
Opencl что это за программа
If x is an atomic variable, then thread A does not need to worry about x being modified by another thread. The platform will guarantee that x is consistent.
The other benefit of atomic memory or atomic operation is that it doesn’t require a locking/unlocking mechanism. Therefore, it’s a little faster and doesn’t have the problem of deadlocks. A common use of atomic operation is thread-safe reference counting. On the other hand, atomics can not be used in some complicated synchronizations that do need explicit mutual exclusions.
In OpenCL 2.0, developers can designate a variable to be atomic by using keyword such as atomic_int . Developers can also synchronize work item with host via fine grained SVM buffers using flags: CL_MEM_SVM_FINE_GRAIN_BUFFER and CL_MEM_SVM_ATOMICS .
OpenCL 2.0 also provides many atomic operations: atomic load, atomic store, atomic compare, and atomic fetch. Here’s an incomplete list of atomic functions:
OpenCL
Источник: www.sites.google.com
Дизайн OpenCL
В статье рассматриваются основные принципы дизайна OpenCL согласно стандарту версии 1.1. Не вдаваясь в излишние на данном уровне изложения подробности описаны 4 модели, на которых держится стандарт: модель платформы, модель исполнения, модель памяти и модель программирования. В статье не приведено ни единой строчки программного кода, так как цель — лишь ввести читателя в мир разработки на OpenCL, осветив различные стороны его дизайна.
Введение
OpenCL — индустриальный стандарт, рожденный в 2008 году в результате взаимодействия специалистов компании Khronos Group с разработчиками программного обеспечения, вендорами аппаратных решений (в том числе мобильных платформ) и производителями процессоров различных типов и назначений. Центральная идея OpenCL — предоставить программисту универсальный инструмент для использования всех вычислительных мощностей современных вычислительных систем.
По задумке авторов, написав однажды программу с использованием OpenCL, можно будет запускать ее практически на любой вычислительной системе: телефонах, графических картах, ускорителях и т.п. Насколько качественно составители стандарта сумели воплотить эту идею — тема отдельной дискуссии. Но определенно сейчас можно сказать одно — данный стандарт явился важным шагом в развитии параллельного программирования для гетерогенных систем.
Созданные на OpenCL программы потенциально могут использовать имеющиеся ресурсы вычислительной системы следующим образом:
- определить доступные ресурсы в гетерогенной системы и выбрать подходящие;
- создать последовательность инструкций, которые будут выполняться на ресурсах;
- подготовить начальные данные для вычислений;
- заставить эти ресурсы выполнить OpenCL-инструкции, обрабатывающие подготовленные данные;
- собрать результаты вычислений.
Для понимания как OpenCL помогает выполнить описанные выше действия рассмотрим OpenCL-приложение с четырех точек зрения.
Вебинар «Вычисляем на видеокартах. Технология OpenCL»
Модель платформы
Модель платформы (platform model) дает высокоуровневое описание гетерогенной системы.
Центральным элементом данной модели выступает понятие хоста (host) — первичного устройства, которое управляет OpenCL-вычислениями и осуществляет все взаимодействия с пользователем. Хост всегда представлен в единственном экземпляре, в то время как OpenCL-устройства (devices), на которых выполняются OpenCL-инструкции могут быть представлены во множественном числе. OpenCL-устройством может быть CPU, GPU, DSP или любой другой процессор в системе, поддерживающийся установленными в системе OpenCL-драйверами.
OpenCL-устройства логически делятся моделью на вычислительные модули (compute units), которые в свою очередь делятся на обрабатывающие элементы (processing elements). Вычисления на OpenCL-устройствах в действительности происходят на обрабатывающих элементах. На рис. 1 схематически изображена OpenCL-платформа из 3-х устройств.
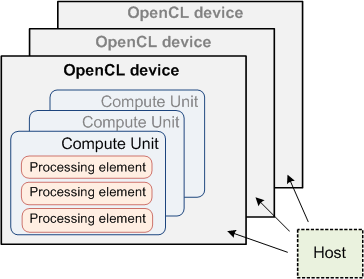
Рис. 1: Схематическое представление OpenCL-платформы.
Модель вычислений
Модель вычислений (execution model) описывает абстрактное представление того, как потоки инструкций выполняются в гетерогенной системе.
С хостом неразрывно связано понятие хостовой программы (host program) — программного кода, выполняющегося только на хосте. OpenCL не указывает как именно должна работать хостовая программа, а лишь определяет интерфейс взаимодействия с OpenCL-объектами.
С точки зрения модели вычислений OpenCL-приложение состоит из хостовой программы и набора ядер (kernels). OpenCL-ядро в общем виде представляет собой функцию, написанную на языке OpenCL C (подмножество языка ISO С’99) и скомпилированную OpenCL-компилятором.
Ядро создается в хостовой программе и затем с помощью специальной команды ставится в очередь на выполнение в одном из OpenCL-устрйоств. Во время выполнения упомянутой команды OpenCL Runtime System создает целочисленное пространство индексов (integer index space), каждый элемент которого носит название глобальным идентификатором (global ID). Каждый экземпляр ядра выполняется отдельно для каждого значения глобального идентификатора. Экземпляр ядра носит название work-item. Таким образом, каждый work-item однозначно определяется своим глобальным идентификатором.
Множество всех work-item разбивается на группы. Такая группа носит название work-group. С каждой work-group сопоставляется свой уникальный идентификатор (work-group ID). Все work-item в одной work-group идентифицируются уникальным в пределах своей группы номером: local ID. Таким образом каждый work-item определяется как по уникальному global ID так и по комбинации work-group ID и local ID внутри своей группы.
Все work-item в пределах одной work-group выполняются параллельно на обрабатывающих элементах одного вычислительного модуля OpenCL-устройства. Это гарантируется стандартом, в то время как совершенно не гарантируется, что несколько work-item из разных групп будут выполнены параллельно. Об этом важном свойстве параллелизма необходимо всегда помнить при разработке OpenCL-программ.
Пространство индексов N-размерно и обычно носит название NDRange. В случае версии стандарта OpenCL 1.1 размерность N принимает значения 1,2 или 3. Таким образом, сетки координат global ID и local ID N-размерны, т.е. определяются N координатами. На рис. 2 схематически показан двумерный NDRange.
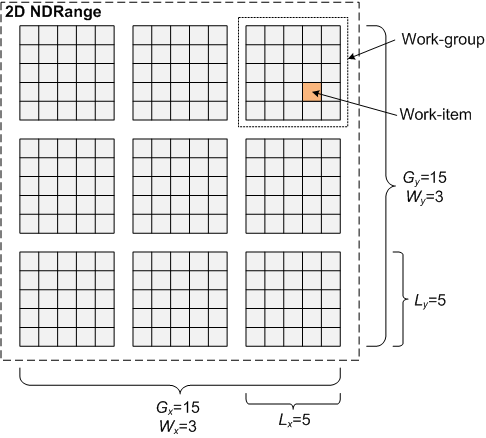
Рис. 2: Пример двумерного NDRange,
где Gx и Gy — число глобальных идентификаторов,
Wx и Wy — число групп, а Lx и Ly — число локальных идентифкаторов в NDRange.
Другим важным понятием модели вычислений является контекст, определение которого (при помощи вызова специальных функций OpenCL API) является первой задачей OpenCL-приложения. Контекст определяет среду выполнения ядер, в которую входят следующие компоненты: устройства, сами ядра, программные объекты (program objects, исходный и выполняемый код будущих ядер), объекты памяти (memory objects).
Взаимодействие между хостом и OpenCL-устройством происходит посредством команд, помещенных в командную очередь (command-queue). Данные команды ожидают в командной очереди своего выполнения на OpenCL-устройстве. Командная очередь создается хостом и сопоставляется одному OpenCL-устройству после того, как будет определен контекст.
Команды делятся на те, что отвечают за: выполнение ядер, управление памятью и синхронизацию выполнения команд в очереди. Команды могут выполняться последовательно (in-order execution) или внеочередно (out-of-order execution). Второй вариант организации очередей поддерживается не всеми платформами, о чем необходимо помнить.
Модель памяти
Модель памяти (memory model) описывает набор регионов памяти и манипулирование ими во время проведения вычислений.
OpenCL-объекты, инкапсулирующие регионы памяти, носят название объектов памяти (memory objects). Объекты памяти бывают двух типов: буферные объекты (buffer objects) и объекты изображения (image objects).
Буферные объекты памяти инкапсулируют непрерывные участки памяти, доступные ядрам во время выполнения. Программист обычно производит отображение структур данных на данные объекты, а в коде ядра получает доступ к данным структурам посредством указателей.
Объекты изображений ограничены хранением изображений. При этом как именно изображение хранится не определяется стандартом и скрыто от программиста. Обычно хранение и доступ к изображению оптимизирован под конкретную аппаратную платформу.
Стандарт описывает следующие пять различных регионов памяти.
- Память хоста (host memory) доступна лишь с хоста.
- Глобальная память (global memory) определяется в памяти, доступной на чтение и запись для всех work-item во всех work-group. Чтение и запись в глобальную память может кешироваться, если OpenCL-устройство поддерживает данную возможность. В случае CPU глобальной является оперативная память. В подавляющем большинстве случаев глобальная (и константная) память самая медленная, так что использовать без необходимости ее не стоит.
- Константная память (constant memory) — глобальный регион памяти, который инициализируемые хостом и из которого work-item может лишь читать данные.
- Локальная память (local memory) доступна лишь в пределах одной work-group. Все work-item в данной work-group могут как читать, так и писать в данный регион памяти одновремено.
- Приватная память (private memory) доступна лишь одному work-item.
На рис. 3 показаны отношения между перечисленными регионами памяти согласно стандарту OpenCL.
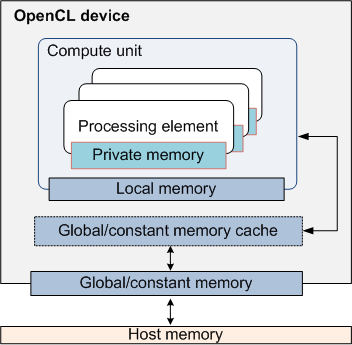
Рис. 3: Схематическое представление нескольких уровней памяти в OpenCL.
Модель программирования
Модель программирования (programming model) описывает варианты переноса абстрактного алгоритма на гетерогенные вычислительные ресурсы.
OpenCL определяет два типа модели программирования: параллелизм по данным (data parallelism) и параллелизм по заданиям (task parallelism).
Параллелизм по данным
Данный тип модели программирования организован вокруг структур данных: каждый элемент определенной хостом структуры данных обновляется одновременно (параллельно) копиями одного и того же OpenCL-ядра. Дизайн такой структуры должен поддерживать возможность одновременного изменения различных её частей.
Модель параллелизма по данным наиболее естественная модель программирования для OpenCL, так как NDRange создается непосредственно перед запуском ядра на устройстве. Задача программиста здесь описать решаемую задачу в терминах упомянутой структуры данных, отобразив ее на NDRange и инкапсулировав ее в объекте памяти.
В случае, если между несколькими work-item необходимо взаимодействие, то программист проектирует свой алгоритм с учетом разбиения множества всех work-item на некоторое количество work-group, в рамках которых несколько work-item могут осуществлять такое взаимодействие. Взаимодействие может осуществляться либо через чтениезапись локальных регионов памяти, либо через синхронизацию посредством группового барьера (work-group barrier).
Если групповой барьер определен в коде ядра, то все work-item в пределах одной work-group должны дойти до этого барьера прежде чем все work-item в этой группе перешагнут барьер и продолжат своё выполнение. Примером задачи, где может понадобится такая синхронизация служит суммирование элементов массива. Ввиду ориентированности технологии OpenCL на широкий круг устройств программисту необходимо учитывать, что OpenCL не поддерживает механизмы синхронизации между несколькими work-item из разных work-group.
Также необходимо помнить не только о том, что все work-item в пределах work-group выполняются одновременно, но и о том, что несколько work-group могут выполняться параллельно, если устройство такую возможность предоставляет. Таким образом, стандарт OpenCL описывает иерархическую модель параллелизма по данным: внутри каждой группы и между различными группами.
При проектировании алгоритма программист имеет две возможности относительно определения work-group. Первое (explicit model) — определить размер групп самостоятельно. Второе (implicit model) — предоставить возможность разбиения на группы непосредственно самой системе.
Параллелизм по заданиям
В стандарте OpenCL под заданием понимается ядро, выполняемое как единственный work-item. При этом вместе с таким заданием в устройстве могут одновременно выполняться и другие work-item. Необходимость параллелизма по заданиям может возникнуть, если параллелизм уже заключен в самом задании. Например, если в ядре задания производятся векторные операции над векторным типом данных.
Также данный тип модели программирования может возникнуть когда несколько команд запуска ядер помещаются в очередь в которой запуск происходит сразу же как команда в нее поместилась. В ряде случаев это позволяет увеличить степень использования OpenCL-устройств, позволяя системе самостоятельно планировать запуск множества различных заданий. Напомним, что параллелизм по заданиям с внеочередным запуском может не работать на некоторых вычислительных платформах и данный вариант модели программирования является скорее опциональной возможностью OpenCL.
Третий вариант параллелизма по заданиям возникает, когда множество заданий зависимо между собой и объединяются в граф с применением OpenCL-событий. Одни команды, помещенные в очередь могут генерировать события, а другие команды могут ожидать этих событий, что бы начать своё выполнение.
Выводы
Ограничения на синхронизацию между несколькими work-item в различных work-group, а также выборочная поддержка устройствами внеочередного выполнения команд из очередей очевидно снижает возможность перенесения алгоритмов из мира CPU на рельсы OpenCL. С развитием аппаратного обеспечения данные ограничения скорее всего исчезнут, что должно отразится в следующих стандартах OpenCL.
Материал по большей части представляет собой переработанный перевод первой главы книги «OpenCL Programming Guide / Aaftab Munshi, Benedict R. Gaster, Timothy G. Mattson, James Fung, Dan Ginsburg / Addison-Wesley — 2011».
Источник: opencl.ru
Стандарт параллельного программирования OpenCL 3.0: новые функции и поддерживаемые устройства

27 апреля 2020 года на мероприятии International Workshop on OpenCL консорциум Khoronos Grop представил предварительные спецификации стандарта OpenCL™ 3.0.

OpenCL (Open Computing Language) — это открытый, не требующий лицензионных отчислений стандарт для кроссплатформенного параллельного программирования различных ускорителей, которые можно найти в суперкомпьютерах, облачных серверах, персональных компьютерах, мобильных устройствах и встроенных платформах. Предыдущая версия стандарта — OpenCL 2.1 — была представлена в марте 2015 года.
За счет использования параллельных вычислений можно существенно повысить скорость работы и отклика широкого спектра приложений во многих сегментах рынка, включая профессиональные инструменты для творчества, научное и медицинское программное обеспечение, обработку машинного зрения, а также обучение и работу нейросетей. Также практическими примерами проблем, которые можно решать с помощью технологий параллельных вычислений, являются: вычислительная химия, Data Science, биоинформатика, моделирование потоков жидкостей и газов, предсказание погоды.

Стандарт OpenCL широко используется компаниями во многих сегментах рынка: создание контента, машинное обучение, в промышленных вычислениях
Разработкой стандарта занимается Khronos Group — промышленный консорциум, целью которого является выработка открытых стандартов интерфейсов программирования (API) в области создания и воспроизведения динамической графики и звука на широком спектре платформ и устройств с поддержкой аппаратного ускорения. В него входят более 100 компаний, в числе которых AMD, Apple, ARM, Google, Intel, Nvidia и другие.
OpenCL 3.0 создавался таким образом, чтобы производители «железа» могли обеспечить для разработчиков широкие функциональные возможности, гибкость развертывания, предоставляя OpenCL-совместимым решениям возможность быть ориентированными на функциональность, соответствующую их целевым рынкам.
пишет в Twitter Баладжи Калидас (Balaji Calidas), директор по разработкам в Qualcomm.
Изменения, которые включены в новую версию стандарта, главным образом служат тому, чтобы API мог использоваться для работы с новыми типа «железа», такими как FPGA, специализированные процессоры для встраиваемых систем, процессоры мобильных устройств, системы граничных вычислений (когда обработка данных происходит непосредственно на IoT устройствах), что может быть полезным, к примеру в робототехнике, автоматизированных производственных линиях, при массивно-распределённой аналитике. Более ранние версии стандарта в основном ориентировались на центральные процессоры и дискретные видеокарты.
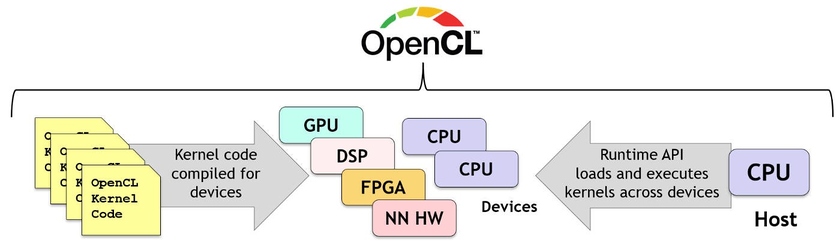
Вычисления OpenCL могут выполняться на CPU, графических процессорах, большом спектре специализированных микросхем
Новыми решениями, включенными в OpenCL 3.0, стали поддержка асинхронных расширений DMA (Direct Memory Access), для передачи сложных структур памяти, например изображений и 2D/3D структур. Дополнительно введена поддержка языка SPIR-V 1.3 (промежуточный язык для параллельных вычислений и графики, разработанный Khronos Group), что позволит повысить взаимодействия между OpenCL и API Vulkan (интерфейс прикладного программирования для 2D, 3D графики от Khronos Group).
OpenCL 3.0 разработан таким образом, чтобы полностью совместимым только со спецификациями OpenCL 1.2, все остальные функции становятся необязательными. Все функции OpenCL 2.X согласованно определены в новой унифицированной спецификации, и текущие реализации OpenCL 2.X, которые обновляются до OpenCL 3.0, могут продолжать поставлять свои существующие функциональные возможности с полной обратной совместимостью.
сказал Винсент Хиндриксен (Vincent Hindriksen), основатель и генеральный директор Stream HPC.
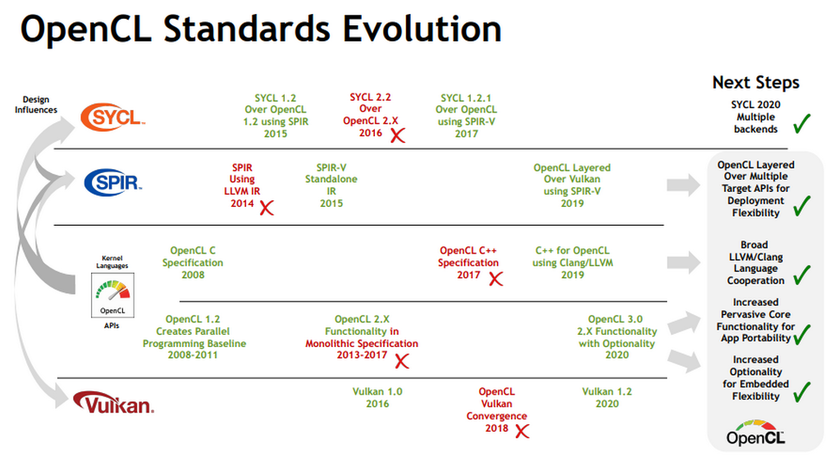
Новое поколение стандарта имеет совместимость как с предыдущими поколениями, так и с другими стандартами и языками
сказал Нил Треветт, вице-президент NVIDIA, президент Khronos Group и председатель рабочей группы OpenCL в пресс-релизе.

OpenCL может применяться вместе с высокоуровневыми API, что может упростить разработку
После выпуска спецификаций OpenCL 3.0 в Khronos Group в течении нескольких месяцев будут собирать предложения участников рынка, по изменениям, которые можно добавить в данную среду разработки, после этого будут выпущены окончательные спецификации. В консорциуме надеются на поддержку нового стандарта игроками рынка.
сказал Джефф МакВей (Jeff McVeigh), вице-президент Intel по архитектуре, графике и программному обеспечению.
Источник: www.tadviser.ru
Ошибка OpenCL.dll: диагноз и лечение
Следует отметить, что несмотря на общее негативное мнение пользователей (определённого сегмента) относительно «забагованности» операционной системы Windows 10, разработчики из компании Microsoft всё-таки сделали более стабильную систему, нежели всеми любимая Windows 7. Это мнение основано на уже продолжительном опыте работы с десятой версии на разных компьютерах на разной конфигурации и с различными «стресс-тестами». Но даже с наличием более проработанных инструментов «доставки» и установки файлов обновлений в работе операционной системы Windows 10 всё ещё встречается множество ошибок, большая часть которых связана с некорректной работой драйверного обеспечения и с нарушением целостности файлов динамической библиотеки компоновки.
В том числе это распространяется и на тему настоящей статьи, где разбору подлежит ошибка с утверждением об отсутствии файла «OpenCL.dll». В чём причина возникновения данной ошибки? А главное — каким образом её можно решить? Обо всём этом и пойдёт речь далее.

Как устранить ошибку OpenCL.dll.
Диагноз и лечение
Начать стоит с того, что, как уже было неоднократно подтверждено, представители данной библиотеки крайне предрасположены к негативному воздействию, даже в большей степени нежели «sys»-объекты (драйверы). Например, на корректность работы данных системных компонентов могут оказывать:
- Пользователем проводились какие-либо манипуляции с системными файлами (например, с реестром).
- Деятельность вирусного программного обеспечения.
- Незавершённость скачивания и установки обновлений для Windows и многое другое.
Наименование файла прямо говорит о его функционале. «OpenCL» — это фреймворк (то есть заготовка или шаблон) для написания программного обеспечения с определённой структурой. В рамках статьи нюансы структуры данного ПО не носят ключевого значения, поэтому и останавливаться на этом более подробно не стоит. Следует лишь выделить немного другую интерпретацию выполняемого им функционала. Заключается она в том, что данная технология необходима для реализации процессов с одновременным применением центрального и графического процессора.
Как исправить ошибку
Если вы в поисках решений посещали иные ресурсы в интернете, то с большой долей вероятности встречали такой совет как: «Ручное скачивание «OpenCL.dll» и его ручное помещение в системный каталог или самостоятельная регистрация». При этом приводится множество ссылок на якобы «безопасные» сайты/каталоги/библиотеки, где «dll» можно скачать абсолютно бесплатно и без вирусного ПО внутри.
Не стоит утверждать, что они однозначно не правы, но только необходимо учитывать, что представители библиотеки динамической компоновки часто используются для сокрытия в их структуре вирусного программного обеспечения. А если вы скачали подобный объект с сюрпризом внутри, и тем более поместили его в раздел диска, где установлена «Windows», то сами постелили красную дорожку для заражения вирусом собственного компьютера. Необходимо понимать, что на пустом месте ничего не происходит. Возникновению любой ошибки предшествует определённая последовательность каких-либо действий. И именно из этого аспекта следует отталкиваться в поисках решения проблем.
- Первое, что необходимо сделать (особенно для владельцев видеокарт от Nvidia и AMD), – это провести проверку на актуальность драйверов видеокарты. Для проверки лучше использовать официальные ресурсы разработчиков и скачивать драйверы только с проверенных источников.
- Если обновление/переустановка драйверов результатов не дали, то попробуйте предварительно полностью удалить старую версию (можно воспользоваться утилитой «Display Driver Uninstaller») и повторно установите новую.
- Если проблема возникла в игре или в приложении, то особое внимание стоит уделить источнику, который использовался для их установки. Например, смените автора репака, попробуйте воспользоваться другим установочным файлов, в том числе скачайте его/их с официального сайта разработчиков. В том числе на время установки ПО (игры) отключите антивирус.
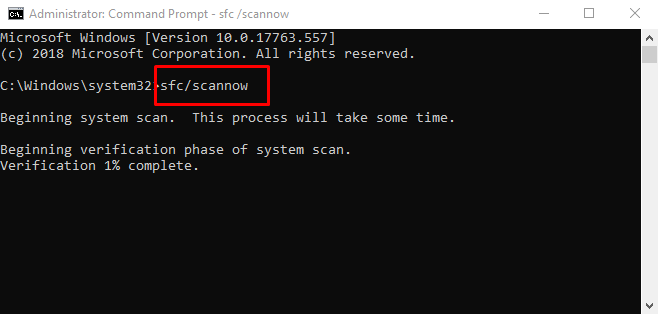
- Проверьте целостность системных компонентов, для этого:
- Нажмите «WIN+S» и введите «cmd.exe».
- Кликните правой кнопкой мышки и выберите «Запуск от имени администратора».
- Введите и выполните команду «sfc/scannow».
- Дождитесь завершения и вывода результатов сканирования.
- Откройте раздел «Параметры» — «Обновление и безопасность» и нажмите на кнопку «Проверить наличие обновлений» (Check for updates).
Установите все критические обновления, так как уже неоднократно было сказано, что с появлением «Windows 10» большая часть обязанностей по поддержанию актуальности драйверов была делегирована «Центру обновления».
Заключение
Только после применения вышеизложенных рекомендаций (соответственно, если ошибка так и осталась нерешённой) можно (на свой страх и риск) попробовать скачать «OpenCL.dll» и поместить его в директорию вручную. Но все возможные негативные последствия придётся решать вам! Поэтому лучшим вариантом будет всё своё внимание уделить комплексной проверке Windows.
Источник: nastroyvse.ru
Подключение OpenCL NVIDIA, QtCreator, MinGW32, Windows
OpenCL (англ. Open Computing Language — открытый язык вычислений) — фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических и центральных процессорах, а также FPGA.
Процедура установки и настройки OpenCL зависит от производителя вашего GPU/CPU:
Для использования OpenCL на процессорах Intel необходимо скачать и установить Intel SDK for OpenCL Applications https://software.intel.com/en-us/opencl-sdk; Владельцам же AMD понадобится обходимый драйвер.
Я же расскажу про установку для NVIDIA.
Для установки библиотеки OpenCL необходимо скачать NVIDIA CUDA Toolkit https://developer.nvidia.com/cuda-downloads, выбрав необходимые опции.
Далее запускаем установку. Компьютер попросит перезагрузку.
По завершению установки, по указанному вами пути будет создана папка CUDA со всеми исходниками.
Запускаем QtCreator. Создаём консольное приложение.
В .pro-файл добавляем следующие строчки (Они могут немного меняться, в зависимости от того, где у вас установлена папка CUDA:
INCLUDEPATH += D:/CUDA/nvcc/include LIBS += -LD:/CUDA/nvcc/lib/Win32 -lOpenCL
Пример моего .pro-файла:
QT += core QT -= gui TARGET = untitled6 CONFIG += console CONFIG -= app_bundle TEMPLATE = app SOURCES += main.cpp CONFIG += C++14 QMAKE_CXXFLAGS += -std=c++14 INCLUDEPATH += D:/CUDA/nvcc/include LIBS += -LD:/CUDA/nvcc/lib/Win32 -lOpenCL
Теперь в файл main.cpp вставим код, для проверки корректности проделанных действий:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67
#include #include int main(){ std::vectorcl::Platform> all_platforms; cl::Platform::get( if(all_platforms.size()==0){ std::cout<» No platforms found. Check OpenCL installation!
n»; exit(1); } cl::Platform default_platform=all_platforms[0]; std::cout <«Using platform: «getInfoCL_PLATFORM_NAME>()<«n»; std::vectorcl::Device> all_devices; default_platform.
getDevices(CL_DEVICE_TYPE_ALL, if(all_devices.size()==0){ std::cout<» No devices found. Check OpenCL installation!
n»; exit(1); } cl::Device default_device=all_devices[0]; std::cout <«Using device: «getInfoCL_DEVICE_NAME>()<«n»; cl::Context context({default_device}); cl::Program::Sources sources; std::string kernel_code= » void kernel simple_add(global const int* A, global const int* B, global int* C) < «» C[get_global_id(0)]=A[get_global_id(0)]+B[get_global_id(0)]; » » > «; sources.
push_back({kernel_code.c_str(),kernel_code.length()}); cl::Program program(context,sources); if(program.build({default_device})!=CL_SUCCESS){ std::cout<» Error building: «
getBuildInfoCL_PROGRAM_BUILD_LOG>(default_device)<«n»; exit(1); } cl::Buffer buffer_A(context,CL_MEM_READ_WRITE,sizeof(int)*10); cl::Buffer buffer_B(context,CL_MEM_READ_WRITE,sizeof(int)*10); cl::Buffer buffer_C(context,CL_MEM_READ_WRITE,sizeof(int)*10); int A[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; int B[] = {0, 1, 2, 0, 1, 2, 0, 1, 2, 0}; cl::CommandQueue queue(context,default_device); queue.enqueueWriteBuffer(buffer_A,CL_TRUE,0,sizeof(int)*10,A); queue.enqueueWriteBuffer(buffer_B,CL_TRUE,0,sizeof(int)*10,B); cl::make_kernelcl::Buffer, cl::Buffer, cl::Buffer> simple_add(cl::Kernel(program, «simple_add»)); cl::EnqueueArgs eargs(queue, cl::NullRange, cl::NDRange(10), cl::NullRange); simple_add(eargs, buffer_A, buffer_B, buffer_C).wait(); int C[10]; queue.enqueueReadBuffer(buffer_C,CL_TRUE,0,sizeof(int)*10,C); std::cout<» result: n»; for(int i=0;i10;i++){ std::cout[i]<» «; } return 0; }
Источник: www.cyberforum.ru