
Big Data
Big Data — это разнообразные данные больших объемов, которые хранятся на цифровых носителях. В их число входит общая статистика рынков и личные данные пользователей: информация о транзакциях и платежах, покупках, перемещениях и предпочтениях аудитории.
Объем больших данных исчисляется терабайтами. Это и тексты, и фотографии, и машинный код. Такой массив информации просто невозможно проанализировать силами человека или с помощью обычного компьютера, для этого нужны специальные инструменты.
Технологии, связанные с хранением и обработкой больших данных, также называют Big Data.
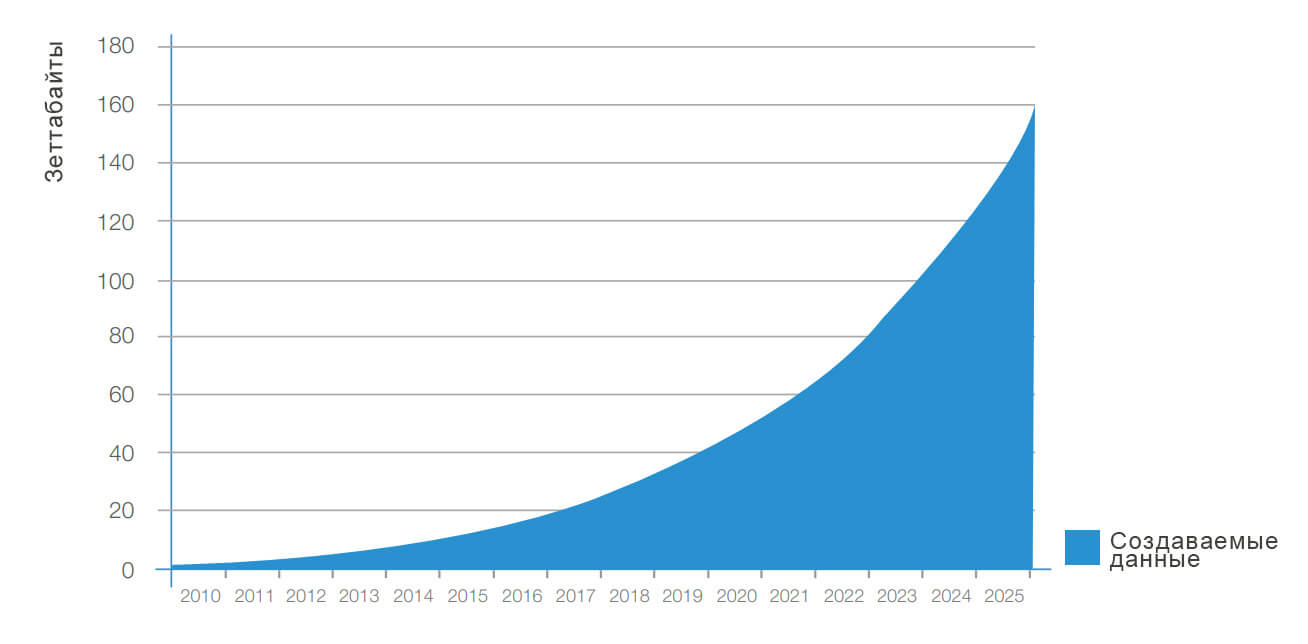
Прогноз роста больших данных в мире. Источник
Характеристики Big Data
Большие данные отличают от обычных наличие признаков «VVV».
Volume (объем) — физический размер данных, их вес и количество места, которое они занимают. Поток таких данных может составлять от 100 Гб в сутки.
Velocity (скорость) — объем информации увеличивается с большой скоростью, в геометрической прогрессии, и требует быстрой обработки и анализа.
Variety (разнообразие) — данные неоднородны и поступают в разных форматах: текст, картинки, голосовые сообщения, транзакции. Они могут быть неупорядоченными, структурированными полностью или частично.
Отдельные IT-компании выделяют дополнительные аспекты работы с большими данными.
Variability (изменчивость) — поток информации неоднороден, случаются всплески или спады. Это осложняет её обработку и анализ.
Value (ценность) — описывает как сложность информации для обработки, так и её степень важности. Для бизнеса особо актуален вопрос целесообразности затрат на обработку данных.
Visualization (визуализация) — возможность наглядно представить результаты анализа, чтобы упростить их восприятие человеком.
Veracity (достоверность) — точность и достоверность самих данных, а также корректность способа, которым получены. Неточности ведут к ошибкам в анализе.
Зачем нужны большие данные
Большие данные применяются во многих отраслях: банки, страхование, ритейл, здравоохранение, логистика, наука, маркетинг. Везде, где можно собрать большой объем информации и проанализировать его.
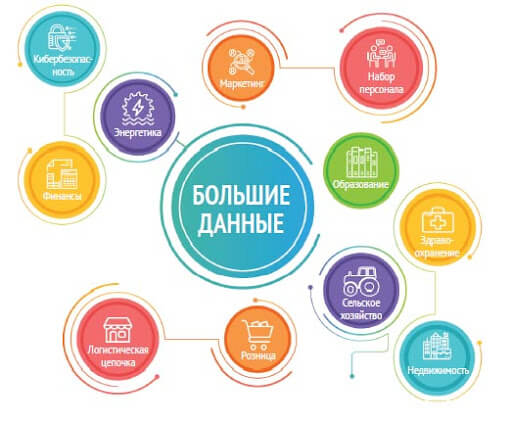
Отрасли, которые используют BigData. Источник
Перед BigData стоит три глобальных задачи:
Строить модели. Систематизировать данные, находить причинно-следственные связи. Это помогает понять, как работают сложные системы, делает их прозрачными.
Производители автомобилей Toyota изучили поведение водителей в момент аварии и разработали систему безопасности. Она анализирует манеру вождения и срабатывает, если человек за рулем перепутал педали.
Поисковый отряд «Лиза Алерт» совместно с «Билайн.Поиск» запустили нейросеть , чтобы обрабатывать фотографии со спутников. А еще они используют алгоритм, который вычисляет потенциальных свидетелей и высылает им информацию о пропавшем человеке.

Оптимизировать процессы. Автоматизировать рутинные или трудозатратные этапы, повысить точность расчетов и экономить ресурсы. Например, сервисы такси автоматически рассчитывают стоимость поездки с учетом спроса, пробок и погоды.
« Магнитогорский металлургический комбинат » внедрил систему, которая в режиме реального времени анализирует параметры плав и выдает рекомендации оператору цеха, что позволяет минимизировать издержки.
Amazon оптимизирует продажи и обновляет цены на сайте примерно каждый 10 минут. Также предлагает дополнительные скидки, после добавления товара в корзину, чтобы уменьшить число брошенных товаров.
Розничная сеть Target показывает разную стоимость товаров для жителей престижных и обычных районов, чтобы максимизировать выручку.
Делать прогнозы. Бизнес с помощью аналитики предсказывает поведение покупателей и спрос, планирует продажи и денежные потоки. Искусственный интеллект эффективнее врачей может выявлять болезни на ранней стадии.
Магазины предлагают персональные рекомендации и скидки для покупателей, которые с большей вероятностью им понравятся.
Застройщики с помощью систем динамического ценообразования определяют максимально выгодную стоимость объектов недвижимости на данный момент, прогнозируют прибыль и выполнение плана продаж.
Как работает технология больших данных
Работа с большими данными происходит в несколько этапов:
- сбор информации из разных источников;
- размещение данных в хранилище;
- обработка и анализ.
Сбор информации
Информация окружает нас повсюду. Социальные сети, поисковые системы, гаджеты, карты лояльности, данные GPS-трекеров, онлайн-кассы генерируют большие потоки данных каждую минуту. Источники Big Data можно разделить на три типа: социальные, машинные и транзакционные.
Социальные — создаются людьми. Информация, которую загружают или создают пользователи интернета: фотографии, электронные письма, сообщения, статьи, записи в блогах. Сюда же относят социально-демографическую статистику стран и компаний.
Транзакционные — возникают при совершении различных операций. Это покупки, переводы денег, поставки товаров, операции с банкоматами, переходы по ссылкам, поисковые запросы.
Машинные — информация с датчиков и устройств. В том числе интернет вещей — данные, которыми устройства обмениваются между собой. Например, датчики внутри автомобилей, метеорологические приборы, смартфоны, умные колонки и т.д.
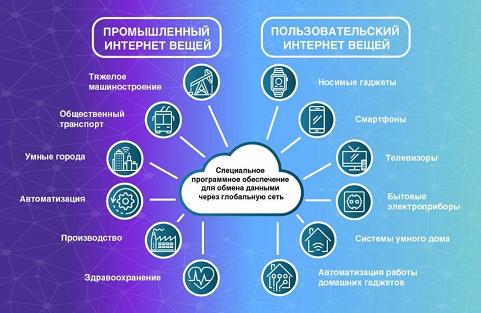
Что входит в интернет вещей. Источник
Хранение
Большие объемы информации требуют больших мощностей для размещения. У компании, которая собирает Big Data, есть три варианта, где хранить данные:
- На собственных серверах. Предприятие самостоятельно закупает, настраивает и обслуживает оборудование.
- Облачное хранение. Фирма арендует место у сторонней компании за плату. Такую услугу предоставляют Amazon, Microsoft или Google. Ряд платформ, помимо хранения, предлагают готовые решения для обработки данных, например Oracle Exadata.
- Публичные большие данные. Хранятся облачно либо на частных серверах, доступ к базе предоставляется бесплатно.
У различных видов хранения есть свои плюсы и минусы:
1. На своём сервере. Это может быть дешевле, но вопросы безотказности, безопасности и поддержки вы должны будете решать сами.
2. В облаке. Это может быть дороже, но вопросы безотказности, безопасности и поддержки будут решаться на стороне облака.
Источник: www.unisender.com
Программа big data что это

Одно из определений больших данных звучит следующим образом: «данные можно назвать большими, когда их размер становится частью проблемы». Такие объемы информации не могут быть сохранены и обработаны с использованием традиционного вычислительного подхода в течение заданного периода времени. Но насколько огромными должны быть данные, чтобы их можно было назвать большими?
Обычно мы говорим о гигабайтах, терабайтах, петабайтах, эксабайтах или более крупных единицах измерения. Тут и возникает неправильное представление. Даже данные маленького объема можно назвать большими в зависимости от контекста, в котором они используются.
Например, почтовый сервер может не позволить отправить письмо с вложением на 100 мегабайт, или, допустим, у нас есть около 10 терабайт графических файлов, которые необходимо обработать. Используя настольный компьютер, мы не сможем выполнить эту задачу в течение заданного периода времени из-за нехватки вычислительных ресурсов.
Как классифицируются большие данные?
Выделим три категории:
Характеристики больших данных
Большие данные характеризуются четырьмя правилами (англ. 4 V’s of Big Data: Volume, Velocity, Variety, Veracity) :
- Объем: компании могут собирать огромное количество информации, размер которой становится критическим фактором в аналитике.
- Скорость, с которой генерируется информация. Практически все происходящее вокруг нас (поисковые запросы, социальные сети и т. д.) производит новые данные, многие из которых могут быть использованы в бизнес-решениях.
- Разнообразие: генерируемая информация неоднородна и может быть представлена в различных форматах, вроде видео, текста, таблиц, числовых последовательностей, показаний сенсоров и т. д. Понимание типа больших данных является ключевым фактором для раскрытия их ценности.
- Достоверность: достоверность относится к качеству анализируемых данных. С высокой степенью достоверности они содержат много записей, которые ценны для анализа и которые вносят значимый вклад в общие результаты. С другой стороны данные с низкой достоверностью содержат высокий процент бессмысленной информации, которая называется шумом.
Традиционный подход к хранению и обработке больших данных
При традиционном подходе данные, которые генерируются в организациях, подаются в систему ETL (от англ. Extract, Transform and Load) . Система ETL извлекает информацию, преобразовывает и загружает в базу данных. Как только этот процесс будет завершен, конечные пользователи смогут выполнять различные операции, вроде создание отчетов и запуска аналитических процедур.
По мере роста объема данных, становится сложнее ими управлять и тяжелее обрабатывать их с помощью традиционного подхода. К его основным недостаткам относятся:
Термины
Облачные Вычисления
Облачные вычисления или облако можно определить, как интернет-модель вычислений, которая в значительной степени обеспечивает доступ к вычислительным ресурсам. Эти ресурсы включают в себя множество вещей, вроде прикладного программного обеспечение, вычислительных ресурсов, серверов, центров обработки данных и т. д.
Прогнозная Аналитика
Технология, которая учится на опыте (данных) предсказывать будущее поведение индивидов с помощью прогностических моделей. Они включают в себя характеристики (переменные) индивида в качестве входных данных и производит оценку в качестве выходных. Чем выше объясняющая способность модели, тем больше вероятность того, что индивид проявит предсказанное поведение.
Описательная Аналитика
Описательная аналитика обобщает данные, уделяя меньше внимания точным деталям каждой их части, вместо этого сосредотачиваясь на общем повествовании.
Базы данных
Данные нуждаются в кураторстве, в правильном хранении и обработке, чтобы они могли быть преобразованы в ценные знания. База данных – это механизм хранения, облегчающий такие преобразования.
Хранилище Данных
Хранилище данных определяется как архитектура, которая позволяет руководителям бизнеса систематически организовывать, понимать и использовать свои данные для принятия стратегических решений.
Бизнес-аналитика
Бизнес-аналитика (BI) – это набор инструментов, технологий и концепций, которые поддерживают бизнес, предоставляя исторические, текущие и прогнозные представления о его деятельности. BI включает в себя интерактивную аналитическую обработку (англ. OLAP, online analytical processing) , конкурентную разведку, бенчмаркинг, отчетность и другие подходы к управлению бизнесом.
Apache Hadoop
Apache Hadoop – это фреймворк с открытым исходным кодом для обработки больших объемов данных в кластерной среде. Он использует простую модель программирования MapReduce для надежных, масштабируемых и распределенных вычислений.
Apache Spark
Apache Spark – это мощный процессорный движок с открытым исходным кодом, основанный на скорости, простоте использования и сложной аналитике, с API-интерфейсами на Java, Scala, Python, R и SQL. Spark запускает программы в 100 раз быстрее, чем Apache Hadoop MapReduce в памяти, или в 10 раз быстрее на диске. Его можно использовать для создания приложений данных в виде библиотеки или для выполнения специального анализа в интерактивном режиме. Spark поддерживает стек библиотек, включая SQL, фреймы данных и наборы данных, MLlib для машинного обучения, GraphX для обработки графиков и потоковую передачу.
Интернет вещей
Интернет вещей (IoT) – это растущий источник больших данных. IoT – это концепция, позволяющая осуществлять интернет-коммуникацию между физическими объектами, датчиками и контроллерами.
Машинное Обучение
Машинное обучение может быть использовано для прогностического анализа и распознавания образов в больших данных. Машинное обучение является междисциплинарным по своей природе и использует методы из области компьютерных наук, статистики и искусственного интеллекта. Основными артефактами исследования машинного обучения являются алгоритмы, которые облегчают автоматическое улучшение на основе опыта и могут быть применены в таких разнообразных областях, как компьютерное зрение и интеллектуальный анализ данных.
Интеллектуальный Анализ Данных
Интеллектуальный анализ данных – это применение специфических алгоритмов для извлечения паттернов из данных. В интеллектуальном анализе акцент делается на применении алгоритмов в ходе которых машинное обучение используются в качестве инструмента для извлечения потенциально ценных паттернов, содержащихся в наборах данных.
Где применяются большие данные
Аналитика больших данных применяется в самых разных областях. Перечислим некоторые из них:
- Поставщикам медицинских услуг аналитика больших данных нужна для отслеживания и оптимизации потока пациентов, отслеживания использования оборудования и лекарств, организации информации о пациентах и т. д.
- Туристические компании применяют методы анализа больших данных для оптимизации опыта покупок по различным каналам. Они также изучают потребительские предпочтения и желания, находят корреляцию между текущими продажами и последующим просмотром, что позволяет оптимизировать конверсии.
- Игровая индустрия использует BigData, чтобы получить информацию о таких вещах, как симпатии, антипатии, отношения пользователей и т. д.
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
- подготовитесь к сдаче вступительных экзаменов в Школу анализа данных Яндекса;
- углубитесь в математический анализ, линейную алгебру, комбинаторику, теорию вероятностей и математическую статистику;
- узнаете роль чисел, формул и функций в разработке алгоритмов машинного обучения.
- освоите специальную терминологию и сможете читать статьи по Data Science без постоянных обращений к поисковику.
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.
Источник: proglib.io
Технологии Big Data: как использовать Большие данные в маркетинге

Big Data — это сложные и объёмные наборы разной информации. Они представлены в «сыром виде» и требуют предварительной обработки, чтобы получить из них ценные сведения, которые могут принести пользу предприятиям и организациям.
В этой статье вы узнаете:
Что такое Big Data?
Термин Big Data появился в 2008 году. Впервые его употребил редактор журнала Nature — Клиффорд Линч. Он рассказывал про взрывной рост объемов мировой информации и отмечал, что освоить их помогут новые инструменты и более развитые технологии.
Чтобы понять Big Data, необходимо определиться с понятием и его функцией в маркетинге. В наши дни пользователи генерируют данные регулярно: когда они открывают какое-либо приложение, ищут информацию в Google, совершают покупки в интернете или просто путешествуют со смартфоном в кармане. В результате возникают огромные массивы ценной информации, которую компании собирают, анализируют и визуализируют.
Big Data буквально переводится на русский язык как «Большие данные». Этим термином определяют массивы информации, которые невозможно обработать или проанализировать при помощи традиционных методов с использованием человеческого труда и настольных компьютеров. Особенность Big Data еще и в том, что массив данных со временем продолжает экспоненциально расти, поэтому для оперативного анализа собранных материалов необходимы вычислительные мощности суперкомпьютеров. Соответственно, для обработки Big Data необходимы экономичные, инновационные методы обработки информации и предоставления выводов.
Но зачем прилагать столько усилий для систематизации и анализа Big Data? Аналитику Больших данных используют, чтобы понять привлекательность товаров и услуг, спрогнозировать спрос на рынке и реакцию на рекламную кампанию. Работа с Big Data помогает фирмам привлечь больше потенциальных клиентов и увеличить доходы, использовать ресурсы рационально и строить грамотную бизнес-стратегию.
А это значит, что аналитики, умеющие извлекать полезную информацию из больших данных, сейчас нарасхват. Научиться этому можно, даже если вы никогда не работали в IT. Например, «Факультет аналитики Big Data» от GeekBrains предлагает удобные онлайн-занятия и десяток кейсов в портфолио. Кстати, первые шесть месяцев обучения бесплатно. Успешно прошедших курс обязательно трудоустроят – это прописано в договоре.
Разница подходов
Традиционная аналитика;Big data аналитика
Постепенный анализ небольших пакетов данных;Обработка сразу всего массива доступных данных Редакция и сортировка данных перед обработкой;Данные обрабатываются в их исходном виде Старт с гипотезы и ее тестирования относительно данных;Поиск корреляций по всем данным до получения искомой информации Данные собираются, обрабатываются, хранятся и лишь затем анализируются;Анализ и обработка больших данных в реальном времени, по мере поступления
Функции и задачи больших данных
Анализ Больших данных начинается с их сбора. Информацию получают отовсюду: с наших смартфонов, кредитных карт, программных приложений, автомобилей. Веб-сайты способны передавать огромные объемы данных. Из-за разных форматов и путей возникновения Big Data отличаются рядом характеристик:
Volume. Огромные «объемы» данных, которые организации получают из бизнес-транзакций, интеллектуальных (IoT) устройств, промышленного оборудования, социальных сетей и других источников, нужно где-то хранить. В прошлом это было проблемой, но развитие систем хранения информации облегчило ситуацию и сделало информацию доступнее.
Velocity. Чаще всего этот пункт относится к скорости прироста, с которой данные поступают в реальном времени. В более широком понимании характеристика объясняет необходимость высокоскоростной обработки из-за темпов изменения и всплесков активности.
Variety. Разнообразие больших данных проявляется в их форматах: структурированные цифры из клиентских баз, неструктурированные текстовые, видео- и аудиофайлы, а также полуструктурированная информация из нескольких источников. Если раньше данные можно было собирать только из электронных таблиц, то сегодня данные поступают в разном виде: от электронных писем до голосовых сообщений.
В России под Big Data подразумевают также технологии обработки, а в мире — лишь сам объект исследования.
Функция;Задача
Big Data — собственно массивы необработанных данных;Хранение и управление большими объемами постоянно обновляющейся информации Data mining — процесс обработки и структуризации данных, этап аналитики для выявления закономерностей;Структурирование разнообразных сведений, поиск скрытых и неочевидных связей для приведения к единому знаменателю Machine learning — процесс машинного обучения на основе обнаруженных связей в процессе анализа;Аналитика и прогнозирование на основе обработанной и структурированной информации
Big Data характеризует большой объем структурированных и неструктурированных данных, которые ежеминутно образуется в цифровой среде. IBM утверждает, что в мире предприятия ежедневно генерируют почти 2,5 квинтиллиона байтов данных! А 90% глобальных данных получено только за последние 2 года.
Но важен не объем информации, а возможности, которые даёт её анализ. Одно из основных преимуществ Big Data — предиктивный анализ. Инструменты аналитики Больших данных прогнозируют результаты стратегических решений, что оптимизирует операционную эффективность и снижает риски компании.
Big Data объединяют релевантную и точную информацию из нескольких источников, чтобы наиболее точно описать ситуацию на рынке. Анализируя информацию из социальных сетей и поисковых запросов, компании оптимизируют стратегии цифрового маркетинга и опыт потребителей. Например, сведения о рекламных акциях всех конкурентов, позволяют руководство фирмы предложить более выгодный «персональный» подход клиенту.
Компании, правительственные учреждения, поставщики медицинских услуг, финансовые и академические учреждения — все используют возможности Больших данных для улучшения деловых перспектив и качества обслуживания клиентов. Хотя исследования показывают, что еще почти 43% коммерческих организаций до сих пор не обладают необходимыми инструментами для фильтрации нерелевантных данных, теряя потенциальную прибыль. Поэтому сегодня на рынке наметился курс на модернизацию бизнес-процессов, освоение новых технологий и внедрение Big Data.
Блокчейн и Биг Дата: потенциал объединенной технологии
Блокчейн — это децентрализованная система транзакций, где каждую транзакцию проверяет каждый элемент сети. Такая система гарантирует неизменность и невозможность манипуляции данными.
Криптовалюты и другие технологии блокчейн становятся все более популярными. Только в Японии почти 50 банков вступили в партнерские отношения с Ripple, сетью блокчейнов с открытым исходным кодом и с третьей по величине рыночной капитализацией криптовалютой в мире. Для банков сотрудничество обеспечит мгновенные безрисковые транзакции по низкой цене. Интерес к подобным операциям проявляют финансовые структуры в других странах, что означает дальнейшее развитие новых технологий в банковской сфере.
Популярность технологии предвещает рост объема транзакционных данных, записанных в регистрах, в геометрической прогрессии. К 2030 году информация, содержащаяся в реестре блокчейн, составит до 20% мирового рынка Больших данных и будет генерировать до 100 миллиардов долларов годового дохода. Хранение этих «озер данных» у традиционных поставщиков облачных хранилищ (AWS или Azure) обойдется в целое состояние. Своевременно на рынке появились поставщики децентрализованных хранилищ данных, предлагающие экономию затрат до 90%. Их работа облегчает внедрение блокчейн по всему миру и гарантирует развитие сферы.
Если большие данные — это количество, то блокчейн — это качество.
Использование блокчейна открывает новый уровень аналитики Big Data. Такая информация структурирована, полноценна и безопасна, так как ее невозможно подделать из-за сетевой архитектуры. Анализируя ее, алгоритмы смогут проверять каждую транзакцию в режиме реального времени, что практически уничтожит мошенничество в цифровой сфере. Вместо анализа записей о махинациях, которые уже имели место, банки могут мгновенно выявлять рискованные или мошеннические действия и предотвращать их.
Технология блокчейн применима не только к финансовому сектору. Неизменяемые записи, контрольные журналы и уверенность в происхождении данных — всё это применимо в любых бизнес-сферах. Уже сейчас компании внедряют блокчейн при торговле продуктами питания, а с другой стороны — изучают перспективы технологии при освоении космоса. Ожидается, что будущие решения в сфере Big Data и блокчейн радикально изменят способы ведения бизнеса.
Машинное обучение
Сегодня во многих отраслях внедряют машинное обучение для автоматизации бизнес-процессов и модернизации экономической сферы. Концепция предусматривает обучение и управление искусственным интеллектом (ИИ) с помощью специальных алгоритмов. Они учат систему на основе открытых данных или полученного опыта. Со временем такое приложение способно прогнозировать развитие событий без явного программирования человеком и часов потраченных на написание кода.
Например, с помощью машинного обучения можно создать алгоритм технического анализа акций и предполагаемых цен на них. Используя регрессионный и прогнозный анализы, статистическое моделирование и анализа действий, эксперты создают программы, которые рассчитывают время выгодных покупок на фондовом рынке. Они анализируют открытые данные с бирж и предлагают наиболее вероятное развитие событий.
При работе с Большими данными машинное обучение выполняет сходную функцию: специальные программы анализируют внушительные объемы информации без вмешательства человека. Все, что требуется от оператора «научить» алгоритм отбирать полезные данные, которые нужны компании для оптимизации процессов. Благодаря этому аналитики составляют отчеты за несколько кликов мыши, высвобождая своё время и ресурсы для более продуктивных задач: обработки результатов и поиск наиболее эффективных стратегий.
В динамично развивающемся мире, где ожидания клиентов всё выше, а человеческие ресурсы всё ценнее, машинное обучение и наука о данных играют решающую роль в развитии компании. Цифровая технологизация рабочего процесса жизненно необходима для сохранения лидирующих позиций в конкурентной среде.
Источник: www.uplab.ru
Big Data: что это такое простыми словами — характеристики технологии больших данных и методы их обработки


Если постараться дать определение простыми словами, что такое big data (биг дата или в переводе большой объем данных), то это обобщающее название для информационного потока, технологии, методов его обработки и системы анализа. Он обрабатывается путем применения программных инструментов, ставших аналогом традиционным базам и решениям Business Intelligence. Все действия направлены на структурирование и получение новых выводов.
Что это такое
IT-сфера уверенно заполняет пространство вокруг людей. Однако получаемые знания не могут уходить «вникуда», а учитывая колоссальный размер, хранилище должно быть объемным. Человечество уже давно перешло на цифровые носители, при этом все они отличаются по размеру.
Для работы с большими массивами информации нужен специальный набор инструментов и методик, чтобы с их помощью решать конкретные поставленные задачи. По сути, совокупность различных данных и инструментарий работы с ними и определяет термин Big Data. Этот социально-экономический феномен напрямую связан с появлением масштабируемых технологий, которые позволяют работать с огромным количеством информации.
Разница используемых методик
Всего выделяют 2 основных подхода к аналитике, которые имеют кардинально разные стратегии.
| Традиционная | Современная |
| Анализирование небольших инфо-блоков | Обработка всего массива информации сразу |
| Редактирование, структурирование | Использование исходников |
| Разработка и проверка гипотез | Поиск соотношений по всему потоку до достижения результата |
| Поэтапность: сбор, хранение, анализ | Аналитика в реальном времени |
Это могут быть консультации, товары или услуги, возможно внедрение программ оптимизации потребления ресурсов, прогнозирование. При этом важно защитить серверы от мошеннических манипуляций и угрозы вируса. Учитывая характер полученных сведений, программист сможет создать уникальные платформы и барьеры, защищающие от утечки.
Как происходило развитие в мире
Рост объема получаемой информации ежегодно растет в геометрической прогрессии. Если в 2003 году он составлял всего 5 Эб, то в 2015 этот показатель возрос до 6,5 Зб и до сих пор продолжает увеличиваться. При этом новые полученные знания можно смело назвать жизненно важным активом, а основы безопасности должны стать фундаментом. Повсеместное возрастание значимости феномена способно кардинально изменить экономическую ситуацию в мире, а незаинтересованный пользователь будет находиться в постоянном контакте с различными электроустройствами.
Источник: www.cleverence.ru
Что такое Big Data: характеристики, классификация, примеры

Что такое Big Data (дословно — большие данные)? Обратимся сначала к оксфордскому словарю:
Данные — величины, знаки или символы, которыми оперирует компьютер и которые могут храниться и передаваться в форме электрических сигналов, записываться на магнитные, оптические или механические носители.
Термин Big Data используется для описания большого и растущего экспоненциально со временем набора данных. Для обработки такого количества данных не обойтись без машинного обучения.
Преимущества, которые предоставляет Big Data:
- Сбор данных из разных источников.
- Улучшение бизнес-процессов через аналитику в реальном времени.
- Хранение огромного объема данных.
- Инсайты. Big Data более проницательна к скрытой информации при помощи структурированных и полуструктурированных данных.
- Большие данные помогают уменьшать риск и принимать умные решения благодаря подходящей риск-аналитике
Примеры Big Data
Нью-Йоркская Фондовая Биржа ежедневно генерирует 1 терабайт данных о торгах за прошедшую сессию.
Социальные медиа: статистика показывает, что в базы данных Facebook ежедневно загружается 500 терабайт новых данных, генерируются в основном из-за загрузок фото и видео на серверы социальной сети, обмена сообщениями, комментариями под постами и так далее.
Реактивный двигатель генерирует 10 терабайт данных каждые 30 минут во время полета. Так как ежедневно совершаются тысячи перелетов, то объем данных достигает петабайты.
Классификация Big Data
Формы больших данных:
- Структурированная
- Неструктурированная
- Полуструктурированная
Структурированная форма
Данные, которые могут храниться, быть доступными и обработанными в форме с фиксированным форматом называются структурированными. За продолжительное время компьютерные науки достигли больших успехов в совершенствовании техник для работы с этим типом данных (где формат известен заранее) и научились извлекать пользу. Однако уже сегодня наблюдаются проблемы, связанные с ростом объемов до размеров, измеряемых в диапазоне нескольких зеттабайтов.
1 зеттабайт соответствует миллиарду терабайт
Глядя на эти числа, нетрудно убедиться в правдивости термина Big Data и трудностях сопряженных с обработкой и хранением таких данных.
Данные, хранящиеся в реляционной базе — структурированы и имеют вид ,например, таблицы сотрудников компании
Неструктурированная форма
Данные неизвестной структуры классифицируются как неструктурированные. В дополнении к большим размерам, такая форма характеризуется рядом сложностей для обработки и извлечении полезной информации. Типичный пример неструктурированных данных — гетерогенный источник, содержащий комбинацию простых текстовых файлов, картинок и видео. Сегодня организации имеют доступ к большому объему сырых или неструктурированных данных, но не знают как извлечь из них пользу.
Примером такой категории Big Data является результат Гугл поиска:
Полуструктурированная форма
Эта категория содержит обе описанные выше, поэтому полуструктурированные данные обладают некоторой формой, но в действительности не определяются с помощью таблиц в реляционных базах. Пример этой категории — персональные данные, представленные в XML файле.
Prashant RaoMale35 Seema R.Female41 Satish ManeMale29 Subrato RoyMale26 Jeremiah J.Male35
Характеристики Big Data
Рост Big Data со временем:
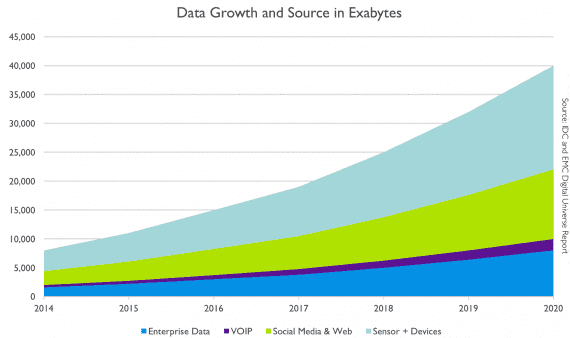
Синим цветом представлены структурированные данные (Enterprise data), которые сохраняются в реляционных базах. Другими цветами — неструктурированные данные из разных источников (IP-телефония, девайсы и сенсоры, социальные сети и веб-приложения).
В соответствии с Gartner, большие данные различаются по объему, скорости генерации, разнообразию и изменчивости. Рассмотрим эти характеристики подробнее.
- Объем. Сам по себе термин Big Data связан с большим размером. Размер данных — важнейший показатель при определении возможной извлекаемой ценности. Ежедневно 6 миллионов людей используют цифровые медиа, что по предварительным оценкам генерирует 2.5 квинтиллиона байт данных. Поэтому объем — первая для рассмотрения характеристика.
- Разнообразие — следующий аспект. Он ссылается на гетерогенные источники и природу данных, которые могут быть как структурированными, так и неструктурированными. Раньше электронные таблицы и базы данных были единственными источниками информации, рассматриваемыми в большинстве приложений. Сегодня же данные в форме электронных писем, фото, видео, PDF файлов, аудио тоже рассматриваются в аналитических приложениях. Такое разнообразие неструктурированных данных приводит к проблемам в хранении, добыче и анализе: 27% компаний не уверены, что работают с подходящими данными.
- Скорость генерации. То, насколько быстро данные накапливаются и обрабатываются для удовлетворения требований, определяет потенциал. Скорость определяет быстроту притока информации из источников — бизнес процессов, логов приложений, сайтов социальных сетей и медиа, сенсоров, мобильных устройств. Поток данных огромен и непрерывен во времени.
- Изменчивость описывает непостоянство данных в некоторые моменты времени, которое усложняет обработку и управление. Так, например, большая часть данных неструктурирована по своей природе.
Big Data аналитика: в чем польза больших данных
Продвижение товаров и услуг: доступ к данным из поисковиков и сайтов, таких как Facebook и Twitter, позволяет предприятиям точнее разрабатывать маркетинговые стратегии.
Улучшение сервиса для покупателей: традиционные системы обратной связи с покупателями заменяются на новые, в которых Big Data и обработка естественного языка применяется для чтения и оценки отзыва покупателя.
Расчет риска, связанного с выпуском нового продукта или услуги.
Операционная эффективность: большие данные структурируют, чтобы быстрее извлекать нужную информацию и оперативно выдавать точный результат. Такое объединение технологий Big Data и хранилищ помогает организациям оптимизировать работу с редко используемой информацией.
Интересные статьи:
- Интернет вещей ускорил развитие AI в геометрической прогрессии
- Квантовые алгоритмы в облаке ускорят обучение моделей машинного обучения в 25-50 раз
- Китай получит данные миллионов африканских лиц для улучшения технологий распознавания
Источник: neurohive.io