Не удается выполнить поиск по тексту в PDF-файле после обновления Acrobat или Acrobat Reader до последней версии
Только в ОС Windows
В Acrobat или Acrobat Reader не удается выполнить поиск по тексту в PDF-файле с помощью инструмента «Найти» или «Расширенный поиск».
Применимо к версиям
- Acrobat (версия 2021.001.20135 | выпуск за 9 февраля 2021 г.)
- Acrobat Reader (версия 2021.001.20135 | выпуск за 9 февраля 2021 г.)
Решение 1. Обновление Acrobat или Acrobat Reader до последнего исправления
Обновите приложение Acrobat или Acrobat Reader. В последнем исправлении выпуска (21.001.20142) эта проблема устранена. Чтобы выполнить обновление прямо из приложения, откройте Acrobat или Acrobat Reader и выберите Справка > Проверка обновлений.
Если проблема не решена, обратитесь к решению 2 ниже.
Решение 2. Включение PDF-индексации с помощью ключа реестра bFallbackOnix32
Применимо в Windows (32-разрядная версия)
How to delete Adobe Reader history Windows 10
Обновите Acrobat и Acrobat Reader до версии 21.001.20142 или более поздней, а затем попробуйте выполнить шаги ниже.
Закройте Acrobat или Acrobat Reader, если приложение уже запущено.
Откройте редактор реестра: откройте меню Выполнить (кнопка меню Windows+R), введите regedit.exe в поле «Открыть» и затем нажмите ОК.
- Acrobat:
Путь: HKEY_LOCAL_MACHINESOFTWAREWOW6432NodeAdobeAdobe AcrobatDCFeatureState
Ключ: bFallbackOnix32
Тип: REG_DWORD
Значение: 1
Путь: HKEY_LOCAL_MACHINESOFTWAREWOW6432NodeAdobeAcrobat ReaderDCFeatureState
Ключ: bFallbackOnix32
Тип: REG_DWORD
Значение: 1
Источник: helpx.adobe.com
Как в открытом текстовом файле в программе Adobe Reader найти определенное слово/фразу и. т. п. , если:
Чтобы я не ввела, даже то, что есть в тексте, мне выводится следующее сообщение:
Reader has finished searching the document. No matches were found.
Что означает: Читатель закончил поиска документа. Не были найдены совпадения. в Find.
Даша Башлакова
-adobe reader не работает с текстовыми файлами, pdf only
-pdf может быть набор картинок (нераспознанный текст) , ессно, никакого текстового поиска быть не может
Александр Новиков
Вообще то PDF никогда не был текстовым форматом, это формат изображения, по сути, фотография. А бесплатные версии Adobe Reader никогда не имели инструментов распознавания и редактирования текста. Для таких операций нужна или платная версия адобовского бегемота, или РЕДАКТОРЫ (а не РИДЕРЫ) от других производителей.
Как правило, для работы с текстом PDF сначала конвертируется в текстовый формат, и только после этого редактируется. P.S. Насколько я помню, Поиск в Adobe Reader предназначен для поиска документов на компьютере по заголовкам, а не поиска слов в тексте. И ответ программы переводится: Ридер закончил поиск ДОКУМЕНТА. Совпадений (в названиях) не обнаружено.
Fix Toolbars Missing In Adobe Reader | How to Show or Hide PDF Toolbars in Adobe Acrobat Reader DC
Что означает — Документов с таким текстом в названиях файлов на компьютере нет. Добавлю, что единственная хорошая разработка Adobe — Photoshop. Всё остальное сделано просто отвратительно, программы других разработчиков и быстрее и качественнее работают. И намного удобнее, да ещё и мультиязычные (включая русский).
Источник: sprashivalka.com
Как починить поиск в русском PDF
Начинающий пользователь Help+Manual, пишущий документацию на русском языке, рано или поздно сталкивается с ситуацией, когда в созданном PDF-документе не работает поиск. Русский текст отображается корректно, но после копирования вставляется из буфера кракозябрами. В этой статье я расскажу, как это исправить и почему так получается.
Настройки по инструкции разработчика
Чтобы в PDF документах на русском языке, сгенерированных Help+Manual, корректно работал поиск, задайте следующие настройки:
- В языковых настройках проекта Configuration Common Properties Language Settings выберите русский язык и русскую кодировку. Это нужно для корректной работы Help+Manual с кириллицей.
- В параметрах публикации Configuration Publishing Options Adobe PDF Fonts Embedding включите внедрение шрифтов. Используйте режимы:
- Embed CID Fonts (обеспечивает максимальное качества текста при увеличении);
- Embed Type3 fonts (выберите, если поиск не заработал с предыдущим режимом; работает всегда, но качество текста при увеличении будет ниже).
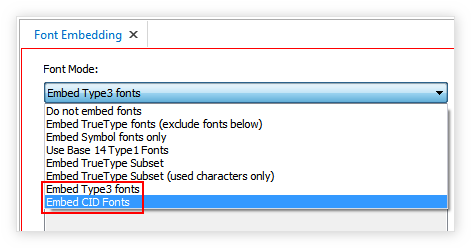
- Проверьте список исключений Do NOT embed these fonts. Он должен быть пустым. Все шрифты, использованные для оформления текста на русском языке, должны быть внедрены в документ*.
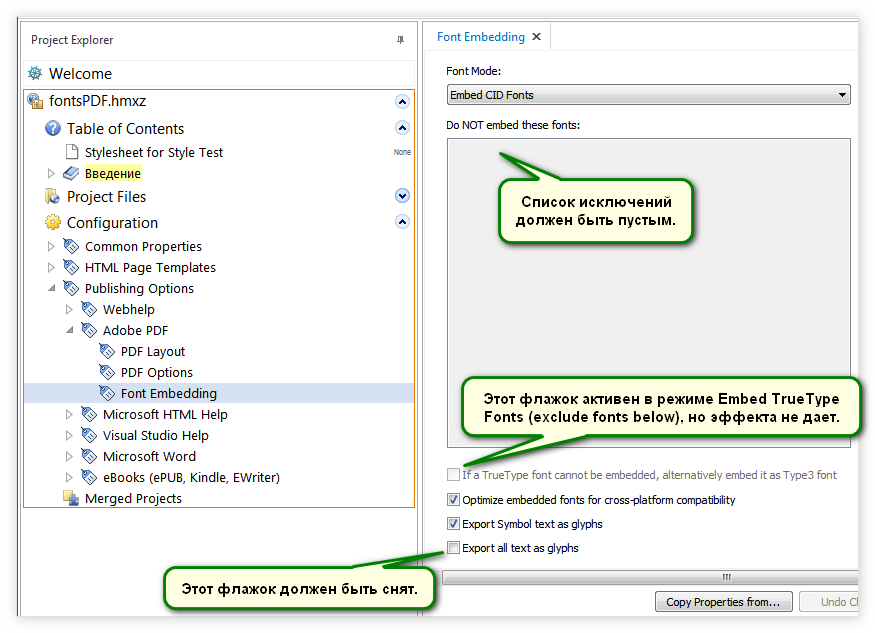
- В нижней части окна проверьте флажок Export all text as glyphs (Экспортировать весь текст как глифы). Он должен быть снят.
- В настройках Help+Manual View Program Options PDF Export проверьте драйвер принтера, используемый для генерации PDF**.
Дополнительная информация
*1. Разработчики формата PDF в документации указывают, что поиск в pdf-файлах, содержащих Кириллицу, должен работать и без внедрения шрифтов:
**2. В моей практике проблему поиска в русских PDF помогал решить только правильно выбранный режим внедрения шрифтов. Но этот пункт есть в инструкции разработчика по наладке поиска в PDF-документах с Кириллицей. Полный текст инструкции можно посмотреть на форуме поддержки.
3. Я пользуюсь Help+Manual с 2005 года, начиная с версии 4. С проблемой поиска в русских PDF-файлах сталкивался только в приложениях Adobe. В других бесплатных программах для просмотра PDF-файлов (например, STDU PDF Viewer и Foxit PDF Reader) поиск текста на русском языке всегда работал корректно. Русский текст также корректно копировался и вставлялся.
В чем причина
Новое — это хорошо забытое старое. Проблема с поиском в русских PDF была в HelpManual начиная с версии 3 для генерации PDF-файлов используется компонент wPDF от компании WPCubed GmbH (Мюнхен).