
5 лучших бесплатных альтернатив Microsoft Access
Microsoft Access — это инструмент для работы с базами данных, который популяризируется благодаря включению его в большинство пакетов Microsoft Office с 1992 года. Как и многие программы для работы с базами данных, Microsoft Access — это сложный инструмент с крутой кривой обучения. Тем не менее, есть альтернативы Microsoft Access, и вот некоторые из лучших.
Зачем использовать альтернативу Microsoft Access?
Является ли Microsoft Access вашим средством доступа к базе данных? Это понятно. Доступ является основной функцией Microsoft Office как для Office 365, так и для отдельных лицензий. Несмотря на рост числа бесплатных альтернатив Microsoft Office, Microsoft Access по-прежнему неизменно входит в топ-10 рейтинга ядра СУБД.
Microsoft Access тоже разделяет мнения. Пользователи Pro-Access указывают на его простоту использования, огромный спектр онлайн-ресурсов, доступных для пользователей всех уровней, а также на мощные инструменты запросов, фильтрации и работы с таблицами.
How to Authorize Kontakt Player libraries
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Пользователи Anti-Access оспаривают отсутствие масштабируемости, разочаровывающее ограничение в 2 ГБ, постоянное использование отдельного файла для базы данных и возможность повреждения базы данных в многопользовательских базах данных. Для других цена Microsoft Access также является камнем преткновения. Другие бесплатные опции базы данных работают так же хорошо, если не лучше, чем Microsoft Access.

LibreOffice Base — отличная отправная точка для тех, кто рассматривает бесплатную альтернативу Microsoft Access. Офисный пакет с открытым исходным кодом остается сильным претендентом на корону Microsoft Office
7 лучших бесплатных альтернатив Microsoft Office
7 лучших бесплатных альтернатив Microsoft Office
Microsoft Office — король офисных пакетов, но это не значит, что он подходит именно вам. Вот некоторые другие офисные апартаменты, которые вам могут понравиться больше!
Прочитайте больше
и последняя версия LibreOffice, 6.1.3, является одной из лучших.
База остается отличной универсальностью, хорошо подходящей как для дома, так и для бизнеса. LibreOffice Base имеет ряд удобных функций, включая поддержку нескольких баз данных для многопользовательских баз данных, таких как MySQL, Adabas D, Microsoft Access и PostgreSQL.
Вероятно, LibreOffice Base находится как можно ближе к прямому клону Microsoft Access. Оба являются интерфейсными инструментами управления базами данных. Вы можете использовать Base для создания достойных приложений баз данных или веб-сайтов, а также выбирать между Firebird или HSQLDB для вашей встроенной базы данных.
Секреты Автоматизации KONTAKT 6 (Native Instruments)

Calligra Suite — это пакет офисного и графического дизайна, разработанный сообществом разработчиков открытого кода KDE. Kexi — это ответ Calligra Suite на Microsoft Access. Kexi предлагает приличное сочетание функций базы данных: ввод данных, запросы, формы, таблицы, отчеты и многое другое. Кроме того, вы можете использовать Kexi в качестве интерфейса для сервера базы данных, такого как MySQL, PostgreSQL или Microsoft SQL Server.
Еще одна удобная функция для пользователей, желающих переключиться, — это помощник по миграции Kexi Microsoft Access. Мастер помогает пользователям переносить базы данных в структуру базы данных Kexi, сохраняя данные и позволяя редактировать приложения.

Axisbase был реализован разочарованным разработчиком, возмущенным ценой принуждения его clientèle платить за Microsoft Access, хотя разработка, кажется, остановилась в январе 2011 года. Axisbase немного отличается от других записей в этом списке тем, что предлагает полное решение для базы данных со знакомым интерфейсом, который похож на Filemaker, Access или Base, но также может выступать в качестве сервера базы данных, такого как MySQL.
Замечания: Axisbase не поддерживает стандартный SQL, поэтому будьте осторожны!
Axisbase — не самая доступная программа для работы с базами данных. Вы будете использовать «строительные блоки» Axisbase для разработки своей базы данных. Строительный блок — это «подмножество данных, список, график, окно или отчет». Строительные блоки могут стать невероятно сложными, такова базовая глубина Axisbase.
Лучшее место для начала — Дом документации Axisbase. Разработчик предоставляет обзор того, сколько систем работает, как вы можете реализовать строительные блоки, и другую важную информацию для развития вашей базы данных.

Symphytum — это персональная визуальная база данных с открытым исходным кодом. Самая большая разница между Symphytum и другими опциями в этом списке — это целевой рынок. Symphytum — это удобный инструмент для персональных баз данных, без необходимости изучать программирование или сложные структуры.
Не позволяйте этому утверждению обмануть вас. Вы по-прежнему можете использовать Symphytum для создания большой визуальной базы данных с множеством настроек. Он очень доступен и имеет несколько удобных функций. Например, вы можете перетаскивать поля с записями, чтобы упорядочить визуальный макет.
Симфитум имеет несколько ограничений, ум. База данных не может «обрабатывать реляционные данные и автоматические вычисления полей». Кроме того, функция импорта CSV оставляет желать лучшего.

Ваша последняя бесплатная альтернатива Microsoft Access также является самой базовой. В этом вы, вероятно, не замените расширенную функциональность Access на PortaBase. Однако PortaBase бесплатна, и вы можете без особых усилий создать базовую базу данных с одной таблицей.
Поскольку это такая базовая программа, изучать тоже нечего. Вы создаете новую базу данных, добавляете нужные поля и начинаете их заполнять. Вы можете импортировать из CSV, XML или MobileDB и экспортировать в CSV, HTML или XML.
Хорошая функция PortaBase — встроенное шифрование файлов. У вас есть возможность зашифровать базу данных с помощью библиотеки шифрования на основе Blowfish, что означает, что шифрование хорошее и надежное. Просто убедитесь, что вы не потеряете свой пароль!
Другие альтернативы Microsoft Access
В списке альтернатив Microsoft Access есть некоторые заметные пропуски.
У вас также есть возможность использовать другие бесплатные базы данных с открытым исходным кодом, такие как MySQL, PostgreSQL, MS SQL, SQLite, Cassandra, MariaDB или один из многих других. Все они представляют собой гибкие, мощные инструменты базы данных, подходящие для широкого спектра задач базы данных.
Тем не менее, для относительной простоты использования, особенно для новых пользователей, желающих поэкспериментировать или освоить свою первую программу управления базами данных, эти варианты представляют собой полное сечение существующего рынка.
Готовы выйти из Microsoft Access? Вот как вы устанавливаете MySQL Community Server на вашем компьютере с Windows
Как установить базу данных MySQL в Windows
Как установить базу данных MySQL в Windows
Если вы часто пишете приложения, которые подключаются к серверам баз данных, было бы неплохо, если бы вы знали, как установить базу данных MySQL на ваш компьютер Windows для тестирования.
Прочитайте больше
,
Узнайте больше о: Microsoft Access.
Сравнение 10 лучших почтовых приложений для Android
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Источник: okdk.ru
3 простых шага по исправлению ошибок NATIVE ACCESS UPDATER.EXE
Tip: В вашей системе запущено много процессов, которые потребляют ресурсы процессора и памяти. Некоторые из этих процессов, кажется, являются вредоносными файлами, атакующими ваш компьютер.
Чтобы исправить критические ошибки native access updater.exe,скачайте программу Asmwsoft PC Optimizer и установите ее на своем компьютере
Очистите мусорные файлы, чтобы исправить native access updater.exe, которое перестало работать из-за ошибки.
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Clean Junk Files».
- Когда появится новое окно, нажмите на кнопку «start» и дождитесь окончания поиска.
- потом нажмите на кнопку «Select All».
- нажмите на кнопку «start cleaning».
Очистите реестр, чтобы исправить native access updater.exe, которое перестало работать из-за ошибки
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Fix Registry problems».
- Нажмите на кнопку «select all» для проверки всех разделов реестра на наличие ошибок.
- 4. Нажмите на кнопку «Start» и подождите несколько минут в зависимости от размера файла реестра.
- После завершения поиска нажмите на кнопку «select all».
- Нажмите на кнопку «Fix selected».
P.S. Вам может потребоваться повторно выполнить эти шаги.
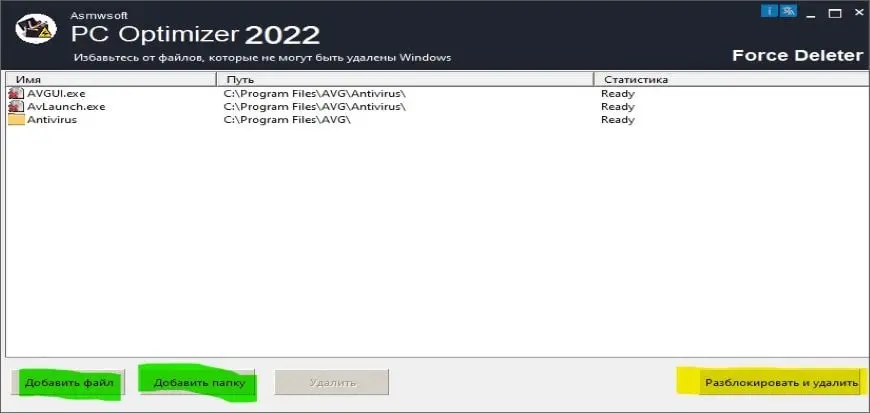
Как удалить заблокированный файл
- В главном окне Asmwsoft Pc Optimizer выберите инструмент «Force deleter»
- Потом в «force deleter» нажмите «Выбрать файл», перейдите к файлу native access updater.exe и потом нажмите на «открыть».
- Теперь нажмите на кнопку «unlock and delete», и когда появится подтверждающее сообщение, нажмите «да». Вот и все.
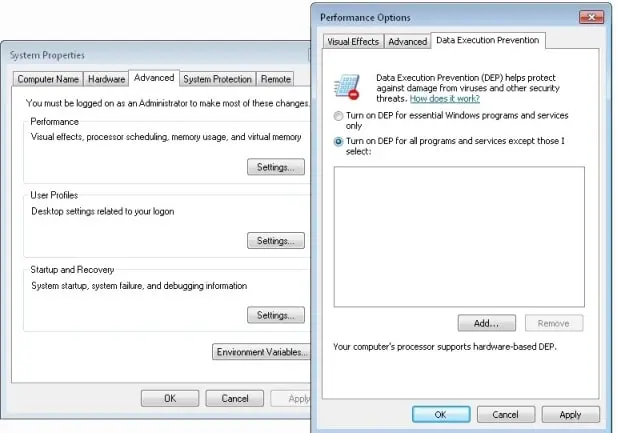
Настройка Windows для исправления критических ошибок native access updater.exe:
- Нажмите правой кнопкой мыши на «Мой компьютер» на рабочем столе и выберите пункт «Свойства».
- В меню слева выберите » Advanced system settings».
- В разделе «Быстродействие» нажмите на кнопку «Параметры».
- Нажмите на вкладку «data Execution prevention».
- Выберите опцию » Turn on DEP for all programs and services . » .
- Нажмите на кнопку «add» и выберите файл native access updater.exe, а затем нажмите на кнопку «open».
- Нажмите на кнопку «ok» и перезагрузите свой компьютер.
Как другие пользователи поступают с этим файлом?
Всего голосов ( 202 ), 133 говорят, что не будут удалять, а 69 говорят, что удалят его с компьютера.
native access updater.exe Пользовательская оценка:
Как вы поступите с файлом native access updater.exe?
Некоторые сообщения об ошибках, которые вы можете получить в связи с native access updater.exe файлом
- (native access updater.exe) столкнулся с проблемой и должен быть закрыт. Просим прощения за неудобство.
- (native access updater.exe) перестал работать.
- native access updater.exe. Эта программа не отвечает.
- (native access updater.exe) — Ошибка приложения: the instruction at 0xXXXXXX referenced memory error, the memory could not be read. Нажмитие OK, чтобы завершить программу.
- (native access updater.exe) не является ошибкой действительного windows-приложения.
- (native access updater.exe) отсутствует или не обнаружен.
NATIVE ACCESS UPDATER.EXE
Описание файла: native access updater.exe Файл native access updater.exe из Native Instruments GmbH является частью Native Instruments SelfUpdateHelperTool. native access updater.exe, расположенный в c program files native instrumentsnative accessnative access updaternative access updater.exe с размером файла 21279344 байт, версия файла 1.0.5 (x64), подпись 60b814621b92783350ecf1c6010096ad.
Проверьте процессы, запущенные на вашем ПК, используя базу данных онлайн-безопасности. Можно использовать любой тип сканирования для проверки вашего ПК на вирусы, трояны, шпионские и другие вредоносные программы.
Источник: www.exedb.com
Caché Native Access — работаем с нативными библиотеками в Caché

Картинка для привлечения внимания
Как известно, Caché это не только СУБД, но и полноценный язык программирования (Caché ObjectScript). И со стороны СУБД, и со стороны Caché ObjectScript (COS) доступ за пределы Caché богат возможностями (в .Net/Java через .Net/Java Gateway, к реляционным СУБД через SQL Gateway, работа с веб-сервисами). Но если говорить о работе с нативными бинарными библиотеками, то такое взаимодействие реализуется через Caché Callout Gateway, который несколько специфичен. О том как радикально облегчить работу с нативными библиотеками непосредственно из COS можно узнать по катом.
Caché Callout Gateway
-
$ZF(-1), $ZF(-2). Первая группа функций позволяет работать с системными командами и консольными программами. Это эффективный инструмент, но его недостаток очевиден — всю функциональность библиотеки сложно реализовать в одной или нескольких программах.
Пример использования $ZF(-1)
Создание новой папки в рабочей директории с именем «newfolder»:
set name = «newfolder» set status = $ZF(-1, «mkdir » _ name)
Пример создания Callout Library и вызова функции из нее
Callout Library, файл test.c:
#define ZF_DLL #include // Файл cdzf.h находится в папке Cache/dev/cpp/include int square(int input, int *output) < *output = input * input; return ZF_SUCCESS; >ZFBEGIN // Таблица символов ZFENTRY(«square», «iP», square) // «iP» означает, что в square два аргумента — int и int * ZFEND
Компиляция (mingw):
gcc -mdll -fpic test.c -o test.dll
На Линуксе надо заменить -mdll на -shared.
Вызов square() из Caché:
USER> do $ZF(-3, «test.dll», «square», 9) 81
Caché Native Access
Чтобы снять ограничения Callout Gateway и сделать работу с нативныим библиотеками удобной, был создан проект CNA . Название — калька с аналогичного проекта под Java-машину JNA.
Возможности CNA:
- Можно вызывать функции из любой динамической (разделяемой) библиотеки, бинарно совместимой с С
- Для вызова функций нужен только код на COS — ничего писать на C или другом компилируемом в машинный код языке не надо
- Поддержка всех простых типов языка C, size_t и указателей
- Поддержка структур (и вложенных структур)
- Поддержка потоков Caché
- Поддерживаемые платформы: Linux (x86-32/64), Windows (x86-32/64)
Установка
Сначала собираем С часть, компилируется одной командой —
make libffi make
Под Windows можно использовать для компиляции mingw, либо скачать уже готовые бинарные файлы. Потом импортируем файл cna.xml в любую удобную область:
do $system.OBJ.Load(«путь к cna.xml», «c»)
Пример работы с CNA
Самая простая нативная библиотека, которая есть на всех системах — стандартная библиотека C. В Windows она обычно находится по адресу C:WindowsSystem32msvcrt.dll, в Linux — /usr/lib/libc.so. Попробуем вызвать какую-нибудь функцию из нее, например strlen, у нее такой прототип:
size_t strlen(const char *);
Class CNA.Strlen Extends %RegisteredObject < ClassMethod Call(libcnaPath As %String, libcPath As %String, string As %String) As %Integer < set cna = ##class(CNA.CNA).%New(libcnaPath) // Создает объект типа CNA.CNA do cna.LoadLibrary(libcPath) // Загружаем libc в CNA set pString = cna.ConvertStringToPointer(string) // Конвертируем строку в формат C и сохраняем указатель на начало // Вызываем strlen: передаем название функции, тип возвращаемого значения, // список типов аргументов и все аргументы через запятую set result = cna.CallFunction(«strlen», cna.#SIZET, $lb(cna.#POINTER), pString) do cna.FreeLibrary() return result >>
В терминале:
USER>w ##class(CNA.Strlen).Call(«libcna.dll», «C:Windowssystem32msvcrt.dll», «hello») 5
Подробности реализации
CNA — это связка библиотеки на C и класса Caché. В основном CNA полагается на libffi. libffi — это библиотека, которая позволяет организовать «низкий уровень» интерфейса внешних функций (FFI). Она помогает забыть о существовании различных соглашений о вызове и вызывать функции во время выполнения, без предоставления их спецификаций во время компиляции.
Но для вызова функций из libffi нужен адрес функции, а мы хотели бы вызывать функции только по имени. Чтобы получить адрес функции из какой-либо по имени придется пользоваться платформо-зависимыми интерфейсами: POSIX и WinAPI. В POSIX есть механизм dlopen() / dlsym() для загрузки библиотеки и поиска адреса функции, в WinAPI — функции LoadLibrary() и GetProcAddress(). Это одно из препятствий к портированию CNA на другие платформы, хотя с другой стороны, почти все современные системы хоть частично, но поддерживают стандарт POSIX (кроме, разумеется, Windows).

libffi написана на C и ассемблере. Следовательно libffi и есть native library, и доступ к ней из Caché, можно получить только c помощью Callout Gateway. То есть нужно написать прослойку, которая бы соединяла libffi и Caché и являлась бы Callout Library, чтобы к ней можно было обращаться из COS. Примерная схема работы CNA:
На этом этапе появляется проблема преобразования данных. Когда мы вызываем функцию из COS, мы передаем аргументы во внутреннем формате Caché. Нужно передать их в Сallout Gateway, потом в libffi, но при этом еще нужно где-то преобразовать их в формат C. Но Callout Gateway поддерживает очень мало типов данных и если бы мы преобразовывали данные на стороне C, то нам пришлось бы передавать все в виде строк, а потом их парсить, что не удобно по многим причинам. Поэтому было принято решение преобразовывать данные на стороне Cache и передавать все аргументы в виде строк с бинарными данными уже в формате C.
Так как все типы данных С, кроме композитных, это числа, то фактически задача преобразования данных сводится к преобразованию чисел в бинарные строки с помощью COS. Для этих целей в Caché есть замечательные функции, позоволяющие обойти необходимость прямого доступа к данным: $CHAR и $ASCII, преобразовывающие 8-битное число в символ и обратно.
Аналоги есть и для всех необходимых чисел — для 16, 32 и 64-битных целых и чисел с плавающей запятой двойной точности. Но есть одно но — все эти функции работают только либо для знаковых, либо для беззнаковых чисел (разумеется, при работе с целыми). В C же, как известно, число любого размера может быть как знаковое, так и беззнаковое. Дополнять эти функции до полноценной работы придется вручную.
- Первый бит отвечает за знак числа: 0 — плюс, 1 — минус
- Положительные числа кодируются аналогично беззнаковым
- Максимальное положительное число — 2 k-1 -1, k — количество бит
- Код отрицательного числа x совпадает с кодом беззнакового числа 2 k +x
Рассмотрим пример преобразования для беззнаковых 32-битных чисел. Если число положительное, то просто используем функцию $ZLCHAR, если отрицательное — то надо найти такое беззнаковое число, чтобы в бинарном виде они совпадали. Как искать это число, напрямую следует из определения дополнительного кода — нужно прибавить исходное число к минимальному, которое не помещается в 32 бита — 2 32 или FFFFFFFF16 + 1. В итоге получается такой код:
if (x < 0) < set x = $ZLCHAR($ZHEX(«FFFFFFFF») + x + 1) >else set x = $ZLCHAR(x) >
Следующая проблема — преобразование структур, композитного типа языка C. Все было бы просто, если бы структуры в памяти представлялись таким же образом, каким они записывались — все поля следуют подряд, одно за другим.
Но в памяти структура располагается так, чтобы адрес каждого из полей был кратен специальному числу, выравниванию поля. Конец структуры тоже выравнивается — по наибольшему выравниванию поля. Выравнивание нужно из-за того, что большинство платформ либо не умеют работать с невыровненными данными, либо делают это довольно медленно. Обычно на x86 выравнивание равно размеру поля, но есть исключение — 32-битный Linux, там выравнивание всех полей, размер которых больше 4 байт, равно как раз 4 байтам. Подробнее про выравнивание данных можно почитать в этой статье.
Возьмем, как пример, такую структуру:
struct X < char a, b; // sizeof(char) == 1 double c; // sizeof(double) == 8 char d; >;
На x86-32 она в разных ОС будет располагаться в памяти по разному:
На практике такое представление структуры формируется достаточно просто. Нужно последовательно записывать поля в память, но каждой раз формировать отступ(padding) — пустое пространство перед записью. Отступ высчитывается таким образом:
set padding = (alignment — (offset # alignment)) # alignment //offset — адрес конца последней записи
Что пока не работает
1) Целые числа в Caché представляются таким образом, что точная работа с ними гарантируется только пока число не выходит за пределы 64-битного знакового числа. Но в C есть 64-битный беззнаковый тип (unsigned long long). То есть передать во внешнюю функцию число, которое превышает максимальное 64-битное знаковое, 2 63 -1(~ 9 * 10 18 ), не удастся.
2) Для работы с вещественными числами в Caché есть два типа: собственный десятичный и числа с плавающей запятой двойной точности стандарта IEEE 754. То есть аналогов типов языка C float и long double в Caché нет. Работать в CNA c этими типами можно, но при каждом попадании в Caché они будут конвертироваться в double.
3) При работе на Windows с long double скорее всего все будет работать неправильно. Это вызвано тем, что у Microsoft и команды разработчиков mingw принципиально разные взгляды на то, каким должен быть long double. Microsoft считает что и на 32, и на 64-битной системе размер long double — 8 байт. В mingw же на 32 битах — 12 байт, на 64 — 16. И так как CNA компилируется именно с помощью mingw — про long double лучше забыть.
4) Отсутствует поддержка объединений (unions) и битовых полей в структурах (bitfields). Это вызвано тем, что libffi их не поддерживает.
Критика, замечания, предложения — приветствуются.
Весь исходный код выложен на гитхаб под лицензией MIT.
github.com/intersystems-ru/cna
Источник: habr.com
Использование JNA для доступа к собственным динамическим библиотекам
Узнайте, как использовать JNA для легкого доступа к машинному коду по сравнению с JNI.
1. Обзор
В этом уроке мы увидим, как использовать библиотеку Java Native Access (сокращенно JNA) для доступа к собственным библиотекам без написания кода JNI (Java Native Interface).
2. Почему JNA?
В течение многих лет Java и другие языки, основанные на JVM, в значительной степени выполняли свой девиз “пиши один раз, работай везде”. Однако иногда нам нужно использовать собственный код для реализации некоторых функций :
- Повторное использование устаревшего кода, написанного на C/C++ или любом другом языке, способном создавать собственный код
- Доступ к системным функциям, недоступным в стандартной среде выполнения Java
- Оптимизация скорости и/или использования памяти для определенных разделов данного приложения.
Изначально такое требование означало, что нам придется прибегнуть к собственному интерфейсу JNI – Java. Несмотря на эффективность, этот подход имеет свои недостатки, и его, как правило, избегали из-за нескольких проблем:
- Требуется, чтобы разработчики писали “клеевой код” на C/C++ для соединения Java и собственного кода
- Требуется полный набор инструментов для компиляции и компоновки, доступный для каждой целевой системы
- Маршалинг и удаление значений из JVM-это утомительная и подверженная ошибкам задача
- Юридические и вспомогательные проблемы при смешивании Java и собственных библиотек
JNA пришла, чтобы решить большую часть сложностей, связанных с использованием JNI. В частности, нет необходимости создавать какой-либо код JNI для использования собственного кода, расположенного в динамических библиотеках, что значительно упрощает весь процесс.
Конечно, есть некоторые компромиссы:
- Мы не можем напрямую использовать статические библиотеки
- Медленнее по сравнению с кодом JNI ручной работы
Однако для большинства приложений преимущества простоты JNA намного перевешивают эти недостатки. Таким образом, справедливо сказать, что, если у нас нет очень конкретных требований, JNA сегодня, вероятно, является лучшим доступным выбором для доступа к машинному коду с Java – или любого другого языка, основанного на JVM, кстати.
3. Настройка проекта JNA
Первое, что нам нужно сделать, чтобы использовать JNA, – это добавить его зависимости в ваш проект pom.xml :
net.java.dev.jna jna-platform 5.6.0
Последнюю версию jna-платформы можно загрузить с Maven Central.
4. Использование JNA
Использование JNA-это двухэтапный процесс:
- Во-первых, мы создаем интерфейс Java, который расширяет интерфейс JNA Library для описания методов и типов, используемых при вызове целевого собственного кода
- Затем мы передаем этот интерфейс в JNA, который возвращает конкретную реализацию этого интерфейса, которую мы используем для вызова собственных методов
4.1. Вызов методов из стандартной библиотеки C
В нашем первом примере давайте используем JNA для вызова функции cosh из стандартной библиотеки C, которая доступна в большинстве систем. Этот метод принимает аргумент double и вычисляет его гиперболический косинус . Программа A-C может использовать эту функцию, просто включив файл заголовка :
#include #include int main(int argc, char** argv)
Давайте создадим интерфейс Java, необходимый для вызова этого метода:
public interface CMath extends Library
Затем мы используем класс Native JNA для создания конкретной реализации этого интерфейса, чтобы мы могли вызвать наш API:
CMath lib = Native.load(Platform.isWindows()?»msvcrt»:»c», CMath.class); double result = lib.cosh(0);
Действительно интересной частью здесь является вызов метода load () //. Он принимает два аргумента: имя динамической библиотеки и интерфейс Java, описывающий методы, которые мы будем использовать. Он возвращает конкретную реализацию этого интерфейса, позволяя нам вызывать любой из его методов.
Теперь имена динамических библиотек обычно зависят от системы, и стандартная библиотека C не является исключением: libc.so в большинстве систем на базе Linux, но msvcrt.dll в Windows. Вот почему мы использовали вспомогательный класс Platform , включенный в JNA, чтобы проверить, на какой платформе мы работаем, и выбрать правильное имя библиотеки.
Обратите внимание, что нам не нужно добавлять расширение .so или .dll , как они подразумеваются. Кроме того, для систем на базе Linux нам не нужно указывать префикс “lib”, который является стандартным для общих библиотек.
Поскольку динамические библиотеки ведут себя следующим образом Синглеты с точки зрения Java, обычной практикой является объявление ПРИМЕР поле как часть объявления интерфейса:
public interface CMath extends Library
4.2. Отображение основных типов
В нашем первоначальном примере вызываемый метод использовал только примитивные типы в качестве аргумента и возвращаемого значения. ОДИН обрабатывает эти случаи автоматически, обычно используя их естественные аналоги Java при сопоставлении с типами C:
- char => байт
- короткий => короткий
- char_t => char
- int => int
- long => com.sun.jna.NativeLong
- долго долго => долго
- float => поплавок
- двойной => двойной
- char * => Строка
Сопоставление, которое может показаться странным, используется для собственного типа long . Это связано с тем, что в C/C++ тип long может представлять 32 – или 64-разрядное значение, в зависимости от того, работаем ли мы в 32 – или 64-разрядной системе.
Для решения этой проблемы JNA предоставляет тип Native Long , который использует правильный тип в зависимости от архитектуры системы.
4.3. Структуры и союзы
Другим распространенным сценарием является работа с API-интерфейсами собственного кода, которые ожидают указатель на некоторый struct или union type . При создании интерфейса Java для доступа к нему соответствующий аргумент или возвращаемое значение должны быть типом Java , который расширяет структуру или объединение соответственно.
Например, учитывая эту структуру C:
struct foo_t < int field1; int field2; char *field3; >;
Его одноранговый класс Java будет:
В качестве альтернативы мы можем переопределить метод getFieldOrder() для того же эффекта. При ориентации на одну архитектуру/платформу первый метод, как правило, достаточно хорош. Мы можем использовать последнее для решения проблем выравнивания на разных платформах, которые иногда требуют добавления дополнительных полей заполнения.
Профсоюзы работают аналогично, за исключением нескольких моментов:
Давайте посмотрим, как это сделать на простом примере:
public class MyUnion extends Union < public String foo; public double bar; >;
Теперь давайте использовать My Union с гипотетической библиотекой:
MyUnion u = new MyUnion(); u.foo = «test»; u.setType(String.class); lib.some_method(u);
Если оба foo и bar where имеют один и тот же тип, нам придется использовать вместо этого имя поля:
u.foo = «test»; u.setType(«foo»); lib.some_method(u);
4.4. Использование указателей
JNA предлагает абстракцию Pointer , которая помогает работать с API, объявленными с нетипизированным указателем – обычно это void * . Этот класс предлагает методы, которые позволяют осуществлять доступ на чтение и запись к базовому буферу собственной памяти, что сопряжено с очевидными рисками.
Прежде чем начать использовать этот класс, мы должны быть уверены, что четко понимаем, кто “владеет” ссылочной памятью в каждый момент времени. Невыполнение этого требования, скорее всего, приведет к трудным для отладки ошибкам, связанным с утечками памяти и/или недопустимыми обращениями.
Предполагая, что мы знаем, что делаем (как всегда), давайте посмотрим, как мы можем использовать хорошо известные функции malloc() и free() с JNA, используемые для выделения и освобождения буфера памяти. Во-первых, давайте снова создадим наш интерфейс-оболочку:
public interface StdC extends Library < StdC INSTANCE = // . instance creation omitted Pointer malloc(long n); void free(Pointer p); >
Теперь давайте используем его для выделения буфера и поиграем с ним:
StdC lib = StdC.INSTANCE; Pointer p = lib.malloc(1024); p.setMemory(0l, 1024l, (byte) 0); lib.free(p);
Метод set Memory() просто заполняет базовый буфер постоянным байтовым значением (в данном случае нулем). Обратите внимание, что экземпляр Pointer не имеет представления о том, на что он указывает, а тем более о его размере. Это означает, что мы можем довольно легко повредить нашу кучу, используя ее методы.
Позже мы увидим, как мы можем смягчить такие ошибки, используя функцию защиты от сбоев JNA.
4.5. Обработка Ошибок
Старые версии стандартной библиотеки C использовали глобальную переменную errno для хранения причины сбоя конкретного вызова. Например, это то, как типичный вызов open() будет использовать эту глобальную переменную в C:
int fd = open(«some path», O_RDONLY); if (fd
Конечно, в современных многопоточных программах этот код не будет работать, верно? Что ж, благодаря препроцессору C разработчики все еще могут писать такой код, и он будет работать просто отлично. Оказывается, что в настоящее время errno – это макрос, который расширяется до вызова функции:
// . excerpt from bits/errno.h on Linux #define errno (*__errno_location ()) // . excerpt from from Visual Studio #define errno (*_errno())
Теперь этот подход отлично работает при компиляции исходного кода, но при использовании JNA такого нет. Мы могли бы объявить расширенную функцию в нашем интерфейсе оболочки и вызвать ее явно, но INA предлагает лучшую альтернативу: LastErrorException .
Любой метод, объявленный в интерфейсах оболочки с , вызывает исключение LastErrorException , автоматически включит проверку на наличие ошибки после собственного вызова. Если он сообщит об ошибке, JNA выдаст исключение LastErrorException , которое включает исходный код ошибки.
Давайте добавим несколько методов в интерфейс Std C wrapper, который мы использовали ранее, чтобы показать эту функцию в действии:
public interface StdC extends Library < // . other methods omitted int open(String path, int flags) throws LastErrorException; int close(int fd) throws LastErrorException; >
Теперь мы можем использовать open() в предложении try/catch:
StdC lib = StdC.INSTANCE; int fd = 0; try < fd = lib.open(«/some/path»,0); // . use fd >catch (LastErrorException err) < // . error handling >finally < if (fd >0) < lib.close(fd); >>
В блоке catch мы можем использовать LastErrorException.getErrorCode () , чтобы получить исходное значение errno и использовать его как часть логики обработки ошибок.
4.6. Обработка Нарушений Доступа
Как упоминалось ранее, JNA не защищает нас от неправильного использования данного API, особенно при работе с буферами памяти, передаваемыми туда и обратно собственным кодом . В обычных ситуациях такие ошибки приводят к нарушению доступа и завершают работу JVM.
JNA в некоторой степени поддерживает метод, который позволяет Java-коду обрабатывать ошибки нарушения доступа. Есть два способа активировать его:
- Установка свойства jna.protected system в true
- Вызов Native.setProtected(true)
Как только мы активируем этот защищенный режим, JNA поймает ошибки нарушения доступа, которые обычно приводят к сбою, и выдаст java.lang.Ошибка исключение. Мы можем проверить, что это работает, используя указатель |, инициализированный недопустимым адресом, и пытаясь записать в него некоторые данные:
Native.setProtected(true); Pointer p = new Pointer(0l); try < p.setMemory(0, 100*1024, (byte) 0); >catch (Error err) < // . error handling omitted >
Однако, как указано в документации, эта функция должна использоваться только для целей отладки/разработки.
5. Заключение
В этой статье мы показали, как использовать JNA для легкого доступа к машинному коду по сравнению с JNI.
Как обычно, весь код доступен на GitHub .
Источник: javascopes.com