
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) это новейший метод механического перевода, который преобразует изображения рукописного текста в редактируемый текст на вашем компьютере. Например, он может сделать обычный PDF с отсканированного файла с помощью OCR или PDF на основе изображения, или преобразует рукописный текст в печатный. Технология была разработана в 1933 году, и с каждым годом развивалась. В настоящее время инструменты OCR способны выполнять огромную работу в преобразовании газет, писем, книг и любых других печатных или рукописных материалов в компьютерные редактируемые тексты.
Технология распознавания OCR рукописных текстов в настоящее время используется в больших масштабах, при этом уровень точности транскрипции растет день ото дня, и она уже близка к совершенству. В настоящее время, вы можете просто взять рецепт от врача и использовать технологию OCR, чтобы расшифровать его. Это невероятно!
Часть 1. Рекомендуемые программы для OCR распознавания рукописных текстов
Поиск лучших программ по OCR распознаванию рукописного текста может стать реальной проблемой, тем более, с тех пор как в Интернете появилось множество таких инструментов. Не беспокойтесь! Мы проанализировали рынок за вас, и выделили 3 лучших инструмента по OCR распознаванию рукописного ввода:
Лучшие программы для распознавания текста. Рейтинг OCR.
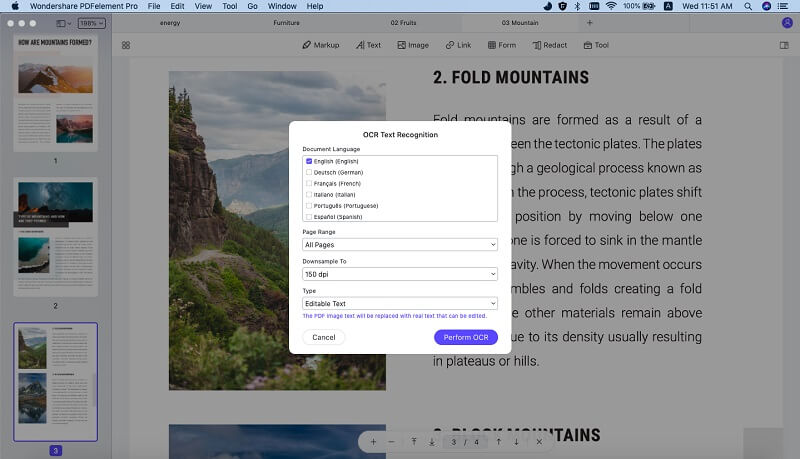
#1. PDFelement Pro
PDFelement ProPDFelement Pro- идеальный инструмент для OCR распознавания PDF-файлов. Он может автоматически распознавать отсканированные файлы PDF и делать их редактируемыми с помощью встроенных инструментов редактирования. Кроме этого, он поддерживает несколько языков OCR. Вы можете легко редактировать ваши PDF-тексты, изображения, ссылки и другие элементы. Также у вас есть возможность конвертировать PDF-файлы в другие форматы.
Основные функции данной PDF OCR программы:
- Расширенная функция OCR позволяет легко конвертировать и редактировать отсканированные PDF-файлы.
- Редактирование текстов PDF, изображений и ссылок – такое же простое, как и внесение изменений в Word.
- С легкостью добавляйте подпись, пароль, водяные знаки, знаки, нарисованные от руки в PDF-файлы.
- Размещайте комментарии и примечание, где вам необходимо.
- Вы также можете просто создавать PDF из множества других форматов.
- Кроме этого, у вас есть возможность конвертировать PDF в такие форматы, как Excel, MS Word и другие.
#2. OCR Desktop
Это OCR приложение для настольного компьютера включает в себя искусственный интеллект и нейронные сети для улучшения качества работы. Конвертер курсивного письма PDF в текст обучали более, чем четырём миллионам вариантов шрифтов, так что вы можете быть уверены, преобразованный текст будет точным насколько это вообще возможно. Он также владеет новейшей технологией OCR для решения любой задачи в распознавании почерка. А что, если мы добавим, что приложение является бесплатным для личного использования? Тем не менее, в нем есть реклама, но если вы хотите избавиться от нее, то необходимо получить зарегистрированную версию.

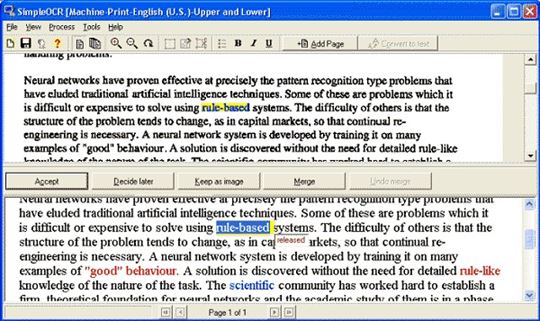
#3. SimpleOCR
SimpleOCR – одна из самых популярных бесплатных программ OCR доступных в сети. Она довольно проста, но в ее арсенале есть все основные функции сканирования и конвертации, которые важны при работе с OCR распознаванием рукописных текстов. Однако если вы хотите расширенные возможности, то тогда вам необходимо воспользоваться платной версией.
#4. TopOCR
Создатели TopOCR говорят, что они создали наиболее мощную систему распознавания, на основе нейронной сети, которая доступна на рынке, а также обещают пользователям лучшие результаты OCR распознавания данных, сделанных с помощью цифровой камеры. Поэтому, если у вас есть письмо, которое вы хотите оцифровать, сфотографируйте его и позвольте TopOCR выполнить свою работу. К сожалению, приложение было бесплатным некоторое время назад, но сегодня вам придется купить его, чтобы использовать. Но разработчики действительно используют сложные алгоритмы обработки изображений, чтобы гарантировать отличный результат!
Часть 2. Советы по распознаванию рукописного текста с помощью OCR
Применение OCR технологии:Технология OCR широко используется во многих сферах: от юристов и учителей до менеджеров и библиотекарей, любой, кто пишет во время своей работы или имеет дело с рукописями, письмами или подобными документами, считает эту технологию невероятной. Вы можете оцифровать любой рукописный документ быстро и просто, превратить его в редактируемый текст, с которым вы можете работать на вашем компьютере.
Советы: Чтобы улучшить использование OCR распознания рукописного текста, убедитесь, что ваши документы написаны четким почерком и чистые, то есть без помарок, а также используйте мощный сканер. Но главное — выберите профессиональную программу распознавания рукописного текста, которая может гарантировать точность редактируемого текста. Если вы решили использовать инструмент OCR на своем компьютере, вам просто нужно выбрать надежное программное обеспечение, доступное в интернете. Вы также можете попробовать использовать онлайн инструменты, но имейте в виду, что они, возможно, имеют довольно ограниченные функции.
Источник: pdf.iskysoft.com
Системы оптического распознавания символов (OCR)
Программные системы и сервисы оптического распознавания символов (ОРС, англ. Optical character recognition, OCR) предназначены для сканирования текста, обработки содержимого и извлечения полезных данных из документов различных видов. С помощью такого программного обеспечения, как правило, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
Чтобы претендовать на включение в категорию OCR, программный продукт должен соответствовать критериям:
- Обрабатывать цифровые фотографии или сканированные документы различных типов;
- Идентифицировать и извлекать соответствующие задаче данные в документах;
- Передавать данные в соответствующие системы внутри организации;
- Помогать в классификации и сортировке захватываемых файлов документов.
Читать далее
Сравнение Системы оптического распознавания символов (OCR)
Выбрать по критериям:
Системы оптического распознавания символов (OCR)
Подходит для
Специалист
Малый бизнес
Средний бизнес
Корпорация
Администрирование
Импорт/экспорт данных
Многопользовательский доступ
Наличие API
Отчётность и аналитика
Тарификация
Ежемесячная оплата
Ежегодная оплата
Единовременная оплата
Оплата потребления
По запросу
Развёртывание
Сервер предприятия
Мобильное устройство
Персональный компьютер
Облако (SaaS)
Графический интерфейс
Веб-браузер
Поддержка языков
Азербайджанский
Белорусский
Бенгальский
Болгарский
Венгерский
Вьетнамский
Грузинский
Индонезийский
Итальянский
Каталонский
Латвийский
Монгольский
Нидерландский
Норвежский
Персидский
Португальский
Украинский
Французский
Хорватский
Английский
Нет продуктов
Руководство по покупке Системы оптического распознавания символов
1. Что такое Системы оптического распознавания символов
Программные системы и сервисы оптического распознавания символов (ОРС, англ. Optical character recognition, OCR) предназначены для сканирования текста, обработки содержимого и извлечения полезных данных из документов различных видов. С помощью такого программного обеспечения, как правило, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
2. Назначение и цели использования Системы оптического распознавания символов
Программные продукты оптического распознавания символов могут использоваться бухгалтерскими, кадровыми, маркетинговыми и информационно-аналитическими группами. Системы OCR предназначены для сбора важной информации из большого количества бумажных и цифровых файлов. Данное программное обеспечение может значительно сократить время, затрачиваемое на ручной ввод, свести к минимуму человеческий фактор и улучшить работу по обнаружению мошенничества.
Системы и сервисы OCR используют новейшие технологии, такие как машинное обучение, обработка естественного языка и распознавание изображений для интеллектуального сканирования документов и непрерывного улучшения на основе шаблонов и поведения пользователей.
3. Обзор основных функций и возможностей Системы оптического распознавания символов
Администрирование Возможность администрирования позволяет осуществлять настройку и управление функциональностью системы, а также управление учётными записями и правами доступа к системе. Импорт/экспорт данных Возможность импорта и/или экспорта данных в продукте позволяет загрузить данные из наиболее популярных файловых форматов или выгрузить рабочие данные в файл для дальнейшего использования в другом ПО.
Многопользовательский доступ Возможность многопользовательской доступа в программную систему обеспечивает одновременную работу нескольких пользователей на одной базе данных под собственными учётными записями. Пользователи в этом случае могут иметь отличающиеся права доступа к данным и функциям программного обеспечения.
Наличие API Часто при использовании современного делового программного обеспечения возникает потребность автоматической передачи данных из одного ПО в другое. Например, может быть полезно автоматически передавать данные из Системы управления взаимоотношениями с клиентами (CRM) в Систему бухгалтерского учёта (БУ).
Для обеспечения такого и подобных сопряжений программные системы оснащаются специальными Прикладными программными интерфейсами (англ. API, Application Programming Interface). С помощью таких API любые компетентные программисты смогут связать два программных продукта между собой для автоматического обмена информацией. Отчётность и аналитика Наличие у продукта функций подготовки отчётности и/или аналитики позволяют получать систематизированные и визуализированные данные из системы для последующего анализа и принятия решений на основе данных.
4. Отличительные черты Системы оптического распознавания символов
Чтобы претендовать на включение в категорию OCR, программный продукт должен соответствовать критериям:
- Обрабатывать цифровые фотографии или сканированные документы различных типов;
- Идентифицировать и извлекать соответствующие задаче данные в документах;
- Передавать данные в соответствующие системы внутри организации;
- Помогать в классификации и сортировке захватываемых файлов документов.
Источник: soware.ru
Распознавание текста
Оптическое распознавание текста англ. optical character recognition (сокр. OCR) — перевод последовательности изображений символа в последовательность кодов, использующихся для представления в текстовом редакторе. Перевод осуществляется с помощью различных алгоритмов, после преобразования изображения в набор элементарных точек.
В данный момент очень сложно найти бесплатную программу для распознавания текста. Но Вам повезло, здесь Вы можете скачать такую программу. Она хоть и не идеальна, но при правильной настройке вполне работоспособна.
CuneiForm 12
35.4 МБ (инсталлятор)
Windows 98/ME/2000/XP/2003/Vista/7 32-bit
Бесплатная программа для автоматического распознавания отсканированного текста. Вид у программы не карамельный, но дело своё она знает.
Компьютер уже уверенно вошел в жизнь рядового гражданина. Когда надо получить сравнительно небольшой объем печатной информации, проще всего набрать этот текст вручную при помощи текстового редактора.
Однако иногда надо «переписать» целую книгу. В таких случаях рациональнее всего использовать сканер. Но сам по себе сканер делает только фотокопию текста, которую никак нельзя редактировать. Для того, чтобы изменить информацию на полученном изображении следует провести распознавание документа.
Бесспорным лидером в этом деле является система OCR (англ. optical character recognition — оптическое распознавание текста) от Abbyy — FineReader. Но стоит она довольно дорого и не каждый может позволить себе иметь в своем арсенале такой инструмент. Сегодня мы познакомимся с бесплатной альтернативой Файн Ридера — программой CuneiForm. Приведу сравнительную таблицу возможностей обеих пакетов:
Сравнение распознавалки текста CuneiForm с платным аналогом FineReader
| Особенности | CuneiForm | FineReader |
| Стоимость | бесплатно | от 1340 р. |
| Количество языков распознавания | 34 | 184 |
| Возможность комбинировать языки распознавания | — | + |
| Сохранение исходного форматирования текста | + | + |
| Пакетное распознавание текста | + | +/- |
| Ограничение по разрешению файла-скана | до 400 dpi | нет |
| Поддержка всех типов сканеров | только с TWAIN-интерфейсом | + |
Как видим, если хочется бесплатно распознавать текст, придется кое в чем уступить. Первое, с чем придется смириться — неумение CuneiForm работать с некоторыми сканерами (в особенности сканерами МФУ). Поэтому придется сканировать документ при помощи стандартных функций Windows. Второе — надо следить за разрешением сканирования.
Это связано с тем, что CuneiForm не может обрабатывать большие файлы (свыше 100 Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато качество распознавания текста в программе намного выше, чем у платного конкурента, а поэтому оптимальным вариантом параметров скана будет 200 dpi (можно и больше, но тогда есть вероятность, что программа просто зависнет).
Количество языков тоже невелико, но основные есть. Более того, хоть комбинировать языки и нельзя, зато в CuneiForm есть смешанный англо-русский режим распознавания! На этом минусы заканчиваются :). Можно начинать установку.
Установка CuneiForm
Здесь сложностей нет, поскольку Вам поможет инсталлятор. Просто запускайте установочный файл и следуйте инструкциям. После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.

Интерфейс программы
Интерфейс CuneiForm намного проще, чем у Fine Reader, и почти не требует настройки. Программой можно полностью управлять благодаря кнопкам на панели инструментов. Рассмотрим их более детально:

Программа может работать в режиме мастера, который активируется первой кнопкой. Но если CuneiForm не поддерживает Ваш сканер, то от этого режима стоит отказаться. Следующая кнопка запускает процесс сканирования (опять же, если есть поддержка сканера). На этой и следующих кнопках Вы можете заметить небольшие стрелочки. Нажав на них, мы получим доступ к некоторым дополнительным функциям.
Работа с CuneiForm
Теперь давайте опробуем CuneiForm на практике. Если программа поддерживает Ваш сканер, то первой кнопкой, которую следует нажать, будет «Получить изображение». Если же такой возможности нет, то откроем уже готовый скан (поддерживаются форматы JPG, GIF, BMP, PNG (не всегда корректно), а также TIF (в полной мере)).

Теперь следует произвести разметку. Она помогает определить блоки, из которых состоит страница. Поддерживается распознавание блоков в виде текста (синяя рамка), рисунков (зеленая рамка) или таблиц (оранжевая рамка) (автоматическую разметку можно доработать вручную, используя контекстное меню блока).

Когда текст обозначен, самое время провести его распознавание. Для этого нажимаем следующую кнопку. По окончании процесса распознавания в рабочем окне отобразится текст, который можно редактировать в небольшом встроенном текстовом редакторе похожем на Microsoft Word. При этом Вы сразу сможете увидеть те слова, в которых программа «не уверена» (голубая подсветка) и в которых есть ошибка (сомнительная буква — розовая).

И, наконец, после успешного редактирования можно сохранить результат нашей работы. Кликаем последнюю кнопку на панели инструментов и сохраняем текст как RTF, HTML или TXT-файл.

Если же Вы желаете большего, то, нажав на стрелочку сбоку, Вы сможете выбрать опции экспорта в одну из предложенных программ (Microsoft Word, Excel или Евфрат).

Посмотрите на предыдущий скриншот. Наверняка вы обратили внимание, что в дополнительных меню кнопок, начиная с «Разметки» и заканчивая «Сохранением», есть в конце пункт «Автомат». Активирование этой опции освобождает Вас от нажатия выбранной кнопки. То есть можно автоматизировать процесс обработки скана до того, что Вы будете лишь открывать новый документ. Все остальное CuneiForm сделает сама!
Общие настройки CuneiForm
Программа изначально настроена самым оптимальным образом, но если Вы что-то захотите изменить, просто зайдите в меню «Файл» и выберите опцию «Общие параметры». Это может пригодиться для смены языка и некоторых других параметров распознавания, форматирования и сканирования текстов.

Пакетное распознавание
На этом можно было бы и закончить, если бы в пакет CuneiForm не входила еще одна утилитка. Откройте «Пуск» снова и в папке с программой обнаружите еще одно приложение — «Пакетное распознавание». Представьте, что Вы отсканировали целую книгу! и теперь надо ее распознать. Если открывать каждый файл-скан по отдельности на это уйдет уйма времени, пакетный же режим представляет возможность указать нужные файлы, а об остальном программа позаботится сама.

Для начала нужно создать новый пакет файлов. Нажимаем соответствующую кнопку и следуем подсказкам запустившегося мастера:
На последнем этапе мы можем либо просто сохранить наш пакет, либо начать немедленное распознавание. В последнем случае запустится режим распознавания, который может затянуться на несколько минут (в зависимости от количества файлов-сканов).

По окончании распознавания Вы сможете увидеть в основном окне все распознанные документы. Если распознавание прошло успешно, то в левой боковой панели Вы обнаружите активными только два списка: «Исходные» и «Обработанные». Если же будут файлы, которые не удалось распознать, их мы найдем в разделе «Ошибки».

Теперь остается только сохранить полученные файлы и радоваться жизни :).
Выводы
Потенциал у CuneiForm явно хороший, однако разработка ведется довольно медленно. Несмотря на открытый исходный код, компания Cognitive, видимо, очень требовательна к разработчикам, раз прогресс так долго не появляется. Остается только надеяться, что дело сдвинется с мертвой точки и программа станет еще лучше, а пока довольствуемся малым. Но такое ли уж оно и малое… Выбор за Вами!
P.S. Разрешается свободно копировать и цитировать данную статью при условии указания открытой активной ссылки на источник и сохранения авторства Руслана Тертышного.
P.P.S. Вам также может пригодится еще одна довольно занятная программа. GetWindowText, пусть и не полноценная система распознавания, но может помочь Вам захватить текст и графику с экрана для последующей обработки:
Захват экрана https://www.bestfree.ru/soft/office/capture.php
Обучающий видеоурок, посвящённый работе с программой CuneiForm
Источник: www.bestfree.ru