
Теперь, когда у нас есть уже текст программы на OpenCL, нам надо подготовить её к выполнению.
Первое, что нам для этого надо сделать — это задать, скажем так, среду исполнения, или как это зовётся в OpenCL — context.
Сначала создадим список необходимых нам свойств (пока одно) контекста:
cl_context_properties clCProp[ 3 ] =
CL_CONTEXT_PLATFORM , ( cl_context_properties ) platformID ,
0 // Нолик означает конец списка
Затем с помощью этого списка и функции clCreateContextFromType получим собственно вот этот самый контекст:
cl_context context = clCreateContextFromType (clCProp, CL_DEVICE_TYPE_GPU , NULL , NULL ,
В данном случае мы получаем контекст для указанной нами платформы ( platformID ), причём только для графических процессоров. Параметры NULL, NULL — это указание на то, что у нас пока нет функции для обратного вызова драйвером (ну не нужна пока), и каких-то особых данных для этой функции.
В переменную ret драйвер вернёт нам ошибку или значение CL_SUCCESS (обработка ошибок опущена, что бы не загромождать текст).
OpenCL
Теперь мы можем создать очередь команд (сами команды в эту очередь ставить будем потом)
cl_command_queue_properties prop = 0 ; // никаких особых свойств не надо пока
cl_command_queue commandQueue = clCreateCommandQueue ( context , myDevices IDs[0] , prop,
Теперь надо подготовить OpenCL-буферы, в которые мы будем загружать потом наши данные (входящий и исходящий буферы):
cl_mem inputImageBuffer = clCreateBuffer ( context , CL_MEM_READ_ONLY , inputSize , 0 ,
/* предпоследний нолик — это значит нет указателя на участок в обычной памяти, и не будем хранить данные в общей куче, а будем копировать в видюху. */
cl_mem outputImageBuffer = clCreateBuffer ( context , CL_MEM_READ_WRITE , outputSize , 0 ,
/* предпоследний нолик — это значит нет указателя на участок в обычной памяти, и не будем хранить данные в общей куче, а будем держать данные в видеокарте, пока не запустим копирование в обычную память. */
Тут надо заметить, что при получении потокового видео я использую три реальных буфера в памяти своей программы — пока драйвер веб-камеры копирует в один буфер очередной кадр, я работаю с другим буфером. Три буфера используются для надёжности, что бы уменьшить вероятность коллизии в случае тормозов в программе. Поэтому при создании OpenCL-буферов никакие адреса указывать нельзя — они всё время меняются, с каждым очередным кадром потокового видео. Передаём в функции создания OpenCL-буферов только требуемые размеры.
Ещё один важный момент: в Линуксе получение данных из веб-камеры выглядит как чтение из файла. При этом устройства и файлы для удобства можно отобразить в оперативную память (функцией mmap(. )). После отображения файла/устройства в память данные из него можно получать, копируя содержимое буферов, на которые отображено устройство/файл. В этом случае если при копировании данных в видеокарту функцией clEnqueueWriteBuffer (. ) мы будем копировать данные из памяти, на которую отображено устроство/файл , результат может оказаться неожиданным. (В спецификации OpenCL так и написано.) Когда я попробовал так сделать, в моей системе начались довольно серьёзные утечки памяти. Поэтому в случае обработки данных, получаемых от устройств, отображённых в память, надо сначала скопировать данные в обычный буфер вашей программы, а уже из этого буфера передавать данные в видеокарту.
Episode 1: What is OpenCL™?
Теперь мы даём драйверу указание создать объект-программу из исходного текста:
int sourceSize = strlen ( YUYVtoBGRprog );
cl_program program = clCreateProgramWithSource ( context , 1 ,
(( const char **)sourceSize,
Теперь уже строим исполняемый код программы:
В данном случае мы строим программу только для самого первого из обнаруженных в нашей системе устройств (да, для разных устройств — разный код). Пятый параметр, передаваемый этой функции — это наша программка, которую драйвер вызовет по окончании создания кода нашей программы. В этой функции мы можем узнать о результатах сборки с помощью функции clGetProgramBuildInfo:
CL_CALLBACK void myOpnCLCallBack ( cl_program program, void *user_data)
<
openCLClass *owner = ( openCLClass *)user_data; // ссылка на наш объект, в котором всё хранится
cl_build_status stat;
size_t t = 0 ;
cl_int ret = clGetProgramBuildInfo (program, stat,
В переменной stat к нам возвращается результат работы строителя программы.
if (stat == CL_BUILD_IN_PROGRESS)
<
return ; // значит программа пока строится
>
else if (stat == CL_BUILD_ERROR)
< /* ошибочка вышла, не построится программа. Здесь надо получить ошибки от компилятора OpenCL, смотрим описание — там всё подробно, я это опускаю */
>
else if (stat == CL_BUILD_SUCCESS)
< // Программа построена, можно грузить в видюху
/* вот тут, собственно, и создаётся уже рабочий объект типа cl_kernel — как я понимаю, это уже ну окончательно, совсем-совсем почти готовая к исполнению программа */
owner-> kernel = clCreateKernel (program, «YUYVtoBGRkernel» , //owner->program
/* Осталось только указать программе, что будет выступать в качестве аргументов в функции
«__kernel void YUYVtoBGRkernel(__global uchar4 *y, __global uchar8 *r)» */
stat = clSetKernelArg (owner-> kernel , 0 , sizeof ( cl_mem ), inputImageBuffer );
stat = clSetKernelArg (owner-> kernel , 1 , sizeof ( cl_mem ), outputImageBuffer );
В качестве аргументов у нас inputImageBuffer и outputImageBuffer. Нулевым номером (нолик) идёт inputImageBuffer, а первым номером outputImageBuffer.
Но и это ещё не всё. Прежде, чем запускать нашу программу на выполнение, ей надо передать данные для копирования во входящий буфер.
// Ставим в очередь копирование из входящего буфера в память видюхи
cl_int stat = clEnqueueWriteBuffer ( commandQueue , inputImageBuffer , CL_TRUE , 0 , inputSize , inputBuff, 0 , 0 , 0 );
inputBuff — это указатель на данные, которые передаются в видеокарту. InputSize — размер этих данных. Третьим параметром здесь идёт значение CL_TRUE , которое говорит о том, что функция clEnqueueWriteBuffer не вернётся, пока данные не будут скопированы. Таким образом мы предохраняемся от возможности запустить на выполнение нашу программу до того, как в видеокарте окажутся исходные данные.
Есть возможность передать в эту функцию ссылку на объект cl_event (событие), и тогда эта функция должна будет по завершению копирования внести в этот объект соответствующие изменения, ориентируясь на которые можно действовать дальше. Тут я не стал пока заморачиваться, и с блокирующим копированием неплохо работает.
И, наконец, запускаем уже нашу многострадальную программу на выполнение:
cl_event events [ 2 ];
cl_event eventSentData [ 2 ];
size_t globalThreads[] = < numOfElems >;
//size_t localThreads[] = ;
cl_int stat = clEnqueueNDRangeKernel ( commandQueue , kernel , 1 , NULL , globalThreads, NULL , 0 , 0 ,
В переменной globalThreads передаём количество тех самых элементов во входящем и в исходящем буферах, которые наша программа должна будет обработать. Основываясь на этом параметре наша программа будет вычислять тот самый индекс, который получается функцией «uint m = get_global_id(0);» . Также передаём ссылку на объект cl_event, что бы читать из видео-карты данные не раньше, чем наша OpenCL-программка закончит обработку данных. Чтение данных из видеокарты осуществляем с помощью функции clEnqueueReadBuffer :
cl_int stat = clEnqueueReadBuffer ( commandQueue , outputImageBuffer ,
CL_FALSE , 0 , outputSize , outputBuff, 1 , events ,
Здесь outputSize и outputBuff — это соответственно размер данных для чтения из видеокарты и указатель на буфер, в который это всё надо скопировать. И кстати, два предпоследних параметра здесь (1, events) обозначают, что надо проверить один (первый) объект cl_event из массива объектов cl_event events [ 2 ] . Этот объект должна изменить функция clEnqueueNDRangeKernel, когда она закончит обработку переданных ей данных. Соответственно, копирование данных начнётся только тогда, когда обработка данных уже закончилась. В третий параметр этой функции мы передаём значение CL_FALSE , что как раз и значит, что вызов этой функции «не блокирующий», то есть он немедленно возвращает управление в нашу программу, а выполнение этой функции откладывается до момента, когда произойдёт событие events [ 0 ] .
Что бы избежать возможных накладок, а именно повторного вызова этой процедуры и использования буферов ввода-вывода нашей OpenCL-программки до того, как обработанные выходные данные будут скопированы в буфер основной программы, после запуска процедуры копирования с lEnqueueReadBuffer ( . ) желательно вызвать процедуру
она позволит нам дождаться окончания процесса копирования данных в основную программу, и позволит нам после этого освободить ресурсы, отожранные библиотекой OpenCL под данные событий:
clReleaseEvent( events [0]);
clReleaseEvent( eventSentData [0]);
Если этого не сделать, ресурсы, отводимые под тысячекратно повторяемые события (в случае обработки видео-потока) постепенно израсходуют всю доступную в системе память.
Последние вызываемые функции (начиная с копирования данных в память видюхи) можно уже вызывать в цикле — программа по завершению никуда не девается, а остаётся в рабочем состоянии. У меня эти три функции вызываются по 10-20-30 раз в секунду (с такой частотой поступают кадры с веб-камеры, зависит от размера кадра).
Когда мы решили уже выключить наше потоковое видео, надо освободить все ресурсы, которые мы заняли в процессе подготовки и создания нашей OpenCL-программы:
clReleaseKernel( kernel );
clReleaseProgram( program );
clReleaseMemObject( inputImageBuffer );
clReleaseMemObject ( outputImageBuffer );
clReleaseCommandQueue ( commandQueue );
clReleaseContext ( context );
На этом и заканчивается полный цикл жизни OpenCL-программы. Создание её, конечно, довольно муторное, особенно если учесть, что надо ещё возможные ошибки обрабатывать, что я здесь опустил, зато если сделать соответствующий класс, можно заметно упростить написание этой рутины (ну, я так и сделал).
Зато, OpenCL даёт доступ к действительно немаленькой мощности, которую можно купить за совсем небольшие деньги. К примеру, цены на видеокарты с процессорами AMD Radeon HD 6770 в Москве начинаются от 3400 рублей (сильно подешевели с лета, как я погляжу). Между тем, этот графический процессор имеет на борту 800 потоковых процессоров (ядер) и выдаёт 1,36 терафлопа пиковой мощности при обработке данных одинарной точности. Видеокарты с двухтерафлопным Radeon HD 6870 c 1120-ю потоковыми процессорами начинаются от 6300 рублей.
С двойной точностью могут работать только ГП Radeon начиная с серии 69ХХ (на данный момент это топовые модели). Впрочем, двойная точность пока мало кому требуется.
Источник: diman-novik-ru.livejournal.com
Технология параллельного программирования OpenCL
Эту статью можно считать продолжением статьи [1] о технологии CUDA, здесь мы поговорим о технологии параллельного программирования OpenCL.
1. Введение
OpenCL (Open Computing Language ) это спецификация, описывающая технологию параллельного программирования, которая в первую очередь ориентирована на GPGPU. Изначально она была разработана компанией Apple, в последствии для развития спецификаций OpenCL был образована группа разработчиков Khronos Compute [2], в неё вошли Apple, nVidia, AMD, IBM, Intel, ARM, Motorola и др. Первая версия стандарта была опубликована в конце 2008 года.
В отличии от nVidia CUDA, AMD Stream и т.п., в OpenCL изначально закладывалась мультиплатформенность, т.е. OpenCL программа должна без изменений в коде работать на GPU разных типов (разных производителей). Такая программа без изменений должна работать даже на CPU без GPU, хотя в этом случае она может выполняться существенно медленнее чем на GPU.
2. Схема работы с аппаратурой
Итак — хотим мультиплатформенность и желательно без существенных потерь в производительности. Достигается этот результат следующим образом [3,4].
OpenCL-программа работает с т.н. платформами (platform) . Платформа это программный пакет, который поставляется соответствующим разработчиком аппаратных средств. Например «AMD Accelerated Parallel Processing» или «Intel OpenCL». При этом несколько платформ могут работать одновременно на одной машине.
Каждая платформа включает в себя ICD (Installable Client Driver) — программный интерфейс OpenCL для работы с устройствами, которые эта платформа поддерживает.
В среде Linux список ссылок на ICD, присутствующих в системе, обычно хранится в каталоге /etc/OpenCL/vendors/ , а библиотека libOpenCL.so выполняет роль диспетчера (ICD loader) , т.е. она направляет вызовы OpenCL функций на устройства, через соответствующие ICD.
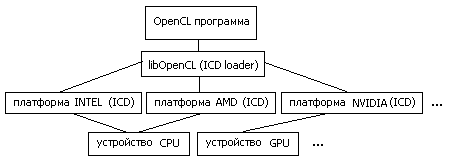
Рис.1: схема работы OpenCL программы с аппаратурой
[ Здесь ] можно увидеть пример конфигурации оборудования. На машине с процессором Intel Core2 CPU 6300 и графическим ускорителем nVidia Quadro FX1700, развернуты три платформы OpenCL: nVidia, AMD, Intel. При этом платформа nVidia поддерживает только GPU Quadro FX1700, а платформы AMD и Intel — только Intel Core2 CPU 6300 в качестве вычислительного устройства. Таким образом каждая платформа содержит одно вычислительное устройство.
Для определения возможностей OpenCL можно воспользоваться утилитой clinfo, также [ здесь ] можно скачать исходник программы, считывающую эту информацию.
Тут надо ещё сказать о версиях OpenCL SDK. При развёртывании платформы на компьютере необходимо уточнить версию пакета. Например, в процессе проведения экспериментов выяснилось, что Intel OpenCL SDK 2014 не поддерживает работу с процессором Intel Core2 CPU 6300, который был установлен на машине. Проблема решилась установкой более старого пакета Intel OpenCL SDK 2012.
3. Структура OpenCL-программы
В OpenCL (аналогично CUDA), программа разделяется на две части: первая часть — управляющая, вторая — вычислительная. В роли управляющего устройства ( host ) выступает центральный процессор (CPU), вычислительное устройство ( device ) выбираем из списка платформ и их устройств. Обычно используется GPU, но не обязательно, это может быть и тот же CPU.
Код, который должен выполняться на device, оформляется специальным способом. Поскольку device могут быть от разных производителей и разных типов, то скомпилировать один бинарник для всех не получится. Решается эта проблема следующим образом.
Текст ядра (kernel) , т.е. части программы выполняемой на device, включается в основную часть программы (выполняемой на host) в «чистом» виде т.е. в виде текстовой строки. Этот исходник компилируется средствами OpenCL непосредственно в процессе работы программы (runtime) для выбранного в данный момент вычислительного устройства, это происходит каждый раз при запуске OpenCL-программы.
Так же есть возможность, скомпилированный таким образом, код ядра сохранить и при инициализации вычислительной программы загружать готовый бинарник. Но в этом случае мы теряем универсальность, этот код будет работать только на одном (данном) типе устройств.
- получить информацию о платформах и устройствах
clGetPlatformIDs(),clGetPlatformInfo(), clGetDeviceIDs(),clGetDeviceInfo() - выбрать устройства и создать для них контекст
clCreateContext() - создать ядро из текста программы
clCreateProgramWithSource(), clBuildProgram(), clCreateKernel() - выделить память для данных на устройствах
clCreateBuffer() - создать очередь комманд для устройтва
clCreateCommandQueue(), clCreateCommandQueueWithProperties( ) - скопировать данные с host на device
clEnqueueWriteBuffer() - назначить параметры выполнения ядра
clSetKernelArg() - запуск ядра
clEnqueueNDRangeKernel() - скопировать результат с device на host
clEnqueueReadBuffer() - обработка результата
- завершение работы, освобождение ресурсов
clReleaseMemObject(), clReleaseKernel(), clReleaseProgram(), clReleaseCommandQueue(), clReleaseContext()
4. Пример OpenCL-программы
В качестве первого примера рассмотрим простую вычислительную задачу: С := d * A + B, где d — константа, А,В и С векторы заданного размера.
__kernel void kernel1(const float alpha, __global float *A, __global float *B, __global float *C) < int idx = get_global_id(0); C[idx] = alpha* A[idx] + B[idx]; >
Листинг 1: код ядра для задачи сложения векторов
Программа запускает много (по количеству элементов векторов) параллельных процессов (тредов) на device, каждый тред получает свой номер (get_global_id), исходя из него считывает свою часть данных из глобальной (__global) памяти device, выполняет вычисления и записывает свою часть результата обратно в память.
Код программы можно скачать [ здесь ]. Для сравнения напишем ещё простую (последовательную) программу и сравним время затраченное на вычисления. Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
| NVIDIA | Quadro FX 1700 | 3.2 |
| AMD | Intel Core2 CPU 6300 | 19.1 |
| Intel | Intel Core2 CPU 6300 | 11.0 |
| — | Intel Core2 CPU 6300 | 9.3 |
Таблица 1: результаты работы программы saxpy для разных платформ
По результатам, представленным в таб.1, видно, что выполнение примера на GPU почти в три раза быстрее чем на CPU. Для CPU платформа Intel показала лучший результат чем AMD, что очевидно для Intel Core2 CPU 6300. Наилучший результат для CPU показала простая программа, что можно объяснить эффективной работой компилятора и отсутствием необходимости выполнять дополнительные процедуры OpenCL.
5. Группы процессов и их конфигурация
Каждое вычислительное устройство обладает своими ограничениями по количеству одновременно выполняемых тредов, и хотя их общее количество в программе может быть велико, выполняться они будут частями или группами, максимальный размер группы зависит от конкретного устройства.
Иногда треды удобно формировать в виде решетки. Рассмотрим пример задачи умножения матриц.
Листинг 2: код ядра для задачи умножения матриц
Имеем на входе матрицы A[M*K], B[K*N] и соответственно буфер для результата C[M*N]. Программа создаёт M*N тредов в виде решетки MxN, каждый тред [r,c] отрабатывает одну ячейку в матрице результата.
Код программы можно скачать [ здесь ].
Для сравнения напишем ещё простую (последовательную) программу и сравним время затраченное на вычисления. Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
| NVIDIA | Quadro FX 1700 | 5169.5 |
| AMD | Intel Core2 CPU 6300 | 2279.0 |
| Intel | Intel Core2 CPU 6300 | 920.1 |
| — | Intel Core2 CPU 6300 | 1340.6 |
Таблица 2: результаты работы программы gemm1 для разных платформ
Результаты несколько расстраивают, поскольку из таб.2 видно, что GPU показала наихудший результат. Проблема в крайне неэффективном использовании памяти GPU. Далее мы исправим это затруднение.
6. Модели памяти и синхронизация процессов
В статье [1] была приведена схема организации GPU. Из этой схемы видно, что этот тип устройств обладает сложно организованной памятью, которая может работать с разной скоростью.
- Память global — основная память уcтройства, самая большая по размеру (512MB для FX1700) и самая медленная, она является общей для всех тредов.
- Память local — общая память для одной группы тредов (shared в терминах CUDA), этот тип быстрее global но существенно меньше по размеру (16KB для FX1700)
- Память private — память треда, быстрая но маленькая (8KB для FX1700)
Вернёмся к предыдущему примеру с умножением матриц. В процессе работы ядро выполняет много повторных чтений из памяти global. Попробуем сократить количество чтений с помощью организации быстрого кэша [5].
Листинг 3: код ядра для задачи умножения матриц с кэшированием
Имеем на входе матрицы A[M*K], B[K*N] и соответственно результат C[M*N]. Программа создаёт M*N тредов в виде решетки MxN, группами размера TSxTS, каждый тред отрабатывает одну ячейку в матрице результата, группа тредов кэширует блоки исходных матриц и далее выполняет операции с этим кэшем.
Для того, что бы кэш корректно был заполнен необходима синхронизация группы тредов (barrier) , достигая barrier программа ждет, пока все треды группы соберутся в этой точке и только после этого продолжает выполнение.
Код программы можно скачать [ здесь ].
Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
| NVIDIA | Quadro FX 1700 | 169.5 |
| AMD | Intel Core2 CPU 6300 | 2301.1 |
| Intel | Intel Core2 CPU 6300 | 1402.7 |
| — | Intel Core2 CPU 6300 | 1340.6 |
Таблица 3: результаты работы программы gemm2 для разных платформ
Из таблицы 3 видно, что модифицированная программа умножения матриц (gemm2) показывает вполне удовлетворительный результат производительности, работая гораздо быстрее первого варианта (gemm1).
7. Заключение
Хотя программы OpenCL могут выполняться с меньшей скоростью в сравнении с CUDA, но они обладает важным свойством — переносимость, этот стандарт имеет хорошие перспективы развития.
В заключении можно ещё привести ссылку на список библиотек, основанных на OpenCL.
https://www.khronos.org/opencl/resources/opencl-libraries-and-frameworks-with-opencl-acceleration
Список литературы
Источник: mechanoid.su
Как ускорить вычисления и повысить производительность программ с помощью принципов массивного параллелизма и OpenCL
Стандартный подход к написанию программ является линейным – операция b выполняется после завершения операции a. Но что делать в случае если таких операций десятки тысяч, а задача требует быстрого произведения данных операций?
Допустим, вы разрабатываете приложение с искусственным интеллектом для распознавания предметов основываясь на данных получаемых с сенсора, или пишете графическое приложение, которое требует множество вычислений на каждом из пикселей. Как сделать так, чтобы обработка информации происходила в реальном времени, а задержка между получением информации, её обработкой и выдачей результата была минимальной?
Те кто сталкивался с данной проблемой, наверняка знают про многопоточность (multithreading) — способ параллельного запуска определённых фрагментов кода для ускорения обработки этого кода. Но, к сожалению, этот метод подходит не всегда, и когда требуется произведение одинаковых операций на большом количестве данных, гораздо эффективнее будет прибегнуть к массивному параллелизму и использовать фреймворки OpenCL или CUDA.
В этой статье мы познакомимся с массивным параллелизмом и напишем программу для параллельных вычислений, используя фреймворк OpenCL.
OpenCL (Open Computing Language) — фреймворк разработанный Apple в 2008 году и поддерживаемый Khronos Group с 2009 года. Он позволяет создавать программы для параллельного исполнения на различных вычислительных девайсах (CPU и GPU), упакованные в «кернели»-ядра (kernels) — части кода, которые будут отправлены на вычислительный девайс для произведения каких-то операций.
OpenCL — замечательный инструмент, который может ускорить вашу программу в десятки, если не сотнитысячи раз. К сожалению, из-за отсутствия простых и доступных гайдов по данной спецификации, в особенности на русском языке, а так-же особенностям работы с ней (о чём мы поговорим чуть позже), начинающему разработчику может быть очень трудно разобраться в теме и попытки изучить спецификацию остаются безуспешными. Это большое упущение, и цель этой статьи — не только доступно и подробно рассказать о спецификации и продемонстрировать как работать с ней, но и написать гайд, который мне хотелось бы прочитать самому когда я начал изучать OpenCL.
Давайте параллелить
Массивный параллелизм — топик для целого цикла лекций по информатике и инженерии, по этому давайте ограничимся небольшим обобщением, чтобы понимать с чем мы имеем дело.
В линейном программировании мы имеем чёткую последовательность действий: a, b, c, d; действие b не будет выполнено до того как завершиться a и c не будет выполнено пока не завершиться b. Но что делать, если нам, например, требуется найти суммы элементов из двух массивов (листов), и в каждом массиве по 100,000 элементов? Последовательное вычисление заняло бы достаточно долгое время, так-как нам пришлось бы совершить минимум 100,000 операций. А что если такая процедура требует многочисленного повторения и результат нужен в реальном времени с минимальной задержкой? Тут нам и приходит на помощь массивный параллелизм!
Допустим, мы хотим вычислить суммы 0 + 3, 1 + 2, 2 + 1, 3 + 0 и записать результаты в массив. В линейном программировании, мы воспользуемся циклом for или while, где операции будут выполняться последовательно, и схема вычислений будет выглядеть примерно так:
Через последовательную итерацию, мы будем выполнять первое действие, записывать результат в массив и переходить к следующему действию. Поскольку для выполнения данных вычислений нам требуется 4 итерации, для наглядности, давайте обозначим что время (t) потраченное на выполнение данных операций равняется 4.
Массивный параллелизм позволяет нам сформировать и отправить данную задачу (0 + 3 и т.д.) для выполнения используя ресурсы, например, видеокарты — она имеет десятки, сотни, тысячи вычислительных единиц (ядер), которые могут производить операции параллельно, независимо друг от друга.
Имея достаточно место в массиве, нам не обязательно ждать пока заполнится предыдущий элемент массива перед тем как записывать следующий, мы можем присвоить задачам индексы, соответствующие их «месту» в массиве, и тем самым, записывать ответ каждого вычисления в правильное место, не дожидаясь пока предыдущая задача будет выполнена.
Другими словами, если 0 + 3 — вычисление номер один, а 1 + 2 — вычисление номер два, мы можем посчитать 1 + 2 и записать ответ во второе место в массиве (res[1]) не зависимо от того записан ли ответ 0 + 3 в первое место (res[0]). При этом, если мы попытаемся одновременно записать информацию в ячейки res[0] (первое место) и res[1] (второе место), у нас не возникнет ошибки.
Таким образом, с помощью массивного параллелизма мы можем одновременно и независимо друг от друга выполнить все нужные нам операции, и записать все ответы в массив, содержащий результаты, всего за одно действие, тем самым, сократив t до 1. Мы только что сократили временную сложность алгоритма (время работы алгоритма) до константного значения 1 (одно действие).
Две системы
Перед тем как мы перейдём к практике, важно прояснить специфику работы с OpenCL и разобраться как переписывать линейный код в параллельном формате. Не волнуйтесь — это совсем не сложно!
Кернель (kernel, вектор — функция, отправляемая на вычислительный девайс в контексте работы OpenCL) и хост (host — код, вызывающий OpenCL; ваш код) существуют, по большему счёту, изолированно друг от друга.
Компиляция и запуск кернеля OpenCL происходят внутри вашего кода, во время его исполнения (онлайн, или runtime execution). Так-же, важно понимать что кернель и хост не имеют общего буфера памяти и мы не можем динамически выделять память (с помощью malloc() и подобных) внутри кернеля. Обмен информацией между двумя системами происходит посредством отправления между ними заранее выделенных регионов памяти.
Другими словами, если у меня в хосте есть объект Х, для того чтобы обратится к нему из кернеля OpenCL, мне для начала нужно его туда отправить. Если вы всё ещё не до конца поняли о чём идёт речь — читайте дальше и всё прояснится!
Модель памяти OpenCL выглядит так:
При создании контекста OpenCL (среда в которой существует данный инстанс OpenCL), мы обозначаем нашу задачу как NDRange — общий размер вычислительной сетки — количество вычислений которые будут выполнены (в примере с суммами использованном выше, NDRange = 4). Информацию записанную в глобальную память (global memory) мы можем получить из любого элемента NDRange.
При отправке задачи на девайс OpenCL (например, видеокарту компьютера), наш NDRange разбивается на рабочие группы (work-groups) — локальная память (local memory), которые содержат в себе рабочие единицы (work-items, изолированные инстансы кернеля) — приватная память (private memory).