
Аннотация: Дается общее понятие структуры данных как исполнителя, который организует работу с данными: хранение, добавление и удаление, поиск и т.п. Рассматриваются реализации одних структур на базе других, в частности, реализации на базе массива. Приводятся наиболее важные из простейших структур данных: очередь и стек, а также их непрерывные реализации на базе массива.
Даются многочисленные примеры использования стека в программировании. Рассматривается обратная польская запись формулы (знак операции после аргументов) и способ ее вычисления на стековой машине. В качестве примера использования обратной польской записи рассматривается графический язык PostScript. Материал иллюстрируется проектом «Cтековый калькулятор», реализованным на языке Си.
Структуры данных
«Алгоритмы + структуры данных = программы». Это — название книги Никлауса Вирта, знаменитого швейцарского специалиста по программированию, автора языков Паскаль , Модула-2, Оберон. С именем Вирта связано развитие структурного подхода к программированию. Н.Вирт известен также как блестящий педагог и автор классических учебников.
6 важных структур данных
Обе составляющие программы, выделенные Н.Виртом, в равной степени важны. Не только несовершенный алгоритм , но и неудачная организация работы с данными может привести к замедлению работы программы в десятки, а иногда и в миллионы раз. С другой стороны, владение теорией программирования и умение систематически применять ее на практике позволяет быстро разрабатывать эффективные и в то же время эстетически красивые программы.
Общее понятие структуры данных
Структура данных — это исполнитель , который организует работу с данными, включая их хранение, добавление и удаление, модификацию, поиск и т.д. Структура данных поддерживает определенный порядок доступа к ним. Структуру данных можно рассматривать как своего рода склад или библиотеку.
При описании структуры данных нужно перечислить набор действий, которые возможны для нее, и четко описать результат каждого действия. Будем называть такие действия предписаниями. С программной точки зрения, системе предписаний структуры данных соответствует набор функций, которые работают над общими переменными.
Структуры данных удобнее всего реализовывать в объектно-ориентированных языках. В них структуре данных соответствует класс , сами данные хранятся в переменных-членах класса (или доступ к данным осуществляется через переменные-члены), системе предписаний соответствует набор методов класса. Как правило, в объектно-ориентированных языках структуры данных реализуются в виде библиотеки стандартных классов: это так называемые контейнерные классы языка C++, входящие в стандартную библиотеку классов STL, или классы, реализующие различные структуры данных из библиотеки Java Developer Kit языка Java .
Тем не менее, структуры данных столь же успешно можно реализовывать и в традиционных языках программирования, таких как Фортран или Си . При этом следует придерживаться объектно-ориентированного стиля программирования: четко выделить набор функций, которые осуществляют работу со структурой данных, и ограничить доступ к данным только этим набором функций. Сами данные реализуются как статические (не глобальные) переменные. При программировании на языке Си структуре данных соответствуют два файла с исходными текстами:
Понятие типа данных. Алгоритмы и структуры данных.
- заголовочный, или h-файл, который описывает интерфейс структуры данных, т.е. набор прототипов функций, соответствующий системе предписаний структуры данных;
- файл реализации, или Си-файл, в котором определяются статические переменные, осуществляющие хранение и доступ к данным, а также реализуются функции, соответствующие системе предписаний структуры данных
Структура данных обычно реализуется на основе более простой базовой структуры, ранее уже реализованной, или на основе массива и набора простых переменных. Следует четко различать описание структуры данных с логической точки зрения и описание ее реализации. Различных реализаций может быть много, с логической же точки зрения (т.е. с точки зрения внешнего пользователя) все они эквивалентны и различаются, возможно, лишь скоростью выполнения предписаний.
Источник: intuit.ru
Структуры данных и способы их реализации
Одним из фундаментальных понятий программирования на протяжении нескольких десятилетий является понятие типизации данных. Отнесение переменной к тому или иному типу позволяет установить внутренний формат хранения значений этой переменной и набор допустимых операций. Все универсальные языки программирования имеют набор базовых простейших типов данных (целочисленные, вещественные, символьные, логические) и возможность объединения их в составные наборы – массивы и записи/структуры.
Абстрактное понятие «Структура данных» определяет способ объединения некоторого набора отдельных элементов данных в единое целое и методы обработки этих наборов.
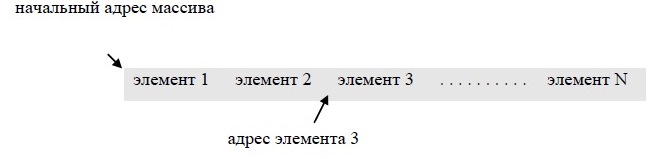
Например, классическая структура МАССИВ есть объединение элементов данных, обладающее следующими свойствами:
- все элементы относятся к одному типу (не обязательно простейшему);
- для хранения элементов массива выделяется непрерывная область памяти;
- каждый элемент имеет порядковый номер-индекс, по которому можно выполнить очень быстрое обращение к данному элементу, независимо от его расположения в массиве.
var MyArr : array [ 1 .. 100 ] of integer;
int MyArr[100] ;
С другой стороны, конструкция типа запись/структура характеризуется следующими особенностями: объединять можно элементы данных разных типов; вся структура занимает непрерывную область памяти; каждый элемент объявляется как поле со своим уникальным именем; доступ к элементам выполняется по именам полей.
Пример объявления записи/структуры с тремя полями и переменной соответствующего типа. Паскаль
type TMyRec = record field1 : integer; field2 : string; field3 : real; end; var MyRec : TMyRec;
struct MyStruct < int field1; char field2[80]; float field3; >; struct MyStruct MyStr;
Возможное размещение полей такой записи/структуры в памяти:

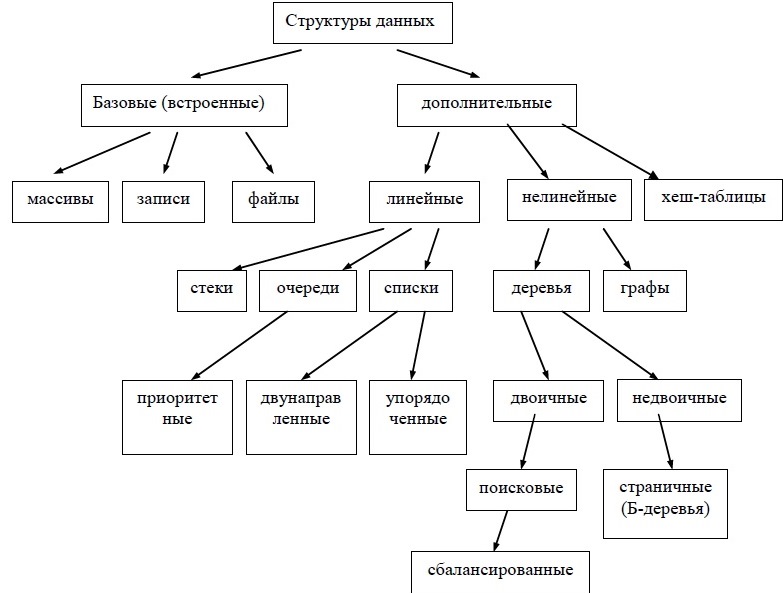
Обе эти стандартные структуры служат основой построения других важных структур, широко используемых в различных приложениях: стеки, очереди, списки, деревья, графы, хеш-таблицы. Каждая из них имеет свои особенности объединения компонент и их обработки и как следствие — свою область применения.
Основные структуры данных представлены на следующей схеме:
Большинство дополнительных структур данных можно реализовать двумя способами:
- на основе массива (статическая или непрерывная реализация);
- на основе использования специальных адресных переменных и механизма динамического распределения памяти (динамическая или связная реализация).
- статическая реализация применима в случае заранее известного и не меняющегося числа элементов в структуре данных (массив, однако!) и часто обеспечивает более высокую скорость выполнения операций;
- динамическая реализация рассчитана на случай, когда число компонентов в структуре данных может изменяться при выполнении программы в очень широких пределах, и такая реализация позволяет более экономно использовать оперативную память.
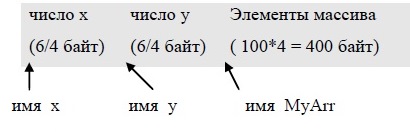
Статическая (непрерывная) реализация связана с процессом распределения памяти при компиляции программы. Каждой объявленной переменной компилятор выделяет необходимую по размеру область памяти и связывает адрес этой области с именем переменной.
Например, пусть объявлены следующие три переменные. Паскаль
var x, y : real; MyArr : array [ 1 .. 100 ] of integer;
float x, y; int MyArr[100];
Тогда компилятор при обработке этих объявлений распределит память примерно следующим образом (с учетом возможных различий в представлении базовых типов на разных платформах):
Особенность статического распределения памяти – жесткая фиксация выделенных областей, невозможность изменения этого распределения при выполнении программы.
Во многих задачах подобная статичность является слишком неудобной, поэтому многие языки программирования, в частности С/С++ и Паскаль, реализуют и другой способ распределения памяти – динамический. Он позволяет выделять память под значения переменных непосредственно в процессе выполнения программы в ответ на вызов специальных стандартных функций. Когда необходимость в использовании этих значений исчезает,
соответствующие области памяти можно освободить для других целей. Это позволяет весьма экономно расходовать такой важнейший ресурс, как оперативная память, хотя и приводит к небольшому замедлению выполнения программы в случае многократного выделения памяти за счет необходимости взаимодействия с операционной системой. Это является еще одним проявлением классического противоречия между скоростью работы программы и требуемыми объемами памяти.
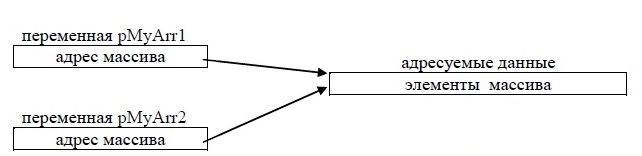
Механизм динамического распределения памяти основан на использовании специальных переменных, которые называют указателями. Переменные-указатели, или переменные ссылочного типа — это специальные переменные, значениями которых являются адреса областей памяти. Каждый указатель может адресовать некоторую область памяти, в которой могут находиться обрабатываемые данные. Чаще всего под адрес отводится 4 байта.
Необходимо четко различать переменную-указатель и адресуемую ею область памяти. Схематично взаимодействие указателей и адресуемых данных можно показать следующим образом:

Тем самым доступ к обрабатываемым данным выполняется не напрямую через имя соответствующей переменной, а косвенно – через использование промежуточной переменной указательного типа.
Отличия в использовании обычных переменных и переменных-указателей:
- Объявление переменной с выделением компилятором для хранения ее значений в необходимой области памяти
- Занесение в выделенную область самих данных с использованием имени переменной
- Использование данных через имя переменной
- Объявление указателя специальным образом БЕЗ выделения компилятором памяти под данные
- Запрос памяти для адресуемых данных во время выполнения программы
- Занесение в динамически выделенную область некоторых данных ТОЛЬКО через переменную-указатель
- Использование данных тоже ТОЛЬКО через переменную-указатель
- Освобождение памяти, если данные больше не нужны
- ввести имя переменной; хорошая рекомендация – начать имя с латинского символа р (от слова pointer);
- связать эту переменную с адресуемыми данными, указав их тип или имя с помощью специального символа ^ (Паскаль) или * (Си)

Еще раз подчеркнем, что объявление переменной-указателя НЕ приводит к выделению памяти для самих адресуемых данных: память выделяется ТОЛЬКО для указателя (например – 4 байта). Поэтому для правильного использования механизма динамического распределения памяти НЕ следует объявлять переменные базового типа (точнее, их объявлять можно, но к динамическому распределению памяти это никакого отношения не имеет).
var MyRec : TMyRec; // обычная переменная-запись со статическим // выделением памяти для полей записи pMyRec : ^TMyRec; // переменная-указатель на структуру-запись с // выделением памяти только для указателя, но не для полей записи!
Важное замечание: объявление переменной-указателя – это всего лишь объявление, т.е. никакого адресного значения эта переменная не получает и использовать ее для доступа к данным категорически нельзя!
Для использования указателя ему надо присвоить некоторое значение – адрес области памяти, где должны храниться обрабатываемые данные. Запрос такой области памяти во время работы программы выполняется за счет обращения к специальным стандартным функциям – New (Паскаль) или malloc (Си, сокращение от Memory Allocation). Эти вызовы обеспечивают динамическое выделение памяти для новых данных программы и вместе с переменными-указателями являются основой реализации динамических структур.
К сожалению, синтаксически использование данных вызовов различно.
Вызов New имеет обязательный параметр – имя переменной-указателя, связанной на этапе объявления с адресуемыми данными, а вызов malloc – параметр-размер запрашиваемой области памяти (удобно использовать стандартную функцию sizeof (тип) для автоматического получения размера).
Эти стандартные вызовы выполняют два основных действия: обращаются к операционной системе для выделения области памяти, необходимой для размещения адресуемых данных; устанавливают начальный адрес данной области памяти в качестве значения заданной переменной-указателя, после чего этот указатель можно использовать для косвенного доступа к данным.
Примеры вызовов для ранее объявленных указателей:

Вызовы New и malloc можно выполнять в любом месте программы любое разумное число раз, в том числе – внутри циклов. Это позволяет при выполнении программы динамически создавать достаточно много данных. Ограничением по количеству создаваемых данных является размер так называемой кучи (heap), т.е. области памяти, которая выделяется программе операционной системой для динамически создаваемых данных.
После успешного выделения области памяти в нее можно заносить необходимые данные, используя для этого соответствующую указательную переменную и специальные синтаксические конструкции вида:
указатель^ // Паскаль
*указатель // Си
Такие конструкции фактически означают сами адресуемые данные, и поэтому с их помощью можно записывать правильные операторы, соответствующие типу самих данных.
Примеры правильных операторов обработки косвенно адресуемых данных для ранее введенных указателей:

Из всего вышесказанного ясно, что переменные адресного типа – это особые переменные со своим набором операций. Основными являются следующие две операции:
1. Присваивание значения одной указательной переменной другой указательной переменной того же базового типа:
pMyArr2 : = pMyArr1; // Паскаль
pMyNewStruct = pMyStruct; // Си
- присваивать можно значения только однотипных указателей, т.е. объявленных с одним и тем же базовым типом (в языке Си при определенных условиях можно
- присваивать указатели разных типов, но пользоваться этой возможностью надо крайне осторожно!);
- указатель в правой части должен иметь некоторое значение;
- после выполнения операции оба указателя будут адресовать одну и ту же область памяти
В частном случае указателю можно присвоить «пустое» (нулевое) значение. Такая переменная считается определенной, но никуда не указывающей. Для этого используются специальные служебные слова nil (Паскаль) или NULL (Си):
pMyNewStruct = NULL;
pMyArr := nil ;
2. Сравнение двух однотипных указательных переменных на равенство или неравенство:
if ( pInt2 = pInt1 ) then begin . . . end; if ( pMyNewArr != pMyOldArr ) < . . . >;
Особенности операции сравнения: сравнивать можно только однотипные указатели; оба указателя должны быть инициализированы. сравниваются не адресуемые данные, а адресные значения!
С помощью служебных слов nil и NULL можно проверять указатели на пустое значение, что часто приходится делать в операциях обработки динамических структур.
Для освобождения динамически распределенной памяти используются противоположные стандартные вызовы — Dispose (Паскаль) и free (Си). Параметром этих вызовов является указательная переменная, используемая для доступа к данным, которые больше программе не нужны:
Dispose ( pMyArr );
free ( pArrInt );
Важное замечание! После отработки этих вызовов соответствующая переменная-указатель становится неопределенной (НЕ путать с ПУСТЫМ указателем!) и ее НЕЛЬЗЯ использовать до тех пор, пока она снова не будет инициализирована с помощью вызова New/malloc или инструкции присваивания. Это может приводить к весьма неприятной ситуации, связанной с появлением так называемых «висячих» указателей: если два указателя адресовали одну и ту же область памяти (а это встречается весьма часто), то вызов Dispose/free с одной из них в качестве параметра оставляет в другой переменной адрес уже освобожденной области памяти и повторное использование этой переменной для доступа к отсутствующим данным приведет к возникновению ошибки.
Еще один тип ошибок, возникающих при использовании указателей, связан с ситуацией, когда некоторый указатель, адресующий некоторые данные, меняет свое адресное значение и в результате программа теряет доступ к этим данным (если, конечно, они не адресуются другим указателем). Эта ситуация носит название «утечка памяти».
Замечание. В языке С++ вместо пары malloc/free для динамического выделения и освобождения памяти используются вызовы new( ) и delete( ).
В заключение необходимо отметить, что использование динамической памяти требует большой осторожности и может быть причиной трудноуловимых ошибок времени выполнения.

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
статьи IT, теория программирования
Бесплатный https и
домен RU в подарок
Источник: upread.ru
Структуры данных
Это определение имеет столь общий характер, что может использоваться в различных случаях, имея несколько разный смысл. Рассмотренные выше конструируемые типы данных обычно относят к элементарным структурам данных. Возможно, по этой причине конструируемые типы данных часто называют структурированными, а запись в языке С называется структурой. В дальнейшем не будем путать структуры в смысле языка С со структурами данных в широком понимании.
Кроме структурированных типов данных имеется еще ряд структур данных, которые относят к элементарным или базовым, хотя в большинство языков программирования не встроена их явная поддержка. Эти структуры будут подробно рассмотрены в следующих разделах, а затем будут использоваться как элементарные кирпичики при конструировании более сложных структур данных или описании алгоритмов.
Структуры данных принято рассматривать на двух уровнях — логическом и физическом. На логическом (абстрактном или внешнем) уровне рассматриваются наиболее существнные признаки структуры, которые не зависят от способа внутреннего представления данных в памяти. Возможность анализа структуры данных на логическом уровне обеспечивает концепция АТД, рассмотренная выше.
На физическом (внутреннем) уровне рассматривается конкретный способ представления структуры в оперативной памяти. При этом принимается во внимание как способ хранения самих элементов данных, так и способ представления отношений между данными. В этом случае иногда используются такие термины как структура хранения или внутренняя структура.
Внутреннее представление структур данных оказывает очень сильное влияние на реализацию алгоритмов, поэтому рассмотрим этот вопрос подробнее.
1.3.2. Структуры хранения — непрерывная и ссылочная
Несмотря на широкое разнообразие структур данных, имеется всего два альтернативных принципа их внутренней организации:
- непрерывная организация — размещение всех элементов структуры по порядку в одной непрерывной области памяти, в результате чего соседние элементы занимают соседние ячейки памяти (такой способ иногда называют векторной организацией, чтобы как-то отделить это понятие от понятия массива, хотя по сути это одно и то же);
- ссылочная организация — отдельные элементы могут располагаться в памяти как угодно (теоретически), но каждый элемент хранит, кроме своего значения, ссылки на связанные с ним элементы (такие структуры часто называют связными или цепными).
Массивы (векторы) предоставляют очень простой и эффективный способ агрегации ячеек памяти, который не требует явного хранения связей между элементами данных. Тем не менее, отношения соседства подразумеваются исходя из способа размещения элементов.
В связных структурах связи хранятся явно в виде ссылок. Например, каждый элемент связной структуры может содержать ссылку на следующий (предыдущий) элемент или две ссылки на два соседних с ним элемента. Из этого следует, что каждый элемент такой структуры состоит из двух различных по значению частей: содержательной (информационной) и указующей (рис. 1.2).
В содержательной части хранятся данные, для обработки которых и существует данная структура. В указующую часть помещаются ссылки на связанные элементы.
Рис. 1.2. Элемент связной структуры
Связные структуры могут быть реализованы двумя различными способами, в зависимости от способа реализации ссылок:
- память под каждый элемент захватывается динамически, при этом ссылки на связанные элементы реализуются с помощью указателей;
- память под всю структуру выделяется статически и организована в виде вектора (массива достаточных размеров), но элементы структуры расположены в массиве не по порядку, а как получится. При этом каждый элемент, кроме своего значения, хранит один или несколько индексов связанных с ним элементов.
Таким образом, ссылками могут быть либо указатели, либо индексы. Второй способ является единственным в языках программирования, где нет указателей, но может применяться и как альтернатива указателям там, где доступны оба варианта. В следующих разделах при рассмотрении вопросов реализации будут анализироваться все возможные варианты.
Сравним различные структуры хранения.
- Организация данных в виде связных структур на основе указателей обеспечивает более эффективное использование памяти по сравнению с массивами в случае, когда даже ориентировочно заранее не известно количество данных. При использовании массива в такой ситуации приходится резервировать память с большим избытком. С другой стороны, связная структура требует дополнительной памяти для хранения указателей, которая иногда может превышать размер полезной информации;
- Для вставки и удаления элементов в заданной позиции связной структуры не требуется передвигать элементы, как при использовании массивов, достаточно только поменять значения указующих полей соседних элементов. Это преимущество любой связной структуры, независимо от того, как она реализована.
- Основным недостатком связных структур является отсутствие прямого доступа к элементам по индексу. Сам принцип организации связных структур порождает последовательный способ доступа к их элементам (продвижение по цепочке, начиная с самого крайнего элемента, до тех пор, пока не будет достигнут нужный элемент данных).
Сравнение показывает, что ни одна из структур хранения не является идеальной, поэтому довольно часто используются структуры данных, в которых комбинируются различные структуры хранения. Например, в известной библиотеке шаблонов STL (Standard Template Library) для языка С++ некоторые типы реализованы как связные списки, элементами которых являются массивы (допустим, тип vector). Не менее часто используются массивы, элементами которых являются списки. Например, такой способ используется в одном из вариантов реализации хеш-таблиц, которые будут рассмотрены в главе 5, посвященной поиску данных.
Источник: studfile.net