectional or reciprocal), упорядоченные параллельно.
В данной статье в качестве примера мы рассмотрим практическое использование параллельных корпусов в обучении языку и учебных корпусов в исследованиях, связанных с проблемами освоения иностранного языка.
Параллельные корпусы в обучении языку и переводу
В методике обучения языку (грамматико-переводной метод) и методике обучения переводу интересным приложением является разработка параллельных электронных корпусов текстов (Parallel Corpora) и использование программ-конкордансов параллельных текстов [11]. Такие разработки в России находятся в стадии развития, хотя параллельные тексты давно используются для сопоставительного перевода и обучения.
В практическом смысле перевод должен ориентироваться на возможности постредактирования, сравнения и оценку различных стратегий и интерпретаций в рамках контекста. Переводчику (особенно начинающему) необходимы ресурсы, которые могли бы выступать эталонами перевода и оценке перевода в тех или иных «стандартных» условиях. По некоторым данным около 50%, а на начальном этапе обучения до 80% времени перевода тратится на обращение к реферативной информации, например, словарям. Электронные параллельные корпусы и лингвистические компьютерные технологии позволяют значительно сократить эти временные затраты и предоставляют образцы профессионального перевода при изучении приемов и способов перевода.
В настоящее время особенно распространены корпусы (или параллельные тексты) художественной литературы [2], хотя для обучения переводу в вузе следует разрабатывать корпусы разных жанров и стилей и в первую очередь ориентироваться на научно-технические, публицистические и деловые тексты.
Учебные корпусы в исследованиях по освоению языка
Под учебным корпусом (Learner Сorpus) понимается электронный корпус текстов группы лиц, изучающих иностранных язык. Основной целью организации учебных корпусов является их анализ на предмет выявления способов и эффективности освоения изучаемого языка (Language Acquisition).
Такого рода корпусы, например, могут быть использованы для лингвистического анализа на предмет выявления лексических или синтаксических ошибок при освоении иностранного языка. Такой подход помогает установить частотность тех или иных типов языковых ошибок, характерные контексты, что необходимо для выработки планов и методических приемов для дальнейшей коррекции в обучении языку.
Учебные корпусы наиболее распространены в Азии и Европе. Наиболее известным является международный англоязычный корпус ICLE (International Corpus of Learner English) эссе студентов продвинутого языкового уровня [10]. Этот корпус в основном используется для дискурсивного анализа и статистического анализа вокабуляра учеников, сопоставительных исследований. Данный корпус является показательным примером эффективности разработок в области корпусной и прикладной лингвистики.
Программы-конкордансы в прикладной лингвистике
В области прикладного языковедения конкордансы (Concordances) получили особое признание лингвистов благодаря новым возможностям эффективного исследования языка и обработки лексического материала текстов различного рода. В последнее время компьютерные конкордансы стали активно использоваться при автоматизированном обучении иностранным языкам (или CALL — Computer Assisted Language Learning).
Конкорданс-программа — это специальная программа обработки текста, которой ставится некоторая лингвистическая задача по поиску той или иной морфемы, слова или словосочетания в контексте. Например, в случае английского языка — найти в данной группе текстов варианты использования неопределенных артиклей или всех слов, оканчивающихся на «-ing». В результате работы программа-конкорданс выдаст все слова с данным окончанием вместе с контекстом, как правило — это строка текста.
Таким образом, преподаватель получает множество примеров как грамматической, так и лексической формы слова (в нашем примере это отглагольные существительные, герундий, форма глагола — причастие I и т.д.). Студент в свою очередь получает естественные примеры демонстрации тех или иных грамматических или лексических явлений, может самостоятельно проводить лингвистические исследования, заниматься НИР.
В разделе изучения грамматики иностранного языка студенту может предлагаться найти и проанализировать формы выражения и использования сложных врем?н (например, Perfect), модальные глаголы и их роль в предложении, место наречий в предложении, и т.п. В разделе лексики — например, найти и объяснить на примерах такие часто вызывающие трудности при использовании слова как MAKE/DO, RISE/RAISE, TELL/SAY, LIE/LAY и т.п. В разделе синтаксиса — например, исследовать пунктуацию того или иного языка и определить различия по сравнению с родным языком. Источниками для таких работ могут служить не только специальные корпусы электронных текстов, но и различные электронные издания, электронные библиотеки (например, в Internet).
В настоящее время конкордансы являются современным эффективным инструментом анализа текста, которые следует активно применять в практике преподавания языка и в лингвистических задачах.
Заключение
Анализ корпусов текстов, методы и наработки корпусной лингвистики являются перспективным направлением в области преподавания иностранных языков [12, 13]. Мировая практика развития этой области доказывает эффективность такого рода приложений, хотя в настоящее время возможности методов корпусной лингвистики в России пока не находят должной реализации в прикладной лингвистике, лингвистическом обучении, обучении родному и иностранному языку. На кафедре «Прикладная лингвистика» Ульяновского государственного технического университета проводятся исследования, связанные с разработкой учебного электронного корпуса письменных текстов начального уровня обучения иностранному языку, а также параллельного корпуса (англо-русского) газетных текстов для обучения переводу. Компьютерные конкордансы уже несколько лет используются на кафедре в учебном процессе для подготовки и написания рефератов, курсовых работ по иностранным языкам, а также для НИР студентов-лингвистов.
Источник: www.rki.today