
Первые упоминания систем, способных распознавать документы, уходят в 90-е годы. С того периода прошло немало времени и современные системы распознавания сильно преобразились. В настоящей статье мы хотели бы рассказать насколько сильно изменились технология распознавания, какие стадии развития прошел данный процесс и что в настоящем мире можно понимать под термином многогранным термином «распознавание документов».
Стадия первая: Получение текстового документа
В самом базовом понимании термин «распознавание документа» обозначает получение текстового документа на основе отсканированного изображения документа. Указанная функция широко востребована многими людьми, поскольку очень часто сталкиваются с тем, что у их под рукой нет исходного вордовского документа, но есть или бумажный экземпляр документа или есть отсканированная копия.
Стадия вторая: Получение базовых атрибутов документа
По мере развития систем распознавания некоторые из них научились определять значения атрибутов документов. Это позволило облегчить процесс занесения данных в информационные системы при облегчить регистрации документов. И если раньше ввод данных был возможен исключительно вручную, путём перенабивки сотрудником текстов из полей, то теперь появилась возможность переносить распознанные данные, полученные после распознавания.
Лучшие программы для распознавания текста. Рейтинг OCR.
Стадия третья: Классификация документов
Далее в системах распознавания появилось понятие автоматической классификации документов. Также данный процесс иногда называют систематизацией или сепарацией документов. Когда в систему загружался документ, от системы распознавания требовалось определить его тип.
Стадия четвёртая: Распознавание неструктурированных документов
Организации, в которых рождается много документов различного типа, нуждаются в автоматизированной системе распознавания, способной полностью систематизировать и атрибутировать документы. Системы данного класса способны в значительной мере сократить затраты компании на ручную обработку документов.
Стадия пятая: Комплекты и верификация
Одним из важных элементов распознавания является возможность определения комплекта документа, объединенных одной логической связью. Данная функция в системах распознавания позволяет не только определять комплект, но и выявлять неполные комплекты документов, тем самым позволяя определять те, которые были оформлены неправильно. Помимо прочего задачи по верификация распознанных данных и перекрёстные проверки документов между собой также могут быть решены при помощи систем автоматического распознавания.
Оффтоп — мы запустили спецпроект! Telegram-канал «Бумажный мир» — экспертный канал о работе с документами и архивной отрасли! Актуальные новости, законодательство, инструкции и инструменты! Подписывайтесь.
Стадия шестая: Справочники
Особенностью любой системы распознавания является то, что распознанные данные могут содержать ошибки, опечатки и другие неточности, которые зачастую не позволяют опираться на них в случае дальнейших действий с документом. Например, если название контрагента из документа распозналось в ошибкой или не так, как ожидал пользователь, то такой результат нельзя назвать приемлемым. И в данной ситуации на помощь приходят справочники и умение систем распознавания работать с ними.
Стадия седьмая: Единый информационный ландшафт
Наиболее полным и безусловно эффективным является процесс распознавания, в результате которого каждый распознанный документ формирует новую электронную карточку или привязывается к действующей карточке той информационной системы, которая используется в организации.
В случае если у вас уже налажен учёт документов в электронном виде, но при этом требуется объединить информацию из бумажного документа с электронной карточкой (начиная от проверки и наполнения атрибутов, заканчивая проверкой содержимого, комплектности или наличия оригинала), то данные задачи могут быть решены с помощью использования систем распознавания документов.
В случае если учёта документов нет и требуется на основании массива бумажных документов сформировать информационный набор электронных карточек документов, то и данная задача на сегодняшний день под силу современным системам распознавания (OCR).
В заключении нам хотелось бы отметиться, что под распространённым понятием «распознавания документов» сегодня можно понимать множество различных процессов и действий, который направленны на получение в автоматическом режиме информации с бумажных документов.
При построении процесса распознавания важно учитывать то, что не нужно распознавать данные из документов, если информация об этих документах уже есть в какой-либо действующей системе. Процесс нужно строить так, чтобы максимально опираться на имеющиеся в наличии данные и связывать, посредством распознавания, документы с этими наборами данных.
Главное предназначение систем распознавания — это автоматизация процесса обработки документов, который еще недавно мог осуществляться исключительно вручную, тем самым нес за собой существенные затраты на своё поддержание. А наш опыт показал, что можно обрабатывать миллионы документов силами всего нескольких специалистов и что процессы распознавания способны в десятки раз сократить затраты, необходимые на регистрацию и различные проверки документов.
Материал подготовлен партнёром «Делис Архив», Иваном Денисовым, ООО «Делис Инфо»
От редакции: Делис Инфо — российская ИТ-компания — эксперт в области повышения эффективности бизнес-процессов, связанных со сбором, использованием, учетом, хранением и обслуживанием документов.
Источник: vc.ru
Возможности систем распознавания текстов кратко
Любая сканированная информации представляет собой графический файл (картинку). Следовательно, отсканированный текст невозможно редактировать без специального перевода в текстовый формат. Этот перевод можно осуществить с помощью систем оптического распознавания символов (optical character recognition – OCR).
Для получения электронной (готовой к редактированию) копии печатного документа, программе OCR необходимо выполнить ряд операций, среди которых можно выделить следующие:
2. Распознавание – текст переводится из графической формы в обычную текстовую.
4. Сохранение – запись распознанного документа в файл нужного формата для дальнейшего редактирования в соответствующей программе.
Перечисленные выше операции в большинстве OCR-систем могут выполняться как в автоматическом (с помощью программы-мастера), так и в ручном режиме (по отдельности).
Современные OCR-системы распознают тексты, набранные различными шрифтами; корректно работают с текстами, содержащими слова на нескольких языках; распознают таблицы и рисунки; позволяют сохранять результат в файле текстового или табличного формата и др.
В качестве примера OCR-систем можно привести CuneiForm от фирмы Cognitive и FineReader от ABBYY Software.
OCR-системаFineReader выпускается в различных версиях (Sprint, Home Edition, Professional Edition, Corporate Edition, Office) и все они, от самой простой до самой мощной имеют очень удобный интерфейс, а также (в зависимости от модификации) имеют ряд достоинств, которые выделяют их среди аналогичных программ.
Например, FineReader Professional Edition (FineReader Pro) обладает следующими функциональными возможностями:
§ поддерживает почти двести языков (даже древние языки и популярные языки программирования);
§ распознает графику, таблицы, документы на бланках и т.п.;
§ полностью сохраняет все особенности форматирования документов и их графическое оформление;
§ позволяет сохранить полученный текст в одном из множества популярных форматах (от документов Microsoft Office до HTML или PDF);
Любая сканированная информации представляет собой графический файл (картинку). Следовательно, отсканированный текст невозможно редактировать без специального перевода в текстовый формат. Этот перевод можно осуществить с помощью систем оптического распознавания символов (optical character recognition – OCR).
Для получения электронной (готовой к редактированию) копии печатного документа, программе OCR необходимо выполнить ряд операций, среди которых можно выделить следующие:
2. Распознавание – текст переводится из графической формы в обычную текстовую.
4. Сохранение – запись распознанного документа в файл нужного формата для дальнейшего редактирования в соответствующей программе.
Перечисленные выше операции в большинстве OCR-систем могут выполняться как в автоматическом (с помощью программы-мастера), так и в ручном режиме (по отдельности).
Современные OCR-системы распознают тексты, набранные различными шрифтами; корректно работают с текстами, содержащими слова на нескольких языках; распознают таблицы и рисунки; позволяют сохранять результат в файле текстового или табличного формата и др.

В качестве примера OCR-систем можно привести CuneiForm от фирмы Cognitive и FineReader от ABBYY Software.
OCR-системаFineReader выпускается в различных версиях (Sprint, Home Edition, Professional Edition, Corporate Edition, Office) и все они, от самой простой до самой мощной имеют очень удобный интерфейс, а также (в зависимости от модификации) имеют ряд достоинств, которые выделяют их среди аналогичных программ.
Например, FineReader Professional Edition (FineReader Pro) обладает следующими функциональными возможностями:
§ поддерживает почти двести языков (даже древние языки и популярные языки программирования);
§ распознает графику, таблицы, документы на бланках и т.п.;
§ полностью сохраняет все особенности форматирования документов и их графическое оформление;
§ позволяет сохранить полученный текст в одном из множества популярных форматах (от документов Microsoft Office до HTML или PDF);

Файл содержит методические указания для выполнения практической работы «Возможности систем распознавания текста». Используется при узучении темы «Способы создания текстовых документов». Этапы работы: сканирование документа, передача документа по локальной сети, работа в программе Fine Reader, форматирование документа в среде MS Word.
Тема: Возможности систем распознавания текстов.
Цель. Изучить возможности и порядок работы с программой распознавания текста Fine Reader.
Оборудование: ЛВС, персональный компьютер, среда MS Word, программа FineReader.
Краткая теория
Процесс ввода текстов в компьютер осуществляется в несколько этапов: сканирование; выделение блоков на изображении; распознавание; проверка ошибок; сохранение результата распознавания (передача его в другое приложение, в буфер и т. п.).
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (или с многостраничными документами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
Fine Reader работает с разными моделями сканеров. В частности, Программа поддерживает стандарт TWAIN.
Порядок выполнения работы
По локальной сети откройте эту папку на вашем компьютере. Скопируйте свой документ в свою папку.
Запустите программу FineReader (Пуск – Программы )
В окне FineReader выполните команду Файл – Открыть изображение, найдите свой документ и откройте его в окне программы FineReader.
Выберите язык для распознавания документа.
Выполните распознавание графического файла, сегментируйте текстовые блоки, таблицы и рисунки.
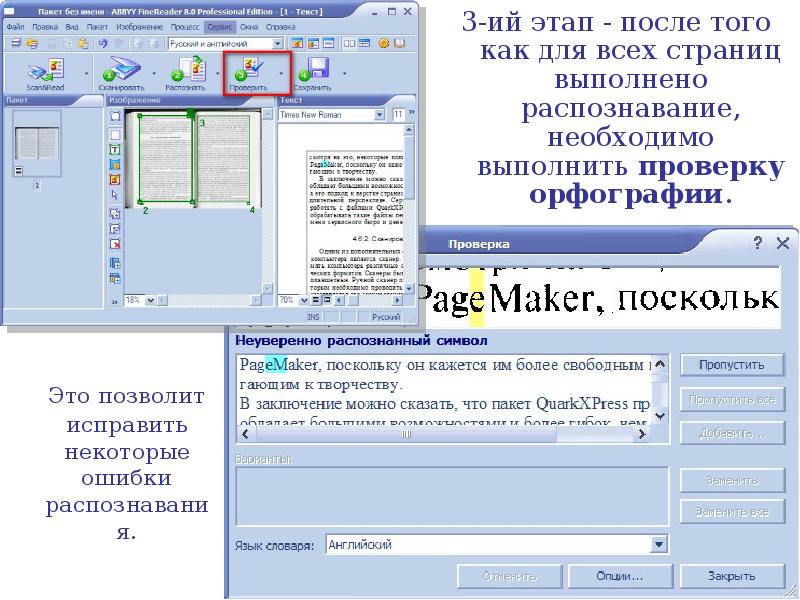
Выполните проверку отсканированного документа. Ошибки исправляйте в окне Текст или в диалоговом окне Проверка.
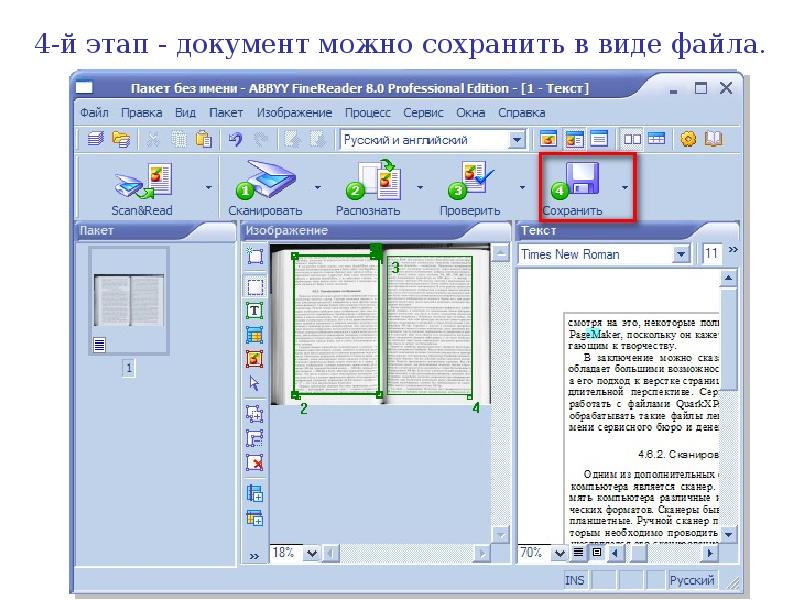
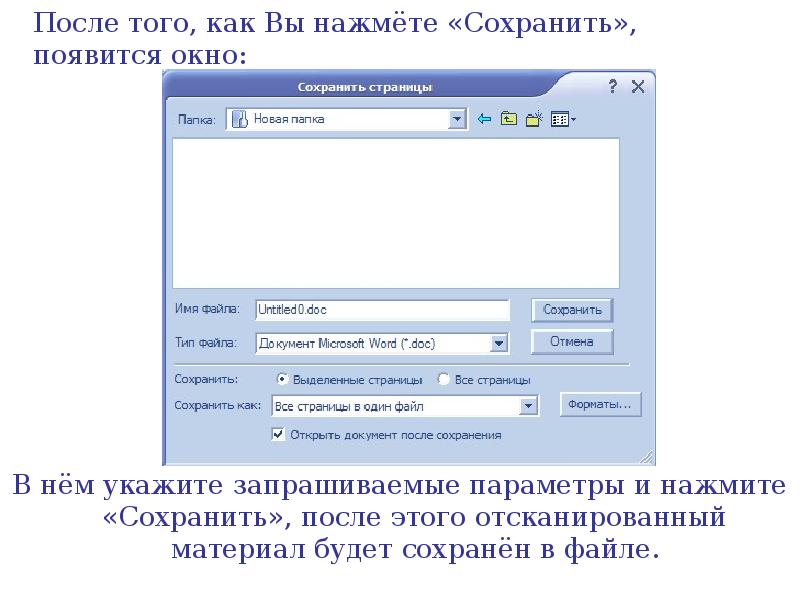
Сохраните отсканированный документ в формате Word .
Задайте параметры страниц документа (вкладка Разметка страницы – группа Параметры страницы): ориентация альбомная, левое поле 1,5 см, правое 1,5 см, верхнее 3см, нижнее 2 см., расстановка переносов Автоматическая. Параметры абзацев: выравнивание по ширине, отступ первой строки 1,5см, интервал перед абзацем 6пт, интервал между строчками 1,15. Для картинки используйте команду Обтекание текстом – по контуру.
В верхний колонтитул запишите дату и номер работы. В нижний колонтитул запишите виши фамилию, имя и группу. В готовый документ запишите тему и цель работы.
Выведите готовый документ на печать.
Контрольные вопросы
Перечислите основные элементы окна программы Fine Reader.
Дайте понятие сегментации изображения.
Как выполняется настройка операций, выполняемых программой Fine Reader?
Вы можете изучить и скачать доклад-презентацию на тему Возможности систем распознавания текстов. Презентация на заданную тему содержит 20 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас — поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!















Возможности систем распознавания текстов Задание: письменно ответить на вопросы (последний слайд), фото прислать.
Одним из средств ввода информации в память компьютера является сканер. Одним из средств ввода информации в память компьютера является сканер. Сканеры позволяют вводить в память компьютера различные изображения в виде файлов графических форматов. Обычно при сканировании получают файл форматов JPEG, TIFF, PCX, BMP и др.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Оно регулируется установкой основных параметров сканирования: Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Оно регулируется установкой основных параметров сканирования: типа изображения, разрешения, яркости.
С помощью сканера можно получить изображение страницы текста в графическом файле. Но работать с таким текстом невозможно: страница с текстом представляет собой обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать.
Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать картинку в символы. С помощью сканера можно получить изображение страницы текста в графическом файле. Но работать с таким текстом невозможно: страница с текстом представляет собой обычную картинку.
Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать картинку в символы. Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR). Наиболее распространенная из них — ABBYY FineReader.
Возможности современных OCR Возможности современных OCR распознавание текста, набранного любым шрифтом, работа с текстами, содержащими слова на нескольких языках, распознавание таблиц, распознавание нечётко набранных текстов, например, текст с пожелтевшей газетной вырезки. сохранять результат в файл, например, Microsoft Word, Excel и т.д.
Одним из козырей FineReader является поддержка неимоверного количества языков распознавания — 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования. Одним из козырей FineReader является поддержка неимоверного количества языков распознавания — 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования. Но далеко не все возможности включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений — для всего этого стоит приобрести профессиональную версию программы.
FineReader работает со сканерами через FineReader работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт, введенный в 1992 году для унификации взаимодействия устройств для ввода изображений в компьютер (например, сканера) с внешними приложениями.
Для распознавания печатных текстов в большинстве случаев достаточно сканировать в чёрно-белом режиме и с разрешением 300 dpi. Для распознавания печатных текстов в большинстве случаев достаточно сканировать в чёрно-белом режиме и с разрешением 300 dpi. Если текст слишком мелкий и при распознавании программа допускает много ошибок, попробуйте увеличить разрешение при сканировании. Помните: при увеличении разрешения время сканирования значительно увеличивается, поэтому без необходимости не сканируйте тексты с разрешением более 300 dpi.
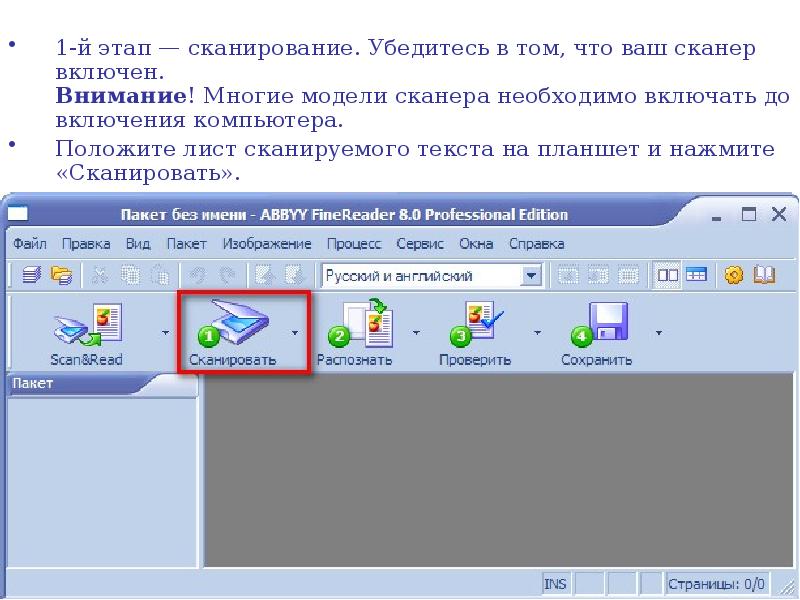
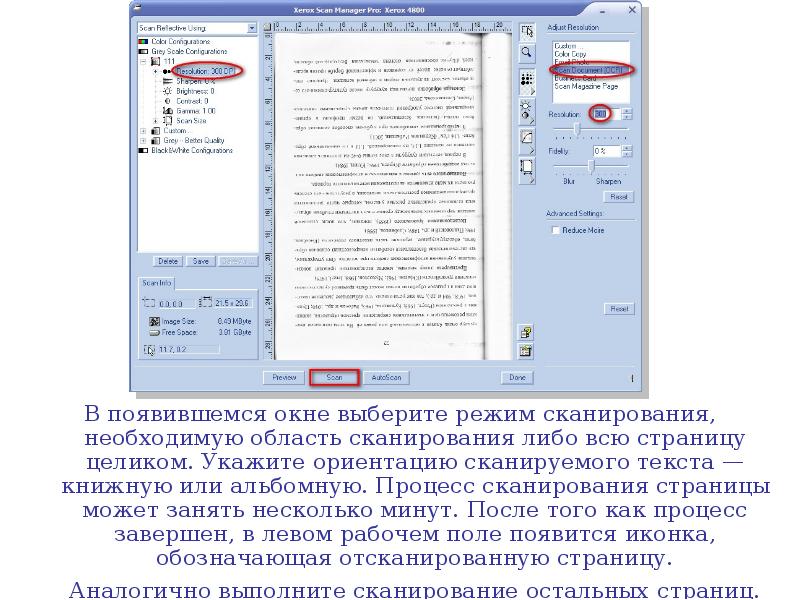
В появившемся окне выберите режим сканирования, необходимую область сканирования либо всю страницу целиком. Укажите ориентацию сканируемого текста — книжную или альбомную. Процесс сканирования страницы может занять несколько минут. После того как процесс завершен, в левом рабочем поле появится иконка, обозначающая отсканированную страницу.
В появившемся окне выберите режим сканирования, необходимую область сканирования либо всю страницу целиком. Укажите ориентацию сканируемого текста — книжную или альбомную. Процесс сканирования страницы может занять несколько минут. После того как процесс завершен, в левом рабочем поле появится иконка, обозначающая отсканированную страницу. Аналогично выполните сканирование остальных страниц.
2-й этап — распознавание. Выберите на левом поле страницу, с которой вы будете работать, при этом справа высветится ее отсканированное изображение. Выберите язык распознаваемого текста: русский, русско-английский, английский. Затем необходимо выполнить разбивку текста на блоки. Разбивка может осуществляться автоматически, с помощью встроенной процедуры, либо вручную.
Ручная разбивка может потребоваться, если структура текста на странице достаточно сложна — в текст врезаны таблицы, диаграммы, рисунки. После разбивки текста можно приступать собственно к распознаванию. Распознавание производится по блокам и в зависимости от мощности компьютера может занимать от нескольких секунд до нескольких минут.
На Рабочем поле уже распознанные страницы отображаются в правой части окна. 2-й этап — распознавание. Выберите на левом поле страницу, с которой вы будете работать, при этом справа высветится ее отсканированное изображение. Выберите язык распознаваемого текста: русский, русско-английский, английский. Затем необходимо выполнить разбивку текста на блоки.
Разбивка может осуществляться автоматически, с помощью встроенной процедуры, либо вручную. Ручная разбивка может потребоваться, если структура текста на странице достаточно сложна — в текст врезаны таблицы, диаграммы, рисунки. После разбивки текста можно приступать собственно к распознаванию. Распознавание производится по блокам и в зависимости от мощности компьютера может занимать от нескольких секунд до нескольких минут. На Рабочем поле уже распознанные страницы отображаются в правой части окна.

Пармон Анна Сергеевна Ответственный редактор
Решения с OCR пригодятся не только крупным организациям, но и небольшим компаниям: когда в штате немного людей, каждый из них выполняет сразу несколько задач. Поэтому еще важнее снизить времязатраты на работу с документами как внутри компании, так и вовне: с клиентами, партнерами и поставщиками услуг.
- Национальное воспитание учащихся старших классов общеобразовательной средней школы
- Психологическая готовность ребенка к школе в доу
- Порядок определения радиоактивного заражения местности кратко
- Особенности формирования и бытования этнокультурных стереотипов кратко
- Рисунок в детский сад на тему пдд светофор
Источник: obrazovanie-gid.ru
Программы OCR: распознавание текста, списки, разработчики, вес программы, выполняемые функции, характеристики, специфические особенности работы и отзывы пользователей


Бумага как основной носитель информации, постепенно утрачивает свое значение. Вместо бумажных документов используют их электронный вариант, если это возможно. Но как перевести в электронный вид имеющиеся архивы? Для решения этой задачи были созданы специальные программы для распознавания текста.
Что такое OCR-программы и как они работают

Эти программные продукты, использующие технологию ORC (Optical character recognition) или ICR (Intelligence character recognition). На русский язык эти аббревиатуры переводятся как «оптическое» или «интеллектуальное распознавание символов».
Программы, использующие OCR, работают следующим образом. Фотография с текстом, полученная от сканера, разбивается на множество фрагментов. Для каждого из них приложение создает несколько предположений. Проверяя их и сравнивая с эталонами, каждому фрагменту дает оценку, соответствующую степени совпадения. Выбирая наибольшую из них, программа «видит» символ и выводит его в поле встроенного текстового редактора.
В данной статье приведено краткое описание нескольких программ для сканирования. Они помогут.
IRC работает по тому же принципу, но для обработки символов используются искусственные нейронные сети. Главное преимущество этого способа – компактность программ и непрерывное обучение. Это позволяет эффективно распознавать слова, написанные человеком рукописными буквами. Но эта технология не способна «прочесть» сплошной рукописный текст.
Для каждой из существующих операционных систем разработаны собственные OCR-программы. Наиболее популярными для работы в ОС Windows являются:
- ABBYY FineReader;
- OmniPage;
- Readiris;
- Samsung Scan OCR Program;
Кроме программ для ПК доступно много онлайн-сервисов по распознаванию текста. Среди них наиболее известны FineReader Online, OnlineOCR, FreeOCR.
Если вам нужно сделать электронную книгу или оформить в виде одного документа отсканированный.
ABBYY FineReader 14

Этот программный продукт разработан отечественной компанией ABBYY, является одной из лучших среди программ, использующих OCR. Основу программы составляет оригинальный движок под названием Finereader Engine. Он предоставляет следующие возможности:
- Быстрое распознавание печатного текста с точностью выше 98 %. Невосприимчивость к качеству исходного изображения. Это позволяет одинаково распознавать текст на фотографиях, полученных при помощи сканера или фотоаппарата.
- Технология ADRT позволяет распознавать не только текст, но и его форматирование: шрифт, отступы, абзацы, колонки.
- Возможность многопоточной обработки изображения. Это позволяет задействовать все ядра процессора (максимум 4) для ускорения процесса распознавания.
- Поддержка более 190 языков, включая те, которые используют алфавит, отличный от латиницы или кириллицы (японский, китайский, арабский).
- Встроенный текстовый редактор позволяет проверить результат распознавания или отредактировать его.
- Взаимодействие с пакетом Office. Оно позволяет экспортировать распознанный текст в Microsoft Word и Exel для дальнейшей обработки.
- Возможность обучения программы. Эта функция позволяет обучить программу «читать» специфические начертания букв. Например, нестандартный шрифт или печатные буквы, написанные рукой.
- Работа с PDF. FineReader позволяет распознавать текст из этого типа файлов и «сшивать» несколько отсканированных изображений в PDF или PDF/A.

Главный недостаток этой программы – цена. Бессрочная лицензия для базовой версии обойдется в 7 тысяч рублей. Версии «Бизнес» и «Энтерпрайз» – в 12 и 39 тысяч рублей, соответственно. Если же предполагается использовать программу только дома, то можно скачать с торрент-трекера взломанную 11-ю или 12-ю версию продукта.
- Процессор: 32- или 64-битный, с тактовой частотой более 1 ГГц и поддержкой набора инструкций SSE 2. (Intel Celeron M и лучше, AMD Athlon 64 и лучше).
- Оперативная память: 1 ГБ. Если процессор имеет более 1 ядра, то для каждого дополнительно требуется 512 МБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800.
- Жесткий диск: 3 ГБ – для установки и работы.
- Сканер: поддерживающий драйверы TWAIN и WIA.
- ОС: Windows 7,8,8.1,10.
Мнение пользователей о FineReader 14
Они отзываются о FineReader положительно, выделяя среди достоинств способность продукта распознавать текст с плохих бумажных оригиналов, удобный и простой интерфейс и высокую скорость обработки изображений.
Среди проблем, возникающих при использовании этой OCR-программы, некоторые юзеры отмечают некорректно работающий менеджер изображений. Например: неадекватная работа регулировки яркости отсканированного изображения.
OmniPage 18

Основной конкурент FineReader на российском рынке ORC-программ. По функционалу она очень похожа на оппонента, но имеет несколько отличий:
- Возможность запуска процесса сканирования и распознавания при помощи кнопок сканера.
- Поддержка 4-ядерных процессоров. Это позволяет уменьшить время распознавания и преобразовывать несколько изображений одновременно.
- Создание собственной электронной библиотеки для букридера (электронной книги) Kindle.
- Автоматическое определение распознаваемого языка.

Среди недостатков программы можно отметить низкую скорость работы, сравнимую с 10-й версией FineReader, и цену за лицензионную копию – 150 долларов.
- Процессор: x32- или x64-битный, с тактовой частотой более 1 ГГц, Intel Pentium и лучше, AMD Athlon и лучше.
- Оперативная память: 512 МБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800 и глубину цвета 16 бит.
- Жесткий диск: 1,1 ГБ для установки всех компонентов и 100 МБ для работы.
- Сканер: поддерживающий драйверы TWAIN,WIA и ISIS.
- ОС: Windows XP SP3,Vista SP2 x32/x64, 7,8.
Мнение пользователей об OmniPage
Отзываются они о ней резко негативно, т.к. проблемы есть во всех частях программы, начиная от красивого, но непонятного интерфейса, и заканчивая плохой справочной информацией. Продукт не адаптирован к работе в WinXP. Его можно заставить работать, но придется потратить какое-то время.
OmniPage имеет проблемы с распознаванием. Например: он легко распознает простой черный текст на листе бумаги с рисунками или таблицами, полученный со сканера. При использовании изображений с фотоаппарата или мобильного телефона точность распознавания падает до 70 %, а это очень неудобно при обработке больших документов.
Также 18-я версия может не запуститься из-за ошибок в коде. Для устранения этой проблемы нужно установить патч 18.01.
Read Iris Pro 17

Read Iris — это OCR-программа, что за меньшие деньги (8000 против 12 000) способна сравниться по функционалу и производительности с FineReader. Профессиональная версия обладает следующими возможностями:
- Полноценная работа с PDF: распознавание, создание файлов для баз данных, сжатие и озвучивание текста.
- Поддержка 140 языков.
- Распознавание бумажных таблиц и текстов с возможностью экспорта в Exel и Word.
- Получение изображений с любой модели сканера.

Также существует корпоративная версия, позволяющая защищать PDF-файлы водяными знаками и работать с документами объемом более 50 страниц.
- Процессор: x86 или x64, с тактовой частотой 1 ГГц или выше.
- Оперативная память: 1 ГБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800.
- Жесткий диск:400 МБ для установки.
- Сканер: поддерживающий драйверы TWAIN,WIA.
- ОС: Windows 7,8,10 x32/x64.
Мнение пользователей о ReadIris
Они отзываются об этой OCR-программе распознавания текста как о хорошем и быстром PDF to Word конвертере с рядом проблем:
- Сложный интерфейс, в котором новичку нелегко разобраться.
- Автоматическое пересканирование документа при изменении области сканирования.
- Плохая техническая поддержка.
- Иногда программа не активируется из-за ошибок в коде программы.
Samsung Scan OCR Program – что это за программа
Это бесплатное программное обеспечение, входящее в комплектацию многофункциональных устройств «3 в 1» (принтер, сканер, копир) от компании «Самсунг». Оно разработано в сотрудничестве с компанией Iris, создавшей ReadIris Pro, и оптимизировано для работы с МФУ этого производителя. От оригинального «Ридирис» Samsung Scan ORC отличается интерфейсом, урезанным функционалом и размерами – на жестком диске она занимает 40 МБ.
Онлайн-сервисы
Они являются альтернативой ресурсоемким стационарным программам для распознавания текста. Например, OCR программе FineReader. Свойства систем подобных проектов позволяют распознавать текст с изображений намного быстрее, чем на автономном ПК. Среди сервисов, занимающихся извлечением текста из фотографий, можно выделить 3 наиболее удобных: FineReaderOnline, FreeOCR, OnlineOCR.

Первый является прямым развитием стационарной версии продукта. При регистрации новому пользователю дается 10 бесплатных страниц для обработки и 5 каждый месяц. Снять это ограничение можно, купив годовую подписку за 3200, 5500, 17800 рублей за 2000, 5000 и 10000 страниц соответственно. Если у пользователя есть лицензия для FineReader 14, то ему достаточно зарегистрироваться и активировать ее для использования в онлайн-версии. В этом случае он получит количество страниц, соответствующее типу приобретенной лицензии: «Стандарт» (2000), «Бизнес» (5000) или «Энтерпрайз» (10000).


Если страниц недостаточно, то их можно приобрести в количестве 50-50 000 штук.

Проект FreeOCR.com отличается от предыдущего своей полной бесплатностью и отсутствием ограничений на количество обрабатываемых страниц. OCR-движок этого сайта поддерживает русский, украинский, турецкий, вьетнамский и все европейские языки – всего 29. Единственным недостатком этого портала является работа только с графическими изображениями, загружаемых последовательно, так как очередь обработки не предусмотрена создателями. Выводится распознанная информация без какого-либо форматирования в формате TXT.
Мнение пользователей об онлайн-OCR-сервисах
Эти сайты необходимы в тех случаях, когда загрузка и установка полноценной ORC-программы нецелесообразна. Например, для вставки в реферат нескольких объемных цитат из книги или журнала. Среди недостатков таких сайтов выделяют условную бесплатность (FineReader) и слабый функционал (FreeOCR,OnlineOCR).
Подводя итог, можно сказать, что OCR-программ распознавания текста с изображением или PDF-файлов создано немало, а в статье приведены лишь самые известные. Поэтому OCR-программу для сканера каждый пользователь сможет себе подобрать в соответствии с требованиями и бюджетом. Либо воспользоваться одним из множества бесплатных OCR-сервисов.
Источник: autogear.ru