
В уроке «1.3 – Знакомство с переменными в C++» мы говорили о том факте, что переменные – это имена фрагментов памяти, которые можно использовать для хранения информации. Вкратце, компьютеры имеют оперативную память (RAM), доступную для использования программами. Когда переменная определена, часть этой памяти выделяется для этой переменной.
Наименьшая единица памяти – это бит (сокращенно от «binary digit», «двоичная цифра»), которая может содержать значение 0 или 1. Вы можете представить бит как обычный выключатель света – либо свет выключен (0), либо или он включен (1). Промежуточного значения нет. Если вы посмотрите на случайный сегмент памяти, всё, что вы увидите, это …011010100101010… или подобную комбинацию.
Память организована в последовательные блоки, называемые адресами памяти (или, для краткости, просто адресами). Подобно тому, как почтовый адрес может использоваться для поиска заданного дома на улице, адрес памяти позволяет нам находить и получать доступ к содержимому памяти в определенном месте.
C++ основные типы данных
Возможно, покажется удивительным, что в современных компьютерных архитектурах каждый бит не имеет собственного уникального адреса памяти. Это связано с тем, что количество адресов памяти ограничено, а побитовый доступ к данным редко бывает необходим. Вместо этого каждый адрес памяти содержит 1 байт данных. Байт – это группа битов, которые используются как единое целое. Современный стандарт подразумевает, что байт состоит из 8 последовательных битов.
Ключевой момент
В C++ мы обычно работаем с фрагментами данных «байтового размера».
На следующем рисунке показаны несколько последовательных адресов памяти вместе с соответствующими байтами данных:
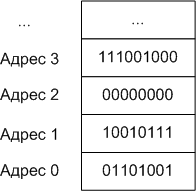
В качестве отступления.
Некоторые старые или нестандартные машины могут иметь байты другого размера (от 1 до 48 бит), однако нам обычно не нужно беспокоиться об этом, поскольку современный стандарт де-факто подразумевает, что 1 байт составляет 8 бит. В этих обучающих статьях мы предполагаем, что байт равен 8 битам.
Типы данных
Поскольку все данные на компьютере представляют собой всего лишь последовательность битов, мы используем тип данных (часто называемый для краткости «типом»), чтобы сообщить компилятору, как интерпретировать содержимое памяти тем или иным образом. Вы уже видели один пример типа данных: целочисленное значение. Когда мы объявляем переменную как целочисленное значение, мы сообщаем компилятору, что «часть памяти, которую использует эта переменная, будет интерпретироваться как целочисленное значение».
Когда вы присваиваете объекту значение, компилятор и CPU заботятся о кодировании вашего значения в соответствующую для этого типа данных последовательность битов, которые затем сохраняются в памяти (помните: память может хранить только биты). Например, если вы присваиваете целочисленному объекту значение 65 , это значение преобразуется в последовательность битов 0100 0001 и сохраняется в памяти, назначенной объекту.
Основы Программирования — #2 — Типы данных
И наоборот, когда объект вычисляется для получения значения, эта последовательность битов восстанавливается обратно в исходное значение. Это означает, что 0100 0001 конвертируется обратно в значение 65 .
К счастью, компилятор и процессор здесь делают всю тяжелую работу, поэтому вам обычно не нужно беспокоиться о том, как значения преобразуются в битовые последовательности и обратно.
Всё, что вам нужно сделать, это выбрать тип данных для вашего объекта, который лучше всего соответствует необходимому вам использованию.
Основные типы данных
C++ имеет встроенную поддержку множества различных типов данных. Они называются базовыми типами данных, но часто неофициально называются примитивными типами или встроенными типами.
Вот список основных типов данных, некоторые из которых вы уже видели:
| float double long double |
Число с плавающей запятой | Число с дробной частью | 3.14159 |
| bool | Целое число (логическое) |
Истина (true) или ложь (false) | true |
| char wchar_t char8_t (C++20) char16_t (C++11) char32_t (C++11) |
Целое число (символ) |
Один символ текста | ‘c’ |
| short int long long long (C++11) |
Целое число (целочисленное значение) |
Положительне и отрицательные числа, включая 0 | 64 |
| std::nullptr_t (C++11) | Нулевой указатель | Нулевой указатель | nullptr |
| void | Без типа | Нет типа | не доступно |
Эта глава посвящена подробному изучению этих базовых типов данных (кроме std::nullptr_t , который мы обсудим, когда будем говорить об указателях). C++ также поддерживает ряд других более сложных типов, называемых составными типами. Составные типы мы рассмотрим в следующей главе.
Примечание автора
Термины «целочисленное значение» (integer) и «целое число» (integral) похожи, но имеют разные значения. Целочисленное значение (integer) – это особый тип данных, который содержит недробные числа, такие как положительные целые числа, 0 и отрицательные целые числа. Целое число (integral) означает «как целое число». Чаще всего целое число используется как часть термина целочисленный тип, который включает все логические, символьные и целочисленные типы (также перечисляемые типы, которые мы обсудим в главе 8). Целочисленные типы названы так, потому что они хранятся в памяти как целые числа, хотя их поведение может различаться (что мы увидим позже в этой главе, когда будем говорить о символьных типах).
Суффикс _t
Многие из типов, определенных в новых версиях C++ (например, std::nullptr_t ), используют суффикс _t . Этот суффикс означает «тип», и это обычная номенклатура, применяемая к современным типам.
Если вы видите что-то с суффиксом _t , вероятно, это тип. Но многие типы не имеют суффикса _t , поэтому он применяется не всегда.
Источник: radioprog.ru
3 Основные типы данных и структуры данных в программировании
Данные – это информация в формализованном виде. Данные по предназначению разделяются на:
- исходные данные – не меняются, получены от пользователя;
- промежуточные данные – формируются в программе, а потом используются;
- результаты — формируются в программе.
- имя
- тип
- структура
- значение
- значение одного объекта;
- множество значений;
- конкретное значение;
- множество значений этого данного (целые, вещественные), диапазон значений (границы изменения) – это ограничения, которые накладываются архитектурой ЭВМ и форматом представления данных;
- набор операций
- возможно, набор функций определенных на этом типе данных.
- арифметические:
- целый;
- вещественный.
- логический;
- символьный.
3.1.1 Арифметические типы
- целый:
3.1.2 Логический тип
Значения: ”истина”, ”ложь”. 
 Операции: — ”и”( конъюнкция ) Обозначается : =b
Операции: — ”и”( конъюнкция ) Обозначается : =b
- проверка наличия свойств или состояния объекта
” y – нечетное ? ” ” В матрице нет отрицательных элементов?” Замена двойных неравенств: c
3.1.3 Символьный тип
Множеством значений являются:
- буквы;
- цифры (0..9)
- специальные символы :+, / , — , * , ( ………….
Синтаксис значений: в ’’ или в “” Это последовательность или цепочка перечисленных ранее символов, заключенная в парные или одинарные кавычки. ‘X’ ”Б” Операции:
- конкатенация ( сцепление ) || . После последнего символа 1-го операнда записывают вплотную все символы 2-го операнда
’П’||’О’ “ПО” ’1’||’4’ ’ ”14”
- сравнение:
, =, ≠, =. t > w, если код t > код w ASCII-код: ’0’>’1’ ’3’’7’ ’f’>’d’ К сожалению символы кириллицы не представляют собой единый диапазон от ’а’ до ’я’, есть разрыв, поэтому сравнивать их, как символы латыни ,нужно аккуратно. 3.2 Структуры данных 3.2.1 Классификация структур данных. 1) Основные:
- регулярные (у регулярных структур данных все составные части имеют одинаковый тип ):
- множество — стек
- массив — очередь
- строка — таблица
- файл
- нерегулярные ( компоненты могут быть различного типа, доступ иной ): запись.
2) Дополнительные:
- списки
- деревья
- графы
Структура – это совокупность данных обладающих вместе некоторым смыслом. Структура состоит из отдельных элементов, группируемых определенным способом. Если элемент данных не может быть дальше расчленен на составные части, его называют скалярным. Соответственно переменные, соответствующие скалярным данным, называют простыми или скалярными. 3.2.2 Массив Массив – это n-мерная последовательность элементов с одинаковым типом и структурой. Обратится к элементу массива можно по его номеру. У массива также есть атрибут размерность, поэтому у каждой размерности должно быть задано количество элементов по этому измерению. Одномерный массив называют вектором. Х : 1 2 3 ……… n 1-мерный: вектор. Х: вектор[1..n] целых ; Доступ к элементу массива: задается имя и номер элемента . Х[2] X[k] Двумерный массив называют матрицей. У матрицы есть строки и столбцы. 1 2 ……….. n
1 2. . . . . . n Y: матрица[1..m.1..n] вещественных ; Доступ к элементам 2-мерного массива: y[1.n]; y[i.j]. Все массивы большей размерности называют просто массивами. 3.2.3 Строка Строка – массив символов. 1 2 ………………… n S:вектор[1..n] символьных;
| П | О | — | 9 | 9 | # |
# — признак окончания строки Атрибут строки: длина ( всегда целое число ) S – пустая строка ( длина строки равна нулю )
| # |
Константы типа строка обрамляются парными кавычками. ”ПО-99” – изображение константы строки. Пустая строка обозначается ”” (без пробелов, без символов между кавычек ) Операции над строками. 1) Конкатенация (сцепление ) – обозначается ||. Пример 3.9: Пусть a=”ПО” b=”-” с=”99” W=a||b||c=”ПО-99” 2) Сравнение Две строки a и b.Строки a=b если их длины состоят из попарно одинаковых символов. a>b 1.Если длина a>длины b 2.Если длина а=длине b, как только a(i)>b(i) (для первых различных символов) aПример 3.10: ”ПО99а””ПО99в” ”x+y” Пример 3.11: STR1=”теплоход” X=str[6..8] X=’ход’ В квадратных скобках указывается диапазон номеров символов, значения которых будут образовывать строку результатов. STR2=”x_ Эта операция возвращает номер элемента исходной строки (1-ый аргумент), начиная с которого встречается заданный образец ( 2-ой аргумент ). K=поиск_подстроки (s1,”t1”) K=0 Если в исходной строке образец не найден, то операция возвращает ноль. 5) Нахождение длины l=длина(”плохо”) l=5; Возвращает длину информационной части строки. l1=длина(””) l1=0; Описание строк: S:строка[10]; SS:строка[n]; 3.2.4 Запись Студент 1 2 3 4 5
| ФИО | |||||
| Результаты сессии | |||||
Строка[25] вектор[1..5] целых Анкета
| ФИО | Год рождения | Место рождения | Номер паспорта |
Строка[25] целое запись запись Место рождения
| Страна | Область | Район | Населенный пункт |
Строка[20] строка[20] строка[35] строка[30] Номер паспорта
| Серия | Номер |
Строка[2] целое Описание записи в синтаксисе языка постановки задач. 
 Студент: запись ФИО:[25];Имя структурарезультаты_сессии:вектор[1..5] целых А
Студент: запись ФИО:[25];Имя структурарезультаты_сессии:вектор[1..5] целых А
 нкета: запись ФИО:строка[25];
нкета: запись ФИО:строка[25]; 
 Год рождения:целое; Место рождения :запись Cтрана:строка[20]; Область:строка[20]; Район: строка[25]; Нас. пункт cтрока[30]; Номер паспорта :запись
Год рождения:целое; Место рождения :запись Cтрана:строка[20]; Область:строка[20]; Район: строка[25]; Нас. пункт cтрока[30]; Номер паспорта :запись 
 Серия: строка[2]; Номер: целое; В отличии от массивов доступ к элементам записи производится по их именам. Доступ к элементу записи осуществляется с помощью оператора ”точка”. . В ломаных скобках записывается семантическая переменная.Пример 3.12: Анкета.ФИО Студент.Результат_сессии[2] 3.2.5 Таблицы имя>: таблица [количество записей>](описание записи>) Пример 3.13: Таблица о студентах группы из N человек. Ведомость: таблица[N] (ФИО: строка[25]; результаты: массив[4] целых). Ведомость
Серия: строка[2]; Номер: целое; В отличии от массивов доступ к элементам записи производится по их именам. Доступ к элементу записи осуществляется с помощью оператора ”точка”. . В ломаных скобках записывается семантическая переменная.Пример 3.12: Анкета.ФИО Студент.Результат_сессии[2] 3.2.5 Таблицы имя>: таблица [количество записей>](описание записи>) Пример 3.13: Таблица о студентах группы из N человек. Ведомость: таблица[N] (ФИО: строка[25]; результаты: массив[4] целых). Ведомость
| ФИО | Результаты |
12 . . . i n Обращение к элементу таблицы : []. Пример 3.14: Фамилия и инициалы 4-го студента: Ведомость[4].ФИО Оценки i-го студента : Ведомость [i].результаты 3.2.5 Очередь Очередь –массив, доступный для обработки с обоих концов. Пример 3.15: 1 2 3 ……………………… N ( номера элементов )
    |
”


 из” ”в”
из” ”в”  элементы начало( номер 1) очередь конец ( номер N ) Дисциплинаобработки: FIFO (First Input – First Output) ( первый пришел – первый ушел ) Операции:
элементы начало( номер 1) очередь конец ( номер N ) Дисциплинаобработки: FIFO (First Input – First Output) ( первый пришел – первый ушел ) Операции:
- ”в” – добавить элемент в очередь ( в конец ).
- ”из” – взять элемент из очереди ( в начале ).
- определить длину очереди во времени.
Очередь – динамическая структура данных. Ее длина не фиксирована и изменяется во времени ( в отличии от массива ). Описание: :очередь [] Пример 3.16: Р: очередь[20] целых; 3.2.6 Стек Стек – это массив , доступный для обработки только с одного конца ( с одной стороны ) 
 Стек
Стек 


   С С |
| B |
| A |
”из” ”в” вершина ( верхушка) Дисциплинаобработки:LIFO (Last Input – First Output) ( последний пришел – первый ушел ) Операции:
- ”в” – добавить ( включить, записать ) элемент в стек ( в верхушку ).
- ”из” – взять ( исключить ) элемент из стека ( из вершины ).
- считать элемент в верхушке.
Стек – динамическая структура данных. Обычно еще есть функции для проверки: 1) стек пуст ? 2) стек переполнен ? Описание: :стек [] Пример 3.18: S:стек[M] символов 3.2.7 Файл Файл – поименованная область памяти. Описание : :файл() Таблица находится в оперативной памяти, а файл во внешней памяти. Типы доступа к элементам :
- файлы последовательного доступа;
- файлы прямого доступа;
У последовательного файла запись с номером N может быть обработана только после того, как будут обработаны предыдущие N-1 записей. В файле с прямым доступом можно обработать произвольную ( по номеру ) запись. Операции:
- открыть для записи;
- открыть для чтения;
- закрыть;
- писать запись ( в файл );
- читать запись ( из файла );
- установить указатель текущей позиции на нужную запись;
- проверить, не ”конец ли файла?”;
………………………………………………………………………….
Источник: studfile.net
Типы данных
Типом данных в программировании называют совокупность двух множеств: множество значений и множество операций, которые можно применять к ним. Например, к типу данных целых неотрицательных чисел, состоящего из конечного множества натуральных чисел, можно применить операции сложения (+), умножения (*), целочисленного деления (/), нахождения остатка (%) и вычитания (−).
Язык программирования, как правило, имеет набор примитивных типов данных — типы, предоставляемые языком программирования как базовая встроенная единица. В C++ такие типы создатель 1 языка называет фундаментальными типами 2 . Фундаментальными типами в C++ считаются:
- логический ( bool );
- символьный (напр., char );
- целый (напр., int );
- с плавающей точкой (напр., float );
- перечисления (определяется программистом);
- void .
Поверх перечисленных строятся следующие типы:
- указательные (напр., int* );
- массивы (напр., char[] );
- ссылочные (напр., double
- другие структуры.
Перейдём к понятию литерала (напр., 1, 2.4F, 25e-4, ‘a’ и др.): литерал — запись в исходном коде программы, представляющаясобой фиксированное значение. Другими словами, литерал — это просто отображение объекта (значение) какого-либо типа в коде программы. В C++ есть возможность записи целочисленных значений, значений с плавающей точкой, символьных, булевых, строковых.
Литерал целого типа можно записать в:
- 10-й системе счисления. Например, 1205 ;
- 8-й системе счисления в формате 0 + число. Например, 0142 ;
- 16-й системе счисления в формате 0x + число. Например, 0x2F .
24, 030, 0x18 — это всё записи одного и того же числа в разных системах счисления.
Для записи чисел с плавающей точкой используют запись через точку: 0.1, .5, 4. — либо в
экспоненциальной записи — 25e-100. Пробелов в такой записи быть не должно.
Имя, с которым мы можем связать записанные литералами значения, называют переменной. Переменная — это поименованная либо адресуемая иным способом область памяти, адрес которой можно использовать для доступа к данным. Эти данные записываются, переписываются и стираются в памяти определённым образом во время выполнения программы. Переменная позволяет в любой момент времени получить доступ к данным и при необходимости изменить их. Данные, которые можно получить по имени переменной, называют значением переменной.
Для того, чтобы использовать в программе переменную, её обязательно нужно объявить, а при необходимости можно определить (= инициализировать). Объявление переменной в тексте программы обязательно содержит 2 части: базовый тип и декларатор. Спецификатор и инициализатор являются необязательными частями:
const int example = 3; // здесь const — спецификатор // int — базовый тип // example — имя переменной // = 3 — инициализатор.
Имя переменной является последовательностью символов из букв латинского алфавита (строчных и прописных), цифр и/или знака подчёркивания, однако первый символ цифрой быть не может 3 . Имя переменной следует выбирать таким, чтобы всегда было легко догадаться о том, что она хранит, например, «monthPayment». В конспекте и на практиках мы будем использовать для правил записи переменных нотацию CamelCase. Имя переменной не может совпадать с зарезервированными в языке словами, примеры таких слов: if, while, function, goto, switch и др.
Декларатор кроме имени переменной может содержать дополнительные символы:
- * — указатель; перед именем;
- *const — константный указатель; перед именем;
- перед именем;
- [] — массив; после имени;
- () — функция; после имени.
Инициализатор позволяет определить для переменной её значение сразу после объявления. Инициализатор начинается с литерала равенства (=) и далее происходит процесс задания значения переменной. Вообще говоря, знак равенства в C++ обозначает операцию присваивания; с её помощью можно задавать и изменять значение переменной. Для разных типов он может быть разным.
Спецификатор задаёт дополнительные атрибуты, отличные от типа. Приведённый в примере спецификатор const позволяет запретить последующее изменение значение переменной. Такие неизменяемые переменные называют константными или константой.
Объявить константу без инициализации не получится по логичным причинам:
const int EMPTY_CONST; // ошибка, не инициализована константная переменная const int EXAMPLE = 2; // константа со значением 2 EXAMPLE = 3; // ошибка, попытка присвоить значение константной переменной
Для именования констант принято использовать только прописные буквы, разделяя слова символом нижнего подчёркивания.
Основные типы данных в C++
Разбирая каждый тип, читатель не должен забывать об определении типа данных.
1. Целочисленный тип (char, short (int), int, long (int), long long)
Из названия легко понять, что множество значений состоит из целых чисел. Также множество значений каждого из перечисленных типов может быть знаковым (signed) или беззнаковым (unsigned). Количество элементов, содержащееся в множестве, зависит от размера памяти, которая используется для хранения значения этого типа. Например, для переменной типа char отводится 1 байт памяти, поэтому всего элементов будет:
- 2 8N = 2 8 * 1 = 256, где N — размер памяти в байтах для хранения значения
В таком случае диапазоны доступных целых чисел следующие:
- [0..255] — для беззнакового char
- [-128..127] — для знакового char
По умолчанию переменная целого типа считается знаковой. Чтобы указать в коде, что переменная должна быть беззнаковой, к базовому типу слева приписывают признак знаковости, т.е. unsigned:
unsigned long values; // задаёт целый (длинный) беззнаковый тип.
Перечисленные типы отличаются только размерами памяти, которая требуется для хранения. Поскольку язык C++ достаточно машинно-зависимый стандарт языка лишь гарантирует выполнение следующего условия:
- 1 = размер char ≤ размер short ≤ размер int ≤ размер long.
Обычно размеры типов следующие: char — 1, short — 2, int — 4, long —8, long long — 8 байт.
Со значениями целого типа можно совершать арифметические операции: +, -, *, /, %; операции сравнения: ==, !=, , >=; битовые операции: .
Большинство операций, таких как сложение, умножение, вычитание и операции сравнения, не вызывают проблем в понимании. Иногда, после выполнения арифметических операций, результат может оказаться за пределами диапазона значений; в этом случае программа выдаст ошибку.
Целочисленное деление (/) находит целую часть от деления одного целого числа, на другое. Например:
- 6 / 4 = 1;
- 2 / 5 = 0;
- 8 / 2 = 4.
Символ процента (%) обозначает операцию определение остатка от деления двух целых чисел:
- 6 % 4 = 2;
- 10 % 3 = 1.
Более сложные для понимания операции — битовые: (побитовый сдвиг вправо).
Битовые операции И, ИЛИ и XOR к каждому биту информации применяют соответствующую логическую операцию:
Советы
В обработке изображения используют 3 канала для цвета: красный, синий и зелёный — плюс прозрачность, которые хранятся в переменной типа int, т.к. каждый канал имеет диапазон значений от 0 до 255. В 16-иричной системе счисления некоторое значение записывается следующим образом: 0x180013FF; тогда значение 1816 соответствует красному каналу, 0016 — синему, 1316 — зелёному, FF — альфа-каналу (прозрачности). Чтобы выделить из такого целого числа определённый канал используют т.н. маску, где на интересующих нас позициях стоят F16 или 12. Т.е., чтобы выделить значение синего канала необходимо использовать маску, т.е. побитовое И:
int blue_channel = 0x180013FF
После чего полученное значение сдвигается вправо на необходимое число бит.
Побитовый сдвиг смещает влево или вправо на столько двоичных разрядов числа, сколько указано в правой части операции. Например, число 39 для типа char в двоичном виде записывается в следующем виде: 00100111. Тогда:
char binaryExample = 39; // 00100111 char result = binaryExample
Если переменная беззнакового типа, тогда результатом будет число 156, для знакового оно равно -100. Отметим, что для знаковых целых типов единица в старшем разряде битового представления — признак отрицательности числа. При этом значение, в двоичном виде состоящие из всех единиц соответствует -1; если же 1 только в старшем разряде, а в остальных разрядах — нули, тогда такое число имеет минимальное для конкретного типа значения: для char это -128.
2. Тип с плавающей точкой (float, double (float))
Множество значений типа с плавающей точкой является подмножеством вещественных чисел, но не каждое вещественное число представимо в двоичном виде, что приводит иногда к глупым ошибкам:
float value = 0.2; value == 0.2; // ошибка, value здесь не будет равно 0.2.
Работая с переменными с плавающей точкой, программист не должен использовать операцию проверки на равенство или неравенство, вместо этого обычно используют проверку на попадание в определённый интервал:
value — 0.2 < 1e-6; // ok, подбирать интервал тоже нужно осторожно
Помимо операций сравнения тип с плавающей точкой поддерживает 4 арифметические операции, которые полностью соответствуют математическим операциям с вещественными числами.
3. Булевый (логический) тип (bool)
Состоит всего из двух значений: true (правда) и false (ложь). Для работы с переменными данного типа используют логические операции: ! (НЕ), == (равенство), != (неравенство), (логическое И), || (логическое ИЛИ). Результат каждой операции можно найти в соответствующей таблицы истинности. например:
| X | Y | XOR |
| 1 | 1 | |
| 1 | 1 | |
| 1 | 1 |
4. Символьный тип (char, wchar_t)
Тип char — не только целый тип (обычно, такой тип называют byte), но и символьный, хранящий номер символа из таблицы символом ASCII . Например код 0x41 соответствует символу ‘A’, а 0x71 — ‘t’.
Иногда возникает необходимость использования символов, которые не закреплены в таблицы ASCII и поэтому требует для хранения более 1-го байта. Для них существует широкий символ (wchar_t).
5.1. Массивы
Массивы позволяют хранить последовательный набор однотипных элементов. Массив хранится в памяти непрерывным блоком, поэтому нельзя объявить массив, не указав его размер 4 . Чтобы объявить массив после имени переменной пишут квадратные скобки ([]) с указанием его размера. Например:
int myArray[5]; // Массив из 5-и элементов целого типа
Для инициализации массива значения перечисляют в фигурных скобках. Инициализировать таким образом можно только во время объявления переменной. Кстати, в этом случае необязательно указывать размер массива:
int odds[] = ; // Массив инициализируется 5-ю значениями
Для доступа к определённому значению в массиве (элемента массива) используют операцию доступа по индексу ([]) с указанием номера элемента (номера начинаются с 0). Например:
odds[0]; // доступ к первому элементу массива. Вернёт значение 1 odds[2]; // доступ к третьему элементу. Вернёт значение 7 odds[4] = 13; // 5-му элементу массива присваиваем новое значение odds[5]; // ошибка доступа
5.3. Строки
Для записи строки программисты используют идею, что строка — последовательный ряд (массив) символов. Для идентификации конца строки используют специальный символ конца строки: ‘�’. Такие специальные символы, состоящие из обратного слэша и идентифицирующего символа, называют управляющими или escape-символами.
Ещё существуют, например, ‘n’ — начало новой строки, ‘t’ — табуляция. Для записи в строке обратного слэша применяют экранирование — перед самим знаком ставят ещё один слэш: ‘’. Экранирование также применяют для записи кавычек.
Создадим переменную строки:
char textExample[5] = ; // записана строка «Test»
Существует упрощённая запись инициализации строки:
char textExample[5] = “Test”; // Последний символ не пишется, но размер всё ещё 5
Не вдаваясь в подробности, приведём ещё один полезный тип данных — string. Строки
такого типа можно, например, складывать:
string hello = «Привет, «; string name = «Макс!»; string hello_name = hello + name; // Получится строка «Привет, Макс!»
6. Ссылка
Ссылка — объект, указывающий на какие-либо данные, но не хранящий их. Например:
int a = 2; // переменная «a» указывает на значение 2 int // переменная «b» указывает туда же, куда и «a» b = 4; // меняя значение b, программист меняет значение a. Теперь a = 4 int // ошибка, так делать нельзя, т.к. ссылка нельзя присвоить значение
Ссылка является весьма удобным средством для оптимизации выполнения программы, в чём читатель убедится, когда разговор зайдёт о функциях и передачи значений параметров в функции.
7. Указатель
Чтобы разобраться с этим типом данных, необходимо запомнить, что множество значений этого типа — адреса ячеек памяти, откуда начинаются данные. Также указатель поддерживает операции сложения (+), вычитания (-) и разыменовывания (*).
Адреса 0x0 означает, что указатель пуст, т.е. не указывает ни на какие данные. Этот адрес имеет свой литерал — NULL :
int *nullPtr = NULL; // пустой указатель
Сложение и вычитание адреса с целым числом или другим адресом позволяет
передвигаться по памяти, доступной программе.
Операция получения данных, начинающихся по адресу, хранящемуся в указателе, называется разыменовывания (*). Программа считывает необходимое количество ячеек памяти и возвращает значение, хранимое в памяти.
int valueInMemory = 2; // задаём переменну целого типа int *somePtr = // копируем адрес переменной, здесь // адрес ячейки памяти, например, 0x2F *somePtr; // значение хранится в 4-х ячейках: 0x2F, 0x30, 0x31 и 0x32
Для указателей не доступна операция присваивания, которая синтаксически совпадает с операцией копирования. Другими словами, можно скопировать адрес другого указателя или адрес переменной, но определить значение адреса самому нельзя.
Сам указатель хранится в памяти, как и значения переменных других типов, и занимает 4 байта, поэтому можно создать указатель на указатель.
8. Перечисления
Перечисления единственный базовый тип, задаваемый программистом. По большому счёту перечисление — упорядоченный набор именованных целочисленных констант, при этом имя перечисления будет базовым типом.
enum color ;
enum access ;
Советы
Часто удобно использовать перечисления, значения которых являются степенью двойки, т.к. в двоичном представлении число, являющееся степенью 2-и, будет состоять из 1-й единицы и нулей. Например:
Результат сложения этих чисел между собой всегда однозначно указывает на то, какие числа складывались:
Void
Синтаксически тип void относится к фундаментальным типам, но использовать его можно лишь как часть более сложных типов, т.к. объектов типа void не существует. Как правило, этот тип используется для информирования о том, что у функции нет возвращаемого значения либо в качестве базового типа указателя на объекты неопределённых типов:
void object; // ошибка, не существует объектов типа void void // ошибка, не существует ссылов на void void *ptr; // ok, храним указатель на неизвестный тип
Часто мы будем использовать void именно для обозначения того, что функция не возвращает никакого значения. С указателем типа void работают, когда программист берёт полностью на себя заботу о целостности памяти и правильном приведении типа.
Приведение типов
Часто бывает необходимо привести значение переменной одного типа к другому. В случае, когда множество значений исходного типа является подмножеством большего типа (например, int является подмножеством long, а long — double), компилятор способен неявно (implicitly) изменить тип значения.
int integer = 2; float floating = integer; // floating = 2.0
Обратное приведение типа будет выполнено с потерей информации, так от числа с плавающей точкой останется только целая часть, дробная будет потеряна.
Существует возможность явного (explicitly) преобразования типов, для этого слева от переменной или какого-либо значения исходного типа в круглых скобках пишут тип, к которому будет произведено приведение:
int value = (int) 2.5;
Унарные и бинарные операции
Те операции, которые мы выполняли ранее, называют бинарными: слева и справа от символа операции находятся значения или переменные, например, 2 + 3. В языках программирования помимо бинарных операций также используют унарные операции, которые применяются к переменным. Они могу находится как слева, так и справа от переменной, несколько таких операций встречались ранее — операция разыменовывания (*) и взятие адреса переменной ( // то же самое, что и a = a + 2; b /= 5; // то же самое, что и b = b / 5; c // то же самое, что и c = c
- разработчиком стандарта языка C++ является Бьёрн Страуструп ↑
- — типы, соответствующие базовым принципам организации компьютерной памяти и самым общим способам хранения информации ↑
- регулярное выражение для имени выглядит следующим образом: [_A-Za-z][_A-Za-z0-9]* ↑
- размером массива называют количество элементов в нём ↑
Источник: markoutte.me