
Что такое Data Mining?
Аннотация: В лекции подробно рассмотрено понятие Data Mining. Описано возникновение, перспективы, проблемы Data mining. Дан взгляд на технологию Data Mining как на часть рынка информационных технологий.
«За последние годы, когда, стремясь к повышению эффективности и прибыльности бизнеса, при создании БД все стали пользоваться средствами обработки цифровой информации, появился и побочный продукт этой активности — горы собранных данных : И вот все больше распространяется идея о том, что эти горы полны золота».
В прошлом процесс добычи золота в горной промышленности состоял из выбора участка земли и дальнейшего ее просеивания большое количество раз. Иногда искатель находил несколько ценных самородков или мог натолкнуться на золотоносную жилу, но в большинстве случаев он вообще ничего не находил и шел дальше к другому многообещающему месту или же вовсе бросал добывать золото, считая это занятие напрасной тратой времени.
Python с нуля. Зачем нужен if __name__ == «__main__». Как это работает?!
Сегодня появились новые научные методы и специализированные инструменты, сделавшие горную промышленность намного более точной и производительной. Data Mining для данных развилась почти таким же способом. Старые методы, применявшиеся математиками и статистиками, отнимали много времени, чтобы в результате получить конструктивную и полезную информацию.
Сегодня на рынке представлено множество инструментов, включающих различные методы, которые делают Data Mining прибыльным делом, все более доступным для большинства компаний.
Термин Data Mining получил свое название из двух понятий: поиска ценной информации в большой базе данных ( data ) и добычи горной руды (mining). Оба процесса требуют или просеивания огромного количества сырого материала, или разумного исследования и поиска искомых ценностей.
Термин Data Mining часто переводится как добыча данных , извлечение информации, раскопка данных , интеллектуальный анализ данных , средства поиска закономерностей , извлечение знаний , анализ шаблонов , «извлечение зерен знаний из гор данных «, раскопка знаний в базах данных , информационная проходка данных , «промывание» данных . Понятие «обнаружение знаний в базах данных » ( Knowledge Discovery in Databases, KDD ) можно считать синонимом Data Mining [1].
Понятие Data Mining , появившееся в 1978 году, приобрело высокую популярность в современной трактовке примерно с первой половины 1990-х годов. До этого времени обработка и анализ данных осуществлялся в рамках прикладной статистики, при этом в основном решались задачи обработки небольших баз данных .
О популярности Data Mining говорит и тот факт, что результат поиска термина » Data Mining » в поисковой системе Google (на сентябрь 2005 года) — более 18 миллионов страниц.
Что же такое Data Mining ?
Data Mining — мультидисциплинарная область, возникшая и развивающаяся на базе таких наук как прикладная статистика , распознавание образов , искусственный интеллект , теория баз данных и др., см. рис. 1.1.
Como funciona o Data attributes? #AluraMais
Рис. 1.1. Data Mining как мультидисциплинарная область
Приведем краткое описание некоторых дисциплин, на стыке которых появилась технология Data Mining .
Понятие Статистики
Статистика — это наука о методах сбора данных , их обработки и анализа для выявления закономерностей , присущих изучаемому явлению.
Статистика является совокупностью методов планирования эксперимента, сбора данных , их представления и обобщения, а также анализа и получения выводов на основании этих данных .
Статистика оперирует данными , полученными в результате наблюдений либо экспериментов. Одна из последующих глав будет посвящена понятию данных .
Понятие Машинного обучения
Единого определения машинного обучения на сегодняшний день нет.
Машинное обучение можно охарактеризовать как процесс получения программой новых знаний. Митчелл в 1996 году дал такое определение: «Машинное обучение — это наука, которая изучает компьютерные алгоритмы, автоматически улучшающиеся во время работы».
Одним из наиболее популярных примеров алгоритма машинного обучения являются нейронные сети.
Понятие Искусственного интеллекта
Искусственный интеллект — научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования видов человеческой деятельности, традиционно считающихся интеллектуальными.
Термин интеллект (intelligence) происходит от латинского intellectus, что означает ум, рассудок, разум, мыслительные способности человека.
Соответственно, искусственный интеллект (AI, Artificial Intelligence ) толкуется как свойство автоматических систем брать на себя отдельные функции интеллекта человека. Искусственным интеллектом называют свойство интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека.
Каждое из направлений, сформировавших Data Mining , имеет свои особенности. Проведем сравнение с некоторыми из них.
Источник: intuit.ru
5.4 Технология Data Mining
По данным компании Gartner, неструктурированные документы составляют более 80% корпоративных данных, а количество внешних источников (интернет-ресурсов, блогов, форумов, СМИ) исчисляется миллионами. В них содержится гигантское количество данных, которые могут обеспечить компании существенное конкурентное преимущество. Основной вопрос — эффективность и скорость извлечения и анализа ценной информации.
Data Mining — «добыча» или «раскопка данных». Data Mining предназначены для решения задач интеллектуального анализа данных, что позволяет повысить эффективность принятия решений.
Data Mining — это процесс обнаружения в сырых данных:
1) ранее неизвестных и нетривиальных
2) практически полезных и доступных интерпретации знаний,
3) необходимых для принятия решений в различных сферах человеческой деятельности.
На рис. 28 представлены уровни знаний, извлекаемых из данных.
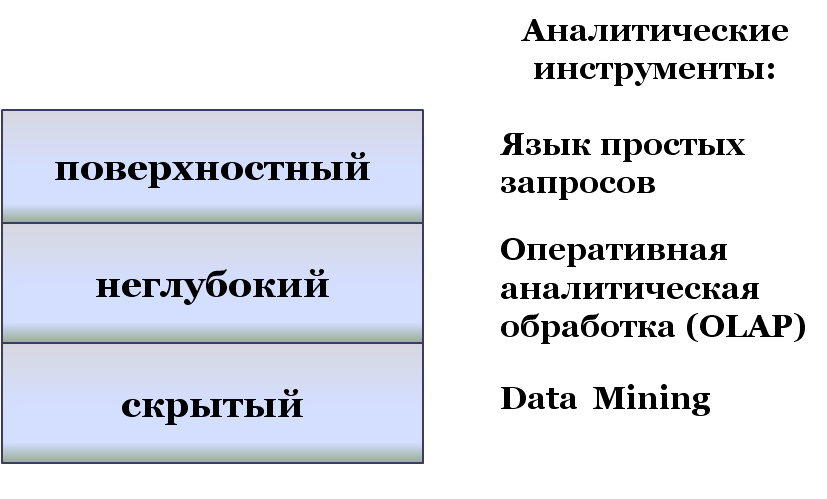
Рис. 28 Уровни знаний, извлекаемых из данных
Data Mining – это технология анализа информации с целью нахождения в уже накопленных предприятием данных ранее неизвестных, но практически полезных знаний, необходимых для принятия решений в различных областях человеческой деятельности.
Это процесс нахождения скрытых закономерностей в существующих данных.
Знания должны описывать новые связи между свойствами, предсказывать значения одних признаков на основе других.
Интеллектуальный анализ данных или «добыча данных» (Data Mining) позволяет проводить глубокие исследования данных, включающие:

- выявление скрытых зависимостей между данными
- выявление устойчивых бизнес-групп
- прогнозирование поведения бизнес-показателей
- оценку влияния решений на бизнес компании
- поиск аномалий и пр.
Типы закономерностей, которые позволяют выявлять методы Data Mining Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и «кока-колу», а при наличии скидки за такой комплект «колу» приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка. Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником. С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил. Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных. Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем. На рис.29 представлены вопросы, на которые можно получить ответ, используя OLAP и технологию Data Mining. Рис. 29 Вопросы, на которые можно получить ответ, используяOLAPиData Mining. Для выполнения этих задач используют IBM SPSS, Oracle Data Mining, SAS Enterprise Miner. Методы Data Mining: нейронные сети, деревья решений, методы ограниченного перебора, генетические алгоритмы, эволюционное программирование, кластерные модели, комбинированные методы. Несмотря на обилие методов Data Mining, приоритет постепенно все более смещается в сторону логических алгоритмов поиска в данных if-then правил. С их помощью решаются задачи прогнозирования, классификации, распознавания образов, сегментации БД, извлечения из данных «скрытых» знаний, интерпретации данных, установления ассоциаций в БД и др. Результаты таких алгоритмов эффективны и легко интерпретируются. Но главной проблемой логических методов обнаружения закономерностей является проблема перебора вариантов за приемлемое время. ПрименениеData Mining Сфера применения Data Mining ничем не ограничена — она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня интересны компаниям, развертывающим проекты на основе информационных хранилищ данных (Data Warehousing).
- оценка влияния решений на бизнес компании
- прогнозирование движения клиентов
- повышение отклика на маркетинговые акции
- прогнозирование спроса и предложения
- анализ потребительских корзин
- выявление закономерностей и аномалий в данных
Некоторые бизнес-приложения Data MiningРозничная торговля. Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
- анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.
- исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа «Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку?»
- создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
Банковское дело. Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач:
- выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
- сегментация клиентов. Разбивая клиентов на различные категории, банки делают свою маркетинговую политику более целенаправленной и результативной, предлагая различные виды услуг разным группам клиентов.
- прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
Телекоммуникации. В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать свои программы маркетинга и ценообразования, чтобы удерживать существующих клиентов и привлекать новых. Типичные мероприятия:
- анализ записей о подробных характеристиках вызовов. Назначение такого анализа — выявление категорий клиентов с похожими стереотипами пользования их услугами и разработка привлекательных наборов цен и услуг;
- выявление лояльности клиентов. Data Mining можно использовать для определения характеристик клиентов, которые, один раз воспользовавшись услугами данной компании, с большой долей вероятности останутся ей верными. В итоге средства, выделяемые на маркетинг, можно тратить там, где отдача больше всего.
Страхование. Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь обширное поле деятельности для методов Data Mining:
- выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями.
- анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда в США крупная страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это новое знание пересмотром своей общей политики предоставления скидок семейным клиентам.
Источник: studfile.net
Data mining технология
Технология Data mining – интеллектуальная обработка данных с использованием методов машинного обучения, математической статистики и теории баз данных.
Термин «data mining» появился в 1990-х годах, но как таковая обработка данных возникла в 18 веке, основываясь на теореме Байеса, чуть позже на регрессионном анализе.
По мере того как количество данных росло, изобретались новые технологии в области информатики (нейронные сети, генетические алгоритмы, метод деревьев решений и т.д.), появлялась возможность хранения большого количества данных и увеличение скорости обработки информации компьютерами интерес к data mining стремительно рос и вскоре обработка данных стала считаться отдельной дисциплиной. Сейчас data mining включает в себя обработку не только текстовых данных (text data mining), но и графических и мультимедийных(web mining).
Устоявшегося перевода словосочетания «data mining» на русский язык нет, дословно это переводится как «добыча данных». Но чаще всего используют формулировку «интеллектуальная обработка данных».
В настоящее время data mining является частью большего понятия – Big data, которое помимо обработки данных включает в себя их сбор и хранение.
Фундаментально data mining основывается на 3-х понятиях:
- Математическая статистика – является основой большинства технологий, используемых для data mining, например, кластерный анализ, регрессионный анализ, дискриминирующий анализ и пр.;
- Искусственный интеллект – воспроизведение нейронной сети мышления человека в цифровом виде;
- Машинное обучение – совокупность статистики и искусственного интеллекта, способствующая пониманию компьютерами данных, которые они обрабатывают для выбора наиболее подходящего метода или методов анализа.
В data mining используются следующие основные классы задач:·
- обнаружение отклонений – выявление данных, отличающихся по каким-либо параметрам из общей массы;
- обучение ассоциациям – поиск взаимосвязей между событиями;
- кластеризация – группирование наборов данных, без заранее известных шаблонов;
- классификация – обобщение известного шаблона для применения к новым данным;
- регрессия – поиск функции, отображающей набор данных с наименьшим отклонением;
- подведение итогов – отображение в сжатом виде исходной информации, включая предоставление отчетов и визуализацию.
Сегодня data mining широко используется в бизнесе, науке, технике, медицине, телекоммуникациях и т.п. Анализ данных по операциям с кредитными картами, анализ данных ЖКХ, программы карт лояльности в магазинах с учетом предпочтения покупателей, национальная безопасность (обнаружение вторжений), исследование генома человека – всего лишь небольшая часть возможных вариантов применения data mining.
Для того, чтобы ознакомиться с решениями в области data mining от ведущих российских поставщиков — свяжитесь с нами по номеру 8 (921) 781 24-49 — звонок, Telegram, Whatsapp или оставьте короткую заявку по ссылке.

- http://www.intuit.ru/studies/courses/6/6/info
- https://www.matillion.com/insights/5-real-life-applications-of-data-mining-and-business-intelligence.
- http://opensourceforu.com/2017/03/top-10-open-source-data-mining-tools/
Источник: iot.ru
Все о Process Mining от ProcessMi
Все о технологии Process Mining — кейсы, термины, решения и аналитика. Российский и зарубежный опыт от группы экспертов ProcessMi
Data Mining (дата майнинг)

Data Mining – это процедура поиска и обнаружения в «сырых» данных скрытых полезных, ранее неизвестных и неопределенных.
Существует несколько определений термина, дополняющих классическое. Среди них:
- нахождение полезных и применимых на практике трендов в БД, которые могут быть применимы для повышения конкурентоспособности бизнеса;
- процесс, который ориентирован на поиск новых зависимостей и корреляций в результате фильтрации сверхбольшого объема данных с использованием математики.
У термина нет дословного перевода на русский, поэтому DM расшифровывают как: извлечение данных, фильтрация новых знаний из данных, интеллектуальный анализ данных, обнаружение новых знаний в БД.
История возникновения Data Mining
Началом существования DM считается мероприятие Григория Пятецкого-Шапиро в 1989 году. Спустя 4 года вышла первая рассылка «Knowledge Discovery Nuggets», еще через год открыты первые интернет-ресурсы по DM.
Свойства Data Mining
Если традиционные методы анализа (например, при помощи статистики и OLAP) направлены на проверку ранее полученных, сформулированных гипотез и предположений, то основное отличие Data Mining – именно в неочевидности полученных трендов и закономерностей.
Знания, извлекаемые при помощи DM, должны обладать определенными свойствами, среди которых:
- Новизна
Полученные в результате применения DM знания должны быть неизвестными, поскольку несут деловую важность и ценность для бизнеса.
- Нетривиальность
Результаты применения DM не могут быть очевидными, например, полученными экспертным путем или наблюдениями. Выявленные закономерности и тенденции должны быть неожиданными и отражать неявные сведения.
- Полезность
Получаемые знания обязаны быть полезными и способными применяться практически.
- Доступность
Знания должны быть объяснимы, иначе есть высокая доля вероятности их случайности, а не закономерности. Вместе с тем, сведения обязаны быть представлены в понятном для восприятия человеком виде.
Задачи Data Mining
- Классификация
Отнесение полученного объекта/наблюдения/события (ОНС) к одному из классов;
- Кластеризация
Разделение большого количества ОНС на кластеры по степени соответствия друг другу;
- Сокращение
Для сжатия информации;
- Ассоциация
Поиск повторений. Самый простой пример – поиск наличия связей в продуктовом наборе покупателя крупного супермаркета;
- Прогнозирование
Предположение относительно будущих состояний объекта, опирающееся на устойчивое основание, полученное из исторических данных;
- Визуализация
Наглядная интерпретация.
Методы Data Mining
Выделяют две основные группы методов DM:
- статистические,
которые используют «средний накопленный опыт»;
- кибернетические
на основе различных математических подходов.
Сферы применения Data Mining
Нет ограничений по возможностям применения DM, главное условие – наличие данных. Хотя самыми первыми оценили перспективы использования подобных новшеств крупные коммерческие компании, которые ведут проекты на основе Data Warehousing. СМИ анонсируют крупные кейсы, где расписан экономический эффект от применения DM, который превысил первоначальные затраты среднем в 50 раз.
Практическое применение Data Mining
Поскольку именно применение полученных знаний на практике и получение экономической выгоды стоит в основе DM, то среди наиболее частых бизнес-задач:
- анализ клиентской базы, выявление наиболее перспективных покупателей (потребителей);
- оптимизация бюджета и поставщиков;
- повышение эффективности HR-службы (функции подбора персонала);
- оценка кредитоспособности потенциальных заемщиков;
- прогноз продаж.
Источник: processmi.com