
High Availability и Disaster Recovery — как связаны эти понятия и за что они отвечают
Ни одна система не может работать безотказно со стопроцентной надежностью. Всегда есть вероятность выхода из строя всей системы или нескольких ее компонентов. Чтобы свести вероятность простоя к минимуму, IT-инженеры используют несколько стратегий, обеспечивающих максимально возможное время безотказной работы. Одна из них — High Availability или отказоустойчивость, другая — Disaster Recovery или аварийное восстановление.
High Availability — отказоустойчивость
High Availability означает, что IT-система, ее компоненты или приложения продолжат работу даже при выходе из строя некоторых элементов. При этом время простоя окажется минимальным или его не будет вовсе.
High Availability важна для систем, где длительный простой может привести к финансовым или репутационным потерям. Например, для онлайн-магазинов или банковских приложений. Представим, что онлайн-магазин крупного ритейлера во время новогодних распродаж сутки будет недоступен. Это приведет к огромным убыткам.
Отказоустойчивость — что это, и как обеспечить 100% доступность сайту
А если на сутки недоступным окажется банковское приложение, то это чревато серьезным репутационным ущербом для банка. Цель High Availability не в том, чтобы на 100% гарантировать, что сбоев не будет, а свести их к минимуму. В идеале, чтобы пользователи даже ничего не заметили.
Другими словами, отказоустойчивость означает, что из-за сбоя одного компонента системы не произойдет отказа в работе всей IT-инфраструктуры. Ведь все её компоненты: серверы, маршрутизаторы, виртуальные машины и балансировщики нагрузки избыточны как на уровне сети, так и на уровне приложений. Именно это и обеспечивает высочайший уровень отказоустойчивости.
Как оценивается High Availabilit
Отказоустойчивость измеряется в процентах от времени безотказной работы за год. Большинство провайдеров услуг со сложными системами обеспечивают время безотказной работы от 99% до 99,999%.
| Доступность | Суммарное время простоя в году |
| 99% | 3,65 дней |
| 99,9% | 8,77 часа |
| 99,99% | 52,60 минуты |
| 99,999% | 5,26 минуты |
Из таблицы видно, что уровень 99,9% предполагает почти девять часов простоя в год. В некоторых отраслях, например, банковской сфере, такой простой недопустим. Соответственно, необходим более высокий уровень отказоустойчивости.
Способы достижения High Availability
Есть несколько ключевых параметров, обеспечивающих высокую отказоустойчивость IT-инфраструктуры.
Географическая избыточность
Самый надежный способ достичь отказоустойчивости после аварии или стихийного бедствия — обеспечить географическую избыточность IT-инфраструктуры. Это достигается за счет развертывания серверов в разных регионах. Именно так делают компании, которым нужна повышенная отказоустойчивость и доступность их сервисов. Они размещают свои дата-центры в нескольких регионах и даже в разных странах и реплицируют в них свои сервисы, чтобы снизить зависимость от одной точки отказа. Поэтому в случае сбоя одного удаленного сервера или даже дата-центра работа продолжится.
Что такое отказоустойчивость? (кластер, сервера, сервисы)
Использование отказоустойчивых решений
Архитектура отказоустойчивой инфраструктуры обычно состоит из кластеров — нескольких связанных серверов с возможностью аварийного переключения между ними. Аварийное переключение — это передача нагрузки с вышедших из строя рабочих мощностей на резервные.
Балансировка сетевой нагрузки
Балансировка улучшает доступность ключевых веб-приложений. В случае отказа одного сервера экземпляры приложений заменяются, а трафик автоматически перенаправляется на работающие серверы. Балансировка нагрузки обеспечивает не только отказоустойчивость, но и дополнительную масштабируемость инфраструктуры.
Настройка синхронизации данных в соответствии с RPO организации
RPO — это объем данных, которые могут быть потеряны из-за сбоя без ущерба для бизнеса. RTO устанавливается в секундах, минутах или часах, в зависимости от количества изменяемых данных в системе. Для разных сервисов параметры RTO могут отличаться.
Disaster Recovery — аварийное восстановление
В отличие от High Availability, аварийное восстановление нужно на случай события с катастрофическими последствиями для IT-инфраструктуры. Причиной могут быть события природного происхождения: пожар, наводнение, землетрясение. А также технологического: авария сервера или сетевой инфраструктуры. Назначение DR — быстрое восстановление работоспособности после катастрофы.
Что нужно для аварийного восстановления
Для этого создается резервная инфраструктура, например, дата-центр где хранятся копии всех критически важных систем. В случае аварии резервный ЦОД возьмет на себя нагрузку, и работа организации продолжится.
Что такое Disaster Recovery Plan (DRP)
Исходя из задач бизнеса, каждая компания самостоятельно определяет стратегию и параметры аварийного восстановления. Для это разрабатывается Disaster Recovery Plan, где указывается максимально допустимое время для восстановления работоспособности — RTO (целевое время восстановления) и упомянутый выше RPO. В плане прописывается место для сохранения резервных копий и как они должны быть восстановлены после аварии.
Так как IT-инфраструктура со временем меняется, DRP необходимо периодически обновлять. Кроме того, регулярно нужно выполнять тесты-проверки работоспособности DRP. О том, что такое DRP мы писали в статье.
Сравнение отказоустойчивости с аварийным восстановлением
High Availability часто путают с аварийным восстановлением — Disaster Recovery. Попробуем разобраться.
High Availability позволяет продолжить работу при сбое одного компонента инфраструктуры, например, отказе сервера.
Аварийное восстановление позволяет продолжить работу при выходе из строя корпоративного или облачного дата-центра, например, из-за пожара.
Другими словами, High Availability — это стратегия устранения сбоев одного или нескольких компонентов IT-инфраструктуры. Disaster Recovery — это способ справиться с катастрофическими событиями, способными уничтожить всю IT-инфраструктуру организации.
Упрощенно говоря, High Availability отвечает за живучесть IT-инфраструктуры, а Disaster Recovery — за возможность восстановить ее после катастрофы. Эти стратегии дополняют друг друга и помогают предприятию справиться с отказами инфраструктуры. Можно сравнить это с кораблём, который вышел в океан.
Во время плавания команда справляется с текущими поломками и продолжает движение в порт назначения. Но однажды корабль сталкивается с айсбергом. Команда быстро понимает, что спасти его нельзя. Она забирает всё самое ценное и пересаживается в резервную инфраструктуру — шлюпки.
High Availability и Disaster Recovery в облаке провайдера
Важно понимать, что поддержка отказоустойчивости корпоративной инфраструктуры и развертывание локальных резервных мощностей для аварийного восстановления доступны лишь очень крупным корпорациям. Причина — высокая стоимость таких решений.
С другой стороны, масштабируемость, географическая избыточность, а также SLA на уровне 99,99 и выше — это стандартные характеристики публичных облаков. Клиентам облачного провайдера не нужно ломать голову, где взять мощности для обеспечения отказоустойчивости. Масштабируемые ресурсы предоставляются по запросу в нужное время и в нужном объеме, а избыточность инфраструктуры заложена еще на стадии проектирования. Кроме того, облачные провайдеры предоставляют свои мощности и готовые решения (DRaaS) для аварийного восстановления. Поэтому для большинства организаций миграция в облако — это недорогое и подходящее решение для повышения отказоустойчивости своей IT-инфраструктуры.
Источник: www.corpsoft24.ru
Надёжность, доступность и отказоустойчивость сайтов и веб-приложений
Действительно серьёзные проекты должны работать без перебоев даже в случае отказа отдельных подсистем. А причин для сбоев в работе немало — это выход из строя серверного «железа», сбои программного обеспечения, аварии на уровне дата-центров. Но всех этих рисков можно избежать или минимизировать их последствия.
Отказоустойчивость — это способность системы продолжать полноценно работать при выходе из строя отдельных компонентов — серверов или каналов связи, сбоев на уровне отдельных модулей системы и т.д.
При этом стоит знать, что построение и сопровождение отказоустойчивой системы будет сложнее и дороже, нежели разработка и поддержка обычной системы. Подходить к проектированию каждого конкретного решения стоит с точки зрения экономической целесообразности. А для того, чтобы критерии принятия решения были объективны, нужны показатели, которые позволят измерить и сопоставить различные варианты.
Отказоустойчивость сложно измерить саму по себе, но измерению поддаётся аптайм — доступность сервиса, выраженная в процентах. Правильнее всего с точки зрения аналитики измерять аптайм за длительные интервалы — как минимум за год, а лучше — еще за больший интервал. Аптайм в диапазоне 99.8-99.9% — это нормальный показатель для обычных проектов на виртуальных хостингах или VPS — это примерно 1-2 часа неработоспособности в месяц или около 12 часов недоступности сервиса в год. Показатель около 99.95% — эквивалент 4 часов недоступности в год — уже достаточно хороший для односерверных инсталляций и для ПО, изначально не спроектированного для высокой отказоустойчивости. Если же требуемый уровень аптайма 99.99% и выше, то обычно требуется как построение соответствующей серверной инфраструктуры, так и модификация кодовой базы проекта для работы в режиме высокой отказоустойчивости.
Для обеспечения нормального уровня доступности не нужно строить отказоустойчивую систему: достаточно просто качественно написанного кода приложения, адекватных процессов сопровождения, рекомендуется пользоваться услугами профессиональных хостинговых компаний — они резервируют каналы связи, питание и охлаждение оборудования, а также для односерверных инсталляций использовать надежные выделенные сервера — лучше физические, а не виртуальные.
Для достижения высокого уровня доступности уже используются механики построения отказоустойчивых систем — в частности, дублирование всех критичных подсистем, что позволяет приложению функционировать, даже если из строя выходит один из компонентов. Основных способа тут два — горизонтальное масштабирование или дублирование всех серверов и настройка их автоматической «горячей» замены. И в том, и в другом случае выполняется дублирование всех критичных компонентов системы, разница лишь в штатных режимах работы и в механике обеспечения отказоустойчивости. При горизонтальном масштабировании компоненты работают параллельно и это к тому же повышает устойчивость к нагрузкам, а при использовании схемы с «горячей заменой» резервный компонент включается только в момент выхода из строя основного. Горизонтальное масштабирование обычно более привлекательно с точки зрения утилизации мощностей, но применимо оно не везде и часто требует более существенных доработок ПО для реализации.
Отказоустойчивость — важное свойство для больших и нагруженных систем: если минута простоя обходится к крупную сумму денег, то целесообразно инвестировать в построение отказоустойчивой инфраструктуры и разрабатывать архитектуру ПО в соответствие с принципами отказоустойчивости.
Источник: web-creator.ru
Отказоустойчивые ИТ-системы: принципы построения
В данной статье рассмотрим вкратце все влияющие на непрерывность функционирования ИТ-систем факторы, акцентировав внимание на отказоустойчивости. Это позволит понять важность этой характеристики с точки зрения ИТ-специалиста и с точки зрения бизнеса.
Инженерные системы ЦОДа
Для нормального функционирования любой ИТ-системы как минимум необходимо обеспечить штатные (предусмотренные производителем) условия эксплуатации поддерживающего ее ИТ-оборудования. Достигается это с помощью инженерных систем. Не слишком углубляясь в подробности, назовем наиболее важные из них: средства бесперебойного электроснабжения, системы климатического контроля, специальные стойки для размещения ИТ-оборудования и охранно-пожарная сигнализация.
Административно-организационное обеспечение
Административно-организационное обеспечение ИТ-систем предполагает специально разработанные регламенты поддержки их непрерывного функционирования и характеризует отлаженность административных процедур. Регламенты делятся на периодические (определяют порядок планового обслуживания ИТ-систем) и инцидентные (описывают действия для выхода из кризисной ситуации).
Еще один аспект административно-организационного обеспечения — четко выстроенная ролевая модель с прописанными требованиями к персоналу на каждую роль, а также грамотная организация труда обслуживающего ИТ-систему персонала.
Средства безопасности
Данный фактор охватывает все аспекты информационной безопасности, а также такой немаловажный для компании в целом компонент, как система контроля и управления доступом. Не заостряя внимание на составе средств безопасности, хочется отметить важность данного компонента и с точки зрения обеспечения непрерывности функционирования ИТ-систем.
Средства контроля и управления ИТ-инфраструктурой и ПО
Непрерывность функционирования и, соответственно, уровень доступности любой ИТ-системы зависят от того, как оперативно обслуживающий персонал получит информацию о внештатной ситуации и как быстро отреагирует на возникшую угрозу отказа ИТ-системы. Своевременность получения сигнала о внештатной ситуации определяется наличием и эффективностью системы мониторинга. Скорость устранения угрозы отказа ИТ-системы напрямую зависит от эффективности средств управления ИТ-инфраструктурой и прикладным и системным ПО. Например, единая консоль мониторинга и управления ИТ-системой позволяет значительно снизить время реакции и сократить время нештатного функционирования системы.
Реализация механизма создания резервных копий
Практически любая ИТ-система зависит от обрабатываемых ею данных, кроме, разве что, систем распределенных вычислений, где ценность самих данных минимальна. Чтобы обеспечить непрерывность функционирования ИТ-системы и свести к минимуму время ее простоя, необходимо регулярно выполнять резервное копирование данных. Это позволяет минимизировать риски потери и изменения данных, а также сократить время простоя ИТ-системы.
Определение отказоустойчивости
Согласно общепринятым представлениям, отказоустойчивость ИТ-системы определяется ее способностью сохранять работоспособность при отказе одного или нескольких компонентов. Исходя из типовой архитектуры ИТ-систем, можно выделить несколько компонентных составляющих общей отказоустойчивости:
- отказоустойчивость программного обеспечения (как системного, так и прикладного);
- отказоустойчивость аппаратного обеспечения ИТ-системы на уровне логических модулей (например, подсистемы хранения данных);
- отказоустойчивость аппаратного обеспечения ИТ-системы на уровне отдельного устройства (например, сервера);
- отказоустойчивость отдельных модулей внутри устройства (например, отказоустойчивость конфигурации жестких дисков);
- отказоустойчивость отдельной площадки (в случае, если ИТ-система имеет географически распределенную архитектуру).
Механизмы реализации отказоустойчивости
В настоящее время единственным механизмом обеспечения отказоустойчивости ИТ-системы является избыточность входящих в нее компонентов. Рассмотрим как реализуется отказоустойчивость на компонентных уровнях.
Отказоустойчивость программного обеспечения. Речь идет об использовании различных способов кластеризации с установкой идентичного программного обеспечения на всех узлах кластера. В случае отказа ПО или программного сбоя на одном из узлов кластера его нагрузка перераспределяется между корректно функционирующими узлами. За это отвечает кластерное ПО, которое по определенным критериям определяет, на каком из узлов неверно функционирует системное или прикладное программное обеспечение и «выключает» данный узел из активной деятельности.
Стоит отметить, что отказ аппаратной части узла приводит к тем же последствиям, но диагностировать причину неработоспособности прикладного или системного программного обеспечения сложно и не имеет особого смысла. Отказ одного из узлов кластера не приводит к остановке ИТ-системы или ограничению ее функциональности. Типичный негативный эффект от такого единичного отказа проявляется в снижении производительности системы и возможной задержке в выполнении операций ввода-вывода на время переноса нагрузки сбойного кластера на другие узлы.
Примером кластерного ПО для обеспечения отказоустойчивости программного обеспечения может служить Veritas Cluster Service. Данный продукт имеет богатый функционал для построения зависимостей между разными уровнями ресурсов кластера, расширенные средства диагностики и определяемый набор политик для переноса нагрузки с отказавшего узла кластера на корректно функционирующие узлы.
Другой пример реализации механизма отказоустойчивости ПО — серверная виртуализация.
Отказоустойчивость аппаратного обеспечения ИТ-системы на уровне логических модулей. В этом случае механизм реализации отказоустойчивости идентичен вышеописанному, но предполагает кластеризацию аппаратных средств без использования внешнего программного обеспечения. Такой вид кластеризации применяется главным образом в системах хранения данных и серверных многоузловых сборках. Средства управления таким аппаратным кластером отвечают только за исправность аппаратной составляющей и не контролируют корректность функционирующего на этом кластере программного обеспечения. Отказ одного сервера или одной системы хранения данных в такой логической сборке не вызовет остановку всей ИТ-системы, а лишь ограничит ее производительность.
Как правило, такого рода отказоустойчивые системы создаются производителем аппаратных средств, но поскольку их внедрение и обслуживание требует высокой квалификации, компания RedSys рекомендует привлекать для выполнения таких работ специализированную ИТ-компанию.
Отказоустойчивость аппаратного обеспечения ИТ-системы на уровне отдельного устройства. Аппаратная отказоустойчивость отдельного устройства обеспечивается избыточностью наименее надежных его компонентов. Например, сервер может иметь несколько дополнительных блоков питания и вентиляторов охлаждения, при этом условия, когда он оказывается неработоспособным, определяются реализованной схемой избыточности тех или иных компонентов. Наиболее распространены схемы N+1 (избыточным является только один компонент в подсистеме, и, соответственно, допускается отказ только одного такого же компонента) и 2N (двукратная избыточность, допускающая выход из строя половины установленных в функциональном блоке идентичных компонентов).
Аппаратная отказоустойчивость устройства обеспечивается его производителем. Возможности настройки в этом случае, как правило, минимальны, а внесение изменений в схему реализации отказоустойчивости возможно только производителем через обновление микрокода аппаратного устройства.
Отказоустойчивость отдельных модулей внутри устройства. Обеспечение отказоустойчивости на уровне отдельных модулей распространено, в частности, при организации хранения данных, причем как оперативного, так и долговременного, и так же основано на избыточности отдельных аппаратных компонентов: жестких дисков и (значительно реже) модулей оперативной памяти.
Обычно в таких случаях пользователь аппаратного устройства сам ищет разумный компромисс между отказоустойчивостью и производительностью модуля, а также риском потери данных и стоимостью их хранения. При этом схема реализации отказоустойчивости выбирается из жестко заданных производителем оборудования вариантов. Вместе с тем варианты здесь могут быть самые разные. Применяются схемы N+1, N+2, 2N, а также множество производных схем, заданных производителем в виде шаблонов. Стоит также отметить, что такого рода решения могут предусматривать автоматическое устранение отказа через некоторый период времени.
Во избежание потери данных отказоустойчивость отдельных модулей хранения реализуется во всех системах корпоративного класса. Для ИТ-персонала компаний это не представляет особой сложности, но для правильного выбора схемы обеспечения отказоустойчивости RedSys рекомендует использовать проектный подход.
Катастрофоустойчивое решение
В редких случаях причиной утраты работоспособности ИТ-системы может стать отказ ЦОДа в целом в результате локальной или глобальной катастрофы. Стоимость катастрофоустойчивого решения весьма значительна, поскольку требует дублирования функционала ЦОДа на географически удаленной площадке. При этом используют два разных подхода.
Первый предполагает практически полное воспроизведение функционала защищаемого ЦОДа на удаленной площадке с той же или, как вариант, с несколько меньшей производительностью. В случае отказа основного ЦОДа его функции берет на себя резервный.
Факторами риска в данном случае являются административный ИТ-персонал, который должен своевременно принять решение о переносе сервисов на другую площадку, и наличие отработанного регламента для успешного выполнения этой операции. Во время переноса нагрузки в резервный ЦОД предоставляемые сервисы могут быть временно недоступны. Существует также риск потерять некоторый объем данных, определяемый тем, как организована репликация данных между ЦОДами. Данный подход к обеспечению катастрофоустойчивости ИТ-систем базируется на нескольких кластерах, объединенных в так называемый метрокластер.
Второй подход предполагает обеспечение сохранности данных, то есть в случае отказа основного ЦОДа на удаленной площадке остаются невредимыми резервные копии и/или реплики данных с СХД основного ЦОДа. Это менее дорогое решение, поскольку на удаленной площадке создается только избыточная часть системы резервного копирования или часть системы хранения данных. Оно не защищает полностью от отказа ЦОДа, но позволяет свести к минимуму риск потери данных.
Автор статьи — Алексей Амосов, директор департамента программно-аппаратных комплексов RedSys.
СПЕЦПРОЕКТ КОМПАНИИ REDSYS
Источник: www.itweek.ru
Отказоустойчивость и катастрофоустойчивость: сравнение подходов

При построении инфраструктуры одним из популярных запросов компаний становится Business continuity, то есть непрерывность бизнес-процессов. Это означает, что система должна сочетать в себе катастрофоустойчивость (Disaster Recovery) и отказоустойчивость, или высокую доступность (High Availability). Разберемся, в чем заключается разница этих подходов и какие преимущества у них имеются.
Подробнее о понятиях
IT-инфраструктура строится с учетом возможных сбоев в работе. В идеале любые критические ситуации система должна переживать с минимальными потерями или вовсе без них. И под сбоями понимаются не только аппаратные или программные неполадки, но и ураганы, пожары и любые другие стихийные бедствия, а также человеческий фактор. По сути список возможных угроз можно продолжать бесконечно.
ИТ-инфраструктура должна быть спроектирована с учетом, если не всех, то хотя бы большинства возможных угроз. Основная задача – чтобы система пережила возможные опасности и осталась в рабочем состоянии. Именно в связи с этим и звучат два термина – отказоустойчивость и катастрофоустойчивость. Рассмотрим подробнее каждый из них.
Отказоустойчивость – это определенное свойство системы сохранять свою работоспособность после отказа одного или нескольких компонентов. С его помощью удается продолжить выполнение бизнес-задач без сбоев и простоя. Это свойство характеризует два технических момента инфраструктуры, а именно – коэффициент готовности и показатели надежности. В первом случае речь идет о времени от всего срока эксплуатации системы, в котором она находится в рабочем состоянии. Второй показатель определяет вероятность безотказной работы инфраструктуры за определенный период.
Катастрофоустойчивость же определяется как способность системы продолжать запущенные задачи при выходе всего ЦОДа из строя. Например, это может потребоваться при отключении электричества или различных природных явлениях, которые влияют на работу оборудования.
Если же говорить кратко, то принцип отказоустойчивости направлен на устранение возможных точек отказа инфраструктуры, тогда как катастрофоустойчивость позволяет поддержать работоспособность системы даже после серьезной аварии.
Аренда выделенного
сервера
Разместим оборудование
в собственном дата-центре
уровня TIER III.
Конфигуратор сервера
Подбор оборудования для решения Ваших задач и экономии бюджета IT
Особенности построения отказоустойчивости
High Availability, или HA, как мы уже отметили, нацелена на избавление от отдельных точек отказа. Следовательно эта концепция подразумевает резервирование различных сведений и избыточность. Резервирование производится в области программного обеспечения, «железа» и окружения. Это требуется для того, чтобы бизнес-процессы не прерывались при выходе из строя отдельного компонента ИТ-системы.
Одним из первых способов для высокой доступности в вычислениях стали средства аппаратного резервирования. Именно их часто применяли внутри локальной сети, до использования облачных приложений. Однако только при помощи аппаратного резервирования решить проблему отказоустойчивости не удалось, поэтому дополнительно стали использоваться следующие решения:
- резервирование питания за счет подключения нескольких источников – помогло решить проблему отключения физических серверов в случае сбоя на одном из них;
- резервирование отдельных хранилищ с применением RAID – позволило устранить возможную потерю данных;
- резервирование сети при помощи подключения контроллеров – решило проблему отключения сервера от сети в случае сбоев;
- устранение ошибок системы для предотвращения повреждения файловой системы.
В дальнейшем была доработана и избыточность ПО. Многие разработчики стали учитывать этот фактор при разработке приложений, для того чтобы предотвратить ошибки в работе при аппаратных сбоях или проблемах конфигурации. Для обеспечения избыточности используются следующие средства:
- внедрение специальных технологий для масштабируемости системы;
- использование технологии кластеризации и распределение нагрузки по серверам;
- обеспечение доступности;
- мониторинг работы программ и приложений;
- использование систем, имеющих способность самовосстанавливаться.
Развитие облачных технологий подняло отказоустойчивость системы на новый уровень. Появилась концепция избыточности окружения, которая характеризуется аппаратной избыточностью в стойке. Ее цель – равномерное распределение нагрузок для устранения точек отказа.
Используемые меры позволяют решить основную проблему инфраструктуры – точки отказа. За счет этого провайдеры могут гарантировать клиентам доступность всех используемых сервисов. Доступность системы фиксируется в SLA, уровень отказоустойчивости обозначается в процентном соотношении. Он отражает время доступности системы и гарантирует максимальную длительность простоя в год. Например, при показателях 99,99% время простоя в течение календарного года не может превышать 52,6 минут.
Высокая доступность системы является результатом тщательного планирования. То есть, если какие-то факторы не будут учтены на стадии разработки инфраструктуры, то добиться полной отказоустойчивости будет практически невозможно. Обязательным является создание «сценария катастрофы», который помогает учесть последствия любых разрушительных событий и понять, как будет работать система в чрезвычайных ситуациях.
Особенности катастрофоустойчивости

Второй подход к построению ИТ-инфраструктуры – это катастрофоустойчивость, или Disaster Tolerance. Он необходим для того, чтобы спасти важные компоненты системы и сохранить ее работоспособность при серьезной аварии. Например, такая ситуация может возникнуть при пожаре, наводнении или любом другом событии, которое приведет к массовому выходу оборудования из строя.
Главный принцип обеспечения катастрофоустойчивости заключается в использовании кластерной конфигурации. Серверы геораспределяются, то есть размещаются в разных местах, при этом поддерживается единство сети хранения данных. Создается основная и резервная площадки, которые используют единую систему.
Для защиты от природных и техногенных катастроф используется резервирование основных систем размещения и обработки данных. То есть, по сути это еще одно проявление геораспределенной системы. Наличие резервного дата-центра позволяет обеспечить работу инфраструктуры в том случае, если пострадает главное здание ЦОДа.
Нередко к катастрофоустойчивости относят и такое понятие, как Disaster Recovery, или DT. Однако формально этот термин обозначает аварийное восстановление системы. Оно требуется для поддержания работоспособности корпоративной инфраструктуры после масштабного сбоя в работе.
Термин «катастрофоустойчивость» тесно связан с двумя факторами – RTO и RPO. Разберемся, что они обозначают:
- RTO – это целевое время. То есть, это тот период, за который система должна вернуться к рабочему состоянию. Для критически важных компонентов инфраструктуры RTO определяется в секундах, тогда как другие системы могут восстанавливаться в течение часов и даже дней.
- RPO – это точка восстановления. Такой параметр отображает допустимый объем потерянных данных после аварии, который измеряется во времени. Суть в том, что некоторые системы могут потерять данные за день, тогда как другие – за несколько секунд.
План создания инфраструктуры
Непрерывность бизнес-задач потребует тщательного планирования на стадии разработки и построения инфраструктуры. Для этого компании потребуется подготовить два плана:
- Business Continuity Plan. Этот документ необходим для непосредственного обеспечения непрерывности бизнеса. В нем детально описывается, что и в какой последовательности нужно сделать для восстановления текущих задач и процессов.
- Disaster Recovery Plan. Этот план содержит подробную информацию о действиях по восстановлению ИТ-инфраструктуры после катастрофы.
В первом случае может описываться принцип организации удаленной работы, перераспределение задач на другие отделы, изменение отдельных процессов и т. д. Во втором – как эффективно и быстро запустить серверы и при этом сохранить текущие процессы.
Оба плана создаются с учетом требований бизнеса, сферы деятельности, особенностей процессов и т. д. Главное условие – использовать эти схемы сразу после аварийной ситуации. В правильно составленных планах будут содержаться подробные инструкции и список сотрудников, ответственных за их выполнение.
Технологии резервирования

Как вы понимаете, для обеспечения непрерывности всех процессов обязательным является наличие резервной площадки для размещения серверов. То есть при возникновении любого форс-мажора важно развернуть инфраструктуру на новых мощностях, поэтому наличие запасного «железа» на резервной площадке окажется очень кстати.
Может использоваться несколько типов резерва:
- Холодный резерв. В этом случае потребуется наличие серверной с запасным оборудованием. Также может планироваться закупка дополнительного оборудования или хранение «железа» на складе. Основная трудность будет связана с быстрым запуском аппаратуры, особенно, в случае его закупки или аренды сразу после возникновения катастрофы. Процедура потребует времени, поэтому возможны простои в работе компании. Помимо склада с оборудованием, наиболее редкие серверы и ПК могут храниться на складах поставщиков. Восстановление инфраструктуры в таком случае может занять от нескольких дней до нескольких недель, однако такой вариант является самым дешевым.
- Теплый резерв. Этот вариант подразумевает наличие запасной площадки, на которой имеется базовая вычислительная инфраструктура, а также настроена сеть и WAN-каналы. То есть подключено базовое оборудования, что позволит сразу можно перенаправить необходимые нагрузки. По вычислительным мощностям теплый резерв будут уступать основной площадке, но зато позволит запустить систему в течение одного дня. Такое решение можно назвать самым популярным, так как оно сочетает низкую стоимость и приемлемое время ввода в эксплуатацию.
- Горячий резерв. Именно такой вариант обеспечивает наилучшую катастрофоустойчивость информационных систем. Предполагается, что у компании имеется резервная площадка, которая по производительности и мощности не уступает основной. Все данные инфраструктуры постоянно реплицируются и копируются, поэтому в запасном ЦОД хранятся актуальные копии данных. Площадка имеет готовую инфраструктуру с настроенными каналами и готова к мгновенному использованию. Этот вариант подойдет для крупных организаций, которым критически важно избежать даже минутных простоев бизнес-процессов. Минус подобного решения – простой оборудования. По сути, вам придется оплачивать сразу две площадки со всей инфраструктурой, из-за чего расходы могут значительно возрасти.
Выводы
IT-инфраструктура обеспечивает доступ сотрудников к нужной информации, именно от нее зависит скорость бизнес-процессов. В последние годы требования к информационным системам только ужесточаются, ведь каждая минута простоя может серьезно ударить по бюджету организации.
Для обеспечения непрерывной работы инфраструктуры потребуется одновременное использование принципов отказо- и катастрофоустойчивости. Эти процессы предполагают соблюдение ряда условий:
- создание плана действий в случае непредвиденных ситуаций;
- применение средств бесперебойного электроснабжения;
- наличие резервов аппаратных компонентов и сети;
- использование резервных копий данных и т. д.
Если вы не знаете, с чего начать построение собственной инфраструктуры и как обеспечить ее надежность и бесперебойность, то специалисты нашего дата-центра Xelent готовы помочь в этом вопросе. Оставляйте заявки на нашем сайте, и мы обязательно перезвоним!
Популярные услуги
Отказоустойчивая инфраструктура
Отказоустойчивая инфраструктура – это комплекс решений, направленных на поддержание постоянной работоспособности оборудования: компьютеров, комплектующих, ПО и локальной сети.
Отказоустойчивое облако Xelent
Каждый элемент в отказоустойчивом облаке подключен к двум независимым линиям питания. Система АВР позволяет корректно переключать нагрузку между основным и резервным питанием.
Виртуальный Дата-центр, VDC с управлением через vCloudDirector
Простая, удобная и надежная интеграция облачной инфраструктуры в IT-инфраструктуру компании с глубокими индивидуальными настройками.
Источник: www.xelent.ru
Отказоустойчивые системы: зачем нужны и как построить
Мы всегда надеемся, что оборудование и инфраструктура будут работать чётко, надёжно, и без поломок. Особенно это важно там, где неисправности приводят к остановке бизнес–процессов и как следствие – финансовым и репутационным потерям.
Как минимум, эти потери складываются из оплаты сотрудников за время простоя (пока они ждут восстановления работы системы), и упущенной за это время прибыли. К этому можно добавить суммы, затраченные на сам ремонт и восстановление системы (покупку исправных комплектующих, оплату работ по установке и замене, и т.п.). Сумма убытков может быть достаточно большой; в некоторых случаях простой может привести к непоправимым последствиям – вплоть до исчезновения бизнеса. Это является поводом задуматься о том, как можно избежать остановки работоспособности.

Самым простым и очевидным способом избежать простоя из-за неисправности является резервирование – то есть такая избыточность оборудования, которая позволит продолжить работу при выходе его части из строя.
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне – самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически – двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости – это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская
плата. Выход из строя RAID-контроллера может привести к частичной или полной
потере данных, а выход из строя материнской платы приведет к остановке всего
сервера. Как защититься от таких неисправностей и обеспечить безотказную
работу?
Резервирование серверов (кластеры)
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двухузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
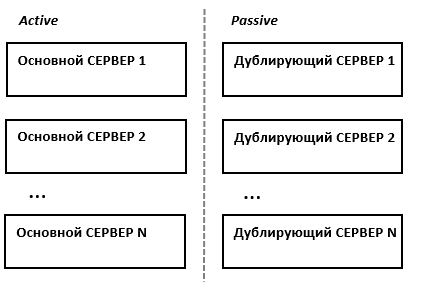
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.

Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
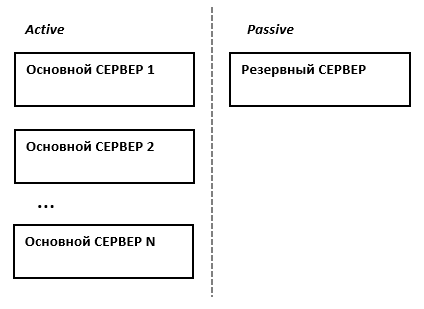
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M – когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
Active/Active
Active/Passive
Источник: habr.com