
Как явствует из предыдущих разделов — аппарат виртуальной памяти является весьма мощным средством. Это не просто абстракция, но самая настоящая «инженерная реализация», обладающая большими возможностями, которые программист, понимающий, что он делает, может смело использовать к вящему улучшению инженерного качества своих программ. И в этом разделе мы рассмотрим один частный случай использования этого аппарата — организацию в программе разделяемых между процессами данных.
В качестве «введения в предмет» нужно сказать, что изоляция адресных пространств разных процессов на физическом уровне , поддерживаемая аппаратурой процессора (т.е. невозможно никаким образом, ни на каком уровне и кому бы то ни было «залезть» в память другого процесса — её просто физически для данного процесса не существует), является большим достоинством, значительно повышающим надёжность, отказоустойчивость и живучесть процессорной программно-аппаратной системы. Однако, она же — именно физическая изоляция — является одновременно и громадным недостатком, поскольку пользователь не обладает сравнимыми «мультизадачными» возможностями. Обычно несколько запускаемых им процессов работают на какую-то общую цель, а, значит, как-то должны обмениваться данными и синхронизировать свою работу, что физически же и невозможно.
Обмен между 1С по-новому! Odata — это просто.
К нашему программистскому счастью распределением страниц памяти по процессам распоряжается всё-таки операционная система, а аппаратура процессора только поддерживает это распределение. И физическая изолированность, которую готов осуществить процессор преодолевается ею весьма просто — достаточно операционной системе распределить одну и ту же страницу физической памяти более, чем в один процесс. т.е., в соответствии с тем, как описано ранее, достаточно своеобразно вести таблицу страниц процесса. Нетрудно видеть, что при этом «не опровергаются никакие принципы», просто возникает своего рода «частный случай», позволяющий не нарушая общего принципа изолированности всё-таки получить «форточку» наружу данного адресного пространства.
Также и очевидно — столь простой и совершенно не затратный способ избирательного преодоления изолированности является одновременно и единственно физически возможным — ничего другого на уровне «выборка данных из оперативной памяти» процессор предоставить не может, поскольку для него не существует никаких «процессов» и «потоков» — процесор в каждый момент времени просто выбирает очередную команду относительно адреса в регистре IP и увеличивает адрес в нём на длину выбранной команды. При переключении же потоков все регистры процессора где-то сохраняются и загружаются значениями, соответствующими другому потоку/процессу — никаких ограничений на использование регистров в «своём» процессе в пользу «чужого» процесса нет.
Поэтому все иные способы преодоления изолированности адресных пространств процессов ( sockets , pipes и т.д.), не связанные явным образом с обменом именно внешней памятью, основаны на вышеизложенном обстоятельстве. Да, наверное, и файлы из этого списка исключать тоже нельзя: если файл — глобальный объект, если система гарантирует упорядочение обращений к нему из нескольких процессов сразу, то, наверное, какие-то управляющие файлом структуры внутренне она между процессами разделяет?
Настройка синхронизации данных 1C. Урок 1. Первый этап настройки
Заметим — ничего более примитивного для организации разделения данных в системе не существует. Слово «примитивный» здесь употреблено в очень уважительном значении и означает, что нет другого механизма, на котором был бы основан данный механизм проекции одной страницы в несколько адресных пространств. Он сам — базовый, самый малозатратный.
Но, что определённо сбивает с толку, так это упоминание в его названии слова «файл». Файлы — это очень громоздкие сущности, требующие для своего обслуживания огромной скрытой от программиста работы.
Это верно, но, если внимательно читать соответствующий раздел, можно заподозрить одно обстоятельство — вполне возможно, что в реализации данного механизма от «файла» в нём используется, может быть, и не более, чем одно название. Понеже это не файл проецируется в память, это, скорее, страницы оперативной памяти отображаются на пространство файла.
Так что подстрочный перевод термина memory-mapped files не совсем семантически и верен. Предположение это вполне подтверждается при внимательном чтении MSDN — параметр hFile функции CreateFileMapping не обязан всегда быть корректным дескриптором файла. Если его значение — INVALID_HANDLE_VALUE , то система всё равно создаст проекцию «файла», но уже — проекцию, отображаемую в системный страничный файл подкачки! Если уж и этот файл считать «файлом», а не какой-то особо выделенной областью на диске с организованным к ней сверхбыстрым доступом, то, наверное, надо признать, что проекция файлов всё-таки основана на «файле».
Но, тем не менее, слово «файл» там присутствует? Да. А почему? Тогда зададимся и вопросом — можно ли было бы сделать то же самое разделение как-то иначе? Ведь основное правило проекции физических страниц — одна и та же физическая страница памяти в разных адресных пространствах может быть помещена по совершенно произвольным адресам.
И содержимое этой страницы во всех этих адресных пространствах физически будет одним и тем же (и совершенно самопроизвольно будет обеспечиваться его когерентность), а вот её логические адреса в разных адресных пространствах совпадать не будут. Только вот понятия неадресной ссылки на физическую страницу, т.е.чего-то наподобие «имени страницы», в системе нет — страницы физической памяти в механизме памяти виртуальной являются только способом доступа, памятью не основной, а вспомогательной.
Так что делать-то нечего — для корректной ссылки на одну и ту же сущность не имеющую однозначного адреса придётся применять что-то другое, уже имеющее однозначную ссылку. Такой сущностью в этой связке и выступает «файл» — вот его-то дескриптор, а в более широком смысле — его имя, во всех процессах точно именует одно и то же. Так что программист, работающий только в своём процессе на это «одно и то же» может совершенно уверенно сослаться. Нужен ли будет для этой проекции отдельный физический файл, или система всё устроит со своим страничным файлом для собственно точного именования неважно, поэтому проекцию файла в память можно рассматривать также и как «регион в адресном пространстве, именуемый дескриптором (именем) файла».
Но, для полноты картины, нужно также сказать и о том, для чего был придуман «механизм проекции файлов», без этого представление обо всём вместе будет явно неполным. Основное системное предназначение механизма проекции — отобразить в память образ исполнимого файла, содержащего программу.
В системах DOS и Windows 3.x загрузка происходила просто — система перегоняла файл целиком с диска в буфер основной памяти. Памяти при этом часто не хватало, загрузка происходила долго и образ файла не мог превысить размера свободной физической памяти.
А поскольку загрузка файла на исполнение — одна из основных операций, то это самым неблагоприятным образом отражалось на потребительских свойствах системы. Механизм проекции разом решил все эти проблемы — и исполнимый файл в формате PE (Portable Executable) можно загрузить в необходимое число регионов (в каждый — по сегменту), и доступ к страницам образа организуется по мере надобности, а не тогда, когда именно весь большой файл будет загружен, и размер физической памяти для размещения всего комплекса модулей, составляющих задачу перестал иметь какое-либо значение.
А, главное, — если в несколько изолированных адресных пространств загружается один и тот же образ DLL теперь это не означает, что пространство им занимаемое должно несколько раз дублироваться. Его страницы могут быть спроецированы в несколько адресных пространств «непосредственно» — вот откуда берёт начало и к чему приводит именно механизм проекции физических страниц (и знание этого обстоятельства для нашего изложения очень важно — ниже мы его используем). Из этого, впрочем, имеются и другие следствия, не совсем следующие потоку изложения данной статьи. Поэтому интересующийся именно ими читатель приглашается сюда.
Обмен данными в приложениях ОС Windows
Цель данной работы – изучить обмен данными в приложениях OS Windows.
В теоретической части курсовой работы будут рассмотрены следующие вопросы:
Обмен данными: статический обмен данными, динамический обмен данными.
Технология OLE.
Использование OLE в Office: связывание, внедрение.
Введение . 3
Теоретическая часть . 5
Глава 1. Обмен данными .5
1.1. Статический обмен данными 5
1.2. Динамический обмен данными (DDE) 9
Глава 2. Технология OLE 12
Глава 3. Использование OLE в Office 14
3.1. Связывание 14
3.2. Внедрение 15
Практическая часть 17
1. Общая характеристика задачи. 17
2. Описание алгоритма решения задачи. 19
Заключение 25
Список использованной литературы 26
Прикрепленные файлы: 1 файл
Федеральное государственное образовательное учреждение
высшего профессионального образования
«Финансовый университет при Правительстве Российской Федерации»
По дисциплине: «Информатика»
«Обмен данными в приложениях ОС Windows»
Выполнила: Смирнова Татьяна Игоревна
Факультет: непрерывного обучения
Направление: бакалавр менеджмента и маркетинга
Группа: день, 1 курс, повышенный уровень
Преподаватель: Кручинин И. И.
Теоретическая часть . 5
Глава 1. Обмен данными .5
1.1. Статический обмен данными 5
1.2. Динамический обмен данными (DDE) 9
Глава 2. Технология OLE 12
Глава 3. Использование OLE в Office 14
3.1. Связывание 14
3.2. Внедрение 15
Практическая часть 17
1. Общая характеристика задачи. 17
2. Описание алгоритма решения задачи. 19
Список использованной литературы 26
Актуальность темы заключается в довольно широком применении технологии обмена данными в среде Windows. Механизм обмена данных между приложениями – жизненно важное свойство многозадачной среды. Windows позволяет работать одновременно нескольким приложениям, поэтому часто было бы желательным, чтобы эти приложения во время работы использовали бы данные совместно.
В отличие от профессиональных операционных систем, где механизм обмена данными между программами доступен только программисту, в Windows это делается очень просто и наглядно для пользователя. Специальный почтовый ящик (Clipboard) Windows позволяет пользователю переносить информацию из одного приложения в другое, не заботясь об ее форматах и представлении. В настоящее время производители программного обеспечения пришли уже к выводу, что для переноса данных из одного приложения в другое почтового ящика уже недостаточно. Появились более новые, универсальные механизмы, которые позволяют переносить из одного приложения в другое разнородные данные. Об этих механизмах и правилах их применения в среде Windows и пойдет речь в теоретической части курсовой работы.
Цель данной работы – изучить обмен данными в приложениях OS Windows.
В теоретической части курсовой работы будут рассмотрены следующие вопросы:
- Обмен данными: статический обмен данными, динамический обмен данными.
- Технология OLE.
- Использование OLE в Office: связывание, внедрение.
В практической части будет решена задача на формирование сводной ведомости учета изготавливаемой продукции ООО «Красный Октябрь»
Для выполнения курсовой работы использовался следующий состав ТО и ПО: процессор Pentium IV, ОС Windows XP Professional, MS Word 2003, MS Excel 2003.
Глава 1. Обмен данными
Одним из наиболее важных достоинств системы Windows является обмен данными между различными приложениями. Например, после создания документа его можно копировать целиком или частично в другие документы, экономя время и уменьшая количество потенциальных ошибок. В большинстве программ для Windows можно копировать и перемещать между документами данные различных типов — графические картинки (подготовленные графическим редактором MS Paint), диаграммы (подготовленные программой Ехсеl) и т.п.
Система Windows поддерживает два различных типа обмена данными – статический и динамический. Статический обмен может быть выполнен с помощью буфера обмена. Динамический обмен данными основан на связывании и внедрении объектов (OLE-технологии).
1.1. Статический обмен данными
Во время своей работы операционная система (OC) Windows выделяет специальную область памяти — буфер обмена (Clipboard). Он используется для обмена данными между приложениями и документами. Роль данных могут играть фрагмент текста или весь текст, рисунок, таблица и т. п. Буфер обмена — это простейшее, но очень эффективное средство интеграции приложений.
В ОС Windows через буфер обмена можно перемещать папки с файлами и отдельные файлы. Существует следующий принцип работы с буфером обмена: с помощью инструментальных средств конкретного приложения можно выделить определенный фрагмент обрабатываемого документа (т. е. участок текста, изображение, таблицу) и поместить его на хранение (записать) в буфер обмена.
Записанный в буфере фрагмент можно вставить либо в другое место того же документа, либо в другой документ того же приложения, либо в документ другого приложения. Например, можно переместить картинку (или фрагмент картинки), нарисованную вами в графическом редакторе, в любое место документа Word или Excel.
Записанный фрагмент сохраняется в буфере до тех пор, пока не дана команда поместить в буфер другую порцию данных: в этом случае прежнее содержимое буфера теряется безвозвратно, оно замещается новой информацией. Если такая информация не поступила, фрагмент сохраняется в буфере до окончания сеанса работы Windows.
Запуск и завершение программ сами по себе на содержимое буфера никак не влияют. Один и тот же фрагмент можно вставлять в документы несколько раз: при вставке содержимое буфера обмена не меняется. Работа с буфером обмена. Во всех приложениях Windows, допускающих использование буфера обмена, схема работы с ним стандартизована. Для обмена предусмотрены команды пункта меню Правка:
- Вырезать — переместить выделенный фрагмент в буфер обмена (и удалить его в исходном документе);
- Копировать – скопировать выделенный фрагмент в буфер обмена (исходный документ не меняется);
- Вставить – вставить содержимое буфера обмена в текущий документ приложения (содержимое буфера не изменяется).
Многие приложения дублируют эти команды в кнопках панели инструментов (а также в контекстном меню), и возможно перемещение, копирование или вставка фрагмента простым щелчком мыши на соответствующей кнопке.
Вместо команд работы с буфером обмена можно использовать сочетания клавиш:
- Вырезать — Shift+Del;
- Копировать — Ctrl+Ins;
- Вставить — Shift+Ins.
Следует помнить, что буфер обмена одинаково бесстрастно принимает на хранение и один символ, и графический фрагмент объемом до нескольких мегабайт. Однако в последнем случае производительность компьютера может снизиться, — поэтому не следует оставлять в буфере слишком массивные части информации, которые вам уже не понадобятся. После использования такой информации лучше очистить буфер, послав в него, например любой текстовый символ. Кратко рассмотрим операции: Вырезать, Копировать и Вставить.
- Документ → буфер обмена. Перед выполнением команд – «Вырезать» или «Копировать» необходимо выделить фрагмент, помещаемый в буфер обмена. Если фрагмент не выделен, эти команды недоступны. Способы выделения фрагмента определяются соглашениями конкретной программы, однако существуют и универсальные приемы. Следует отметить, что в команде «Вырезать» совмещены две стандартных операции: удаление выделенного фрагмента и заполнение буфера обмена. Поэтому эта команда более «опасна», чем команда «Копировать».
- Буфер обмена → документ. Если буфер обмена пуст (то есть с момента старта Windows команды «Вырезать» или «Копировать» не выполнялась или буфер очищен специальной командой), операция «Вставить» недоступна. Существует еще много способов заполнения буфера обмена, например, в ОС Windows есть следующая интересная возможность. Если, работая в операционной системе, нажать клавишу Print-Screen, графический образ всего экрана в виде растровой картинки будет скопирован в буфер обмена. Затем можно вставить эту картинку в документ какого-либо редактора (например, Word), отредактировать, если необходимо, и записать в файл. Если нажать клавиши Alt+PrintScreen, в буфер обмена копируется только активное окно.
Куда вставляется фрагмент по команде «Вставить»? Точка вставки определяется соглашениями конкретной программы и характером информации, помещенной в буфер обмена. Например, редактор презентаций PowerPoint вставляет графический фрагмент в центр слайда, давая тем самым возможность вручную переместить новый элемент изображения в нужное место.
Однако текстовый фрагмент практически всегда вставляется в позицию текстового курсора. Процессор Word любой фрагмент вставляет в позицию текстового курсора. Окно буфера обмена.
Для работы с буфером обмена Windows предлагает специальную программу — Просмотр буфера обмена, которую можно вызвать из Главного меню → Программы → Стандартные (в Windows 2000 Окно буфера обмена переименовано в Папку обмена, которая вызывается командой clipbrd). Во-первых, окно этой программы — это настоящее «зеркало» буфера обмена, отображающее текущее содержимое Clipboard.
Во-вторых, это приложение позволяет записать содержимое буфера обмена на постоянное хранение в файл специального формата (с расширением .CLP) и прочитать такой файл в буфер. Это нужно для обмена файлами разных форматов, так как всякая версия ОС Windows может прочитать любые файлы с расширением .CLP Просмотр буфера обмена позволяет с помощью отдельных команд изменить формат вывода фрагмента на экран, а также очистить буфер обмена.
Расширение функций буфера обмена. Приложения Windows устроены таким образом, что буфер обмена часто оказывается полезным даже тогда, когда никаких команд работы с буфером не предусмотрено.
Дело в том, что механизмы выделения, копирования, вставки фрагментов документа (особенно текстовых) чаще всего встроены в приложение, и клавиатурные сочетания Ctrl+Ins и Shift+Ins работают всегда, независимо от функций приложения. Тем самым гибкость такой системы при обмене информацией между базой данных системы и внешними носителями информации значительно расширяется. Например, в системе может отсутствовать функция вставки готового текстового файла в базу данных (файл → база данных), однако пользователю не придется заново набирать такой файл. Достаточно открыть его (например, в приложении Word), скопировать в буфер обмена, а затем вставить данный файл.
1.2. Динамический обмен данными (DDE)
DDE – это разработанный Microsoft набор специальных соглашений (протокол) об обмене данными между приложениями Windows. В самом начале развития персонального компьютера, когда объем памяти на внешнем запоминающем устройстве был мал и дорог, при помощи DDE решали проблему недостатка свободного места на диске.
Так как связываемый документ хранится в виде файла только в одном месте, то при связывании свободное место используется эффективно. Попытаемся пояснить суть этого метода связывания на простом примере. Допустим, требуется составить документ, содержащий сведения о различных программных и аппаратных продуктах (как минимум, краткое описание и цена).
Очевидно, что подготовить данный документ необходимо с помощью текстового редактора, например Word. Представим, что подлежащие внесению в документ сведения о продуктах и их ценах уже существуют в базе данных, которая управляется некоторым Windows-приложением, например Access.
Для ускорения процесса подготовки документа разумно по уже известной методике передать необходимые сведения из базы данных в буфер обмена (Clipboard). Однако вполне возможно, что через некоторое время цены изменятся. При старой методике (через буфер) это приведет к необходимости подготовить документ заново.
Использование DDE-метода позволяет избежать этого, так как обеспечивает динамический обмен данными и обновление их в подготавливаемом документе по мере их изменения в источнике. При таких условиях «выходной» документ всегда будет «первой свежести». Каким же образом происходит актуализация (динамическое обновление данных в выходном документе)?
Разберемся сначала с происхождением обновляемых данных. Они находятся в документе-источнике и хранятся там приложением-источником. Сохранение документа источника и лежит в основе функционирования DDE-метода. Из сохраненного документа-источника требуемые сведения копируются через Clipboard в выходной документ. Процедура этого копирования нам знакома.
Особенность состоит в том, что DDE-метод устанавливает между источником и копиями некоторую связь. И связь эта обеспечивает автоматическое (или по требованию) обновление копии по мере появления изменений в источнике. Многие Windows-приложения поддерживают методику DDE как для создания источников связывания, так и для восприятия динамически обновляемых данных.
Но при практическом применении DDE-метода следует учитывать ряд требований. Первое и наиболее важное состоит в том, что приложения, подлежащие связыванию, должны поддерживать DDE-метод. Важным является также определение, в каком качестве данное приложение будет существовать в DDE: в качестве источника или приемника. Не все приложения можно использовать в обоих качествах.
Данные, являющиеся источником в DDE-операциях, должны быть обязательно сохранены, так как связь осуществляется непосредственно через файлы документов. Рассмотрим способ актуализации без открытия окна. Допустим, что у нас существуют два документа (Источник и Приемник) Word и между ними существует связь посредством DDE.
Предположим, что мы открыли документ Источник и изменили его, затем закрыли окно текстового редактора. Поскольку мы закрыли окно Word, то внесенное изменение осталось теперь только в файле источника на диске. Далее опять запустим Word и загрузим в него оставшийся неизменным файл документа Приемника. Хотя во время внесения изменений в текст, окно приемника было закрыто, целевой Word-документ предстает в актуализированном виде. Это произошло потому, что связь в DDE методе осуществляется не через окна, а через файлы.
Если файл-источник поврежден или перемещен, то связь нарушается и для её восстановления необходимо заново создавать все ссылки. Сейчас DDE вытеснено более новой технологией OLE, которая широко используется в Windows приложениях (об OLE речь пойдет в следующей главе). Однако все же в ряде случаев DDE применяется. На сегодняшний день в DDE можно выделить два уровня:
1. В некоторых приложениях Windows избранные операции DDE встроены в интерфейс программы. Например, в процессоре Word имеется возможность решить следующую задачу. Пусть имеется документ Word, и в этом документе содержится текст «серийного» письма, которое необходимо разослать по нескольким адресам. В этом письме имеются переменные поля с фамилией адресата и его адресом.
Фамилии и адреса содержатся в базе данных MS Access. Надо изготовить несколько экземпляров одного и того же письма, каждый из которых будет отличаться от другого фамилией и адресом. Эту операцию можно выполнить с помощью команды Сервис-Слияние. (Tools-Mail Merge).
2. Второй уровень DDE требует знания некоторых программных средств и может быть использован квалифицированными пользователями или программистами. Суть этого уровня проиллюстрируем примером.
Допустим, программист разработал информационную систему, в которой предусмотрено автоматизированное составление расписания каких-то мероприятий (например, встреч, конференций, семинаров и т. п.). Это расписание надо красиво напечатать (с указанием дат, дней недели, колонтитулов и т. п.). Лучше всего справится с этой задачей процессор Word.
Поэтому программист заготовил в процессоре Word некий шаблон расписания и снабдил его закладками. Итак, можно сказать, что с появлением метода DDE возник качественный скачек в продвижении технологии связывания и совместного использования документов. Но все же остались некоторые недочеты, которые в своем большинстве были исправлены схемой OLE.
Глава 2. Технология OLE
Объектно-ориентированная технология – это термин, за которым скрывается ряд новых методологий анализа, проектирования и программирования. При использовании ОО технологии анализ, проектирование и разработка системы проводятся с помощью объектов. Под объектом понимается «разумный», самодостаточный агент, отвечающий за выполнение определенных системных задач.
Алгоритмическая и объектно-ориентированная декомпозиция. Традиционно сложилось так, что проектирование и реализация программного обеспечения осуществляется с точки зрения функций или алгоритмов. Как правило, мы разделяем сложную задачу на более простые и решаем ее алгоритмически.
При использовании алгоритмической декомпозиции проблема разбивается на фундаментальные функциональные единицы, или подсистемы. После этого каждая подсистема реализуется как набор связанных процедур. Эти процедуры воздействуют на данные, не учитывая присущие этим данным взаимосвязи. Алгоритмическая декомпозиция — это способ решения проблемы с функциональной точки зрения.
При алгоритмической декомпозиции все внимание сосредоточено на том, какие преобразования необходимо выполнить над данными без учета их семантической связи. Можно подойти к решению проблемы по-другому.
Прежде чем изучать функциональные взаимосвязи или интересоваться, что происходит с набором данных, необходимо выявить логически обособленные сущности в предметной области, определить их свойства, взаимосвязи и отношение к решаемой проблеме. Лишь разобравшись в сути проблемы, можно моделировать систему при помощи программного обеспечения.
Такой способ анализа называется объектно-ориентированной декомпозицией. В объектно-ориентированной декомпозиции термины, которые используются при анализе и проектировании, наследуются прямо из предметной области.
Это позволяет моделировать взаимоотношения реального мира естественным и адекватным образом, сохраняя семантические взаимосвязи между функциями и соответствующими данными. Например, при разработке системы резервирования авиабилетов определились бы такие сущности (объекты), как самолеты, маршруты, города и пассажиры.
Пользуясь ОО декомпозицией, необходимо применить понятия, термины конкретной предметной области, а не искусственные конструкции системы разработки программного обеспечения. Объектно-ориентированная декомпозиция — это способ решения проблемы с объектной точки зрения. Употребляя ОО декомпозицию, внимание пользователя фокусируется на конкретном объекте.
Дополнительно устанавливаются логические и семантические связи между объектами, их поведением. Что такое объекты? Объект в ОО технологиях определяется следующим образом: Объект — это самодостаточный программный модуль, который абстрактно описывает физическую или логическую сущность реального мира.
Он скрывает (инкапсулирует) детали своей реализации и имеет общедоступный интерфейс. Объекты являются автономными программными модулями, которым присуши некоторое состояние на данный момент и определенное поведение. Состояние объекта — это его внутренние, то есть закрытые, данные и скрытые детали его реализации. Общедоступный интерфейс формирует поведение объекта.
Он определяет, что объект может делать. Интерфейс реализован как набор функций, называемых методами. Объект включает в себя функции и данные, на которые эти функции воздействуют. Функции и данные, благодаря такой организации, связаны семантически.
Поскольку все объекты в ОО системе имеют семантическую связь, общая структура такой системы является более гибкой и ясной по сравнению с традиционными способами организации. Для современных информационных технологий понятие объекта является основополагающим.
Источник: www.referat911.ru
Межпроцессный обмен
Аннотация: К основным способам межпроцессного обмена традиционно относят каналы и разделяемую память, для организации которых используют разделяемые ресурсы. Анонимные каналы поддерживают потоковую модель, в рамках которой данные представляют собой неструктурированную последовательность байтов. Именованные каналы, поддерживающие как потоковую модель, так и модель, ориентированную на сообщения, обеспечивают обмен данными не только в изолированной вычислительной среде, но и в локальной сети
Введение
Из курса ОС известно, что для выполнения таких задач, как совместное использование данных, построение интегрированных многофункциональных приложений и т.д., различным процессам (а также различным потокам) необходимо взаимодействовать между собой. Поскольку процессы изначально задумывались как обособленные сущности, для обеспечения корректного взаимодействия процессов требуются специальные средства и действия операционной системы.
Известно также, что в основе межпроцессного (Inter Process Communications , IPC ) обмена обычно находится разделяемый ресурс (например, канал или сегмент разделяемой памяти), и, следовательно, ОС должна предоставить средства для генерации, именования, установки режима доступа и атрибутов защиты таких ресурсов. Обычно такой ресурс может быть доступен всем процессам, которые знают его имя и имеют необходимые привилегии.
Кроме того, организация связи между процессами всегда предполагает установления таких ее характеристик, как:
- направление связи. Связь бывает однонаправленная (симплексная) и двунаправленная (полудуплексная для поочередной передачи информации и дуплексная с возможностью одновременной передачи данных в разных направлениях);
- тип адресации. В случае прямой адресации информация посылается непосредственно получателю, например, процессу P-Send (P, message). В случае непрямой или косвенной адресации информация помещается в некоторый промежуточный объект, например, в почтовый ящик;
- используемая модель передачи данных — потоковая или модель сообщений (см. ниже);
- объем передаваемой информации и сведения о том, обладает ли канал буфером необходимого размера;
- синхронность обмена данными. Если отправитель сообщения блокируется до получения этого сообщения адресатом, то обмен считается синхронным, в противном случае — асинхронным.
Кроме перечисленных у каждой связи есть еще ряд особенностей.
Способы межпроцессного обмена.
Традиционно считается, что основными способами межпроцессного обмена являются каналы и разделяемая память ( рис. 7.1), которые базируются на соответствующих объектах ядра.
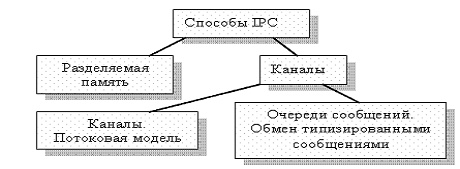
Рис. 7.1. Основные способы межпроцессного обмена
В случае разделяемой памяти два или более процессов совместно используют сегмент памяти. Общение происходит с помощью обычных операций копирования или перемещения данных в памяти (средствами обычных языков программирования).
Каналы предполагают созданные средствами операционной системы линии связи. Двумя основными моделями передачи данных по каналу являются поток ввода-вывода и сообщения. При передаче в рамках потоковой модели данные представляют собой неструктурированную последовательность байтов и никак не интерпретируются системой. В модели сообщений на передаваемые данные накладывается некоторая структура, обычно их разделяют на сообщения заранее оговоренного формата.
Ограниченный объем курса не позволяет рассмотреть другие механизмы межпроцессного обмена, реализованные в ОС Windows , например, сокеты, Clipboard или удаленный вызов процедуры ( RPC ). Исчерпывающая справочная информация на эту тему имеется в MSDN .
Понятие о разделяемом ресурсе
Межпроцессный обмен базируется на разделяемых ресурсах, к которым имеет доступ некоторое множество процессов. При этом возникают задачи создания, именования и защиты таких ресурсов. Обычно один из процессов создает ресурс , наделяет его атрибутами защиты и именем, по которому данный ресурс может быть доступен остальным процессам (даже в случае завершения работы процесса-создателя).
В качестве примера рассмотрим общение через разделяемую память ( рис. 7.2).
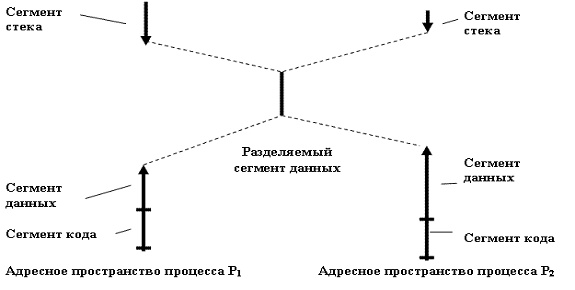
Рис. 7.2. Адресные пространства процессов, взаимодействующих через сегмент разделяемой памяти
В ОС Windows сегмент разделяемой памяти создается с помощью Win32-функции CreateFileMapping (см. рис. 7.3). В случае успешного выполнения данной функции создается ресурс — фрагмент памяти, доступный по имени ( параметр lpname ), который базируется на соответствующем объекте ядра — «объекте-файле, отображаемом в память » с присущими любому объекту атрибутами.
Процессу -создателю возвращается описатель (handle) ресурса. Другие процессы, желающие иметь доступ к ресурсу, также должны получить его описатель. В данном случае это можно сделать с помощью функции OpenFileMapping , указав имя ресурса в качестве одного из параметров.
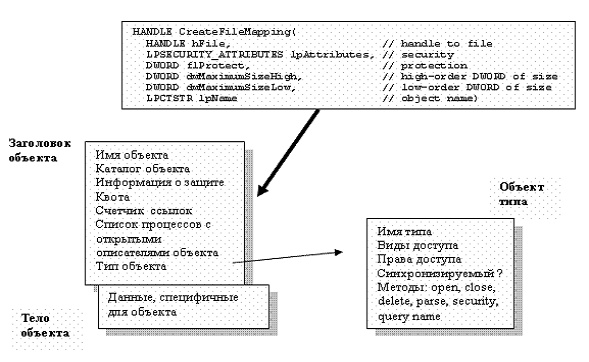
Рис. 7.3. Создание сегмента разделяемой памяти базируется на разделяемом ресурсе, которому соответствует объект ядра
Способы создания и характеристики файлов, отображаемых в память , будут рассмотрены в Части III курса «Система управления памятью», а в рамках данной темы ограничимся сведениями об обмене информации по каналам связи. При этом не надо забывать, что при любом способе общения в рамках одной вычислительной системы всегда будет использоваться элемент общей памяти. Другое дело, что в случае каналов эта память может быть выделена не в адресном пространстве процесса, а в адресном пространстве ядра системы, как это показано на рис. 7.4.
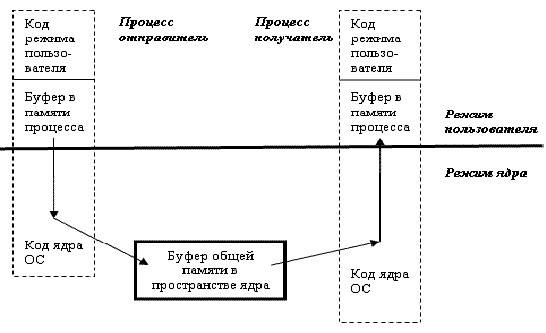
Рис. 7.4. Обмен через каналы связи осуществляется через буфер в адресном пространстве ядра системы
Каналы связи
Основной принцип работы канала состоит в буферизации вывода одного процесса и обеспечении возможности чтения содержимого программного канала другим процессом. При этом часто интерфейс программного канала совпадает с интерфейсом обычного файла и реализуется обычными файловыми операциями read и write . Для обмена могут использоваться потоковая модель и модель обмена сообщениями.
Механизм генерации канала предполагает получение процессом-создателем (процессом-сервером) двух описателей (handles) для пользования этим каналом. Один из описателей применяется для чтения из канала, другой — для записи в канал.
Один из вариантов использования канала — это его использование процессом для взаимодействия с самим собой. Рассмотрим следующее изображение системы, состоящей из процесса и ядра, после создания канала ( рис. 7.5):
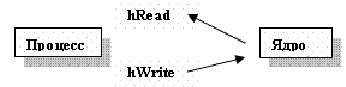
Рис. 7.5. Общение процесса с самим собой через канал связи
Из этого рисунка легко увидеть, что даже если процесс посылает данные самому себе, они проходят через ядро . Следовательно, для организации таких каналов, а также их именования, в ядре должны быть реализованы элементы файловой системы.
Очевидно, что обмен процесса с самим собой через канал большого смысла не имеет, поэтому обычно через канал взаимодействуют два (или более) процессов. Процесс, создающий канал, принято называть сервером, а другой процесс — клиентом. Для общения с каналом клиент и сервер должны иметь описатели (дескрипторы, handles) для чтения и записи.
Процесс- сервер получает описатель при создании канала. Процесс-клиент может получить описатели в результате наследования, в том случае, когда клиент является потомком сервера. Это типично для общения через так называемые анонимные каналы.
Другой способ получения — открытие по имени уже существующего именованного канала неродственным процессом, который в результате также становится обладателем необходимых описателей. Если организация доступа к каналу прошла успешно, то схема взаимодействия может выглядеть так, как показано на рис. 7.6.

Рис. 7.6. Общение процессов через канал связи
Если нужно организовать однонаправленную связь и принято решение о направлении передачи данных, то можно «закрыть» неиспользуемый конец канала. В примере на рис. 7.7 клиент посылает через канал информацию серверу.
Источник: intuit.ru