
Cognitive OpenOCR — первая в России OCR-система с открытыми исходными кодами
Впервые в России показана работа промышленной OCR-системы в ОС Linux.
Cognitive Technologies открыла исходные коды интерфейса системы распознавания текстов OCR Cuneiform и анонсировала дальнейшие планы развития проекта Cognitive OpenOCR . Об этом было объявлено на выставке Softool 2008 на совместной с GNU/ Linuxcenter пресс-конференции. На мероприятии были продемонстрированы уже имеющиеся результаты проекта — показана работа OCR -комплекса, собранного из кодов ядра распознавания, под управлением ОС Linux .
Это событие — очередной шаг программы «Распознавание должно быть на каждом компьютере», цель которой — сделать общедоступными технологии OCR благодаря открытости кода и нулевой стоимости ПО. Ранее в рамках реализации этой программы Cognitive Technologies перевела свою OCR Cuneiform в статус бесплатной ( freeware ) и открыла коды ядра распознавания системы — ее интеллектуальной начинки.
OpenAL — зачем нужен, как скачать и установить на Windows?
Открытие кодов интерфейса программы имеет большое значение для пользователей свободного программного обеспечения. Если открытые коды ядр а распознавания были ориентированы в основном на разработчиков и системных программистов, которые могли встраивать технологии OCR в свои программные продукты, то сейчас домашние и корпоративные пользователи могут самостоятельно собрать и использовать OCR -систему полностью из открытых кодов.
Кроме этого, публикация исходных кодов интерфейса позволит расширить круг участников проекта OpenOCR . Теперь разработчики сообщества Open Source получат возможность, наряду с развитием функциональных возможностей, вносить улучшения в текущий и создавать новые пользовательски е интерфейс ы системы.
Как отмечает директор по развитию GNU/ Linuxcenter А. Жмурко: «Постепенно ПО с открытым кодом становится все более востребованным бизнес-средой. Зачастую ограничения его распространения связаны с отсутствием по ряду направлений автоматизации программ, пригодных для промышленного использования. В частности, это касалось и отсутствия достойных OCR -продуктов, работающих в среде Linux . С открытием кодов программы Cuneiform и началом проекта OpenOCR преодолена очередная преграда на пути открытого ПО в бизнес».
По словам руководителя направления СПО Cognitive Technologies В.В. Арлазарова: «После открытия исходных кодов ядра распознавания Cuneiform сообществом буквально за пару месяцев была успешно решена сложнейшая задача — портирование системы под Linux . Теперь же есть все основания полагать, что, с открытием интерфейса, до конца 2008 года можно ожидать появления системы распознавания текстов с открытым исходным кодом, ориентированной на конечных пользователей, работающих в наиболее распространенных в мире ОС».
Источник: www.iksmedia.ru
Chronoscan
![]()
OpenVAS. Безопасность системы! Проверка на уязвимость.
Полный комплект для сканирования документов.
Любой источник: сканеры, многофункциональные принтеры, электронные письма, факсы, веб-сервисы или папки.
Автоматическая классификация документов
Ввод данных с помощью вспомогательных автоматических полей.
Извлечение текста из PDF-файлов и преобразование в индексированные данные.
Экспорт данных в любую ODBC-совместимую базу данных.
Загрузить документы в облако.
Экспорт документов и данных в ваш CRM / ERP.
Зональное распознавание текста, для автоматической обработки форм.
Мультиязычное распознавание текста с полной поддержкой международных символов.
Источник: progsoft.net
Скачать OCR CuneiForm v12 на Windows
В статье рассказано о программе OCR CuneiForm. Вы узнаете, что это такое, каковы возможности данного софта, как правильно установить и пользоваться для распознавания текстов.
Особенности [ править | править код ]
CuneiForm позиционируется как система преобразования электронных копий бумажных документов и графических файлов в редактируемый вид с возможностью сохранения структуры и гарнитуры шрифтов оригинального документа в автоматическом или полуавтоматическом режиме. Система включает в себя две программы для одиночной и пакетной обработки электронных документов.
Список языков, поддерживаемых системой:
Кроме того, поддерживается смесь русского и английского языка. Распознавание смесей других языков поддерживается только в ветке, разработанной Андреем Боровским в 2009 году[3]. Обучение другим языкам затруднительно в виду связи каждого языка с dat-файлом, структура и способ получения каковых разработчиками не раскрывались.
Наше мнение о CuneiForm
Мы тщательно протестировали данный инструмент перед тем как добавить его в список рассматриваемых нами приложений. В результате этого тестирования программа показала себя только с самой лучшей стороны. Со всеми поставленными задачами приложение отлично справилось, во время работы сбоев или зависаний замечено не было. Многие пользователи называют данное приложением бесплатным аналогом FineReader, мы считаем, что эти слова имеют некий смысл, так как CuneiForm является действительно качественным продуктом.

Если у вас появились проблемы при скачивании CuneiForm или возникли вопросы при использовании этой программы, обязательно пишите о них в комментариях, мы ответим каждому!
Скачать КьюниФорм бесплатно
Скачать CuneiForm для Windows 10, 7, 8, XP
| Официальный дистрибутив OCR CuneiForm |
| Тихая установка без диалоговых окон |
| Рекомендации по установке необходимых программ |
| Пакетная установка нескольких программ |
SoftOK рекомендует InstallPack, с его помощью вы сможете быстро установить программы на компьютер, подробнее на сайте.
С OCR CuneiForm также скачивают:
Лучший отечественный браузер
Мощный бесплатный антивирус
Современный быстрый браузер
Мощный инструмент для работы с архивами
Программа для разговоров во время игры
Программы для организации VPN-туннеля
Скачать другие программы для компьютера
Отзывы
Если нужно оцифровать архивные материалы, использую CuneiForm – бесплатное приложение, которое шустро обрабатывает информацию.
Султан Журналист
Программа с точностью определяет заголовки и адаптирует форматирование под заранее заданный стиль.
Сергей Системный администратор
Много работаю с библиотечными материалами. Чтобы не нести домой много книг, фотографирую нужные мне страницы, а дома трансформирую снимки в текстовый формат с помощью CuneiForm.
Кирилл Преподаватель
Хотя последняя Windows-версия увидела мир в далеком 2009 году, этот релиз CuneiForm все еще актуален и радует стабильностью в работе даже на новых версиях ОС – я скачал его бесплатно с меню на русском языке для Виндовс 10.
Асхан Менеджер
Задать вопрос о OCR CuneiForm
Бесплатные аналоги ABBYY FineReader для Linux
ABBYY FineReader – одна из самых лучших программ для распознавания текста.
Используя бесплатный аналог ABBYY FineReader вы экономите 3590 рублей.

img2txt – онлайн сервис по распознаванию текстов из отсканированных изображений. Сервис работает с английским, русским и украинским языками. Стоит отметить, что загружаемое изображение не должно содержать таблицы, изображения, диаграммы, а также превышать 4 Мб. Кроме того, оно должно быть представлено в одном из следующих форматов: jpg, jpeg, png. подробнее…

www.free-ocr.com – онлайн сервис для распознавания текста. Качество распознавания хорошее, даже при невысоком качестве изображения. Имеет ограничение на размер распознаваемого файла в 2 Mb. Поддерживает такие языки как: русский, английский, немецкий, французский, испанский, итальянский, чешский, датский, нидерландский, финский, греческий, норвежский, польский, португальский, шведский, турецкий, украинский. подробнее…

Free Online OCR – бесплатный онлайн сервис для распознавания текста. К достоинствам аналога ABBYY FineReader можно отнести хорошее качество распознавания текста; неограниченное количество загрузок; работа с 70 языками, в том числе русским; распознавание текста, содержащего сразу несколько языков; отсутствие регистрации.
Free Online OCR предоставляет возможность выделять, а также разворачивать часть документа, предназначенную для дальнейшей обработки. Распознает следующие форматы: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM и PCX. Работает с такими форматами сжатия как Unix compress, bzip2, bzip и gzip; со следующими мультистраничными документами: TIFF, PDF и DjVu. Распознает файлы DOCX и ODT с изображениями. Работает с ZIP архивами. Результат может быть получен в виде простого текста (TXT), документа Microsoft Word (DOC) и PDF-файла Adobe Acrobat. подробнее…

SimpleOCR – бесплатное приложение для распознавания текста. Умеет распознавать рукописный текст. Поддерживаемые языки: английский, голландский, французский. Умеет читать изображения со сканера. подробнее…

OnlineOCR.net – бесплатный сервис по распознаванию текста и сохранению его в форматах docx, xlsx или txt. Сервис позволяет распознавать до 15 изображений в час без регистрации, хотя регистрация бесплатна. Количество поддерживаемых языков огромное, включая русский, украинский, белорусский. Распознавание происходит довольно быстро.
Качество работы сервиса на хорошо отсканированных изображениях нормальное. Если текст содержит картинки или отсканирован плохо, то качество страдает. Сервис имеет ограничение по размеру файла в 5 МБ. подробнее…
Установка
- http://openocr.org/download/
2. Пример распознавания текста
Будем считать что необходимые картинки для распознавания вы уже получили (отсканировали там, или скачали в интернете книгу в формате pdf/djvu и достали из них нужные картинки. Как это сделать — см. в этой статье).
1) Открываем требуемую картинку в программе CuineForm ( файл/открыть или « Cntrl+O «).
2) Чтобы приступить к распознаванию — нужно сначала выделить различные области: текста, картинок, таблиц и пр. В программе Cuneiform это можно сделать не только в ручную, но и автоматически! Для этого щелкните по кнопке « разметка » в верхней панели окна.
3) Спустя 10-15 сек. программа автоматически подсветит все области различными цветами. Например, область текста выделяется синим цветом. Кстати, подсветила она все области правильно и довольно быстро. Честно говоря, не ожидал от нее такой быстрой и правильной реакции…
4) Для тех, кто не доверяет автоматической разметке, можно воспользоваться и ручной. Для этого есть панелька инструментов (см. картинку ниже), благодаря которой можно выделить: текст, таблицу, картинку. Передвинуть, увеличить/уменьшить начальное изображение, подрезать края. В общем, неплохой набор.
5) После того, как все области были размечены, можно приступить к распознаванию. Для этого просто щелкните по одноименной кнопке, как на картинке ниже.
6) Буквально через 10-20 сек. перед вами откроется документ в Microsoft Word с распознанным текстом. Что интересно, в тексте для этого примера, ошибки, конечно были, но их крайне не много! Тем более, учитывая в каком невзрачном качестве был исходный материал — картинка.
По скорости и качеству вполне сравнимо с FineReader!
Использование
Программа очень проста с точки зрения пользовательского интерфейса и управления. В верхней части расположены крупные кнопки, отвечающие за основные функции программы.
С их помощью вы можете сделать следующее:
- Распознать текст из файла, хранящегося на вашем жестком диске.
- Распознать документ с помощью сканера, подключенного к ПК.
- Пометить и распознать автоматически или вручную.
- Сохраните результат на жестком диске.
Графические интерфейсы для CuneiForm [ править | править код ]
- YAGF
- OCRFeeder
- KBookOCR
- Cuneiform-Qt
- Puma.NET (англ.) русск. (англ.) — интерфейсная библиотека .NET
- Quneiform
TroubleShooting
Работа в Windows 7
Ошибка передачи данных при работе в программе CuneiForm
Описание ошибки:Причина в особенностях работы TWAIN драйверов сканера, в CuneiForm используются 2 режима передачи memory-buffered (режим по умолчанию) и memory-native. Раньше драйвера сканера не всегда реализовали оба, или один из них был не очень стабилен. Была ситуация когда это зависело и от производителя, и от версии драйвера. Сейчас у производителей промышленных сканеров (Fujitsu, Kodak и др.) поддерживаются все режимы, а у остальных производителей видимо ситуация с режимами передачи иногда остается нестабильной.
Лекарство: Необходимо отредактировать файл face.ini, который находится в директории windows. Находим в файле ключ TWAIN_TransferMode и делаем его равным memory-native. То есть должно быть TWAIN_TransferMode=memory-native
Ответы на другие вопросы о работе программы CuneiForm вы можете найти на форуме CuneiForm.
GOCR
GOCR – это свободная кроссплатформенная система оптического распознавания текстов, работающая из командной строки. Программа пока находится в ранней стадии разработки, поэтому имеет ряд серьезных недостатков (например, распознает только одноколоночный текст). Кроме того, изучение man-страницы показало, что опций, позволяющих задать язык распознавания, программа не имеет, что подтвердилось экспериментом – русский текст gocr пытается распознать как английский. Естественно, в таблицу я данную программу включать не стал.
Критика
- Программа не умеет распознавать JPEG файлы, содержащие шум (напр., скриншоты экрана), с чем лучше справляется FineReader[7].
- Версия для Windows не обновлялась уже больше 2 лет и проект по развитию OpenOCR скорее всего заморожен в связи с отсутствием людских и денежных ресурсов[8].
- Отсутствие встроенной поддержки распознавания документов PDF и экспорта результатов распознавания в этот формат [8].
- Отсутствие возможности использования OpenOffice для просмотра распознанного текста (только MS Office) [9].
- Отсутствие возможности создания табличных блоков [10]
- Отсутствие коммерческой поддержки продукта. Официальная поддержка фирмой Cognitive Technologies по нему не оказывается.
- Форум проекта периодически подвергается спамерским атакам, плохое модерирования на форуме (нет реакции на сигнал модератору, спамерские сообщения не чистятся, в том числе и в тематических ветках, что затрудняет их чтение) — см. вышестоящие ссылки.
См. также
- OpenOCR (CuneiForm)
- Tesseract
- Как создать документ PDF
- LibreOffice
- OpenOffice HOWTO
Источник: vkspy.info
Приложения архивации и FineReader в качестве инструментов для тестирования производительности ПК
В предыдущих статьях нашего цикла, посвященного различным реальным приложениям, которые могут использоваться для тестирования процессоров, компьютеров, ноутбуков и рабочих станций и которые в дальнейшем будут положены в основу нового тестового пакета iXBT Application Benchmark 2018, мы уже рассмотрели довольно внушительный пакет различных приложений. Напомним, что это были видеоконверторы, приложения для редактирования и создания видеоконтента, редакторы цифровых фотографий и рендеры.
В этой статье мы рассмотрим еще три приложения, которые можно использовать для тестирования процессоров и ПК, но нельзя отнести к одной логической группе: это такие относительно распространенные приложения, как Abbyy FineReader 12, WinRAR 5.50 и 7-Zip 18.
Конечно, можно было бы классифицировать эти программы как некий набор офисных приложений, просто потому что нет четкого критерия, что именно называть офисными приложениями, и под это определение попадает любая программа, которая может использоваться в офисе. Однако обычный человек под офисными приложениями все-таки скорее понимает программы, входящие в пакет Microsoft Office, и это, в общем, вполне справедливо.
При этом как раз программ из пакета Microsoft Office в нашем списке приложений, на базе которых возможно создание тестов, нет и не будет. Нас каждый раз спрашивают, будут ли тесты на основе таких программ, как Excel. Отвечаем: таких тестов не будет, потому что в них нет никакого смысла. Эти программы не являются ресурсоемкими сами по себе и не позволяют оценить производительность системы.
Можно, конечно, имитировать сложнейшие расчеты в Excel, но это будет классический сферический конь в вакууме, поскольку на практике никто такими расчетами в Excel не занимается. Ну а говорить о других программах из пакета Microsoft Office в плане возможного их использования для тестов тем более бессмысленно. А потому вернемся к нашим Abbyy FineReader 12, WinRAR 5.50 и 7-Zip 18.
Abbyy FineReader 12 — это известная программа оптического распознавания символов (OCR), у которой почти нет конкурентов на российском рынке. Аналоги, конечно, есть, но они не получили широкого распространения. Кроме того, эти альтернативные продукты по тем или иным причинам не подходят для тестирования.
Часть из них работает только с изображениями и не поддерживает работу с многостраничными PDF-файлами. В частности, бесплатная программа CunieForm OpenOCR «заточена» на работу со сканером и понимает только изображения. Есть утилиты, которые не понимают русского языка.
И есть множество утилит, которые реализованы в виде онлайн-сервиса, что исключает возможность их использования для реализации тестов. Одним словом, потратив достаточно много времени, мы пришли к выводу, что реальной альтернативы пакету Abbyy FineReader попросту нет. Именно поэтому группа программ оптического распознавания представлена только одной программой Abbyy FineReader 12.
Что касается архиваторов, то тут все проще. Раньше мы использовали только WinRAR, но теперь решили добавить еще и бесплатный и очень популярный архиватор 7-Zip. Конечно, никто уже давно не использует архиваторы для высвобождения места на жестком диске. Тем не менее, архиваторами пользуются все, просто в 90% случаев мы используем операцию разархивирования.
Например, при скачивании различной информации из интернета приходится прибегать к разархивации. А вот операция создания архива используется на практике довольно редко, но все же используется.
В частности, если нужно выложить какие-либо данные в интернет для доступа к ним других пользователей, то первоначально эти данные, как правило, архивируются — причем не столько даже с целью уменьшения объема, сколько с целью упаковки всех файлов в один. При этом разархивирование, хотя оно и используется значительно чаще, чем архивирование, не позволяет оценить производительность компьютера: эта операция не создает серьезной нагрузки на процессор, да и нагрузка на накопитель далека от максимальной. Сравнивая время разархивирования на различных системах нельзя сделать корректного вывода относительно их производительности. Поэтому бессмысленно использовать операцию разархивирования для тестирования компьютера и в нашем тестовом пакете мы используем только операцию архивирования.
Ну а теперь, после краткого вступления, рассмотрим тесты более конкретно.
Abbyy FineReader 12
Приложение Abbyy FineReader использовалось в нашем тестовом пакете и ранее. За прошедшее время вышла новая версия программы (Abbyy FineReader 14), но из-за сложностей с ее получением мы решили использовать предыдущую версию, то есть FineReader 12.
Сам тест мы также не стали менять. Напомним, что в нашем тесте измеряется время распознавания PDF-документа — «Большого толкового словаря правильной русской речи» Л. И. Скворцова, состоящего из 1103 страниц.
Напомним особенность работы приложения Abbyy FineReader 12. Весь процесс распознавания можно условно разделить на два этапа. На первом считываются страницы распознаваемого документа и эти считанные страницы распознаются.
В ходе первого этапа FineReader создает небольшую нагрузку на накопитель и высокую нагрузку на процессор, причем процесс распознавания является многопоточным и хорошо распараллеливается на все доступные ядра процессора. На втором этапе (завершающем), когда все страницы документа уже распознаны, нагрузка на процессор резко снижается, однако программа не заканчивает свою работу и до полного завершения процесса проходит еще какое-то время (до 15%-20% от времени распознавания). В нашем тесте за время выполнения задачи принимается время только распознавания текста (процесс с интенсивной загрузкой процессора), без учета завершающей фазы. На наш взгляд, это более корректно.
WinRAR 5.50
Архиватор WinRAR мы тоже использовали в тестовом пакете и ранее. В новом тесте изменилась версия архиватора (WinRAR 5.50 вместо WinRAR 5.40) и сама тестовая задача.
Напомним, что ранее для загрузки процессора мы использовали формат сжатия RAR5 и метод компрессии Best (максимальное сжатие). Далее архиватору “подсовывались” для сжатия файлы большого размера (с тем, чтобы минимизировать обращение к накопителю). Конечно, такой тест был несколько академическим в том смысле, что он оторван от реальности.
В новом тесте мы решили использовать более реалистичный сценарий. Используется формат сжатия RAR (кстати, формата RAR5 в новой версии нет) и метод компрессии Normal.
Сжатию подвергается папка размером 9,15 ГБ, которая содержит различные типы данных. Это и фотографии, и видео, и PDF-документы, и пр. Результатом теста является время сжатия данных.
7-Zip 18
В отличие от WinRAR, 7-Zip — бесплатный, а потому очень популярный архиватор. Ранее этот архиватор нами не использовался.
В тесте с архиватором 7-Zip 18 используется такая же задача, как и в тесте с архиватором WinRAR 5.50, то есть архивированию подлежит та же папка размером 9,15 ГБ, но, естественно, используются другие настройки архивации: формат сжатия 7z, уровень сжатия Fast, метод сжатия (алгоритм) LZMA2. Подробные настройки архиватора приведены на скриншоте.
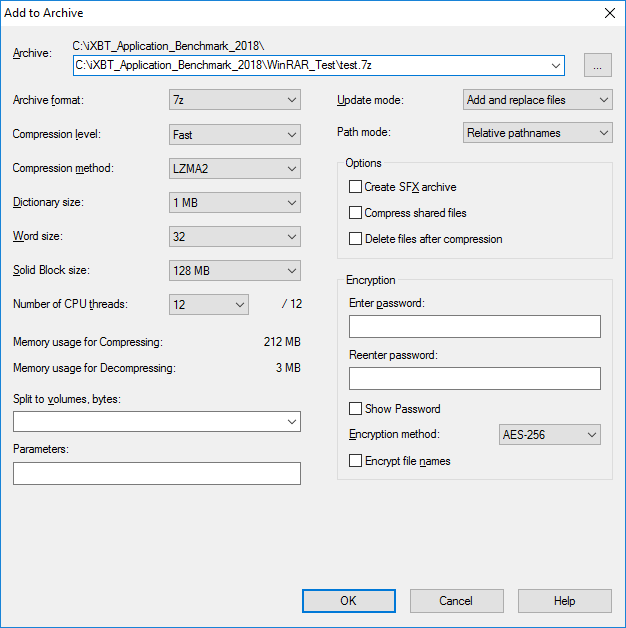
Отметим, что в настройках архиватора 7-Zip 18 можно указать количество используемых процессором потоков (Number of CPU threads). В нашем тесте всегда используется максимальное количество потоков. К примеру, для шестиядерного процессора с Hyper-Threading будет использоваться 12 потоков.
Метод сжатия Fast мы выбрали исключительно потому, что в этом случае время выполнения теста в программе 7-Zip и не слишком маленькое, и не чрезмерно большое (при прогоне на шести ядрах процессора Core i7-8700K). Кстати, по аналогичным соображениям в программе WinRAR 5.50 был выбран метод сжатия Normal.
Зависимость результатов от числа ядер процессора и технологии Hyper-Threading
Для того чтобы проанализировать зависимость результатов тестирования от количества ядер процессора и технологии Hyper-Threading, мы использовали стенд следующей конфигурации:
- процессор: Intel Core i7-8700K;
- видеокарта: процессорное графическое ядро (Intel UHD Graphics 630);
- память: 16 ГБ DDR4-2400 (двухканальный режим работы);
- материнская плата: Asus Maximus X Hero (Intel Z370);
- накопитель: SSD Seagate ST480FN0021 (480 ГБ, SATA);
- операционная система: Windows 10 (64-битная).
Количество доступных ядер процессора (от одного до шести) регулировалось в настройках UEFI BIOS. Один раз тестирование проводилось при использовании технологии Hyper-Threading, а второй раз — при отключении данной технологии в UEFI BIOS.
Результаты тестирования при использовании технологии Hyper-Threading приведены далее.
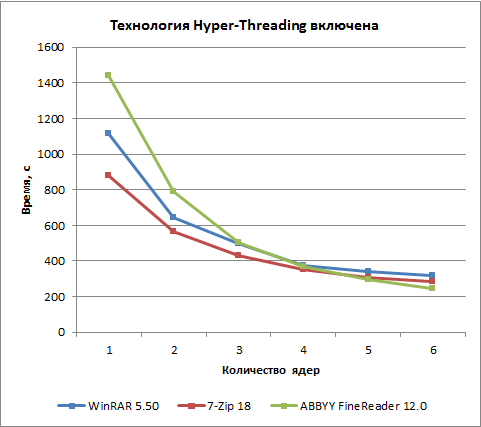
Как видно по результатам тестирования, результат (время выполнения теста) обратно пропорционален числу ядер процессора для всех приложений. Это классический вариант зависимости времени выполнения теста от количества ядер процессора в случае, когда тестовая задача хорошо распараллеливается на все ядра процессора и грузит при этом каждое ядро на 100%.
Можно также заметить, что тест на основе приложения Abbyy FineReader 12.0 более чувствителен к числу ядер процессора, нежели тесты на основе архиваторов WinRAR 5.50 и 7-Zip 18.
Результаты тестирования при отключенной технологии Hyper-Threading приведены далее. Результаты для архиваторов WinRAR 5.50 и 7-Zip 18 вполне типичные и не вызывают вопросов, а вот результат для Abbyy FineReader 12.0 получается немного нелогичным (либо для одного и двух ядер время должно быть больше, либо для трех ядер время должно быть меньше). Тем не менее, это не ошибка, а перепроверенный несколько раз факт. Почему так получается, мы объяснить не можем, поэтому ограничиваемся лишь констатацией факта.
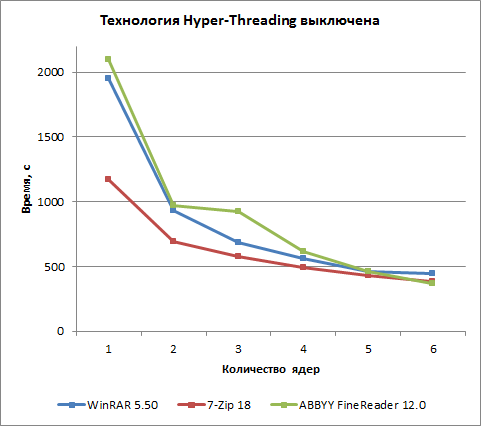
Можно также сопоставить для каждого теста в отдельности результаты тестирования при использовании технологии Hyper-Threading с результатами без этой технологи.
Для теста на основе приложения WinRAR 5.50 использование технологии Hyper-Threading позволяет сократить время архивации примерно на 30% при числе ядер процессора от двух до шести, а в случае одного ядра время сокращается на 42%.
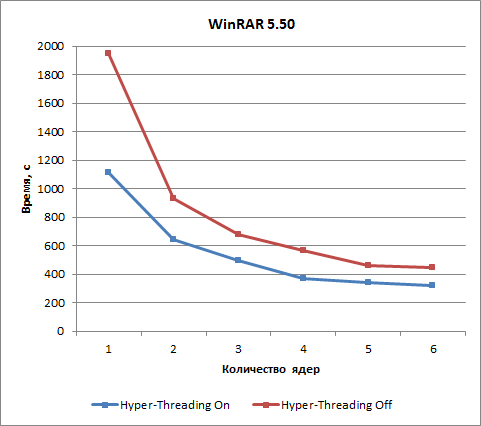
Для теста на основе приложения 7-Zip 18 использование технологии Hyper-Threading сокращает время архивации примерно на 25%.
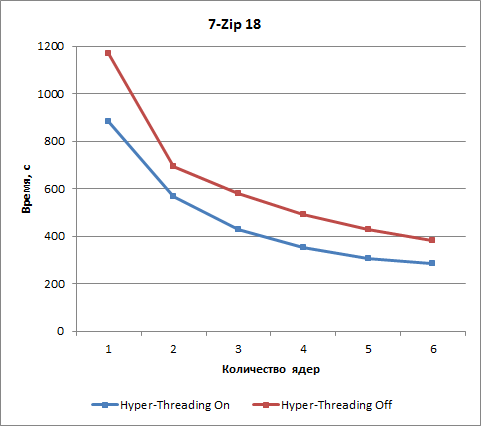
В приложении Abbyy FineReader 12.0, как уже отмечалось, при отключении технологии Hyper-Threading результаты получаются довольно странные. Поэтому скажем так: технология Hyper-Threading в данном случае позволяет существенно улучшить результаты (сократить время теста). При шести ядрах процессора сокращение времени составляет 33%.
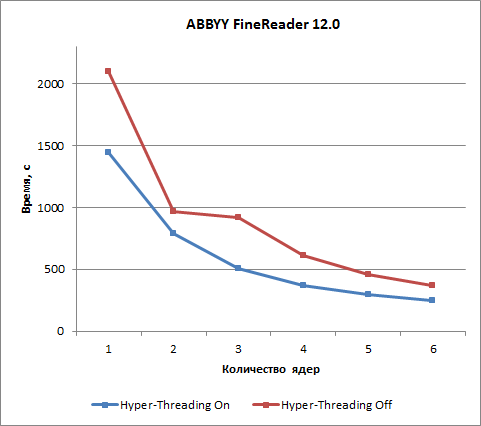
В этой статье мы рассмотрели тесты на основе приложений WinRAR 5.50, 7-Zip 18 и Abbyy FineReader 12.0, которые в дальнейшем будут использоваться в нашем тестовом пакете iXBT Application Benchmark 2018. В следующей статье нашего цикла, посвященного разработке нового пакета тестов на основе реальных приложений, мы рассмотрим приложения для инженерных и научных расчетов.
Источник: www.ixbt.com