
Atom Search — поисковые систем
Наслаждайтесь лучшими поисковыми системами в одном приложении с одним щелчком мыши, чтобы получить доступ к лучшим поисковым системам, которые существуют? Экономия времени и мегабайтов, которые они потребляли бы, выполняя поиск во всех этих приложениях каждой поисковой системы.
Atom Search получает доступ к лучшим и самым быстрым поисковым системам прямо в одном и том же месте и у вас под рукой, и вы сможете получить доступ к лучшим поисковым системам, которые вы можете себе представить.
Будьте более продуктивными, используя лучшие поисковые системы, такие как: Google, Yahoo, Bing, Ask, Duk Duk и многие другие.
-Веб-поиск в одном месте
-Энциклопедия, Википедия и др.
-Поиск изображений и видео
-Поиск сайтов для покупок, аукционов и т. Д.
-Все поиски в социальных сетях
-Поиск любимых видео в Интернете
Примечание. Все связанные веб-сайты имеют зарегистрированные товарные знаки соответствующих компаний. Atom Search не связан с какими-либо связанными поисковыми системами или веб-сайтами, и мы не собираем данные о веб-поисках в приложении.
Поисковая система: что это такое и для чего она нужна | SEMANTICA
Последнее обновление
29 авг. 2022 г.
Безопасность данных
arrow_forward
Чтобы контролировать безопасность, нужно знать, как разработчики собирают ваши данные и передают их третьим лицам. Методы обеспечения безопасности и конфиденциальности могут зависеть от того, как вы используете приложение, а также от вашего региона и возраста. Информация ниже предоставлена разработчиком и в будущем может измениться.
Источник: play.google.com
Поисковая система
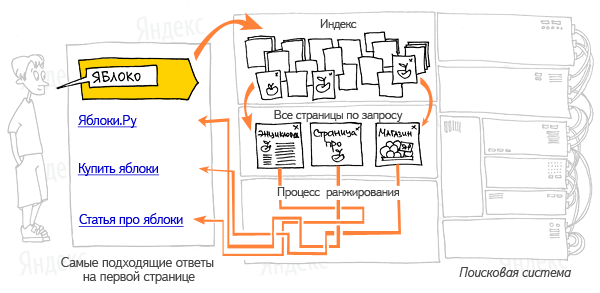
Поисковая система (поисковик) — это специальная программа, которая автоматизирует поиск информации в интернете. Благодаря индексации этот процесс происходит очень быстро, а в результате ранжирования пользователь получает упорядоченный список ресурсов, на которых содержится необходимая информация.
Искать информацию в интернете без поисковых систем было бы крайне сложно. Просмотреть триллионы страниц, расположенных хаотично, без всякой закономерности и структуры невозможно без использования специальных алгоритмов. Для этого и нужны поисковики. Они выстраивают четкую иерархию в этой системе и делают интернет доступным и удобным.
Самыми популярными поисковыми системами в России, по данным Яндекс.радар , являются «Яндекс» (61,7%) и Google (37,0%), доля Mail.ru и Rambler вместе взятых не превышает 1%.
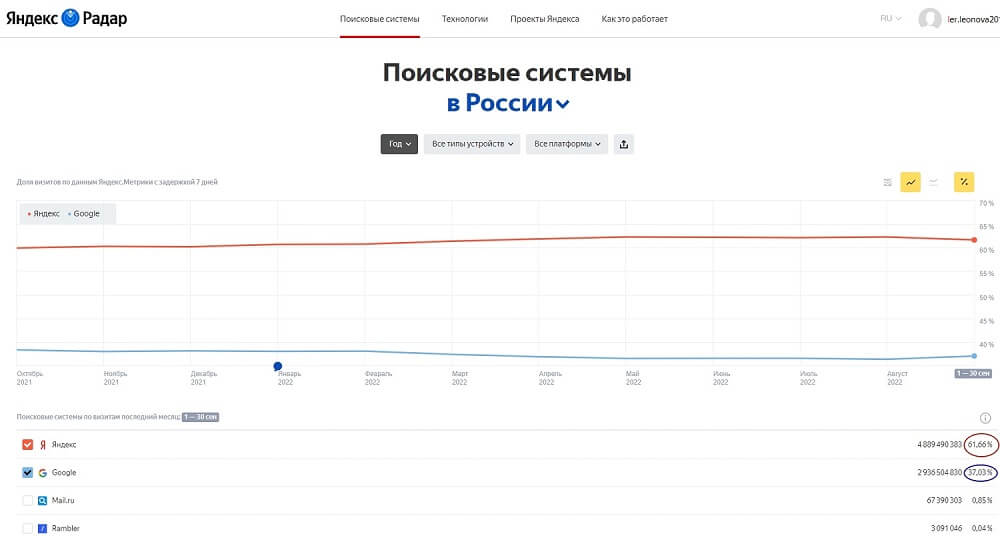
Если обратиться к мировой статистике, то здесь лидирует Google (84,8%), а «Яндекс» (1,06%) уходит на 6-е место.
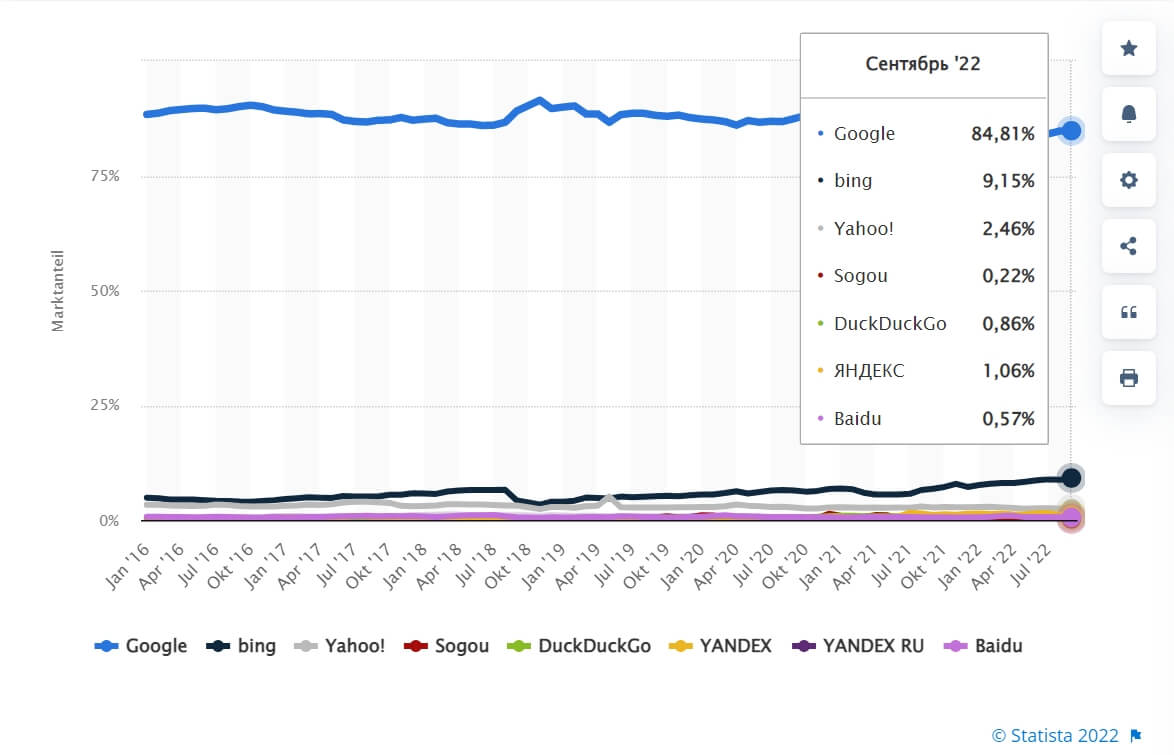
Как работает поисковая система
Доля рынка наиболее часто используемых поисковых систем по всему миру по состоянию на сентябрь 2022 г. Источник
Принципы работы поисковых систем
Принципы работы любой поисковой системы примерно одинаковы и их условно можно разделить на несколько этапов.
Составление списка страниц
Для того чтобы поисковая система смогла найти нужную фразу в большом количестве сайтов, эти сайты должны быть ей известны, то есть прочитаны и сохранены в памяти.
Можно сравнить с библиотекой: если вы не знаете, какие книги стоят на полках и никогда не заглядывали в них, то вероятность того, что вы быстро сориентируетесь и найдете нужную цитату, равна нулю.
Поисковая система узнает о содержимом сайтов с помощью специального робота — краулера, или паука . Название происходит от английского crawler (ползающее насекомое, ползунок). Робот обходит все страницы, переходит по ссылкам и постепенно охватывает миллиарды веб-страниц в сети, сохраняет их и отправляет на индексацию.
Индексация
Следующий этап — добавление данных о странице в базу поисковой системы. Обычно поисковик собирает и хранит информацию о содержимом страниц: ключевых словах, которые там используются, а также размещенном контенте (статьях, документах, изображениях, аудиофайлах). Пока страница не проиндексирована, для поисковика она не существует.
По аналогии с библиотекой это работает так: недостаточно знать, в каких примерно книгах содержится похожая фраза. Важно найти релевантную страницу с текстом. Тогда вы сможете воспользоваться этой информацией.
Искать фразу или слова, перелистывая страницы книги или просматривая весь сайт, неудобно. Но если у вас есть предметный указатель, например такой, который используется в технической литературе, учебниках или инструкциях к приборам, вы сможете без труда найти любой термин.

В предметном указателе к инструкции все термины расставлены по алфавиту и обозначены страницы, на которых они встречаются
Тот же принцип лежит в основе поисковой индексации.
Индексный робот получает информацию о странице от краулера и упорядочивает ее. Удаляет ненужные элементы, выбирает слова и запоминает, где эти слова были обнаружены. Получается подробный список адресов страниц и размещенных на них слов.
Ранжирование и поисковая выдача
Поиск и ранжирование — наиболее приближенная к пользователям и значимая для них часть процесса. Если предыдущие этапы проходят в автоматическом режиме и фактически являются подготовительными, то на этом этапе появляется видимый результат — поисковая выдача, ради которой и создаются поисковые машины.
Когда человек вводит текст в поисковую строку, машина с помощью алгоритмов выбирает все страницы, имеющие отношение к запросу. Их очень много и в таком количестве они не нужны, поэтому необходимо их отсортировать, упорядочить и выбрать релевантные страницы. То есть самые правильные и имеющие отношение к делу.
Этот процесс называется ранжированием. Он проходит в несколько этапов, на каждом из которых фильтрация становится сложнее, а список ресурсов сужается. Невозможно точно определить, какие алгоритмы влияют на ранжирование, потому что все поисковики используют свои формулы, которые постоянно обновляются и развиваются.
Результаты поисковой выдачи различаются:
- в разных поисковиках, так как используются различные критерии фильтрации;
- в разных регионах, так как в запросах учитывается местонахождение пользователя;
- на разных устройствах — в десктопной и мобильной версии;
- по одинаковым запросам у разных пользователей, так как учитывается индивидуальная история поиска.
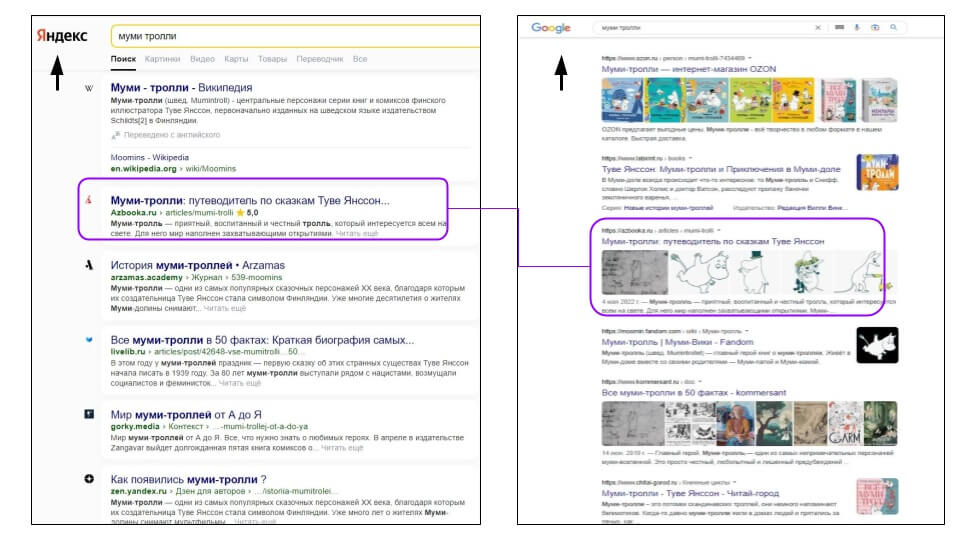
По запросу «Муми тролли» «Яндекс» и Google выдают разные результаты, на первой странице совпадает только один сайт из шести
На выходе получается привычный для нас список ресурсов. Чем выше место веб-ресурса в этом списке, тем более актуальную информацию он содержит. Такая структура удобна пользователям и полезна владельцам страниц. Первые получают самую необходимую информацию в порядке значимости, вторые используют поисковую выдачу для продвижения своего сайта.
Апдейт и границы индексирования
Поисковая система использует данные только тех ресурсов, которые были проиндексированы. Это значит, что существуют страницы, которые не попадают в поисковую выдачу.
Формальных ограничений нет, но на практике они возможны:
- Языковые границы. Например, разные приоритеты индексации «Яндекс» и Google. «Яндекс» больше нацелен на русскоязычную аудиторию и ее интересы, хотя и не ограничивается только ими, Google индексирует сайты со всего мира.
- Технические ошибки разработчиков.
- Не все форматы данных одинаково хорошо индексируются, так как изначально поисковые машины были рассчитаны на обработку веб-страниц, то есть формат HTML.
- Плохая работа сервера или сайт загружается с перебоями.
- Дубли страниц и копипаст с других ресурсов.
- Низкий трафик.
- Слишком большая глубина сайта, размер документа — файлы более 10Мб не индексируются .
- Другие причины, иногда такие экзотические, как «Adult-фильтр» — блокировка сайтов за взрослый контент.
Но главная причина того, что страница не появляется в выдаче — она новая, и поисковый робот просто не успел ее проиндексировать. В зависимости от характеристик сайта обновление или апдейт страниц может занять от нескольких минут до недель. Проверить индексирование страницы можно в Яндекс.Вебмастере раздел «Индексирование», а в Google Search Console «Проверка URL».
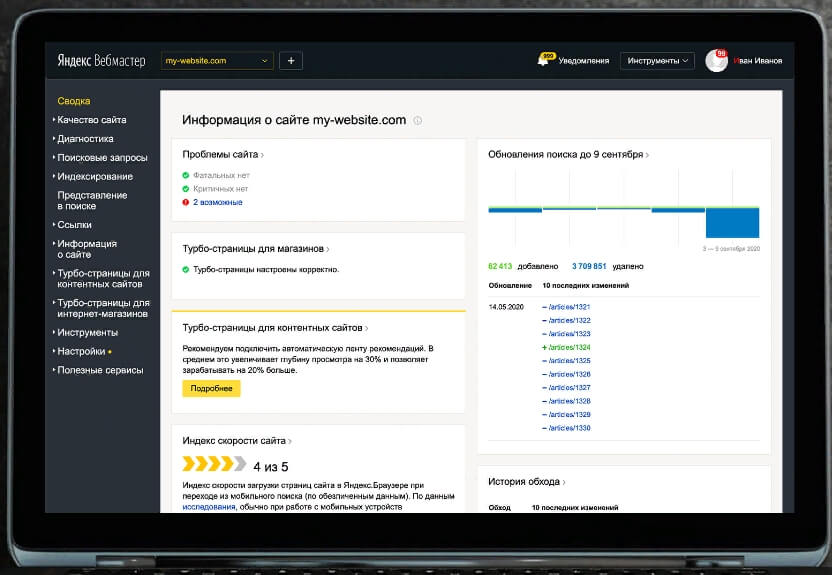
Яндекс.Вебмастер помогает понять, виден ли сайт в поисковой выдаче
Апдейт не только обновляет базы данных поисковиков, но и приводит к пересортировке поисковой выдачи. Поэтому сайт, который находился на вершине ранжирования, может в один момент исчезнуть из зоны видимости. А так как критерии ранжирования засекречены, то снова вернуться в верхние строчки может быть довольно сложно.
Виды поисковых систем
Поисковые системы делятся на четыре категории в зависимости от типа обработки данных:
- Системы на основе поисковых роботов — краулеров. Принципы работы такой системы описаны выше и большинство популярных поисковых систем работает по этой технологии. Задача поисковика — обойти и просканировать сеть, чтобы создать структурированный архив веб-документов и список слов. А целью является создание ранжированного списка ресурсов.
Примеры: Google, «Яндекс», Baidu (крупнейшая китайская поисковая система). - Системы, управляемые человеком. Каталог сайтов полностью формируется вручную. Владелец сайта отправляет описание веб-мастеру и указывает категорию каталога, в которую его нужно включить. Сайт проверяет человек и включает в список, если он проходит модерацию. Это гарантирует более качественный контент, чем в первом варианте, но значительно замедляет ранжирование и обновление данных.
Примеры: каталог Yahoo, dmoz - Гибридные системы. Сочетание автоматических поисковых роботов и процессов, управляемых человеком. Например, восстановление в каталоге удаленного сайта, нарушившего правила. Владелец страницы в этом случае вносит исправления и отправляет запрос в поддержку. Решение о повторном включении ресурса в поисковую систему принимает эксперт.
Примеры: MSN. Сюда же условно можно отнести Google, «Яндекс» и другие популярные поисковики, функционал которых не исключает ручную корректировку каталогов. - Метакраулеры. В отличие от поисковых систем, метакраулеры сами не сканируют веб-страницы для создания списков. Вместо этого они позволяют отправлять запросы нескольким поисковым системам одновременно.
Примеры: dogpile, DuckDuckGo
Есть и другие специализированные сервисы, которые можно использовать для поиска информации. Некоторые из них более удобны для поиска книг, фотографий, а какие-то обеспечивают большую конфиденциальность при работе и не запрашивают данные пользователей.
Источник: www.unisender.com
Поисковые системы
Поисковые системы (ПС) уже давно являются обязательной частью интернета и нашей повседневной жизни. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.

Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и продвижение своих сайтов, понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
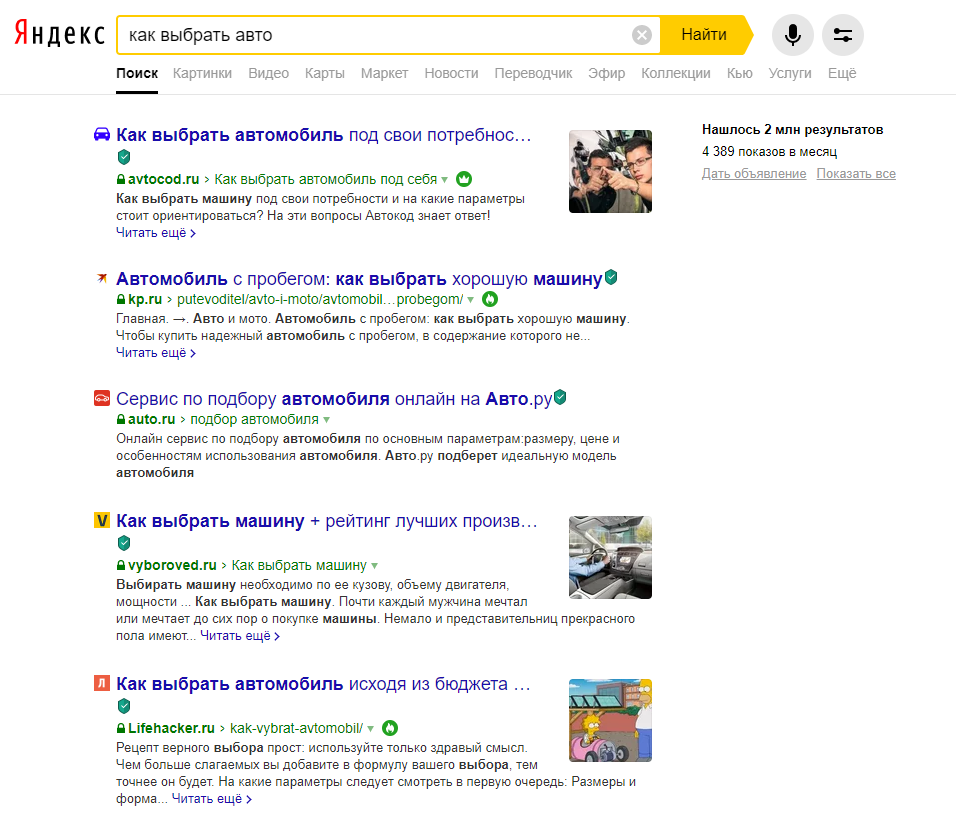
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Туле»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. Приучить же пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее?
Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями?
Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?
Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:
Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.
Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.
Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.
К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.
Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самым известным и большим каталогом в мире был DMOZ (прекратил работу 14 марта 2017 года) имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.
Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.

В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.

В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.

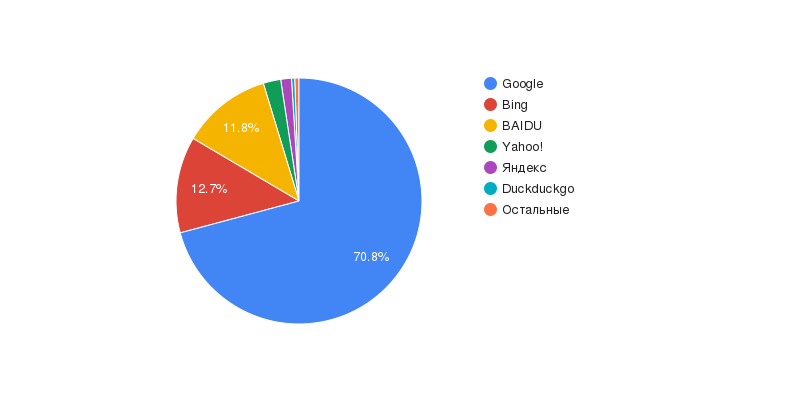
Доля поисковых систем
- Google — 70,83 %;
- Bing — 12,61 %;
- Baidu — 11,83 %;
- Yahoo! — 2,30 %;
- Яндекс — 1,41 %;
- DuckDuckGo — 0,42 %;
- Яндекс — 59,10%
- Google — 38,85%
- Поиск.Mail.ru — 1,18%
- Rambler — 0,07%
- Остальные — 0,80%

Принципы работы поисковой системы
Модуль индексирования.
Данный компонент состоит из трех программ-роботов:
Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.
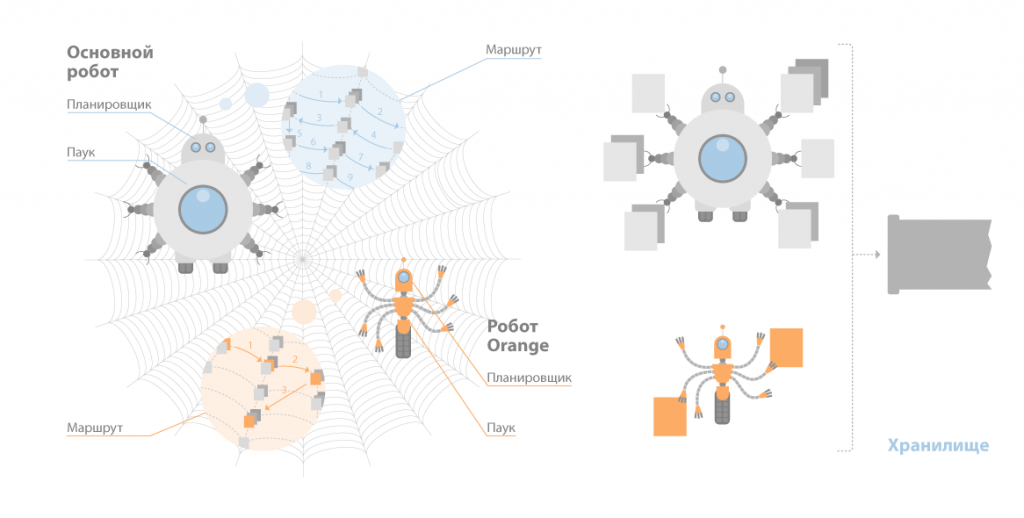
«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Crawler, исследуя найденные ссылки, ищет новые документы, еще не ставшие известными поисковой системе.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.
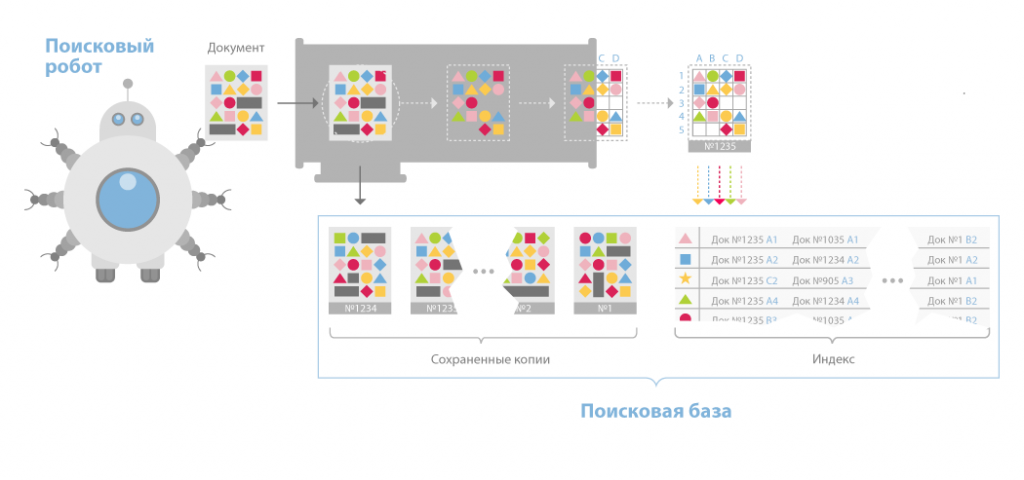
Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) — комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.
Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Источник: uniofweb.ru
Работа поисковых систем: общие принципы работы поисковиков

24 января 2 августа Игорь Серов SEO учебник yahoo, анализировать сайт, база данных, бот, механизм поисковой оптимизации, поисковый паук, поисковый робот, поисковых роботов, программа seo анализа, работа поисковиков, ссылка
Вступление
Каждая поисковая система имеет свой алгоритм поиска запрашиваемой пользователем информации. Алгоритмы эти сложные и чаще держатся в секрете. Однако общий принцип работы поисковых систем можно считать одинаковым. Любой поисковик:
- Сначала собирает информацию, черпая её со страниц сайтов и вводя её в свою базы данных;
- Индексирует сайты и их страницы, и переводит их из базы данных в базу поисковой выдачи;
- Выдает результаты по поисковому запросу, беря их из базы проиндексированных страниц;
- Ранжирует результаты (выстраивает результаты по значимости).
Работа поисковых систем – общие принципы
Вся работа поисковых систем выполняют специальные программы и комбинации этих программ.
Перечислим основные составляющие алгоритмов поисковых систем:
- Spider (паук) – это браузероподобная программа, скачивающая веб-страницы. Заполняет базу данных поисковика.
- Crawler (краулер, «путешествующий» паук) – это программа, проходящая автоматически по всем ссылкам, которые найдены на странице.
- Indexer (индексатор) – это программа, анализирующая веб-страницы, скачанные пауками. Анализ страниц сайта для их индексации.
- Database (база данных) – это хранилище страниц. Одна база данных это все страницы загруженные роботом. Вторая база данных это проиндексированные страницы.
- Search engine results engine (система выдачи результатов) – это программа, которая занимается извлечением из базы данных проиндексированных страниц, согласно поисковому запросу.
- Web server (веб-сервер) – веб-сервер, осуществляющий взаимодействие пользователя со всеми остальными компонентами системы поиска.
Реализация механизмов поиска у поисковиков может быть самая различная. Например, комбинация программ Spider+ Crawler+ Indexer может быть создана, как единая программа, скачивающая и анализирующая веб-страницы и находящая новые ресурсы по найденным ссылкам. Тем не менее, нижеупомянутые общие черты программ присущи всем поисковым системам.
Читать по теме: Советы по оптимизации сайта для начинающих

Программы поисковых систем
Spider
«Паук» скачивает веб-страницы так же как пользовательский браузер. Отличие в том, что браузер отображает содержащуюся на странице текстовую, графическую или иную информацию, а паук работает с html-текстом страницы напрямую, у него нет визуальных компонент. Именно, поэтому нужно обращать внимание на ошибки в html кодах страниц сайта.
Crawler
Программа Crawler, выделяет все находящиеся на странице ссылки. Задача программы вычислить, куда должен дальше направиться паук, исходя из заданного заранее, адресного списка или идти по ссылках на странице. Краулер «видит» и следует по всем ссылкам, найденным на странице и ищет новые документы, которые поисковая система, пока еще не знает. Именно, поэтому, нужно удалять или исправлять битые ссылки на страниц сайта и следить за качеством ссылок сайта.
Indexer
Программа Indexer (индексатор) делит страницу на составные части, далее анализирует каждую часть в отдельности. Выделению и анализу подвергаются заголовки, абзацы, текст, специальные служебные html-теги, стилевые и структурные особенности текстов, и другие элементы страницы. Именно, поэтому, нужно выделять заголовки страниц и разделов мета тегами (h1-h4,h5,h6), а абзацы заключать в теги
.
Database
База данных поисковых систем хранит все скачанные и анализируемые поисковой системой данные. В базе данных поисковиков хранятся все скачанные страницы и страницы, перенесенные в поисковой индекс. В любом инструменте веб мастеров каждого поисковика, вы можете видеть и найденные страницы и страницы в поиске.
Search Engine Results Engine
Search Engine Results Engine это инструмент (программа) выстраивающая страницы соответствующие поисковому запросу по их значимости (ранжирование страниц). Именно эта программа выбирает страницы, удовлетворяющие запросу пользователя, и определяет порядок их сортировки. Инструментом выстраивания страниц называется алгоритм ранжирования системы поиска.
Важно! Оптимизатор сайта, желая улучшить позиции ресурса в выдаче, взаимодействует как раз с этим компонентом поисковой системы. В дальнейшем все факторы, которые влияют на ранжирование результатов, мы обязательно рассмотрим подробно.
Читать по теме: Как подготовить статью для публикации на сайте, блоге
Web server
Web server поисковика это html страница с формой поиска и визуальной выдачей результатов поиска.
Повторимся. Работа поисковых систем основана на работе специальных программ. Программы могут объединяться, компоноваться, но общий принцип работы всех поисковых систем остается одинаковым: сбор страниц сайтов, их индексирование, выдача страниц по результатам запроса и ранжирование выданных страниц по их значимости. Алгоритм значимости у каждого поисковика свой.
Другие уроки SEO учебника
- Значение PageRank в ранжировании страниц сайта
- Высокочастотные и низкочастотные запросы
- Пресс-релизы в продвижении сайта
- Советы по оптимизации сайта для начинающих
- Подбор ключевых слов – общий принцип подбора ключей сайта
- Уточнение поисковых запросов – финальный этап составления семантического ядра
- Что такое Google PageRank: о бывшем значении PageRank в ранжировании
- Оценка конкуренции поисковых запросов – предпоследний шаг в составлении основного семантического ядра
- Ссылочный текст и релевантность ссылающихся страниц
- Что такое Google Sandbox
Источник: seojus.ru