
Системы машинного перевода — это системы, которые предназначены для перевода текстов (письменных, а иногда и в устном формате) с одних естественных языков на другие с помощью специальной компьютерной программы.
Введение
Следует заметить, что за последние десятилетия технологии машинного перевода, а также искусственного интеллекта, в целом, осуществили громаднейший шаг вперед. Уже мало кого можно удивить словосочетанием «нейронная сеть» или «самообучающаяся система». Тем не менее так было далеко не всегда, поскольку в течение долгого времени ученые предпринимали попытки создания механизма перевода с одного естественного (это обстоятельство является важным условием в определении машинного перевода) языка на другой, но эти попытки оказывались безуспешными.
Сдай на права пока
учишься в ВУЗе
Вся теория в удобном приложении. Выбери инструктора и начни заниматься!
Начало было положено в тридцатые годы прошлого века, когда советский ученый П. П. Смирнов-Троянский смог представить Академии наук СССР созданную им «машину для подбора и печатания слов при переводе с одного языка на другой». Машина представляла собой стол, перед которым располагался фотоаппарат, который был синхронизирован с печатной машинкой. На поверхности стола располагалось «глоссарное поле», то есть, свободно передвигающаяся пластина с нанесенными на нее словами на трех и более языках.
Машинный перевод
Оператор выполнял фотографирование карточки, соответствующей определенному слову, а на печатной машинке должен был набрать его морфологическую информацию, то есть, часть речи, число, падеж и так далее. Лента печатной машинки и пленка камеры должны были выходить одновременно. Так получалась совокупность кадров со словами и их морфологией.
А далее лингвисты должны были превратить совокупность фотографий в связный литературный текст. То есть, для того чтобы переводить тексты, и оператору, и лингвистам достаточно было владеть только своим родным языком.
«Системы машинного перевода»
Готовые курсовые работы и рефераты
Решение учебных вопросов в 2 клика
Помощь в написании учебной работы
Системы машинного перевода
Системы машинного перевода подразделяются на следующие категории:
- Категория систем, выполненных на базе грамматических правил RBMT (Rule-Based Machine Translation).
- Категория статистических систем SMT (Statistical Machine Translation).
- Категория гибридных систем, сочетающих в себе преимущества первых двух групп.
- Уже существует еще один, сравнительно новый вид машинного перевода, а именно, нейронный.
Системы RBMT способны анализировать текст и выполнять его перевод на основе встроенных словарей и совокупности грамматических правил для выбранной языковой пары. ПРОМТ и Systran могут считаться наиболее известными примерами систем RBMT. Качественный уровень перевода таких систем оставляет желать лучшего, но они и по сегодняшний день все еще применяются. К примеру, во всем известных переводах названий товаров на Aliexpress.
Компьютерная лингвистика №6: машинный перевод
К числу достоинств систем RBMT следует отнести морфологическую точность (слова при переводе не путаются), повторяемость (наличие всегда одинакового результата перевода) и возможность настройки системы под выбранную предметную область (возможность обучить специальным терминам).
В системах SMT используется принцип статистического анализа, что означает загрузку в систему огромных объемов текстов на исходном языке и их переводов, выполненных специалистами. Программа способна анализировать статистику межъязыковых соответствий, синтаксических конструкций и тому подобное, а далее может опираться на нее при подборе вариантов перевода. Такие процедуры по сути представляют собой самообучение.
В этом плане уже уместно отметить наличие возможности нейронного машинного перевода NMT (Neural Machine Translation), так как самообучение считается характерным, прежде всего, для перевода на основе нейронных сетей. Этот вид перевода берет свое начало еще с середины девяностых годов прошлого века, а сегодня считается главным типом машинного перевода.
Нейронная сеть является математической моделью, построенной по принципу сетей нервных клеток живых организмов. Наличие возможности обучения может считаться одним из основных достоинств нейронных сетей в сравнении с традиционными алгоритмами перевода. Нейронную систему способен обучить и человек, путем корректировок итоговых результатов перевода. Именно по такому принципу и работают онлайн-переводчики Яндекс и Google. Благодаря наличию самообучения качественный уровень перевода у них возрастает после каждого нового переведенного текста.
В середине двухтысячных годов широкую известность получило «глубинное обучение» (Deep learning). Главным его отличием от стандартных нейронных сетей является тот факт, что его сети обучаются обнаруживать набор характерных свойств объектов, не вдаваясь в мелкие подробности их происхождения. Таким образом, при данном типе перевода независимо друг от друга функционирует следующая пара механизмов:
- В начале одна нейронная сеть выполняет кодирование текста на базе каких-либо характеристик.
- Далее вторая нейронная сеть осуществляет декодирование их в текст переводного языка.
Здесь уместно вспомнить известный принцип, что следует переводить смыслы, а не слова.
За последние годы нейронные сети сумели превзойти все, что было изобретено в сфере перевода за последние двадцать лет. Они даже сумели освоить согласование родов и падежей в различных языках. Помимо этого, впервые стал возможен прямой перевод между языками, у которых не было раньше ни одного общего словаря. До этого методы статистического перевода практически всегда должны были работать через английский язык. Для нейронного перевода это уже не требуется.
В 2016-ом году Google запустил систему нейронного перевода девяти языков между собой, а в 2017-ом году в неее был добавлен и русский язык. Специалисты Google разработали собственную систему, которая получила название Google Neural Machine Translation (GNMT). Система GNMT способна улучшить качество перевода, используя метод машинного перевода на базе примеров EBMT(Example-based machine translation). Это означает, что система обучается на основе аналогии, используя базу примеров переводов, выполненных людьми.
Источник: spravochnick.ru
Что такое машинный перевод?

Машинный перевод – это процесс автоматического перевода текстов с одного языка на другой с помощью искусственного интеллекта и без вмешательства со стороны человека. Современный машинный перевод превосходит возможности обычного дословного перевода – он способен передать полный смысл заложенной в исходном тексте информации на целевой язык. Он анализирует все текстовые элементы и определяет, как слова влияют друг на друга.
Каковы преимущества машинного перевода?
Переводчики используют сервисы машинного перевода, чтобы переводить быстрее и эффективнее. Ниже представлены некоторые преимущества машинного перевода.
Сервисы автоматического перевода
Машинный перевод является хорошей отправной точкой для профессиональных переводчиков. Многие системы управления переводами интегрируют в свой рабочий процесс одну или несколько моделей машинного перевода. Они выполняют автоматический перевод текста, а затем человек-переводчик занимается его постредактированием.
Высокая скорость перевода
Машинный перевод работает очень быстро, переводя миллионы слов всего за несколько секунд. С его помощью можно переводить большое количество таких данных, как сообщения в чатах в реальном времени или материалы крупномасштабных судебных дел. Кроме того, машинный перевод позволяет обрабатывать документы на иностранном языке, находить актуальные термины и запоминать, чтобы применять их в будущем.
Большой выбор языков
Многие крупные поставщики услуг машинного перевода поддерживают от 50 до более 100 языков. Кроме того, переводы могут осуществляться на несколько языков одновременно, что полезно для выпуска продуктов на международном рынке и обновления документации.
Экономичность
Машинный перевод позволяет повысить производительность и предоставляет возможность быстро выполнять переводы, сокращая время их выхода на рынок. Человеку не нужно вмешиваться в работу систем перевода, так как они могут обеспечивать элементарный перевод приемлемого качества. Это снижает затраты и ускоряет процесс перевода. Например, для крупных проектов можно интегрировать машинный перевод с системами управления контентом, чтобы автоматически маркировать и упорядочивать контент, перед тем как переводить его на другой язык.
Какие существуют варианты использования машинного перевода?
Ниже представлены несколько примеров использования машинного перевода.
Внутренняя коммуникация
Компаниям, действующим в разных странах по всему миру, сложно управлять коммуникациями. Сотрудники обладают разными языковыми навыками или могут не владеть официальным языком компании на приемлемом уровне. Машинный перевод позволяет устранить языковые барьеры в общении. С его помощью можно быстро получить перевод текста и понять его основной смысл. Его можно использовать для перевода презентаций, бюллетеней и других распространенных коммуникационных материалов.
Внешняя коммуникация
Компании пользуются услугами машинного перевода, чтобы поддерживать эффективную связь с внешними заинтересованными сторонами и клиентами. Например, переводят важные документы для международных партнеров и клиентов на различные языки. С помощью машинного перевода можно переводить отзывы на продукты онлайн-магазинов, работающих на международных рынках, чтобы клиенты могли ознакомиться с ними на своем родном языке.
Анализ данных
Некоторые виды машинного перевода могут обрабатывать миллионы пользовательских комментариев и предоставлять высокоточные результаты в короткие сроки. Ежедневно компании выполняют перевод большого количества контента, размещенного в социальных сетях и на веб-сайтах, для сбора аналитики. Например, они могут автоматически анализировать отзывы клиентов, написанные на разных языках.
Онлайн-обслуживание клиентов
Бренды могут взаимодействовать с клиентами со всего мира, говорящими на разных языках. Например, они могут использовать машинный перевод, чтобы:
- качественно переводить запросы клиентов со всего мира;
- расширить возможности чата в режиме реального времени и автоматизировать отправку электронных писем клиентам;
- улучшить качество обслуживания клиентов без необходимости набора новых сотрудников.
Правовые исследования
Юристы используют машинный перевод для подготовки правовых документов разных стран. Машинный перевод предоставляет возможность анализировать большое количество материалов, которые было бы сложно обработать на иностранном языке.
Как развивался машинный перевод?
Идея использовать компьютеры для автоматического перевода текстов на естественном языке впервые появилась в начале 1950-х годов. Однако в то время сложность перевода была намного выше, чем предполагали ученые. Чтобы реализовать технологию машинного перевода, компьютерам того времени недоставало вычислительной мощности для обработки и хранения данных.
И только в начале 2000-х компьютерное программное обеспечение, технологии хранения данных и аппаратное оборудование стали соответствовать требованиям машинного перевода. На стадии ранних разработок использовались статистические базы данных языков, которые должны были обучать компьютеры переводу текста. Это требовало большого количества ручного труда и времени. Для каждого нового языка им приходилось разрабатывать новую базу данных. С тех пор машинный перевод стал более быстрым и точным, а также появилось несколько различных стратегий машинного перевода.
Какие существуют подходы к машинному переводу?
В машинном переводе исходный текст или язык называется исходным, а язык, на который выполняется перевод, – целевым. Процесс машинного перевода осуществляется в два этапа:
- декодирование значения исходного текста на языке оригинала;
- передача смысла на целевой язык.
Машинный перевод
Системы машинного перевода — это приложения или интерактивные сервисы, использующие технологии машинного обучения для перевода больших объемов текста с любого из поддерживаемых языков. Служба переводит текст «источника» с одного языка на другой «целевой» язык.
Хотя понятия, лежащие в основе технологии машинного перевода и интерфейсов для ее использования, сравнительно просты, Наука и технологии, лежащие в ее составе, чрезвычайно сложны и объединяют несколько передовых технологий, в частности, глубокое обучение ( искусственный интеллект), большие данные, лингвистика, облачные вычисления и веб-интерфейсы API.
С начала 2010 года, новые технологии искусственного интеллекта, глубокие нейронные сети (ака глубокого обучения), позволило технологии распознавания речи, чтобы достичь уровня качества, что позволило команде Microsoft Translator объединить распознавание речи с его Основные технологии перевода текста для запуска новой технологии перевода речи.
Исторически сложилось так, что основным методом машинного обучения, используемым в промышленности, был Статистический машинный перевод (SMT). SMT использует расширенный статистический анализ для оценки наилучших возможных переводов для слова, учитывая контекст нескольких слов. SMT используется с середины 2000-х годов всеми основными поставщиками услуг перевода, включая Microsoft.
Появление нейронного машинного перевода (NMT) привело к радикальному сдвигу в технологии перевода, что привело к гораздо более качественным переводам. Эта технология перевода начала внедряться для пользователей и разработчиков в Последняя часть 2016.
Технологии перевода SMT и NMT имеют два общих элемента:
- Оба требуют большого количества предварительно человека переведенного содержания (до миллионов переведенных предложений) для обучения систем.
- Ни выступать в качестве двуязычных словарей, переводить слова на основе списка потенциальных переводов, но перевести на основе контекста слово, которое используется в предложении.
Что такое переводчик?
Услуги переводчика и речи, часть Когнитивные услуги Коллекция API, являются службами машинного перевода от корпорации Майкрософт.
Перевод текста
Переводчик используется группами Microsoft с 2007 года и доступен в качестве API для клиентов с 2011 года. Переводчик широко используется в Microsoft. Он включен в группы локализации продуктов, поддержки и онлайн-коммуникаций. Эта же служба также доступна без дополнительной платы из знакомых продуктов Майкрософт, таких как Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypeи Yammer.
Переводчик может быть использован в веб-приложениях или клиентских приложениях на любой аппаратной платформе и с любой операционной системой для выполнения перевода на язык и других связанных с языком операций, таких как обнаружение языка, текст в речь или словарь.
Используя стандартную технологию REST для промышленности, разработчик отправляет в службу исходный текст (или аудио для перевода речи) с параметром, указывающим на целевой язык, и служба отправляет обратно переведенный текст для использования клиентом или веб-приложением.
Служба Переводчика — это служба Azure, размещенная в центрах обработки данных Майкрософт, и получает выгоду от безопасности, масштабируемости, надежности и непрекращаемости доступности, которую также получают другие облачные службы Майкрософт.
Перевод речи
Технология перевода речи переводчика была запущена в конце 2014 года, начиная с Skype Translator, и доступна в качестве открытого API для клиентов с начала 2016 года. Он интегрирован в функцию Microsoft Translator live, Skype, трансляцию встреч Skype и приложения Microsoft Translator для Android и iOS.
Речевой перевод теперь доступен через Microsoft Speech, сквозной набор полностью настраиваемых сервисов для распознавания речи, перевода речи и синтеза речи (text-to-speech).
Как работает перевод текста?
Есть две основные технологии, используемые для перевода текста: наследие один, Статистический машинный перевод (SMT), и более новое поколение 1, нейронные машины перевода (NMT).
Статистический машинный перевод
Внедрение переводчиком статистического машинного перевода (SMT) основано на более чем десятилетних исследованиях на естественном языке в корпорации Майкрософт. Вместо того, чтобы писать правила ручной работы для перевода между языками, современные системы перевода подходят к переводу как к проблеме изучения преобразования текста между языками из существующих человеческих переводов и использования последних достижений в области прикладной статистики и машинного обучения.
Так называемая «параллельная corpora» выступает в качестве современного Розеттского камня в огромных пропорциях, обеспечивая слово, фразу и идиоматические переводы в контексте для многих языковых пар и доменов. Методы статистического моделирования и эффективные алгоритмы помогают компьютеру решить проблему расшифровки (обнаружение соответствия между исходным и целевым языком в обучающих данных) и расшифровки (нахождение наилучшего перевода нового предложения ввода). Переводчик объединяет силу статистических методов с лингвистической информацией для создания моделей, которые лучше обобщают и ведут к более понятным переводам.
Из-за такого подхода, который не полагается на словари или грамматические правила, он обеспечивает лучшие переводы фраз, где он может использовать контекст вокруг данного слова по сравнению с попыткой выполнить одно слово переводы. Для переводов на отдельные слова, двуязычный словарь был разработан и доступен через www.Bing.com/Translator.
Перевод нейронных машин
Непрерывные улучшения в переводе имеют важное значение. Тем не менее, с середины 2010-х годов улучшилась производительность с помощью технологии SMT. Используя масштаб и мощь суперкомпьютера ИИ от Microsoft, в частности, Microsoft Cognitive Toolkit, Переводчик теперь предлагает нейронную сеть (LSTM) на основе перевода, что позволяет новое десятилетие улучшения качества перевода.
Эти модели нейронных сетей доступны для всех языков речи через службу speech на Azure и через текстовый API с помощью идентификатора категории «generalnn».
Переводы нейронных сетей принципиально различаются в том, как они выполняются по сравнению с традиционными SMT.
Следующая анимация изображает различные шаги нейронной сети переводы пройти, чтобы перевести предложение. Из-за этого подхода, перевод будет принимать в контексте полного предложения, по сравнению с несколькими словами скользящее окно, что технология SMT использует и будет производить больше жидкости и человека-перевод глядя переводы.
На основе обучения нейронной сети каждое слово кодируется по вектору 500-Dimensions (a), который представляет его уникальные характеристики в пределах определенной языковой пары (например, английский и китайский). На основе языковых пар, используемых для обучения, нейронная сеть будет самостоятельно определить, что эти размеры должны быть. Они могут кодировать простые понятия, такие как пол (женский, мужской, нейтральный), уровень вежливости (сленг, случайные, письменные, формальные и т.д.), тип слова (глагол, существительное и т.д.), а также любые другие неочевидные характеристики, полученные из обучающих данных.
Шаги нейронной сети переводы проходят следующие:
- Каждое слово, или, точнее, 500-размерный вектор, представляющий его, проходит через первый слой «нейронов», который будет кодировать его в 1000-мерном векторе (b), представляющем слово в контексте других слов в предложении.
- После того как все слова были закодированы один раз в эти 1000-размерных векторов, процесс повторяется несколько раз, каждый слой позволяет лучше тонкой настройки этого 1000-размер представления слова в контексте полного предложения (вопреки SMT технологии, которые могут принимать во внимание только от 3 до 5 слов окно)
- Окончательная выходная матрица затем используется слоем внимания (т.е. программным алгоритмом), который будет использовать как эту конечную выходную матрицу, так и вывод ранее переведенных слов, чтобы определить, какое слово из исходного предложения должно быть переведено далее. Он также будет использовать эти вычисления для потенциального удаления ненужных слов на целевом языке.
- Слой декодера (Translation) преобразует выбранное слово (или, точнее, вектор 1000-Dimension, представляющий это слово в контексте полного предложения) в наиболее подходящий эквивалент целевого языка. Вывод этого последнего слоя (c) затем подается обратно в слой внимания, чтобы вычислить, какое следующее слово из исходного предложения должно быть переведено.
В примере, изображенном в анимации, контекстно-ориентированная модель 1000-Dimension «в»будет кодировать, что существительное (Дом) — женское слово на французском языке (La Maison). Это позволит соответствующий перевод для «в»быть»La»и не»Le»(сингулярный, мужской) или»Les»(множественное число), когда он достигнет уровня декодера (перевода).
Алгоритм внимания также вычисляется на основе слов (ов), ранее переведенных (в данном случае «в»), что следующее слово, которое будет переведено должно быть предметом («Дом»), а не прилагательное («Синий»). В может достичь этого, потому что система узнала, что английский и французский инвертировать порядок этих слов в предложениях. Было бы также подсчитано, что если прилагательное должно было быть «Большой»вместо цвета, что он не должен инвертировать их («большой дом»= >»La Grande Maison»).
Благодаря такому подходу конечный результат в большинстве случаев более свободно и ближе к человеческому переводу, чем перевод на основе SMT.
Как работает перевод речи?
Переводчик также способен переводить речь. Эта технология подвергается в переводчик жить функцию (http://translate.it), переводчик приложений, Skype переводчик и также изначально доступны только через Skype переводчик функции и в Microsoft Translator Apps на iOS и Android, эта функциональность теперь доступна для разработчиков с последней версией Open API на основе REST, доступный на портале Azure.
Хотя это может показаться, как прямо вперед процесс на первый взгляд, чтобы построить технологию перевода речи из существующих кирпичей технологии, она требует гораздо больше работы, чем просто подключить существующий «традиционный» человек-машина распознавания речи движок к существующему тексту перевода один.
Чтобы правильно перевести «источник» речи с одного языка на другой «целевой» язык, система проходит через четыре этапа процесса.
- Распознавание речи для преобразования звука в текст
- Труетекст: технология Microsoft, которая нормализует текст, чтобы сделать его более подходящим для перевода
- Перевод с помощью движка перевода текста, описанного выше, но на моделях перевода, специально разработанных для реальной жизни разговорные разговоры
- Текст в речь, при необходимости, для получения перевода аудио.
Автоматическое распознавание речи (ASR)
Автоматическое распознавание речи (ASR) выполняется с помощью системы нейронной сети (NN), обученной анализу тысяч часов входящей звуковой речи. Эта модель обучаются на взаимодействие человека с человеком, а не от человека к машине команды, создание распознавания речи, которая оптимизирована для нормальных разговоров. Для достижения этой цели требуется гораздо больше данных, а также больший DNN, чем традиционный ASRs от человека к машине.
Труетекст
Как люди беседуя с другими людьми, мы не говорим, как прекрасно, ясно или аккуратно, как мы часто думаем, что мы делаем. С помощью технологии труетекст, буквальный текст преобразуется, чтобы более точно отразить намерение пользователя путем удаления речи disfluencies (заполнители слов), таких как «UM» s, «а» s «и» s «, как» s, заикание и повторений. Текст также становится более читаемым и переводимым путем добавления разрывов предложений, правильных знаков препинания и прописных букв. Для достижения этих результатов, мы использовали десятилетия работы по языковым технологиям, мы разработали от переводчика для создания труетекст. На следующей схеме показано, что на примере реальной жизни различные преобразования труетекст работает для нормализации этого литерального текста.
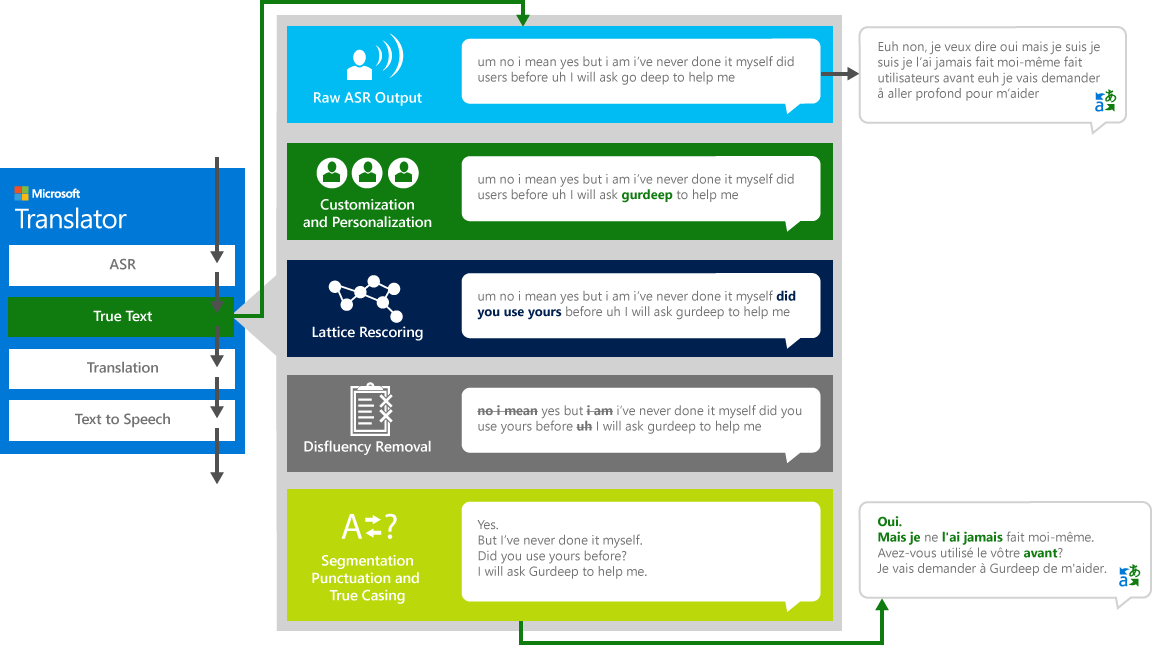
Перевод
Затем текст переводится на любой из языки и диалекты при поддержке Переводчика.
Переводы с использованием API перевода речи (в качестве разработчика) или в приложении или службе речевого перевода, подается с новейшими нейронными сетями на основе переводов для всех поддерживаемых языков речевого ввода (см. Здесь для полного списка). Эти модели были также построены путем расширения текущих, в основном письменного текста обученные модели перевода, с более устного текста корпусов для создания лучшей модели для разговорных типов переводов. Эти модели также доступны через Стандартная категория «речь» традиционного API перевода текстов.
Для любых языков, не поддерживаемых нейронным переводом, выполняется традиционный SMT-перевод.
Текст в речь
Если целевой язык является одним из 18 поддерживаемых текста в речь Языки, а для варианта использования требуется звуковой выход, затем текст преобразуется в речевой вывод с помощью синтеза речи. Этот этап опущен в сценариях преобразования речи в текст.
Исследования
Просмотр последних научных работ из группы переводчиков Microsoft.
Источник: www.microsoft.com