
OCR — оптическое распознавание символов
Распознавание текста или оптическое распознавание символов также называется распознаванием текста или извлечением текста. Методы распознавания текста на основе машинного обучения позволяют извлекать печатный или рукописный текст из изображений, таких как плакаты, уличные знаки и наклейки продуктов, а также из таких документов, как статьи, отчеты, формы и счета. Текст обычно извлекается как слова, текстовые строки и абзацы или текстовые блоки, что обеспечивает доступ к цифровой версии отсканированного текста. Это устраняет или значительно сокращает необходимость ввода данных вручную.
Как OCR связан с интеллектуальной обработкой документов (IDP)?
Интеллектуальная обработка документов (IDP) использует OCR в качестве базовой технологии для дополнительного извлечения структуры, связей, значений «ключ-значение», сущностей и других аналитических сведений, ориентированных на документ, с помощью расширенной службы искусственного интеллекта на основе машинного обучения, такой как Распознаватель документов. Распознаватель документов включает оптимизированную для документов версию Read в качестве механизма распознавания текста, делегируя другим моделям для получения аналитических сведений более высокого уровня. Если вы извлекаете текст из отсканированных и цифровых документов, используйте Распознаватель документов Чтение OCR.
Лучшие программы для распознавания текста. Рейтинг OCR.
Обработчик OCR
Модуль распознавания текста для чтения Майкрософт состоит из нескольких расширенных моделей на основе машинного обучения, поддерживающих глобальные языки. Это позволяет им извлекать печатный и рукописный текст, включая смешанные языки и стили письма. Чтение доступно в виде облачной службы и локального контейнера для гибкости развертывания. В последней предварительной версии он также доступен в качестве синхронного API для отдельных сценариев, не относящихся только к документам, с повышением производительности, что упрощает реализацию пользовательского интерфейса с помощью OCR.
Операции Компьютерное зрение устаревших операций ocr и RecognizeText больше не поддерживаются и не должны использоваться.
Выпуски OCR (чтение)
Выберите выпуск Read, который лучше всего соответствует вашим требованиям.
| Изображения: общие, in-the-wild images | наклейки, уличные знаки и плакаты | предварительная версия Компьютерное зрение версии 4.0 | Оптимизировано для общих изображений, не относящихся к документам, с синхронным API с улучшенной производительностью, который упрощает внедрение OCR в сценарии взаимодействия с пользователем. |
| Документы: цифровые и отсканированные, включая изображения | книги, статьи и отчеты | Распознаватель документов | Оптимизировано для отсканированных и цифровых документов с асинхронным API для автоматизации интеллектуальной обработки документов в большом масштабе. |
Сведения о Компьютерное зрение общедоступной версии 3.2
Ищете самые последние Компьютерное зрение версии 3.2 ga read? Обратите внимание, что все будущие улучшения распознавания текста для чтения будут частью двух новых служб, перечисленных выше. Дальнейшие обновления Компьютерное зрение версии 3.2 не будут. Чтобы продолжить, ознакомьтесь с обзором и кратким руководством по Компьютерное зрение версии 3.2.
Использование OCR
Попробуйте OCR с помощью Vision Studio. Затем перейдите по одной из ссылок на выпуск Read в последующих разделах, которые лучше всего соответствуют вашим требованиям.
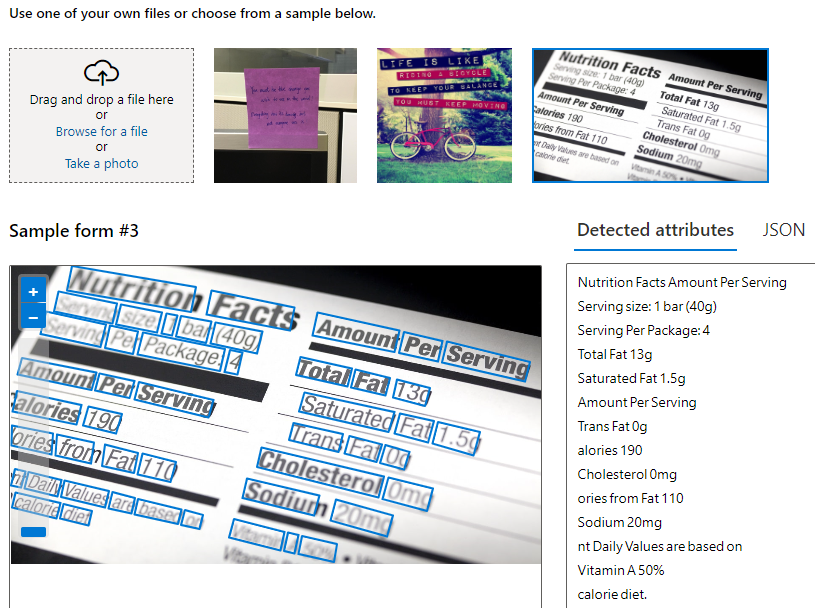
Поддерживаемые языки распознавания текста
Обе версии для чтения, доступные сегодня в Компьютерное зрение поддерживают несколько языков для печатного и рукописного текста. Распознавание текста для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского, русского, арабского, хинди и других международных языков, использующих латинский, кириллица, арабский и деванагари. Распознавание текста для рукописного текста поддерживает английский, китайский (упрощенное письмо), французский, немецкий, итальянский, японский, корейский, португальский и испанский языки.
Общие функции распознавания текста
Модель чтения OCR доступна в Компьютерное зрение и Распознаватель документов с общими базовыми возможностями при оптимизации для соответствующих сценариев. В следующем списке перечислены общие возможности:
- Извлечение печатного и рукописного текста на поддерживаемых языках
- Страницы, текстовые строки и слова с оценкой расположения и достоверности
- Поддержка смешанных языков, смешанный режим (печать и рукописный ввод)
- Функция доступна как контейнер Distroless Docker для локального развертывания
Использование облачных API OCR или развертывание локальной среды
Облачные API являются предпочтительным вариантом для большинства клиентов из-за простоты интеграции и быстрой производительности. Azure и служба Компьютерное зрение обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы можете сосредоточиться на обслуживании своих клиентов.
Для локального развертывания контейнер Read Docker (предварительная версия) позволяет развернуть общедоступные возможности OCR Компьютерное зрение версии 3.2 в собственной локальной среде. Контейнеры соответствуют конкретным требованиям к безопасности и управлению данными.
Конфиденциальность и безопасность данных OCR
Как и в случае со всеми другими Cognitive Services, разработчикам, использующим API компьютерного зрения, следует учитывать политику корпорации Майкрософт касательно клиентских данных. Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Дальнейшие действия
- Распознавание текста для общих (недокументных) изображений. Воспользуйтесь кратким руководством по REST API анализа изображений Компьютерное зрение 4.0 предварительной версии.
- OCR для документов PDF, Office и HTML, а также изображений документов: начните с Распознаватель документов Чтение.
- Ищете предыдущую общедоступную версию? Ознакомьтесь с краткими руководствами по пакету SDK для Компьютерное зрение 3.2 или REST API.
Источник: learn.microsoft.com
Что такое оптическое распознавание символов?

Оптическое распознавание символов (OCR) – это процесс преобразования изображения текста в машиночитаемый текстовый формат. Например, при сканировании бланка или квитанции, компьютер сохраняет скан в виде файла изображения. Текстовый редактор невозможно использовать для редактирования, поиска или подсчета слов в файле изображения. OCR помогает преобразовать изображение в текстовый документ, содержимое которого хранится в виде текстовых данных.
В чем заключается важность OCR?
Большинство рабочих процессов связано с получением информации из печатных изданий. Любой бизнес-процесс предусматривает бланки, счета, отсканированные юридические документы и контракты, напечатанные на бумажном носителе. Такие большие объемы бумажной работы требуют много времени и места для хранения и обработки. Хотя безбумажный документооборот — это путь вперед, сканирование документа в изображение создает определенные трудности. Этот процесс требует ручного вмешательства и может быть утомительным и медленным.
При оцифровке содержимого документа создаются файлы изображений со скрытым в них текстом. Программы обработки текста не могут обработать текст в изображениях. Технология OCR решает эту проблему путем преобразования изображения в текстовые данные, которые могут быть проанализированы офисным ПО. Затем такие данные можно использовать для аналитики, оптимизации операций, автоматизации процессов и повышения производительности.
Как работает OCR?
Технология OCR включает следующие этапы:
Получение изображения
Сканер считывает документы и преобразует их в двоичные данные. ПО OCR анализирует отсканированное изображение и классифицирует светлые области как фон, а темные — как текст.
Предварительная обработка
Чтобы подготовить текст к распознаванию, ПО OCR очищает изображение и удаляет ошибочные области. Применяются следующие методы очистки:
- Выравнивание и устранение уклона отсканированного документа для облегчения распознавания.
- Сглаживание контраста или удаление пятен цифрового изображения и сглаживание краевых эффектов текстовых изображений.
- Стирание рамок и линий на сканированном изображении.
- Распознавание шрифтов для многоязычной технологии OCR
Распознавание текста
Существует два основных типа алгоритмов OCR или программных процессов, которые использует ПО OCR для распознавания текста: сопоставление шаблонов и выделение признаков.
Сопоставление шаблонов
Сопоставление шаблонов работает путем выделения изображения символа, называемого глифом, и сравнения его с аналогичным глифом, хранящимся в памяти. Распознавание образа произойдет только в том случае, если шрифт и масштаб хранящегося глифа совпадают со шрифтом и масштабом отсканированного глифа. Данный метод эффективен при работе со сканами документов, набранных известным шрифтом.
Выделение признаков
Выделение признаков разбивает или раскладывает глифы на такие признаки, как линии, замкнутые контуры, направление линий и пересечения линий. Затем признаки используются для поиска наилучшего или ближайшего подходящего соответствия среди различных хранящихся глифов.
Окончательная обработка
После анализа система преобразует извлеченные текстовые данные в компьютерный файл. Некоторые системы OCR могут создавать аннотированные PDF-файлы, включающие как предыдущую, так и последующую версии отсканированного документа.
Какие виды OCR существуют?
Специалисты по анализу данных классифицируют различные виды технологий OCR на основе их использования и применения. Ниже представлены лишь некоторые примеры:
Программы простого оптического распознавания символов
Простой механизм OCR применяет множество различных хранимых шаблонов шрифтов и изображений текста в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления шаблонов для посимвольного сравнения изображений текста с внутренней базой данных. Подход, при котором система сопоставляет текст слово за словом, называется оптическим распознаванием слов. Он имеет свои ограничения, поскольку существует практически неограниченное количество шрифтов и стилей почерка, и каждый отдельный тип не может быть учтен и сохранен в базе данных.
Программы интеллектуального распознавания символов
Современные системы OCR используют технологию интеллектуального распознавания символов (ICR) для считывания текста так же, как это делает человек. Они используют передовые методы машинного обучения человеческим навыкам чтения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Она ищет различные атрибуты изображения (кривые, линии, пересечения и петли) и объединяет результаты различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обрабатывает изображения по символам, процесс не занимает много времени, а результаты получаются за считанные секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тому же принципу, что и ICR, но обрабатывают изображения целых слов без предварительного выделения символов в изображении.
Оптическое распознавание знаков
Оптическое распознавание знаков позволяет идентифицировать логотипы, водяные знаки и другие обозначения в документе.
В чем заключаются основные преимущества OCR?
Специалисты по анализу данных классифицируют различные виды технологий OCR на основе их использования и применения. Ниже представлены лишь некоторые примеры:
Программы простого оптического распознавания символов
Простой механизм OCR применяет множество различных хранимых шаблонов шрифтов и изображений текста в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления шаблонов для посимвольного сравнения изображений текста с внутренней базой данных. Подход, при котором система сопоставляет текст слово за словом, называется оптическим распознаванием слов. Он имеет свои ограничения, поскольку существует практически неограниченное количество шрифтов и стилей почерка, и каждый отдельный тип не может быть учтен и сохранен в базе данных.
Программы интеллектуального распознавания символов
Современные системы OCR используют технологию интеллектуального распознавания символов (ICR) для считывания текста так же, как это делает человек. Они используют передовые методы машинного обучения человеческим навыкам чтения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Она ищет различные атрибуты изображения (кривые, линии, пересечения и петли) и объединяет результаты различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обрабатывает изображения по символам, процесс не занимает много времени, а результаты получаются за считанные секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тому же принципу, что и ICR, но обрабатывают изображения целых слов без предварительного выделения символов в изображении.
Оптическое распознавание знаков
Оптическое распознавание знаков позволяет идентифицировать логотипы, водяные знаки и другие обозначения в документе.
В чем заключаются основные преимущества OCR?
Ниже приведены основные преимущества технологии OCR:
Текст с возможностью поиска
Предприятия могут преобразовывать имеющиеся и новые документы в базу знаний с возможностью полноценного поиска. ПО для автоматической обработки текстовой базы позволяет совершенствовать базу знаний предприятия.
Эффективность работы
Применение ПО OCR позволяет повысить эффективность работы путем автоматической интеграции документооборота и цифровых рабочих процессов. Вот несколько примеров того, что может сделать ПО OCR:
- Сканирование заполненных вручную форм для автоматизированной проверки, рассмотрения, редактирования и анализа. Такой подход сокращает время ручной обработки документов и ввода данных.
- Поиск необходимых документов с помощью быстрого поиска термина в базе данных, вместо ручного перебора файлов в ящике.
- Преобразование рукописных заметок в редактируемые тексты и документы.
Решения искусственного интеллекта
OCR часто является составляющей других решений в области искусственного интеллекта, которые могут внедрять предприятия. К примеру, OCR может применяться для сканирования и распознавания номерных знаков и дорожных указателей в самоуправляемых автомобилях, выявления логотипов брендов в сообщениях в социальных сетях или идентификации упаковки продукта в рекламных изображениях. Такие технологии искусственного интеллекта помогают предприятиям принимать более эффективные маркетинговые и операционные решения, которые позволяют сократить расходы и улучшить качество обслуживания клиентов.
Для чего применяется OCR?
Ниже перечислены некоторые распространенные случаи использования OCR в различных отраслях:
Банковская сфера
Банковская сфера использует OCR для обработки и проверки документов по кредитам, депозитных чеков и других финансовых операций. Такая проверка позволила повысить эффективность борьбы с мошенничеством и укрепить безопасность транзакций. Например, BlueVine, финансовая технологическая компания, предоставляющая финансирование малому и среднему бизнесу, использовала Amazon Textract, облачный сервис OCR, для разработки продукта, с помощью которого малые бизнесы в США могут быстро получить доступ к кредитам по Программе защиты заработной платы (PPP) в рамках пакета мер по стимулированию экономики в условиях COVID-19. Amazon Textract автоматически обрабатывал и анализировал десятки тысяч форм PPP в день, благодаря чему BlueVine смогла помочь нескольким тысячам предприятий получить средства и сохранить более 400 000 рабочих мест.
Здравоохранение
В системе здравоохранения OCR используется для обработки историй болезни пациентов, включая лечебные процедуры, анализы, больничные карты и страховые выплаты. OCR помогает оптимизировать рабочий процесс и сократить объем ручной работы в больницах, а также поддерживать актуальность записей. Например, компания nib Group обеспечивает медицинское страхование более 1 миллиона австралийцев и ежедневно получает тысячи заявок на выплату страхового возмещения за получение медицинских услуг. Клиенты компании могут сфотографировать свой медицинский счет и отправить его через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, что позволяет компании гораздо быстрее рассматривать заявки.
Логистика
Логистические компании используют OCR для более эффективного отслеживания этикеток на упаковках, счетов, квитанций и других документов. Например, компания Foresight Group использует Amazon Textract для автоматизации обработки счетов в SAP. Ввод таких документов вручную отнимал много времени и приводил к ошибкам, поскольку сотрудникам Foresight приходилось вводить данные в несколько систем бухгалтерского учета. Благодаря Amazon Textract программное обеспечение компании Foresight стало более точно считывать символы на различных носителях и повысило эффективность ведения бизнеса компании.
Как AWS может помочь с OCR?
AWS предлагает две услуги, которые могут помочь внедрить OCR в бизнесе:
Amazon Textract – это сервис машинного обучения (ML), который с помощью OCR автоматически извлекает печатный и рукописный текст и данные из отсканированных документов (например, PDF-файлов). Сервис позволяет быстро считывать тысячи различных документов различных носителей и форматов. После извлечения информации из документов Amazon Textract присваивает уровень уверенности, что дает возможность принимать обоснованные решения о том, как использовать полученные результаты.
Amazon Rekognition может анализировать миллионы изображений и видеозаписей за считанные минуты и дополнять задачи визуальной проверки, выполняемые человеком, с помощью искусственного интеллекта. Для извлечения текста из изображений и видео можно использовать API Amazon Rekognition. В нем имеется возможность распознавать искаженный и деформированный текст из изображений и видеозаписей дорожных знаков, публикаций в социальных сетях и упаковок продуктов.
Создайте учетную запись AWS и начните работу с технологией OCR уже сегодня.
Источник: aws.amazon.com
OCR для распознавания документов и автоматического ввода данных
Арнольд работает страховым консультантом. Ежедневно он тратит 2 часа на правку отчетов и оформление страховых полисов. Агентов в фирме много, но всех объединяет одна проблема: слишком много ручной работы. Время, потраченное на набор текста и исправление ошибок, лучше потратить на общение с клиентами или развитие новых навыков. Все это негативно отражается на бизнесе.
Чтобы оптимизировать работу, сократите бессмысленный ручной труд. В этом поможет OCR.
Что такое OCR?
Оптическое распознавание символов или OCR — это технология для переноса бумажного документа или цифрового изображения в текстовый документ, который легко читать, копировать и редактировать.
OCR пригодится там, где нужно обрабатывать большие объемы текста или работать с бумажными носителями. Страховые компании, банки, государственные учреждения, транспортные компании. Все, кто хочет извлечь текст из изображения, могут делать это проще и быстрее.
Как это работает?
Потребуется цифровое изображение или бумажная распечатка. Специальная программа распознает текст на бумаге или изображении и переводит его в редактируемый текст. Дальше — полная свобода действий и минимум потраченного времени.
Для компании Арнольда мы разработали специальный алгоритм обработки паспортов и водительских прав. Страховые агенты просто фотографируют нужный документ на телефон. Программа сама заполняет ФИО, серию, номер паспорта и другие поля заявления.

В чем выражается польза?
Вы работаете быстрее
Раньше на оформление страховки требовалось 15-20 минут. С помощью нашего OCR-софта все решается за 5 минут и 3 простых шага:
- Сотрудник фотографирует документ
- Поля электронного заявления заполняются автоматически
- Быстро проверяет текст на наличие ошибок
Вы работаете с удовольствием
Чем меньше рутинной работы, тем лучше. Монотонное печатание утомляет. Просто наведите камеру телефона на паспорт, права или любой другой документ. Программа распознает текст и автоматически заполнит необходимые поля.
Так Арнольд и его коллеги перестали тратить время на ручную печать и освободили время для настоящей работы.
Как мы распознавали документы для страховой компании
Рассказываем, как работаем над алгоритмами распознавания текста. С небольшими изменениями процесс общий для обработки любых бумажных документов. Указанные ниже методы мы использовали для распознавания паспорта и водительских прав.
- Локализация
- Фильтрация
- Извлечение строк
- Распознавание текста по символам или по строкам
Локализация
Это нахождение документа на изображении. Для локализации мы пробовали три основных подхода:
- OpenCV и обученный классификатор Хаара
- Полносверточные нейронные сети
- Аналитический подход на основе поиска связных компонент
В первом подходе документ помечается прямоугольником и обрезается до тех пор, пока в рамке не останется выделенной область с текстом; если документ на видео не найден, то алгоритм продолжает поиск в видеопотоке.
Во втором подходе мы применяем полносверточные нейронные сети. На вход сети подается цветное изображение паспорта. На выходе формируется два канала: первый используется для поиска центра первой страницы паспорта, второй — для поиска центра второй страницы. При этом сеть тренируется предсказывать маску, в которой над центрами страниц паспорта находятся гауссовы пики.
Третий подход мы применили для распознавания паспорта. Использовали шаблон, где на развороте паспорта находились две области с серией и номером документа. Если такой шаблон в кадре, то перед нами паспорт. В основе данного подхода лежит поиск связанных компонент. Смотрите видео ниже.
Фильтрация
Фон документов ламинированный, с бликами света и водяными знаками. Для нейронной сети все это — шум, который мешает распознавать символы. Поэтому мы этот шум постарались убрать. Для этого использовали:
- Алгоритм фильтрации шума fastNlMeansDenoisingColored с окном подходящего размера для затирания линий
- Билатеральный фильтр для получения однородного фона
- Метод адаптивной бинаризации
Извлечение строк
Для водительских прав мы применили OpenCV и детектировали контуры букв.Затем мы разбивали строки на буквы, которые потом подавали на вход нейронной сети для распознавания.

Для извлечения строк паспорта мы применили полносверточную нейронную сеть.
Распознавание текста
Для распознавания текста мы использовали нейронные сети. Текст на правах мы распознавали по буквам с помощью сверточной нейронной сети, обученной на большом датасете изображений букв. Для создания и обучения нейронной сети мы использовали фреймворк Torch.
Текст в паспорте также распознавали с помощью полносверточной нейронной сети. Регистр буквы при распознавании не учитывается. Для обучения сети мы подготовили специальный скрипт — генератор обучающей выборки:

1. Водительское удостоверение
3. Исполняемый бинарный файл
4. Исходные коды C++, из которых собран исполняемый файл
5. Lua скрипт, осуществляющий работу с нейросетью. В нем описана архитектура сети.
6. Бинарный файл с весами сети, подгружаемый Lua скриптом. Веса получены после обучения сети
Почему вашему бизнесу нужны наши алгоритмы распознавания текста
Комбинируя различные подходы, мы добились точности распознавания 90%. Это больше, чем предлагают доступные на рынке инструменты.
Высокая точность достигается за счет специализированного подхода. Мы проверяем множество гипотез и выбираем то, что работает лучше для конкретной бизнес-задачи.
Используйте OCR в бизнесе для распознавания документов. Так вы повысите скорость работы, увеличите продуктивность и освободите сотрудников от малоэффективного ручного труда.
Сохранить в Pocket
- Поделиться в Facebook
- Share on Linkedin
- Запостить в Twitter
- Сохранить в Pocket
- 0 Репосты
Подпишитесь
Оставьте адрес, и каждый месяц мы будем высылать свежую статью
о новых трендах в разработке програмного обеспечения.
Источник: www.azoft.ru
Зачем нужны программы распознавания текста OCR, самая известная из них
Мы разобрались с принципами работы систем оптического распознавания символов. Кратко ознакомились с историей развития технологий OCR. В публикации рассмотрим, зачем нужны программы для распознавания текста, назовём наиболее распространённые из них. Какие приложения для работы со сканами знаете вы? А кроме FineReader?
Цель применения приложений
При помощи сканера, камеры смартфона или фотоаппарата создаются цифровые копии бумажных документов. Воспринимать их содержимое на дисплее компьютера и ноутбука комфортно. На портативных устройствах просматривать страницу, содержимое которой не помещается на экран, неудобно. Придётся постоянно перетаскивать изображение по дисплею, масштабировать его.
Использовать скан книги, выдержки из периодического издания в качестве цитаты или исходника для работы (реферата, доклада, курсовой работы) можно после превращения картинки в текст. Для этого следует осуществить распознавание документа. Помогут в этом системы оптического распознавания информации – приложения, которые извлекают из графических файлов текстовую информацию, передают её в текстовый редактор или документ. Вследствие появляется возможность её редактирования, обработки.

Часто поверх изображения накладывается текстовый слой, как на картинке выше. Так сохраняется внешний вид страниц книги и появляется возможность копирования, редактирования её содержимого.
Сканеры с программным обеспечением для распознавания символов широко применяются в библиотеках, архивных фондах для оцифровки бумажных книг, журналов, газет, брошюр, писем, прочих рукописей и бумажных документов с возможностью их дальнейшего редактирования или извлечения текстовой информации. Корпорация Google около 20 лет занимается оцифровкой архивов и книг, исторических источников.
Сколько времени займёт набор на клавиатуре пары цитат длиной в несколько абзацев? Считанные минуты. Если для выполнения курсовой или дипломной работы нужно набрать с десяток страниц, уйдут часы. Программы распознавания текста (OCR) решат проблему за десятки секунд, причём они справляются с сохранением структуры документа.
Приложения определяют наличие таблиц, картинок, диаграмм, списков, справляются с текстом на нескольких языках, формулами. Они сохраняют тип и размер шрифта, способны очищать исходное изображение от дефектов: потёртости, желтизна бумаги, огрехи печати, перегибы страниц и прочее.
Примеры
- CuneiForm;
- SimpleOCR;
- MyScript Stylus;
- Office Lens;
- Readiris 17;
- Readiris Pro;
- Freemore OCR;
- Scanitto Pro.
Самой известной программой оптического распознавания текстов является FineReader от компании ABBYY. Из инструмента для оцифровки файлов она превратилась в мощный инструмент для работы с цифровыми документами. Также разработаны десятки веб-сервисов для решения поставленной задачи.
Источник: bingoschool.ru
Программа для распознавания текста: ТОП-7 лучших утилит
Оптическое распознавание текста – процесс, при котором сфотографированный или отсканированный текст, с помощью специальной программы, переводится в формат документа.
То есть, вместо картинки вы будете иметь стандартный набранный текст, который можно редактировать.
В данном материале мы обсудим, какая программа для распознавания текста лучше (ТОП-7 утилит приведены ниже).

Содержание:
- Выбор
- Технические характеристики
- Abbyy Fine Reader
- OCR Cunei Form
- Readiris Pro
- OCR Freemore
- Abbyy Screenshot Reader
- Adobe Acrobat
- Free Online OCR
- Вывод
Выбор
Как же выбрать наиболее подходящую программу, и какие основные особенности имеет такой софт?
Отличаться он может по разным показателям – точности распознавания, способности работать с тем или иным языком, возможности сохранять исходную структуру текста и т. п.
Такой софт может распространяться платно и бесплатно, и быть реализован как онлайн (в виде особых сервисов), так и в форме предустанавливаемых программ.
Алгоритм работы заключается в том, что для каждой буквы алфавита составляется база вариантов того, как она может выглядеть на фото, выделяются и сохраняются ее основные элементы. Как только такие элементы обнаруживаются на фото, программа распознает соответствующую букву. В зависимости от того, насколько качественно и подробно была составлена такая база, зависит качество распознавания материала в итоге.
Потому важно, чтобы софт был рассчитан на работу именно с русским языком (некоторые программы могут работать с текстом, написанным сразу на двух языках, другие – нет).
Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста (таблицы, списки), тип его оформления (отступы и т. п.) и даже шрифт.
В каких же случаях такой софт необходим?
- При создании документов, когда имеется только распечатанный вариант;
- При составлении рефератов, докладов и необходимости процитировать в них большой отрывок текста из книги;
- Для редакторских работ, когда текст имеется лишь в формате фото и т. д.
На самом деле сфера использования софта очень велика, и правильно выбранный, он способен облегчить и ускорить работу с текстом.
Технические характеристики
Софт отличается по многим параметрам: способу реализации (онлайн или в виде утилиты), лицензии на использование (платно или бесплатно), списку распознаваемых языков, качеству распознавания и другое.
Для того, чтобы пользователь мог сделать правильный выбор максимально быстро, ниже в таблице приведены основные характеристики таких программ.
| Платно, с бесплатным пробным периодом на 10 дней | да | да | да | частично | частично | да |
| Бесплатно | да | да | нет | да | нет | да |
| Платно, с бесплатным пробным периодом на 14 дней | нет | да | нет | да | да | да |
| Бесплатно | да | нет | нет | да | нет | да |
| Платно, с бесплатным пробным периодом на 14 дней | нет | да | да | нет | нет | частично |
| Платно, с бесплатным пробным периодом на 7 дней | да | нет | нет | частично | нет | частично |
| Бесплатно | нет | нет | нет | нет | частично | да |
Все утилиты, перечисленные в таблице, ниже описаны подробно, и размещены в порядке ТОПа, от лучшей к худшей.
Источник: geek-nose.com