
Что же такое OpenMP? Основная задача, которая стояла перед разработчиками стандарта OpenMP, — создать программный интерфейс, позволяющий использовать многопоточный программный код как в ОС Windows, так и в Unix/Linux, а кроме того, совместимый с наиболее распространенными языками программирования.
Что же такое OpenMP? Разработка этого теперь широко используемого стандарта многопоточного программирования началась почти десять лет назад. Распространенные в то время операционные системы (Windows, Unix, Solaris) предполагали различные методы программирования потоков. Основная задача, которая стояла перед разработчиками стандарта OpenMP, — создать программный интерфейс, позволяющий использовать многопоточный программный код как в ОС Windows, так и в Unix/Linux, а кроме того, совместимый с наиболее распространенными языками программирования.
OpenMP — это реализация метода мультипоточного программирования (multithreading). Всю OpenMP- программу можно разделить на последовательные и параллельные секции. Для выполнения параллельного участка кода порождается необходимое количество дочерних потоков, причем как именно это происходит в конкретной операционной системе, скрыто от программиста. То есть при разработке программ можно сосредоточиться на алгоритмической части, не тратя сил на реализацию технических аспектов параллелизма.
Вводная — Параллельные(многопоточные) вычисления в OpenMP и C++17.
Рассмотрим наиболее часто используемые конструкции OpenMP на примере классического приложения, вычисляющего полином некоторой степени.
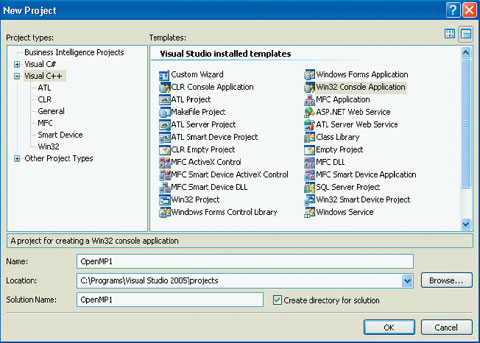
Итак, откроем новый проект в MS Visual Studio 2005. Это будет пустое консольное приложение для Win32 (Win32 Console Application). Для того чтобы Visual Studio не создавала автоматически никакого программного кода, нужно в мастере Win32 Application Wizard на второй вкладке установить флажок Empty Project (Пустой проект) (рис.1).
Теперь в папке Source File (Файлы с программным кодом) создадим новый файл, который и будет содержать код нашего приложения (листинг 1).

Дальше необходимо включить в проект поддержку OpenMP, в противном случае компилятор проигнорирует все прагмы OpenMP. Для этого в Solution Explorer надо вызвать меню, щелкнув правой кнопкой мыши по самой первой строчке, содержащей название проекта (в нашем случае OpenMP1), и выбрать пункт Properties в выпадающем меню. В левой части появившегося окна раскройте список с заголовком С/С++, затем выберите в нем Language, и тогда справа появится список опций, одна из которых будет носить имя OpenMP Support (рис.2).
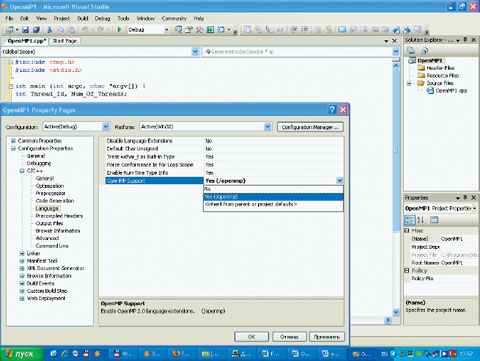
В выпадающем списке, расположенном напротив этой опции, нужно выбрать Yes (/openmp), тем самым добавив в проект поддержку OpenMP. Теперь можно закрыть окно, нажав кнопку OK. Запустим приложение с помощью комбинации клавиш + .
OpenMP
Рассмотрим более подробно, как работает наша программа. Выражение #pragma omp parallel сообщает компилятору о том, что описывается некая OpenMP-конструкция, а именно параллельная секция. Это подразумевает, что участок кода, стоящий в фигурных скобках, будет выполняться параллельно на нескольких вычислительных ядрах. Заключительная конструкция в рассматриваемой директиве — private (Thread_Id). Здесь необходимо вспомнить, что в системах с общей памятью, для программирования которых и создавался OpenMP, необходимо всегда различать общие и частные переменные (см. врезку «Работа с переменными…»).
Директива private (Thread_Id) указывает, что переменная Thread_Id в создаваемом параллельном регионе будет частной. Нужно это для того, чтобы присвоить ей номер текущего потока, используя функцию omp_get_num_threads (). В то же время функция omp_get_thread_num () вернет некоторое целое число — общее число порожденных потоков. Очевидно, что для любого потока выполнения это число будет одним и тем же, а значит, нет необходимости менять тип переменной Num_Of_Threads с общего на частный, подобно переменной Thread_Id. Стоит добавить, что все функции OpenMP начинаются с приставки «omp_» и все порожденные в рамках определенного параллельного региона потоки нумеруются с нуля.
Параллельные регионы OpenMP
Рассмотрим классический код программы для вычисления полинома (листинг 2).
Вычисление полинома высоких степеней — задача простая, но требующая значительных вычислительных ресурсов. Следует обратить внимание на то, что прог-раммный код в данном случае уже оптимизирован: так, если сумму произведений S вычислять по формуле S = S + a [j] * pow (x, j), где функция pow () возводит аргумент x в степень j на каждом шаге цикла, то падение производительности будет иметь просто катастрофический характер. Поэтому следующий шаг к сокращению времени работы программы — распределение вычислений между всеми доступными процессорами.
Рассмотрим код более подробно. Здесь вычислительная нагрузка сосредоточена внутри цикла. Самый простой способ распараллелить цикл — добавить прагму #pragma omp parallel for, как это сделано в листинге 3.
Здесь приведен фрагмент программы, поясняющий, как именно нужно модифицировать цикл for в функции main. Мы указываем компилятору, что хотим организовать вычисления таким образом, чтобы данный цикл выполнялся параллельно в нескольких потоках. Однако далеко не всегда достаточно добавить такую директиву.
Часто требуется, чтобы любые две итерации цикла были независимы одна от другой по данным. То есть если результат вычислений зависит от порядка их выполнения, то имеет место взаимная зависимость итераций между собой и компилятор, определив это, не сможет распараллелить данный цикл. В таких случаях нужно разделить работу между вычислительными потоками другим способом.
Наиболее распространенный — явно указать компилятору, какие действия можно выполнять независимо друг от друга. Для этого в стандарте OpenMP реализован механизм параллельных секций. Пример их использования для рассмотренного выше кода приведен в листинге 4, но стоит рассмотреть принципы работы с этой конструкцией более подробно.
Прагма omp parallel sections декларирует создание одной или нескольких параллельных секций, однако главная задача этой конструкции — описать, каким образом упомянутые секции будут взаимодействовать. В рассматриваемом примере указывается, что переменная S в порождаемых параллельных секциях будет общей, для чего используется конструкция shared (S).
Нужно это для того, чтобы вычисленная сумма была корректной — в обеих описанных ниже секциях переменная S используется для суммирования. Затем директива num_threads (2) сообщает компилятору, что для выполнения кон-струкции parallel sections следут создать два потока. Тут появляется некоторое отличие от реализации параллелизма в предыдущих примерах. Так, при использовании прагмы parallel for вычислительные потоки порождались в момент выполнения программы и их количество определялось количеством доступных процессорных ядер, а сейчас код программы заранее требует, чтобы в параллельном регионе были созданы ровно два потока. Стоит добавить, что директива num_threads (N), где N — целое положительное число, может использоваться и с другими OpenMP-конструкциями, допустим, так: #pragma omp parallel for num_threads (4).
В нашем примере мы создаем две секции кода, которые взаимодействуют посредством сохранения вычисленных значений в общей переменной S. Можно воспользоваться и другим подходом для вычисления суммы. Скажем, объявить еще две переменные S1 и S2, присвоить им нулевые значения до объявления параллельных секций, затем в каждой секции вычислить свою сумму элементов S1 или S2. Таким образом, переменные S1 и S2 будут содержать «полусуммы», после чего результат S можно будет найти как их сумму. Фрагмент кода, реализующий данную идею, приведен в листинге 5.
Важно понимать, что переменные S1 и S2 объявлены вне параллельного региона, а значит, для обеих созданных секций являются общими. В этом кроется потенциальная опасность: так, например, возможно, что в результате ошибки программиста второй поток выполнения запишет какое-либо значение в переменную S1, которую использует для суммирования первый поток. Некорректный результат очевиден. Чтобы этого избежать, целесообразно использовать директиву private (S1,S2). Описанный здесь пример, конечно, несколько надуман, однако по мере увеличения числа строк параллельного кода вероятность возникновения ошибки вследствие некорректного использования общих переменных возрастает.
Синхронизация выполнения параллельных потоков
Синхронизация потоков, выполняющихся в рамках одной программы, наиболее часто требуется, когда планируется совместное использование разделяемых ресурсов (а к таким относятся и общие переменные) или когда потоки начинают обмениваться сообщениями между собой. OpenMP значительно упрощает задачу: проблемы организации совместного доступа к общим переменным в параллельных секциях скрыты от программиста. Так, в рассмотренных выше примерах переменные, описанные в параллельной секции как shared (), с точки зрения прикладного программиста ничем не отличаются от всех остальных. Между тем имеются и дополнительные сред-ства синхронизации:
#pragma omp barrier (создание барьера): выполнение любого потока, достигшего данной прагмы, будет приостановлено до тех пор, пока все порожденные в рамках запущенной программы потоки не достигнут этой точки. В рассмотренных выше случаях в параллельных секциях данная конструкция задействуется по умолчанию.
Директива nowait (используется, например, так: #pragma omp for nowait) по действию обратна барьеру. Скажем, если в рамках параллельного региона потоки будут созданы с данной директивой, то синхронизации их между собой происходить не будет.
В заключение стоит отметить, что наиболее полно стандарт OpenMP описан на странице www. openmp. org, а детали его реализации в MS Visual Studio 2005 рассмотрены в MSDN.
Работа с переменными в многопоточных приложениях
Общая переменная (shared) в вычислительных системах с общей памятью — это именованный участок памяти, доступный всем OpenMP-потокам. В то же время частные (private) — это локализированные переменные, и каждый процесс обладает собственной копией такой переменной. Доступ к ним закрыт для всех создающихся потоков, кроме одного — владельца, поэтому все изменения некоторой частной переменной в одном потоке никак не повлияют на работу остальных. По умолчанию все переменные в OpenMP-программе общие, но с исключениями: частными являются индексы параллельных циклов и переменные, которые объявлены в параллельных регионах. И наконец, для переменной можно указать, что она будет частной в рамках некоторого параллельного региона.
Источник: www.osp.ru
Использование OpenMP для распараллеливания вычислений
Есть задача — восстановить пароль по его MD5 хэшу. Пароль простой, состоит из 7 цифр и начинается с 8-ки. Оговорюсь сразу — пароль мой, я его банально забыл, и это не инструкция о том, как брутфорсить чужие пароли.
Программа должна работать в несколько потоков для максимально быстрого достижения результата. Хотя бы потому, что запускать я ее буду на компьютере с двухъядерным процессором. Один поток не сможет максимально использовать оба ядра.
Рассмотрим два способа: создание нескольких рабочих потоков и использование OpenMP
Способ первый — создание нескольких потоков.
Для простоты будем решать задачу в лоб, без синхронизации потоков при выводе результатов. Иначе придется позаботиться о deadlock-ах, вернее об их отсутствии.
// Объявляем переменные
const int g_nNumberOfThreads = 4;
const int g_nFrom = 8000000;
const int g_nTo = 8999999;
const string g_strCompareWith = «4ac7b1796b90478f2991bb9a7b05d2bf» ;
// Объявляем структуру, через которую будем передавать в поток исходные данные
struct THREAD_PARAMS
int nFrom;
int nTo;
>;
// Прототип функции вычисляющей хэш MD5
BOOL GetMD5Hash( string strIn, string
int nFrom = pThreadParams->nFrom;
int nTo = pThreadParams->nTo;
for ( int i = nFrom; i < nTo; ++i)
stringstream stream;
stream
// Вычисляем очередной хэш
GetMD5Hash(stream.str(), strHash);
// Запуск потоков
void MultiThreadWay()
int nDataLength = ( int )(g_nTo — g_nFrom) / g_nNumberOfThreads;
HANDLE *hThreads = new HANDLE[g_nNumberOfThreads];
for ( int i = 0; i < g_nNumberOfThreads; ++i)
THREAD_PARAMS *pParams = new THREAD_PARAMS();
С использованием OpenMP код получился гораздо короче. При этом вычисление пароля вторым методом, на моем компьютере, выполнялось значительно быстрее. Не смотря на то, что оба метода «грузили» оба ядра почти полностью.
Если Вас заинтересовал OpenMP Вы можете начать изучение со статей, размещенные на сайте компании Intel
И не забудьте посетить сайт OpenMP. Там Вы сможете найти список компиляторов, поддерживающих OpenMP и спецификации OpenMP
Источник: habr.com
Основные конструкции OpenMP
Аннотация: Настоящая лекция посвящена изложению основ параллельного программирования с использованием OpenMP. В начале обсуждаются основные принципы программирования в OpenMP и рассматривается принципиальная схема программирования. Приводятся конкретные реализации управляющих директив OpenMP для программ, написанных на алгоритмических языках Fortran и C/C++.
Перечисляются основные правила применения директив OpenMP, использующихся для описания данных и организации параллельных вычислений. Обсуждаются вопросы видимости данных и корректности доступа к данным. Рассматриваются методы распараллеливания циклов и контроля распределения работы между процессорами. Приводятся способы балансировки работы процессоров с помощью директив OpenMP, а также задания внешних переменных окружения с помощью функций OpenMP.
Основные принципы OpenMP
OpenMP — это интерфейс прикладного программирования для создания многопоточных приложений, предназначенных в основном для параллельных вычислительных систем с общей памятью. OpenMP состоит из набора директив для компиляторов и библиотек специальных функций. Стандарты OpenMP разрабатывались в течение последних 15 лет применительно к архитектурам с общей памятью.
Описание стандартов OpenMP и их реализации при программировании на алгоритмических языках Fortran и C/C++ можно найти в [2.1-2.6]. Наиболее полно вопросы программирования на OpenMP рассмотрены в монографиях [2.7-2.8]. В последние годы весьма активно разрабатывается расширение стандартов OpenMP для параллельных вычислительных систем с распределенной памятью (см., например, работы [2.9]). В конце 2005 года компания Intel анонсировала продукт Cluster OpenMP, реализующий расширение OpenMP для вычислительных систем с распределенной памятью. Этот продукт позволяет объявлять области данных, доступные всем узлам кластера, и осуществлять передачу данных между узлами кластера неявно с помощью протокола Lazy Release Consistency.
OpenMP позволяет легко и быстро создавать многопоточные приложения на алгоритмических языках Fortran и C/C++. При этом директивы OpenMP аналогичны директивам препроцессора для языка C/C++ и являются аналогом комментариев в алгоритмическом языке Fortran. Это позволяет в любой момент разработки параллельной реализации программного продукта при необходимости вернуться к последовательному варианту программы.
В настоящее время OpenMP поддерживается большинством разработчиков параллельных вычислительных систем: компаниями Intel, Hewlett-Packard, Silicon Graphics , Sun , IBM , Fujitsu, Hitachi, Siemens, Bull и другими. Многие известные компании в области разработки системного программного обеспечения также уделяют значительное внимание разработке системного программного обеспечения с OpenMP.
Среди этих компаний отметим Intel, KAI, PGI, PSR, APR , Absoft и некоторые другие. Значительное число компаний и научно-исследовательских организаций, разрабатывающих прикладное программное обеспечение , в настоящее время использует OpenMP при разработке своих программных продуктов. Среди этих компаний и организаций отметим ANSYS, Fluent, Oxford Molecular, NAG, DOE ASCI , Dash , Livermore Software , а также и российские компании ТЕСИС, Центральную геофизическую экспедицию и российские научно-исследовательские организации, такие как Институт математического моделирования РАН, Институт прикладной математики им. Келдыша РАН, Вычислительный центр РАН, Научно-исследовательский вычислительный центр МГУ, Институт химической физики РАН и другие.
Принципиальная схема программирования в OpenMP
Любая программа , последовательная или параллельная, состоит из набора областей двух типов: последовательных областей и областей распараллеливания. При выполнении последовательных областей порождается только один главный поток (процесс). В этом же потоке инициируется выполнение программы, а также происходит ее завершение.
В последовательной программе в областях распараллеливания порождается также только один, главный поток , и этот поток является единственным на протяжении выполнения всей программы. В параллельной программе в областях распараллеливания порождается целый ряд параллельных потоков.
Порожденные параллельные потоки могут выполняться как на разных процессорах, так и на одном процессоре вычислительной системы. В последнем случае параллельные процессы (потоки) конкурируют между собой за доступ к процессору . Управление конкуренцией осуществляется планировщиком операционной системы с помощью специальных алгоритмов.
В операционной системе Linux планировщик задач осуществляет обработку процессов с помощью стандартного карусельного ( round-robin ) алгоритма. При этом только администраторы системы имеют возможность изменить или заменить этот алгоритм системными средствами. Таким образом, в параллельных программах в областях распараллеливания выполняется ряд параллельных потоков. Принципиальная схема параллельной программы изображена на рис.2.1.
Рис. 2.1. Принципиальная схема параллельной программы
При выполнении параллельной программы работа начинается с инициализации и выполнения главного потока (процесса), который по мере необходимости создает и выполняет параллельные потоки, передавая им необходимые данные. Параллельные потоки из одной параллельной области программы могут выполняться как независимо друг от друга, так и с пересылкой и получением сообщений от других параллельных потоков.
Последнее обстоятельство усложняет разработку программы, поскольку в этом случае программисту приходится заниматься планированием, организацией и синхронизацией посылки сообщений между параллельными потоками. Таким образом, при разработке параллельной программы желательно выделять такие области распараллеливания, в которых можно организовать выполнение независимых параллельных потоков.
Для обмена данными между параллельными процессами (потоками) в OpenMP используются общие переменные. При обращении к общим переменным в различных параллельных потоках возможно возникновение конфликтных ситуаций при доступе к данным. Для предотвращения конфликтов можно воспользоваться процедурой синхронизации ( synchronization ). При этом надо иметь в виду, что процедура синхронизации — очень дорогая операция по временным затратам и желательно по возможности избегать ее или применять как можно реже. Для этого необходимо очень тщательно продумывать структуру данных программы.
Выполнение параллельных потоков в параллельной области программы начинается с их инициализации. Она заключается в создании дескрипторов порождаемых потоков и копировании всех данных из области данных главного потока в области данных создаваемых параллельных потоков. Эта операция чрезвычайно трудоемка — она эквивалентна примерно трудоемкости 1000 операций.
Эта оценка чрезвычайно важна при разработке параллельных программ c помощью OpenMP, поскольку ее игнорирование ведет к созданию неэффективных параллельных программ, которые оказываются зачастую медленнее их последовательных аналогов. В самом деле: для того чтобы получить выигрыш в быстродействии параллельной программы, необходимо, чтобы трудоемкость параллельных процессов в областях распараллеливания программы существенно превосходила бы трудоемкость порождения параллельных потоков. В противном случае никакого выигрыша по быстродействию получить не удастся, а зачастую можно оказаться даже и в проигрыше.
После завершения выполнения параллельных потоков управление программой вновь передается главному потоку. При этом возникает проблема корректной передачи данных от параллельных потоков главному.
Здесь важную роль играет синхронизация завершения работы параллельных потоков, поскольку в силу целого ряда обстоятельств время выполнения даже одинаковых по трудоемкости параллельных потоков непредсказуемо (оно определяется как историей конкуренции параллельных процессов, так и текущим состоянием вычислительной системы). При выполнении операции синхронизации параллельные потоки, уже завершившие свое выполнение, простаивают и ожидают завершения работы самого последнего потока. Естественно, при этом неизбежна потеря эффективности работы параллельной программы. Кроме того, операция синхронизации имеет трудоемкость, сравнимую с трудоемкостью инициализации параллельных потоков, т. е. эквивалентна примерно трудоемкости выполнения 1000 операций.
На основании изложенного выше можно сделать следующий важный вывод : при выделении параллельных областей программы и разработке параллельных процессов необходимо, чтобы трудоемкость параллельных процессов была не менее 2000 операций деления. В противном случае параллельный вариант программы будет проигрывать в быстродействии последовательной программе. Для эффективной работающей параллельной программы этот предел должен быть существенно превышен.
Синтаксис директив в OpenMP
Основные конструкции OpenMP — это директивы компилятора или прагмы (директивы препроцессора) языка C/C++. Ниже приведен общий вид директивы OpenMP прагмы.
#pragma omp конструкция [предложение [предложение] … ]
2.2. Общий вид OpenMP прагмы языка C/C++
В языке Fortran директивы OpenMP являются строками-комментариями специального типа. Ниже в примере 2.3 приведены примеры таких строк в общем виде. Для обычных последовательных программ директивы OpenMP не изменяют структуру и последовательность выполнения операторов.
Таким образом, обычная последовательная программа сохраняет свою работоспособность. В этом и состоит гибкость распараллеливания с помощью OpenMP.
Большинство директив OpenMP применяется к структурным блокам. Структурные блоки — это последовательности операторов с одной точкой входа в начале блока и одной точкой выхода в конце блока.
c$omp конструкция [предложение [предложение] … ] !$omp конструкция [предложение [предложение] … ] *$omp конструкция [предложение [предложение] … ]
2.3. Общий вид директив OpenMP в программе на языке Fortran
В примерах 2.4 и 2.5 показаны примеры структурного и неструктурного блоков соответственно во фрагментах программ, написанных на языке Fortran.
Видно, что в первом примере рассматриваемый блок является структурным, поскольку имеет одну точку входа и одну точку выхода. Во втором примере рассматриваемый блок не является структурным, поскольку имеет две точки входа. Следовательно, использование конструкций OpenMP для его распараллеливания некорректно. Из этих примеров видно, что директивы OpenMP, применяемые к структурным блокам, аналогичны операторным скобкам begin и end в алгоритмических языках Algol и Pascal .
c$omp parallel 10 wrk (id) = junk (id) res (id) = wrk (id)**2 if (conv (res)) goto 10 c$omp end parallel print *, id
2.4. Пример структурного блока в программе на языке Fortran
c$omp parallel 10 wrk (id) = junk (id) 30 res (id) = wrk (id)**2 if (conv (res)) goto 20 goto 10 c$omp end parallel if (not_done) goto 30 20 print *, id
2.5.
Пример неструктурного блока в программе на языке Fortran
В следующем фрагменте программы (Пример 2.6) показан общий вид основных директив OpenMP на языке Fortran.
c$omp parallel c$omp private (var1, var2, …) c$omp lastprivate (var1, var2, …) c$omp if (expression) c$ompв шестой позиции строки используется для продолжения длинных директив OpenMP, не умещающихся на одной строке в программах на Fortran (см. рис.2.6).
Ниже во фрагменте программы (Пример 2.7) приведен общий вид основных директив OpenMP на языке C/C++.
# pragma omp parallel private (var1, var2, …) shared (var1, var2, …) firstprivate (var1, var2, …) lastprivate (var1, var2, …) copyin (var1, var2, …) reduction (operator: var1, var 2, …) if (expression) default (shared | none)
2.7. Общий вид основных директив OpenMP на языке C/C++
По сравнению с предыдущим, в рассматриваемом фрагменте появилось еще одно дополнительное предложение OpenMP — copyin . Оно позволяет легко и просто передавать данные из главного потока в параллельные. В Fortran также существует аналогичная возможность, однако механизм ее реализации несколько иной. Подробнее эти возможности будут рассмотрены далее. Кроме того, отметим, что вместо Fortran-директивы OpenMP
c$omp end parallel
в C/C++ используются обычные фигурные скобки . Для продолжения длинных директив на следующих строках в программах на C/C++ применяется символ » обратный слэш» в конце строки (см. пример 2.7).
Рассмотренные в настоящем разделе директивы OpenMP не охватывают весь спектр директив. В следующих разделах рассмотрим более подробно основные директивы OpenMP и механизм их работы.
Источник: intuit.ru