
Elasticsearch Введение — 1.1 Основные понятия
В этом уроке мы сосредоточимся на основных концепциях Elasticsearch. Начать использовать Elasticsearch очень просто, большинство операций имеют настройки по умолчанию и их легко переопределить.
Elasticsearch — это нечто большее, чем просто поисковая система, она поддерживает сложные агрегации, геофильтры и список продолжается. И самое прекрасное это скорость получение запросов. Чтобы понять, как происходит эта магия, мы кратко рассмотрим, как Elasticsearch устроен внутри. И эти знания помогут нам лучше понять его сильные и слабые стороны. Не беспокойтесь, что Elasticsearch, как любой другой проект с открытым исходных кодом, очень быстро развивается, основные принципы все равно остаются неизменными.
Основные понятия Elasticsearch
Elasticsearch — высоко масштабируемая поисковая система с открытым исходным кодом. Хотя он начинался как текстовая поисковая система, сейчас он развивается как аналитический механизм, который может предоставить не только поиск, но и сложные агрегации. Поддержка таких функций, как автозаполнение, фильтры на основе геолокации, многоуровневая агрегация, а также удобство использования привели к приятия в масштабах всей отрасли. При этом я считаю, чтобы хорошо выполнить работу, важно иметь правильный инструмент и уметь его выбрать. Для этого в конце этого урока мы обсудим сильные и слабые стороны Elasticsearch.
ElasticSearch что это такое — ElasticSearch уроки
В этом разделе мы рассмотрим основные понятий и терминологию Elasticsearch. Начнем с основных моментов, вставка, обновление и поиск. Если вы знакомы с SQL, в таблицы ниже показаны эквивалентные термины в Elasticsearch.
| SQL | Elasticsearch |
| База данных | Индекс |
| Таблица | Тип |
| Ряд | Документа |
| Колонка | Поле |
Документ
В Elasticsearch данные хранятся в виде документов JSON ( Javascript Object Notation ). Большинство хранилищ данных NoSQL используют JSON для хранения своих данных, поскольку формат JSON очень лаконичный, гибкий и понятный людям. Документ в Elasticsearch очень похож на строку по сравнению с реляционной базой данных. Допустим, у нас есть таблица User со следующей информацией.
| id | name | age | gender | |
| 1 | Иван | 14 | m | [email protected] |
| 2 | Lena | 20 | f | [email protected] |
< «id»: 1, «name»: «Иван», «age»: 14, «gender»: «m», «email»: «[email protected]» >, < «id»: 2, «name»: «Лена», «age»: 20, «gender»: «f», «email»: «[email protected]» >
Кроме того Elasticsearch поддерживает хранение вложенных объектов:
ЧТО ТАКОЕ ELASTICSEARCH? ВВОДНЫЙ УРОК
< «id»: 2, «name»: «Лена», «age»: 20, «gender»: «f», «email»: «[email protected]», «address»: < «street»: «123 High Lane», «city»: «Big City», «state»: «Small State», «zip»: 12345 >>
Elascticsearch построен для обработки неструктурированных данных и может автоматически определять типы данных полей документа. Вы можете индексировать новые документы или добавлять новые поля без изменения схемы. Этот процесс также известен как динамическое отображение. Подробности обсудим на 3 уроке.
Индекс
Индекс похож на базу данных. Термин индекс не следует путать с индексом базы данных, как можно предложить если вы знакомы с реляционными базами данных. Индекс подразумевает логическую группировку Типов (таблиц). Имя индекса должно быть уникальным и состоять из строчных букв.
Тип
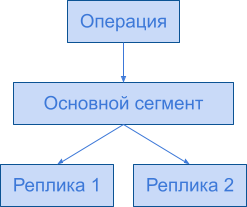
Тип похож на таблицу базы данных, индекс может иметь один или несколько типов. Тип — это логическое разделение различных видов данных. Например, если вы создаете приложение для блога, можно предложить создать тип для статей и комментариев.
Например тип для статей:
Тип для комментариев:
Мы также можем определить отношения между различными типами. Например, отношение между родителями и дочерними элементами может быть определено между статьями и комментариями. Статья (родитель) может иметь один или несколько комментариев (детей). Мы обсудим это в следующих уроках.
Кластер и узел
В традиционных базах данных обычно у нас есть только один сервер, обслуживающий все запросы. Elasticsearch — это распределенная система, что означает она состоит из одного или нескольких узлов, которые действуют как одно целое, что позволяет масштабировать и обрабатывать нагрузку, превышающую то, что может обработать один сервер. Каждый узел (сервер) имеет часть данных. Вы можете запустить Elasticsearch только с одним узлом, а затем добавить больше узлов или другими словами, масштабировать кластер, когда количество данных превышает возможности одного сервер.

На рисунке выше кластер имеет три узла с именами elasticsearch1, elasticsearch2, elasticsearch3. Эти три узла работают вместе, чтобы обрабатывать все запросы индексирования и извлечения данных. В зависимости от потребностей вашего приложения вы можете добавлять и удалять узлы (серверы) «на лету». Да и такая замечательная возможность есть в Elasticsearch мы обсудим это в следующих уроках.
Shard (осколок или шард)
Индекс представляет собой набор из одного или нескольких шардов. За счет чего Elasticsearch может хранить информацию объем которой превышает возможности одного сервера. Elasticsearch использует Apach Lucene для индексирования и обработки запросов. Шард — это не что иное, как экземпляр Apache Lucene. В следующих уроках мы обсудим почему именно Apache Lucene и как он используется в Elasticsearch.
Источник: codedzen.ru
Почему Elasticsearch — хороший выбор для сбора и анализа данных среднего объёма
Когда ваш бизнес предполагает анализ статистических данных, поступающих из разных источников, вам требуется эти данные собирать, хранить, индексировать, трансформировать в другие данные, анализировать и т. д.
Часто бывает так, что масштаб проекта ещё недостаточно велик для внедрения крупных программных платформ наподобие Hadoop, и в этом случае вам помогут универсальные варианты на базе стандартных NoSQL-решений, которые позволят справиться с накоплением и обработкой данных среднего объёма.
К таким решениям, исходя из нашей практики, относится Elasticsearch.
Что такое Elasticsearch
Elasticsearch — это представитель кластерных NoSQL с JSON REST API.
Мы можем считать его и нереляционным хранилищем документов в формате JSON, и поисковой системой на базе полнотекстового поиска Lucene.
Аппаратная платформа — Java Virtual Machine.
Официальные клиенты доступны на Java, NET (C#), Python, Groovy, JavaScript, PHP, Perl, Ruby.
Elasticsearch разрабатывается компанией Elastic вместе со связанными проектами, называемыми Elastic Stack, — Elasticsearch, Logstash, Beats и Kibana.
Beats — легковесные агенты и отправители данных с различных устройств. Logstash собирает и обрабатывает данные зарегистрированных событий. За хранение и поиск данных отвечает Elasticsearch. Kibana визуализирует данные через web-интерфейс.
Сегодня Elastic Stack с успехом используется сервисами eBay, Adobe, Uber, Nvidia, Blizzard, Citibank, Volkswagen, Microsoft, SoundCloud, GitHub, Netflix, Amazon. Чем же привлекателен Elasticsearch в контексте поставленной задачи? Давайте разберёмся.
Простой выбор
Одним из пунктов технического задания в рамках нашего проекта было требование собирать и анализировать статистику примерно с 25 (+/- 5) тысяч различных устройств.
Аппаратные возможности, операционные системы, сетевые интерфейсы, типы и назначение устройств неоднородны — от смартфона и телевизора до инфраструктурного сервера.
Устройства находятся в отдельных зданиях (примерно 1500 зданий, в каждом от 10 до 20 устройств), обслуживаются однотипной, но изолированной от других зданий инфраструктурой.
Оценив поставленную задачу, мы поняли, что нам не нужна большая суперсистема, которую можно отнести к категории BigData и/или HighLoad. С другой стороны, любые привычные методы сохранения и обработки информации, такие как запись в текстовый файл или SQL-базу, не подходили из-за объёма и специфики данных, поскольку большая часть работы происходила с логами устройств. Сыграло свою роль и наличие дополнительной статистики, которую сообщают сервисы, запущенные на устройствах.
Также в нашем случае по оценке объёма входящих данных, скорости их поступления и озвученных задач аналитики не было необходимости отдельно строить OLTP- и OLAP-системы.
Другими словами, система предполагает сбор статистики, к тому же она обеспечивает некоторое накопление данных и показ этой истории в удобном и интересном для менеджеров и аналитиков проекта виде. В результате мы выбрали Elasticsearch как оптимальное решение.
Да и Elastic Stack в целом предназначен для решения такого класса задач.
А что, собственно, собираем?
Как говорилось ранее, устройства разные, а вот статистическая информация нас, как правило, интересует достаточно однотипная: температура и загрузка процессора, объём потребляемой памяти, время и режимы использования устройства, какие программы запускались, сетевой трафик, сколько задач выполнено, что в логи записано, какие ошибки зарегистрированы и прочие данные с устройства и об устройстве.
Что на базе собранной информации хотят получить аналитики и менеджеры?
Самый частый из встречающихся сценариев — он же был изначально озвучен в техническом задании — это сбор и хранение всей (сырой) статистики по всем устройствам и сервисам за последний месяц с последующей агрегацией по дням и группировкой по зданиям с «бессрочным» хранением полученного результата.
Raw-индексы перезаписываются каждый месяц новыми данными, Agg-индексы накапливаются по дням «бесконечно» (пока хватает дискового пространства).
Все остальные пожелания по группировке и разбивке данных, по аналитическим срезам, визуальному представлению и т. п. выполняются аналитиками и менеджерами самостоятельно с использованием как Kibana, так и Power BI.
Периодически некоторые данные, чаще всего новые, получаемые из исходных, выделяются в отдельную задачу предварительного расчёта, которая выполняется с помощью вычислительной платформы Spark «по расписанию» и сохраняется в ещё один Agg-индекс, откуда эти подготовленные данные попадают в сложные отчёты и т. д.
Немного фактов о системе
Elasticsearch, как выяснилось, прекрасно подходит для работы в пределах определённого объёма данных (2–10 терабайт в год, 20–30 миллиардов документов в индексах), а также хорошо интегрируется с кластером Spark.
Агенты (Beats) помогают на конкретном устройстве или конкретном сервере собрать информацию, которая интересует пользователей системы. С помощью этих агентов можно собирать разного рода данные: системную информацию Windows из журнала, логи операционной системы Linux, данные устройства на ОС Android, самим анализировать трафик с устройства, будь то TCP, HTTP и т. д.
Локальный для инфраструктуры каждого здания Logstash отлично справляется с отправкой данных, собираемых агентами устройств, в централизованный кластер Elasticsearch, а Kibana предоставляет удобный способ построения веб-отчётов.
Необходимые инфраструктурные ресурсы
В нашем случае используется Linux-кластер в составе 3–10 нод.
Нода — это 8 процессорных ядер, 16–32 гигабайта оперативной памяти, жёсткий диск размером 1–5 терабайт. Сеть 1 Гигабит.
Масштабируемость
Данная подсистема статистики может работать с любой сферой деятельности, где требуется сбор и анализ статистических данных среднего объёма. Это может быть обработка статистической информации с 1 000 и до 30 000 холодильников, мобильных устройств, ноутбуков, интерактивных панелей и т. д.
Когда устройств меньше, чем 1–3 тысячи, система избыточна, есть более простые решения. Количество в 10 000–30 000 единиц оптимально по объёму и скорости появления новых данных с устройств.
50 и более тысяч устройств повлекут за собой усложнение системы, и в этом случае надо выбирать другое решение.
Хотя, если мы воспринимаем 50–100 тысяч устройств как три сегмента по 15–30 тысяч, то можно просто запустить три подсистемы нашей статистики.
Основная идея заключается в том, что чем более изолированы «сектора», тем проще применить решение формата «три по тридцать».
На примере проекта городского масштаба мы рассмотрели применение Elasticsearch для работы с большими данными, оценили его преимущества и целесообразность применения для задач, где массивные решения вроде Hadoop избыточны.
Источник: tproger.ru
Elasticsearch
Elasticsearch – это одна из самых популярных поисковых систем в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска.
Назначение и основные функциональные возможности
Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. ES является ядром ELK-стека (Elastic Stack), в состав которого, помимо Elasticsearch, входят следующие продукты [1]:
- Logstash– инструмент сбора, преобразования и сохранения в общем хранилище событий из различных источников (файлы, базы данных, логи и пр.) в реальном времени;
- Kibana– веб-интерфейс для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в его индексах ES через динамические панели мониторинга, таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени;
- FileBeat –агент на серверах для отправки различных типов оперативных данных в ES.
Из ключевых функциональных возможностей Elasticsearch стоит отметить следующие [2]:
- автоматическая индексация новыхJSON-объектов, которые загружаются в базу и сразу становятся доступными для поиска, за счет отсутствия схемы согласно типичной NoSQL-концепции. Это позволяет ускорить прототипирование поисковых Big Data решений.
- поддержка восточных языков (китайский, японский, корейский);
- гибкостьпоисковых фильтров, включая нечеткий поиск и мультиарендность, когда в рамках одного объекта ES можно динамически организовать несколько различных поисковых систем;
- наличие встроенных анализаторов текста позволяет Elasticsearch автоматически выполнять токенизацию, лемматизацию, стемминг и прочие преобразования для решения NLP-задач, связанных с поиском данных.
Основные достоинства и недостатки Elasticsearch описаны здесь. Подчеркнем, что одним из главных недостатков ES считается склонность этой NoSQL-СУБД к утечкам данных из-за отсутствия встроенных средств обеспечения информационной безопасности, таких как система авторизации и ограничения прав доступа. Кроме того, после установки движок по умолчанию связывается с портом 9200 на все доступные интерфейсы, что открывает доступ к базе данных [2]. Подробнее об уязвимостях Elasticsearch читайте нашу отдельную статью.
История разработки и развития Elasticsearch
Основными ключевыми вехами в истории Elasticsearch считаются следующие:
- февраль 2010 года – Шай Бейнон (Shay Banon) выпустил первую версию системы под лицензией Apache0 [1];
- 2012 год – для коммерциализации проекта Бейнон основал нидерландскую компанию Elasticsearch BV [1];
- июнь 2014 года – стартап привлек внешнее финансирование в размере $104 миллионов [1];
- март 2015 года – компания Elasticsearch изменила название на Elastic [1];
- 2018 год – компания Elastic открыла исходный код своего коммерческого продукта X-Pack, который расширяет возможности Elasticsearch, включая обеспечение cybersecurity [3];
- 2019 год – компания Elastic сделала базовые функции обеспечения информационной безопасности ELK-стека бесплатными для всех пользователей, а не только тех, кто подписан на коммерческой основе [4].
Архитектура и принципы работы ES
ES обеспечивает горизонтально масштабируемый поиск с поддержкой многопоточности. Система основана на библиотеке Apache Lucene, которая предназначена для индексирования и поиска информации в любом типе документов. Все функции Lucene доступны через API-интерфейсы на JSON и Java. ES позволяет работать с GET- запросами в реальном времени, но не поддерживает распределённые транзакции. Бесшовная интеграция с Kibana гарантирует легкую управляемость по HTTP-интерфейсу с помощью JSON-запросов за счет REST API.
В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер. Поисковые индексы можно разделить на сегменты, реплицировав каждый из которых несколько раз. Это обеспечивает отказоустойчивость системы. На узле ES-кластера может размещаться несколько сегментов.
Каждый узел кластера действует как координатор для делегирования операций правильному сегменту с автоматической перебалансировкой и маршрутизацией. Связанные данные часто хранятся в одном и том же индексе из одного или нескольких первичных сегментов и нескольких реплик. После создания индекса количество первичных сегментов нельзя изменить. Долгосрочное хранение индекса обеспечивает шлюз, позволяя восстанавливать индекс при сбое сервера [5].
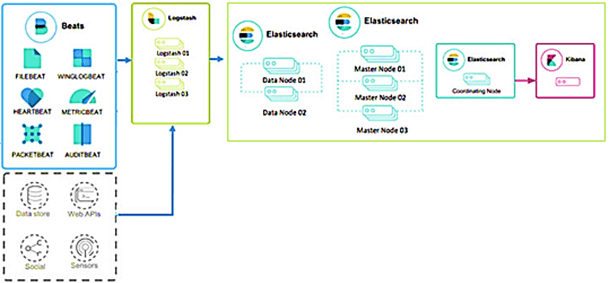
Где используется Elasticsearch: компании и Big Data проекты
Благодаря широкому набору функциональных возможностей, особенно полнотекстовому поиску по множеству языков и аналитике в реальном времени, Elasticsearch активно применяется в различных Big Data системах крупных и средних компаний по всему миру. Из наиболее известных зарубежных пользователей стоит отметить корпорации Netflix, IBM, Facebook, Amazon, GitHub, Wikimedia, CERN, Mozilla, Adobe [2]. В России ES применяется в проектах Альфа-Банка, облачной платформе автоматизации рекрутмента Potok.io, сети лабораторий «Центр молекулярной диагностики» (CMD), ИТ-компании «Инфотех-Групп» и многих других предприятий, о чем мы писали здесь.
Источники
- https://ru.wikipedia.org/wiki/Elasticsearch
- https://ru.bmstu.wiki/Elastic_Elasticsearch
- https://habr.com/ru/post/443528/
- https://www.elastic.co/blog/security-for-elasticsearch-is-now-free
- https://ru.bmstu.wiki/Elastic_Stack
Источник: www.bigdataschool.ru
Что такое Elasticsearch

Elasticsearch – это распределенный поисковый и аналитический движок на базе Apache Lucene. Вскоре после выпуска в 2010 году Elasticsearch стала самым популярным поисковым движком и обычно используется для таких примеров, как анализ журналов, полнотекстовый поиск, интеллектуальные системы безопасности, бизнес-аналитика и мониторинг текущих процессов.
21 января 2021 года Elastic NV объявила об изменении стратегии лицензирования программного обеспечения и о том, что новые версии Elasticsearch и Kibana под разрешительной лицензией Apache версии 2.0 (ALv2) выходить не будут. Вместо них предложены новые версии программного обеспечения по лицензии Elastic, а исходный код доступен по лицензии Elastic или SSPL. Эти лицензии не являются открытыми исходными кодами и не дают пользователям ту же свободу. Желая предоставить специалистам, которые работают с открытым исходным кодом, и нашим клиентам безопасный высококачественный комплект инструментов для поиска и аналитики с полностью открытым исходным кодом, мы создали проект OpenSearch – развиваемую сообществом ветвь открытого исходного кода Elasticsearch и Kibana с лицензией ALv2.
Как работает Elasticsearch?
Вы можете отправлять данные в Elasticsearch в виде документов JSON с помощью API или инструментов приема, таких как Logstash и Amazon Kinesis Firehose. Elasticsearch автоматически сохраняет исходный документ и добавляет ссылку на него в индекс кластера, включая возможность поиска. Следом можно найти и извлечь документ, используя API Elasticsearch. Также для визуализации данных и создания интерактивных панелей управления можно задействовать Kibana – инструмент визуализации с Elasticsearch.
Версии Elasticsearch с лицензией Apache 2.0 (до версии 7.10.2 и Kibana 7.10.2) можно запускать локально, на Amazon EC2 или в сервисе Amazon OpenSearch. При развертывании в локальной среде или на Amazon EC2 вы несете ответственность за установку Elasticsearch и другого необходимого программного обеспечения, подготовку инфраструктуры и управление кластером. С другой стороны, сервис Amazon OpenSearch – это полностью управляемый сервис, поэтому вам не нужно беспокоиться о трудоемком процессе управления кластерами и таких задачах, как подготовка оборудования, исправление программного обеспечения, восстановление после сбоев, резервное копирование и мониторинг.
Преимущества Elasticsearch
Выгодное соотношение цены и времени
Elasticsearch предлагает простые API на основе REST и легкий HTTP-интерфейс, а также использует документы JSON без схем, благодаря чему проще приступить к работе и быстро создавать приложения для различным примеров использования.
Высокая производительность
Распределенная система Elasticsearch позволяет параллельно обрабатывать большие объемы данных, мгновенно подбирая наилучшее соответствие к запросу.
Бесплатные инструменты и модули
Elasticsearch встроен в Kibana, популярный инструмент визуализации и составления отчетов. Доступна также интеграция с Beats и Logstash, при этом исходные данные легко преобразовывать и загрузить в кластер Elasticsearch. Можно использовать ряд подключаемых модулей Elasticsearch с открытым исходным кодом, таких как языковые анализаторы и механизмы рекомендаций, для более широкой функциональности ваших приложений.
Операции в режиме, близком к реальному времени
Выполнение операций в Elasticsearch, таких как чтение или запись данных, обычно занимает менее секунды. Это позволяет использовать его в таких примерах, где необходимо реагировать почти в режиме реального времени, например для мониторинга приложений и обнаружения аномалий.
Простая разработка приложений
Elasticsearch обеспечивает поддержку различных языков, включая Java, Python, PHP, JavaScript, Node.js, Ruby и многие другие.
Начало работы с Elasticsearch в AWS
Управление и масштабирование Elasticsearch может оказаться сложным и потребует знаний в области настройки и конфигурации Elasticsearch. Чтобы клиентам было легче запустить Elasticsearch с открытым исходным кодом, AWS предлагает Сервис Amazon OpenSearch для интерактивной аналитики журналов, мониторинга приложений в режиме реального времени, поиска по веб-сайтам и выполнения других задач.
Чтобы узнать больше о сервисе OpenSearch и способах его практического использования, перейдите по этой ссылке.
В состав OpenSearch входят некоторые фрагменты кода Elasticsearch, созданного Elasticsearch B.V. и распространяемого по лицензии Apache, а также фрагменты другого исходного кода. Elasticsearch B.V. не является источником другого исходного кода. ELASTICSEARCH является зарегистрированной торговой маркой Elasticsearch B.V.
Подробнее о ценах на Сервис Amazon OpenSearch
Готовы приступить к разработке?
Источник: aws.amazon.com
Без SQL: учимся работать с данными на Elasticsearch

Elasticsearch — это поисковый и аналитический движок, с помощью которого ваша команда может быстро искать информацию в любых типах данных и анализировать их.

Собираем на дрон для штурмовиков Николаевской области. Он поможет найти и уничтожить врага
Он позволяет управлять релевантностью результатов и проводить масштабирование.
Объемы данных растут все быстрее и быстрее. Их становится сложнее структурировать и выделять полезную информацию. Так реляционные базы данных отходят на задний план, а хранилища и поисковые системы без использования SQL становятся все популярнее.
Elasticsearch — это распределенный механизм на основе архитектуры RESTful. Наряду с Kibana, Beats и Logstash, Elasticsearch — это компонент комплекта приложений Elastic Stack, который дает возможность надежно и безопасно получать данные из любого источника и в любом формате, искать, анализировать и визуализировать данные в режиме реального времени.
С помощью Elasticsearch можно решать многие задачи:
УПРАВЛІННЯ КОМАНДОЮ
Зберіть свою команду мрії та ведіть її до спільної мети.

- добавить поле поиска на сайт или в приложение;
- хранить и анализировать журналы, метрики;
- автоматически моделировать поведение данных в режиме реального времени с помощью машинного обучения;
- автоматизировать рабочие процессы;
Кроме прочего, нужно сказать, что Elasticsearch — это программное обеспечение с открытым исходным кодом, которое распространяется бесплатно.
Хранение и поиск данных
Документы
Elasticsearch предназначен для работы с большими объемами данных, которые могут быть как структурированными, так и неструктурированными.
Он не хранит данные в реляционной БД. Для этого понадобилось бы много разных таблиц и связей между ними. Не говоря уже о том, что при появлении каждого нового типа данных пришлось бы выполнять уйму работы, чтобы внести изменения.
Вместо этого информация хранится в виде сериализованных документов JSON. Этот формат позволяет хранить произвольные структуры данных.
Например, коллекцию сериалов можно представить так:
| В СУБД | В виде объектов |
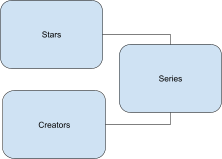 |
 |
В формате JSON эти объекты записываются просто:

Удобно, что пользователи сами могут определять структуру данных в документах. Из них проще извлекать информацию, и их можно легко менять.
Поиск
В руководстве по Elasticsearch утверждается, что полнотекстовый поиск осуществляется в течение одной секунды. Если Elasticsearch работает с большим объемом данных, как ему удается проводить поиск по всему их тексту в режиме, близкому к реальному времени?
Это возможно благодаря использованию обратного индекса. При индексировании составляется список уникальных слов, встречающихся во всех документах, со ссылками на документы, в которых содержится каждое слово. Поэтому Elasticsearch создан на базе библиотеки для полнотекстового поиска Apache Lucene, в которой используется обратный индекс.
Поиск с помощью Elasticsearch
Elasticsearch не зависит от схем данных. Когда включено динамическое связывание типов, Elasticsearch автоматически выявляет и добавляет в индекс новые поля, распознавая целые и дробные числа, строки, булевские значения и даты.
При необходимости можно определить правила для динамического связывания. Это позволит анализировать текст в зависимости от языка, на котором он написан, использовать пользовательские форматы дат, отличать полнотекстовые строки от строк с точными значениями и распознавать форматы, которые не могут быть распознаны автоматически.
Кроме того, одно и то же поле можно проиндексировать по-разному для разных целей, например, для полнотекстового поиска и в качестве тега.
Индекс
Elasticsearch использует индекс Lucene, который напоминает базу данных: данные находятся в пространстве имен и для их упорядочения используется схема. По своей сути индекс представляет собой логическую группу, состоящую из одного или нескольких физических сегментов (shards), которые являются экземплярами Lucene.
В результате распределения документов между сегментами и распределения сегментов между узлами обеспечивается отказоустойчивость, благодаря которой вы защищены от сбоев аппаратного обеспечения.
Давайте сравним Elasticsearch, MongoDB и PostgreSQL с точки зрения возможностей, обеспечиваемых индексом.
| Elasticsearch | MongoDB | PostgreSQL |
| Поисковик | Хранилище документов | База данных |
| Документы JSON со связями (mappings) в индексе | Документы BSON в коллекциях | Данные в таблицах |
| Одна запись, много чтений. Высокая скорость поиска | Высокая эффективность операций, связанных с записью | Высокая эффективность операций, связанных с записью |
| Гибкая схема | Гибкая схема | Схема обязательна, что дает возможность проводить операции, которые иначе было бы невозможно провести |
Если имеется большой объем данных, использование распределенного индекса снижает нагрузку на систему. Она работает не с большим объемом данных, а со сравнительно небольшими индексами.
Поэтому в Elasticsearch предусмотрена возможность регулировать количество сегментов в параметре index.number_of_shards . По умолчанию его значение равно 5, но вы можете изменить его в зависимости от того, сколько сегментов будет участвовать в поиске.
Кроме того, следует учесть, что по мере заполнения данными Elasticsearch объединяет малые сегменты в большие, поэтому нужно следить за тем, чтобы они не становились слишком крупными и не снижали эффективность работы.
Сегменты бывают первичными и реплицированными. Реплицированный сегмент — это копия первичного сегмента. Реплики обеспечивают избыточность и защищают оборудование от сбоев, а также повышают скорость обработки запросов. Вы можете в любой момент изменить количество реплик, но количество первичных сегментов фиксируется на момент создания индекса.
Масштабирование
Elasticsearch — распределенная система. В ней разделены не только индексы. Сегменты хранятся на отдельных машинах, которые называют узлами. В свою очередь, узлы объединяются в кластеры.
Когда нагрузка возрастает, Elasticsearch добавляет узлы в кластер и автоматически распределяет нагрузку между всеми доступными узлами. По мере добавления узлов в кластер растет и скорость выполнения запросов. В результате ваше приложение не перегружается и в то же время обеспечивается его доступность и масштабируемость. Когда же нагрузка спадает, количество узлов уменьшается и нагрузка перераспределяется. Такой вид масштабирования называется горизонтальным.
Кластеры и управление ими
Чтобы получать информацию из распределенной системы, масштаб которой со временем изменяется, нужно определять, когда и к каким сегментам следует обращаться. Поэтому узлы данных объединяются в кластеры, где существуют также координирующие узлы, которые выполняют именно эту функцию.
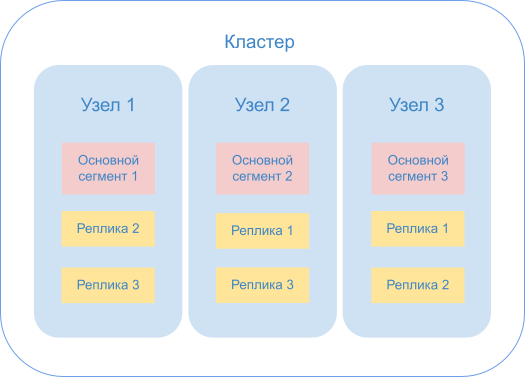
Кластер — это группа узлов с одним и тем же значением атрибута cluster.name . Если запущен один экземпляр Elasticsearch, то кластер состоит из единственного узла. Все первичные узлы находятся на нем, и он готов к использованию. Но создать на нем реплицированные сегменты невозможно, поэтому в случае сбоя могут быть потеряны данные.
Добавление узлов в кластер повышает его емкость и надежность. Когда в кластер добавляется узел, реплицированные сегменты выделяются автоматически, и его отказоустойчивость повышается.
По умолчанию добавляемый узел может быть как узлом данных, так и master-узлом, который управляет кластером. Рекомендуем помещать в кластер небольшое фиксированное количество узлов, которые могут быть выбраны основными ( master-eligible nodes ). Такие узлы отвечают, например, за создание или удаление индекса, отслеживание узлов, которые входят в кластер, и принятие решений о распределении сегментов между узлами. Добавлять же в кластер лучше те узлы данных, которые не могут быть выбраны основными.
Основные узлы обеспечивают управление кластером и позволяют избежать конфликтов между координирующими узлами, например, в случае перемещения сегментов с узла на узел. Поскольку у них есть вся информация о состоянии кластера, таким узлам требуется повышенный объем ресурсов и стабильное оборудование.
Репликация данных
Если данные только в одном экземпляре, то существует возможность их потерять, если откажет узел, на котором они хранятся. Чтобы избежать этого, создаются реплики на других узлах. В отличие от резервных копий — это полные копии всех данных.
Когда используются реплики, запись данных производится сначала в первичный сегмент, а уже после слияния и фиксации в Lucene изменяются все реплики.
Чтобы не потерять данные, лучше создать реплики
Для обеспечения отказоустойчивости нужно создать реплику каждого сегмента. Общее количество реплик должно быть не меньше количества узлов данных. Тогда при отказе одного узла можно будет пользоваться репликой данных на другом узле во время восстановления поврежденного. Чтобы использовать реплики эффективно, можно указать их количество в параметре number_of_replicas .
Отказоустойчивость
Мы рассмотрели, как обеспечить отказоустойчивость в случае отказа узла данных. Но как обезопасить систему на случай сбоя основного узла? Ведь его потеря приведет к тому, что весь кластер перестанет быть работоспособным.
На этот случай можно создать несколько основных узлов. На роль основного узла могут претендовать узлы, которые могут быть выбраны основными.
Когда отказывает один такой узел, новым основным узлом будет выбран тот, который обладает самой актуальной информацией о кластере. Выбор делается при достижении кворума во время голосования узлов, которые имеют право голоса. Он должен быть нечетным и составлять 50% + 1 голос.
В голосовании участвуют узлы, для которых в конфигурации указано значение параметра node.voting_only: true . Это узлы, которые предназначены только для голосования. Конфигурация голосования изменяется автоматически, и нужно следить за тем, чтобы включенных узлов было не меньше тех, которые составили бы кворум (контрольное количество голосующих).
Взаимодействие
Для взаимодействия с кластером извне и для взаимодействия узлов между собой используются различные протоколы, которые мы сравнили в таблице ниже.
API можно вызывать синхронно и асинхронно.
Частый запуск и остановка клиентов узлов приводит к лишнему «шуму» в кластере.
Также существуют отдельные библиотеки для:
- JavaScript (только поиск для приложений);
- Node.js (поисковый клиент для приложений и рабочего места);
- PHP (только поиск для приложений);
- Python (клиент для корпоративного поиска);
- Ruby (клиент для корпоративного поиска).
Заключение
Эффективность Elasticsearch как поискового движка обеспечивается благодаря обратному индексу и распределению данных. По мере увеличения или уменьшения их объема он удобно масштабируется, вы можете не переживать о потере данных — они надежно защищены с помощью реплик и избыточных узлов.
Источник: highload.today