
Если вы когда-либо писали или даже использовали Python, вы, вероятно, привыкли видеть файлы исходного кода Python; у них есть имена, заканчивающиеся на .py. Возможно, вы также видели другой тип файла с именем, оканчивающимся на .pyc, и возможно, вы слышали, что это файлы Python с «байт-кодом». И, возможно, вы слышали, что они экономят время, не позволяя Python пересматривать ваш исходный код при каждом запуске. Но помимо «о, это байт-код Python», знаете ли вы, что находится в этих файлах и как Python использует их?
Если нет, то сегодня ваш счастливый день. Я расскажу вам, что такое байт-код Python, как его использует Python для выполнения вашего кода и как знание о нем может вам помочь.
Python часто описывается как интерпретируемый язык – язык, на котором ваш исходный код переводится в нативные инструкции процессора во время работы программы, но это только частично верно. Python, как и многие интерпретируемые языки, на самом деле компилирует исходный код в набор инструкций для виртуальной машины, и интерпретатор Python является реализацией этой виртуальной машины. Этот промежуточный формат называется «байт-код».
Просто о битах, байтах и о том, как хранится информация #2
Таким образом, эти файлы .pyc, оставленные Python, – это не просто «более быстрая» или «оптимизированная» версия вашего исходного кода; это инструкции байт-кода, которые будут выполняться виртуальной машиной Python во время работы вашей программы.
Давайте посмотрим на пример. Вот классический «Hello, World!», написанный на Python:

И вот байт-код, в который он превращается (переведенный в удобочитаемую форму):

Если вы наберете функцию hello() и используете для ее запуска интерпретатора CPython, приведенный выше листинг будет выполняться Python. Хотя это может показаться немного странным, поэтому давайте посмотрим детальнее на происходящее.
Внутри виртуальной машины Python
CPython использует виртуальную машину на основе стека. То есть он полностью ориентирован на структуры данных стека (где вы можете «протолкнуть» элемент на «вершину» структуры или «вытолкнуть» элемент с «верха»).
CPython использует три типа стеков:
- Call stack. Это основная структура работающей программы на Python. У него есть один элемент (фрейм) для каждого в настоящее время активного вызова функции, причем нижняя часть стека является точкой входа в программу. Каждый вызов функции помещает новый кадр в стек вызовов, и каждый раз, когда возвращается вызов функции, его фрейм удаляется.
- В каждом фрейме есть evaluation stack (стек оценки), также называемый data stack. В этом стеке происходит выполнение функции Python, а выполнение кода Python состоит в основном из помещения чего-либо в этот стек, манипулирования этим и его возврата обратно.
- Также в каждом фрейме есть block stack. Он используется Python для отслеживания определенных типов управляющих структур: циклов, блоков try/except и т. д. Это приводит к тому, что записи помещаются в block stack, а он уже выталкивается всякий раз, когда вы выходите из одной из этих структур. Это помогает Python знать, какие блоки активны в данный момент, так что, например, оператор continue или break может воздействовать на правильный блок.
Большинство инструкций байт-кода Python манипулируют оценочным стеком текущего фрейма стека вызовов, хотя есть некоторые инструкции, которые делают другие вещи (например, переход к конкретным инструкциям или манипулирование стеком блоков).
КАК РАБОТАЕТ ИНТЕРПРЕТАТОР PYTHON (CPython)
Чтобы почувствовать это, предположим, что у нас есть некоторый код, который вызывает функцию, например: my_function (my_variable, 2). Python преобразует это в последовательность из четырех инструкций байт-кода:
- Инструкция LOAD_NAME, которая ищет функциональный объект my_function и помещает его в верхнюю часть стека оценки.
- Еще одна инструкция LOAD_NAME, которая ищет переменную my_variable и помещает ее в верхнюю часть стека оценки.
- Инструкция LOAD_CONST, чтобы поместить буквенное целое значение 2 поверх стека оценки.
- Инструкция CALL_FUNCTION.
Инструкция CALL_FUNCTION будет иметь аргумент 2, что указывает на то, что Python должен извлечь два позиционных аргумента из верхней части стека; тогда вызываемая функция будет сверху, и она также может быть выдвинута (для функций, включающих аргументы ключевых слов, используется другая инструкция – CALL_FUNCTION_KW, но с аналогичным принципом работы. Также используется третья инструкция, CALL_FUNCTION_EX, для вызовов функций, которые включают распаковку аргументов с помощью операторов * или **). Как только Python получит все это, он выделит новый фрейм в стеке вызовов, заполнит локальные переменные для вызова функции и выполнит байт-код my_function внутри этого кадра. Как только это будет сделано, кадр будет извлечен из стека вызовов, а в исходном кадре возвращаемое значение my_function будет помещено поверх стека оценки.
Доступ и понимание байт-кода Python
Если вы хотите поэкспериментировать с этим, модуль dis в стандартной библиотеке Python очень полезен; модуль dis предоставляет «дизассемблер» для байт-кода Python, что позволяет легко получить удобочитаемую версию и просмотреть различные инструкции байт-кода. Документация для модуля dis просматривает его содержимое и предоставляет полный список инструкций байт-кода, а также информацию о том, что они делают и какие аргументы они принимают.
Например, чтобы получить список байт-кодов для функции hello(), я набрал его в интерпретаторе Python и запустил:
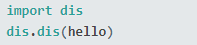
Функция dis.dis() будет дизассемблировать функцию, метод, класс, модуль, скомпилированный объект кода Python или строковый литерал, содержащий исходный код, и напечатает понятную для человека версию. Другая удобная функция в модуле dis – это distb(). Вы можете передать ему объект трассировки Python или вызвать его после возникновения исключения, и он разберет самую верхнюю функцию в стеке вызовов во время исключения, напечатает его байт-код и вставит указатель на инструкцию, которая вызвала исключение.
Также полезно посмотреть на объекты скомпилированного кода, которые Python собирает для каждой функции, поскольку при выполнении функции используются атрибуты этих объектов кода. Например:
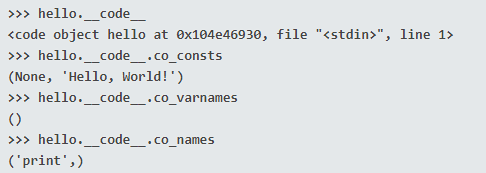
Объект кода доступен как атрибут __code__ в функции и содержит несколько важных атрибутов:
- co_consts – это кортеж любых литералов, встречающихся в теле функции;
- co_varnames – это кортеж, содержащий имена любых локальных переменных, используемых в теле функции;
- co_names – это кортеж любых нелокальных имен, на которые есть ссылки в теле функции.
Многие инструкции байт-кода, особенно те, которые загружают значения для помещения в стек или сохраняют значения в переменных и атрибутах, – используют индексы в этих кортежах в качестве аргументов.
Итак, теперь мы можем понять список байт-кода функции hello():
- LOAD_GLOBAL 0: говорит Python найти глобальный объект, на который ссылается имя с индексом 0 для co_names (который является функцией печати), и поместить его в стек оценки;
- LOAD_CONST 1: принимает литеральное значение по индексу 1 co_consts и проталкивает его (значение по индексу 0 равно литералу None, которое присутствует в co_consts, поскольку вызовы функций Python имеют неявное возвращаемое значение None, если не достигнут явный оператор возврата);
- CALL_FUNCTION 1: сообщает Python о вызове функции; ему нужно будет удалить один позиционный аргумент из стека, тогда новая вершина стека будет функцией для вызова.
«Необработанный» байт-код (как нечитаемые человеком байты) также доступен в объекте кода как атрибут co_code. Вы можете использовать список dis.opname для поиска имен инструкций байт-кода по их десятичным значениям байтов, если вы хотите попытаться вручную разобрать функцию.
Использование байт-кода
Сейчас вы наверное задаетесь вопросом: «Какова практическая ценность всей этой информации?».
Во-первых, понимание модели исполнения Python поможет вам понять ваш код. Людям нравится шутить о том, что C является своего рода «переносимым ассемблером», где вы можете догадаться, в какие машинные инструкции превратится тот или иной фрагмент исходного кода C. Понимание байт-кода даст вам те же возможности с Python. Если вы можете предвидеть, во что превращается байт-код вашего исходного кода Python, вы можете принять более правильное решение о том, как его написать и оптимизировать.
Во-вторых, понимание байт-кода – полезный способ ответить на вопросы о Python. Например, я часто вижу новых программистов на Python, которые задаются вопросом, почему одни конструкции быстрее других (например, почему <> быстрее, чем dict()). Знание того, как получить доступ и прочитать байт-код Python, позволяет вам выработать ответы (попробуйте: dis.dis(«<>») или dis.dis(«dict ()»)).
Наконец, понимание байт-кода и того, как Python выполняет его, дает полезные знания о конкретном виде программирования, которым программисты Python нечасто занимаются, – стек-ориентированное программирование.
Другие мануалы
- Преимущества и недостатки бесплатных доменов
- Синий экран смерти? — Наиболее частые причины популярной ошибки
- Tripmydream Academy: выбери удаленную работу для себя
- Как просушить телефон от воды в домашних условиях с несъемным аккумулятором
Источник: overcoder.net
Программирование графики на языке Java

Рассмотрим два понятия необходимые для нашего курса: SDK и applet (апплет).
SDK (Java Developers Kit) — это базовая среда разработки программ на Java. Она является невизуальной и имеет бесплатную лицензию на использование. Есть и визуальные платные среды разработки (например, JBuilder и др.).
Апплет — это небольшая программа, выполняемая браузером (например, на Internet Explorer). Апплет встраивается специальным образом в web-страничку. При подкачке такой странички браузером он выполняется виртуальной Java-машиной самого браузера.
На языке Java возможно создание как самостоятельных приложений, так и создание интернет апплетов. Здесь мы рассмотрим создание апплетов с компьютерной графикой, применяемых в интернет технологиях. В 1995 году компания Sun Microsystems приняла решение объявить о новом продукте, переименовав его в Java (единственное разумное объяснение названию—любовь программистов к кофе). Когда Java оказалась в руках Internet, стало необходимым запускать Java-аплеты—небольшие программы, загружаемые через Internet.
Особенностью языка Java является компиляция исходного кода в так называемый байт-код, независимый от платформы. При компиляции апплета создается файл с расширением class.

Рисунок 5.2. компиляция и запуск Java программы
Исходная Java-программа должна быть в файле с расширением java. Программа транслируется в байт-код компилятором javac.exe. Оттранслированная в байт-код программа имеет расширение class. Для запуска программы нужно вызвать интерпретатор java.exe, указав в параметрах вызова, какую программу ему следует выполнять. Кроме того, ему нужно указать, какие библиотеки нужно использовать при выполнении программы. Библиотеки размещены в файлах с расширением jar
Источник: ozlib.com
Оттранслированная в байт код программа
«Байт-код или байткомд (англ. byte-code), иногда также используется термин псевдокомд — машинно-независимый код низкого уровня, генерируемыйтранслятором и исполняемый интерпретатором. Большинство инструкций байт-кода эквивалентны одной или нескольким командам ассемблера. Трансляция в байт-код занимает промежуточное положение между компиляцией в машинный код и интерпретацией.» — Wikipedia.com, статья «Байт-код».

Рисунок 14 — Байт-код
Байт-код получил свое название за то, что длинна каждого кода определенной операции составляет ровно 1 байт, но длинна кода команды может отличаться. Каждая инструкция имеет вид однобайтовый код операции от 0 до 255, после которого идут следующие параметры — регистры либо адреса используемой памяти. Но это как правило, в частных случаях спецификация байт-кода может значительно различаться.
Приложение на байт-коде как правило компилируется интерпретатором байт-кода (чаще всего называется виртуальной машиной, так как по своей структуре очень схож с о строением компьютера). Основное преимущество — кроссплатформенность таких приложений. Это означает, что один и тот же байт код может выполняться на принципиально различных платформах и архитектурах. Однако, поскольку байт-код обычно менее абстрактный, более компактный и более «компьютерный», чем исходный код, эффективность байт-кода обычно выше, чем чистая интерпретация исходного кода, предназначенного для правки человеком.
По этой причине многие современные интерпретируемые языки на самом деле транслируют в байт-код и запускают интерпретатор байт-кода. К таким языкам относятся Perl, PHP, Ruby (начиная с версии 1.9) и Python. Компилятор Clipper создает исполняемый файл, в который включен байт-код, транслированный из исходного текста программы, и виртуальная машина, исполняющая этот байт-код.
Программы на Java обычно передаются на целевую машину в виде байт-кода, который перед исполнением транслируется в машинный код «на лету» — с помощью JIT-компиляции. В стандарте открытых загрузчиков Open Firmware фирмы Sun Microsystems байт-код представляет операторы языка Forth.
В то же время возможно создание процессоров, для которых данный байт-код является непосредственно машинным кодом (такие процессоры существуют, например, для Java и Forth).
Также некоторый интерес представляет p-код (p-code), который похож на байт-код, но физически может быть менее лаконичным и сильно варьироваться по длине инструкции. Он работает на очень высоком уровне, например «напечатать строку» или «очистить экран». P-код повсеместно используется в СУБД и некоторых реализациях BASIC и Паскаля.
Концепция решения проблемы
Описание предлагаемого метода подхода
Автор данной работы предлагает создание внутренней локальной сети для определенной организации, с целью обеспечения максимальной безопасности данных. Сеть должно быль построена по средством разработанной Латыповым А.А. серверной части, работа с сетью должна осуществляться по средством написанного на языке SmallBasic браузера, концепцию которого предлагает автор данной работы.
Основной проблемой, поставленной перед автором, является обеспечение максимальной безопасности. Для ее достижения был разработан комплекс принимаемых мер, описанных ниже.
Первой, и самой главной мерой, которая должна быть принята для обеспечения безопасности внутрикорпоративной сети — отсутствие к ней доступа извне. К этому можно отнести доступ через глобальную сеть, открытие доступа или распространение файлов, хранящихся в сети для лиц, не относящихся к сотрудникам организации.
Для выполнения поставленных задач было разработано несколько методов, гарантирующих безопасность и сохранность файлов, находящихся в корпоративной сети.
Одним из главных решений, которые были приняты в ходе выполнения данной работы, был отказ от личной регистрации пользователей с присвоением для них пары логин и пароль. Данная концепция широко применяется в разных системах для распознавания пользователя, но она не может обеспечивать достаточной безопасности, так как злоумышленники при получении данной информации могут воспользоваться ею в корыстных целях.
На замену привычному способу регистрации пользователей был разработан другой подход, благодаря которому работа с сетью возможна только на компьютерах организации и только для зарегистрированных пользователей. Заключается она в том, чтобы вшить пару логин и пароль в сам браузер во время его программирования. В таком случае для каждого пользователя будет скомпилирован свой личный браузер, содержащий пару логин и пароль конкретного пользователя. Этот браузер будет установлен на рабочее место служащего системным администратором в единичном экземпляре. Такой подход обеспечит:
· быстроту работы (пользователю не придется тратить время на заполнение полей «логин» и «пароль», а так же подключение к сети).
· безопасность, так как посторонний пользователь не сможет подключится сети не имея специального браузера, либо прямого физического доступа к компьютеру.
· точное ведение журнала действий пользователей сети.
На каждом их этих пунктов стоит остановится подробнее.
Работа для пользователя на подобном браузере будет максимально упрощенной по той причине, что от него не требуется никаких действий для подключения рабочего компьютера к сети. Достаточно будет просто включить компьютер и запустить заранее установленный системным администратором бразуер. По завершении работы достаточно будет просто выключить приложение. Так же пользователь будет свободен от необходимости держать в памяти логин и пароль, так как их нельзя никуда записать, чтобы эти данные не попали посторонним.
Такой подход обеспечит максимальную безопасность, ведь кроме мер стандартной безопасности, сеть будет защищена невозможностью подключения к ней посторонних компьютеров с получением доступа к информации без получения отдельной копии браузера. Но на случай, если злоумышленник заполучил копию браузера с чьего-либо рабочего места, был предусмотрен функционал браузера, который проверяет при запуске, не зарегистрирован ли в сети на данный момент браузер с таким же логином и паролем, как у него. В случае, если его логин и пароль совпали с уже зарегистрированными в сети, то все копии с подобной парой логин пароль закрывается, а доступ к сети навсегда блокируется. Это не позволит посторонним пользователям установить либо скопировать чужую версию браузера на свой компьютер и пытать подключиться к локальной сети организации.
Так же этот подход обеспечивает безопасность в том случае, если злоумышленник попытается «вытащить» для себя логин и пароль из приложения, так как скомпилированная на языке SmallBasic программа представляет собой байт-код, описанный выше. Это означает, что программа даже при попытке чтения ее кода представляет собой язык низкого уровня, непригодный для чтения человеком, что делает невозможным поиск в исходном коде никакой информации, способной дать доступ к сети.
Следующим пунктом идет точное ведение журнала активности пользователей. Пара логин — пароль, вшитая в код программы, позволяет быть уверенным, с какого компьютера действовал тот или иной пользователь.
Сам из себя браузер должен представлять окно с единственной открытой страницей, доступ к которой получает пользователь только после того, как его браузер успешно подключается к сети.
На странице пользователя будет располагаться информация, предоставленная ему сервером. Запуск рабочего компьютера так же будет совмещен с запуском сервиса, который будет служить для обновления информации, отображаемой браузером. для сервиса было разработано 2 концепции:
· Таймер. Эта концепция подойдет в том случае, если рабочий день в организации не нормированный, либо график изменчив в зависимости от дня недели, либо других событий. Концепция предполагает собой сервис, активируемый через заранее заданный системным администратором промежуток времени при условии, что браузер запущен.
· Строго заданное время обновления. Такой способ подойдет для организаций, в которых рабочий день длится строго отведенное время и возможно установить регламент, строго оговаривающий время запуска и выключения рабочих компьютеров. В этом случае сервис будет срабатывать во время включения компьютера.
Данные концепции призваны выполнить 2 задачи — снабжение работников обновленной информацией. Принцип работы сервиса следующий — сервис проверяет версию контента, либо дату его изменения. Если дата изменения либо версия отличаются от той, что отображается на экране пользователя, то данные обновляются, а пользователь во время обновления видит предупредительное окно, отображающее информацию об обновлении страницы. Таким образом будут достигнуты цели постоянного обновления информации для пользователя удобным для системного администратора либо руководителя фирмы способом. Так же будет исключена возможность перегрузки сервера запросами обновления страницы, отправленными пользователями, так как работники не имеют такой функции.
Страница, отображаемая в окне браузера уникальна для каждого пользователя. Эта концепция была заимствована из новейшей современной системы co-array — параллельного программирования. Таким образом каждый пользователь получает от сервера свои уникальные задания, не отвлекаясь на информацию, которая к нему не относится. Задания, составленные для работников, помещаются в специальные папки, находящиеся на компьютере-сервере.
Источник: studbooks.net