
NoSQL – это подход к реализации масштабируемого хранилища (базы) информации с гибкой моделью данных, отличающийся от классических реляционных СУБД. В нереляционных базах проблемы масштабируемости (scalability) и доступности (availability), важные для Big Data, решаются за счёт атомарности (atomicity) и согласованности данных (consistency) [1].
Зачем нужны нереляционные базы данных в Big Data: история появления и развития
NoSQL-базы оптимизированы для приложений, которые должны быстро, с низкой временной задержкой (low latency) обрабатывать большой объем данных с разной структурой [2]. Таким образом, нереляционные хранилища непосредственно ориентированы на Big Data. Однако, идея баз данных такого типа зародилась гораздо раньше термина «большие данные», еще в 80-е годы прошлого века, во времена первых компьютеров (мэйнфреймов) и использовалась для иерархических служб каталогов. Современное понимание NoSQL-СУБД возникло в начале 2000-х годов, в рамках создания параллельных распределённых систем для высокомасштабируемых интернет-приложений, таких как онлайн-поисковики [1].
Что такое СУБД
Вообще термин NoSQL обозначает «не только SQL» (Not Only SQL), характеризуя ответвление от традиционного подхода к проектированию баз данных. Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII-файлы, а вместо SQL-запросов доступа к данным использовала шелловские скрипты [3].
В начале 2000-х годов Google построил свою поисковую систему и приложения (GMail, Maps, Earth и прочие сервисы), решив проблемы масштабируемости и параллельной обработки больших объёмов данных. Так была создана распределённые файловая и координирующая системы, а также колоночное хранилище (column family store), основанное на вычислительной модели MapReduce.
После того, как корпорация Google опубликовала описание этих технологий, они стали очень популярны у разработчиков открытого программного обеспечения. В результате этого был создан Apache Hadoop и запущены основные связанные с ним проекты. Например, в 2007 году другой ИТ-гигант, Amazon.com, опубликовав статьи о своей высокодоступной базе данных Amazon DynamoDB. Далее в эту гонку NoSQL- технологий для управления большими данными включилось множество корпораций: IBM, Facebook, Netflix, eBay, Hulu, Yahoo! и другие ИТ-компаний со своими проприетарными и открытыми решениями [1].

Какие бывают NoSQL-СУБД: основные типы нереляционных баз данных
Все NoSQL решения принято делить на 4 типа:
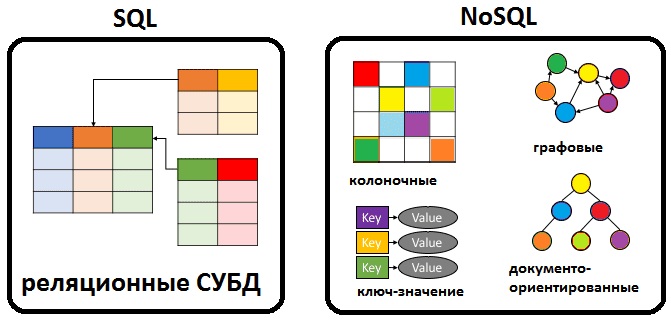
- Ключ-значение (Key-value) – наиболее простой вариант хранилища данных, использующий ключ для доступа к значению в рамках большой хэш-таблицы [4]. Такие СУБД применяются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в масштабируемых Big Data системах, включая игровые и рекламные приложения, а также проекты интернета вещей (Internet of Things, IoT), в т.ч. индустриального (Industrial IoT, IIoT). Наиболее известными представителями нереляционных СУБД типа key-value считаются Oracle NoSQL Database, Berkeley DB, MemcacheDB, Redis, Riak, Amazon DynamoDB, которые поддерживают высокую разделяемость, обеспечивая беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД [2].
- Документно-ориентированное хранилище, в котором данные, представленные парами ключ-значение, сжимаются в виде полуструктурированного документа из тегированных элементов, подобно JSON, XML, BSON и другим подобным форматам [4]. Такая модель хорошо подходит для каталогов, пользовательские профилей и систем управления контентом, где каждый документ уникален и изменяется со временем [2]. Поэтому чаще всего документные NoSQL-СУБД используются в CMS-системах, издательском деле и документальном поиске. Самые яркие примеры документно-ориентированных нереляционных баз данных – это CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML [1].
- Колоночное хранилище, которое хранит информацию в виде разреженной матрицы, строки и столбцы которой используются как ключи. В мире Big Data к колоночным хранилищам относятся базы типа «семейство столбцов» (Column Family). В таких системах сами значения хранятся в столбцах (колонках), представленных в отдельных файлах. Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных [4]. Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable [1].
- Графовое хранилище представляют собой сетевую базу, которая использует узлы и рёбра для отображения и хранения данных [4]. Поскольку рёбра графа являются хранимыми, его обход не требует дополнительных вычислений (как соединение в SQL). При этом для нахождения начальной вершины обхода необходимы индексы. Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.) [1]. Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии [3]. Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB. О том, как проанализировать граф в Neo4j средствами языка запросов Cypher, читайте в нашей отдельной статье.
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы [1];
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в. т.ч. полнотекстовый поиск по базе [2];
- возможность работать с разными представлениями информации, в т.ч. без задания схемы данных [1];
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения [5].
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа [2];
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений [2].
Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов [5]. Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всехACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) [1]. Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции [1]. Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай [5];
- недостаток специалистов поNoSQL-базам по сравнению с реляционными аналогами [5].
Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема.
Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь. А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS.
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/
Источник: bigdataschool.ru
Системы управления базами данных

В этом подразделе приводится классификация СУБД, и рассматриваются основные их функции. В качестве основных классификационных признаков можно использовать следующие: вид программы, характер использования, модель данных. Названные признаки существенно влияют на целевой выбор СУБД и эффективность использования разрабатываемой информационной системы.
Классификация СУБД. В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД. Рассмотрим какие из имеющихся на рынке программ имеют отношение к БД и в какой мере они связаны с базами данных.
К СУБД относятся следующие основные виды программ:

полнофункциональные СУБД;
серверы БД;
клиенты БД;
средства разработки программ работы с БД.
Полнофункциональные СУБД (ПФСУБД) представляют собой традиционные СУБД, которые сначала появились для больших машин, затем для мини-машин и для ПЭВМ. Из числа всех СУБД современные ПФСУБД являются наиболее многочисленными и мощными по своим возможностям. К ПФСУБД относятся, например, такие пакеты как: Clarion Database Developer, DataBase, Dataplex, dBase IV, Microsoft Access, Microsoft FoxPro и Paradox R: BASE.
Обычно ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. п. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE (Query By Example — формулировки запросов по образцу, см. подраздел 3.8). Многие ПФСУБД включают средства программирования для профессиональных разработчиков.
Некоторые системы имеют в качестве вспомогательных и дополнительные средства проектирования схем БД или CASE-подсистемы. Для обеспечения доступа к другим БД или к данным SQL-серверов полнофункциональные СУБД имеют факультативные модули.
Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Эта группа БД в настоящее время менее многочисленна, но их количество постепенно растет. Серверы БД реализуют функции управления базами данных, запрашиваемые другими (клиентскими) программами обычно с помощью операторов SQL. Примерами серверов БД являются следующие программы: NetWare SQL (Novell), MS SQL Server (Microsoft), InterBase (Borland), SQLBase Server (Gupta), Intelligent Database (Ingress).
В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. При этом элементы пары клиент — сервер могут принадлежать одному или разным производителям программного обеспечения.
В случае, когда клиентская и серверная части выполнены одной фирмой, естественно ожидать, что распределение функций между ними выполнено рационально. В остальных случаях обычно преследуется цель обеспечения доступа к данным любой ценой. Примером такого соединения является случай, когда одна из полнофункциональных СУБД играет роль сервера, а вторая СУБД (другого производителя) — роль клиента. Так, для сервера БД SQL Server (Microsoft) в роли клиентских (фронтальных) программ могут выступать многие СУБД, такие как: dBASE IV, Biyth Software, Paradox, DataEase, Focus, 1-2-3, MDBS III, Revelation и другие.
Средства разработки программ работы с БД могут использоваться для создания разновидностей следующих программ:
клиентских программ;
серверов БД и их отдельных компонентов;
пользовательских приложений.
Программы первого и второго вида довольно малочисленны, так как предназначены, главным образом, для системных программистов. Пакетов третьего вида гораздо больше, но меньше, чем полнофункциональных СУБД.
К средствам разработки пользовательских приложений относятся системы программирования, например Clipper, разнообразные библиотеки программ для различных языков программирования, а также пакеты автоматизации разработок (в том числе систем типа клиент-сервер). В числе наиболее распространенных можно назвать следующие инструментальные системы: Delphi и Power Builder (Borland), Visual Basic (Microsoft), SILVERRUN (Computer Advisers Inc.), S-Designor (SDP и Powersoft) и ERwin (LogicWorks).
Кроме перечисленных средств, для управления данными и организации обслуживания БД используются различные дополнительные средства, к примеру, мониторы транзакций (см. подраздел 4.2).
По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУ БД обычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД, например, относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др.
Многопользовательские СУБД включают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix.
По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.
С точки зрения пользователя, СУБД реализует функции хранения, изменения (пополнения, редактирования и удаления) и обработки информации, а также разработки и получения различных выходных документов.
Для работы с хранящейся в базе данных информацией СУБД предоставляет программам и пользователям следующие два типа языков:
язык описания данных — высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных;
язык манипулирования данными — совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам.
Названные языки в различных СУБД могут иметь отличия. Наибольшее распространение получили два стандартизованных языка: QBE (Query By Example) — язык запросов по образцу и SQL (Structured Query Language) — структурированный язык запросов. QBE в основном обладает свойствами языка манипулирования данными, SQL сочетает в себе свойства языков обоих типов — описания и манипулирования данными.
Перечисленные выше функции СУБД, в свою очередь, используют следующие основные функции более низкого уровня, которые назовем низкоуровневыми:
управление данными во внешней памяти;
управление буферами оперативной памяти;
управление транзакциями;
ведение журнала изменений в БД;
обеспечение целостности и безопасности БД.
Дадим краткую характеристику необходимости и особенностям реализации перечисленных функций в современных СУБД.
Реализация функции управления данными во внешней памяти в разных системах может различаться и на уровне управления ресурсами (используя файловые системы ОС или непосредственное управление устройствами ПЭВМ), и по логике самих алгоритмов управления данными. В основном методы и алгоритмы управления данными являются внутренним делом СУБД и прямого отношения к пользователю не имеют. Качество реализации этой функции наиболее сильно влияет на эффективность работы специфических ИС, например, с огромными БД, со сложными запросами, большим объемом обработки данных.
Необходимость буферизации данных и как следствие реализации функции управления буферами оперативной памяти обусловлено тем, что объем оперативной памяти меньше объема внешней памяти.
Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу после обработки.
Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программ- / ном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется.
Говорят, что транзакции присущи три основных свойства:
атомарность (выполняются все входящие в транзакцию операции или ни одна);
сериализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);
долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции).
Примером транзакции является операция перевода денег с одного счета на другой в банковской системе. Здесь необходим, по крайней мере, двухшаговый процесс. Сначала снимают деньги с одного счета, затем добавляют их к другому счету. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс между счетами.
Контроль транзакций важен в однопользовательских и в многопользовательских СУБД, где транзакции могут быть запущены параллельно. В последнем случае говорят о сериализуемости транзакций. Под сериализацией параллельно выполняемых транзакций понимается составление такого плана их выполнения (сериального плана), при котором суммарный эффект реализации транзакций эквивалентен эффекту их последовательного выполнения.
При параллельном выполнении смеси транзакций возможно возникновение конфликтов (блокировок), разрешение которых является функцией СУБД. При обнаружении таких случаев обычно производится откат путем отмены изменений, произведенных одной или несколькими транзакциями.
Ведение журнала изменений в БД (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении.
Журнал СУБД — это особая БД или часть основной БД, непосредственно недоступная пользователю к используемая для записи информации обо всех изменениях базы данных. В различных СУБД в журнал могут заноситься записи, соответствующие изменениям в СУБД на разных уровнях: от минимальной внутренней операции модификации страницы внешней памяти до логической операции модификации БД (например, вставки записи, удаления столбца, изменения значения в поле) и даже транзакции.
Для эффективной реализации функции ведения журнала изменений в БД необходимо обеспечить повышенную надежность хранения и поддержания в рабочем состоянии самого журнала. Иногда для этого в системе хранят несколько копий журнала.
Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно для случая использования БД в сетях. Целостность БД, есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Поддержание целостности БД включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в БД, или отсутствие повторяющихся записей в таблицах реляционных БД.
Обеспечение безопасности достигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе данных и к отдельным ее элементам (таблицам, формам, отчетам и т. д.).
Статьи к прочтению:
- Системы виртуальной реальности (свр)
- Системные и локальные шины
Что такое базы данных, СУБД и язык SQL
Похожие статьи:
- Реляционные системы управления базами данных Использование указателей было одновременно и сильной и слабой стороной иерархических и сетевых СУБД. Достоинство указателей состоит в том, что они…
- Примеры систем управления базами данных СУБД DBASE СУБД типа DBASE позволяют работать с реляционными базами данных (БД), структура которых состоит из трех элементов: • число полей БД; •…
Источник: csaa.ru
Лекция Системы управления базами данных. Классификация субд

Единственный в мире Музей Смайликов
Самая яркая достопримечательность Крыма

Скачать 39.56 Kb.
Лекция 2. Системы управления базами данных. Классификация СУБД
Классификация СУБД.
В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использовании БД. Классифицировать СУБД можно: по виду программ, по характеру использования, по способу доступа к БД, по модели данных и т.д.
Классификация по виду программ. К СУБД относятся следующие основные виды программ: полнофункциональные СУБД; серверы БД; клиенты БД.
Полнофункциональные СУБД (ПФСУБД) являются наиболее многочисленными и мощными по своим возможностям. ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. д. Многие ПФСУБД включают средства программирования. Некоторые системы имеют средства проектирования схем БД или CASE-подсистемы.
К ПФСУБД относятся: Clarion Database Developer, Data Ease, Dataplex, dBase IV, Microsoft Access, Microsoft FoxPro, Paradox R:BASE.
Серверы БД предназначены для организации центров обработки данных в сетях ЭВM. Серверы БД реализуют функции управления БД, запрашиваемые другими (клиентскими) программами обычно с помощью операторов SQL.
Примерами серверов БД являются следующие программы: NetWare SQL (Novell), MS SQL Server (Microsoft), InterBase (Borland), SQLBase Server (Gupta), Intelligent Database (Ingress).
Клиенты БД. В роли клиентских программ для серверов БД могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т.д. Элементы пары «клиент-сервер» могут принадлежать одному или разным производителям ПО. Если клиентская и серверная части выполнены одной фирмой, распределение функций между ними выполнено рационально.
Классификация по характеру использования. По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУБД обеспечивают возможность создания персональных БД и приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД относятся Visual FoxPro, Paradox, dBase, Access и др.
Многопользовательские СУБД включают в себя сервер БД и клиентскую часть, могут работать в однородной и в неоднородной вычислительной среде (с разными типами ЭВМ и ОС). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix.
Классификация по способу доступа к БД СУБД бывают: файл-серверные, клиент-серверные, встраиваемые.
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере. Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок.
Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: высокая загрузка локальной сети; затруднённость или невозможность централизованного управления и обеспечения важных характеристик (высокая надёжность, доступность и безопасность). Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД. На данный момент файл-серверная технология считается устаревшей.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно в монопольном режиме. Клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно.
Недостаток клиент-серверных СУБД: повышенные требования к серверу. Достоинства: более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения важных характеристик (высокая надёжность, доступность и безопасность).
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемая СУБД – СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Классификация по модели данных. По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.
Функции СУБД
С точки зрения пользователя, СУБД реализует функции хранения, модификации (добавления, редактирования и удаления) и обработки информации, а также разработки и получения различных выходных документов.
- управление данными во внешней памяти;
- управление буферами оперативной памяти;
- управление транзакциями;
- журнализация и восстановление БД после сбоев;
- поддержка языков БД.
Контроль доступа к данным – это возможность обеспечения только санкционированного доступа к БД, используя защиту паролем, поддержку уровней доступа к БД и к отдельным ее элементам и т.д. Каждый пользователь должен иметь возможность работы только с теми данными БД, которые доступны для него в соответствии с его пользовательскими правами. Т.о. обеспечивается безопасность в СУБД.
Управление параллельностью заключается в том, что СУБД имеют механизм, который гарантирует корректное обновление данных многими пользователями при одновременном доступе. Коллизии при совместной работе могут привести к нарушению логической целостности данных, поэтому СУБД должна предусматривать меры, не допускающие обновление дынных пользователем, пока эти данные используются кем-то еще. В описанных случаях используются, так называемые, блокировки. Существуют различные типы блокировок – табличные, страничные, строчные и т.д., которые различаются количеством заблокированных записей.
Поддержка целостности данных осуществляется для того, чтобы данные и их изменения соответствовали заданным правилам. Целостность БД – это свойство БД, которое означает, что в ней содержится непротиворечивая, полная и адекватно отражающая предметную область информация. Подержание целостности БД включает в себя проверку целостности и ее восстановление в случае обнаружения противоречий в БД. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять данные, хранимые в базе. Примеры условий: ограничение диапазонов вводимых данных, отсутствие повторяющихся записей в таблицах БД и т.д.
Управление буферами оперативной памяти заключается в поддержании СУБД собственного набора буферов оперативной памяти с собственными правилами замены буферов.
Это связано с тем, что СУБД обычно работают с БД значительного размера; чаще всего размер БД существенно больше доступного объема оперативной памяти. Если при обращении к элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью.
Общесистемной буферизации, производимой ОС, недостаточно для целей СУБД, которая располагает гораздо большей информацией о необходимости буферизации той или иной части БД. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в БД после обработки.
Управление транзакциями. Механизм транзакций используется в СУБД для поддержания логической целостности данных в базе. Транзакция – это некоторая неделимая последовательность операций над данными БД, которую СУБД рассматривает как единое целое и отслеживает от начала до завершения.
Если транзакция успешно выполняется, то СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти. Если все изменения в рамках транзакции отменяются по какой-либо причине (сбои и отказы оборудования, ошибки в ПО…), то ни одно из них не отражается на состоянии БД, т.е. транзакция отменяется.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (это несколько идеализированное представление, т.к. в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег).
- атомарность (выполняются все входящие в транзакцию операции или ни одна);
- сериализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);
- долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции).
Контроль транзакций важен в однопользовательских и в многопользовательских СУБД, где транзакции могут быть запущены параллельно.
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Сериализация параллельно выполняющихся транзакций – это такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций – это план, который приводит к сериализации транзакций. Если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно.
При параллельном выполнении смеси транзакций возможно возникновение конфликтов (блокировок), разрешение которых является функцией СУБД. При обнаружении таких случаев обычно производится «откат» путем отмены изменений, произведенных одной или несколькими транзакциями. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
Функция журнализации заключается в обеспечении СУБД надежности хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. К аппаратным сбоям относятся: внезапная остановка работы ПК (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (например, по причине ошибки в программе) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной.
В любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. То есть поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал – это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда – минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода.
СУБД придерживаются стратегии «упреждающей» записи в журнал протокола WAL (Write Ahead Logging – «пиши сначала в журнал»). Она заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления – индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу).
При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Архивная копия – это полная копия БД к моменту начала заполнения журнала. Для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования.
Тогда восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
Поддержка языков БД. Для работы с БД используются специальные языки, называемые языками БД. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Выделялись два языка – язык определения схемы БД (SDL – Schema Definition Language) и язык манипулирования данными (DML – Data Manipulation Language).
SDL служил для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными (операторы ввода, удаления, модификации и выборки данных).
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с БД. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
Язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД – именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
На языковом уровне производится поддержание представлений. Специальные операторы языка SQL позволяют определять представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя.
Авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В их число входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Источник: topuch.com