
Что такое CUDA в видеокартах от nVidia и зачем эта технология 3D-художнику
На современных видеокартах можно делать параллельные математические вычисления, не связанные с 3D-графикой. Наиболее известные программные интерфейсы Direct3D (DirectX) или OpenGL, ответственные за вывод графики, в данном случае не подходят. На сегодня есть два основных типа интерфейсов для доступа к таким вычислениям, в том числе векторным, на GPU – CUDA и OpenCL. Стоит также уточнить, что в отличие от многоядерных CPU, ядра видеокарт менее универсальны и более просты. Из-за этого, их может быть на видеокарте огромное количество. nVidia GeForce RTX 2070 имеет 2560 CUDA ядер.
Другие материалы по теме «железа» на канале: #3dn_hardware
CUDA — аббревиатура запатентована фирмой nVidia и расшифровывается как Compute Unified Device Architecture. Это закрытая программно-аппаратная архитектура. CUDA состоит из самих вычислительных ядер и «родного» API — программного интерфейса. К дополнительным преимуществам можно отнести полную аппаратную поддержку целочисленных и побитовых операций и некоторые особенности в работе с памятью, что также ускоряет вычисления.
Технология CUDA от NVIDIA GEFORCE.Как включить в AFTER EFFECTS И PREMIER PRO
OpenCL – идеологически схожий открытый проект, который разрабатывается некоммерческим консорциумом «Khronos Group». В него входят такие крупные компании, как Intel, AMD, Apple и даже nVidia. Хотя она этого и не афиширует. У AMD Radeon доступ к ресурсам вычислений завязан на OpenCL. В отличие от CUDA не является «родным» и оптимизированным под конкретную архитектуру, хотя и более универсальный.
Поэтому видеокарты от AMD могут проигрывать в среднем от 10% до 60% в тестах на такие параллельные математические вычисления. С выходом всё более новых драйверов и версий самого стандарта, ситуация улучшается. nVidia также поддерживает OpenCL, но «поверх» своего API CUDA, и в тестах этого стандарта будет еще менее производительной.
Количество исполнительных ядер в моделях при схожей цене у nVidia и AMD не будет сильно отличаться. А ядра у этих двух брендов объединены в потоковые мультипроцессоры. При схожей архитектуре и характеристиках, за счет CUDA AMD будет проигрывать в параллельных вычислениях на GPU.
Распараллеливание операций также возможно и на CPU. Даже одновременное использование мощностей видеокарты и центрального процессора. Но с той лишь разницей, что при наличии дискретной видеокарты, CPU станет узким местом, а общая производительность упадет.
Популярные рендер движки: V-Ray, Arnold, Redshift, Octane, RenderMan и другие менее известные, использование видеокарт от AMD через OpenCL на данный момент не поддерживаются. То же касается и Adobe Substance 3D Painter-a, как стандарта для текстурирования и запекания текстурных карт. Также всё не очень хорошо и с программами для симуляций, VFX, композа и видеомонтажа. Marmoset Toolbag также не поддерживает OpenCL на данный момент. Единственный пакет 3D-моделирования с поддержкой OpenCL рендера – Blender со встроенным рендер движком Cycles, EEVEE OpenCL не поддерживает.
NVIDIA CUDA для начинающих
Думаю, что в ближайшем будущем ситуация должна измениться, а стандарт OpenCL будет более популярным и получит поддержку основными программными пакетами в области графики и видео. Кроме общего развития стандартов, на это может повлиять кризис полупроводников и цены на рынке видеокарт среднего и топ-сегмента, которые в несколько раз выше рекомендованной и не доступны среднему пользователю. В начале января на выставке CES 2022, компания Intel представила свою линейку видеокарт на новой архитектуре Arc Alchemist. Но скорее всего в продажу они поступят не ранее третьего квартала 2022 года. Наиболее вероятным, будет использования Intel-ом OpenCL, так как внедрить новый стандарт в индустрию сей час крайне сложно и дорого.
В итоге всё сводится к программно-аппаратной реализации доступа и поддержке производителями софта. Вывод только один — на данный момент альтернативы CUDA нет.
Пишите своё мнение в комментариях, задавайте вопросы и подписывайтесь на канал. Если вам понравилась статья, поддержите лайком. Спасибо.
Другие материалы по теме «железа» на канале: #3dn_hardware
#3d #видеокарты #cg #игры #nvidia #intel #amd #3d-графика
Источник: dzen.ru
Аппаратная часть
Архитектура GPU построена несколько иначе, нежели CPU. Поскольку графические процессоры сперва использовались только для графических расчетов, которые допускают независимую параллельную обработку данных, то GPU и предназначены именно для параллельных вычислений. Он спроектирован таким образом, чтобы выполнять огромное количество потоков (элементарных параллельных процессов).
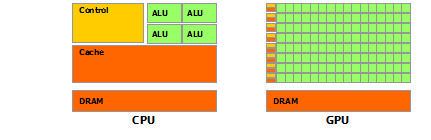
Как видно из картинки – в GPU есть много простых арифметически-логических устройств (АЛП), которые объединены в несколько групп и обладают общей памятью. Это помогает повысить продуктивность в вычислительных заданиях, но немного усложняет программирование.
«Для достижения лучшего ускорения необходимо продумывать стратегии доступа к памяти и учитывать аппаратные особенности.»
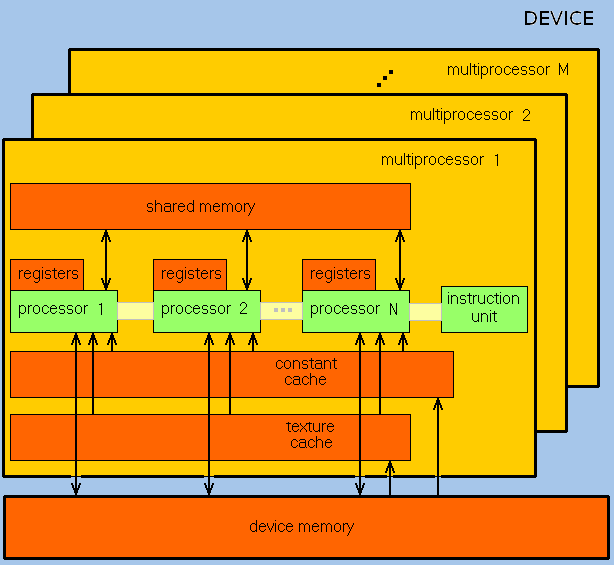
GPU ориентирован на выполнение программ с большим объемом данных и расчетов и представляет собой массив потоковых процессоров (Streaming Processor Array), что состоит из кластеров текстурных процессоров (Texture Processor Clusters, TPC). TPC в свою очередь состоит из набора мультипроцессоров (SM – Streaming Multi-processor), в каждом из которых несколько потоковых процессоров (SP – Streaming Processors) или ядер (в современных процессорах количество ядер превышает 1024).
Набор ядер каждого мультипроцессора работает по принципу SIMD (но с некоторым отличием) – реализация, которая позволяет группе процессоров, работающих параллельно, работать с различными данными, но при этом все они в любой момент времени должны выполнять одинаковую команду. Говоря проще, несколько потоков выполняют одно и то же задание.
В результате GPU фактически стал устройством, которое реализует потоковую вычислительную модель (stream computing model): есть потоки входящих и исходящих данных, что состоят из одинаковых элементов, которые могут быть обработаны независимо друг от друга.
Вычислительные возможности
Продолжаем разбираться с CUDA. Каждая видеокарта обладает так называемыми compute capabilities – количественными характеристиками скорости выполнения определенных операций на графическом процессоре. Данное число показывает, насколько быстро видеокарта будет выполнять свою работу.
В NVIDIA эту характеристику обозначают Compute Capability Version. В таблице приведены некоторые видеокарты и соответствующие им вычислительные возможности:

Полный перечень можно посмотреть здесь. Compute Capability Version описывает множество параметров, среди которых: количество потоков на блок, максимальное количество блоков и потоков, размер warp, а также многое другое.
Потоки, блоки и сетки
CUDA использует большое количество отдельных потоков для расчетов. Все они группируются в иерархию – grid / block / thread.
Верхний уровень – grid – отвечает ядру и объединяет все потоки, которые выполняет данное ядро. Grid – одномерный или двумерный массив блоков (block). Каждый блок (block) представляет собой полностью независимый набор скоординированных между собой потоков. Потоки из разных блоков не могут взаимодействовать.
Мы упоминали об отличии от SIMD-архитектуры. Есть такое понятие, как warp – группа из 32 потоков (в зависимости от архитектуры GPU, но почти всегда 32). Только потоки в рамках одной группы (warp) могут физически выполняться одновременно. Потоки разных варпов могут находиться на разных стадиях выполнения программы.
Такой метод обработки данных обозначается термином SIMT (Single Instruction – Multiple Theads). Управление работой варпов выполняется на аппаратном уровне.
Почему иногда центральный процессор выполняет задания быстрее графического?
Выше уже было написано, что не стоит выполнять на GPU слишком простые задания. Чтобы понять, следует определить два термина:
- Задержка – это преимущественно время ожидания между запросом на какой-либо ресурс и получением доступа к данному ресурсу.
- Пропускная способность – количество операций, которые выполняются за единицу времени.
Таким образом, главный вопрос состоит в следующем: почему графический процессор иногда «тупит»? Объясняем на простом примере.
У нас есть 2 автомобиля:
- легковой фургон – скорость 120 км/ч, способен вместить 9 человек;
- автобус – скорость 90 км/ч, способен вместить 30 человек.
Если одна операция – это передвижение одного человека на определенное расстояние (пусть будет 1 км), то задержка (время, за которое один человек пройдет 1 км) для первого авто составит 3600/120 = 30 сек, а пропускная способность – 9/30 = 0,3. Для автобуса – 3600/90 = 40 сек и 30/40 = 0,75.
CPU – это фургон, а GPU – автобус: у него большая задержка, но также и большая пропускная способность. Если для вашего задания задержка каждой конкретной операции не так важна, как количество этих самых операций в секунду, то стоит рассмотреть использование GPU.
Выводы
Отличительными чертами GPU в сравнении с CPU являются:
- архитектура, максимально нацеленная на увеличение скорости расчета текстур и сложных графических объектов;
- предельная мощность типичного GPU намного больше, чем у CPU;
- благодаря специализированной конвейерной архитектуре GPU более эффективен в обработке графической информации, нежели центральный процессор.
Главный минус CUDA в том, что данная технология поддерживается только видеокартами NVIDIA без каких-либо альтернатив.
Графический процессор не всегда может дать ускорение при выполнении определенных алгоритмов. Поэтому перед использованием GPU для вычислений стоит хорошо подумать, а нужен ли он в данном случае. Вы можете использовать видеокарту для сложных вычислений: работа с графикой или изображениями, инженерные расчеты, криптографические задачи (майнинг), и т. д., но не используйте GPU для решения простых задач (разумеется, вы можете, но тогда эффективность будет равняться нулю).
Помните о задаче с фургоном и автобусом, а также не забывайте, что использование графического процессора гораздо вероятнее замедлит программу, нежели ускорит ее.
Вас также могут заинтересовать такие материалы по теме:
- Взламываем шифры: криптография за 60 минут
- Выбираем ноутбук для программирования
- HTTPS: внутреннее устройство и почтовые голуби
- 7 сложных технологий простым языком
- 10 полезных ресурсов по технологии blockchain
- Что такое Биткоин и разбираемся, как он работает
Источник: proglib.io
Что за CUDA-ядра и зачем они нужны?

Графический процессор любой видеокарты состоит из небольших блоков, которые в свою очередь из вычислительных юнитов. У AMD это потоковые процессоры, у Intel — шейдерные ядра, а у NVIDIA — CUDA-ядра. Поскольку карты NVIDIA наиболее распространены и популярны (порядка 84% рынка в 2022 году), в этой статье поверхностно ознакомимся с их универсальной вычислительной единицей — с ядром CUDA.

Блок-схема ядра GA102 (GeForce RTX 4090): 84 SM-блоков (активны 64), каждый содержит 256 CUDA.
Коротко о главном
CUDA — это технология, запатентованная NVIDIA и используемая только в их видеокартах. Ядра CUDA похожи на обычные, используемые в процессорах. CUDA означает Compute Unified Device Architecture, что в переводе Вычислительная Унифицированная Архитектура Устройства.
Ядро CUDA отличается от обычного процессорного архитектурой. Они нацелены на то, чтобы эффективно работать параллельно . Ядра CUDA проще по устройству, но в видеокарте их очень много. Если в процессоре могут быть 2-16 ядер, то в видеокарте их сотни, а то и тысячи. Например, у карты GeForce RTX 3080 их 8960, а у GeForce GTX 980 — 2048.

Говоря иными словами, если процессорное ядро — это высококвалифицированный инженер, который может делать всё, но в системе их мало. CUDA — низкоквалифицированный рабочий, но их много, и они наваливаются на задачу все разом.
Где используются CUDA?
В первую очередь в игровых видеокартах NVIDIA.
Видеокарты с ядрами CUDA призваны взять на себя самые тяжелые элементы. Процессор в компьютере с такой видеокартой играет роль администратора, решая базовые задачи. В данном случае CUDA решают только графические задачи. Обработка графики требует большого количества одновременных вычислений, на это «заточены» ядра CUDA, и поэтому их так много.
Одновременные вычисления — это суть игр, ведь в игре стреляют, бегут, едут, летят, плывут, и все это в один момент. CUDA же решают задачи вместе и сразу.
Это исключает ситуации, когда одно ядро ждет, пока другие ядра выполняют свои задачи, и потери производительности из-за такого ожидания.
Где будут полезны ядра?

В играх
Ядра от NVIDIA влияют на производительность всей графики в игре, но в первую очередь на тени, освещение, сглаживание, физические модели. Их работа делает игру реалистичнее и детальнее.
В рабочих задачах
Спектр применения CUDA в рабочих задачах очень широк. Как сказано в названии, это унифицированный вычислительный юнит, который может делать всё. Наиболее часто CUDA-вычисления применяются в: вычислительной математике, для работы с искусственным интеллектом, анализа Big Data, финансовой аналитике, прогнозах погоды.
Послесловие

В завершение настоятельно рекомендуем ознакомиться с этим роликом от легендарных разрушителей легенд, за полторы минуты максимально наглядно показывающим, что такое CUDA.
565 просмотров
Поделиться 0 Нравится
Также будет интересно

- технологии
- NVIDIA
Знакомимся с DLDSR — осовременивателем старых игр, но и не только
Возможно ли сделать полюбившиеся проекты более привлекательными ? В этом нам поможет но.
1001 просмотров
Поделиться 0 Нравится

- технологии
- NVIDIA
- AMD
AMD FSR или NVIDIA DLSS? — выясняем на примере Deathloop
Хотите разобраться в чем отличие между DLSS и FSR на примере конкретной игры? Сегодня м.
Источник: digital-razor.ru
Нужны ли графические ядра Nvidia CUDA для игр?

Ядра CUDA являются эквивалентом процессорных ядер Nvidia. Они оптимизированы для одновременного выполнения большого количества вычислений, что очень важно для современной графики. Естественно, на графические настройки больше всего повлияло количество ядер CUDA в видеокарте, и они требуют больше всего от графического процессора, то есть теней и освещения, среди прочего.
CUDA долгое время была одной из самых выдающихся записей в спецификациях любой видеокарты GeForce. Однако не все до конца понимают, что такое ядра CUDA и что конкретно они означают для игр.
В этой статье дан краткий и простой ответ на этот вопрос. Кроме того, мы кратко рассмотрим некоторые другие связанные вопросы, которые могут возникнуть у некоторых пользователей.
Что такое ядра видеокарты CUDA?
CUDA является аббревиатурой от одной из запатентованных технологий Nvidia: Compute Unified Device Architecture. Его цель? Эффективные параллельные вычисления.
Одиночное ядро CUDA аналогично ядру ЦП, основное отличие в том, что оно менее изощренное, но реализовано в большем количестве. Обычный игровой процессор имеет от 2 до 16 ядер, но количество ядер CUDA исчисляется сотнями, даже в самых низких современных видеокартах Nvidia GeForce. Между тем, у высококлассных карт сейчас их тысячи.
Что делают ядра CUDA в играх?
GPU во многих отношениях отличается от CPU, но, если говорить об этом с точки зрения непрофессионала: CPU — это скорее администратор, отвечающий за управление компьютером в целом, а GPU лучше всего подходит для выполнения тяжелых работ.
Обработка графики требует одновременного выполнения множества сложных вычислений, поэтому такое огромное количество ядер CUDA реализовано в видеокартах. И учитывая, как графические процессоры разрабатываются и оптимизируются специально для этой цели, их ядра могут быть намного меньше, чем у гораздо более универсального CPU.
И как ядра CUDA влияют на производительность в игре?
По сути, любые графические настройки, которые требуют одновременного выполнения вычислений, значительно выиграют от большего количества ядер CUDA. Наиболее очевидными из них считается освещение и тени, но также включены физика, а также некоторые типы сглаживания и окклюзии окружающей среды.
Ядра CUDA или потоковые процессоры?

Там, где у Nvidia GeForce есть ядра CUDA, у их основного конкурента AMD Radeon есть потоковые процессоры.
Теперь эти две технологии, а также соответствующие архитектуры GPU каждой компании, очевидно, различаются. Однако в основном и функционально ядра CUDA и потоковые процессоры — это одно и то же.
Ядра CUDA лучше оптимизированы, поскольку аппаратное обеспечение Nvidia обычно сравнивают с AMD, но нет никаких явных различий в производительности или качестве графики, о которых вам следует беспокоиться, если вы разрываетесь между приобретением Nvidia или AMD GPU.
Сколько ядер CUDA вам нужно?
И вот сложный вопрос. Как часто бывает с бумажными спецификациями, они просто не являются хорошим индикатором того, какую производительность вы можете ожидать от аппаратного обеспечения.
Многие другие спецификации, такие как пропускная способность VRAM, более важны для рассмотрения, чем количество ядер CUDA, а также вопрос оптимизации программного обеспечения.
Поэтому лучший способ определить производительность видеокарты — взглянуть на некоторые тесты. Таким образом, вы можете точно знать, какой тип производительности вы можете ожидать в определенной игре.

Для общего представления о том, насколько мощен графический процессор, мы рекомендуем проверить UserBenchmark. Однако, если вы хотите увидеть детальное и всестороннее тестирование, есть несколько надежных сайтов, таких как GamersNexus, TrustedReviews, Tom’s Hardware, AnandTech и ряд других.
Вывод
Надеемся, что это помогло пролить некоторый свет на то, чем на самом деле являются ядра CUDA, что они делают и насколько они важны. Прежде всего, мы надеемся, что помогли развеять любые ваши заблуждения по этому поводу.
Источник: fps-up.ru
Что такое технология CUDA в видеокартах Nvidia и что она дает?

Всем привет! Сегодня обсудим CUDA: что это такое в видеокарте, зачем нужна такая технология, что она дает, как работает и есть ли в ней практическая польза. Ранее на блоге, я рассказывал о том, что такое VRM в видеокарте, если интересно, то почитать про это можно тут. А теперь к сегодняшней теме.
Что такое CUDA
Термин — аббревиатура словосочетания Compute Unified Device Architecture. Это программно-аппаратная среда, разработанная для проведения графических вычислений. Такая технология позволяет добиться значительного ускорения вычислений, которые проводятся графическими процессорами.
Используется в GPU марки NVidia, для чего используется поддержка ряда фирменных функций и «фишек». Для дальнейшего понимания материала следует объяснить значение таких терминов:
- Устройство — сам видеоадаптер, который выполняет поданные центральным процессором команды;
- Хост — ЦП, запускающий различные задания и выделяющий под это необходимые вычислительные ресурсы;
- Ядро — задание, которое будет обрабатываться устройством.
Много потоковые вычисления реализованы с помощью упрощенных версий языков программирования С и Фортран. Разработчик может получить доступ к набору инструкций видеокарты согласно заданным алгоритмам.
Такую опцию можно активировать с помощью базового набора многих языков программирования — например, MATLAB или Python.
Как работает
Алгоритм вычислений выглядит следующим образом:
- Хост выделяет на компьютере требуемое количество ОЗУ;
- Он же копирует данные из собственной памяти в память графического ускорителя;
- CPU запускает ядро на устройстве;
- Видеокарта его обрабатывает;
- Результаты копируются из RAM в память ЦП.
Так как GPU изначально разработаны под графические вычисления, что допускает параллельную обработку, то и CUDA в ряде случаев справится с задачей быстрее, чем сам центральный процессор. Все упирается в эффективность алгоритмов доступа к памяти устройства.
Сам центральный процессор, хотя тоже может обрабатывать данные несколькими ядрами одновременно, должен выполнять одну и ту же команду. В случае с видео платой таких ограничений нет, поэтому целесообразно делегировать этому компоненту часть полномочий по обработке информации.
Можно утверждать следующее:
Предельная мощность GPU при использовании CUDA в итоге будет больше, чем у CPU. Их архитектура изначально нацелена на выполнение задач по обработке текстур и сложных 3D много полигональных объектов, поэтому с числовыми данными видеоадаптер справится без особой нагрузки.
Единственный минус CUDA — пожалуй, то, что эта технология поддерживается только графическими чипами NVidia.
Стоит учесть. Что такая технология будет эффективна при сложных расчетах (например, инженерных вычислениях или майнинге), но совершенно нецелесообразна для решения простых задач.
Также для вас будут полезны публикации «Сравниваем технологии Nvidia SLI и AMD CrossFire» и «Устанавливаем видеокарту вертикально и что для этого нужно». Буду признателен, если вы поделитесь этим постом в любой социальной сети — так вы можете поучаствовать в развитии моего блога. До скорой встречи!
С уважением, автор блога Андрей Андреев.
Источник: infotechnica.ru