

Это вторая часть серии Наука о данных, в которой вы познакомитесь с необходимыми шагами для обработки вашего набора данных. Обработка данных — одна из самых фундаментальных задач для специалиста по данным, поскольку вы понимаете, что мы тратим большую часть нашего времени на очистку и настройку набора данных. Прежде чем мы начнем, убедитесь, что у вас установлен Orange.
Пожалуйста, прочтите первую часть по настройке и установке, если вы ее пропустили. Внизу будут ссылки для навигации по всей серии Data Science Made Easy. Начнем с простой фильтрации столбцов и строк.
Выбрать столбцы
Допустим, вы успешно определили несколько важных функций из набора данных и хотите создать новый набор данных только с этими функциями. Это легко сделать с помощью виджета Выбрать столбцы. Предполагается, что вы загрузили набор данных Iris в виджет Файл через пользовательскую документацию просмотра.
- Перетащите виджет Выбрать столбцы на холст.
- Подключите виджет Файл и виджет Выбрать столбцы.
- Дважды щелкните виджет Выбрать столбцы, чтобы открыть интерфейс.
Открыв интерфейс Выбрать столбцы, вы можете перемещать переменные влево и вправо. Слева представлены нежелательные функции, а справа — выбранные функции. Когда вы примете решение, закройте интерфейс и дважды щелкните виджет Таблица данных. Вы должны увидеть выбранные вами функции.
Оранж 5 обзор программы
Выбрать строки
Помимо возможности просто выбирать функции, вы также можете отфильтровать данные по своему желанию. Давайте подробнее рассмотрим виджет Выбрать строки.
- Перетащите виджет Выбрать строки на холст.
- Подключите виджет Файл и виджет Выбрать строки.
- Дважды щелкните виджет Выбрать строки, чтобы открыть интерфейс.
Вы можете установить условия с помощью интерфейса Выбрать строки, чтобы отфильтровать нужные данные. Предполагая, что вы используете набор данных Iris, мы можем отфильтровать данные определенного класса. Точно так же мы можем отфильтровать данные, не относящиеся к определенному классу.
Кроме того, мы также можем установить условие для таких характеристик, как длина чашелистника, который должен быть больше определенного значения. Вы можете добавить столько условий, сколько захотите. Дважды щелкните виджет Таблица данных, вы должны увидеть отфильтрованные данные.
Конструктор функций
Бывают случаи, когда необходимо создать новую функцию из существующих. Например, вы можете создать функцию ИМТ, используя характеристики роста и веса человека. Обычно это называется проектированием функций. Orange поставляется со встроенным виджетом под названием Конструктор функций, который позволяет нам создавать новую функцию, используя существующие функции.
Если у вас хорошая память, вы помните, что я сказал, что «для обработки данных не используется код». Ну, вы угадали. Я соврал тебе! Для разработки функций требуются некоторые базовые знания программирования на Python. Не беспокойтесь, я здесь, чтобы направлять вас.

- Щелкните правой кнопкой мыши на холсте, чтобы открыть параметры виджета. Найдите виджет Конструктор функций и добавьте его на холст.
- Добавьте виджет Таблица данных.
- Подключите их все, как показано на рисунках выше.
- Дважды щелкните по нему, чтобы открыть интерфейс.

- Нажмите кнопку «Создать», и вы увидите раскрывающийся список, содержащий числовые, категориальные и текстовые.
- Выберите Числовой, и будет создан новый элемент (скорее всего, с именем X1).
- Измените имя на sepal_length_square (измените соответственно в зависимости от ваших предпочтений, поскольку это имя для вашей новой функции).
- Сосредоточьтесь на правом текстовом поле. Это та часть, где вы будете вводить некоторый код. Нажмите кнопку «Выбрать объект», и вы увидите все объекты из вашего набора данных. Выберите длину чашелистника, и вы увидите, что «sepal_length» добавляется в текстовое поле. Вы можете ввести его сами, но не забудьте добавить подчеркивание для каждого пробела в названии функции.
- «Выбрать функцию» предоставляет список математических функций, которые можно использовать, если вы не знакомы со сценариями. У вас не должно возникнуть проблем, поскольку предоставляемые функции аналогичны функциям в любой электронной таблице Excel. Введите ** 2, и вы получите sepal_length ** 2, как на картинке выше.
- Добавьте новый категориальный элемент, выполнив шаги, указанные выше. Категориальный используется для обозначения объекта. Например, вы можете сгруппировать радужку на мелкую, среднюю и большую в зависимости от длины чашелистника. Код основан на следующем: «(value) if (название функции)‹ (value), else (value ) if (название функции) ‹(значение), else (значение)»
- Измените имя на small_iris и введите следующее «0, если sepal_length‹ 5, иначе 1, если sepal_length ‹6 else 2»
- В текстовом поле значений введите «S, M, L». Это представляет собой метку метки на основе условий на шаге 7. 0 будет отображаться в S, 1 будет отображаться в M, а 2 будет отображаться в L.
Вы должны увидеть следующий результат после закрытия интерфейса Конструктора функций и открытия интерфейса таблицы данных.

Основываясь на официальной документации, вот несколько быстрых советов для новичков в Python:
- +, — добавить, вычесть
- * чтобы умножить
- / делить
- %, чтобы разделить и вернуть остаток
- ** для экспоненты (для квадратного корня из квадрата 0,5)
- // для разделения полов
- ‹,›, ‹=,› = Меньше, больше, меньше или равно, больше или равно
- == для равных
- ! = для не равных
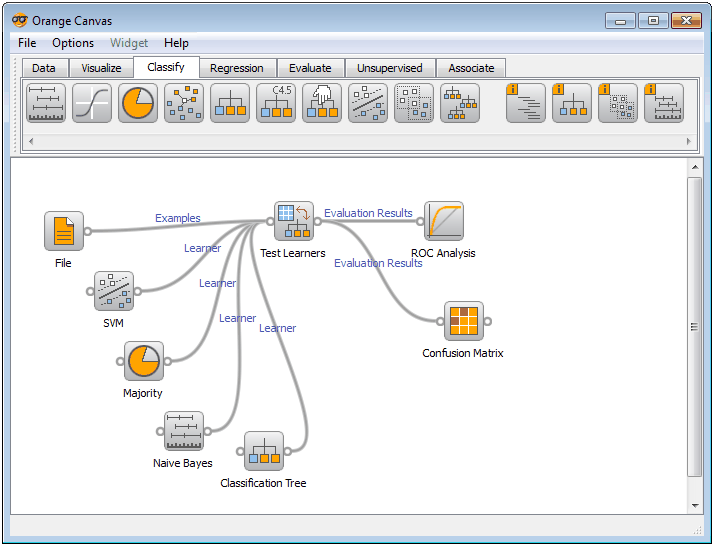
Сэмплер данных
Виджет Data Sampler — один из самых важных виджетов для специалиста по данным. Разделение набора данных на набор поездов и набор тестов — одна из самых фундаментальных задач. Вы помните функцию train_test_split, предоставляемую sklearn? Функциональность этого виджета такая же, как у train_test_split. Давайте проверим это на холсте.
- Перетащите виджет Файл на холст.
- Перетащите виджет Образец данных на холст.
- Соедините виджет Файл с виджетом Образец данных.
- Перетащите два виджета Таблица данных на холст. Первый виджет предназначен для данных поезда, а второй виджет — для тестовых данных.
- Соедините виджет Data Sampler с обоими виджетами Data Table, как показано на рисунке выше.
- Дважды щелкните ссылку между виджетом Выборка данных и вторым виджетом Таблица данных, чтобы открыть интерфейс редактирования ссылок.
- Подключите Оставшиеся данные к данным и удалите связь между образцом данных и данными, дважды щелкнув ссылку. Это позволяет второй таблице данных получать оставшиеся данные в соответствии с настройками, установленными в выборке данных.
- Дважды щелкните Data Sampler, чтобы открыть интерфейс.

На основании официальной документации,
- Фиксированная доля данных: возвращает выбранный процент всех данных (например, 70% всех данных). В этом случае 70% — Выборка данных и 30% — Остаточные данные.
- Фиксированный размер выборки: возвращает выбранное количество экземпляров данных с возможностью установить Образец с заменой, который всегда выбирает из всего набора данных (не вычитает экземпляры, уже находящиеся в подмножестве. ). При замене вы можете создать больше экземпляров, чем доступно во входном наборе данных.
- Перекрестная проверка: экземпляры данных разбиваются на дополнительные подмножества, где вы можете выбрать количество сверток (подмножеств) и какую свертку вы хотите использовать в качестве образца.
- Bootstrap: выводит выборку из статистики совокупности.
Сохранять данные
Вся обработка данных, проведенная до сих пор, применима только к Orange. Изменения не отражаются в исходном наборе данных. Если вы хотите сохранить обработанные данные, используйте виджет Сохранить данные.

Вы можете разместить его после таблицы данных, чтобы данные поезда сохранялись независимо, как показано на рисунке выше.

Точно так же вы можете выбрать некоторые данные в любом виджете Визуализировать и сохранить только выбранные данные.

Вы можете определить тип файла и проверить, использовать ли сжатие или нет. Есть два способа сэкономить:
- Сохранить: перезаписать существующие файлы.
- Сохранить как: создать новый файл.
Вот и все, ребята! Вы узнали, как фильтровать набор данных с помощью виджета Выбрать столбцы и виджета Выбрать строки. Кроме того, вы можете использовать свои навыки программирования на Python для разработки функций с помощью виджета Конструктор функций. Вы также можете сделать это через графический интерфейс пользователя.
Затем виджет Data Sampler позволяет разделить данные на набор для обучения и набор для тестирования. По завершении обработки данных вы можете сохранить их в файл с помощью виджета Сохранить данные. Есть еще много виджетов, которые можно использовать для обработки данных. Не стесняйтесь обращаться к официальной документации. Благодарим за чтение части 2 руководства Data Science Made Easy. В следующей части я расскажу о тестировании и оценке с помощью Orange. ❤️
Наука о данных стало проще
- Интерактивная визуализация данных
- «Обработка данных»
- Тест и оценка
- Моделирование и прогнозирование данных
- Имидж-аналитика
Ссылка
- Https://orange.biolab.si/
- Https://github.com/biolab/orange3
- Https://orange.biolab.si/docs/
Источник: digitrain.ru
Orange для чего программа
Интерактивный data mining: возможности Orange — продукта с открытым исходным кодом
Интерактивный data mining: возможности Orange — продукта с открытым исходным кодом
3 апреля 2019 состоялась дата-среда из цикла «Большие данные в экономике», который совместно организуют АНО «Инфокультура», Ассоциация участников рынка данных и РАНХиГС.
Об основах интерактивного data mining рассказал Дмитрий Стефановский, директор «Центра компетенций по цифровой прослеживаемости и консалтингу» РАНХиГС, кандидат технических наук, специалист в области прикладных исследований по цифровой трансформации.

Data mining – интеллектуальный анализ данных, совокупность методов обнаружения в данных ранее неизвестных, нетривиальных и практически полезных знаний. Сегодня результаты анализа данных позволяют по-новому взглянуть на процессы, происходящие на предприятии. При этом на практике академический подход часто не может быть внедрен в бизнес-процессы, потому что организации не могут себе позволить, чтобы сотрудники тратили большое количество времени, спорили, доказывали, искали тонкости того или иного подхода, копались в особенностях самих методов анализа, пытались их улучшить.

Стоимость анализа данных для любой организации и исследовательского проекта очень высока. Постоянно стоит задача удешевить аналитику и попробовать разные методы. В своем выступлении Дмитрий Стефановский прокомментировал: «Это проистекает от того, что нет единой теории и сложившейся методики анализа данных. Как обычно действуют – берут данные, по очереди применяют к ним один за другим методы, проверяют качество этих методов и выбирают тот метод, который дал наилучший результат. Это во многом напоминает кибернетический подход: мы метод подаем на данные, смотрим его результаты, выжил – не выжил, отбрасываем».

При этом необходима среда, которая позволила бы это все делать быстро и сравнивать результаты в едином визуальном поле. Нужен инструмент, который позволит вам быстро построить и проанализировать модель. Одним из таких инструментов является бесплатный продукт Orange. Данный открытый продукт предлагает машинное обучение и визуализацию данных для новичков и экспертов.
Подробный рассказ о продукте и его возможностях, а также практические примеры применения Orange в RFM-анализе и анализе текстов смотрите в записи дата-среды:
А также рекомендуем выступление Дмитрия Стефановского на «Дне открытых данных в Москве» 2019, где разбирается кейс применения Orange для целей Федеральной налоговой службы. Задача состояла в том, чтобы на основе данных (доход предприятия в год, издержки в год, уплаченные налоги и время с момента последней проверки) предсказать, какое предприятие должно обязательно пройти проверку и обосновать, почему именно это предприятие.
Всем тем, кто хотел бы повысить квалификацию, системно и углубленно изучить современные способы анализа данных в экономике, мы рекомендуем магистерские программы РАНХиГС: «Системы больших данных в экономике» и «Цифровая экономика и современная комбинаторика» (дистанционная программа).
20 апреля состоится День открытых дверей в РАНХиГС. С 14:40 – 16:10 у всех желающих будет возможность задать вопросы руководителям магистерских программ «Системы больших данных в экономике» и «Цифровая экономика и современная комбинаторика».
Источник: www.infoculture.ru
Orange — инструмент для визуализации и анализа данных

Orange является инструментом для визуализации и анализа данных с открытым исходным кодом . Интеллектуальный анализ данных проводится путем визуального программирования и с помощью Python сценариев .
- Сохраняет выбор пользователя ;
- Интеллектуально выбирает каналы связи между виджетами;
- Присутствует множество в ариантов визуализации от гистограмм до тепловых карт;
- Набор с более чем 100 виджетов.
О лаборатории
Время покажет
- Декабрь 2017 (1)
- Ноябрь 2017 (1)
- Октябрь 2017 (1)
- Март 2017 (1)
- Январь 2017 (1)
- Октябрь 2016 (1)
- Сентябрь 2016 (1)
- Август 2016 (1)
- Июль 2016 (1)
- Июнь 2016 (1)
- Май 2016 (1)
- Апрель 2016 (1)
- Март 2016 (2)
- Февраль 2016 (7)
- Январь 2016 (2)
- Декабрь 2015 (5)
- Сентябрь 2015 (8)
- Июнь 2015 (1)
- Май 2015 (2)
- Ноябрь 2014 (1)
- Сентябрь 2014 (1)
- Май 2014 (1)
- Декабрь 2013 (1)
- Декабрь 2012 (2)
- Ноябрь 2012 (1)
- Апрель 2012 (1)
- Март 2011 (1)
- Декабрь 2010 (1)
- Июль 2010 (1)
- Апрель 2008 (1)
Эволюция интеллекта
Источник: i-intellect.ru