

На сегодняшний день существует большое количество различных систем управления базами данных — СУБД, от коммерческих до открытых, от реляционных до новомодных NoSQL и аналогичных.
Одним из лидеров направления СУБД является PostgreSQL и ее различные ответвления, о некоторых из которых мы рассмотрим подробнее.
В этой статье мы начнем говорить о СУБД PostgreSQL, рассмотрим отличия редакций и некоторые особенности архитектуры, а также процесс установки. Но начнем мы с небольшого ликбеза для того, чтобы читатели плохо знакомые с терминологией баз данных могли быстро войти в курс дела.
Итак, схемой мы будем называть логическое объединение таблиц в базе данных, а сама БД это физическое объединение таблиц. Индекс — отношение, которое содержит данные, полученные из таблицы или материализованного представления. Его внутренняя структура поддерживает быстрое извлечение и доступ к исходным данным.
PostgreSQL (Postgres) — Installation & Overview |¦| SQL Tutorial |¦| SQL for Beginners
Еще один важный термин, это первичный ключ — частный случай ограничения уникальности, определенной для таблицы или другого отношения, которое также гарантирует, что все атрибуты в первичном ключе не имеют нулевых значений. Как следует из названия, для каждой таблицы может быть только один первичный ключ, хотя возможно иметь несколько уникальных ограничений, которые также не имеют атрибутов, поддерживающих значение null.
Ну и наконец, наверное, самый распространенный термин — транзакция это комбинация команд, которые должны действовать как единая атомарная команда. То есть, все они завершаются успешно или завершаются неудачно как единое целое, и их эффекты не видны другим сеансам до завершения транзакции, и, возможно, даже позже, в зависимости от уровня изоляции. Соответственно, если выполнение хотя бы одной команды внутри транзакции завершилось ошибкой — вся транзакция завершится ошибкой.
Редакции PostgreSQL
В этой статье мы рассмотрим три основные редакции PostgreSQL:
- Классический PostgreSQL;
- Российский Postgres Professional;
- 2nd Quadrant Postgres-XL.
Начнем с классики

Классической редакцией СУБД PostgreSQL является «ванильная» сборка от PGDG, PostgreSQL Global Development Group. PostgreSQL создана на основе некоммерческой СУБД Postgres, разработанной как open-source проект в Калифорнийском университете в Беркли. Название расшифровывалось как «Post Ingres», и при создании Postgres были применены многие ранние наработки БД Ingres.
Именно эту редакцию мы будем рассматривать в конце статьи, когда речь пойдет об установке базы.
Postgres Professional

Сборка Postgres Pro это российская коммерческая СУБД, разработанная компанией Postgres Professional с использованием свободно-распространяемой СУБД PostgreSQL. Но при этом классическая СУБД значительно переработана для соответствия требованиям корпоративных заказчиков и российских регуляторов. Также Postgres Pro входит в реестр российского ПО и имеет действующий сертификат ФСТЭК.
Что такое базы данных? ДЛЯ НОВИЧКОВ / Про IT / Geekbrains
Рассмотрим более подробно основные отличия Postgres Pro Standard от классической PostgreSQL.
Прежде всего, существуют две версии Postgres Pro:
- Postgres Pro Standard
- Postgres Pro Enterprise
Sysadminium
Рассмотрим общее устройство PostgreSQL. А именно как с ним взаимодействует клиент, его особенности. Рассмотрим работу его процессов и то как они взаимодействуют с памятью. Дополнительно можете почитать документацию.
Клиент серверная работа PostgreSQL
PostgreSQL эта сервер который обслуживает базы данных SQl. К нему подключаются клиенты и с помощью SQL запросов работают с этими базами. Клиентские приложения могут быть расположены на сервере приложений или прямо на компьютере пользователя.
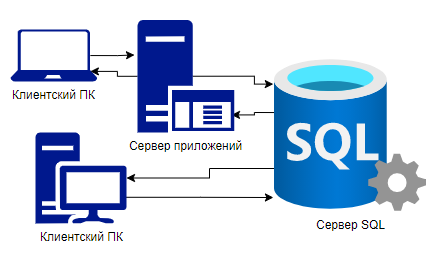
Клиент – это какое-то приложение, например psql. Клиент с сервером общается по определённому протоколу. Протокол у PostgreSQL открытый, но для каждого приложения его не нужно реализовывать. Обычно используют стандартные библиотеки и драйверы. Основная библиотека это libpq, её использует psql и все штатные утилиты PostgreSQL.
Для многих языков программирования есть свои библиотеки, которые основаны на libpq.
Алгоритм работы с сервером примерно такой:
- клиент подключается к серверу, а сервер выполняет его аутентификацию;
- клиент формирует запросы, а сервер их выполняет и возвращает результаты;
- дополнительно клиент управляет транзакциями, а сервер обеспечивает их поддержку.
Транзакции SQL
Транзакция – это группа последовательных операций с базой данных, которые выполняются как одна операция.
Транзакция имеет определённые требования:
- Атомарность – это означает что транзакция всегда выполняется полностью, или не выполняется вообще. Это гарантирует что все операции в транзакции будут успешно завершены. А если не будут, то транзакция откатив все предыдущие операции и база вернется в исходное состояние. Другими словами, нельзя выполнить транзакцию наполовину.
- Согласованность – предполагается что база до выполнения транзакции находится в одном согласованном состоянии. Согласованность гарантирует что после выполнения транзакции база должна перейти в другое согласованное состояние, или вернуться в прежнее.
- Изолированность – это свойство позволяет транзакциям работать независимо друг от друга. Две параллельные транзакции должны отработать, как будто выполнялись последовательно.
- Долговечность – гарантирует, что результат совершенной транзакции сохранится в случае сбоя системы.
За выполнение атомарности, согласованности и изолированности отвечает много-версионность. За долговечностью следит другой механизм – журнал.
Выполнение запроса
Запрос в процессе своего выполнения проходит 4 стадии:
- Разбор. Система определяет корректность запроса. Он должен быть синтактически правильным и все объекты к которым он обращается должны существовать. Также к этим объектам должны быть права доступа. Для разбора PostgreSQL хранит системные каталоги – это такое место, где СУБД хранит информацию о таблицах и столбцах и служебные сведения. Системные каталоги это обычные таблицы. Поэтому вы можете удалить и пересоздать их, добавить столбцы, изменить и добавить строки, то есть разными способами вмешаться в работу системы.
- Трансформация. В PostgreSQL есть механизм правил, с помощью которых можно немного изменить запрос. Например если вы ссылаетесь на какое-нибудь представление, то имя представления с помощью правил трансформируется в запрос, который стоит за этим представлением. После трансформации получается более низкоуровневый запрос.
- Планирование. Когда мы пишем запрос на SQL, мы говорим что хотим получить, а не как это сделать. За то “как это сделать” отвечает планировщик основываясь на статистике. Статистика включает в себя: сколько у нас таблиц, сколько в них строчек, сколько они занимают страниц, как распределены данные в столбцах и тому подобное. Планировщик решает с каких таблиц начать выполнение запроса, какие условия и в каком порядке применять и так далее. Планировщик подготавливает план выполнения.
- Выполнение. И наконец, когда построен план выполнения, начинается работа с данными.
После выполнения запроса его результат отдаётся клиенту. Обычно результат отдается целиком, но можно использовать так называемые курсоры, чтобы отдавать результат построчно. Курсор вначале нужно открыть, затем с помощью команды FETCH мы построчно получаем результат запроса и в конце закрываем курсор.
Еще в PostgreSQL есть механизм подготовки оператора. Мы заранее можем провести разбор и трансформацию и сохранить такой разобранный запрос. Дальше, для подготовленного оператора вы задаёте фактические параметры и запрос минуя разбор и трансформацию сразу начинает планироваться с этими параметрами. Если у запроса нет параметров, то и план запроса сохраняется и сразу начинается выполнение.
Процессы и память
Процессов на сервере PostgreSQL много, но выделяют три вида:
- Основной процесс, раньше назывался Postmaster, сейчас просто Postgres. Он слушает назначенный порт и по необходимости запускает другие процессы: фоновые или обслуживающие. Когда клиентское приложение хочет подключиться, то основной процесс запускает обслуживающий процесс и подключает приложение к нему.
- Обслуживающие процессы. Работает с клиентом (отвечает за обработку его запросов). У этого процесса есть локальная память для хранения подготовленных операторов (разобранных запросов), курсоров и другого. Сколько клиентов подключаются к серверу, столько и обслуживающих процессов создается.
- Фоновые процессы. Выполняют различные служебные операции, например очищают базу от уже неактуальных данных.
Память выделяемая для работы PostgreSQL тоже бывает разных типов:
- Локальная память процесса. Необходима обслуживающему процессу для хранения подготовленных операторов, курсоров, различных переменных окружения и тому подобное. В эту память входит и так называемая WorkMem память, которая используется для внутренних операций.
- Общая память. В ней хранятся фактические данные, то есть таблицы базы данных. Все процессы взаимодействуют с базой данных и друг с другом через эту память. Так эта память общая для всех процессов, то к ней применяют механизм блокировок. Если 1 процесс работает с какой-то структурой данных он должен её заблокировать от других процессов.
Пулы соединений
Чтобы уменьшить потребление памяти, иногда используют пулы соединений. Между клиентом и сервером работает менеджер пула. Он открывает несколько соединений с базой данных и держит их. А все клиентские соединения работают с базой данных через этот менеджер пула. Так получается уменьшить количество обслуживающих процессов и соединений, а значит экономится оперативная память.
Встроенного пула в PostgreSQL нет, но клиент сам может его реализовать.
Двойная буферизация PostgreSQL
Напрямую к дискам PostgreSQL не обращается, а обращается используя ОС. В Linux все что читается или пишется на диск всегда проходит дисковый кэш. Например прочитали вы файлик, он попал в кэш (в оперативную память), следующий раз при обращении к этому файлу он будет читаться из кэша а не с диска.
Получается, выполнили вы запрос, некоторые таблички были прочитаны с диска и попали в дисковый кэш. Из кэша PostgreSQL забрал из в общую память, чтобы поработать с табличками. Получается данные дублируются в оперативной памяти. Это не очень хорошо, но нужно знать про эту особенность работы PostgreSQL.
Надежность PostgreSQL при сбоях
Чтобы гарантировать восстановление после сбоя PostgreSQL использует журнал предварительной записи – WAL. Этот журнал позволяет после сбоя восстановить согласованность данных. Подробнее разберу его позже, а пока просто запомните, что такой механизм присутствует.
Расширяемость PostgreSQL
Так как PostgreSQL это база с открытым исходным кодом, её можно дописать под себя. Но PostgreSQL позволяет многое в себя добавить не меняя код ядра с помощью расширений. Расширения позволяют создавать новые типы данных, новые типы индексов, новые функции, операторы и другое. Также можно создавать свои фоновые процессы.
Дополнительно к вышесказанному, к базе данных можно подключать внешние источники данных. Например, подключить к базе данных файл и работать с ним как с таблицей.
Источник: sysadminium.ru
Что такое PostgreSQL и как ее установить
В статье мы расскажем, что такое PostgreSQL и как происходит его установка и настройка на сервере.
PostgreSQL — это реляционная СУБД. Она имеет открытый код и распространяется свободно. Postgre создана на основе процедурного языка PL/pgSQL. Система управления базами данных поддерживается в системах Unix. Postgre можно установить в ОС семейства Linux: например, на Ubuntu, Debian и CentOS.
Как установить и настроить PostgreSQL на Ubuntu
1. Обновите дистрибутивы:
sudo apt update
2. Установите Postgre и contrib:
sudo apt install postgresql postgresql-contrib
3. Чтобы узнать версию PostgreSQL, введите команду:
postgres -V

PostgreSQL install Ubuntu
PostgreSQL на Linux: основные команды
Как работать в консоли PostgreSQL:
- Как запустить сервер:
sudo -u postgres psql
- Как создать базу данных:
CREATE DATABASE dbname;
- Как создать пользователя:
CREATE USER username WITH LOGIN PASSWORD ‘password’;
- username — имя пользователя БД,
- password — пароль.
- Как создать таблицу:
CREATE TABLE table_name ( address varchar(80), user_id int, order real, date date );
Как подключить PostgreSQL к Django
Django — это фреймворк для создания приложений на Python. По умолчанию в нём используется SQLite, однако Django позволяет установить PostgreSQL.
1. Подключитесь к серверу по SSH.
2. Обновите дистрибутивы. Для этого поочерёдно выполните команды:
sudo apt update sudo apt upgrade
3. Установите PostgreSQL и модули, необходимые для работы:
sudo apt install postgresql postgresql-contrib python3-pip python3-dev libpq-dev nginx
4. Запустите консоль Postgre:
sudo -u postgres psql
5. Создайте базу данных для проекта:
CREATE DATABASE projectname;
Вместо projectname укажите название проекта.
6. Создайте пользователя базы данных и присвойте ему пароль:
CREATE USER username WITH PASSWORD ‘password’;
- username — имя пользователя БД,
- password — пароль пользователя.
7. Назначьте кодировку UTF-8:
ALTER ROLE username SET client_encoding TO ‘utf8’;
Вместо username укажите имя пользователя базы данных.
8. Задайте схему изоляцию транзакции:
ALTER ROLE username SET default_transaction_isolation TO ‘read committed’;
Вместо username укажите имя пользователя базы данных.
9. Укажите стандарт времени:
ALTER ROLE username SET timezone TO ‘UTC’;
Вместо username укажите имя пользователя базы данных.
10. Выдайте пользователю права на управление БД:
GRANT ALL PRIVILEGES ON DATABASE projectname TO username;
- projectname — название проекта,
- username — имя пользователя БД.
11. Закройте консоль Postgre:
12. Обновите pip:
sudo -H pip install —upgrade pip
13. Установите virtualenv:
sudo -H pip install virtualenv
14. Создайте папку для хранения файлов проекта:
mkdir ~/projectnamedirectory
Вместо projectnamedirectory укажите название папки.
15. Перейдите в новую директорию:
cd ~/projectnamedirectory
Вместо projectnamedirectory укажите название папки.
16. Внутри директории создайте виртуальное окружение:
virtualenv projectnameenv
Вместо projectnameenv укажите название виртуального окружения.
17. Активируйте виртуальное окружение с помощью команды:
source projectnameenv/bin/activate
Вместо projectnameenv укажите название виртуального окружения.
18. Установите Django, gunicorn и psycopg:
pip install django gunicorn psycopg2-binary
19. Создайте проект:
django-admin startproject projectname ~/projectnamedirectory
- projectname — название проекта,
- projectnamedirectory — название папки, в которой хранятся файлы проекта.
20. Откройте файл настроек:
sudo nano ~/projectnamedirectory/projectname/settings.py
- projectname — название проекта,
- projectnamedirectory — название папки, в которой хранятся файлы проекта.
21. В начале файла добавьте строки:
from pathlib import Path import os
Найдите строку ALLOWED_HOSTS и добавьте в ней параметры:
ALLOWED_HOSTS = [‘123.123.123.123’, ‘localhost’]
Вместо 123.123.123.123 укажите IP-адрес вашего сервера.
В этом же файле в блоке DATABASES добавьте данные для подключения к БД:
DATABASES = < ‘default’: < ‘ENGINE’: ‘django.db.backends.postgresql_psycopg2’, ‘NAME’: ‘projectname’, ‘USER’: ‘username’, ‘PASSWORD’: ‘password’, ‘HOST’: ‘localhost’, ‘PORT’: », >>
- projectname — имя базы данных,
- username — имя пользователя БД,
- password — пароль пользователя БД.
В строках STATIC_URL и STATIC_ROOT укажите параметры:
STATIC_URL = ‘/static/’ STATIC_ROOT = os.path.join(BASE_DIR, ‘static/’)
Затем сохраните изменения и закройте файл.
22. Перейдите в директорию проекта:
cd ~/projectnamedirectory
Вместо projectnamedirectory укажите имя директории проекта.
23. Перенесите исходную схему БД в PostgreSQL. Для этого поочерёдно выполните команды:
python manage.py makemigrations python manage.py migrate
24. Создайте суперпользователя проекта:
python manage.py createsuperuser
- Username — укажите имя пользователя,
- Email address — введите адрес электронной почты,
- Password — укажите пароль,
- Password (again) — повторите пароль.
Затем нажмите Enter:

Запуск PostgreSQL из командной строки Linux
25. Разблокируйте порт 8000:
sudo ufw allow 8000
26. Протестируйте проект. Для этого запустите сервер Django:
python manage.py runserver 0.0.0.0:8000
27. Откройте браузер и введите в адресной строке 123.123.123.123:8000. Вместо 123.123.123.123 укажите IP-адрес сервера. Если настройка сервера прошла корректно, на экране отобразится стартовая страница Django:
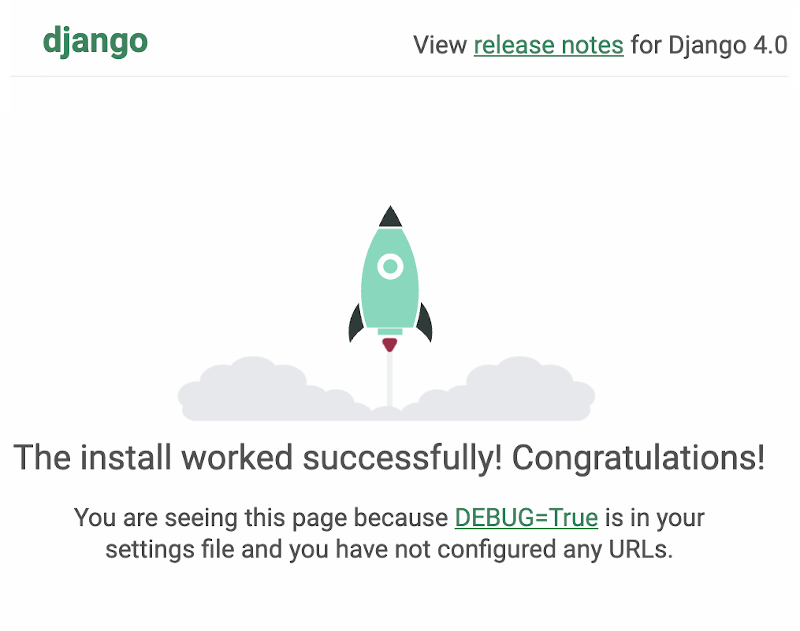
PostgreSQL Python установка
Готово. Теперь вы знаете, как запустить PostgreSQL на Django.
Как настроить PostgreSQL на Docker
Чтобы настроить Postgre:
1. Установите Docker с помощью официального руководства.
4. Создайте директорию проекта:
mkdir ~/projectname
Вместо projectname укажите название проекта.
5. Перейдите в директорию проекта:
cd ~/projectname
Вместо projectname укажите название проекта.
6. Откройте настройки проекта с помощью команды:
nano ~/projectname/docker-compose.yaml
Вместо projectname укажите название проекта.
7. В файл docker-compose.yaml добавьте следующие параметры:
version: ‘3.1’ volumes: pg_project: ‘projectname’ services: pg_db: image: postgres restart: always environment: — POSTGRES_PASSWORD=password — POSTGRES_USER=username — POSTGRES_DB=dbname volumes: — pg_project:/var/lib/postgresql/data ports: — $:5432
- version: ‘3.1’ — версия Docker,
- pg_project: ‘projectname’ — название проекта,
- POSTGRES_PASSWORD=password — пароль БД,
- POSTGRES_USER=username — логин пользователя БД,
- POSTGRES_DB=dbname — имя базы данных.
Затем сохраните изменения и закройте файл.
Популярные статьи
- Как указать (изменить) DNS-серверы для домена
- Я зарегистрировал домен, что дальше
- Как добавить запись типа A, AAAA, CNAME, MX, TXT, SRV для своего домена
- Что такое редирект: виды и возможности настройки
- Как создать почту со своим доменом
Источник: 2domains.ru